note
- Qwen3-VL模型,提供稠密型(2B/4B/8B/32B)和混合专家型(30B-A3B/235B-A22B)两种变体。通过集成高质量的多元模态数据迭代和架构创新(如增强的交错MRoPE、DeepStack视觉-语言对齐和基于文本的时间对齐)
- 其原生支持256K token的交错序列,使其能够在长复杂文档、图像序列和视频上进行稳健的推理,特别适用于现实世界应用中高保真跨模态理解的需求。Qwen3-VL系列的密集和MoE变体确保了在不同延迟和质量要求下的灵活部署,后训练策略包括非思考模式和思考模式,进一步提升了模型的应用范围。
- 数据过滤方面,去除噪声、低对齐样本,确保数据质量与多样性。
- 模型架构方面,使用DeepStack 跨层融合,提取视觉编码器多中间层特征,通过轻量残差连接注入 LLM 对应层,强化视觉-语言对齐,保留从低级到高级的丰富视觉信息。
- Qwen3-VL创新:
- 采用SigLIP-2架构并继续动态分辨率训练,小规模模型(2B/4B)使用SigLIP2-Large(300M),默认使用SigLIP2-SO-400M变体
- 支持动态输入分辨率,同时使用2D-RoPE(相对位置编码)和可学习的绝对位置嵌入(根据输入尺寸插值),以支持动态分辨率
- 模态桥接部分从单层MLP,转变为多层独立Merger (DeepStack)
- 位置编码从标准RoPE/MRoPE,转变为Interleaved MRoPE
- 未来工作将集中于扩展Qwen3-VL的能力,以实现交互式感知、工具增强推理和实时多模态控制
文章目录
速读:Qwen3-VL
链接:https://arxiv.org/pdf/2511.21631
模型家族包含密集型(2B/4B/8B/32B)与混合专家(Mixture-of-Experts, MoE)两种架构(30B-A3B/235B-A22B),以适应不同延迟-质量权衡需求。
1、快速介绍
【多模态大模型进展】Qwen3-VL-4B/8B发布,Qwen3-VL系列小参数模型,共提供4B与8B两种参数规模,每种规模均发布Instruct与Thinking两个版本。https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
主要特点为模型原生上下文256K,可扩展至1M,支持小时级视频逐秒索引;新增Interleaved-MRoPE、DeepStack与Text--Timestamp Alignment三项结构改进,分别用于长视频时序建模、多尺度ViT特征融合和事件定位。OCR语种从19种增至32种,低光、模糊、倾斜场景下的鲁棒性提升,可解析古籍与专业术语。视觉Agent可直接操作PC与移动GUI,完成元素识别、工具调用与任务闭环;视觉编码增强功能可根据图像或视频生成Draw.io、HTML、CSS、JS代码;空间感知支持2D Grounding与3D Grounding,可判断物体位置、视角与遮挡关系。此外,NexaAI适配本地推理方案,通过NexaSDK提供GGUF、MLX、NexaML三种格式,支持在Apple Silicon、NVIDIA、Intel、AMD、Qualcomm NPU等,https://nexa.ai/blogs/qwen3vl
2、模型应用
这些 Cookbook 围绕真实场景设计,覆盖高精度文档解析、多语言自然场景 OCR、长视频理解、3D 物体定位、空间关系推理,以及面向移动端和计算机操作的智能体控制等核心能力,全面展现 Qwen3-VL 在复杂视觉语言任务中的强大表现。
🔗 链接: https://github.com/QwenLM/Qwen3-VL/tree/main/cookbooks
