在分布式搜索领域,Elasticsearch 几乎是"快"的代名词。
你是否想过下边这样的场景:
当我们在日志系统中查询刚刚报错的堆栈信息时,为什么面对亿级数据量,ES 依然能在毫秒级返回结果?
更神奇的是,为什么数据刚刚写入,仅仅过了不到一秒,就能被检索到?
是的,更准确地说,ES 一直宣称的特性是**"近实时" (NRT,Near Real-Time)**。
那么,为什么是"近"实时呢?这个字面上的"一字之差"背后,隐藏着 Elasticsearch 为了实现超高速搜索所做的精妙架构权衡。
01
超快查询的基石:Lucene 和倒排索引
在说"近实时"之前,我们必须先理解 ES 为什么"快"。如果底层存储结构不支持极速查找,那么无论上层怎么优化,最后都是徒劳。
ES 的快,核心在于其底层的Lucene 引擎 ,以及一种被称为**倒排索引(Inverted Index)**的数据结构。
Apache Lucene
**Lucene 是由 Apache 软件基金会维护的一个开源的 Java 库,用于全文检索和信息检索。**Lucene 提供了强大的低级别的索引和搜索功能,例如文本分词、倒排索引创建、相关性计算等。
Lucene 主要功能包括:
-
**文本分词和分析:**将文本切分成词条,便于索引和搜索。
-
**倒排索引:**创建倒排索引结构,便于快速检索包含特定词条的文档。
-
**查询解析:**支持多种查询(布尔查询、短语查询、范围查询等),并计算文档与查询的相关性分数。
-
**排序和打分:**根据查询与文档的匹配程度(得分)对结果进行排序。
-
**全文检索:**高效实现了全文搜索的复杂算法。
Lucene 是一个库,不是一个独立的搜索服务或引擎,需要开发者编写代码来与 Lucene 交互并构建索引和查询。
**Elasticsearch 就是一个构建在 Lucene 之上的分布式搜索引擎,它封装了 Lucene 的功能,**提供了更多的特性和用户友好的 REST API,便于开发和管理。
Elasticsearch 的核心搜索、索引、分析等功能实际上是由 Lucene 提供的;换句话说,Lucene 是 Elasticsearch 的核心引擎。
倒排索引
传统的关系型数据库(如 MySQL)通常采用正向索引,即通过文档 ID(行 ID)去查找该文档(行)的内容。这种方式用ID的键位做查询条件,速度很快,但对于全文检索来说,就很尴尬,比如like %name%,这样就走不到索引了,需要全表查询。
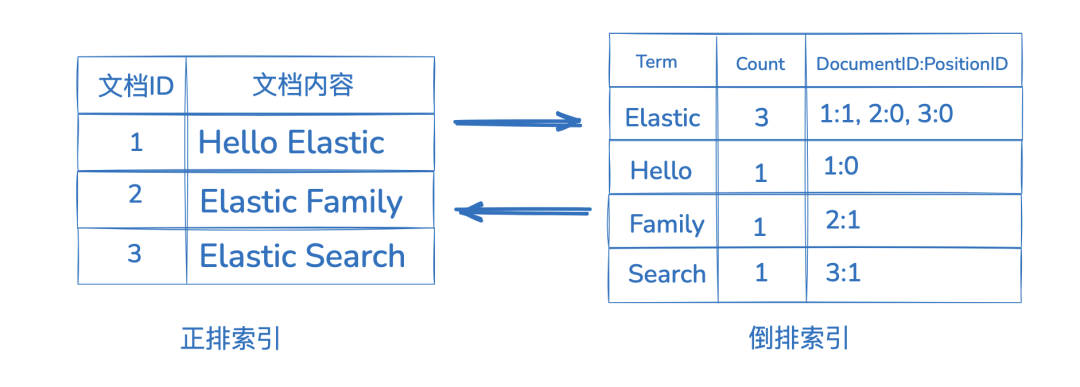
倒排索引则完全颠倒了这种关系,从上图可以看到,它的核心结构,是一个从词项(Term)到包含该词项的文档列表(Posting List)的映射。
当用户搜索一个词时,ES/Lucene 直接在词典中定位该词,然后立即获取包含该词的文档 ID 列表,无需扫描任何文档。这使得全文本匹配查询的速度几乎是 O(1) 级别的。
02
从写入到可查:近实时的诞生
Elasticsearch 的近实时特性,是其数据持久化和可搜索性机制之间博弈的结果。
比如,当我们向 ES 发送下边一条写入文档请求时,数据并不会立刻存入磁盘,也不会立刻被搜索到,它会经历以下几个阶段:
POST /logs/_doc{"level":"INFO","message":"order created","timestamp":"2025-12-12T10:00:00"}
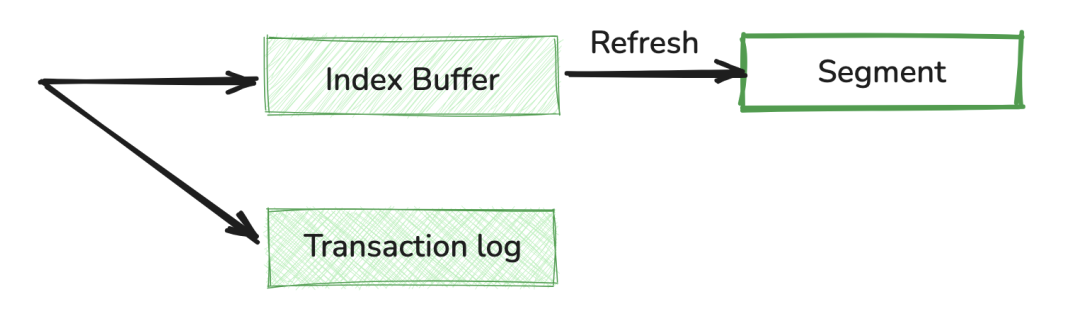
ES 写入过程图
1、写入 Index Buffer
当写入请求到达 ES 节点后,数据首先会被写入:
-
Indexing Buffer(索引缓冲区,内存)
-
按 shard 维度维护
此时,这部分数据就在内存里。但是,它是不可被搜索的。
2、同时写入 Transaction log
为了保证数据的持久性和可靠性,ES 采用了一种预写日志(Write-Ahead Log, WAL)机制,即 Translog。
-
**Transaction log 的作用:**确保即使系统发生硬件故障、电源中断或进程崩溃,已接收但尚未提交到 Lucene 永久索引的文档也不会丢失。
-
如何工作: 每个索引操作(CRUD)都会在内存缓冲区写入的同时,追加写入 到分片所在的磁盘上的 Translog 文件中。默认情况下,Translog 是在每次索引、删除、更新操作后同步 (fysnc) 刷新到磁盘的。
-
**持久性保证:**只要文档写入了 Translog 并同步到磁盘,它就被认为是持久的,即使 Lucene 索引本身还没有写入磁盘。
3、Refresh:变为可查的关键一步
要让内存中的文档变成可搜索的状态,就必须执行Refresh(刷新)操作。这是从"写入"到"可查"的关键一步。
-
刷新机制: Refresh 操作会将内存缓冲区(Index Buffer)中的文档清空,并将其转换为一个新的、内部的**Lucene 段 (Segment)**文件。
-
**Segment 段的打开:**这个新创建的段会被打开,并立即对搜索可见。
此时 Segment 仍然在操作系统的文件系统缓存中,尚未同步到永久磁盘存储。
- **延迟的来源:**默认情况下,Elasticsearch 的 index.refresh_interval 设置为 1 秒。这意味着从文档被索引到它能被搜索到,通常会有 0 到 1 秒的延迟。
这里是理解近实时 NRT 的核心:
-
**Segment 是 Lucene 的最小索引单元。**一旦数据变成了 Segment,它就拥有了倒排索引结构,可以被搜索了。
-
这个 Segment 被写入了操作系统的 FileSystem Cache(文件系统缓存),而不是物理磁盘。
写入 文件系统缓存的速度是非常快的(内存操作),不需要物理磁盘磁头寻道。正是因为 ES 允许数据先存在于 OS Cache 中即可被搜索,才实现了"秒级"可见。
4、Flush:真正的落盘
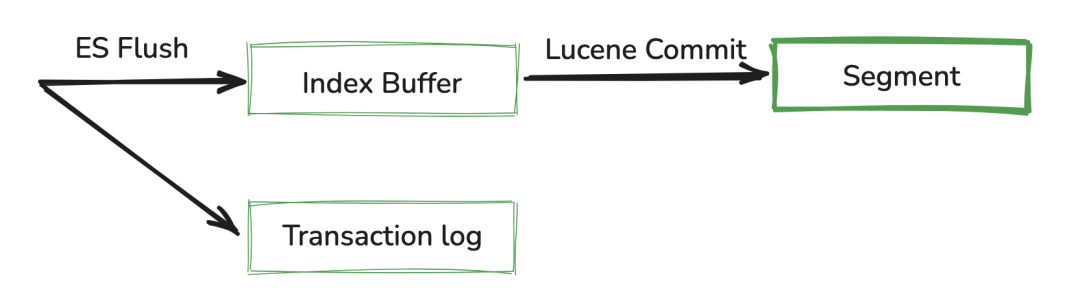
随着时间推移,Translog 越来越大。ES 需要定期进行 Flush 操作,Flush 通常包含以下内容:
-
**执行刷新:**首先进行一次 Refresh,确保所有内存中的文档都变成可搜索的段。
-
强制同步: 调用 Lucene 的 commit 操作,强制将所有内存中的段数据(即索引文件)同步 (fsync) 到磁盘的永久存储。(这时 Segment 才写入磁盘)
-
**清空 Translog:**在所有段文件安全写入磁盘后,Translog 文件会被清空并重新开始记录。
**Flush 的频率:**Flush 操作比 Refresh 频率低得多,通常每 30 分钟自动执行一次,或在 Translog 文件达到一定大小时触发。
正是通过这种内存Index Buffer/Translog -> Refresh -> Flush的三步走策略,ES 巧妙地实现了高吞吐、高可靠、且近实时的索引能力。
03
Segment 的不可变性与合并
ES 的查询性能还有一个重要前提:Segment。
Segment 特性
Segment 是:
-
不可变(Immutable)的索引文件
-
包含完整的倒排索引结构
-
一旦生成,只读不写
