前言
世界模型一定是2026年的具身领域最热的研究方向之一,为何这么说呢
- 尽管模型容量和数据获取规模持续扩张,视觉--语言--动作(VLA)模型在接触丰富且高度动态的操作任务中仍然十分脆弱,在这些任务中,细微的执行偏差会累积并最终导致失败
- 另一方面,尽管强化学习(RL)为提升鲁棒性提供了一条有原则的途径,但在真实物理世界中,基于当前策略的强化学习受到安全风险、硬件成本以及环境重置等因素的限制
为弥合这一鸿沟,RISE应运而生,一个通过想象进行机器人强化学习的可扩展框架。其核心是一个组合式世界模型,该模型
- 通过可控的动力学模型预测多视角未来
- 使用进度价值模型评估想象出的结果,从而为策略改进产生信息量丰富的优势信号
第一部分 RISE: Self-Improving Robot Policy withCompositional World Model
1.1 引言与相关工作
1.1.1 引言
如原论文所说,在高层语义能力上,VLA 在复杂物理动力学条件下的稳健操作方面仍然有所欠缺,例如对运动物体的精确抓取或高效的双手协同操控 65,37
-
这一差距凸显了模仿学习(Imitation Learning, IL)的内在局限性------IL 是使 VLA 能够生成可执行动作的核心机制
具体而言,IL 天生受制于专家示范的质量和覆盖范围,同时还受到"暴露偏差"(exposure bias)问题的困扰:一旦机器人稍微偏离专家示范的流形,就缺乏将其轨迹纠正回来的恢复能力,从而导致误差不断累积 73,45,37,15 -
通过自身成败(成功与失败)来提升智能体能力的强化学习则提供了一种潜在的补救途径