💬 体验地址:chat.qwen.ai (在模型列表选择Qwen3-VL系列模型)
🤖 模型链接:https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144b
⚙️ 百炼 API :https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
一、研究背景
- 研究问题:这篇文章要解决的问题是如何构建一个能力更强的视觉语言模型(VL模型),以在多模态基准测试中取得卓越的表现。具体来说,该模型需要支持高达256K token的交错上下文,无缝集成文本、图像和视频。
- 研究难点:该问题的研究难点包括:如何在保持文本理解能力的同时,增强长上下文理解能力;如何有效地进行跨模态推理;如何在多模态学习目标之间平衡文本和模态数据的贡献。
- 相关工作:该问题的研究相关工作包括早期的视觉语言模型(如CLIP和ALIGN)以及最近的多模态模型(如Llama系列和Gemini系列)。这些模型在视觉感知、长上下文理解和多模态推理方面取得了一定的进展,但在处理长视频和复杂任务时仍存在不足。
二、Qwen3-VL模型架构
相关模型列表:
Qwen3-VL 以三种密集型变体(Qwen3-VL-2B/4B/8B/32B)和两种 MoE(Mixture of Experts)变体(Qwen3-VL-30B-A3B、Qwen3-VL-235B-A22B)实现,均基于 Qwen3 Backbone 构建。旗舰模型 Qwen3-VL-235B-A22B 拥有总计 2350 亿参数,每 token 激活 220 亿参数。该模型在广泛的多模态任务中表现优于大多数视觉语言模型(Visual Language Model, VLM),并在多数语言基准测试中超越其纯文本对应模型。
1、增强的交错MRoPE位置编码
- 传统的MRoPE(在qwen2.5 vl中):
- 将嵌入维度划分为时间(t)、水平(h)和垂直(w)子空间,导致频谱不平衡。
- 交错MRoPE通过在低频和高频带中均匀分布t、h和w分量,解决了这一问题,
- 为了增强图像和视频的空间-时间建模能力,Qwen3-VL采用了交错MRoPE,作者采取如下优化方法:
- 将t、h、w分量在嵌入维度上交错分布
- 每个时空轴在低高频带均匀表示
- 显著改善长距离视频位置建模
具体为:
python
传统MRoPE (Qwen2-VL):
维度: [t,t,t,t, h,h,h,h, w,w,w,w] (分组排列)
└─低频─┘ └─中频─┘ └─高频─┘
问题: t只在低频,w只在高频 → 谱不平衡
Qwen3-VL Interleaved MRoPE:
维度: [t,h,w,t, h,w,t,h, w,t,h,w] (交错排列)
└── 每个轴均匀分布所有频段 ──┘2、视觉编码器
作者采用 SigLIP-2 架构作为视觉编码器,并基于官方预训练预训练权重进行初始化,继续以动态输入分辨率进行训练。为有效适应动态分辨率,作者采用 2D-RoPE(Rotary Position Embedding),并根据输入尺寸对绝对位置嵌入进行插值,遵循 CoMP的方法。具体而言,作者默认使用 SigLIP2-SO-400M 变体,并在小规模 LLM(2B 和 4B)中采用 SigLIP2-Large(300M)。
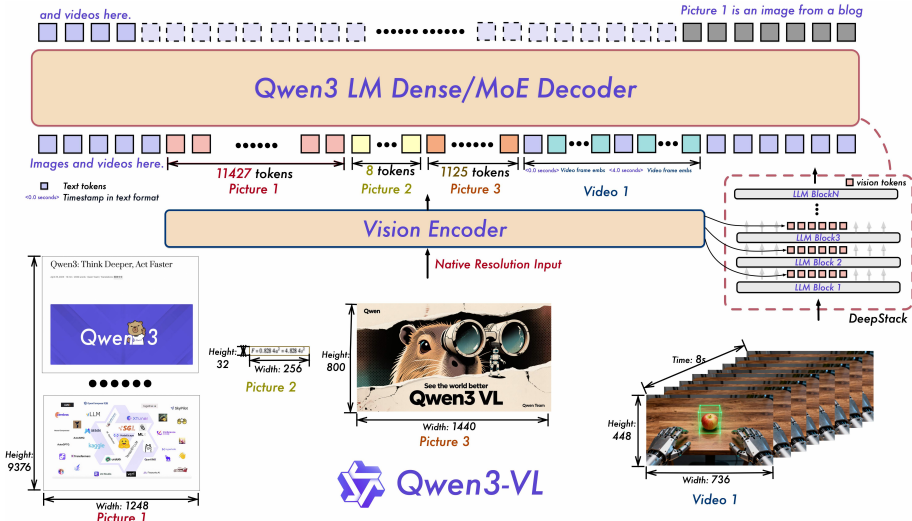
3、显式视频时间戳
- 在Qwen2.5-VL中,采用了一种时间同步的 MRoPE 变体,以赋予模型时间感知能力。然而,作者发现该方法存在两个关键局限性:
