如果你让当今最先进的AI视频模型生成一段"冰块落入温水"的视频,你很可能会得到一个画质惊艳、光线完美、动态流畅的短片。它几乎能以假乱真。
但如果你是一位物理系学生,可能会立刻发现破绽:冰块的融化速度均匀得诡异,热水降温的过程没有遵循热传导应有的梯度,汽化与液滴的形态违背了相变的基本原理。
这看似微小的"失真",揭示了一个关乎AI未来的根本性问题:现有的 "世界模型" ,并不是理解并模拟这个世界的运行法则,而是在记忆并模仿我们曾记录过的画面

一、物理常识测试

论文《TOWARDS WORLD SIMULATOR: Crafting Physical Commonsense-Based Benchmark for Video Generation》 ,构建了 PhyGenBench 基准:
- 测试范围:涵盖力学、光学、热学、材料属性4大领域,共27条基础物理定律(如重力、浮力、反射、热传导等)。
- 测试内容:设计了160个提示词,每个都对应一个简单、清晰、可观察的物理现象。例如:"一块铁被轻轻放在水箱的水面上"(测试对密度与浮力的理解)。
在PhyGenEval自动化评估框架下,即使当时表现最佳的模型Gen-3,得分也仅为0.51(满分1分)。
结论一 :AI视频模型,在生成符合基础物理常识的画面时,表现依然不足。 它们更像是在复刻"看起来合理"的视觉模式,而非内化了"铁比水重所以会下沉"的因果规律。真正的"世界模拟器",需要掌握的是成体系的科学知识。
二、科学推理测试
《Benchmarking Scientific Understanding and Reasoning for Video Generation using VideoScience-Bench》推出了 VideoScience-Bench 基准:
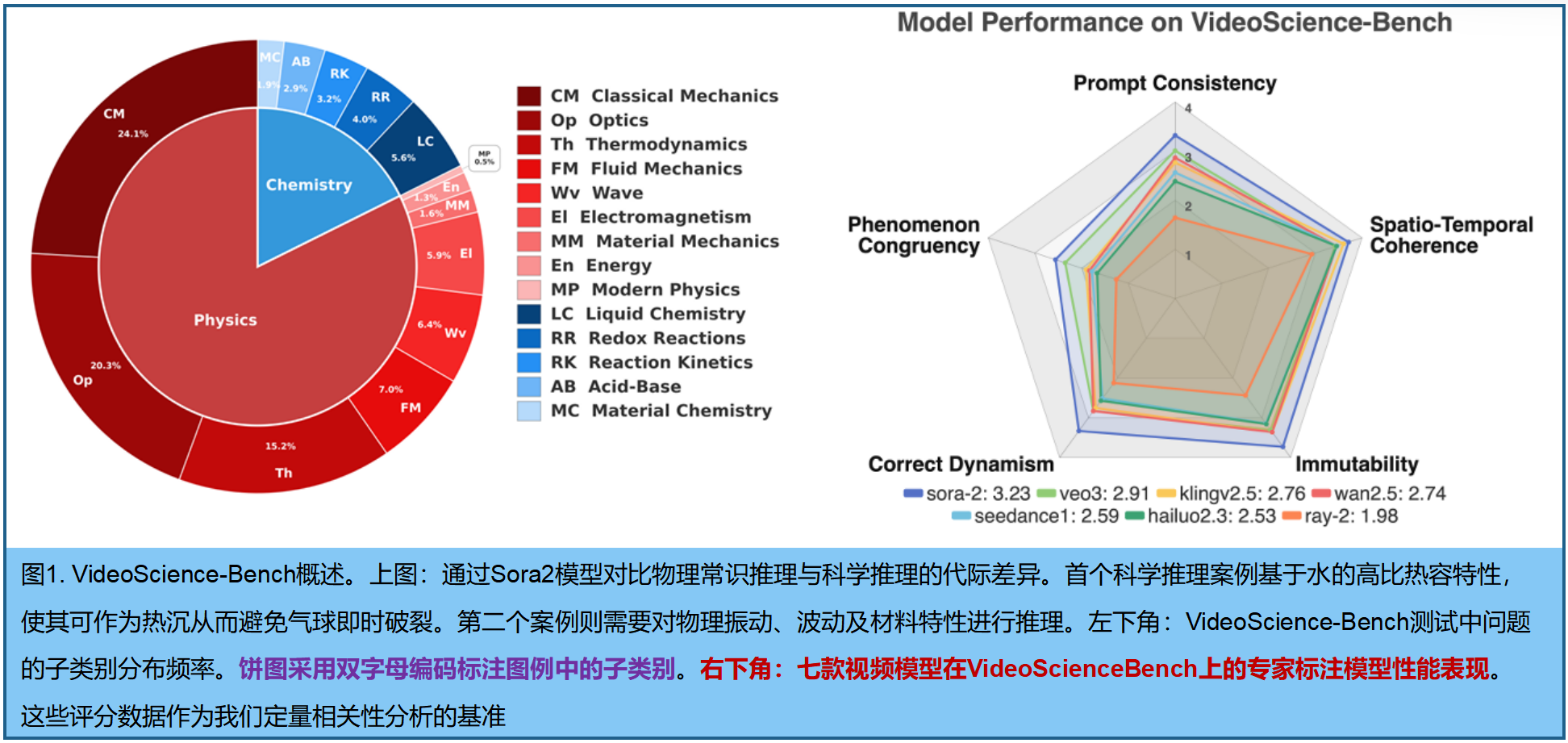
- 测试范围:涵盖物理学与化学的14个主题、103个核心概念。从经典力学、光学,到氧化还原反应、反应动力学,要求本科级别的知识储备。
- 测试内容:每个prompt,必须同时涉及至少两个科学概念的交叉与推理。例如:"演示一个装有不同浓度盐水的烧杯,在相同低温下,因凝固点降低效应而产生的差异化结冰过程与冰晶形态。" 要答对此题,模型需整合 溶液性质、热传导、晶体生长 多个知识点。
- 测试指标:专家从五个严格维度评分:提示一致性、现象符合性、正确动力学、不变性、时空连贯性。
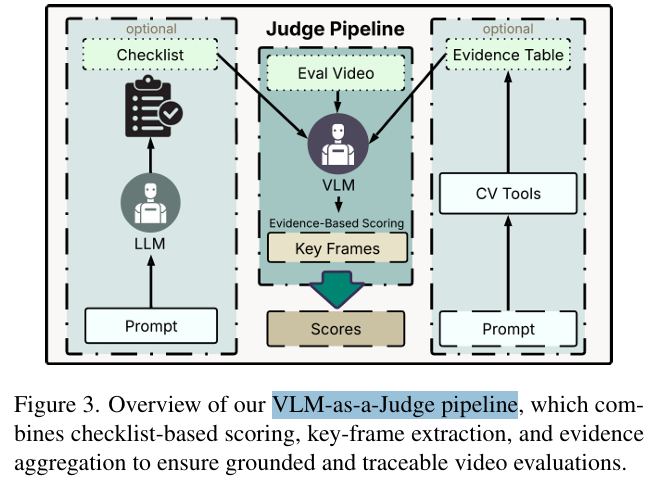
- 拓展测试:研究还配套开发了 VideoScience-Judge 评估框架,它利用"任务清单+关键帧证据+计算机视觉工具",让另一个AI(VLM)扮演严谨的助教,其评分与人类专家高度相关。
