标题:《Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering》
项目:https://ayushtewari.com/projects/srender/
来源:英国剑桥大学
文章目录
- 摘要
- 一、相关工作
- 二、关键帧扩散与三维渲染
-
- 1.自适应的关键帧选择
- 2.关键帧生成器(Diffusion)
- [3. 3D重建和渲染](#3. 3D重建和渲染)
- [4.时间窗口(Temporal chunk)](#4.时间窗口(Temporal chunk))
- 三、实验
摘要
基于扩散模型的现代视频生成模型虽能生成高度逼真的片段,但计算效率低下------往往需要耗费数分钟的GPU运算时间来生成短短几秒的视频。这种低效性成为将生成式视频应用于需要实时交互场景(如具身AI和VR/AR)的关键障碍。
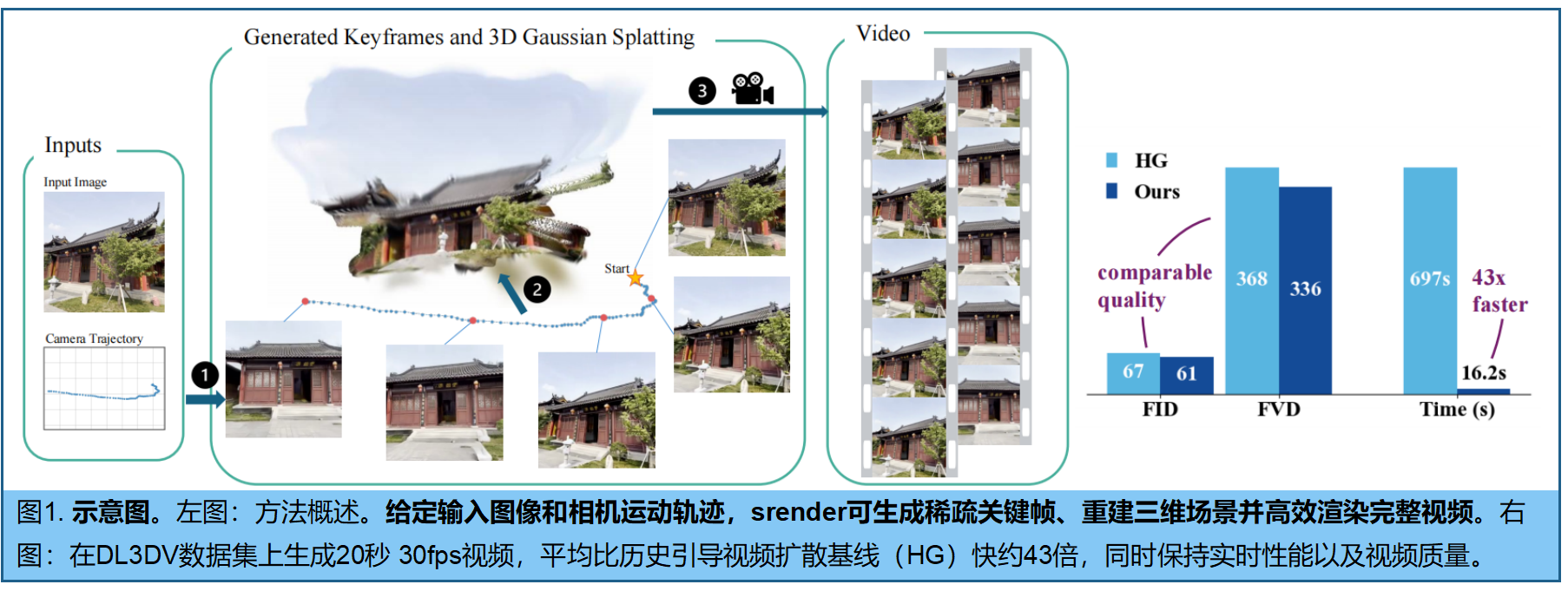
本文提出了一种针对静态场景的相机条件视频生成新策略:先利用基于扩散的生成模型生成稀疏关键帧集,再通过三维重建与渲染合成完整视频。通过将关键帧转化为三维表示并渲染中间视图,确保几何一致性的同时,将生成成本分摊至数百帧。我们进一步引入预测模型,可为特定摄像机轨迹预测最优关键帧数量,使系统能自适应分配计算资源。最终提出的srender方法采用极简关键帧处理简单轨迹,采用密集关键帧处理复杂运动轨迹。该方法在生成20秒视频时,生成速度较基于扩散的基准模型提升40倍以上,同时保持高视觉保真度与时间稳定性,为高效可控的视频合成提供了切实可行的解决方案。
一、相关工作
1.像机控制的视频模型
近年来,视频生成模型在扩散模型17的推动下取得了快速发展。多数模型专注于文本转视频或图像转视频任务 SVD、Veo3(google deepmind)、Sora(open ai)、Cosmos(NVIDIA)、Wan(Ali)。继图像领域潜在扩散模型取得成功后,早期视频模型在三维变分自编码器(VAE)的潜在空间中训练了三维UNet2。