- 通过将时间位置 ID 直接绑定到绝对时间,该方法在处理长视频时会产生过大且Sparse的时间位置 ID,从而削弱模型对长时序上下文的理解能力。
- 在该方案下实现有效学习需要在多种帧率(fps)下进行广泛且均匀的采样,显著增加了训练数据构建的成本。
- 显式视频时间戳:
- 为了更有效地表示时间信息,Qwen3-VL采用了基于文本的时间戳,而不是绝对时间对齐。
- 每个视频时间片段都带有格式化的文本字符串(例如,
<3.0秒>),并在训练中使用秒和HMS格式生成时间戳,以确保模型能够有效学习和解释多样的时间码表示。
| Qwen2.5-VL | Qwen3-VL | |
|---|---|---|
| 方案 | T-RoPE (绝对时间位置编码) | 文本时间戳 (Text-based Timestamp) |
| 实现方式 | 通过MRoPE位置编码直接嵌入绝对时间信息 | 用格式化文本字符串如 <3.0 seconds> 作为token输入 |
| 状态 | ❌ 被弃用 | ✅ 当前qwen3 vl采用 |
4、视觉-语言融合:DeepStack集成
- DeepStack集成:为了加强视觉-语言对齐,Qwen3-VL引入了DeepStack机制。该机制通过将视觉编码器的不同层的视觉标记通过轻量级残差连接路由到相应的LLM层,增强了多级融合,而不会引入额外的上下文长度。
- 作者受到DeepStack的启发,将视觉 Token (visual tokens)注入到大语言模型(LLM)的多个层级中。与原始的DeepStack方法不同,后者将多尺度视觉输入的 Token 进行堆叠,作者将其扩展为从视觉Transformer(Vision Transformer, ViT)的中间层提取视觉 Token 。这种设计能够保留从Low-Level到High-Level的丰富视觉信息。
- 具体而言,如图1所示,作者从视觉编码器的三个不同层级中选取特征。随后,专用的视觉-语言融合模块将这些多层级特征投影为视觉 Token (visual tokens),并直接添加到前三个大语言模型(LLM)层的对应隐藏状态中。
动作:
python
视觉编码器层1 ──→ Merger ──┐
视觉编码器层2 ──→ Merger ──┼→ 分别注入LLM的对应层
视觉编码器层3 ──→ Merger ──┘优势:
- 保留从低级到高级的多层次视觉信息
- 通过残差连接,不增加序列长度
- 增强细粒度视觉理解 (InfoVQA +2.3, DocVQA +1.6)
相关对比:
| 特性 | 说明 |
|---|---|
| 每个Merger的结构 | 仍然是 2层MLP(与Qwen2.5-VL相同) |
| Merger数量 | 3个(对应选取的3个ViT层) |
| 输出到哪里 | 分别加到LLM的第1/2/3层的hidden states(通过残差连接) |
5、其他
作者从每样本损失(per-sample loss)转向平方根归一化的每 token 损失(square-root-normalized per-token loss),该方法在训练过程中能更好地平衡文本与多模态数据的贡献。
三、模型训练
- 数据收集:Qwen3-VL的训练数据集包括高质量的图像-字幕对、交错文本-图像序列、知识世界数据、OCR数据、文档解析数据和长文档理解数据。具体来说,图像-字幕对来自网络资源,交错文本-图像序列来自中国和其他英语网站,知识世界数据涵盖了超过12个语义类别,OCR数据包括3000万个内部收集的样本,文档解析数据包括300万个PDF文件,长文档理解数据包括合成和实际的长文档数据。
