引入
分布式系统,涉及一个非常关键的问题:单点问题------如果某个服务器程序,只有一个节点(只搞一个物理服务器,来部署这个服务器程序)
遇到的困难:
- 可用性问题,如果这个机器挂了,就意味着服务中断了
- 性能/支持的并发量也是非常有限的
引入分布式系统,主要就是为了解决上述单点问题。
在分布式系统中,希望有多个服务器来部署redis服务,从而构成一个redis集群,此时就可以让这个集群给整个分布式系统中其他服务提供更稳定高效的数据存储功能。
分布式系统中,希望有多个服务器来部署redis服务,存在以下几种redis的部署方式:
- 主从模式
- 主从 + 哨兵模式
- 集群模式
主从模式
在若干个redis节点中,有的是主节点 ,有的是从节点。
假设有三个物理服务器(称之为三个节点),分别部署了一个redis-server进程。
此时就可以把其中一个节点,作为主节点 ,另外两个节点作为从节点 。
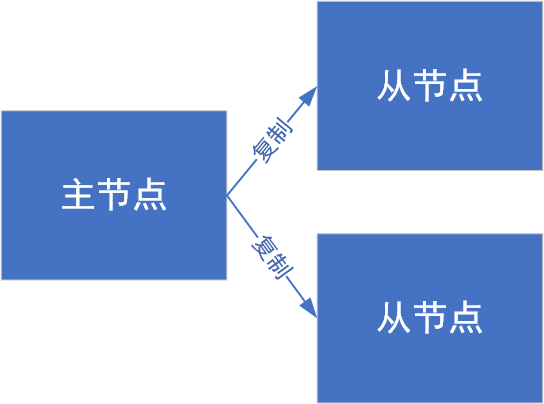
从节点上的数据要跟随主节点变化,要跟主节点的数据保持一致 ------从节点就是主节点的副本。
如果改了从节点的数据,是否把从节点的数据往主节点上同步?
不允许的,redis主从模式中,从节点上的数据,不允许修改,只能读取数据。
后续客户端来读取数据,就可以从任意一个节点中读取。
对于之前的单点问题------单个redis服务器节点挂了,整个redis就挂了。
而上述这个主从结构,这些redis的机器不太可能同时挂。
如果是挂掉了某个从节点,没什么影响,此时继续从主节点或其他节点读取数据即可。
如果是挂掉了主节点,还是有一定影响,从节点只能读数据,如果需要写数据,就没得写了。
实际上,主从模式主要针对读操作,进行并发量&可用性的提高,而写操作的话,是非常依赖主节点的,主节点也不能搞多个。
关于主从节点的传输
主从节点之间是通过网络传输 的(TCP)
TCP内部支持了nagle算法(默认开启)
