【Linux系统编程】GDB调试进阶技巧与冯诺依曼体系结构深度解析

🎬 Doro在努力 :个人主页
🔥 个人专栏 : 《MySQL数据库基础语法》《数据结构》
⛺️严于律己,宽以待人
目录
- 一、GDB调试进阶技巧
- [1.1 调试的本质](#1.1 调试的本质)
- [1.2 断点的艺术](#1.2 断点的艺术)
- [1.3 单步调试的两种模式](#1.3 单步调试的两种模式)
- [1.4 变量监视与查看](#1.4 变量监视与查看)
- [1.5 高级调试技巧](#1.5 高级调试技巧)
- 二、冯诺依曼体系结构
- [2.1 什么是体系结构](#2.1 什么是体系结构)
- [2.2 冯诺依曼体系的核心组成](#2.2 冯诺依曼体系的核心组成)
- [2.3 数据流动原理](#2.3 数据流动原理)
- 三、存储分级与内存的意义
- [3.1 存储分级金字塔](#3.1 存储分级金字塔)
- [3.2 为什么需要内存](#3.2 为什么需要内存)
- [3.3 程序为什么要加载到内存](#3.3 程序为什么要加载到内存)
- 四、总结与思考
一、GDB调试进阶技巧
1.1 调试的本质
很多同学在学习调试时,往往只关注命令本身,却忽略了调试的本质。调试的本质是帮助我们分析和定位问题。我们遇到问题后,首先要发现问题,然后分析问题,最后解决问题。调试器就是帮助我们完成分析和定位这个过程的工具。
在Linux环境下,GDB(GNU Debugger)是最强大的调试工具之一。但要真正用好GDB,我们必须理解:所有的调试命令都是围绕"找问题"这个核心目标展开的。