对Sora-2, Veo-3, Kling, Wan等7个顶级模型的测试显示:
- 优点:所有模型在视觉质量(时空连贯性、不变性)上表现优异,这也是当前技术最卷的方向。
- 缺点:在科学现象的正确性(Phenomenon Congruency)和基本物理定律的遵守(Correct Dynamism)上,所有模型都大幅失分。即便是表现最好的Sora-2和Veo-3,在"现象符合性"上的得分(按4分制)也仅分别为2.56和2.35,相当于刚过及格线。
- 代表案例:在"铝碘反应"测试中,Sora-2能正确生成点燃的紫色闪光,而Hailuo-2.3则完全未能引发反应。在"旋转杯中的小球"测试中(考察离心力),Sora-2和Veo-3这两个"优等生"竟都未能正确设置实验或模拟出现象。
结论二 :当前视频生成模型,在需要复杂、交叉科学推理的任务上,能力仍然非常有限。 它们可以成为顶级的"视觉特效师",但距离成为理解科学原理的"实验模拟器"还有很长的路要走。
三、"世界模型"演进路线
- 第一级:视觉真实。目标是生成高分辨率、连贯、美观的视频。现已基本攻克。
- 第二级:物理常识。目标是让视频中的物体运动符合日常直觉(球下落、水流动)。PhyGenBench显示,此关仍未通过。
- 第三级:科学推理。目标是让视频能正确演绎复杂的、多概念交织的科学过程。VideoScience-Bench表明,此关挑战巨大。
未来的突破,或许在于神经符号结合 (将深度学习与物理公式引擎融合)、仿真器引导训练 (用高精度物理仿真生成"正确"数据),或更根本的因果表征学习。
1. 论文1:《Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y., Li, D., Qiao, Y., & Luo, P. (2024). TOWARDS WORLD SIMULATOR: Crafting Physical Commonsense-Based Benchmark for Video Generation》.
2. 论文2:《Hu, L., Shankarampeta, A., Huang, Y., Dai, Z., Yu, H., Zhao, Y., Kang, H., Zhao, D., Rosing, T., & Zhang, H. (2025). Benchmarking Scientific Understanding and Reasoning for Video Generation using VideoScience-Bench》.