后续模型为提升可扩展性,用Transformer替换了UNet10,48。大多数视频扩散模型遵循标准扩散流程,即从同一噪声水平对视频所有帧进行联合去噪 。近期具有影响力的扩散强制方法**diffusion forcing** 打破了这一趋势,提出为每帧添加独立噪声水平,并将不同噪声水平的帧共同扩散。该策略在推理时支持多种去噪策略,包括通过可变长度条件帧实现长距离视频生成的自回归解码,以及关键帧间的视频插值。这项工作随后激发了 大量关于自回归视频模型的研究 1,6--9,20,32,60。摄像机控制视频生成作为视频生成的子领域已被证明效果显著。现有方法要么 直接编码所需摄像机pose,以约束生成模型14,62,要么显式利用世界三维结构,例如通过从输入图像计算点云并从目标摄像机视角渲染来约束生成模型19,41。本研究聚焦于相机控制视频生成问题,采用扩散强制架构。该设计选择可生成具有强场景一致性和对先前帧灵活条件化的稀疏关键帧。
总体而言,视频扩散模型的推理过程成本极高。即便是生成短时(<3秒)片段,在高端硬件上也可能耗费数分钟1,18,48,55。学界已尝试通过教师-学生蒸馏7,57或缓存技术20,25等方法提升模型速度 。但现有方案均依赖神经网络逐帧生成视频,未能有效利用视频信号中的信息冗余。
2.三维重建
三维表征技术的突破性进展,尤其是3DGS使得从图像集合中重建高质量场景成为可能。近年来,
- 1.许多模型通过训练神经网络,直接从带pose输入图像回归3DGS表征pixelsplat、Dreamgaussian。这些方法无需优化即可恢复精细且一致的三维几何结构。
- 2.最新的工作Vggt、Anysplat Feed-forward 3d gaussian splatting from unconstrained views 通过借鉴DUST3R52的架构设计,进一步拓展了这一能力,即使从无pose图像集也能实现高效的三维重建。
