并发工具类
43 CountDownLatch 了解吗?
CountDownLatch是JUC中的一个同步工具类,用于协调多个线程的同步,确保主线程在多个子线程完成任务后继续执行。
核心思想:通过一个倒计时计数器来控制多个线程的执行顺序。
java
class CountDownLatchExample {
public static void main(String[] args) throws InterruptedException {
int threadCount = 3;
CountDownLatch latch = new CountDownLatch(threadCount); // 设置计时器
for (int i = 0; i < threadCount; i++) { // 3个线程
new Thread(() -> {
try {
Thread.sleep((long) (Math.random() * 1000)); // 模拟任务执行
System.out.println(Thread.currentThread().getName() + " 执行完毕");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
latch.countDown(); // 线程完成后,计数器 -1
}
}).start();
}
latch.await(); // 主线程等待
System.out.println("所有子线程执行完毕,主线程继续执行");
}
}- 在使用的时候,我们需要先初始化一个 CountDownLatch 对象,指定一个计数器的初始值,表示需要等待的线程数量。
- 然后在每个子线程执行完任务后,调用
countDown()方法,计数器减 1。 - 接着主线程调用
await()方法进入阻塞状态,直到计数器为 0,也就是所有子线程都执行完任务后,主线程才会继续执行。
(1)场景题:假如要查10万多条数据,用线程池分成20个线程去执行,怎么做到等所有的线程都查找完之后,即最后一条结果查找结束了,才输出结果?
分析场景:就是需要20条子线程与主线程同步,先20条子线程同时运行完毕后,再主线程启动输出。
这非常适合CountDownLatch,使用如下:
- 第一步,创建 CountDownLatch 对象,初始值设定为 20,表示 20 个线程需要完成任务。
- 第二步,创建线程池,每个线程执行查询操作,查询完毕后调用
countDown()方法,计数器减 1。 - 第三步,主线程调用
await()方法,等待所有线程执行完毕。
java
class DataQueryExample {
public static void main(String[] args) throws InterruptedException {
// 模拟10万条数据
int totalRecords = 100000;
int threadCount = 20;
int batchSize = totalRecords / threadCount; // 每个线程处理的数据量
// 创建线程池
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
CountDownLatch latch = new CountDownLatch(threadCount);
// 模拟查询结果
ConcurrentLinkedQueue<String> results = new ConcurrentLinkedQueue<>();
for (int i = 0; i < threadCount; i++) {
int start = i * batchSize;
int end = (i == threadCount - 1) ? totalRecords : (start + batchSize);
executor.execute(() -> {
try {
// 模拟查询操作
for (int j = start; j < end; j++) {
results.add("Data-" + j);
}
System.out.println(Thread.currentThread().getName() + " 处理数据 " + start + " - " + end);
} finally {
latch.countDown(); // 线程任务完成,计数器减1
}
});
}
// 等待所有线程完成
latch.await();
executor.shutdown();
// 输出结果
System.out.println("所有线程执行完毕,查询结果总数:" + results.size());
}
}
java
// 结果:
5000
pool-1-thread-6 处理数据 25000 - 30000
pool-1-thread-9 处理数据 40000 - 45000
pool-1-thread-14 处理数据 65000 - 70000
pool-1-thread-13 处理数据 60000 - 65000
pool-1-thread-12 处理数据 55000 - 60000
pool-1-thread-8 处理数据 35000 - 40000
pool-1-thread-15 处理数据 70000 - 75000
pool-1-thread-11 处理数据 50000 - 55000
pool-1-thread-10 处理数据 45000 - 50000
pool-1-thread-5 处理数据 20000 - 25000
pool-1-thread-2 处理数据 5000 - 10000
pool-1-thread-4 处理数据 15000 - 20000
pool-1-thread-1 处理数据 0 - 5000
pool-1-thread-7 处理数据 30000 - 35000
pool-1-thread-19 处理数据 90000 - 95000
pool-1-thread-3 处理数据 10000 - 15000
pool-1-thread-20 处理数据 95000 - 100000
pool-1-thread-17 处理数据 80000 - 85000
pool-1-thread-16 处理数据 75000 - 80000
pool-1-thread-18 处理数据 85000 - 90000
所有线程执行完毕,查询结果总数:100000
多线程耗时: 51 ms44 CyclicBarrier 了解吗?
循环栅栏CyclicBarrier,也是 Java 并发包 (java.util.concurrent) 中的一个同步工具类。
它的核心作用是:让一组线程到达一个屏障(Barrier)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
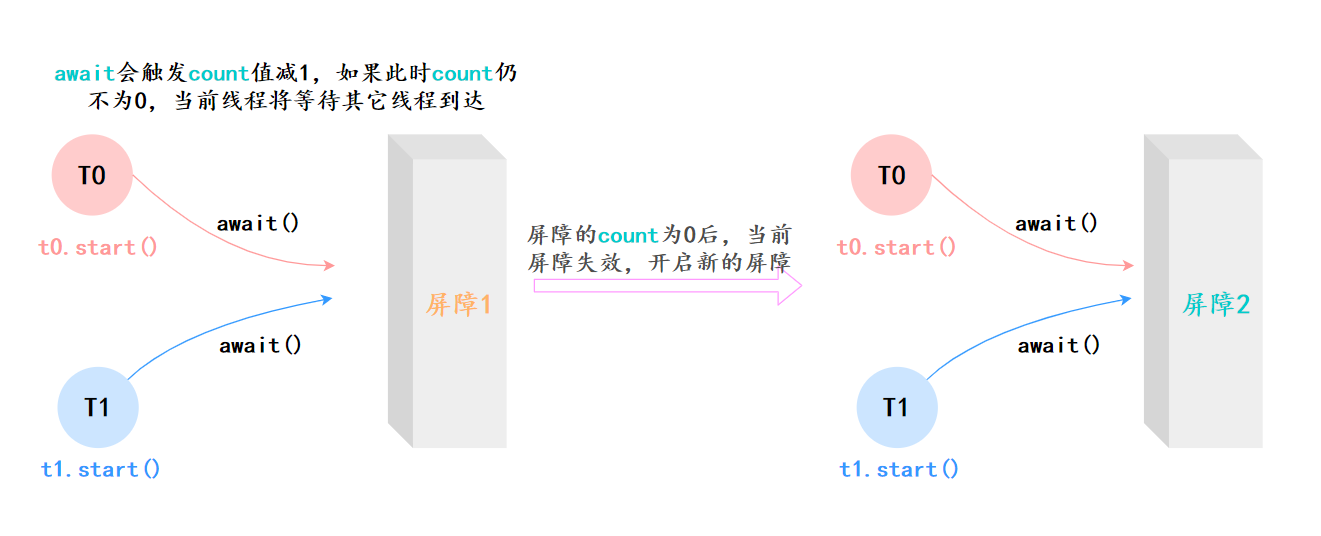
在使用的时候,我们需要先初始化一个 CyclicBarrier 对象,指定一个屏障值 N,表示需要等待的线程数量。
然后每个线程执行 await() 方法,表示自己已经到达屏障,等待其他线程,此时屏障值会减 1。
当所有线程都到达屏障后,也就是屏障值为 0 时,所有线程会继续执行。
java
public class CyclicBarrierDemo {
public static final int THREAD_COUNT = 3;
public static final CyclicBarrier barrier = new CyclicBarrier(THREAD_COUNT);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName()+"-到达屏障");
// 线程到达屏障等待
barrier.await();
System.out.println(Thread.currentThread().getName()+"-继续运行");
} catch (InterruptedException | BrokenBarrierException exception) {
exception.printStackTrace();
}
}).start();
}
}
}
java
// 结果
Thread-0-到达屏障
Thread-2-到达屏障
Thread-1-到达屏障
Thread-1-继续运行
Thread-0-继续运行
Thread-2-继续运行45 CyclicBarrier 和 CountDownLatch 有什么区别?
一个是所有线程相互等待,是几个并发线程之间的同步;另一个是子线程和主线程之间的同步。CyclicBarrier 让所有线程相互等待,全部到达后再继续;CountDownLatch 让主线程等待所有子线程执行完再继续。
