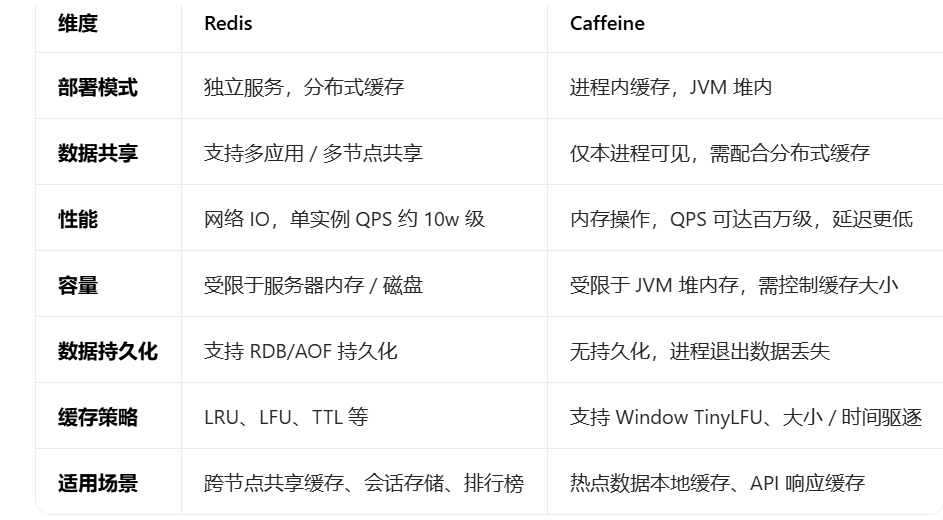
一、Redis vs Caffeine 核心对比
二、Caffeine 核心原理与参数设置
核心原理
Caffeine 基于 Window TinyLFU 算法,结合了访问频率和时间因素,比传统 LRU 更高效地识别热点数据。其内部采用分段锁和无锁队列,大幅提升并发性能。
关键参数设置
maximumSize:缓存最大条目数,防止内存溢出。expireAfterWrite:写入后固定时间过期,适合时效性强的数据。expireAfterAccess:最后一次访问后固定时间过期,适合冷数据自动清理。refreshAfterWrite:后台异步刷新缓存,避免缓存击穿。recordStats:开启统计功能,用于监控命中率、加载时间等指标。
Window TinyLFU 算法:
Window Tiny Least Frequently Used ,是Caffeine 缓存 的核心淘汰算法,融合LRU+LFU 优势,兼顾访问频率 与时效性,解决 LRU 缓存污染、LFU 冷启动 / 僵化问题。
总缓存 = Window Cache(1%) + Main Cache(99%) ,配合TinyLFU 频率统计。
1. Window Cache(窗口缓存,LRU)
- 容量:总容量1%,纯 LRU 管理
- 作用:过滤新数据、抗扫描攻击,避免低频突发流量污染主缓存
- 流程:新数据→Window;满时按 LRU 淘汰尾部,候选进入主缓存
2. Main Cache(主缓存,SLRU)
- 分两段:Protected(80%) + Probation(20%)
- Probation:刚进入、访问 1 次的 "试用区"
- Protected:访问≥2 次的 "保护区",更难被淘汰
- 淘汰规则:满时先从 Probation 淘汰;再从 Protected 尾部淘汰
3. TinyLFU 频率统计(Count-Min Sketch)
- 用概率数据结构 近似统计访问频率,4-8 位计数器(传统 LFU 需 32 位)
- 多哈希映射,取最小值避免冲突高估
- 带时间衰减:旧频率自动衰减,防止历史高频数据僵化
完整工作流程(get/put)
1. 访问(get)
- 先查 Window Cache:命中→移到 Window 头部,频率 + 1
- 未命中→查 Main Cache:
- 命中 Probation→移到 Protected 头部,频率 + 1
- 命中 Protected→移到 Protected 头部,频率 + 1
- 都未命中→返回未命中,准备加载
2. 写入 / 加载(put)
- 新数据→写入 Window Cache(LRU 头部)
- Window 满→淘汰尾部候选,与 Main Probation 尾部按频率 PK
- 候选频率更高→替换进入 Probation,原数据淘汰
- 否则→候选直接淘汰
- Main 满→先淘汰 Probation 尾部;再淘汰 Protected 尾部
关键优势
- ✅ 抗缓存污染:Window 过滤低频突发,保护主缓存热点
- ✅ 冷热兼顾:新热点快速升温,旧高频自动衰减
- ✅ 低内存开销:TinyLFU 仅用极小空间统计频率
- ✅ 高命中率:比 LRU/LFU 在真实场景命中率更高
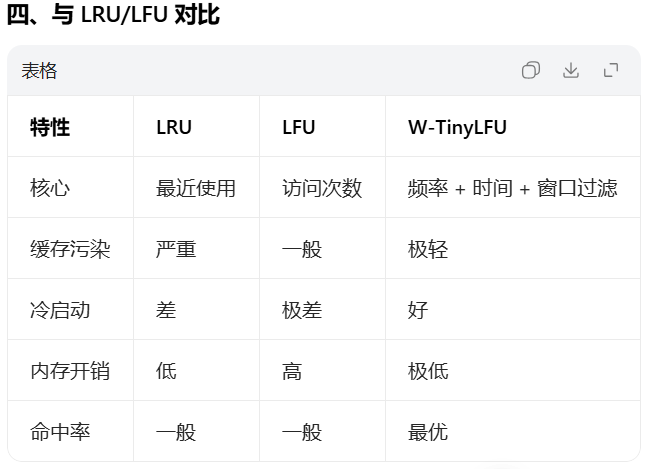
全新数据先进 1% 的 Window LRU,Window 满了淘汰尾部候选,和 Main Probation 尾部比频率(高则进 Main);Main 分 Probation(试用)和 Protected(保护),Probation 数据再访问就升级到 Protected,全程用 TinyLFU 统计频率做淘汰 PK,既防缓存污染又兼顾冷热数据。
