本篇技术博文摘要 🌟
- 文章始于核心要素 回顾,继而详细拆解了标准训练流程 ,涵盖数据准备、模型构建、编译 等关键步骤,并着重剖析了
fit()方法的核心参数。- 为了更直观地监控与理解模型行为,文章介绍了训练过程可视化 的实用方法,包括训练曲线与流程图 的生成。在高级技巧 部分,指导读者超越基础API,学习如何通过自定义训练循环 获得对训练过程的完全控制,并有效利用回调函数实现日志记录、检查点保存等自动化任务。
- 针对实践中不可避免的挑战,文章汇总了常见问题与解决方案 ,提供了清晰的排查表 与涵盖数据管道优化、混合精度训练及分布式训练 的性能优化建议。
- 最后,通过 Fashion MNIST数据集上构建并优化CNN模型 的系列实践小项目,将前述理论串联应用:从基础模型实现,到结合高级技巧进行增强,再到完全使用自定义训练循环进行重建,从而确保读者能够通过动手实践真正掌握从入门到进阶的完整模型训练技能。
引言 📘
- 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。
- 我是盛透侧视攻城狮,一个"什么都会一丢丢"的网络安全工程师,目前正全力转向AI大模型安全开发新战场。作为活跃于各大技术社区的探索者与布道者,期待与大家交流碰撞,一起应对智能时代的安全挑战和机遇潮流。

上节回顾
目录
[本篇技术博文摘要 🌟](#本篇技术博文摘要 🌟)
[引言 📘](#引言 📘)
[1.TensorFlow 模型训练](#1.TensorFlow 模型训练)
[2.4.1训练方法中fit() 方法主要参数](#2.4.1训练方法中fit() 方法主要参数)
6.实践小项目练习(由于主包在乡下,始终没有下载好MINST数据集)
[6.1Fashion MNIST构建CNN模型](#6.1Fashion MNIST构建CNN模型)
[6.2Fashion MNIST构建CNN模型结合高级技巧](#6.2Fashion MNIST构建CNN模型结合高级技巧)

1.TensorFlow 模型训练
TensorFlow 提供了构建和训练神经网络模型的全套工具。
模型训练是指通过数据让模型自动调整参数,从而获得预测能力的过程。

1.1模型训练的核心要素
- 数据:训练集、验证集和测试集
- 模型架构:神经网络的层结构和连接方式
- 损失函数:衡量模型预测与真实值差异的指标
- 优化器:调整模型参数的算法
- 评估指标:衡量模型性能的标准

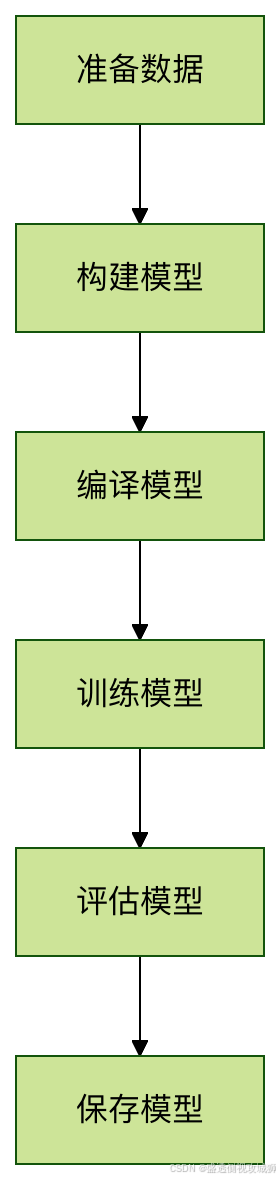
2.训练流程
2.1数据准备
python
import tensorflow as tf
from tensorflow.keras import datasets
# 加载数据集(以MNIST为例)
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 数据预处理
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
# 转换为TensorFlow Dataset
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels))
train_dataset = train_dataset.shuffle(10000).batch(64)
2.2模型构建
python
from tensorflow.keras import layers, models
# 构建Sequential模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 查看模型结构
model.summary()2.3模型编译
python
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
2.4模型训练
python
history = model.fit(train_dataset,
epochs=10,
validation_data=(test_images, test_labels))2.4.1训练方法中fit() 方法主要参数
| 参数 | 类型 | 说明 |
|---|---|---|
| x | 输入数据 | 训练数据 |
| y | 目标数据 | 标签数据 |
| epochs | 整数 | 训练轮数 |
| batch_size | 整数 | 每批数据量 |
| validation_data | 元组 | 验证数据集 |
| callbacks | 列表 | 回调函数列表 |