- 开启了,就会增加tcp的传输延迟,但节省了网络带宽
- 关闭了,就会减少tcp的传输延迟,但增加了网络带宽
目的是和tcp捎带应答一样,针对小的tcp数据包进行合并,减少了包的个数------节省带宽,但增加延迟
配置文件中repl-disable-tcp-nodelay这个选项可以用于在主从同步通信过程中,关闭tcp的nagle算法,从节点更快速和主节点进行同步。
配置主从结构
配置redis主从结构,首先需要启动多个redis服务器。
在一个云服务器上,运行多个redis-server进程,需要保证多个redis-server的端口是要不同的。
bash
root@VM-8-5-ubuntu:/etc/redis# cp redis.conf ./slave1.conf
root@VM-8-5-ubuntu:/etc/redis# cp redis.conf ./slave2.conf
root@VM-8-5-ubuntu:/etc/redis# ll
total 340
drwxrws--- 2 redis redis 4096 Feb 14 13:42 ./
drwxr-xr-x 130 root root 12288 Feb 8 00:01 ../
-rw-r----- 1 redis redis 106601 Feb 12 00:58 redis.conf #主服务器
-rw-r----- 1 root redis 106601 Feb 14 13:42 slave1.conf #从服务器1
-rw-r----- 1 root redis 106601 Feb 14 13:42 slave2.conf #从服务器2
bash
# 配置文件中都改为允许后台进程
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
# When Redis is supervised by upstart or systemd, this parameter has no impact.
daemonize yes #改为yes,按照守护进程(后台进程)的方式来运行主服务器配置文件
bash
# Accept connections on the specified port, default is 6379 (IANA #815344).
# If port 0 is specified Redis will not listen on a TCP socket.
port 6379从服务器1配置文件
bash
# Accept connections on the specified port, default is 6379 (IANA #815344).
# If port 0 is specified Redis will not listen on a TCP socket.
port 6380从服务器2配置文件
bash
# Accept connections on the specified port, default is 6379 (IANA #815344).
# If port 0 is specified Redis will not listen on a TCP socket.
port 6381启动所有从服务器
bash
root@VM-8-5-ubuntu:/etc/redis# redis-server ./slave1.conf
root@VM-8-5-ubuntu:/etc/redis# redis-server ./slave2.conf
root@VM-8-5-ubuntu:/etc/redis# ps aux | grep redis
root 260322 0.0 0.3 67872 6840 ? Ssl 13:54 0:00 redis-server 0.0.0.0:6380 #从服务器1