| 对比项 | CyclicBarrier | CountDownLatch |
|---|---|---|
| 主要用途 | 让所有线程相互等待,全部到达后再继续 | 让主线程等待所有子线程执行完 |
| 可重用性 | ✅ 可重复使用,每次屏障打开后自动重置 | ❌ 不可重复使用,计数器归零后不能恢复 |
| 是否可执行回调 | ✅ 可以,所有线程到达屏障后可执行 barrierAction | ❌ 不能 |
| 线程等待情况 | 所有线程互相等待,一个线程未到达,其他线程都会阻塞 | 主线程等待所有子线程完成,子线程执行完后可继续运行 |
| 适用场景 | 线程相互依赖,需要同步执行 | 主线程等待子线程完成 |
| 示例场景 | 计算任务拆分,所有线程都到达后才能继续 | 主线程等多个任务初始化完成 |
46 Semaphore了解吗?
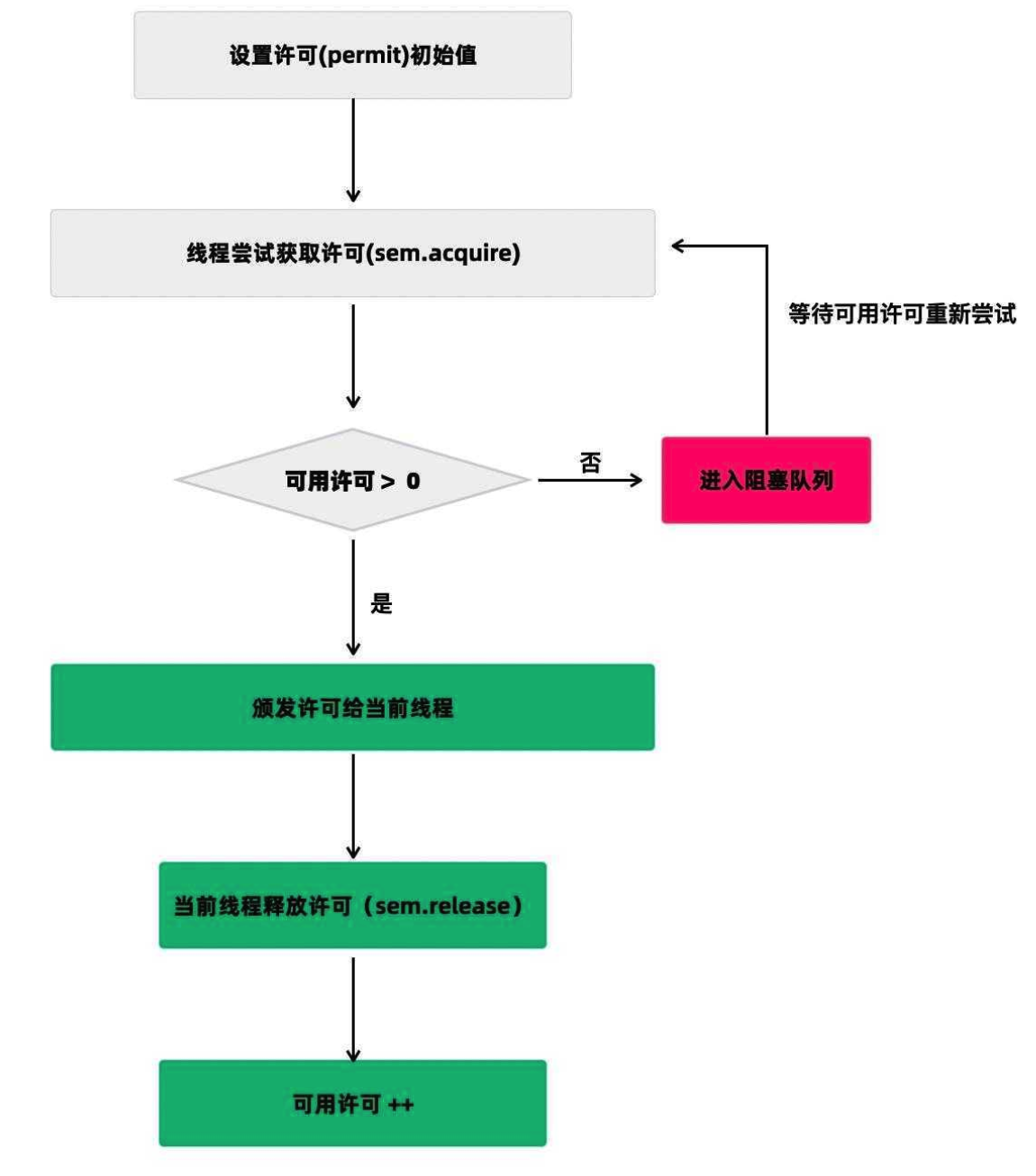
Semaphora(信号量), 用于控制同时访问某个资源的线程数量,类似限流器,确保最多只有指定数量的线程能够访问某个资源,超过的必须等待。(流量控制)
拿停车场来举例。
停车场的车位是有限的,如果有空位,显示牌需要显示剩余的车位,车辆就可以驶入;否则就会显示数字 0,新来的车辆就得排队等待。如果有车离开,显示牌重新显示闲置的车位数量,等待的车辆按序驶入停车场。
使用示例:
在使用 Semaphore 时,首先需要初始化一个 Semaphore 对象,指定许可证数量,表示最多允许多少个线程同时访问资源。
获取acquire():然后在每个线程访问资源前,调用 acquire() 方法获取许可证,如果没有可用许可证,则阻塞等待。
释放release():访问完资源后,要调用 release() 方法释放许可证。
java
class SemaphoreExample {
private static final int THREAD_COUNT = 5;
private static final Semaphore semaphore = new Semaphore(2); // 最多允许 2 个线程访问
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
new Thread(() -> {
try {
semaphore.acquire(); // 获取许可(如果没有可用许可,则阻塞)
System.out.println(Thread.currentThread().getName() + " 访问资源...");
Thread.sleep(2000); // 模拟任务执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(); // 释放许可
}
}).start();
}
}
}结果:
java
Thread-2 访问资源...
Thread-1 访问资源...
Thread-0 访问资源...
Thread-4 访问资源...
Thread-3 访问资源...使用场景:用于流量控制,比如数据库连接池、网络连接池等。
假如有这样一个需求,要读取几万个文件的数据,因为都是 IO 密集型任务,我们可以启动几十个线程并发地读取。
**但是在读到内存后,需要存储到数据库,而数据库连接数是有限的,**比如说只有 10 个,那我们就必须控制线程的数量,保证同时只有 10 个线程在使用数据库连接。就可以使用 Semaphore 来做流量控制:
java
public class SemaphoraTest {
public static final int THREAD_COUNT = 30;
public static final ExecutorService executorService = Executors.newFixedThreadPool(THREAD_COUNT);
public static final Semaphore s = new Semaphore(10); // 数据库连接有限
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < THREAD_COUNT; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire(); // 获取信号量
System.out.println("save data");
}catch (InterruptedException e){
}finally {
s.release(); // 释放信号量
}
}
});
}
executorService.shutdown();
}
}47 Exchanger了解吗?
Exchanger------交换者,用于在两个线程之间进行数据交换。
使用:支持线程之间双向数据交换。
比如说线程 A 调用 exchange(dataA),线程 B 调用 exchange(dataB),它们会在同步点交换数据,即 A 得到 B 的数据,B 得到 A 的数据。
如果一个线程先调用 exchange(),它会阻塞等待,直到另一个线程也调用 exchange()。
使用 Exchanger 的时候,需要先创建一个 Exchanger 对象,然后在两个线程中调用 exchange() 方法,就可以进行数据交换了。
java
class ExchangerExample {
private static final Exchanger<String> exchanger = new Exchanger<>();
public static void main(String[] args) {
new Thread(() -> {
try {
String threadAData = "数据 A";
System.out.println("线程 A 交换前的数据:" + threadAData);
String received = exchanger.exchange(threadAData);
System.out.println("线程 A 收到的数据:" + received);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
String threadBData = "数据 B";
System.out.println("线程 B 交换前的数据:" + threadBData);
String received = exchanger.exchange(threadBData);
System.out.println("线程 B 收到的数据:" + received);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}使用场景:Exchanger 可以用于遗传算法,也可以用于校对工作,比如我们将纸制银行流水通过人工的方式录入到电子银行时,为了避免错误,可以录入两遍,然后通过 Exchanger 来校对两次录入的结果。
java
class ExchangerTest {