- 预训练阶段:预训练分为四个阶段:初始对齐阶段、多模态预训练阶段、长上下文预训练阶段和超长短上下文适应阶段。每个阶段的训练目标和数据混合比例有所不同,以确保模型逐步建立从基本对齐到长上下文理解的能力。
- S0阶段:仅训练MLP融合层,实现视觉-语言基础对齐
- S1阶段:全参数多模态预训练,序列长度8K
- S2阶段:长上下文预训练,序列长度扩展至32K
- S3阶段:超长上下文适应,支持256K令牌上下文窗口
- 后训练阶段包括三个阶段:
- 长链式思维数据的有监督微调、
- 从更强教师模型的知识蒸馏
- 强化学习
- 每个阶段的数据和方法都有所不同,以提高模型的指令遵循能力、推理能力和与人类偏好的对齐。
预训练阶段的具体信息:
python
Stage 0: 视觉-语言对齐 (Vision-Language Alignment)
├── 仅训练MLP merger
├── 视觉编码器和LLM冻结
├── 67B tokens, 8K序列长度
└── 数据: 高质量图像-标题对、OCR数据
Stage 1: 多模态预训练 (Multimodal Pre-Training)
├── 全参数训练
├── ~1T tokens, 8K序列长度
├── 混合VL数据 + 纯文本数据
└── 新增: 交错图文、视觉定位、STEM、视频
Stage 2: 长上下文预训练 (Long-Context)
├── ~1T tokens, 32K序列长度
├── 增加纯文本比例(长文本理解)
└── 大量视频和agent数据
Stage 3: 超长上下文适应 (Ultra-Long-Context)
├── 100B tokens, 262K序列长度
└── 专注: 长视频、长文档理解对应的数据构成:
| 数据类型 | 关键改进 |
|---|---|
| 图像标题 | 用Qwen2.5-VL-32B重新生成高质量描述,语义去重 |
| 交错图文 | 支持长达256K tokens的书籍级文档 |
| OCR | 扩展至39种语言 (Qwen2.5-VL仅10种) |
| 文档解析 | QwenVL-HTML/Markdown双格式,支持复杂布局 |
| grounding | 归一化坐标0,1000,支持2D/3D定位、计数 |
| 空间理解 | 关系推理、 affordance、动作规划 |
| 代码 | UI→HTML/CSS、图像→SVG、视觉编程 |
| 视频 | 时间戳交错描述、时空定位、长度自适应采样 |
| STEM | 6000万K-12/大学题目,1200万长CoT推理 |
| Agent | GUI感知+决策、函数调用、搜索能力 |
四、模型评测分析
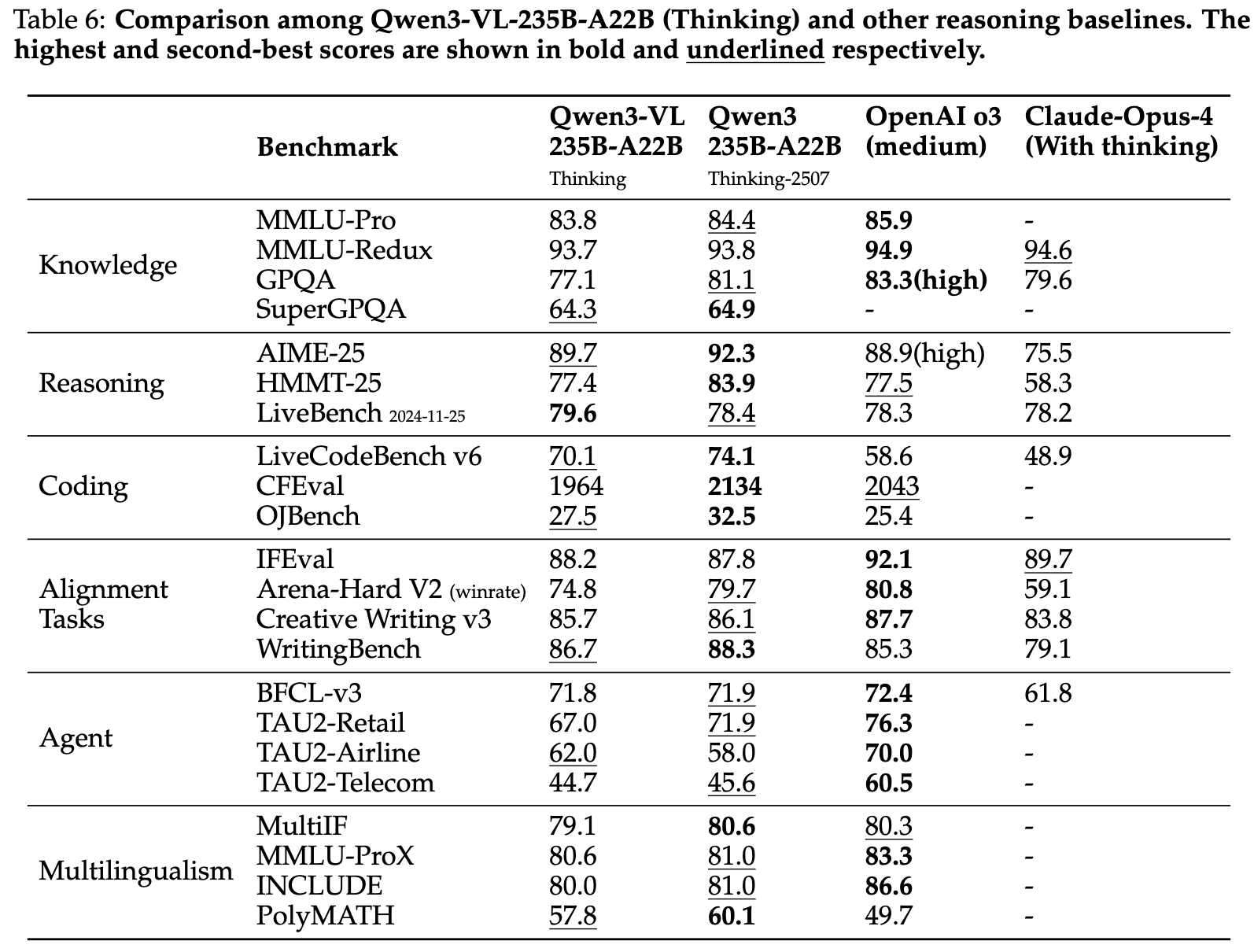
qwen3-VL-235B-A22B模型和主流多模态图生文模型的效果对比:
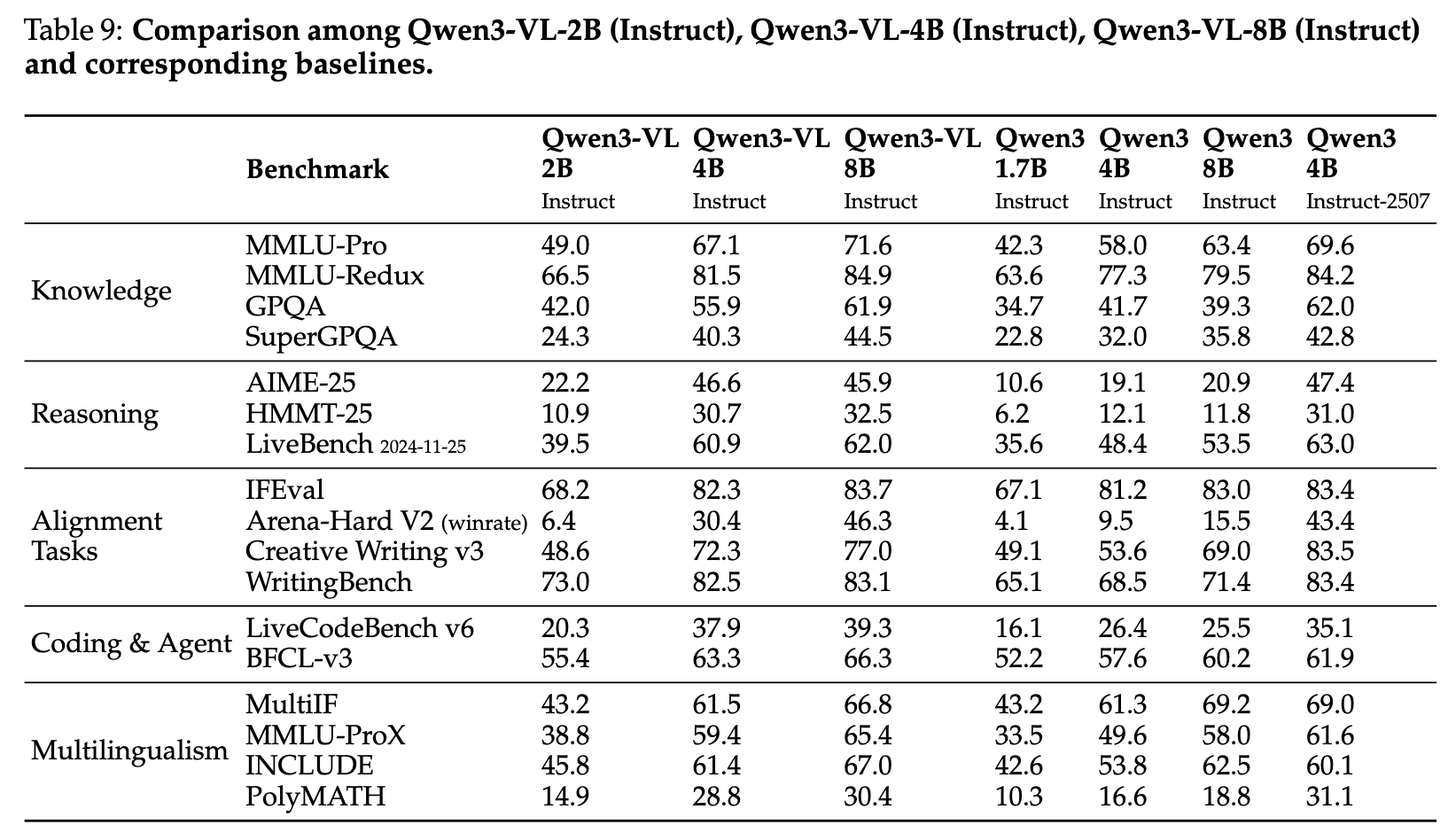
对于几个小参数的qwen3 vl模型,效果比a22b模型差,也是能理解的,毕竟参数量摆在这里:
一般视觉问答:在MMBench-V1.1、RealWorldQA、MMStar和SimpleVQA等基准测试中,Qwen3-VL系列模型展示了强大的性能。特别是在大模型(如Qwen3-VL-235B-A22B)中,Qwen3-VL-235B-A22B-Thinking在MMStar上取得了78.7分的高分,接近Gemini-2.5-Pro的79.5分。