该领域的研究进展主要集中在确定性重建领域 。这类模型仅能重建输入图像中直接可见的场景部分,无法呈现与观测数据相符的完整三维场景分布。因此,尽管它们能生成高质量几何结构,但无法作为生成模型使用。部分研究已探索生成式三维重建技术 。早期方法11,33通过图像扩散模型优化三维表征,但这类基于优化的流程速度较慢,且通常仅适用于单个物体场景。近期方法将扩散与三维表征相结合44,46,实现了部分前馈式三维生成。然而这些方法尚未达到当前最先进的视频扩散模型在视觉质量、稳定性及多视角一致性方面的表现。与此密切相关的还有先用图像扩散模型从单一输入图像生成多视角图像,再拟合三维表征的方法34,36。虽然这些方法能生成连贯的三维资源,但仍局限于以物体为中心的场景,无法扩展到完整场景或长镜头拍摄 。近期也有研究将 视频扩散模型的生成能力与显式三维场景表征相结合Voyager、Marble、Wonderworld,在生成式三维场景重建方面取得了显著成果 。
本方法通过采用确定性前馈三维重建模型替代视频模型中的密集视频帧生成,该模型可从生成的稀疏关键帧重建三维全局表征(3DGS)。由于中间帧的确定性前馈三维重建与渲染速度远超扩散式帧合成,因此视频生成速度可显著提升。
二、关键帧扩散与三维渲染
图2展示了srender的功能。输入 :图像和指定的摄像机运动轨迹,生成:从输入图像开始并对应该轨迹的视频序列。
与通过扩散法逐帧生成不同,srender采用稀疏关键帧合成技术,并通过三维重建高效渲染剩余帧。
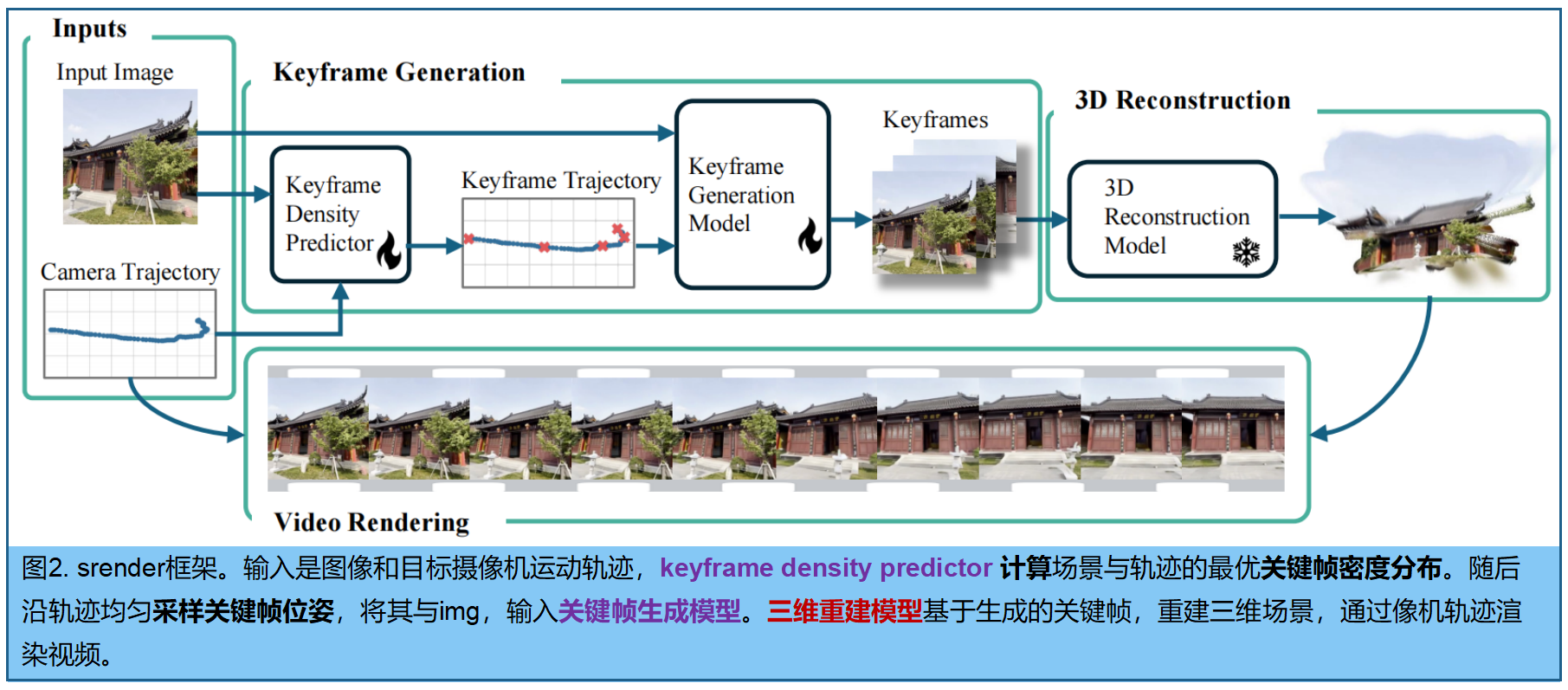
流程 :
- 1.首先关键帧密度预测,通过分析摄像机运动轨迹来确定关键帧的最佳稀疏度。该模型能根据运动复杂度自适应分配计算资源。
- 2.基于扩散的生成器,根据输入图像和对应摄像机姿态,合成选定的关键帧。由此生成的多视角画面集,完整呈现了沿预设摄像机轨迹不同角度的静态场景
- 3.利用确定性(非生成式)神经网络从这些关键帧重建三维高斯表示。完成重建后,即可以高帧率渲染出结构紧凑、几何协调的视频画面。
1.自适应的关键帧选择
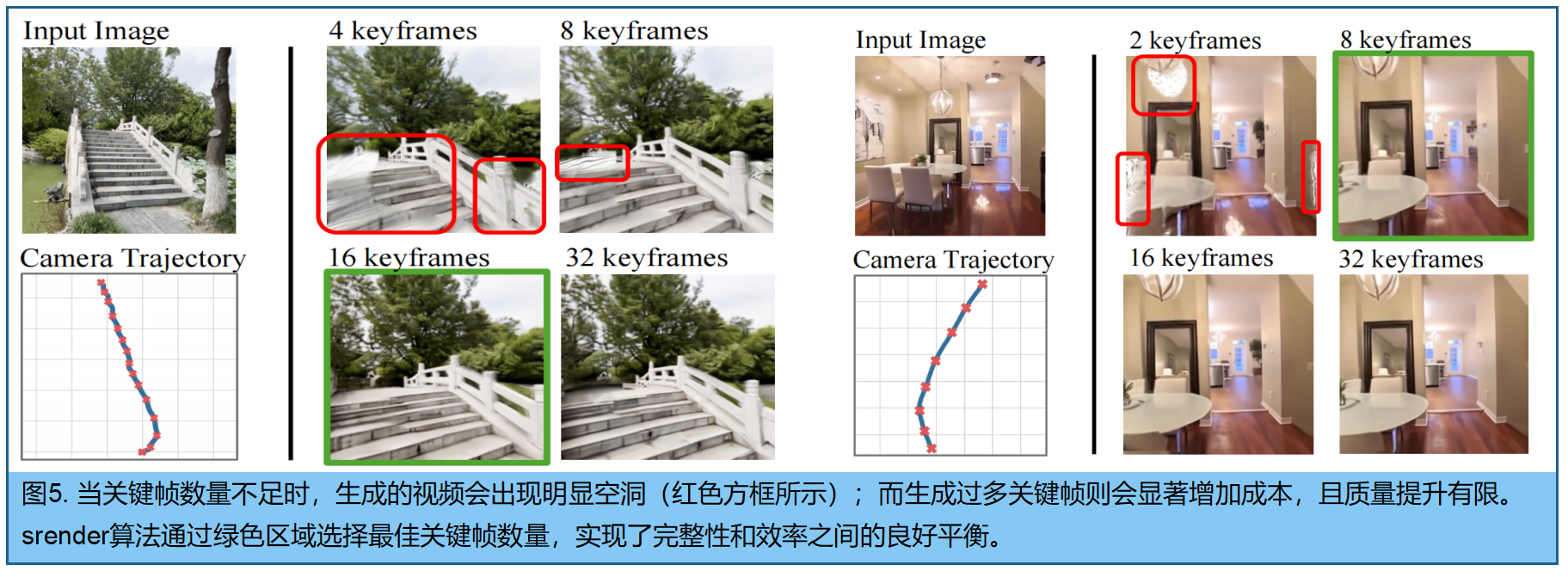
关键帧数量:密集采样会增加计算成本,而采样过稀则会导致三维重建不完整,渲染视图中会出现可见的空洞。