private static final Exchanger<String> exgr = new Exchanger<String>();
private static ExecutorService threadPool = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "银行流水A"; // A录入银行流水数据
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "银行流水B"; // B录入银行流水数据
String A = exgr.exchange("B");
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:"
+ A + ",B录入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}
}48 能说一下 ConcurrentHashMap 的实现吗?【*】
超级重点,ConcurrentHashMap是HashMap的线程安全版本,要回答好这个问题,必须分 JDK 1.7 和 JDK 1.8 两个版本来对比讲解,因为它们的实现原理发生了"翻天覆地"的变化。
JDK 1.7 使用"分段锁";JDK 1.8 使用"CAS + synchronized"
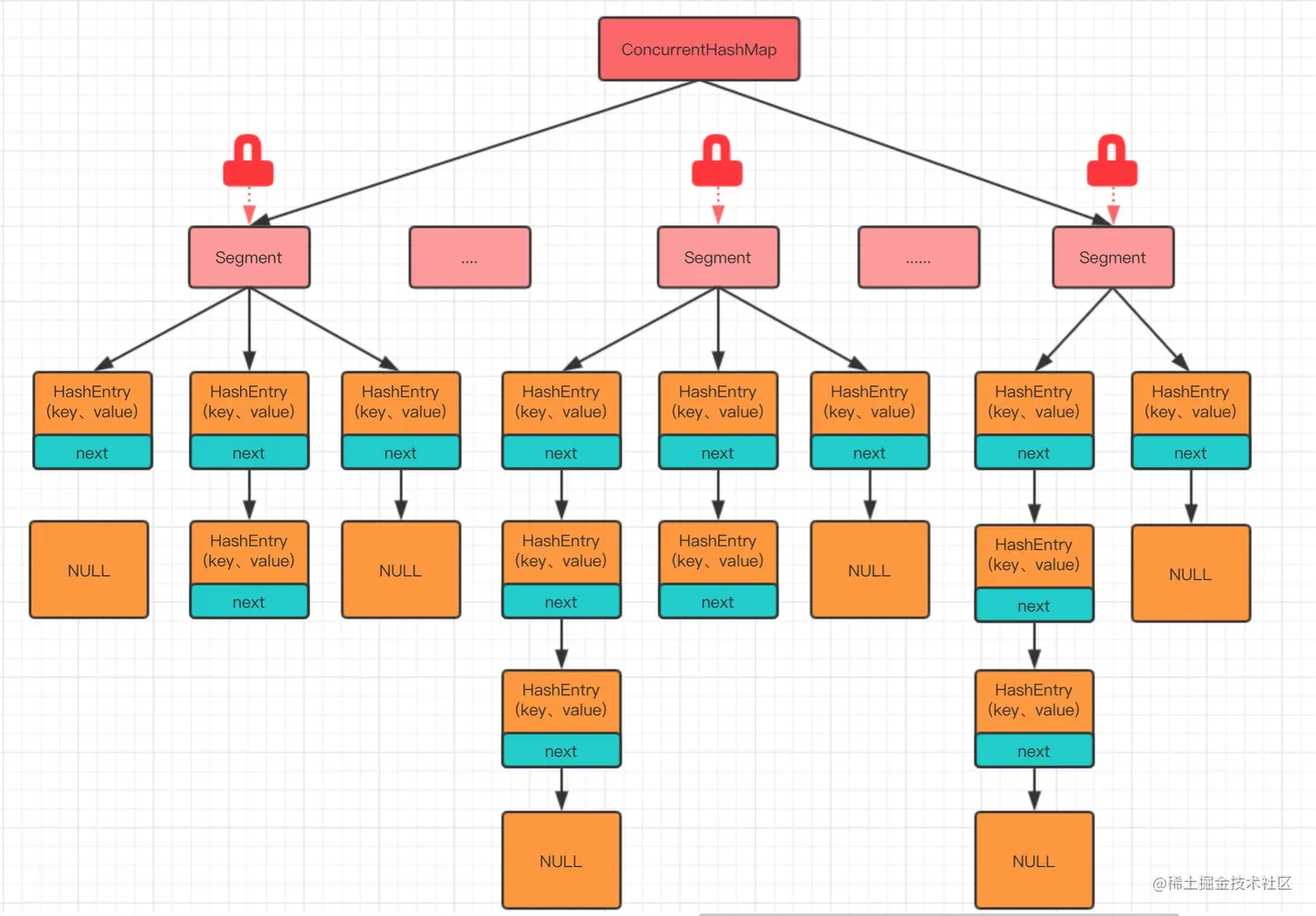
JDK1.7的实现:
JDK1.7采用的是分段锁,整个Map被分为若干段,每一个Segment独立加锁。不同的线程可以同时操作不同的段,从而实现并发。分段锁是使用的ReentrantLock(可重入锁)
默认情况下,Segment 数组的大小是 16 。这意味着理论上它支持 16 个线程并发写,只要它们的 Hash 值映射到了不同的 Segment 上。
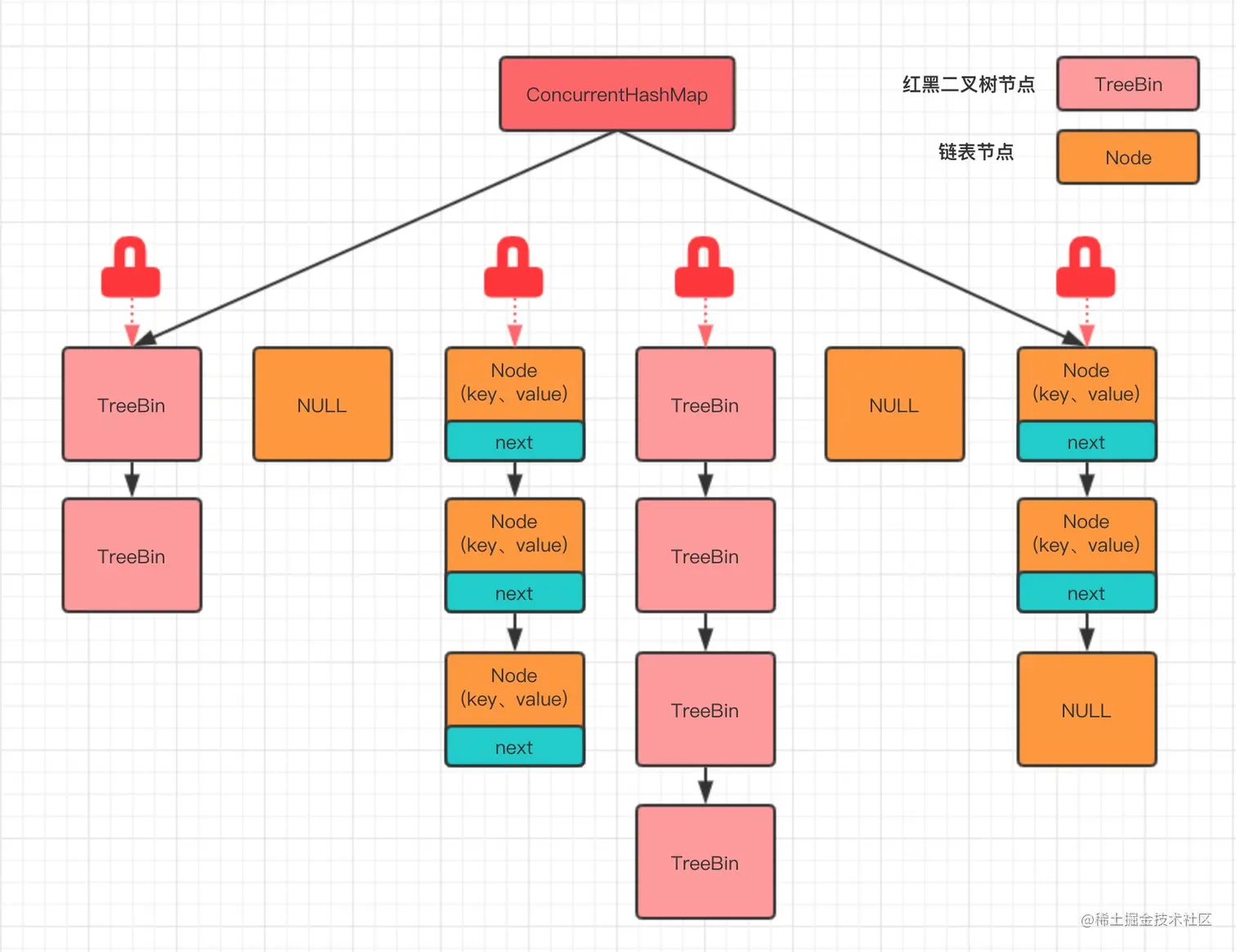
JDK1.8的实现:
JDK 1.8 彻底抛弃了 Segment 分段锁的概念,直接采用了 Node 数组 + 链表 + 红黑树 的结构(和 JDK 1.8 的 HashMap 结构一致),并发控制粒度更细。将锁细化到了每一个桶(数组的每一个槽),接着配合CAS和synchronized以最大程度减少锁的竞争。它的锁粒度更细,只锁数组的链表头节点。红黑树的根节点
读操作:ConcurrentHashMap 使用了 volatile 变量来保证内存可见性。
写操作:ConcurrentHashMap 优先使用 CAS 尝试插入,如果成功就直接返回;否则使用 synchronized 代码块进行加锁处理。
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment数组 + HashEntry数组 + 链表 | Node数组 + 链表 + 红黑树 |
| 锁的实现 | 分段锁 (ReentrantLock) | CAS + synchronized |
| 锁的粒度 | Segment (默认16个) | Node (数组槽位,随容量增加) |
| 并发度 | 受限于 Segment 个数 | 极高 (取决于数组长度) |
| Hash冲突 | 链表 (查询 O(n)) | 链表 / 红黑树 (查询 O(log n)) |
| Size计算 | 先尝试不加锁,失败则锁住所有 Segment | 使用 LongAdder 机制 (baseCount + CounterCell),高并发下性能极高 |
(1)说一下 JDK 7 中 ConcurrentHashMap 的实现原理?
采用分段锁,JDK 7 的 ConcurrentHashMap 采用的是分段锁,整个 Map 会被分为若干段,每个段都可以独立加锁,每个段类似一个 Hashtable。不同段之间不同线程可以同时操作
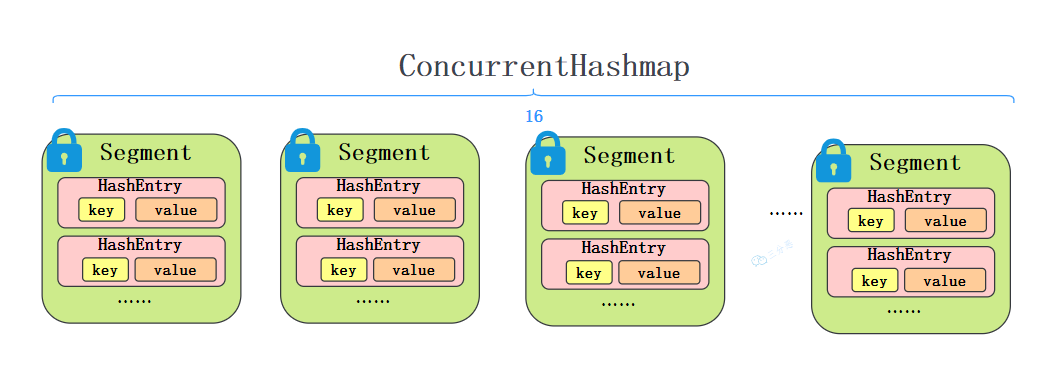
它由一个 Segment 数组组成。每个 Segment 本质上就是一把锁(继承自 ReentrantLock),同时它内部维护了一个 HashEntry 数组(类似于 HashMap)。
默认情况下,Segment 数组的大小是 16 。这意味着理论上它支持 16 个线程并发写,只要它们的 Hash 值映射到了不同的 Segment 上。
每个段维护一个键值对数组 HashEntry<K, V>[] table,HashEntry 是一个单项链表。
java
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
final HashEntry<K,V> next;
}段继承了 ReentrantLock,所以每个段都是一个可重入锁,不同的线程可以同时操作不同的段,从而实现并发。
java
static final class Segment<K,V> extends ReentrantLock {
transient volatile HashEntry<K,V>[] table;
transient int count;
}(2)说一下 JDK 7 中 ConcurrentHashMap 的 put 流程?
put的流程:
- 计算 key 的 hash 值。
- 根据 hash 值找到对应的 Segment。
- 获取该 Segment 的锁(ReentrantLock.lock())。
- 在 Segment 内部进行链表操作(插入/更新)。
- 释放锁。
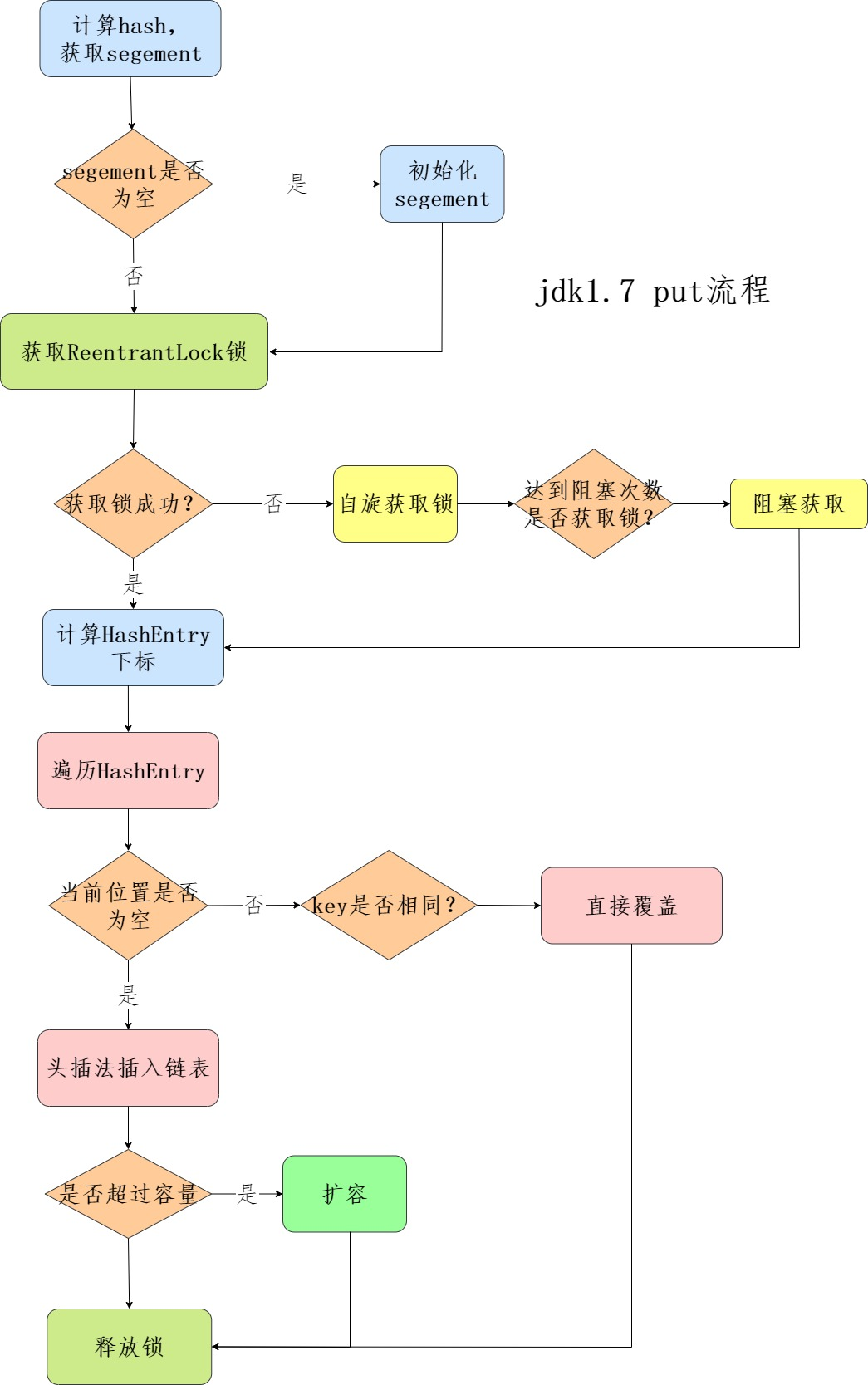
put 流程和 HashMap 非常类似,只不过是先定位到具体的段,再通过 ReentrantLock 去操作而已。一共可以分为 4 个步骤:
第一步:先通过计算hash,来确定段,如果段为空就开始初始化
第二步:使用ReentrantLock来进行加锁,如果加锁失败就自旋,自旋超过次数就进行阻塞,保证一定能够获取到锁(失败会先自旋再阻塞)
第三步:遍历段中的键值对HashEntry,key相同就直接替换,key不存在就插入。
第四步,释放锁。
(3)说一下 JDK 7 中 ConcurrentHashMap 的 get 流程?
get就更加简单,直接通过hash计算定位段,再遍历HashEntry,找到就直接返回value。get不需要进行加锁,因为使用了volatile就不存在可见性问题。
(4)说一下 JDK 8 中 ConcurrentHashMap 的实现原理?
JDK8中ConcurrentHashMap,取消了分段锁,使用CAS+synchronized实现了粒度更加细的桶锁,并且使用红黑树来优化链表以提高哈希冲突时的查询效率,性能比 JDK 7 有了很大的提升。
JDK 1.8 彻底抛弃了 Segment 分段锁的概念,直接采用了 Node 数组 + 链表 + 红黑树 的结构(和 JDK 1.8 的 HashMap 结构一致),并发控制粒度更细。
(5)说一下 JDK 8 中 ConcurrentHashMap 的 put 流程?