在诸如 LIBERO 60 之类的虚拟模拟器中,智能体可以并行进行海量交互,其中状态与奖励的更新都是可控且可访问的。此类精心设计的模拟器所具备的这些特性,激发了将强化学习成功迁移到最新 VLAs 上的工作 63,56,61然而,这种可控性与并行性在真实世界环境中并不成立:如图 Fig.1(a) 所示,机器人的执行过程是串行的、耗时的,并且由于需要人工监控与复位而劳动密集。这些物理层面的挑战在很大程度上将以往真实世界强化学习方法限制在离线数据上,而这些数据与当前策略存在严重的分布偏移85,64,65,80
最终,如果缺乏足够的 on-policy 数据流,策略的改进可能会受到瓶颈限制 52,90,72 -
simulator与物理世界之间的差距推动了世界模型的发展
世界模型先从被动经验中学习,然后在给定不同动作的条件下模拟未来结果78,27,29,30,31,50然而,构建可用于真实世界机器人系统的世界模型面临根本性挑战。对于控制任务,世界模型必须对动作做出忠实响应,才能表达准确的后果。尽管通过集成高容量生成模型提升了视觉真实感 87,26,99,但如何在各种动作上提高可控性仍然是一个开放问题 55
否则,判断最终是否成功就需要世界模型模拟整个任务执行过程,而这超出了大多数生成式世界模型的可靠预测范围 55,57
为了解决这些问题,来自1 The Chinese University of Hong Kong 2 Kinetix AI 3 The University of Hong Kong 4 Shanghai Innovation Institute 5 Horizon Robotics 6 Tsinghua University的研究者提出了 RISE,这是一个整体性的学习框架,如图 1(b) 所示
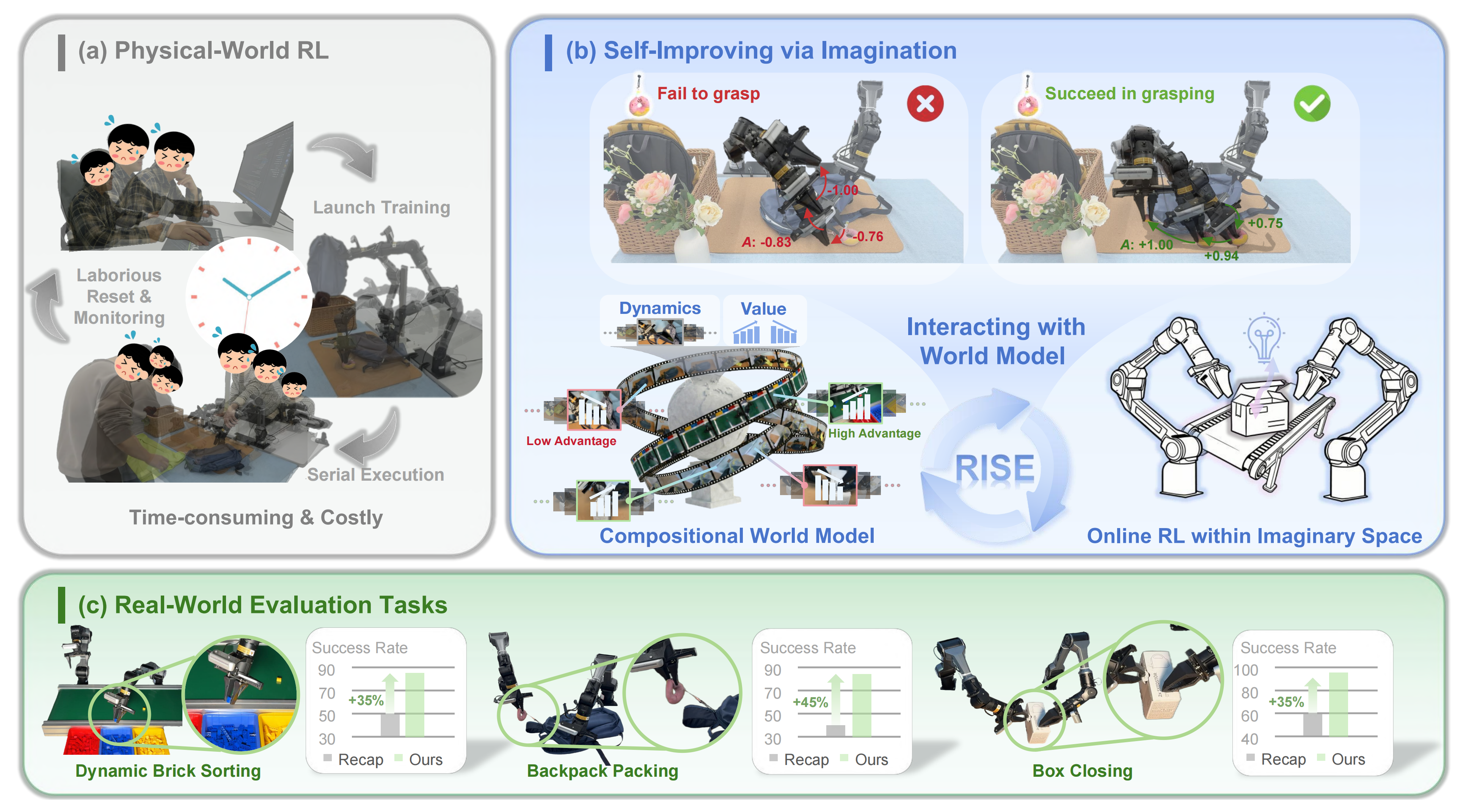
- 其paper地址为:RISE: Self-Improving Robot Policy with Compositional World Model
其作者包括