- 新数据 A → 进 Window 头部;
- 访问 A → Window 头部,频率 + 1;
- Window 满,淘汰尾部 B → B 和 Main Probation 尾部 C PK;
- B 频率>C → B 进 Probation,C 淘汰;
- 访问 B → B 升级到 Protected 头部;
- 再访问 B → 只移到 Protected 头部,不回 Window;
- Main 满 → 先删 Probation 尾部,再删 Protected 尾部。
- Window 内数据访问:移头部 + 频率 + 1(不挪窝,等淘汰 PK);
- Main Probation 访问:升 Protected + 移头部 + 频率 + 1;
- Main Protected 访问:移头部 + 频率 + 1;
- 全新数据:进 Window 头部。
三、JDK 线程池工作流程
- 任务提交 :调用
execute()或submit()提交任务。 - 核心线程处理:如果核心线程数未满,创建新的核心线程执行任务。
- 队列缓冲:如果核心线程已满,任务进入阻塞队列等待。
- 非核心线程创建:如果队列已满,且当前线程数小于最大线程数,创建新的非核心线程执行任务。
- 拒绝策略:如果队列和线程池均已满,触发拒绝策略(如 AbortPolicy、CallerRunsPolicy 等)。
四、MySQL 建表建索引的考量点
-
业务查询模式
- 优先为
WHERE、JOIN、ORDER BY中的高频字段建立索引。 - 避免为低选择性(如性别、状态)的字段建立单列索引。
- 优先为
-
索引类型选择
- 主键索引:每张表必须有,通常使用自增 ID,保证插入性能。
- 唯一索引:用于保证字段值的唯一性,如用户手机号、邮箱。
- 普通索引:用于加速查询,如商品分类、创建时间。
- 联合索引:遵循 "最左前缀原则",将查询频率高的字段放在左侧。
-
性能与维护成本
- 索引会增加写入(INSERT/UPDATE/DELETE)的开销,需权衡读写比例。
- 避免创建过多冗余索引,定期使用
EXPLAIN分析慢查询,优化索引。 - 大表可考虑分区表或分库分表,而非单纯依赖索引。
-
数据分布与更新频率
- 频繁更新的字段不适合作为索引,会导致频繁的索引页分裂。
- 对于范围查询(如
BETWEEN、>),联合索引的最后一个字段应是范围字段。
- 在 MySQL 的
EXPLAIN结果中,partitions列表示查询命中的表分区 - 如果值为
<null>,说明这张表没有使用分区表,或者查询不需要扫描任何分区。 - 如果表是分区表(如按时间、范围分区),这里会列出查询实际访问的分区名称,帮助你判断是否只扫描了必要分区,避免全表扫描。
filtered 是一个百分比值,表示在存储引擎返回的行中,有多少比例的数据被服务层(Server 层)的条件过滤掉了。
- 公式:
filtered = (服务层过滤后剩余行数 / 存储引擎返回行数) × 100% - 你的截图中
filtered = 100,表示:- 存储引擎返回的所有行,都满足了
WHERE条件,没有被服务层过滤掉。 - 这是一个理想情况,说明查询条件高效,没有浪费资源在无效数据上。
- 存储引擎返回的所有行,都满足了
- 如果
filtered很低(比如 1%),说明存储引擎返回了大量数据,但大部分都被服务层过滤掉了,这意味着索引可能不够高效,需要优化。