多模态推理:在MMMU、MathVision、MathVision-Wildphoto、MathVista等STEM相关任务和视觉谜题任务中,Qwen3-VL系列模型表现出色。特别是Qwen3-VL-235B-A22B-Instruct在多个基准测试中取得了最佳或次优成绩。
对齐和主观任务:在MM-MT-Bench、HallusionBench和MIA-Bench等基准测试中,Qwen3-VL系列模型显著优于其他闭源模型。特别是在HallusionBench上,Qwen3-VL-235B-A22B-Thinking比Gemini-2.5-Pro高出6.3分。
文本识别和文档理解:在OCR解析、文档问答和文档推理等基准测试中,Qwen3-VL系列模型也表现出色。特别是在OCR相关的VQA基准测试中,Qwen3-VL-235B-A22B-Instruct和Qwen3-VL-235B-A22B-Thinking在所有任务中都取得了强有力的一致性结果。
2D和3D定位:在RefCOCO、CountBench和ODinW-13等2D和3D定位基准测试中,Qwen3-VL系列模型展示了卓越的性能。特别是Qwen3-VL-235B-A22B在ODinW-13上取得了48.6 mAP的高分,表明其在多目标开放词汇对象定位中的强大能力。
细粒度感知:在V*、HRBench-4K和HRBench-8K等细粒度感知基准测试中,Qwen3-VL系列模型相比其前身Qwen2.5-VL-72B有显著提升,特别是在集成外部工具后,性能提升显著。
多图像理解:在BLINK和MuirBench等多图像理解基准测试中,Qwen3-VL系列模型展示了整体优越性,特别是在MuirBench上,Qwen3-VL-235B-A22B-Thinking取得了80.1分的高分,超过了所有其他模型。
具身和空间理解:在ERQA、VSIBench和EmbSpatial等具身和空间理解基准测试中,Qwen3-VL系列模型展示了与顶级模型相媲美的能力,特别是在EmbSpatial上,Qwen3-VL-235B-A22B取得了84.3分的高分。
视频理解:在VideoMME、MVBench、VideoMMMU等视频理解基准测试中,Qwen3-VL系列模型展示了显著的改进,特别是在集成交错MRoPE、文本时间戳和大规模时间密集视频字幕后,Qwen3-VL-8B的性能与显著更大的Qwen2.5-VL-72B模型相当。
参考:
1、评测ToolCall任务benchmark的prompt:
python
Your role is that of a research assistant specializing in visual information. Answer questions about images by looking at them closely and then using research tools. Please follow this structured thinking process and show your work.
Start an iterative loop for each question:
- **First, look closely:** Begin with a detailed description of the image, paying attention to the user's question. List what you can tell just by looking, and what you'll need to look up.
- **Next, find information:** Use a tool to research the things you need to find out.