Jiazhi Yang1,2∗† Kunyang Lin2∗ Jinwei Li2,6∗ Wencong Zhang2∗ Tianwei Lin5 Longyan Wu4 Zhizhong Su5 Hao Zhao6 Ya-Qin Zhang6 Li Chen3 Ping Luo3 Xiangyu Yue1♮ Hongyang Li3♮ - 其项目地址为:opendrivelab.com/kai0-rl
具体而言,其核心思想是通过"想象"来强化机器人基础模型,从而实现自我提升。在该框架的核心,是由一个学习得到的世界模型所实现的在线学习环境
受先前工作启发,这些工作将世界建模分解为可处理的子问题,从而能够灵活利用异构的架构和先验知识 5,20,97,86,作者构建了一个组合式世界模型(Compositional World Model),将仿真问题分解为两个目标:动力学预测和价值估计,使得每一部分都可以采用最适合其角色的网络架构和训练目标来实例化
- 基于高效的视频扩散模型 59,28,作者在大规模机器人数据集上采用 Task-centric Batching 策略对动力学模型进行预训练,以提升动作控制能力,从而有助于在目标任务上的高效微调
- 价值模型从预训练的 VLA 骨干网络 8 初始化,并通过进度估计 66, 92,25 和时序差分(Temporal-Difference)学习 77 两种目标进行适配,从而对想象状态提供稠密且对失败敏感的评估
最终,作者将这些组件结合起来,为候选动作计算优势,使得通过优势条件化训练实现稳定的策略改进
由此,RISE 能在想象中高效地执行同策略强化学习。如图 Fig.2 所示,作者在一系列真实世界任务上对 RISE 进行了严格评估,这些任务对动态适应性和精确性提出了严苛要求

结果表明,RISE 以不小的幅度优于以往的 RL 方法,同时避免了代价高昂的真实世界试错过程
1.1.2 相关工作
// 待更
1.1.3 预备知识