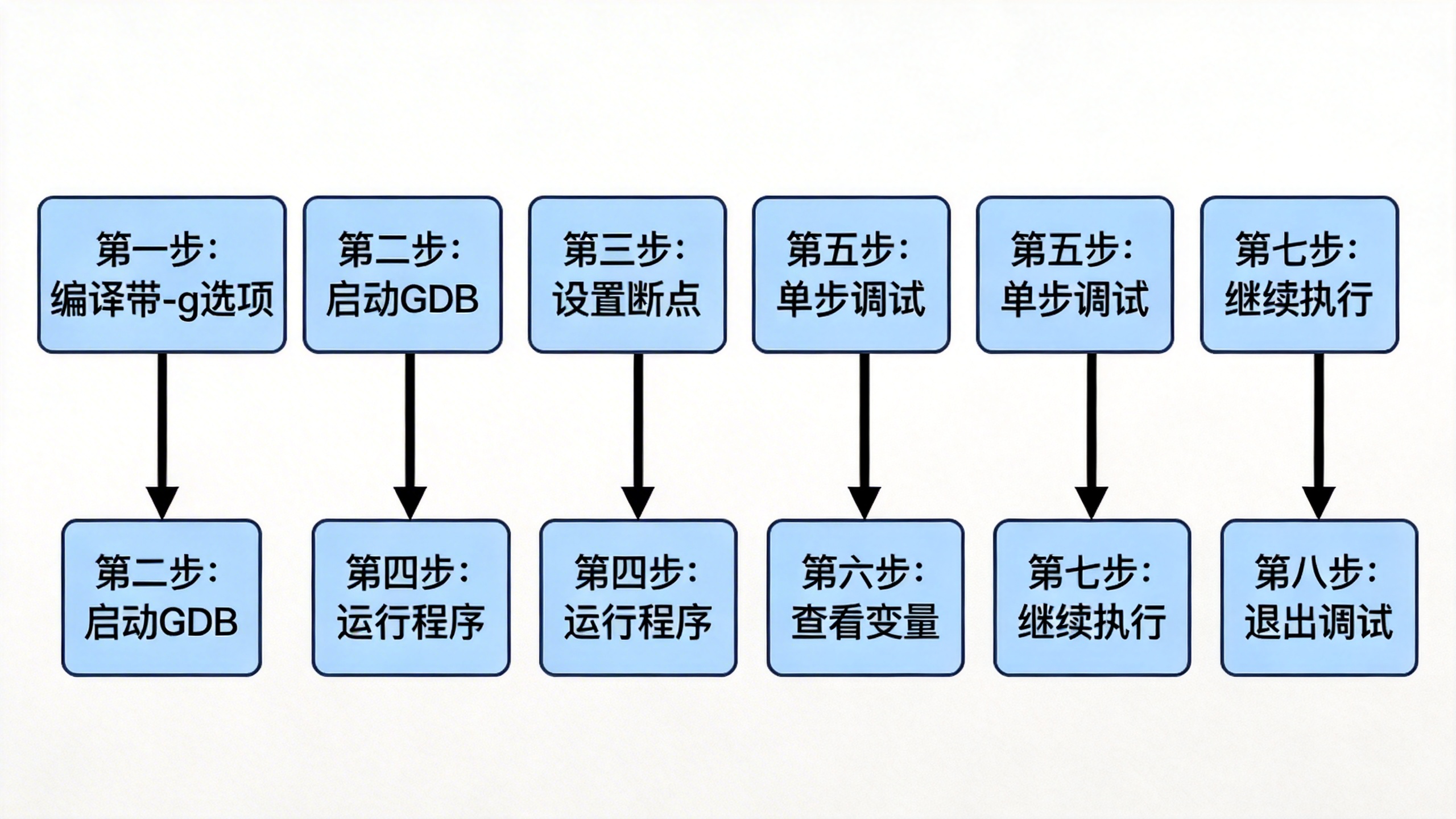
1.2 断点的艺术
断点的本质
断点(Breakpoint)是调试中最基础也是最重要的概念。断点的本质是将代码执行区域化,让我们可以把查找Bug的范围从大缩小到小。通过设置断点,我们可以将查找问题的过程转化为一个"查找"的任务,采用类似二分查找的方式,快速定位问题所在。
c
// 示例代码:求和函数
#include <stdio.h>
int Sum(int s, int e)
{
int result = 0;
for(int i = s; i <= e; i++)
{
result += i;
}
return result;
}
int main()
{
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n", start, end, n);
return 0;
}
断点编号机制
在GDB中,断点有一个重要的特性:断点编号在一个调试周期内是线性递增的。这意味着:
- 创建一个断点,编号从1开始
- 删除断点后,再创建新断点,编号会继续增加
- 重新启动GDB后,编号会重新从1开始
bash
(gdb) b 19 # 创建1号断点
(gdb) b 21 # 创建2号断点
(gdb) d 1 # 删除1号断点
(gdb) b 19 # 创建3号断点(不是1号!)断点的使能与禁用
除了创建和删除断点,我们还可以对断点进行使能(Enable)和禁用(Disable)操作。这有什么意义呢?