root 260337 0.0 0.3 67872 6944 ? Ssl 13:54 0:00 redis-server 0.0.0.0:6381 #从服务器2
redis 3579030 0.1 0.4 78116 8064 ? Ssl Feb12 4:57 /usr/bin/redis-server 0.0.0.0:6379 #主服务器
root 260561 0.0 0.1 6544 2304 pts/3 S+ 13:54 0:00 grep --color=auto redisslaveof配置主从结构
配置主从结构,需要使用slaveof
- 在配置文件中加入
slaveof {masterHost} {masterPort}随reids启动生效 - 在redis-server启动命令时加入
--slaveof {masterHost} {masterPort}生效 - 直接使用redis命令:
slaveof {masterHost} {masterPort}生效
例子:直接使用redis命令
bash
root@VM-8-5-ubuntu:/etc/redis# redis-cli -p 6380 # 登录一个从节点(从服务器1)
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 以6379为主节点
OK例子:修改配置文件
bash
# 从服务器1
# 加上主从结构配置
# 以6379为主节点
slaveof 127.0.0.1 6379
bash
# 从服务器2
# 加上主从结构配置
# 以6379为主节点
slaveof 127.0.0.1 6379kill命令杀死进程,重新启动
bash
root@VM-8-5-ubuntu:/etc/redis# kill -9 324720 324735 3579030
root@VM-8-5-ubuntu:/etc/redis# ps aux | grep redis
root 328243 0.0 0.1 6544 2304 pts/3 S+ 18:25 0:00 grep --color=auto rediskill -9 260322 260337这种停止redis-server的方式是之前直接运行redis-server命令进行搭配的(redis-server ./slave1.conf)
而如果使用service redis-server start 这种方式启动的,就必须使用service redis-server stop进行停止(此时如果使用kill -9方式停止,kill后,redis-server进程能自动启动)
bash
root@VM-8-5-ubuntu:/etc/redis# redis-server ./slave1.conf
root@VM-8-5-ubuntu:/etc/redis# redis-server ./slave2.conf
root@VM-8-5-ubuntu:/etc/redis# ps aux | grep redis
root 328361 0.0 0.3 67872 7344 ? Ssl 18:25 0:00 redis-server 0.0.0.0:6379
root 328402 0.1 0.3 78116 6952 ? Ssl 18:25 0:00 redis-server 0.0.0.0:6380
root 328434 0.0 0.3 78116 7208 ? Ssl 18:25 0:00 redis-server 0.0.0.0:6381
root 328478 0.0 0.1 6544 2304 pts/3 S+ 18:25 0:00 grep --color=auto redis
bash