首先,对于世界模型的形式化表述
如原论文所述,作者旨在构建一个世界模型,它由
- 一个用于预测未来状态的动力学模型
- 一个用于预测不同行动方案下回报的价值模型组成。关键在于,这些预测的回报被转换为优势,以指导RL 训练
形式上,令为时刻
的多视角观测,其中包含
个摄像机视角
- 作者采用长度为N 的历史窗口
来捕获时间依赖性 - 条件动作
其中
动力学模型 在给定历史上下文和所提出的动作序列的条件下,预测未来观测
为了评估想象轨迹的效用,作者进一步引入一个价值模型,其根据观测和任务指令,通过
为"成功完成"分配一个进度信号,总之,作者将优势定义为整个片段上的平均累积改进
具体来说,作者将每个预测的未来观测值与初始观测值
之间的差值作为动作
的奖励,然后在该动作片段的时间范围上取期望,作为优势------视为公式2:
其中 A 与策略 π 提出的动作块相关联,从而构成用于策略优化的学习信号。D 与 V 之间的交互发生在想象空间中,且这两个模块都兼容多视图图像
其次,对于强化学习
作者将该问题表述为一个标准的RL 设定,其决策过程是由元组表征的马尔可夫决策过程MDP
-
在每个时间步
-
策略与环境之间的交互诱导出轨迹分布
目标是最大化期望回报
为了度量特定动作序列相对于平均策略表现的优劣,作者使用优势函数,通过式(2) 进行估计
为了确保相对于参考策略 的稳定提升,作者采用来自π∗0.6 2 的概率推断框架。且不是直接最大化正则化目标,而是通过用改进概率
对
加权来构造 ++目标分布
++ ------即公式3:
由于改进完全由优势值决定,故有。应用贝叶斯法则使得能够将改进的似然表示为一个密度比------定义为公式4:
将式(4) 代入目标分布并令β = 1,即可抵消无条件先验 ,从而得到简化的目标
在实践中,作者通过将策略条件化在离散化的优势上来实现这一点,从而引导生成朝向高回报轨迹