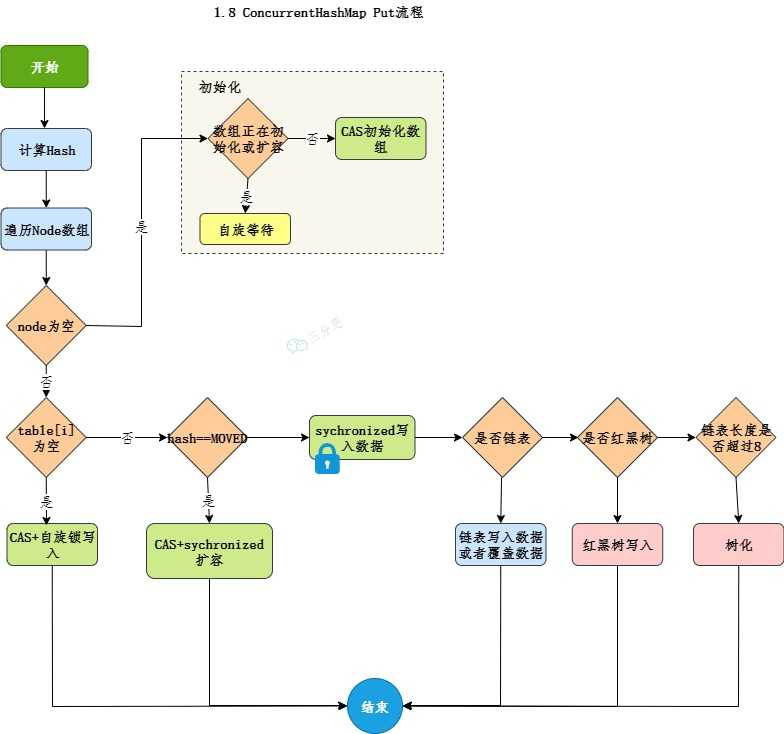
这是一个死循环过程,直到插入成功
- 判断初始化:如果 table 还没初始化,先进行初始化(CAS 控制)。
- 计算 Hash:定位到数组下标 i。
- 情况 A:该位置为空 (null)
- 无需加锁 !直接使用 CAS 尝试将新节点放入该位置。
- 如果 CAS 成功,结束;如果失败(说明有其他线程抢先了),自旋重试。
- 情况 B:该位置正在扩容
- 发现节点的 hash 值为 MOVED (-1),说明数组正在扩容,当前线程会帮忙一起扩容(Help Transfer)。
- 情况 C:该位置有数据 (Hash冲突)
- 加锁 :使用 synchronized 锁住当前位置的头节点(只有这里才加锁)。
- 插入:遍历链表或红黑树,更新值或追加新节点。
- 转树:如果链表长度 >= 8,将链表转为红黑树。
通过源码进行解读
java
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 1.计算key的hash,以确定桶在数组中的位置
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 下面是4中情况:
// 2.情况一:如果Node[] table数组为空
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 3.情况二:table不为空,计算索引的位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 4. CAS插入节点,这一步是无锁的状态
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 5.情况三:需要扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 6.情况四:CAS操作失败,使用 synchronized 代码块插入节点
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
// 7.插入的过程中会判断桶的哈希是否小于 0(f.hash >= 0),小于 0 说明是红黑树,大于等于 0 说明是链表。
if (fh >= 0) { // 链表操作
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树操作
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 8.如果链表长度超过 8,转换为红黑树。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 9.在插入新节点后,会调用 addCount() 方法检查是否需要扩容。
addCount(1L, binCount);
return null;
}源码中:在 ConcurrentHashMap 中,普通的节点(Node)存储的是数据的 Hash 值(经过运算后的正数)。为了区分"普通数据节点"和"处于特殊状态的节点",JDK 1.8 巧妙地设计了一套负数 Hash 编码体系。
java
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
- 正数 Hash -> 普通数据(链表头节点)。
- -1 (MOVED) -> 正在扩容,数据已搬走。
- -2 (TREEBIN) -> 红黑树。
- -3 (RESERVED) -> 计算占位。
(6)说一下 JDK 8 中 ConcurrentHashMap 的 get 流程?
源码如下:get 也是通过 key 的 hash 进行定位,如果该位置节点的哈希匹配且键相等,则直接返回值。
java
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 1.通过hash,计算索引
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 2.普通数组节点,链表的头或者红黑树的根节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 3.特殊节点,需要调用find来进行查找,如果节点的哈希为负数,说明是个特殊节点,比如说如树节点或者正在迁移的节点,就调用find方法查找。
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 4.否则遍历链表查找匹配的键
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
// 5。如果都没找到,返回 null。
return null;
}(7)说一下 HashMap 和 ConcurrentHashMap 的区别?
HashMap是非线程安全的场景,在单线程的环境下使用;ConcurrentHashMap是线程安全的版本,多线程的环境下使用。
(8)你项目中怎么使用 ConcurrentHashMap 的?
场景题:ConcurrentHashMap 是 Java 后端开发中处理高并发 、线程安全 数据的"神器"。它的核心价值在于:在保证线程安全的前提下,提供了极高的读写性能(比 Hashtable 或 Collections.synchronizedMap 快得多)。
并发任务去重,防止同一个任务被多个线程重复执行。
用户点击"提交订单",前端没做好防抖,发了 10 个请求过来。后端需要保证同一时间只有一个请求在处理。
ConcurrentHashMap的使用场景
(9)说一下 ConcurrentHashMap 对 HashMap 的改进?
1.hash的计算
首先是 hash 的计算方法上,ConcurrentHashMap 的 spread 方法接收一个已经计算好的 hashCode,然后将这个哈希码的高 16 位与自身进行异或运算。
java
// ConcurrentHashMap
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS; // 保证计算结果是一个非负数
}
// HashMap
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}HASH_BITS:HASH_BITS 是一个常数,值为 0x7fffffff,它确保结果是一个非负整数。
2.对Node节点的进一步封装
ConcurrentHashMap 对节点 Node 做了进一步的封装,比如说用 Forwarding Node 来表示正在进行扩容的节点。
java
// Forwarding Node正在进行扩容的节点
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
// 占位符节点
static final class ReservationNode<K,V> extends Node<K,V> {
ReservationNode() {
super(RESERVED, null, null, null);
}
Node<K,V> find(int h, Object k) {
return null;
}
}3.并发机制,CAS与synchronized代码块来进行并发写入
可以看putVal源码,其中使用到了casTabAt()/synchronized(f)
(10)为什么 ConcurrentHashMap 在 JDK 1.7 中要用 ReentrantLock,而在 JDK 1.8 要用 synchronized
JDK1.7使用的是分段锁,每个 Segment 都继承了 ReentrantLock,这样可以保证每个 Segment 都可以独立地加锁。
JDK1.8 ConcurrentHashMap 取消了 Segment 分段锁,采用了更加精细化的锁------桶锁,以及 CAS 无锁算法,每个桶都可以独立地加锁,只有在 CAS 失败时才会使用 synchronized 代码块加锁,这样可以减少锁的竞争,提高并发性能。
JDK 1.8 放弃 ReentrantLock 是为了追求极致的锁粒度(从分段锁到节点锁) ,而为了避免给数以万计的节点创建 Lock 对象带来的内存爆炸 ,利用对象头即可加锁且已被 JVM 高度优化的 synchronized 成为了唯一且最优的选择。
特性 JDK 1.7 (ReentrantLock) JDK 1.8 (synchronized) 胜出者 锁粒度 Segment (分段,较粗) Node (桶级别,最细) 1.8 内存开销 每个 Segment 是个大对象 利用对象头,零额外对象 1.8 无锁支持 较少,主要依赖锁 大量使用 CAS,无冲突不加锁 1.8 JVM优化 库层面,优化空间小 JVM 内置,自动偏向/轻量锁 1.8
49 ConcurrentHashMap 怎么保证可见性?
使用volatile关键词修饰变量,保证可见性。ConcurrentHashMap 中的 Node 节点中,value 和 next 都是 volatile 的,这样就可以保证对 value 或 next 的更新会被其他线程立即看到。
源码:
java
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V value;
volatile Node<K,V> next;
}
/* ---------------- Fields -------------- */
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node<K,V>[] nextTable;
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
*/
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*/
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;50 为什么 ConcurrentHashMap 比 Hashtable 效率高
锁的粒度差距。加锁的时机。
HashTable是直接在HashMap的方法上加synchronized实现的,锁的是整个Map对象,也就上说整个Map任何时刻只允许一个线程访问,锁的粒度非常大。
java
public synchronized V put(K key, V value) {
if (value == null) throw new NullPointerException();
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % table.length;
...
return oldValue;
}ConcurrentHashMap在JDK1.8中使用CAS+synchronized实现,仅仅在必要的时候加锁,既有乐观锁又有悲观锁。减少锁的开销。
比如说 put 的时候优先使用 CAS 尝试插入,如果失败再使用 synchronized 代码块加锁。
get 的时候是完全无锁的,因为 value 是 volatile 变量 修饰的,保证了内存可见性。
java
public V get(Object key) {
int hash = spread(key.hashCode());
Node<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
Node<K,V> e = tabAt(tab, index);
if (e != null) {
do {
if (e.hash == hash && (e.key == key || (key != null && key.equals(e.key)))) {
return e.value; // 读取 volatile 变量,保证可见性
}
} while ((e = e.next) != null);
}
return null;
}51 能说一下 CopyOnWriteArrayList 的实现原理吗?
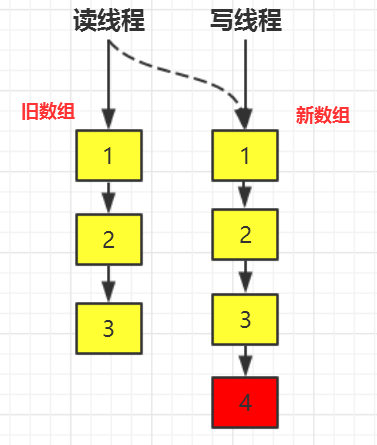
CopyOnWrite写时复制,CopyOnWriteArrayList 是 ArrayList 的线程安全版本,适用于读多写少的场景。
写时复制的核心思想就是写操作的时候常见一个新的数组,修改结束后再替换原有数组,这样就确保了操作无锁,从而提高并发性能,读操作无锁,写操作复制新数组。,类似快照的方法,写操作需要使用可重入锁保证线程安全
源码层面
内部结构:维护一个volatile数组。
java
// 只能通过 getArray/setArray 访问
private transient volatile Object[] array;volatile 的作用 :保证可见性。一旦数组被修改(指向了新数组),所有线程立马就能看到最新的数组,不需要加锁读取
读操作
直接读取,没有任何锁,也不需要CAS
java
public E get(int index) {
return get(getArray(), index); // 直接取,极快
}写操作------复制新数组
写操作是加锁的(通常是 ReentrantLock 或 synchronized),但锁的粒度很大。
流程:
- 加锁:保证同一时刻只有一个线程在写入(避免多个线程同时复制出多个副本)。
- 获取旧数组:拿到当前的 array 引用。
- 复制新数组 :创建一个长度为 len + 1 的新数组,把旧数组的数据拷进去。
- 写入新数据:把新数据填到新数组的最后一位。
- 引用替换 :把内部的 array 引用指向新数组(这一步是 volatile 写,瞬间对所有读线程可见)。
- 解锁。
java
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); // 1. 加锁
try {
Object[] elements = getArray();
int len = elements.length;
// 2. 复制出新数组(长度+1)
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 3. 修改新数组
newElements[len] = e;
// 4. 将引用指向新数组 (volatile 写)
setArray(newElements);
return true;
} finally {
lock.unlock(); // 5. 解锁
}
}CopyOnWriteArrayList 就是通过"读写分离"的思想,牺牲了写操作的性能(加锁+复制)和空间(双倍内存),换取了读操作的极致性能(无锁)。
52 能说一下 BlockingQueue 吗?