禁用断点的价值在于保留调试痕迹。当我们调试时,可能需要在某个位置反复测试,但又不想每次都停在那里。这时可以禁用断点,保留这个位置的记忆,证明我们曾经在这里调试过。
bash
(gdb) disable 1 # 禁用1号断点
(gdb) enable 1 # 启用1号断点1.3 单步调试的两种模式
在Visual Studio中,我们有F10(逐过程)和F11(逐语句)两个调试快捷键。在GDB中,对应的是next(简写n)和step(简写s)命令。
next命令 - 逐过程
next命令类似于VS中的F10,它会单步执行代码,但不会进入函数内部。当遇到函数调用时,它会将整个函数作为一个整体执行完毕。
bash
(gdb) n # 逐过程执行,不进入函数step命令 - 逐语句
step命令类似于VS中的F11,它会进入函数内部,逐行执行函数中的代码。这对于深入理解函数内部逻辑非常有用。
bash
(gdb) s # 逐语句执行,进入函数内部三种范围执行命令
除了基本的单步调试,GDB还提供了三种"范围执行"命令,帮助我们批量执行代码:
- continue ©: 从当前位置连续执行,直到遇到下一个断点或程序结束
- finish: 执行完当前函数,然后立即停止
- until 行号: 执行到指定行号处停止
bash
(gdb) c # 连续执行到下一个断点
(gdb) finish # 执行完当前函数
(gdb) until 20 # 执行到第20行until命令的使用注意事项:
- 不能跨函数使用,只能在一个函数内部跳转
- 不能向前跳转(跳转到前面的行号),这会导致函数执行完毕
- 不能跳转到空行,GDB会自动找到最近的有效代码行
1.4 变量监视与查看
display命令 - 长显示
在调试过程中,我们经常需要持续观察某些变量的值。display命令可以实现"长显示"功能,每次程序停止时,自动显示指定变量的值。
bash
(gdb) display i # 长显示变量i的值
(gdb) display result # 长显示变量result的值要取消长显示,使用undisplay命令,需要指定显示项的编号:
bash
(gdb) undisplay 1 # 取消编号为1的长显示项print命令 - 打印与表达式求值
print(简写p)命令不仅可以打印变量的值,还可以计算表达式的值。这在调试时非常有用,可以帮助我们验证计算逻辑。