为了方便大家更好的理解,我还是给大家step by step的解释一下:公式4以及最后简化的目标,即其到底是如何一步一步推导出来的
第一步,首先明确公式4的目的/含义( 明白了公式4,最后的简化目标便可迎刃而解**)**
公式 (4) 的目的是将改进似然度
其中
第二步,设定基本假设:改进由优势函数决定
论文指出,由于改进事件
第三步,应用贝叶斯定理
根据贝叶斯定理的基本形式
第四步,映射到策略符号
为了使公式与强化学习框架一致,论文将概率分布映射到具体的策略表示上 :
即对于上面第三步最后那个等式右边的项,从下至上、从左至右
将上述符号代入,并由于该项主要作为目标分布
把上面第4步最后得到的公式4,代入到此公式3
由于该式子的右侧中,分子分母皆存在一个
故两者相除便可直接抵消,从而使得剩下的项为
由于
因此,可以直接得到简化的目标分布
上面一系列推导的意义在于
- 原本需要根据"优势函数"去加权旧策略-公式3
这在计算上可能很复杂
通过上述推导,目标分布变成了"在改进发生的条件下采取动作的概率"- 从而使得在实际训练中,这意味着只需要让模型学习那些被打上"高优势(High Advantage)"标签的动作即可
简单来说,抵消先验
1.2 RISE的完整方法论
如原论文所述,本节会有三个部分的内容
- 作者提出了一种组合式世界模型,将动力学预测与价值估计相结合,从而提供一个具有信息量丰富学习信号的交互式环境
- 在真实环境经验上建立一个策略预热阶段,使策略锚定于实际行为分布,并赋予其基于优势量条件的能力
- 提出一个自改进循环,在世界模型内迭代生成想象轨迹并优化策略
至于算力分配在内的实现细节在最后给出
1.2.1 组合式世界模型:先实现可控动力学模型、后实现进度值模型
可扩展的强化学习(RL)需要精确的环境建模,以将当前状态和策略动作映射到未来的动态和回报
- 为此,作者提出一种组合式世界模型,将动力学预测与价值估计解耦,从而使得可以对每个组件的架构进行独立优化