BlockingQueue是JUC包下的一个线程安全队列,阻塞队列,支持阻塞式的"生产者-消费者"模型。是一个接口
当队列容器已满,生产者线程会被阻塞,直到消费者线程取走元素后为止;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
BlockingQueue 的实现类有很多,比如说 ArrayBlockingQueue、PriorityBlockingQueue 等。
| 实现类 | 数据结构 | 是否有界 | 特点 |
|---|---|---|---|
| ArrayBlockingQueue | 数组 | ✅ 有界 | 基于数组,固定容量,FIFO |
| LinkedBlockingQueue | 链表 | ✅ 可有界(默认 Integer.MAX_VALUE) | 基于链表,吞吐量比 ArrayBlockingQueue 高 |
| PriorityBlockingQueue | 堆(优先队列) | ❌ 无界 | 元素按优先级排序(非 FIFO) |
| DelayQueue | 优先队列(基于 Delayed 接口) | ❌ 无界 | 元素到期后才能被取出 |
| SynchronousQueue | 无缓冲 | ✅ 容量为 0 | 必须一对一交换数据,适用于高吞吐的任务提交 |
| LinkedTransferQueue | 链表 | ❌ 无界 | 支持 tryTransfer(),数据立即交给消费者 |
对比题
ArrayBlockingQueue vs LinkedBlockingQueue 的区别
- 层结构:Array 是数组;Linked 是链表。
- 内存占用:Array 预先分配内存;Linked 动态创建节点(但在高并发下,频繁创建/销毁 Node 对象会增加 GC 压力)。
- 锁的粒度 (关键):
- Array 使用 一把锁(生产和消费互斥)。
- Linked 使用 两把锁 (生产锁 putLock,消费锁 takeLock),生产和消费互不干扰,并发性能更好。
(1)阻塞队列是如何实现的?
阻塞队列通过可重入锁ReentrantLock+Condition来确保并发安全。
- 一个 ReentrantLock 锁。
- 两个 Condition 条件变量:
- notEmpty:用来唤醒消费者(队列不空了,快来取)。
- notFull:用来唤醒生产者(队列不满了,快来放)。
put
java
lock.lock();
try {
while (count == items.length) {
// 队列满了,生产者在 notFull 条件上等待(阻塞)
notFull.await();
}
enqueue(e); // 入队
// 入队后,唤醒消费者:"我不空了,你快来取"
notEmpty.signal();
} finally {
lock.unlock();
}take
java
lock.lock();
try {
while (count == 0) {
// 队列空了,消费者在 notEmpty 条件上等待(阻塞)
notEmpty.await();
}
dequeue(); // 出队
// 出队后,唤醒生产者:"我不满了,你快来放"
notFull.signal();
} finally {
lock.unlock();
}线程池
53 什么是线程池?【*】
线程池是用来管理和复用线程的工具,它可以减少线程创建和销毁的开销
在Java中,ThreadPoolExecutor是线程池的核心实现,它通过设置核心线程数、最大线程数、任务队列和拒绝策略来控制线程的执行和创建。
举个例子:就像你开了一家餐厅,线程池就相当于固定数量的服务员,顾客(任务)来了就安排空闲的服务员(线程)处理,避免了频繁招人和解雇的成本。
(1)线程池的任务队列是什么队列?
阻塞队列
54 你在项目中有用到线程池吗?
推荐阅读:线程池在美团业务中的应用
场景题:有的,在拼团项目中,需要去多线程异步加载拼团活动信息、商品信息等数据,内置可配置的线程池,基于ThreadPoolEsecutor,适用于IO密集型的任务。
线程池参数的设定:
java@Data @ConfigurationProperties(prefix = "thread.pool.executor.config", ignoreInvalidFields = true) public class ThreadPoolConfigProperties { /** 核心线程数 */ private Integer corePoolSize = 20; /** 最大线程数 */ private Integer maxPoolSize = 200; /** 最大等待时间 */ private Long keepAliveTime = 10L; /** 最大队列数 */ private Integer blockQueueSize = 5000; /* * AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 * DiscardPolicy:直接丢弃任务,但是不会抛出异常 * DiscardOldestPolicy:将最早进入队列的任务删除,之后再尝试加入队列的任务被拒绝 * CallerRunsPolicy:如果任务添加线程池失败,那么主线程自己执行该任务 * */ private String policy = "AbortPolicy"; }
55 说一下线程池的工作流程?【*】
线程池工作流程:任务提交->核心线程执行->任务队列缓存->非核心线程执行->拒绝策略
详细:
第一步,创建线程池。
第二步,调用线程池的 execute()方法,准备执行任务。
- 如果正在运行的线程数量小于 corePoolSize,那么线程池会创建一个新的核心线程来执行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么线程池会将这个任务放入等待队列;
- 如果等待队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么线程池会创建新的线程来执行这个任务;
- 如果等待队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会执行拒绝策略。
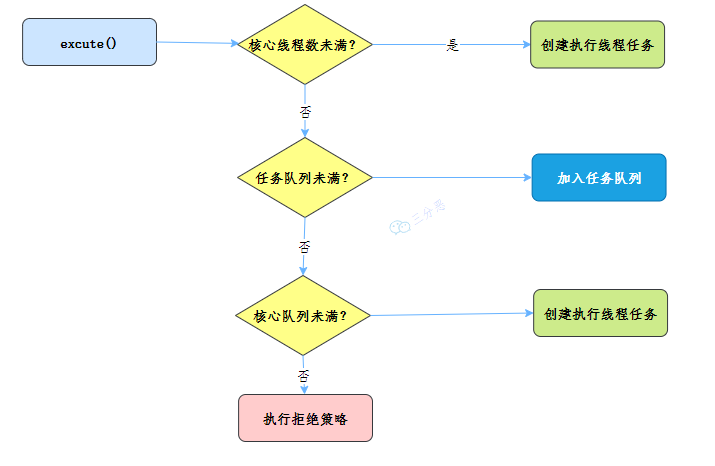
第三步,线程执行完毕后,线程并不会立即销毁,而是继续保持在池中等待下一个任务。
第四步,当线程空闲时间超出指定时间,且当前线程数量大于核心线程数时,线程会被回收。
(1)能用一个生活中的例子说明下吗?
银行工作线程模拟:
java
/**
* @author YinHang
* @description 线程池demo
* @create 2026-02-13 17:08
*/
public class ThreadPoolDemo {
public static void main(String[] args) {
// 1.创建线程池
ExecutorService executor = new ThreadPoolExecutor(
3,
6,
0,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
// 2.模拟10个客户来银行办理业务
try {
for (int i = 0; i < 10; i++) {
final int finalI = i;
executor.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t" + "办理业务" + finalI);
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
executor.shutdown();
}
}
}结果:
java
pool-1-thread-1 办理业务0
pool-1-thread-2 办理业务1
pool-1-thread-3 办理业务2
pool-1-thread-2 办理业务4
pool-1-thread-1 办理业务3
pool-1-thread-2 办理业务6
pool-1-thread-3 办理业务5
pool-1-thread-3 办理业务9
pool-1-thread-2 办理业务8
pool-1-thread-1 办理业务756 线程池的主要参数有哪些?【*】
线程池主要有7大核心参数:核心线程数、最大线程数、非核心线程存活时间、非核心线程存活时间单位、等待队列、创建线程使用工厂、拒绝策略。
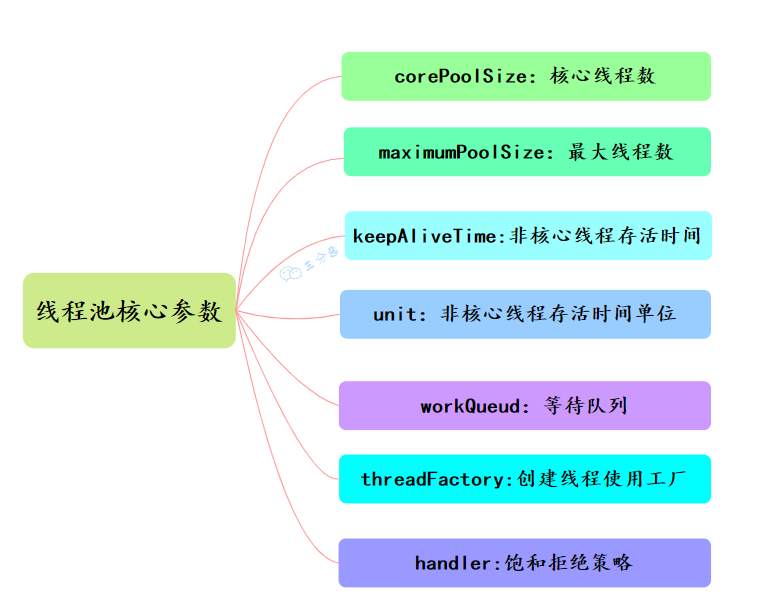
1.corePoolSize: 核心线程数,长期存活,执行任务的主力。
2.maximumPoolSize:线程池允许的最大线程数。
3.workQueue: 任务队列,存储等待执行的任务
4.handler: 拒绝策略,任务超载时的处理方式。也就是线程数达到 maximumPoolSize,任务队列也满了的时候,就会触发拒绝策略。
5.threadFactory: 线程工厂,用于创建线程,可自定义线程名。
6.keepAliveTime: 非核心线程的存活时间,空闲时间超过该值就销毁
7.unit:keepAliveTime的时间单位
- TimeUnit.DAYS: 天
- TimeUnit.HOURS: 小时
- TimeUnit.MINUTES: 分钟
- TimeUnit.SECONDS: 秒
- TimeUnit.MILLISECONDS: 毫秒
- TimeUnit.MICROSECONDS: 微秒
- TimeUnit.NANOSECONDS: 纳秒
(1)能简单说一下参数之间的关系吗?
任务优先使用corePoolSize核心线程数,核心线程用完之后就进入任务队列workQueue,队列满了就启动非河西线程备用,线程池达到最大之后就触发了拒绝策略,非核心线程的空闲时间超过了存活时间就被回收。
(2)核心线程数不够会怎么进行处理?
当提交的任务数超过了 corePoolSize,但是小于 maximumPoolSize 时,线程池会创建新的线程来处理任务。
当提交的任务数超过了 maximumPoolSize 时,线程池会根据拒绝策略来处理任务。
(3)举个例子说一下这些参数的变化?