root@VM-8-5-ubuntu:/etc/redis# netstat -anp | grep redis-server
tcp 0 0 0.0.0.0:6381 0.0.0.0:* LISTEN 328434/redis-server
tcp 0 0 0.0.0.0:6380 0.0.0.0:* LISTEN 328402/redis-server
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 328361/redis-server
tcp 0 0 127.0.0.1:52640 127.0.0.1:6379 ESTABLISHED 328402/redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:52640 ESTABLISHED 328361/redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:52648 ESTABLISHED 328361/redis-server
tcp 0 0 127.0.0.1:52648 127.0.0.1:6379 ESTABLISHED 328434/redis-server
tcp6 0 0 ::1:6379 :::* LISTEN 328361/redis-server
tcp6 0 0 ::1:6380 :::* LISTEN 328402/redis-server
tcp6 0 0 ::1:6381 :::* LISTEN 328434/redis-server ESTABLISHED:表示已建立连接
127.0.0.1:52640 <=> 127.0.0.1:6379从服务器1与主服务器之间已建立起tcp连接
127.0.0.1:52648 <=> 127.0.0.1:6379从服务器2与主服务器之间已建立起tcp连接
至此已经形成主从结构。
断开主从结构
slaveof no one:直接在客户端中输入命令
直接使用这个命令断开现有的主从复制关系。
从节点断开主从关系,他就不再属于其他节点,但是里面已经有的数据不会丢弃。
拓扑结构
若干个节点之间,按照啥样的方式进行组织连接。
⼀主⼀从拓扑
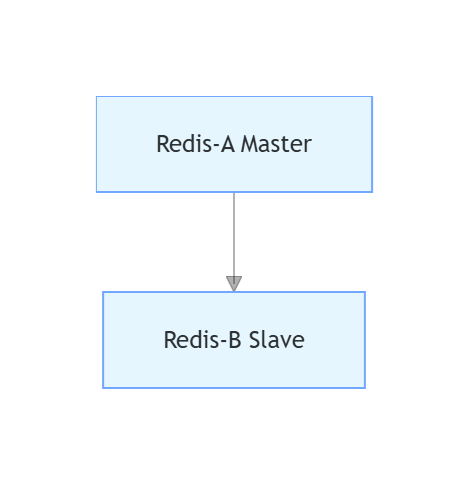
当应⽤写命令并发量较⾼且需要持久化时,可以只在从节点上开启 AOF,这样既可以保证数据
安全性同时也避免了持久化对主节点的性能⼲扰。
注意:当主节点关闭持久化功能时,如果主节点宕机,要避免⾃动重启操作,因为一旦重启主节点无法通过aof方式恢复,数据消失,但是从节点要同步主节点数据,导致从节点数据也消失。
⼀主多从拓扑
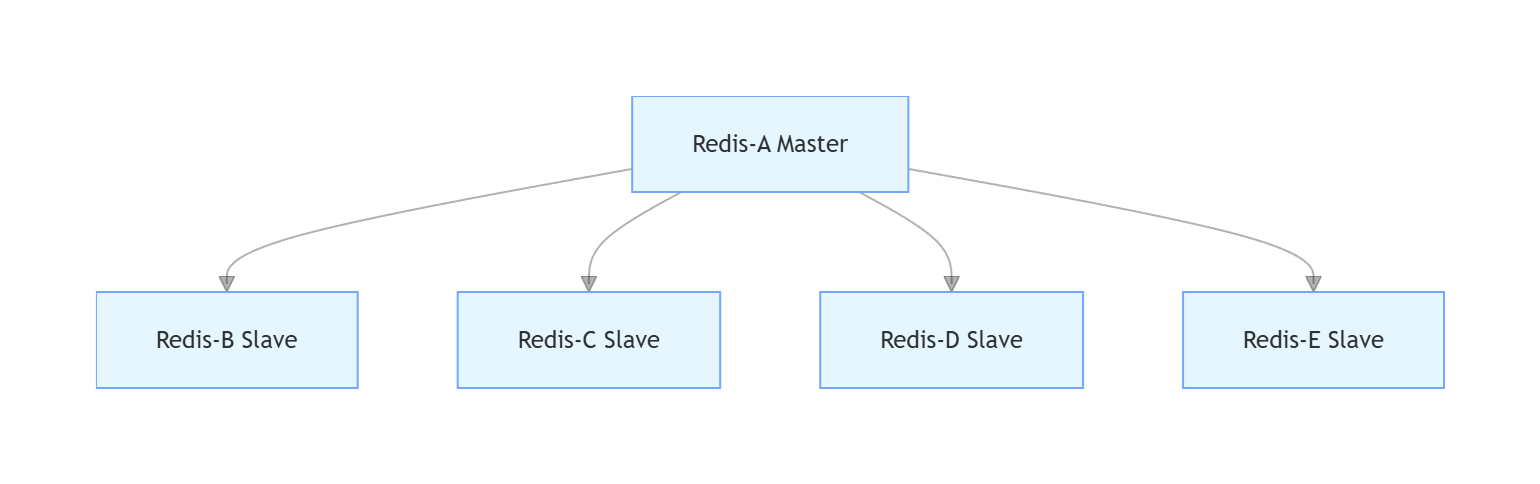
对于写并发量较⾼的场景,多个从节点会导致主节点写命令的多次发送从⽽加重主节点的负载,消耗主节点的带宽比较多。
树形拓扑
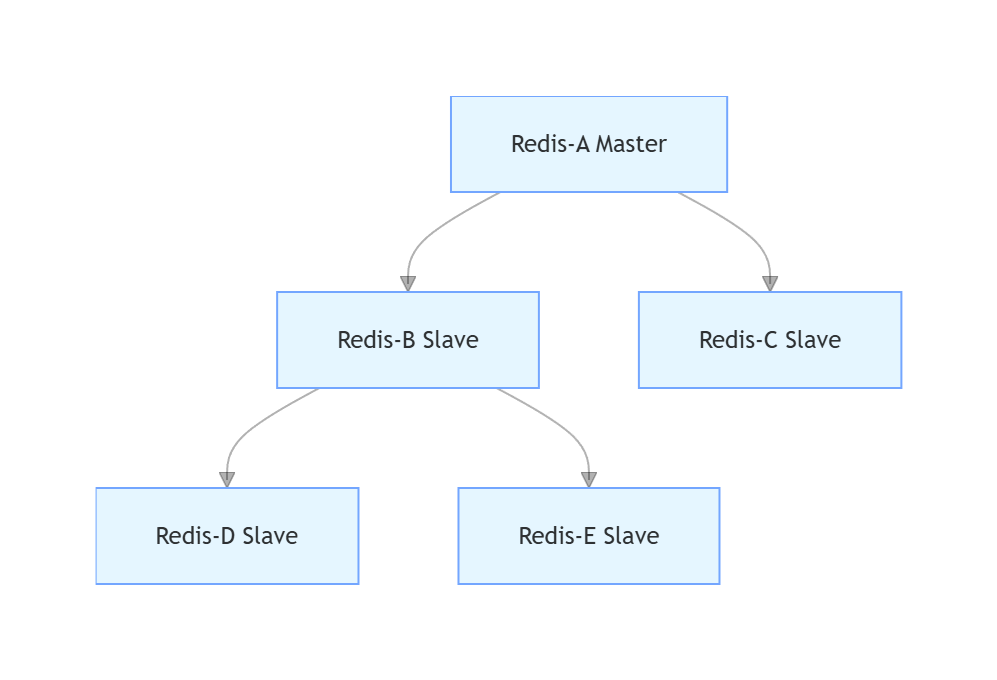
主节点不需要刚才那么多带宽 ,但是数据一旦修改了,同步的延迟是比较长的。
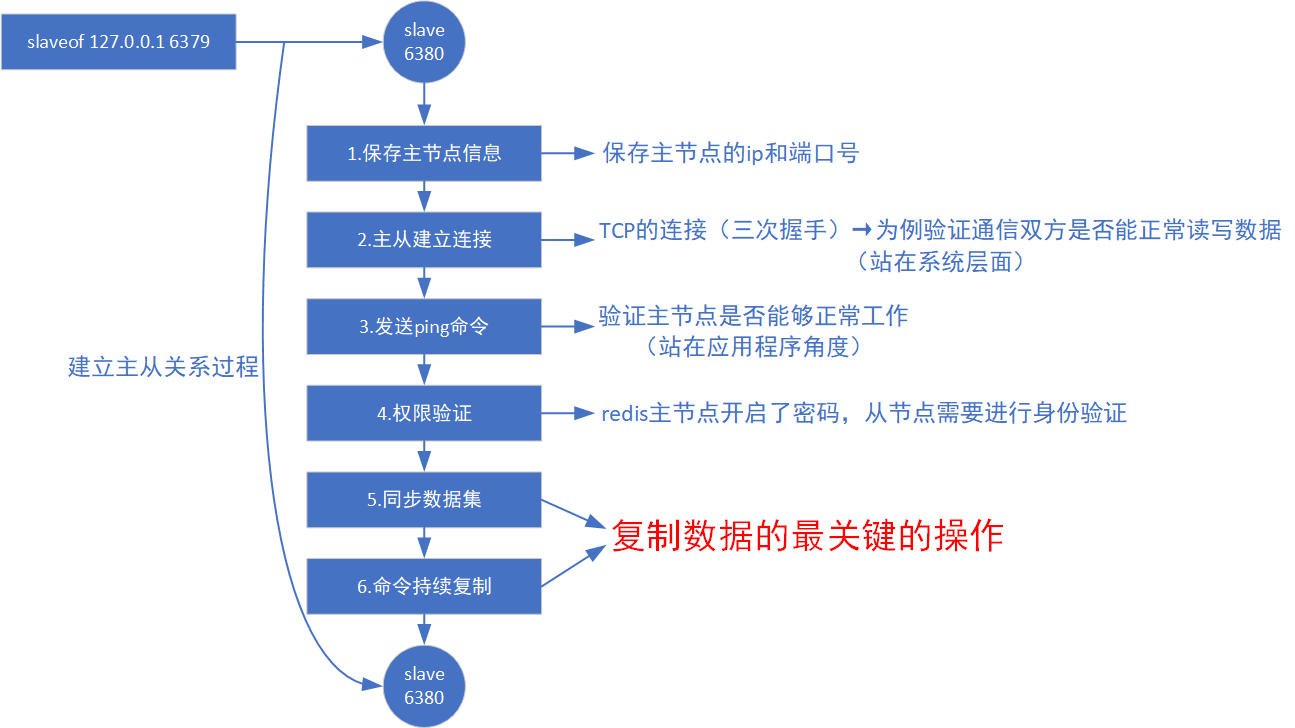
主从复制的原理
主从节点建立复制流程图
psync命令
redis提供了psync命令,完成数据同步的过程。
psync不需要咱们手动执行,redis服务器会在建立好主从关系之后,自动执行psync。
从节点负责执行psync,从节点从主节点这边拉取数据。
同步过程分为:全量复制和部分复制。
- 全量复制:⼀般⽤于初次复制场景,Redis 早期⽀持的复制功能只有全量复制,它会把主节点全部数据⼀次性发送给从节点,当数据量较⼤时,会对主从节点和⽹络造成很⼤的开销。