- **Then, review the findings:** Carefully analyze what the tool tells you and decide on your next action.
Continue this loop until your research is complete.
To finish, bring everything together in a clear, synthesized answer that fully responds to the user's question.
#Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{ "type":"function", "function": {"name": "image_zoom_in_tool", "description": "Zoom in on a specific region of an image by cropping it based on a bounding box (bbox) and an optional object label", "arguments": {"type": "object", "properties": {"bbox_2d": {"type": "array", "items": {"type": "number"}, "minItems": 4, "maxItems": 4, "description": "The bounding box of the region to zoom in, as [x1, y1, x2, y2], where (x1, y1) is the top-left corner and (x2, y2) is the bottom-right corner"}, "label": {"type": "string", "description": "The name or label of the object in the specified bounding box"}, "img_idx": {"type": "number", "description": "The index of the zoomed-in image (starting from 0)"}}, "required": ["bbox_2d", "label", "img_idx"]}}}
</tools>
For each function call, return a JSON object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
<image>
{question}2、评测HRBench4K benchmark(Visual Grounding任务,需要选出图中对应的Bounding Box,即bbox)的prompt:
python
Your role is that of a research assistant specializing in visual information. Answer questions about images by looking at them closely and then using research tools. Please follow this structured thinking process and show your work.
Start an iterative loop for each question:
- **First, look closely:** Begin with a detailed description of the image, paying attention to the user's question. List what you can tell just by looking, and what you'll need to look up.
- **Next, find information:** Use a tool to research the things you need to find out.
- **Then, review the findings:** Carefully analyze what the tool tells you and decide on your next action.
Continue this loop until your research is complete.
To finish, bring everything together in a clear, synthesized answer that fully responds to the user's question.
#Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{ "type":"function", "function": {"name": "image_zoom_in_tool", "description": "Zoom in on a specific region of an image by cropping it based on a bounding box (bbox) and an optional object label", "arguments": {"type": "object", "properties": {"bbox_2d": {"type": "array", "items": {"type": "number"}, "minItems": 4, "maxItems": 4, "description": "The bounding box of the region to zoom in, as [x1, y1, x2, y2], where (x1, y1) is the top-left corner and (x2, y2) is the bottom-right corner"}, "label": {"type": "string", "description": "The name or label of the object in the specified bounding box"}, "img_idx": {"type": "number", "description": "The index of the zoomed-in image (starting from 0)"}}, "required": ["bbox_2d", "label", "img_idx"]}}}
</tools>
For each function call, return a JSON object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
<image>
{question}
{options}Reference
1 https://nexa.ai/blogs/qwen3vl