假设一个场景,线程池的配置如下:
java
corePoolSize = 5
maximumPoolSize = 10
keepAliveTime = 60秒
workQueue = LinkedBlockingQueue(容量为100)
handler = ThreadPoolExecutor.AbortPolicy()场景一:当系统启动后,有 10 个任务提交到线程池。
- 前 5 个任务会立即执行,因为核心线程数足够容纳它们。
- 随后的 5 个任务会被放入等待队列。
场景二:如果此时再有 100 个任务提交到线程池。
- 工作队列已满,线程池会创建额外的线程来执行这些任务,直到线程总数达到 10。
- 如果任务继续增加,超过了工作队列+最大线程数的限制,新来的任务会被 AbortPolicy 拒绝,抛出 RejectedExecutionException 异常。
场景三:如果任务突然减少:
核心线程会一直运行,而超出核心线程数的线程,会在 60 秒后回收。
57 线程池的拒绝策略有哪些?【*】
线程池有四种拒绝策略:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy。
- AbortPolicy:默认的拒绝策略,会抛 RejectedExecutionException 异常。
- CallerRunsPolicy:让提交任务的线程自己来执行这个任务,也就是调用 execute 方法的线程。
- DiscardOldestPolicy:等待队列会丢弃队列中最老的一个任务,也就是队列中等待最久的任务,然后尝试重新提交被拒绝的任务。
- DiscardPolicy:丢弃被拒绝的任务,不做任何处理也不抛出异常。
当线程池无法接受新的任务时,也就是线程数达到 maximumPoolSize,任务队列也满了的时候,就会触发拒绝策略。
如果默认策略不能满足需求,可以通过实现 RejectedExecutionHandler 接口来定义自己的淘汰策略。例如:记录被拒绝任务的日志。
自定义拒绝策略接口:
java
class CustomRejectedHandler {
public static void main(String[] args) {
// 自定义拒绝策略
RejectedExecutionHandler rejectedHandler = (r, executor) -> {
System.out.println("Task " + r.toString() + " rejected. Queue size: "
+ executor.getQueue().size());
};
// 自定义线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(
2, // 核心线程数
4, // 最大线程数
10, // 空闲线程存活时间
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2), // 阻塞队列容量
Executors.defaultThreadFactory(),
rejectedHandler // 自定义拒绝策略
);
for (int i = 0; i < 10; i++) {
final int taskNumber = i;
executor.execute(() -> {
System.out.println("Executing task " + taskNumber);
try {
Thread.sleep(1000); // 模拟任务耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}结果:
java
Executing task 1
Executing task 0
Executing task 4
Task JUC.ThreadPoolTest$$Lambda$2/2065951873@b4c966a rejected. Queue size: 2
Task JUC.ThreadPoolTest$$Lambda$2/2065951873@2f4d3709 rejected. Queue size: 2
Task JUC.ThreadPoolTest$$Lambda$2/2065951873@4e50df2e rejected. Queue size: 2
Executing task 5
Task JUC.ThreadPoolTest$$Lambda$2/2065951873@1d81eb93 rejected. Queue size: 2
Executing task 2
Executing task 358 线程池有哪几种阻塞队列?
线程池有5种阻塞队列:有界队列ArrayBlockingQueue、无界队列LinkedBlockingQueue、优先级队列PriorityBlockingQueue、延迟队列DelayQueue、同步队列SynvhronousQueue
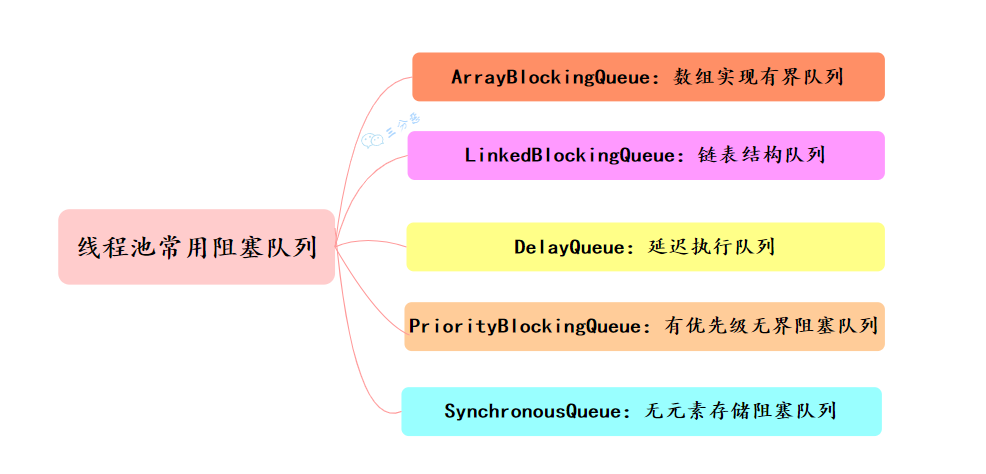
(1)ArrayBlockingQueue:一个有界 的先进先出的阻塞队列,底层是一个数组,适合固定大小的线程池。
- 底层结构 :数组 (Array)。
- 容量 :有界 (Bounded)。必须在构造时指定大小,且不可改变。
- 核心特性:
- 一把锁 :内部只使用一把 ReentrantLock。这意味着生产者和消费者会争抢同一把锁,无法真正的并行操作。
- 公平性:可以设置公平锁(先来后到),但性能会下降。
- 适用场景:
- 资源有限,必须防止 OOM(内存溢出)的场景。
- 并发量不是特别惊人,追求系统稳定性的系统。
java
ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10, true);(2)LinkedBlockingQueue:无界队列,底层单向链表实现,不指定大小,默认的大小就是Integer.MAX_VALUE,容易导致 OOM。
- 底层结构 :单向链表 (Linked List)。
- 容量 :可选有界。
- 坑点 :如果你不指定容量,默认为 Integer.MAX_VALUE(约 21 亿)。这在生产环境中等同于无界,容易导致 OOM。
- 核心特性:
- 两把锁 (锁分离) :putLock(生产锁)和 takeLock(消费锁)。生产者和消费者互不干扰,并发性能通常高于 ArrayBlockingQueue。
- 适用场景:
- 线程池默认:FixedThreadPool 和 SingleThreadExecutor 都在用它。
- 生产-消费速率差距较大,且需要高吞吐量的场景(务必手动指定容量)。
(3)PriorityBlockingQueue支持优先级排序的无界阻塞队列。任务按照其自然顺序或 Comparator 来排序。适合用于需要按照优先级处理任务的场景,比如优先处理紧急任务。
- 底层结构 :二叉堆 (Binary Heap),底层是数组。
- 容量 :无界(会自动扩容,直到内存耗尽)。
- 核心特性:
- 打破 FIFO :它不按"先来后到"排队,而是按优先级(Comparator 或 Comparable)排队。
- 每次取出的都是优先级最高的元素。
- 适用场景:
- 任务有轻重缓急的场景(如:VIP 会员请求优先处理,系统核心日志优先写入)。
(4)延迟队列DelayQueue:类似于 PriorityBlockingQueue,由二叉堆实现的无界优先级阻塞队列。
- 底层结构 :PriorityQueue(基于优先级的堆)。
- 容量 :无界。
- 核心特性:
- 时间控制:元素必须实现 Delayed 接口。
- 不到时间拿不走:只有当元素的延迟时间到了(Expired),消费者才能从队列中把它取出来。
- 排序:内部按"剩余时间"排序,快过期的排在队头。
- 适用场景:
- 缓存过期清理(Cache Eviction)。
- 任务超时处理(如订单 30 分钟未支付自动关闭)。
- 定时任务调度。
Executors 中的 newScheduledThreadPool() 就使用了 DelayQueue 来实现延迟执行。
java
// ScheduledThreadPoolExecutor源码
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue()); // 使用延迟队列实现
}(5)SynchronousQueue
同步移交队列,一个插入操作必须等待另一个线程的移除操作,同样,任何一个移除操作都必须等待另一个线程的插入操作。不存元素
Executors.newCachedThreadPool() 就使用了 SynchronousQueue,这个线程池会根据需要创建新线程,如果有空闲线程则会重复使用,线程空闲 60 秒后会被回收。
- 底层结构 :无存储空间(容量为 0)。
- 容量 :0。
- 核心特性:
- 一夫当关:每一个 put 操作必须等待一个 take 操作,否则无法继续(反之亦然)。
- 它不是用来存数据的,而是用来直接移交数据的。
- 性能极高(基于 CAS,无锁算法)。
- 适用场景:
- CachedThreadPool:线程池核心,用于处理执行时间短、吞吐量极高的任务。
- 两个线程间如果不希望有缓冲,直接交换数据。
java
// Executor源码
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}| 队列名称 | 底层结构 | 容量限制 | 锁机制 (核心区别) | 典型应用场景 | 风险点 |
|---|---|---|---|---|---|
| ArrayBQ | 数组 | 有界 (必填) | 一把锁 (ReentrantLock) | 资源受限、防 OOM | 吞吐量受限于单锁 |
| LinkedBQ | 链表 | 可选 (默认无界) | 两把锁 (读写分离) | 高吞吐、FixedThreadPool | 默认无界易导致 OOM |
| PriorityBQ | 二叉堆 | 无界 | 一把锁 | VIP 插队、任务调度 | 无界可能导致 OOM;饿死低优先级任务 |
| DelayQueue | PriorityQueue | 无界 | 一把锁 + Condition | 缓存过期、超时取消 | 无界可能导致 OOM |
| Synchronous | 无 | 0 | 无锁 (CAS) | CachedThreadPool、直接传递 | 必须配合无限线程数,否则易丢任务 |
59 线程池提交 execute 和 submit 有什么区别?
execute无返回值,submit有返回值。
execute 方法没有返回值,适用于不关心结果和异常的简单任务。
java
threadsPool.execute(new Runnable() {
@Override public void run() {
System.out.println("execute() 方法提交的任务");
}
});submit 有返回值,适用于需要获取结果或处理异常的场景。
java
Future<Object> future = executor.submit(harReturnValuetask); // 使用FutureM<T>来存储返回值
try { Object s = future.get(); }
catch (InterruptedException e | ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池 executor.shutdown();
}60 线程池怎么关闭知道吗?