即从一个上下文观测开始,在候选动作片段条件下,动力学模型会模拟出可信的未来轨迹,这些轨迹会由价值模型进行评估,以便为策略改进推导出优势 - 作者在图3中给出了想象结果的若干定性样本
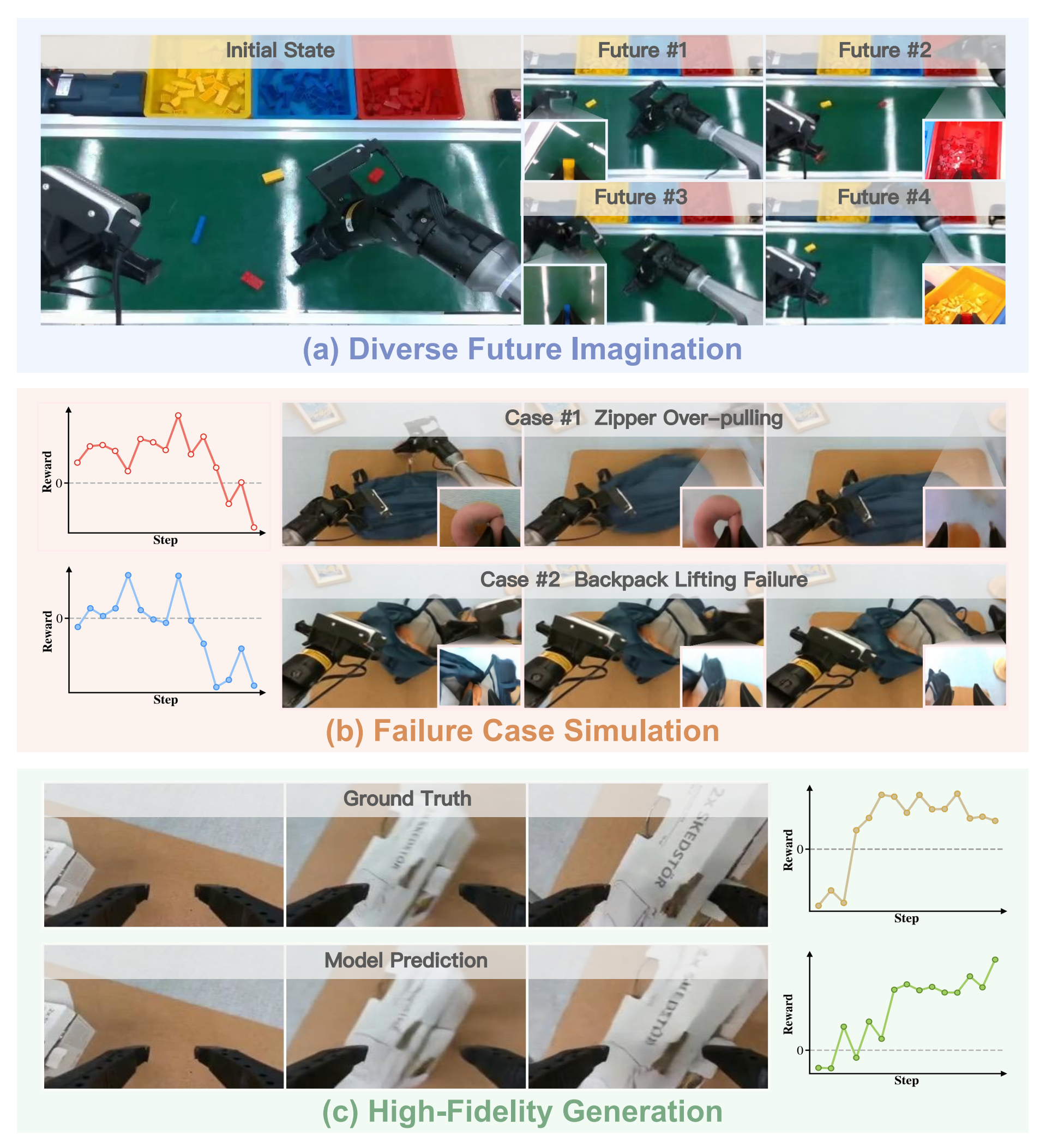
关键的是,该模型仅在训练阶段使用,在推理阶段不会带来任何计算开销
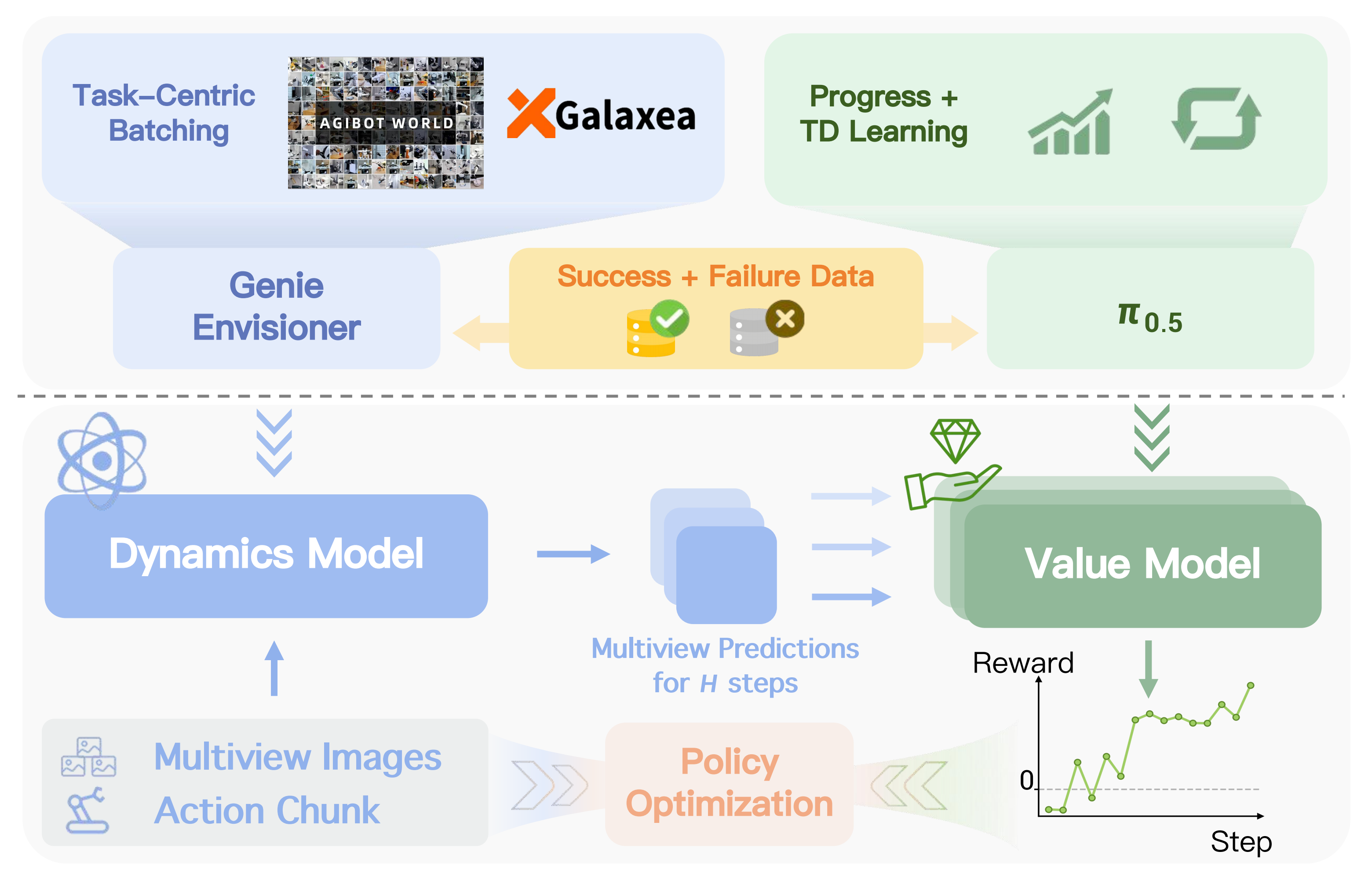
至于世界模型的训练配方和推理流程如图4所示
首先,如果想实现可控动力学模型,即要在强化学习中可靠地模拟未来状态,需要满足两个基本要求:
- 生成延迟不能高得难以接受,否则会成为强化学习系统吞吐量的瓶颈
- 生成的状态不仅在视觉上要合理可信,还必须与条件动作保持一致
因此,作者将动力学模型初始化为预训练的 Genie Envisioner 59(即 GE-base 变体),该模型继承了 LTX-Video 28 的架构优势,并在生成质量与推理速度之间实现了良好的折中
相比之下,诸如Cosmos 1 等先进世界模型在合成 25 帧多视角观测时需要超过 10 分钟,而 GE 只需不到 2 秒即可达到同样的预测时域,带来约 300 倍的加速。这样的生成效率是支撑实用强化学习训练的关键支柱
不过
-
尽管具有较高的效率,GE-Base 最初是以文本为条件进行建模,而不是以细粒度的机器人动作为条件。为了赋予该模型精确的动作可控性,使其能够进一步应用于特定任务场景,作者还在大规模动作标注数据集『包括 AgibotWorld 11 和 Galaxea 43』上对模型进行了进一步优化------通过加入一个额外的轻量级动作编码器来实现
此外,与原始 GE-base训练相比,作者在上下文帧上施加更强的噪声,以提升在遇到运动模糊和视觉伪影(这些现象可能同时出现在真实录制和合成数据中)时的生成鲁棒性