bash
(gdb) p result # 打印result的值
(gdb) p start + end # 计算表达式start + end的值
(gdb) p result * flag # 验证计算逻辑info locals命令 - 查看所有局部变量
当我们进入一个函数后,如果想快速查看所有局部变量的值,可以使用info locals命令。这相当于VS中的"局部变量"窗口。
bash
(gdb) info locals # 显示当前函数的所有局部变量1.5 高级调试技巧
watch命令 - 监视变量变化
watch命令是GDB中一个非常强大的功能。它可以监视一个变量或表达式的值,当该值发生变化时,程序会自动暂停并通知我们。
bash
(gdb) watch result # 监视result变量的变化watch命令的典型应用场景:
-
检测不应该被修改的变量: 当我们有一个全局变量或指针,在某些代码段中不应该被修改,但怀疑它被误改了,就可以用watch监视它。
-
追踪变量变化过程: 当我们想观察一个变量在程序运行过程中的所有变化时,watch会自动帮我们捕获每一次变化。
c
// 示例:全局变量flag不应该被修改
int flag = 1; // 标志位,控制计算方向
int Sum(int s, int e)
{
int result = 0;
for(int i = s; i <= e; i++)
{
result += i;
}
return result * flag; // 如果flag被意外修改,结果就会出错
}set var命令 - 动态修改变量值
set var命令允许我们在调试过程中动态修改变量的值 。这个技巧的价值在于验证我们对问题原因的猜测。
假设我们发现程序运行结果不对,怀疑是某个变量的值有问题。以前我们需要:
- 退出GDB
- 修改源代码
- 重新编译
- 重新运行测试
现在使用set var,我们可以直接在调试时修改:
bash
(gdb) p flag # 发现flag的值为0
(gdb) set var flag=1 # 将flag修改为1
(gdb) n # 继续执行,验证结果是否正确set var的典型应用场景:
- 验证标志位问题: 当我们怀疑某个标志位设置错误时,可以直接修改验证
- 测试边界条件: 快速测试不同参数值对程序的影响