使用shutdown()和shutdownNow()来关闭线程池
- shutDown(): shutdown()不会立即停止线程池,而是会等待所有任务执行完毕后再关闭线程池。
java
ExecutorService executor = Executors.newFixedThreadPool(3);
executor.execute(() -> System.out.println("Task 1"));
executor.execute(() -> System.out.println("Task 2"));
executor.shutdown(); // 不会立刻关闭,而是等待所有任务执行完毕- shutDownNow():shutDownNow则是会有一系列操作,达到立即关闭线程池的目的,比如停止外部任务的接受,忽略队列里等待的任务、尝试将正在跑的任务中断(发出中断信号)
java
ExecutorService executor = Executors.newFixedThreadPool(3);
executor.execute(() -> {
try {
Thread.sleep(5000); // 模拟长时间运行任务
System.out.println("Task executed");
} catch (InterruptedException e) {
System.out.println("任务被中断");
}
});
List<Runnable> unexecutedTasks = executor.shutdownNow(); // 立即关闭线程池
System.out.println("未执行的任务数: " + unexecutedTasks.size());需要注意的是,shutdownNow 不会真正终止正在运行的任务,只是给任务线程发送 interrupt 信号,任务是否能真正终止取决于线程是否响应 InterruptedException。
| 特性 | shutdown() | shutdownNow() |
|---|---|---|
| 态度 | 温柔(优雅关闭) | 粗暴(立即关闭) |
| 新任务 | 拒绝 (抛异常) | 拒绝 (抛异常) |
| 队列中的任务 | 继续执行完 | 丢弃,并返回列表 |
| 正在跑的任务 | 继续执行完 | 试图中断 (Interrupt) |
| 返回值 | void | List (没做的任务) |
| 适用场景 | 程序正常退出、服务下线 | 紧急停止、任务出错需要重置 |
61 线程池的线程数应该怎么配置?【*】
场景实践,主要考虑两种场景:CPU密集型任务和IO密集型任务
1.对于 CPU 密集型任务,我的目标是尽量减少线程上下文切换,以优化 CPU 使用率。一般来说,核心线程数设置为处理器的核心数或核心数加一是较理想的选择。
+1 是为了以备不时之需,如果某线程因等待系统资源而阻塞时,可以有多余的线程顶上去,不至于影响整体性能。
2.对于 IO 密集型任务,由于线程经常处于等待状态,等待 IO 操作完成,所以可以设置更多的线程来提高并发,比如说 CPU 核心数的两倍。
核心数可以通过 Java 的Runtime.getRuntime().availableProcessors()方法获取。
实际情况:会根据业务需求和系统资源来调整线程池的其他参数,比如最大线程数、任务队列容量、非核心线程的空闲存活时间等。
CPU密集型任务
任务主要是在进行复杂的计算(如加密解密、压缩解压、正则匹配、算法计算、图像处理等)。CPU 一直在满负荷运转,很少等待。
目标:减少线程切换(Context Switch)。因为 CPU 已经在 100% 工作了,多开线程只会增加切换成本,导致性能下降。
IO密集型任务
任务大部分时间都在**"等"**(读写数据库、调用外部接口、读写文件、网络通信)。CPU 计算的时间很短。做的事很简单但是要等资源分配
目标:多开线程,压榨 CPU。因为当线程 A 在等数据库返回时,CPU 是空闲的,这时候应该让线程 B 赶紧利用 CPU 干活。
"线程池的线程数配置不能一概而论,主要取决于任务类型:
- 如果是 CPU 密集型 (如加密、算法),为了减少上下文切换,通常设置为 CPU 核数 + 1。
- 如果是 IO 密集型 (如 Web 服务、数据库调用),因为 CPU 经常空闲,需要多配线程,通常公式是 CPU 核数 * (1 + 等待时间/计算时间) 。在实际开发中,一般先按 2 * CPU 核数 设置初始值。
- 但是 ,公式只是参考。最准确的方式是进行压测,观察 CPU 利用率和系统吞吐量,找到最佳平衡点。
- 为了应对突发流量,现在主流的架构会使用动态线程池(如结合 Nacos),在运行时动态调整线程参数,避免重启。"
(1)如何知道你设置的线程数多了还是少了?
可以通过内存监控和调式来判断线程数是多是少。
比如说通过 top 命令观察 CPU 的使用率,如果 CPU 使用率较低,可能是线程数过少;如果 CPU 使用率接近 100%,但吞吐量未提升,可能是线程数过多。
然后再通过 VisualVM 或 Arthas 分析线程运行情况,查看线程的状态、等待时间、运行时间等信息。
也可以使用 jstack 命令查看线程堆栈信息,查看线程是否处于阻塞状态。
bash
jstack <Java 进程 ID> | grep -A 20 "BLOCKED" // 查看阻塞线程 如果有大量的 BLOCKED 线程,说明线程数可能过多,竞争比较激烈。
62 有哪几种常见的线程池?
一般使用Executors去创建线程池,有四种:固定大小线程池newFixedThreadPool、缓存线程池newCachedThreadPool、定时任务线程池newScheduledThreadPool、单线程线程池newSingleThreadPool
固定大小的线程池 Executors.newFixedThreadPool(int nThreads);,适合用于任务数量确定,且对线程数有明确要求的场景。例如,IO 密集型任务、数据库连接池等。
缓存线程池 Executors.newCachedThreadPool();,适用于短时间内任务量波动较大的场景。例如,短时间内有大量的文件处理任务或网络请求。
定时任务线程池 Executors.newScheduledThreadPool(int corePoolSize);,适用于需要定时执行任务的场景。例如,定时发送邮件、定时备份数据等。
单线程线程池 Executors.newSingleThreadExecutor();,**适用于需要按顺序执行任务的场景。**例如,日志记录、文件处理等。
63 能说一下四种常见线程池的原理吗?
四种常见线程池都是基于ThreadPoolExecutor的不同配置。不管是 FixedThreadPool、CachedThreadPool,还是 SingleThreadExecutor 和 ScheduledThreadPoolExecutor。
(1)固定大小缓存池FixedThreadPool
java
// FixedThreadPool源码
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue. At any point, at most
* {@code nThreads} threads will be active processing tasks.
* If additional tasks are submitted when all threads are active,
* they will wait in the queue until a thread is available.
* If any thread terminates due to a failure during execution
* prior to shutdown, a new one will take its place if needed to
* execute subsequent tasks. The threads in the pool will exist
* until it is explicitly {@link ExecutorService#shutdown shutdown}.
*
* @param nThreads the number of threads in the pool
* @return the newly created thread pool
* @throws IllegalArgumentException if {@code nThreads <= 0}
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, // 核心线程数
nThreads, // 最大线程数 corePoolSize == maximumPoolSize
0L, // 非核心线程存活时间
TimeUnit.MILLISECONDS, // 时间单位
new LinkedBlockingQueue<Runnable>() // 使用无界队列
);
}线程池大小是固定的,corePoolSize == maximumPoolSize,默认使用 LinkedBlockingQueue 作为阻塞队列,适用于任务量稳定的场景,如数据库连接池、RPC 处理等。
新任务提交时,如果线程池有空闲线程,直接执行;如果没有,任务进入 LinkedBlockingQueue 等待。缺点是任务队列默认无界,可能导致任务堆积,甚至 OOM。

(2)缓存线程池CachedThreadPool
java
// CachedThreadPool源码分析
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, // 核心线程数
Integer.MAX_VALUE,// 最大线程数
60L, // 非核心线程存活时间
TimeUnit.SECONDS, // 单位
new SynchronousQueue<Runnable>() // 无容量的同步队列
);
}线程池大小不固定,corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE。空闲线程超过 60 秒会被销毁,使用 SynchronousQueue 作为阻塞队列,适用于短时间内有大量任务的场景。
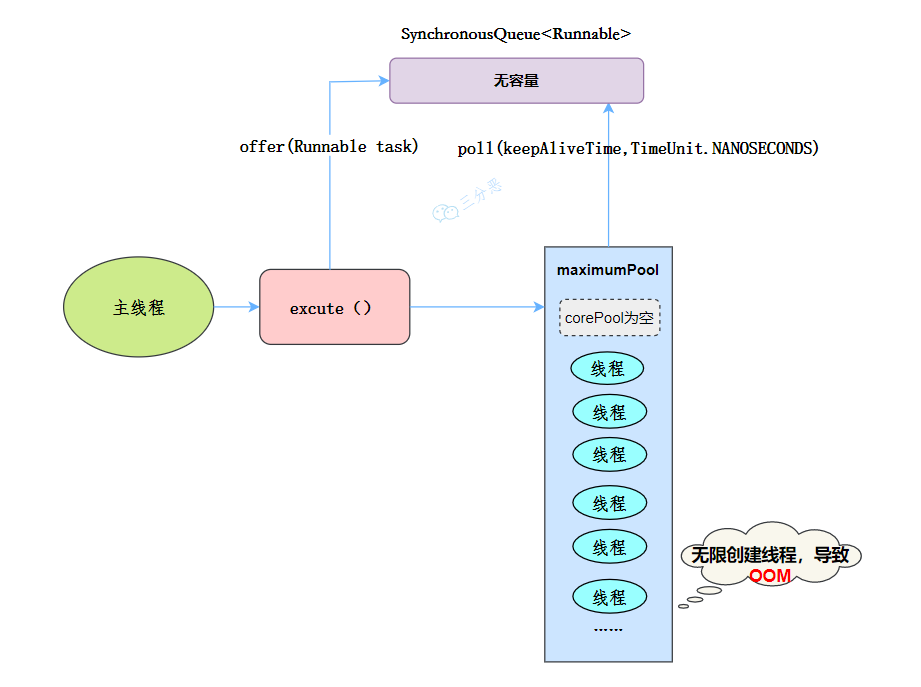
提交任务时,如果线程池没有空闲线程,直接新建线程执行任务;如果有,复用线程执行任务。线程空闲 60 秒后销毁,减少资源占用。缺点是线程数没有上限**,在高并发情况下可能导致 OOM。**
没有核心线程,不用等待,都是非核心线程,就是马上用马上空闲和销毁
(3)定时线程池ScheduledThreadPool
java
// ScheduledThreadPool源码,ScheduledThreadPoolExecutor继承ThreadPoolExecutor
/**
* Creates a new {@code ScheduledThreadPoolExecutor} with the
* given core pool size.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, // 核心线程数
Integer.MAX_VALUE, // 最大线程数
0, // 非核心存活实际按
NANOSECONDS,
new DelayedWorkQueue()); // 默认使用延迟队列
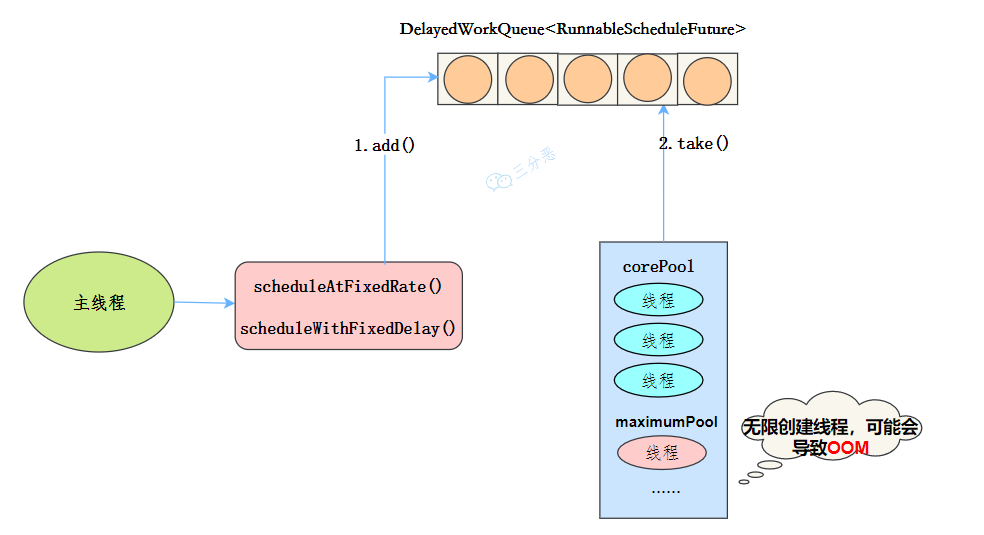
}定时任务线程池的大小可配置,支持定时 & 周期性任务执行,使用 DelayedWorkQueue 作为阻塞队列,适用于周期性执行任务的场景。
执行定时任务时,schedule() 方法可以将任务延迟一定时间后执行一次;scheduleAtFixedRate() 方法可以将任务延迟一定时间后以固定频率执行;scheduleWithFixedDelay() 方法可以将任务延迟一定时间后以固定延迟执行。
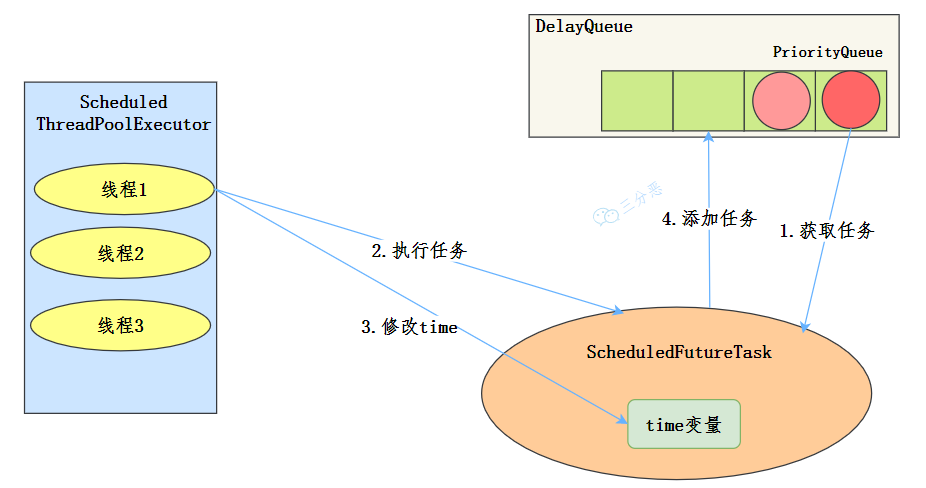
缺点是,如果任务执行时间 > 设定时间间隔,scheduleAtFixedRate 可能会导致任务堆积。
(4)单线程线程池SingleThreadPool
java
// SingleThreadPool源码
/**
* Creates an Executor that uses a single worker thread operating
* off an unbounded queue. (Note however that if this single
* thread terminates due to a failure during execution prior to
* shutdown, a new one will take its place if needed to execute
* subsequent tasks.) Tasks are guaranteed to execute
* sequentially, and no more than one task will be active at any
* given time. Unlike the otherwise equivalent
* {@code newFixedThreadPool(1)} the returned executor is
* guaranteed not to be reconfigurable to use additional threads.