3.训练过程可视化
3.1训练曲线
python
import matplotlib.pyplot as plt
# 绘制训练和验证的准确率曲线
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()3.2训练流程图

4.高级训练技巧
4.1自定义训练循环
python
# 定义损失函数和优化器
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
# 自定义训练步骤
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_fn(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
# 自定义训练循环
for epoch in range(10):
for images, labels in train_dataset:
loss = train_step(images, labels)
print(f'Epoch {epoch}, Loss: {loss.numpy()}')
4.2回调函数使用
python
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
# 创建回调函数
callbacks = [
ModelCheckpoint('best_model.h5', save_best_only=True),
EarlyStopping(patience=3, monitor='val_loss')
]
# 使用回调训练
model.fit(train_dataset,
epochs=20,
validation_data=(test_images, test_labels),
callbacks=callbacks)
5.常见问题与解决方案
5.1训练问题排查表
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 损失不下降 | 学习率过高/过低 | 调整学习率 |
| 准确率波动大 | 批量大小不合适 | 调整batch_size |
| 过拟合 | 模型太复杂 | 添加正则化或Dropout |
| 训练速度慢 | 硬件限制 | 使用GPU加速或减小模型 |
5.2性能优化建议
5.2.1数据管道优化
- 使用prefetch和cache加速数据加载
python
train_dataset = train_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)5.2.2混合精度训练
python
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)5.2.3分布式训练
python
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = create_model()
model.compile(...)5.3SSL/信号不稳定问题
5.3.1手动下载数据集
5.3.2找到TensorFlow缓存目录
python
# 运行此代码找到缓存目录
import os
cache_dir = os.path.join(os.path.expanduser('~'), '.keras', 'datasets', 'fashion-mnist')
print(f"缓存目录: {cache_dir}")5.3.3手动放置文件
- 将下载的4个文件放入上述目录中。如目录不存在,创建它

6.实践小项目练习
6.1Fashion MNIST构建CNN模型
- 至少包含2个卷积层
- 训练10个epoch
- 记录训练过程中的准确率和损失变化
python
import tensorflow as tf
from tensorflow.keras import layers, models, datasets
import matplotlib.pyplot as plt
# 加载Fashion MNIST数据集
(x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# 构建CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 训练模型
history = model.fit(
x_train, y_train,
epochs=10,
validation_split=0.2,
verbose=1
)
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.title('损失变化')
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()
plt.title('准确率变化')
plt.show()
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"测试准确率: {test_acc:.4f}")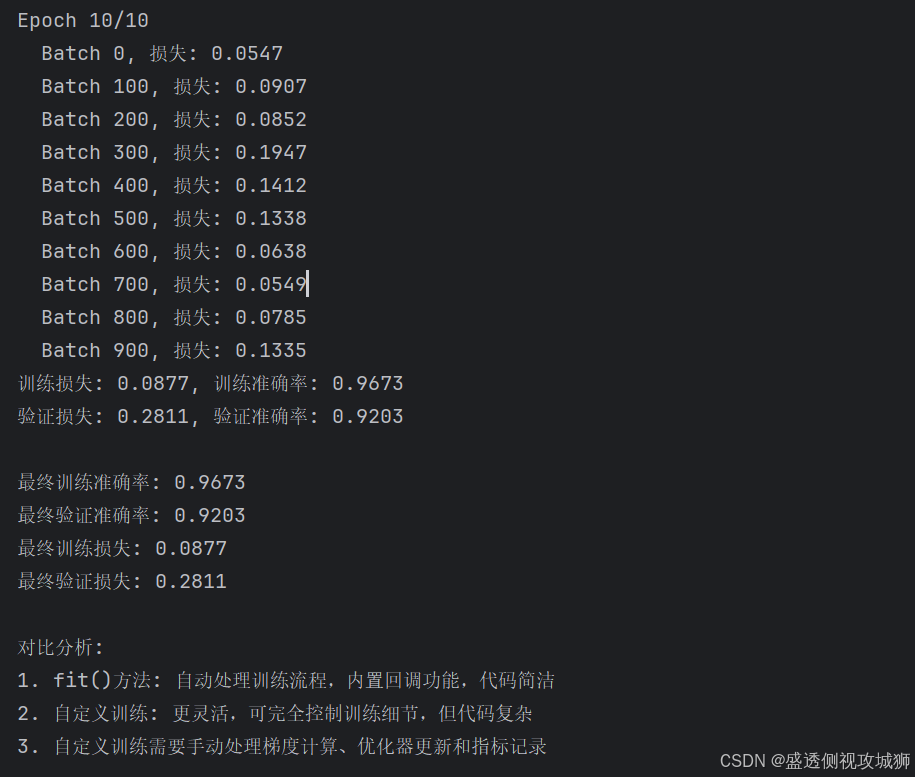
6.2Fashion MNIST构建CNN模型结合高级技巧
- 添加EarlyStopping回调
- 实现学习率衰减
- 使用ModelCheckpoint保存最佳模型
- 注意:运行代码前先可能需要更新一下版本
bashpip install --upgrade tensorflow