- 部分复制:⽤于处理在主从复制中因⽹络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点。因为补发的数据远⼩于全量数据,可以有效避免全量复制的过⾼开销。
PSYNC 的语法格式
psync relicationid offset
- 如果 replicationid 设为 ? 并且 offset 设为 -1 此时就是在尝试进⾏全量复制。
- 如果 replicationid offset 设为了具体的数值, 则是尝试进⾏部分复制。
psync可以从主节点获取全量数据,也可以获取一部分数据。
主要就是看offset的进度
- offset 写作 -1,就是获取全量数据。
- offset 写作具体数据,则是从当前偏移量位置获取
replicationid/replid(复制id)
主节点的复制 id 。是主节点生成的,主节点每次启动 时生成,或者从节点晋级成主节点 也会生成。
注意:即使是同一个主节点,每次重启,生成的 replication id 都是不同的。
info replication 获取到当前 replication id 的值
从节点的内存里会专门存一个 master_replid 字段,值就是主节点的 replid。
主服务器
bash
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=98392,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=98392,lag=1
master_failover_state:no-failover
master_replid:a893633de924b56a66226aab2aa053782827ad6e #生成一个replid
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98392从服务器
bash
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:98378
slave_repl_offset:98378
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:a893633de924b56a66226aab2aa053782827ad6e #保存主节点的replid
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98378
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:98364例子:
比如主节点 A 的 replid 是 ID1,从节点 B 连上 A 后,就把自己的 master_replid 设为 ID1。
只要 B 的 master_replid 是 ID1,就说明 B 认 A 当主,只同步 A 的数据。
如果 B 不小心连到了其他主节点 C(replid 是 ID2),发现 master_replid 和对方的 replid 不一致,就知道「连错主了」,会重新确认同步关系。
在主服务器的信息,我们发现有两个 replid 分别是 master_replid 与 master_replid2
bash
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=3752,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=3752,lag=1
master_failover_state:no-failover
master_replid:a893633de924b56a66226aab2aa053782827ad6e #主节点的replid