最佳关键帧集的选择需综合考虑相机运动轨迹与场景几何结构。平滑的运动轨迹或有限的视差可能仅需少量关键帧,而视角剧烈变化或复杂几何结构则需要更密集的采样 。我们将这一问题转化为 学习任务:通过相机运动轨迹和场景外观特征预测最优关键帧数量。
模型(可学习的) 。训练了一个基于Transformer的关键帧密度预测器:以完整的相机位姿序列作为输入,每个pose表示为独立token 。场景外观通过DINOv2]图像编码器提取全局特征token ,作为附加token。经过多个自注意力块处理,最终特征被平均并通过轻量级 MLP 预测最优关键帧数量。监督信号 :从RealEstate10k12和DL3DV30数据集获取。
伪算法见算法1 (确保选定的关键帧能完整覆盖视频所有像素):每个视频,使用 VGGT 重建点云。从首帧开始,将选定关键帧的点云集合迭代投影到后续帧。当投影覆盖度低于阈值时,将当前帧标记为新关键帧。为平滑或低视差轨迹生成稀疏关键帧,为复杂运动生成密集关键帧。在获得关键帧数量后,沿相机轨迹均匀采样关键帧的相机位姿

2.关键帧生成器(Diffusion)
得到关键帧pose后,通过基于Diffusion的生成器,合成对应的关键帧。其目标是生成少量高质量、几何一致性良好的视图,以从指定视角捕捉静态场景。
关键帧生成器,基于相机条件视频扩散技术的最新进展,特别是 diffusion forcing 和 history-guided video diffusion,可提升帧间的时间和几何一致性。
a.预备知识
在标准去噪扩散模型中,数据样本 x 0 x_0 x0,通过前向加噪过程 q ( x t ∣ x t − 1 ) q(x_t | x_{t−1}) q(xt∣xt−1)来扰动,神经网络通过预测每一步的噪声来学习逆转该过程。生成过程始于对 x T ∼ N ( 0 , I ) x_T ∼ N(0,I) xT∼N(0,I)进行采样并应用:
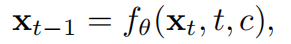