- 跳过某些代码逻辑: 通过修改循环计数器等,快速跳过某些代码段
条件断点 - 精准定位问题
条件断点是断点的高级用法。它允许我们设置断点只在满足特定条件时才触发。
创建条件断点的两种方式:
- 创建时直接指定条件:
bash
(gdb) b 11 if i == 30 # 在第11行设置断点,只有当i等于30时才触发- 为已存在的断点添加条件:
bash
(gdb) b 11 # 先创建普通断点
(gdb) condition 2 i==30 # 为2号断点添加条件条件断点的典型应用场景:
想象我们在写一个冒泡排序算法,发现前8轮排序都是正确的,只有最后两轮出错。如果我们在循环内部设置普通断点,每次循环都会触发,非常麻烦。这时就可以使用条件断点:
bash
(gdb) b 循环行号 if i == 8 # 只有当i等于8时才触发断点这样,前7轮循环会直接执行,当i等于8时才会暂停,大大提高了调试效率。
二、冯诺依曼体系结构
2.1 什么是体系结构
在学习计算机组成原理时,我们经常会听到"体系结构"这个词。所谓的体系结构,通常表示的是计算机是如何组织硬件的。
就像秦始皇统一六国后,推行"车同轨,书同文"的标准一样,计算机硬件的各个组件也需要统一的标准,才能协同工作。内存条、硬盘、CPU等不同厂商生产的硬件,之所以能够组装在一起使用,就是因为它们遵循了统一的接口标准。
2.2 冯诺依曼体系的核心组成
冯诺依曼体系结构是现代计算机的基础架构,它由五大基本部件组成:
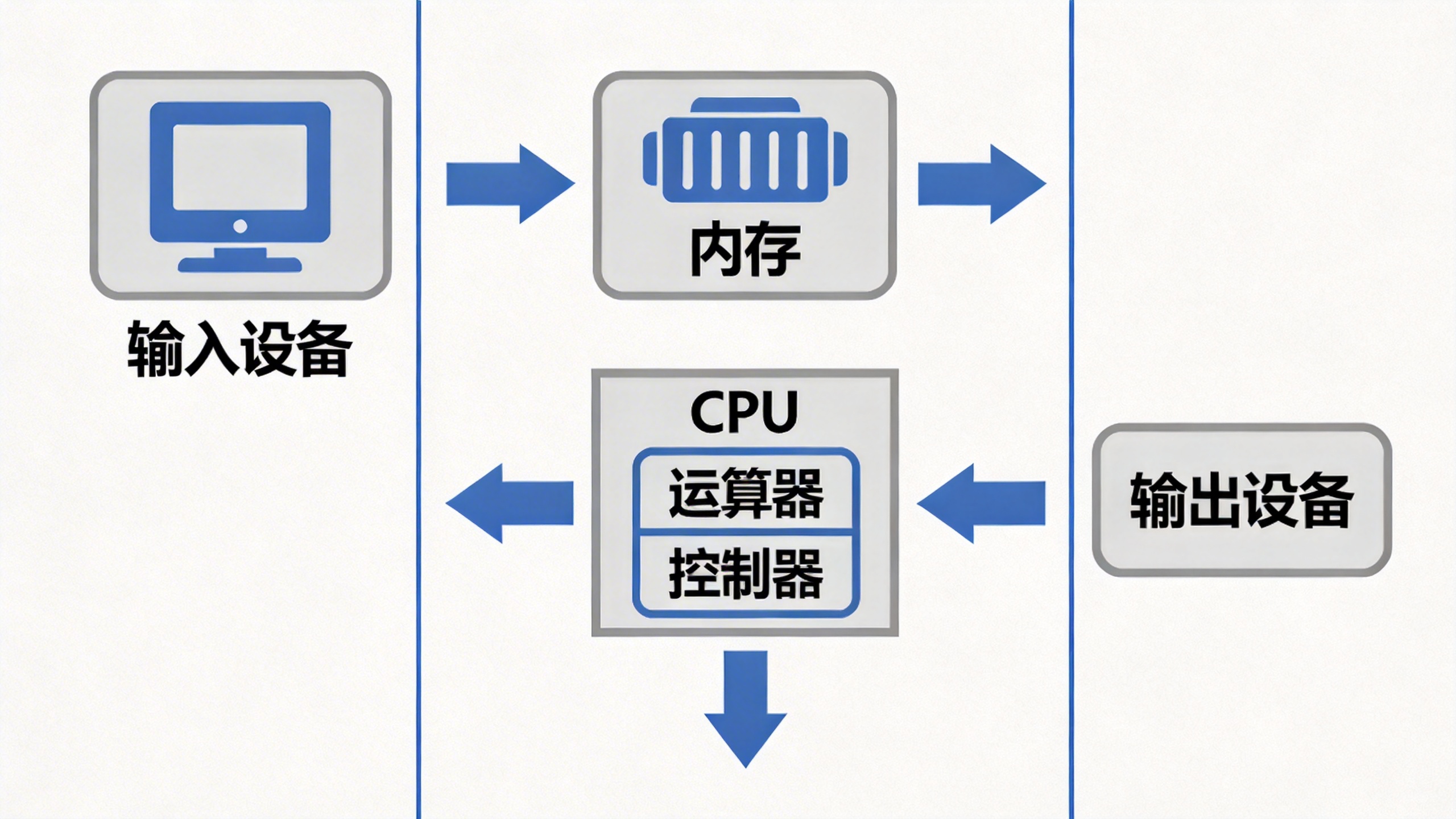
输入设备
输入设备负责将外部数据输入到计算机中。常见的输入设备包括:
- 键盘、鼠标
- 扫描仪、摄像头
- 麦克风、手写板
- 磁盘(在读取数据时作为输入设备)
输出设备
输出设备负责将计算机处理的结果输出。常见的输出设备包括:
- 显示器、打印机
- 扬声器、耳机
- 网卡(在网络通信时作为输出设备)
中央处理器(CPU)
CPU是计算机的核心,它包含两个主要部件:
- 运算器: 负责执行算术运算(加减乘除)和逻辑运算(与或非)
- 控制器: 负责控制整个计算机系统的协调工作
CPU的特点是速度快、能力强,但容量有限。它就像一位大学生,能够处理复杂的任务,但数量有限。
存储器(内存)
内存是冯诺依曼体系结构中的关键组件。它位于CPU和外设之间,起到数据中转站的作用。