python
import tensorflow as tf
from tensorflow.keras import layers, models, datasets, callbacks, optimizers
import numpy as np
# 加载Fashion MNIST数据集
(x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# 构建CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 定义学习率调度器
lr_schedule = optimizers.schedules.ExponentialDecay(
initial_learning_rate=0.001,
decay_steps=1000,
decay_rate=0.9
)
# 编译模型
model.compile(
optimizer=optimizers.Adam(learning_rate=lr_schedule),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 定义回调函数
callbacks_list = [
callbacks.EarlyStopping(
monitor='val_loss',
patience=3,
restore_best_weights=True
),
callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=2,
min_lr=1e-6
),
callbacks.ModelCheckpoint(
filepath='best_model.h5',
monitor='val_accuracy',
save_best_only=True,
mode='max',
save_weights_only=False
),
callbacks.CSVLogger('training_log.csv')
]
# 训练模型
history = model.fit(
x_train, y_train,
epochs=20,
validation_split=0.2,
callbacks=callbacks_list,
verbose=1
)
# 加载最佳模型
best_model = models.load_model('best_model.h5')
# 评估最佳模型
test_loss, test_acc = best_model.evaluate(x_test, y_test, verbose=0)
print(f"最佳模型测试准确率: {test_acc:.4f}")
# 查看训练历史
print(f"训练最佳准确率: {max(history.history['val_accuracy']):.4f}")
6.3通过6.1来进行自定义训练
- 使用自定义训练循环实现6.1,接着比较与fit()方法的差异
python
import tensorflow as tf
from tensorflow.keras import layers, models, datasets
import numpy as np
# 加载Fashion MNIST数据集
(x_train, y_train), (x_test, y_test) = datasets.fashion_mnist.load_data()
# 数据预处理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255.0
# 转换为TensorFlow Dataset
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(60000).batch(64)
val_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
val_dataset = val_dataset.batch(64)
# 构建CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# 定义损失函数和优化器
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# 定义评估指标
train_loss_metric = tf.keras.metrics.Mean(name='train_loss')
train_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy(name='train_acc')
val_loss_metric = tf.keras.metrics.Mean(name='val_loss')