扩散强迫与历史引导 。在视频扩散中, x 0 x_0 x0是由多个图像帧组成的视频。输出视频的每一帧都需要去噪。diffusion forcing 为每帧分配独立的噪声水平,使得模型能够同时对不同噪声水平的帧进行降噪,从而可以在任意帧位将干净的历史帧与部分噪声的待生成帧混合。在此基础上,history-guided video diffusion 通过对子集帧(例如已降噪的帧)应用classifier-free guidance,以促进长距离一致性。
b.我们的模型
我们将选定的关键帧视为低帧率视频,并训练一个历史引导扩散模型来捕捉它们的联合分布。条件信息由第一帧输入和相机轨迹提供。第一帧作为所有生成关键帧的稳定外观锚点。
然而,直接在极低帧率下训练扩散模型存在稳定性问题:大视角跳跃会导致几何漂移和光度漂移。为解决这一问题,我们采用渐进式训练策略。首先在高帧率视频上进行密集监督训练,随后通过子采样逐步降低有效帧率,直至匹配推理阶段使用的稀疏关键帧间距。该过程使模型能够在处理大视角变化前先学习短距离对应关系,从而即使在高稀疏度条件下也能生成稳定且连贯的多视角图像。
历史引导扩散模型,上下文窗口为8帧。为生成超过8个连贯的关键帧,我们采用两阶段推理方案:
- 首先仅以 input image 为条件,生成均匀覆盖整个轨迹的8个关键帧;
- 随后使用相同模型,以最近的已有关键帧作为条件,生成剩余关键帧。
这种设计既能确保任意长度关键帧序列的连贯性,又能让扩散成本保持可控。
3. 3D重建和渲染
基于生成的关键帧,我们重建静态场景的三维表征,并沿轨迹渲染密集视频。采用预训练的AnySplat模型22,该模型可直接从小规模无pose图像集中预测 3DGS。
AnySplat 3D重建 :AnySplat通过单次前向传播,即可从多张未标注图像中预测高斯参数。该技术不采用迭代逆向渲染,而是将多视角特征映射至三维高斯场,从而实现快速可靠的稀疏视角重建。其采用 VGGT 49估计相机pose。AnySplat具有确定性特征,仅重建可见场景内容,可在数秒内处理数十张图像。
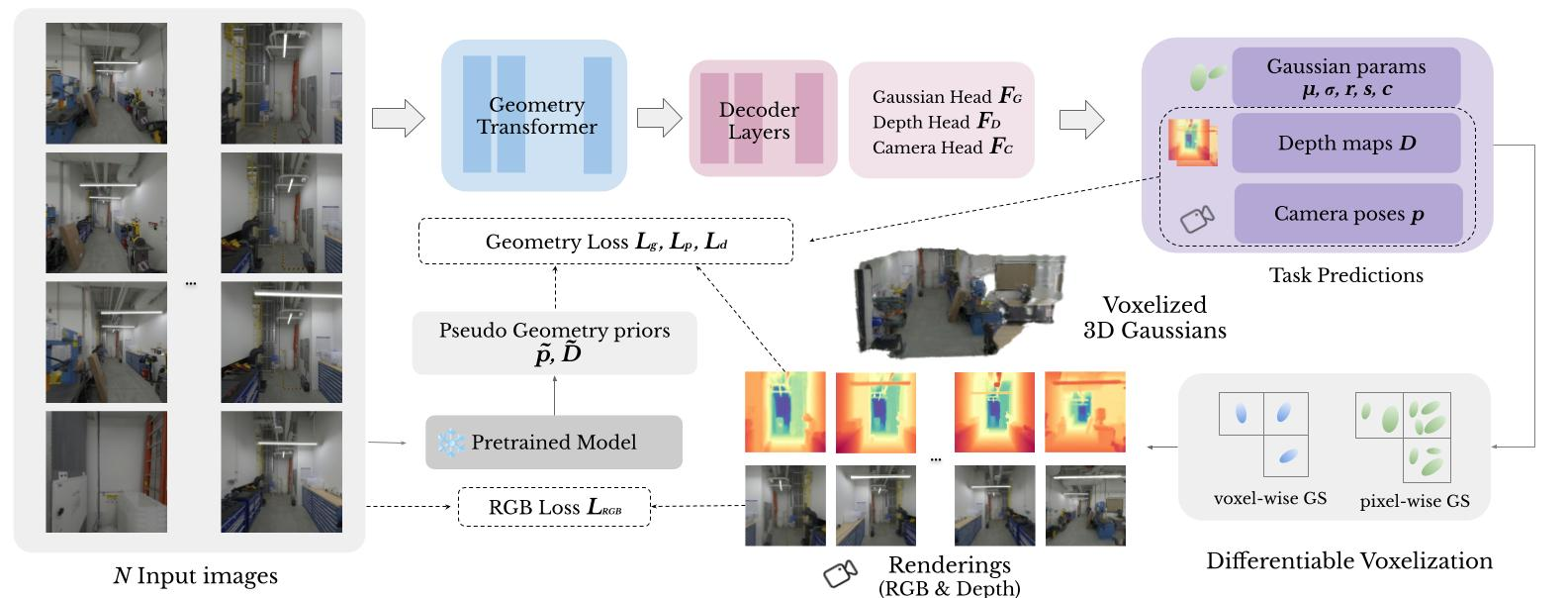