重要原则: 在冯诺依曼体系中,CPU不能直接访问外设,外设也不能直接访问CPU。所有的数据交换都必须通过内存进行。
2.3 数据流动原理
数据流向规则
根据冯诺依曼体系结构的规定:
- 输入设备 的数据必须先写入内存
- CPU 只能从内存读取数据
- CPU 处理完的数据必须写回内存
- 内存 再将数据输出到输出设备
这个规定看似增加了数据传输的步骤,但实际上是为了提高整体效率。
为什么需要内存作为中转
这里就涉及到一个重要的概念:木桶原理。
木桶原理: 一个木桶能装多少水,取决于最短的那块木板。
在计算机系统中,外设(如磁盘、键盘)的速度非常慢,通常是毫秒级别;而CPU的速度非常快,是纳秒级别。如果让CPU直接和外设打交道,整个系统的效率就会被外设的速度所拖累。
内存的速度介于CPU和外设之间,比外设快得多。通过内存作为中转站,CPU可以高速地从内存读取数据,而外设可以慢慢地将数据载入内存。这样,CPU不需要等待外设,大大提高了系统的整体效率。
三、存储分级与内存的意义
3.1 存储分级金字塔
在计算机系统中,存储设备按照距离CPU的远近和速度的快慢,形成了一个金字塔结构:
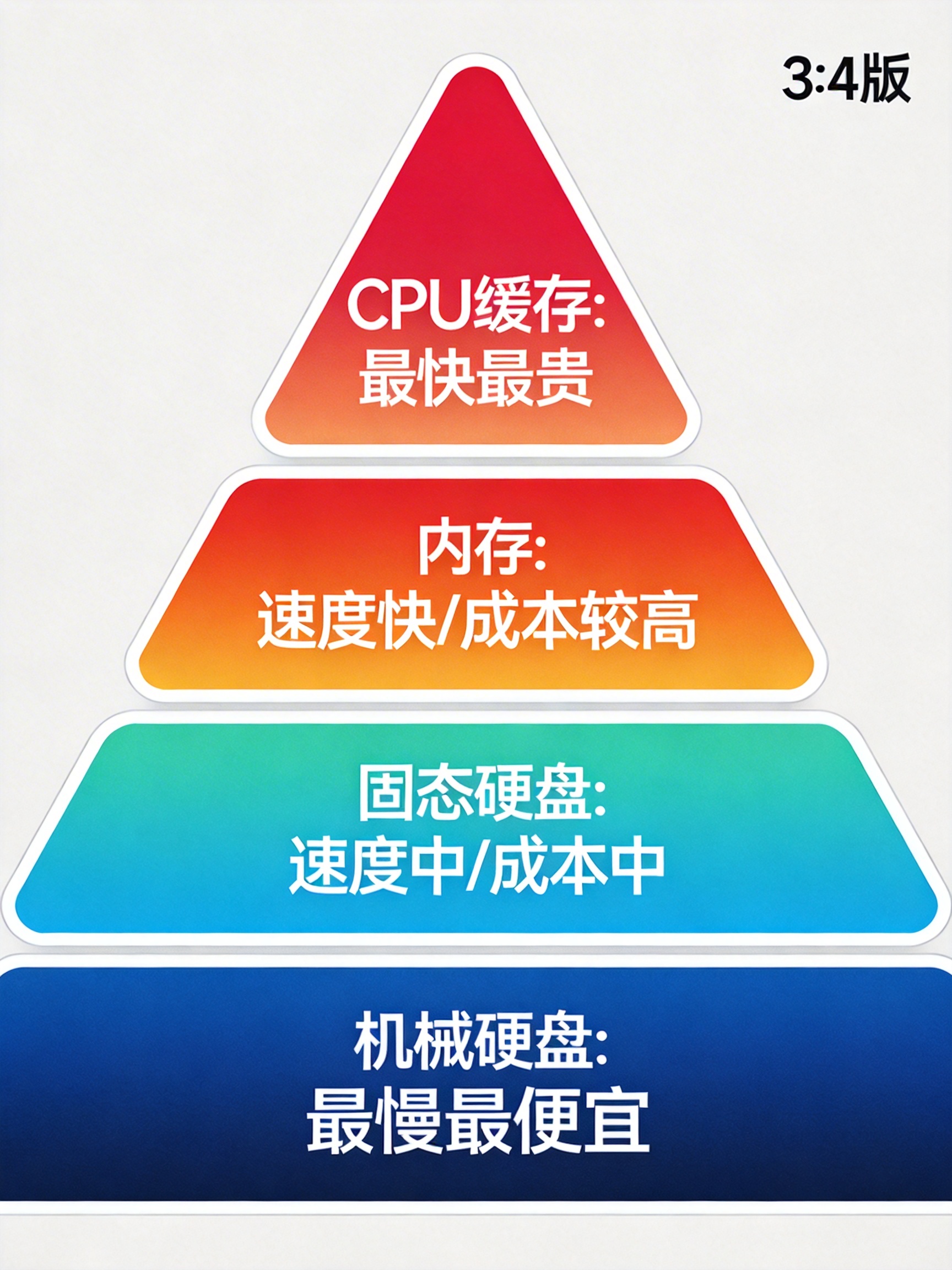
金字塔顶端:CPU缓存
- 位置: 集成在CPU内部
- 速度: 最快,纳秒级别
- 成本: 最高
- 容量: 最小(通常几MB到几十MB)
第二层:内存(RAM)
- 位置: 通过内存总线与CPU连接
- 速度: 快,比CPU缓存慢10倍左右
- 成本: 较高
- 容量: 中等(通常8GB到64GB)
第三层:固态硬盘(SSD)
- 位置: 通过SATA或NVMe接口连接
- 速度: 中等,比内存慢100倍以上
- 成本: 中等
- 容量: 较大(通常256GB到2TB)
金字塔底端:机械硬盘(HDD)
- 位置: 通过SATA接口连接
- 速度: 最慢,毫秒级别
- 成本: 最低
- 容量: 最大(通常1TB到10TB)
速度与成本的关系
存储分级遵循一个基本规律:离CPU越近,速度越快,成本越高;离CPU越远,速度越慢,成本越低。
这种分级设计是为了在性能 和成本之间找到平衡点。如果全部使用最快的存储设备,计算机的价格会非常昂贵,普通人无法承受;如果全部使用最便宜的存储设备,计算机的速度会非常慢,无法满足使用需求。
3.2 为什么需要内存
理解了存储分级,我们就能回答一个关键问题:为什么计算机需要内存?