-
然而,当在每次优化迭代中将多种任务和视觉域混合在同一 batch 中时,在异构动作数据上微调可控世界模型容易出现不稳定和收敛缓慢的问题
作者又通过一种任务中心的批处理策略(Task-Centric Batching)来缓解这一问题,其中,每个 batch 只从少量任务中采样,但在同一任务下覆盖更多与不同动作相关的样本
直观来看,该批处理策略在 batch 优化中更侧重同一场景下的动作多样性,而不是场景多样性,从而有助于提升动作可控性在实验上,采用该策略既提高了特定任务微调的效率(见表 V),也带来了更显著的策略提升(见表 IV)
在上述设计的加持下,作者的动力学模型能够提供快速且忠实的多视角状态预测,从而支撑自我改进闭环
其次,实现进度值模型
基于想象的策略改进在关键上依赖于一种与奖励相关的信号,该信号在*(i) 长时间范围内是稠密的,并且(ii) 对接触密集操控中的细微失败敏感*
因此,作者学习一个价值估计器V,它将感知到的观测映射为一个用于对想象轨迹进行评分的标量值。V 是从一个预训练的VLA 策略π0.5 8 参数化得到的,这带来了两个优势
- 首先,π0.5 已在广泛的机器人数据集上进行过训练,因此具备可自然迁移到价值估计上的机器人中心理解
- 其次,该策略的骨干网络兼容多视角输入,而通用的VLM 多数是在单视角图像上开发的,并未进行此类适配
在训练方面
-
作者使用一个简单的时间进度估计作为目标,来对V 进行 warm-start,这使得作者的价值模型具备对单调时间结构的粗略理解
其中 -
为了解决这一问题,作者将进度损失与时间差分(Temporal-Difference, TD)学习77 结合起来,后者同时利用成功示范和失败轨迹来建立一个能够区分成功与错误的价值函数
其中
作者的最终价值学习目标简单地将两个项结合起来,以分别利用这两项所提供的学习稳定性和误差敏感性