AnySplat 的可微分体素化 。 现有的前馈 3DGS 方法通常为每个像素分配一个高斯函数,这对于稀疏视图输入(2-16 张图像)有效,但一旦使用超过 32 个视图,就会面临规模化带来的复杂度问题。引入可微分的体素化模块,将高斯中心 { μ g μ_g μg} 聚类成大小为 𝜖 的 S S S 个体素。为了保持体素化的可微性,每个高斯中心还预测一个置信度 C g C_g Cg。通过 softmax 函数将这些分数转换为体素内权重。最后,任何像素级高斯属性 a g a_g ag(例如,不透明度或颜色)都被聚合到其对应的体素中。
我们将生成的关键帧输入AnySplat系统,以获取场景的3DGS。由于AnySplat预测的pose与输入的相机轨迹处于不同坐标系,通过估计最小二乘仿射变换来实现两者对齐 。最后,在每个相机pose渲染3DGS,生成高密度输出视频。该阶段运行速度极快,是srender相较于基于扩散的基准方法效率提升的主要原因。
4.时间窗口(Temporal chunk)
本方法的核心在于,生成的关键帧,需在完整像机运动轨迹中,保持几何与光度学一致性。对于RealEstate10k这类简单数据集,或在复杂场景中较短时长的拍摄,该假设通常成立:扩散模型生成的关键帧稳定性足以支持单次高质量全局重建。
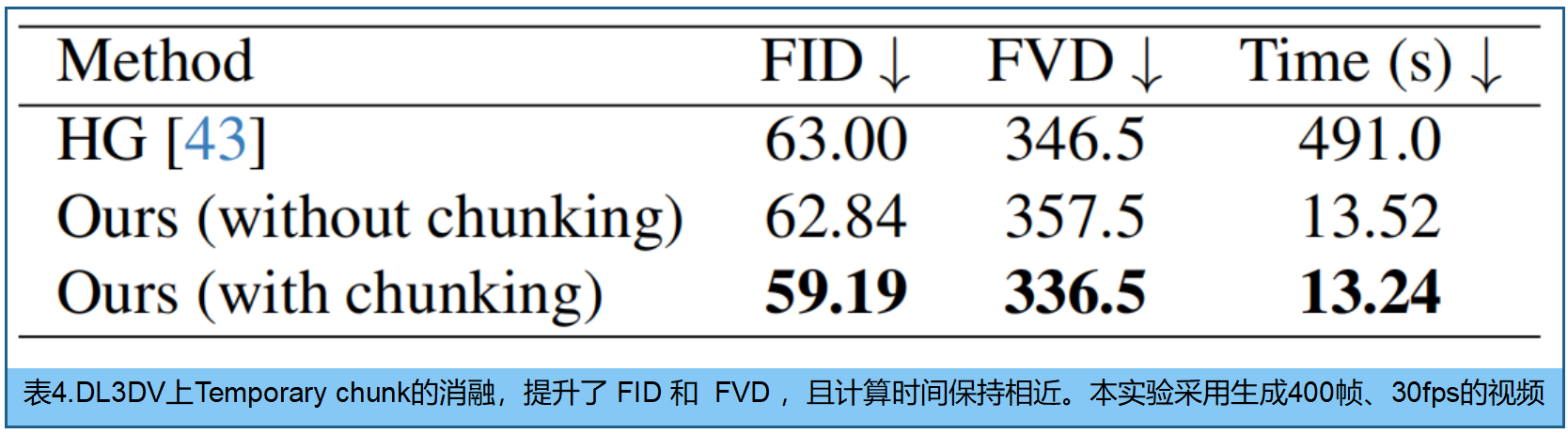
然而在DL3DV等更具挑战性的数据集上,无论是使用我们的模型还是其他基准模型,生成的长轨迹关键帧都存在明显漂移现象。超过约10秒的关键帧往往在结构、外观或相对几何关系上出现不一致。这反映出当前扩散模型存在更广泛的局限性------它们难以处理长距离环闭问题,也无法在大基线变化中保持多视角一致性 。若试图从所有关键帧重建单一全局3D场景,由于3D模型需要协调相互矛盾的观测数据,会导致重建结果模糊不清。为解决这一问题, 将关键帧划分为固定时长的 Temporal chunk(实践中为10秒),经实证验证,生成的关键帧在此时长内具有良好的一致性。