master_replid2:0000000000000000000000000000000000000000 #为什么会有两个replid
master_repl_offset:3752
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:3752- replid------主节点复制ID
- replid2------旧主节点复制ID
一般情况下replid2是用不上的。
特殊情况:只有从节点晋升为主节点时才会用到,新主会把之前老主的 replid 存到自己的 replid2 里。
关于从节点晋升为主节点
从节点和主节点断开连接,有两种情况:
- 从节点主动和主节点断开连接
slaveof no one这个时候,从节点就能晋升成主节点。 - 主节点挂了
这个时候从节点不会晋升成主节点,需要人工干预的方式恢复主节点。
场景举例------replid2的用处
有一个主节点A(生成一个replid),还有一个从节点B(获取到A的replid)。
如果A和B通信过程中出现了网络抖动,B可能认为A挂了,B就会自己成为主节点(从节点晋升成主节点),给自己生成一个replid。
此时,B也会保存,之前旧的replid,就是通过 replid2 保存。
后续网络稳定了,B还可以根据replid2,重新和A建立主从关系(A主,B从)。注意 :可能需要手动干预,哨兵机制,可以自动完成这个过程
offset 偏移量
主节点和从节点上都会维护 偏移量 (整数)
主节点的偏移量:主节点上会收到很多的修改操作的命令,每个命令都要占据几个字节,主节点会把这些命令的字节数进行累加。
从节点的偏移量:描述了现在从节点数据同步到什么地方了。
主服务器中记录了从服务器的offset
bash
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=98392,lag=1 #从服务器1的offset
slave1:ip=127.0.0.1,port=6381,state=online,offset=98392,lag=1 #从服务器2的offset
master_failover_state:no-failover
master_replid:a893633de924b56a66226aab2aa053782827ad6e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98392总结 :
replication id 和 offset 共同描述了一个"数据集合"。
如果两台机器,replication id一样,offset一样,就可以认为这两个redis机器上存的数据一模一样。
psync 运⾏流程
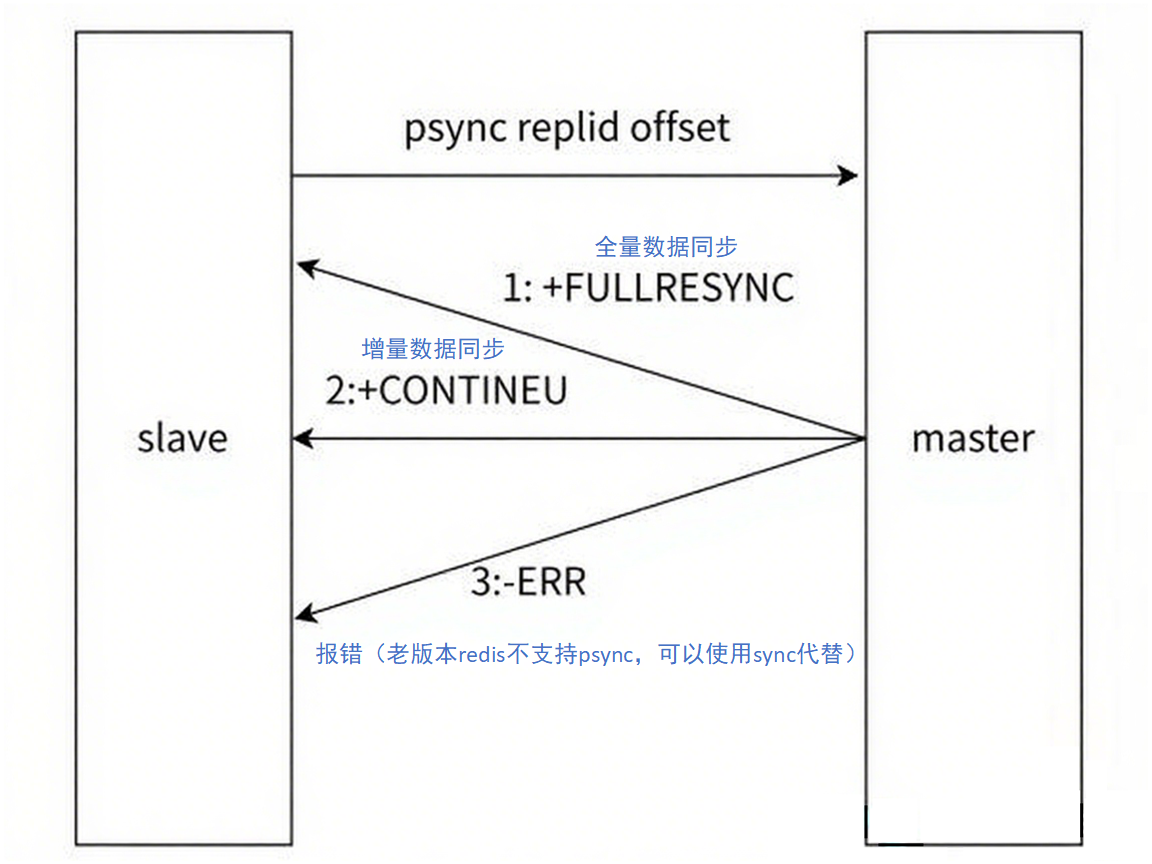
什么时候进行全量复制:
- 首次和主节点进行数据同步
- 主节点不方便进行部分复制
什么时候进行部分复制:
- 从节点之前已经从主节点上复制过数据,因为网络抖动或从节点重启了
- 从节点需要重新从主节点这边同步数据,此时看看能不能只同步一小部分
全量复制
主从第⼀次建⽴复制时必须经历的阶段。
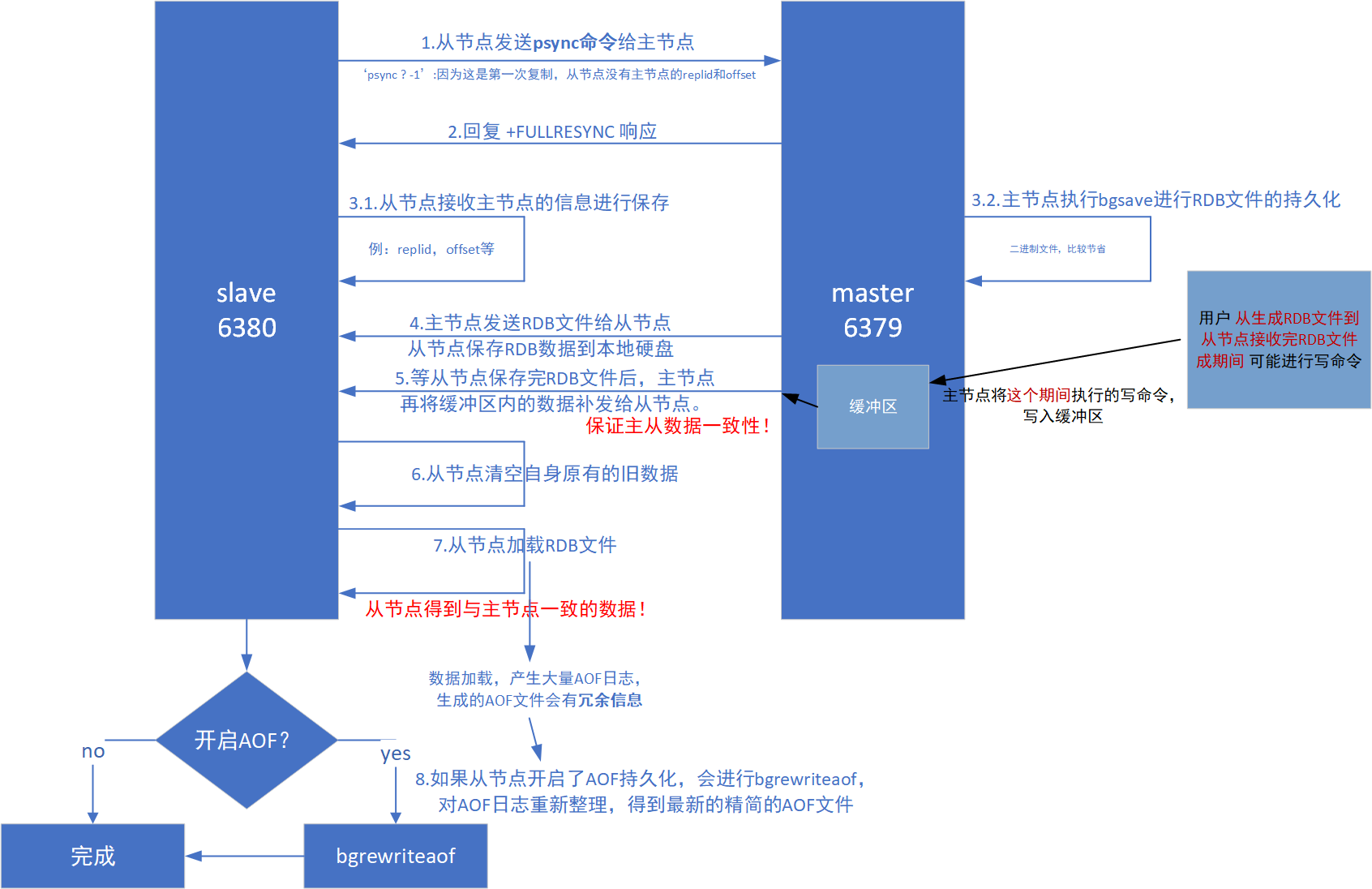
无硬盘复制
主节点,生成的rdb的二进制数据,不是直接保存到文件中,而是进行网络传输。(省下了一次读硬盘和写硬盘的操作)
从节点,之前也是先把收到的rdb数据,写入硬盘,然后加载,现在也可以省略这个过程,直接把收到的数据进行加载。
即使引入了无硬盘复制,这个全量复制的操作仍然是比较耗时的,原因是网络传输大量数据是没法省的。
关于replid与runid
一个redis服务器上,replid与runid是都存在的,两个不同的id看起来非常像。
主节点
bash
127.0.0.1:6379> info server
...