原因一:速度匹配
CPU的速度是纳秒级别,外设的速度是毫秒级别,两者相差百万倍。如果没有内存作为缓冲,CPU每次访问外设都要等待很长时间,这是对CPU计算能力的巨大浪费。
内存的速度是微秒级别,虽然比CPU慢,但比外设快得多。通过内存,CPU可以高速地读写数据,而外设可以慢慢地载入或输出数据,两者不需要互相等待。
原因二:批量数据传输
内存的另一个重要作用是批量数据传输。
假设CPU需要处理100个数据。如果没有内存,CPU每次需要数据时,都要从外设读取,需要100次I/O操作。而有了内存,外设可以一次性将100个数据载入内存,CPU直接从内存读取,只需要1次I/O操作。
这种"批量预读"和"批量写入"的策略,大大减少了I/O操作的次数,提高了系统效率。
原因三:性价比
内存的存在,让计算机具有了性价比。
如果我们把所有的存储设备都换成最快的内存,一台计算机的价格可能高达几十万甚至上百万,普通人根本买不起。正是因为有了内存、硬盘等不同速度的存储设备,我们才能用几千元的价格买到一台性能不错的电脑。
冯诺依曼体系结构的伟大之处,就在于它通过引入内存,在速度和成本之间找到了完美的平衡点,让计算机能够普及到千家万户。
3.3 程序为什么要加载到内存
最后,我们来回答一个很多同学都困惑的问题:为什么程序运行前必须先加载到内存?
从硬件角度解释
根据冯诺依曼体系结构的规定,CPU只能访问内存,不能直接访问外设。
程序本质上是一系列的指令和数据。当程序存储在磁盘上时,CPU无法直接执行它。必须先将程序从磁盘载入内存,CPU才能从内存中读取指令和数据,执行程序。
从软件角度解释
程序运行时,需要不断地读取指令、读取数据、写入结果。这个过程涉及大量的内存访问操作。如果程序还在磁盘上,每次访问都要进行磁盘I/O,速度会非常慢,程序几乎无法运行。
将程序加载到内存后,CPU可以以极高的速度访问指令和数据,程序才能正常运行。
总结
程序必须先加载到内存,这是由冯诺依曼体系结构的硬件设计决定的。内存作为CPU和外设之间的桥梁,既解决了速度不匹配的问题,又保证了系统的性价比,是现代计算机系统不可或缺的核心组件。
四、总结与思考
GDB调试技巧总结
通过今天的学习,我们掌握了GDB的多种高级调试技巧:
- 断点管理: 创建、删除、使能、禁用断点,理解断点编号的机制
- 单步调试: next(逐过程)和step(逐语句)的区别和应用场景
- 范围执行: continue、finish、until三个命令的灵活运用
- 变量监视: display长显示、print表达式求值、info locals查看局部变量
- 高级技巧: watch监视变量变化、set var动态修改变量、条件断点精准定位
调试的核心思想是:通过断点缩小问题范围,通过单步调试精确定位,通过变量监视观察状态变化,最终找到并解决问题。
冯诺依曼体系结构的核心思想
冯诺依曼体系结构的精髓在于:
- 五大部件: 输入设备、输出设备、CPU(运算器+控制器)、内存
- 数据流动: 所有数据必须通过内存中转,CPU不直接与外设交互
- 存储分级: 通过不同速度的存储设备,在性能和成本之间找到平衡
- 程序预加载: 程序必须先载入内存,CPU才能执行
写在最后
作为一名程序员,我们不仅要掌握编程语言的语法,更要理解计算机底层的工作原理。只有深入理解冯诺依曼体系结构,才能真正明白程序是如何运行的;只有熟练掌握GDB调试技巧,才能高效地定位和解决问题。
希望这篇文章能够帮助大家更好地理解Linux系统编程的核心概念。如果在学习过程中有任何问题,欢迎在评论区留言讨论。让我们一起在技术的道路上不断前行!