分块重建策略:每个窗口,独立使用AnySplat 重建3dgs,并对齐密集输入的摄像机运动轨迹。chunk在相邻片段间设置共享关键帧,并通过估算共享pose集之间的仿射变换来实现场景对齐。完成对齐后,通过查询每个摄像机pose对应的特定片段三维模型来渲染密集视频。无需依赖扩散模型生成无漂移关键帧的情况下,生成高质量视频。
三、实验
1.实验细节
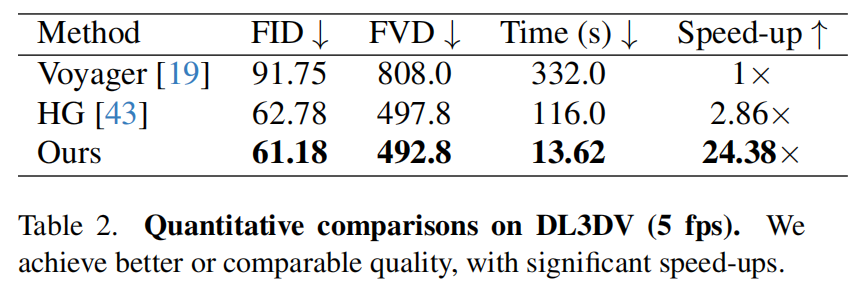
数据集 。在两个基于摄像机运动的视频数据集上进行实验:RealEstate10k (RE10K):沿给定的摄像机运动轨迹生成了20秒时长、10fps(200帧)的视频。对于包含显著更大摄像机运动的DL3DV数据集 ,生成20秒时长、30fps(600帧)的视频。我们为每个数据集分别训练模型,并在256×256分辨率 下训练所有模型。评估使用DL3DV测试集中的50个视频和RE10K测试集中的200个视频。 除表1中的主要评估外,我们采用DL3DV的5帧/秒子采样版本,因为基线方法生成高帧率序列要么速度极慢要么根本无法实现。该测试集使我们能够在不产生高计算成本的情况下对长序列进行比较。
视频生成基准模型 。对比基准模型是历史引导视频扩散模型(HG )43。 该模型具有特殊意义,因其与我们的关键帧生成器共享相同的扩散架构和训练设置,唯一区别在于HG生成所有帧,而srender中的关键帧生成器仅生成稀疏关键帧。我们使用与本模型相同的训练数据集对HG进行训练。此外,我们还与Hunyuan团队19提出的最新相机条件模型Voyager进行了对比。Voyager作为最新模型,其性能不仅对标多项现代视频生成方法42,55,63,还实现了性能提升,因此成为极具代表性的基准模型。我们采用Voyager的预训练模型,但当前版本无法生成数百帧的视频,因此仅在5帧/秒的设置下进行对比。
2D帧插值基准 。与两种2D帧插值方法进行对比:FILM 40和RIFE 21。这些方法通过在生成的关键帧之间插值中间帧,使我们能够评估三维渲染是否比纯二维时间插值更具优势。
2.评价指标