val_acc_metric = tf.keras.metrics.SparseCategoricalAccuracy(name='val_acc')
# 自定义训练步骤
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images, training=True)
loss = loss_fn(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss_metric.update_state(loss)
train_acc_metric.update_state(labels, predictions)
return loss
# 自定义验证步骤
@tf.function
def val_step(images, labels):
predictions = model(images, training=False)
v_loss = loss_fn(labels, predictions)
val_loss_metric.update_state(v_loss)
val_acc_metric.update_state(labels, predictions)
return v_loss
# 训练循环
epochs = 10
train_losses, train_accs = [], []
val_losses, val_accs = [], []
for epoch in range(epochs):
print(f"\nEpoch {epoch + 1}/{epochs}")
# 重置指标
train_loss_metric.reset_states()
train_acc_metric.reset_states()
val_loss_metric.reset_states()
val_acc_metric.reset_states()
# 训练阶段
for batch, (images, labels) in enumerate(train_dataset):
loss = train_step(images, labels)
if batch % 100 == 0:
print(f" Batch {batch}, 损失: {loss:.4f}")
# 验证阶段
for images, labels in val_dataset:
val_step(images, labels)
# 记录指标
train_loss = train_loss_metric.result().numpy()
train_acc = train_acc_metric.result().numpy()
val_loss = val_loss_metric.result().numpy()
val_acc = val_acc_metric.result().numpy()
train_losses.append(train_loss)
train_accs.append(train_acc)
val_losses.append(val_loss)
val_accs.append(val_acc)
print(f"训练损失: {train_loss:.4f}, 训练准确率: {train_acc:.4f}")
print(f"验证损失: {val_loss:.4f}, 验证准确率: {val_acc:.4f}")
# 最终评估
print(f"\n最终训练准确率: {train_acc:.4f}")
print(f"最终验证准确率: {val_acc:.4f}")
print(f"最终训练损失: {train_loss:.4f}")
print(f"最终验证损失: {val_loss:.4f}")
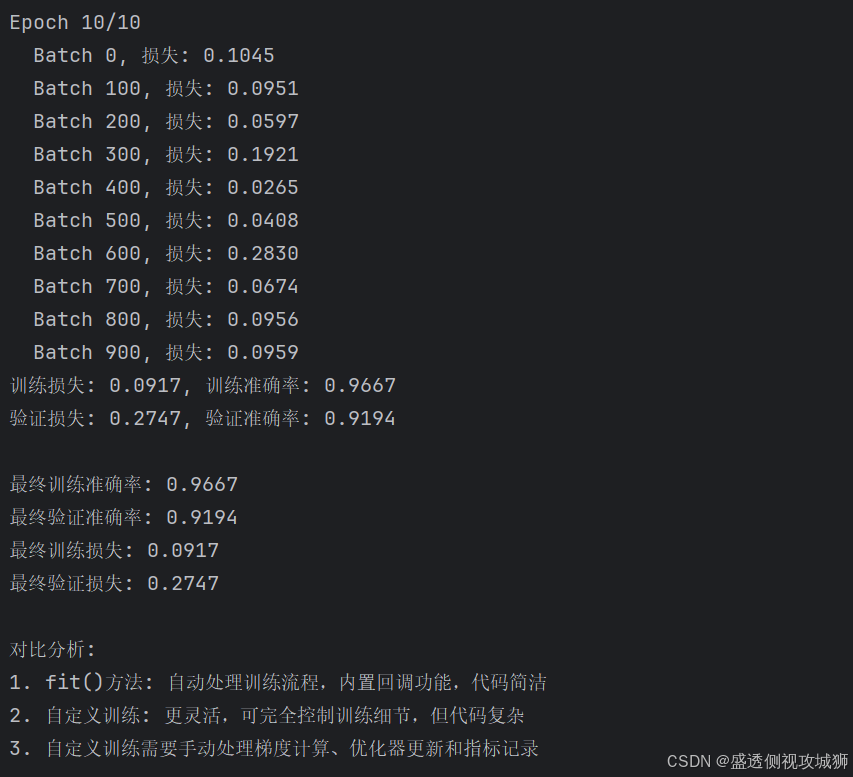
# 对比分析
print("\n对比分析:")
print("1. fit()方法: 自动处理训练流程,内置回调功能,代码简洁")
print("2. 自定义训练: 更灵活,可完全控制训练细节,但代码复杂")
print("3. 自定义训练需要手动处理梯度计算、优化器更新和指标记录")欢迎各位彦祖与热巴畅游本人专栏与技术博客
你的三连是我最大的动力
点击➡️指向的专栏名即可闪现
➡️计算机组成原理****
➡️操作系统
➡️****渗透终极之红队攻击行动********
➡️ 动画可视化数据结构与算法
➡️ 永恒之心蓝队联纵合横防御
➡️****华为高级网络工程师********
➡️****华为高级防火墙防御集成部署********
➡️ 未授权访问漏洞横向渗透利用
➡️****逆向软件破解工程********
➡️****MYSQL REDIS 进阶实操********
➡️****红帽高级工程师
➡️红帽系统管理员********
➡️****HVV 全国各地面试题汇总********