run_id:52d12c115537e49aaa709c34f07a89ee5687248e
...
bash
127.0.0.1:6379> info replication
...
master_replid:a893633de924b56a66226aab2aa053782827ad6e
...从节点
bash
127.0.0.1:6380> info server
...
run_id:1587269a8f33ae3698016d4b630557aa620199fd #与主节点不同
...
bash
127.0.0.1:6380> info replication
...
master_replid:a893633de924b56a66226aab2aa053782827ad6e #与主节点相同
...runid 每个节点都不相同 的,主要使用在支持redis哨兵实现,和主从复制没什么关系。
replid 是具有主从关系的节点,是相同的 ,主要使用在主从复制中。
部分复制
主从节点出现网络终端,从节点需要重连,去同步这个终端期间的数据时,考虑部分复制,保证了主从节点的一致性。补发的这部分数据⼀般远远小于全量数据,所以开销很⼩。
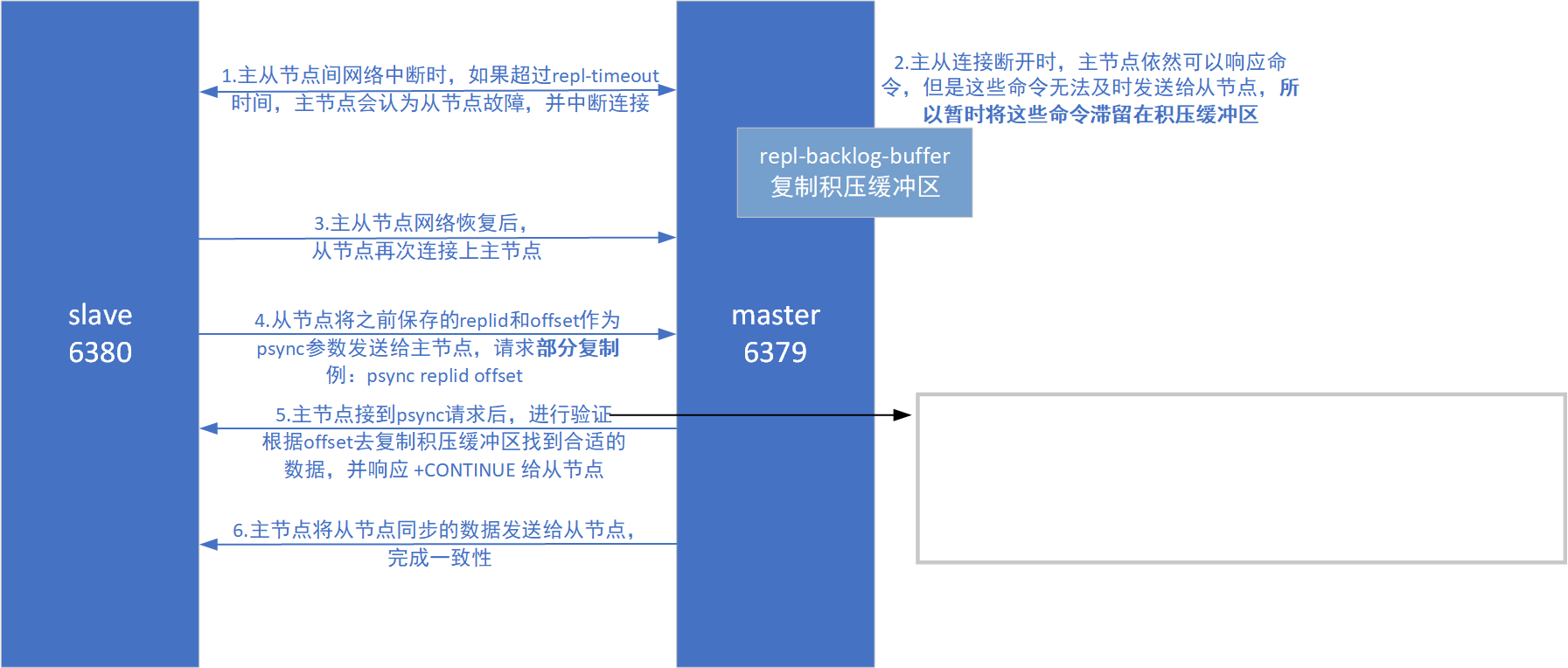
repl-backlog-buffer(复制积压缓冲区)
复制积压缓冲区是保存在主节点上的⼀个固定⻓度的环形队列 。
需要记录缓冲区起始偏移量和缓冲区已使用长度,就可以知道缓冲区的有效数据。
写满后覆盖最旧数据,"有效数据段" 会在环形空间内 "滑动"。
bash
127.0.0.1:6379> info replication
# Replication
role:master
...