Segment的上述特性带来了极大的优势:
-
**无需加锁:**查询线程在读取段时,无需担心数据会被其他写入线程修改,因此无需使用复杂的锁机制,大大提高了并发查询效率。
-
**高效缓存:**操作系统可以将不可变的段文件(尤其是倒排索引的核心结构)完美地加载到文件系统缓存中。
Segment 合并
由于 refresh_interval 默认 1 秒,意味着每秒都会产生一个新的小 Segment。时间一长,文件句柄会被耗尽,查询也会因为要扫描太多 Segment 而变慢。
ES 后台会有一个独立线程,悄悄地进行**Merge (合并)**操作:
-
选取一些小的 Segments
-
将它们合并成一个大的 Segment
-
关键点:在合并过程中,真正剔除掉那些被标记为"已删除"的文档
-
合并完成后,删除旧的小 Segments
Merge 操作不影响性能,但是,**合并是一个 I/O 密集型操作,会占用磁盘带宽。**但这是一个必要的后台任务,确保索引结构保持优化,从而保证前端查询的速度。
04
分布式架构带来的查询加速
另外,Elasticsearch 作为一个分布式系统,这种架构天生会带来一些查询加速的效果。
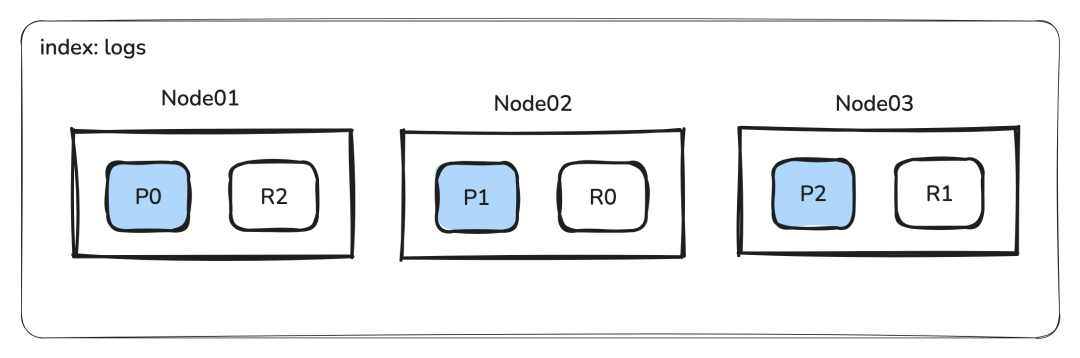
1、分片(Shards)与副本(Replicas)
-
**分片 (Shards):**ES 将一个索引(Index)分解成多个独立的 Lucene 索引,称为主分片 (Primary Shards)。这些分片被分布在集群的不同节点上。
-
**并行查询:**当一个搜索请求到达时,ES 会将查询分发到所有相关的主分片和副本分片上,这些分片并行地在其本地数据上执行查询。
-
**横向扩展:**增加节点数量和分片数量,意味着可以同时处理更多的查询和更多的数据,是实现大规模高性能查询的直接途径。
2、两阶段查询
阶段一:查询 (Query Phase)
-
接收请求: 任何节点都可以接收用户的搜索请求,该节点成为协调节点 (Coordinating Node)。
-
**分发查询:**协调节点将搜索请求发送给涉及索引的所有分片(通常是主分片或副本分片中负载较轻的一个)。
-
**本地执行:**每个分片独立地执行查询,找出符合条件的文档。
-
**返回局部结果:**每个分片只返回文档的 ID (Document ID) 和计算出的相关性得分。
此阶段:只查索引,不取完整文档
阶段二:取回 (Fetch Phase)
-
**收集排序:**协调节点接收到所有分片返回的 Document ID 和 _score 得分列表。
-
**全局排序:**协调节点对这些局部结果进行全局排序,确定最终需要返回给用户的 N 个文档。
-
**批量取回:**协调节点根据最终排序结果,向持有这些文档 ID 的分片发起一个高效的批量取回 (Multi-Get) 请求。
-
**返回结果:**分片将完整的文档内容返回给协调节点,协调节点最终将完整的结果集返回给用户。
通过两阶段查询,这种**"先定位、后取数"**的设计机制,ES 将繁重的搜索和评分工作分散到各个节点并行处理,而协调节点只负责轻量级的排序和数据聚合,从而在分布式环境中实现了极高的查询效率。
05
写在最后
通过以上的介绍,我们会知道 ES 非常适合:日志分析、搜索系统、可观测性平台等场景;但并不适用于强一致事务和严格实时读写。
"从写入到可查"的过程,体现了 Elasticsearch 架构的精妙:它牺牲了严格的"实时"性,以换取惊人的索引吞吐量和查询速度。
通过 Lucene 的底层优化和自身的分布式协调能力,Elasticsearch 成为了构建现代、高性能搜索和分析平台的首选工具。