图像与视频质量 。采用FrechetInceptionDistance (FID)15评估每帧图像质量,该指标通过比较生成帧与真实帧的分布相似性来衡量。为评估时间一致性,我们使用FrechetVideoDistance(FVD)47,该指标通过对比生成序列与真实序列中提取的视频片段分布,同时评估外观与运动一致性
效率 。srender的核心目标是实现高效的视频生成,报告了在单个 NVIDIA GH200超级芯片上合成每个视频所需的生成时间(以实际运行时间计)
3.定量指标
表1表明,用关键帧扩散和3D渲染流程替代密集扩散不会降低视觉质量,反而能生成更一致的图像和视频。

在DL3DV上,SRENDER实现了比HG快40倍以上的加速效果;在RE10K上则达到20倍以上的提升。特别值得一提的是,srender在DL3DV上实现了实时渲染性能,仅需平均16.21秒即可生成256×256分辨率、20秒时长、30帧/秒的视频,对应生成帧率为37.01帧/秒。相比之下,HG的生成帧率仅为0.86帧/秒。这些数据充分证明,显式三维重建与渲染技术在不牺牲画质的前提下,能带来显著的效率提升
表2展示了DL3DV在5fps测试集上的结果,其与HG和最先进的Voyager模型进行了对比。
4.定性结果
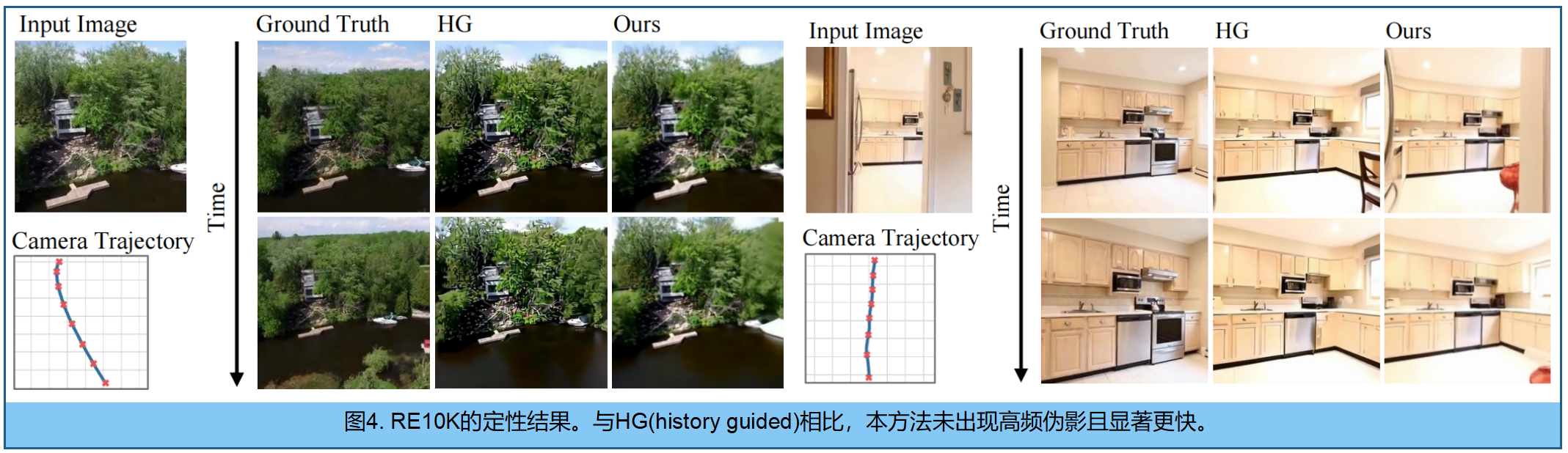
图3展示了DL3DV 与 HG模型 及 Voyager模型 的定性对比 。我们的方法在大视角变化下仍能生成高质量结果。图4提供了RE10K数据集的补充对比,其中srender模型再次实现了高视觉保真度和轨迹全程一致的外观表现。读者可访问网站,查看生成序列的完整可视化效果。

虽然基于3D重建流程生成的视频,相较于扩散模型基线,可能略显平滑且高频细节较少 ,但它们避免了HG模型特有的高频伪影,并保持了比Voyager更显著的几何稳定性,整个轨迹中结构与外观始终保持一致。
其他结果:
#pic_center =60%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E