1.2.2 基于真实世界经验的策略预热
在进行 on-policy 改进之前,作者首先利用离线收集的数据对学习过程进行热启动,这会将策略锚定在目标任务上物理上合理的行为分布上,从而避免在后续阶段出现不加选择的探索
-
数据构成和训练目标主要遵循 RECAP 2
对于每个任务,作者在离线收集的数据上对预训练策略(即 π0.58)进行微调,这些数据由专家示范、包含成功与失败的策略 rollout,以及有人为干预的纠正组成 -
在训练过程中,策略以优势信号为条件,该优势信号由我们学习得到的价值模型 V------*见下述式 (2)*进行标注
其中将不同于RECAP 中同时为离线数据和策略 rollout 标注优势,作者宣称,在他们的早期实验中作者发现,同时为这两种数据源分配优势的效果反而比仅对 rollout 数据标注优势更差
因此,在作者的实验中,只对 rollout 数据分配学习得到的优势,而专家数据和人工纠正数据则直接与最优优势(记为 1)配对
由此,该预热阶段使策略能够吸收不同质量的动作数据,这对于随后基于在线试错进行学习的自我改进阶段至关重要
1.2.3 利用世界模型进行自我改进
在经过离线数据预热阶段获得优势条件化能力之后,作者将组合式世界模型作为一个交互式模拟器来改进策略
该自我改进循环如图 5 所示,迭代地执行 rollout 阶段和训练阶段『*RISE 的自我改进循环。学习流程包含两个阶段。上:Rollout 阶段。在给定最优优势作为提示的情况下,rollout 策略与世界模型交互以生成 rollout 数据。*下:训练阶段。随后在优势条件化方案下训练行为策略,以生成合适的动作』
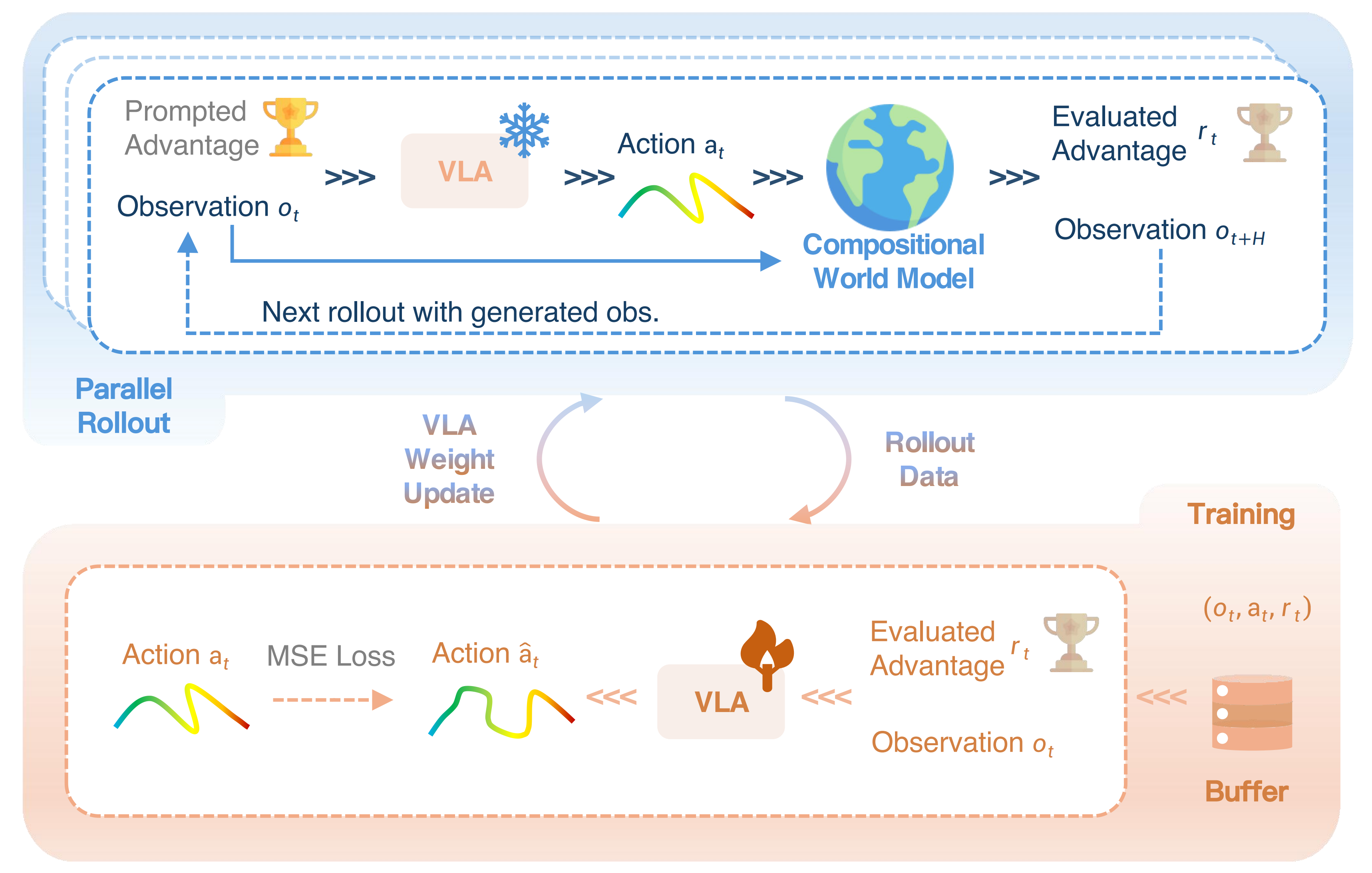
- Rollout 阶段
首先,作者从预热离线数据集中采样一个初始状态
除了进行观察外,作者还通过最优优势值 来提示策略
来提示策略
// 待更