repl_backlog_active:1 #积压缓冲区激活状态
repl_backlog_size:1048576 #积压缓冲区总大小
repl_backlog_first_byte_offset:7479 #缓冲区起始偏移量
repl_backlog_histlen:1048576 #缓冲区已使用长度如果当前从节点需要的数据, 已经超出了主节点的积压缓冲区的范围, 则无法进行部分复制, 只能全量复制了。
实时复制
主从节点在建立复制连接 后,主节点会把⾃⼰收到的修改操作 , 通过 tcp 长连接的方式, 源源不断的传输给从节点. 从节点就会根据这些请求来同时修改⾃⾝的数据. 从⽽保持和主节点数据的⼀致性.
在进行实时复制的时候,需要保证连接处于可用状态,需要通过心跳包的⽅式 来维护连接状态。
心跳包机制------主从节点彼此都有⼼跳检测机制,各⾃模拟成对方的客户端进⾏通信。
- 主节点:默认,每个10s给从节点发送一个ping命令,从节点收到返回一个pong。
- 从节点:默认,每隔1s就给主节点发送一个特定的请求,就会上报当前从节点复制数据的进度(offset)。
- 如果主节点发现从节点通信延迟超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线,断开复制客⼾端连接。从节点恢复连接后,心跳机制继续进⾏
附录:查看redis服务器相关信息
查看主服务器的信息:客户端连接主服务器情况下,输入info replication
bash
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=3752,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=3752,lag=1
master_failover_state:no-failover
master_replid:a893633de924b56a66226aab2aa053782827ad6e
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:3752
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:3752核心角色与从节点信息
| 参数 | 含义 |
|---|---|
| role:master | 当前 Redis 实例是主节点(master) |
| connected_slaves:2 | 当前主节点连接了 2 个从节点 |
| slave0:ip=127.0.0.1,port=6380,state=online,offset=3752,lag=0 | 第一个从节点信息:- IP / 端口:127.0.0.1:6380- 状态:online(在线)- offset:3752(从节点已同步的复制偏移量)- lag:0(主从数据同步延迟,0 表示无延迟) |
| slave1:ip=127.0.0.1,port=6381,state=online,offset=3752,lag=1 | 第二个从节点信息:- IP / 端口:127.0.0.1:6381- 状态:online(在线)- offset:3752(和主节点偏移量一致)- lag:1(同步延迟 1 秒,属于正常范围) |
主节点上会收到源源不断的修改数据的请求,从节点就需要从主节点这里同步这些请求,但是从节点和主节点之间的数据同步不是瞬间完成的。
offset就相当于是从节点和主节点之间,同步数据的进度。
主节点故障转移与复制 ID
| 参数 | 含义 |
|---|---|
| master_failover_state:no-failover | 当前无故障转移操作(主节点正常运行) |
| master_replid:a893633de924b56a66226aab2aa053782827ad6e | 主节点的复制 ID(唯一标识当前主节点的复制数据集) |
| master_replid2:0000000000000000000000000000000000000000 | 备用复制 ID(仅在主节点切换 / 故障转移后会生成,当前无) |
复制偏移量
| 参数 | 含义 |
|---|---|
| master_repl_offset:3752 | 主节点当前的复制偏移量(可以理解为 "数据进度条",数值越大表示同步的数据越多) |
| second_repl_offset:-1 | 备用偏移量(无备用复制 ID 时为 -1) |
复制积压缓冲区(repl_backlog)
复制积压缓冲区是主节点维护的一个环形缓冲区,用于断连后的从节点快速同步(避免全量复制):
| 参数 | 含义 |
|---|---|
| repl_backlog_active:1 | 复制积压缓冲区已启用(1 = 开启,0 = 关闭) |
| repl_backlog_size:1048576 | 缓冲区大小为 1MB(1024*1024) |
| repl_backlog_first_byte_offset:1 | 缓冲区中第一个字节的偏移量 |
| repl_backlog_histlen:3752 | 缓冲区中已存储的有效数据长度(当前 3752 字节,远小于缓冲区大小,无溢出风险) |