*
* @return the newly created single-threaded Executor
*/
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, // 核心线程数
1, // 最大线程数
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>())
);
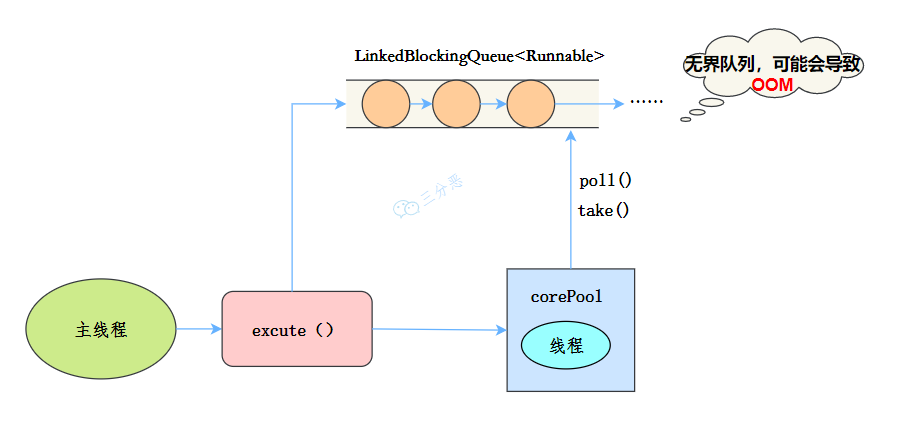
}线程池只有 1 个线程,保证任务按提交顺序执行,使用 LinkedBlockingQueue 作为阻塞队列,适用于需要按顺序执行任务的场景。
始终只创建 1 个线程,新任务必须等待前一个任务完成后才能执行,其他任务都被放入 LinkedBlockingQueue 排队执行。缺点是无法并行处理任务。
(5)使用无界队列的线程池会出现什么问题?
就是会导致内存溢出OOM,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致内存使用不断飙升,最终出现 OOM。
64 线程池异常怎么处理知道吗?
有四种处理方式:try-catch捕获异常,使用Future获取异常、自定义ThreadPoolExector重写afterExecute方法、使用UncaughtExceptionHandler捕获异常。
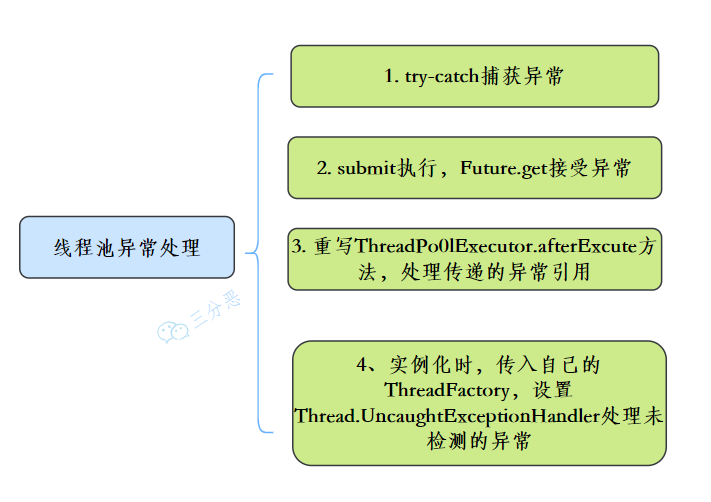
(1)try-catch 是最简单的方法。
java
executor.execute(() -> {
try { // 使用try-catch
System.out.println("任务开始");
int result = 1 / 0; // 除零异常
} catch (Exception e) {
System.err.println("捕获异常:" + e.getMessage());
}
});(2)使用 Future 获取异常。
java
Future<Object> future = executor.submit(() -> {
System.out.println("任务开始");
int result = 1 / 0; // 除零异常
return result;
});
try {
future.get(); // 使用future去捕获异常
} catch (InterruptedException | ExecutionException e) {
System.err.println("捕获异常:" + e.getMessage());
}(3)自定义 ThreadPoolExecutor 重写 afterExecute 方法。
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()) {
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t != null) { // 当抛出的异常不为空null,输出异常
System.err.println("捕获异常:" + t.getMessage());
}
}
};
executor.execute(() -> {
System.out.println("任务开始");
int result = 1 / 0; // 除零异常
});(4)使用 UncaughtExceptionHandler 捕获异常。
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.setThreadFactory(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.err.println("捕获异常:" + e.getMessage());
}
});
return thread;
}
});
executor.execute(() -> {
System.out.println("任务开始");
int result = 1 / 0; // 除零异常
});(5)使用场景
不关系返回值,使用execute(),使用UncaughtExceptionHandler:
java
thread.setUncaughtExceptionHandler((t, e) ->
System.err.println("线程 " + t.getName() + " 捕获到异常:" + e.getMessage()));如果项目使用 submit(),关心任务返回值,建议使用 Future:
java
Future<?> future = executor.submit(task);
try {
future.get();
} catch (ExecutionException e) {
System.err.println("捕获异常:" + e.getCause());
}如果想要全局捕获所有任务异常,建议重写 afterExecute 方法:
java
class MyThreadPoolExecutor extends ThreadPoolExecutor {
@Override
protected void afterExecute(Runnable r, Throwable t) {
if (t == null && r instanceof Future<?>) {
try { ((Future<?>) r).get(); } catch (Exception e) { System.err.println("任务异常:" + e.getCause()); }
}
}
}65 能说一下线程池有几种状态吗?
线程有5种状态依次流转:RUNNING->SHUTDOWN->STOP->TIDYING->TERMINATED
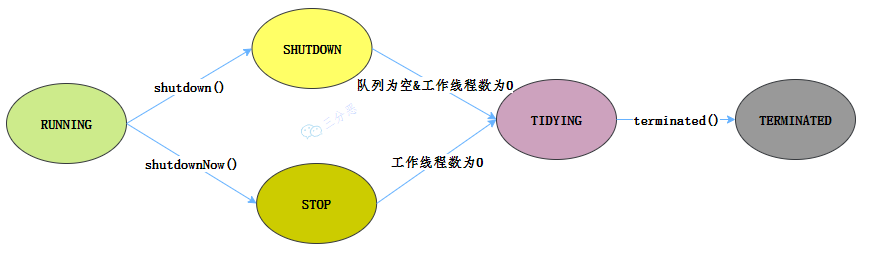
- RUNNING 状态的线程池可以接收新任务,并处理阻塞队列中的任务;
- SHUTDOWN 状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- STOP 状态的线程池不会接收新任务,也不会处理阻塞队列中的任务,并且会尝试中断正在执行的任务;
- TIDYING 状态表示所有任务已经终止;
- TERMINATED 状态表示线程池完全关闭,所有线程销毁。
| 状态 | 状态码 | 是否接收新任务 | 是否执行队列中的任务 | 是否中断正在执行的任务 |
|---|---|---|---|---|
| RUNNING | 111 | ✅ 是 | ✅ 是 | ❌ 否 |
| SHUTDOWN | 000 | ❌ 否 | ✅ 是 | ❌ 否 |
| STOP | 001 | ❌ 否 | ❌ 否 | ✅ 是 |
| TIDYING | 010 | ❌ 否 | ❌ 否 | ❌ 否 |
| TERMINATED | 011 | ❌ 否 | ❌ 否 | ❌ 否 |
66 线程池如何实现参数的动态修改?
利用中间件Nacos配置中心区机型线程池参数的动态修改或者自定义线程池,监听参数变化去动态调整参数。
线程池提供的 setter 方法就可以在运行时动态修改参数,比如说 setCorePoolSize 可以用来修改核心线程数、setMaximumPoolSize 可以用来修改最大线程数。
需要注意的是,调用 setCorePoolSize() 时如果新的核心线程数比原来的大,线程池会创建新的线程;如果更小,线程池不会立即销毁多余的线程,除非有空闲线程超过 keepAliveTime。
67 线程池调优了解吗?【*】
线程池的配置优化是针对多线程应用性能调优的关键环节。
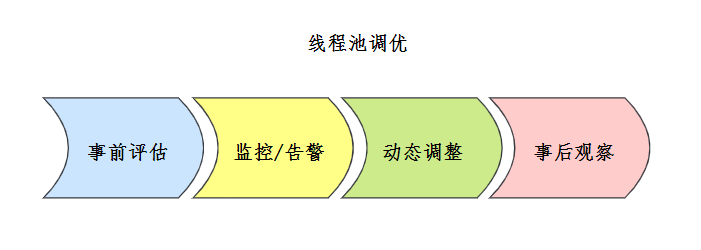
首先我会根据任务类型设置核心线程数参数,比如 IO 密集型任务会设置为 CPU 核心数*2 的经验值。
其次我会结合线程池动态调整的能力,在流量波动时通过 setCorePoolSize 平滑扩容,或者直接使用 DynamicTp 实现线程池参数的自动化调整。
最后,我会通过内置的监控指标建立容量预警机制。比如通过 JMX 监控线程池的运行状态,设置阈值,当线程池的任务队列长度超过阈值时,触发告警。
68 线程池在使用的时候需要注意什么?
我认为有 3 个比较重要的关注点:
- 第一个,选择合适的线程池大小 。过小 的线程池可能会导致任务一直在排队;过大的线程池可能会导致大家都在竞争 CPU 资源,增加上下文切换的开销
- 第二个,选择合适的任务队列。使用有界队列可以避免资源耗尽的风险,但是可能会导致任务被拒绝;使用无界队列虽然可以避免任务被拒绝,但是可能会导致内存耗尽
- 比如在使用 LinkedBlockingQueue 的时候,可以传入参数来限制队列中任务的数量,这样就不会出现 OOM。
- 第三个,尽量使用自定义的线程池,而不是使用 Executors 创建的线程池。
因为 newFixedThreadPool 线程池由于使用了 LinkedBlockingQueue,队列的容量默认无限大,任务过多时会导致内存溢出;newCachedThreadPool 线程池由于核心线程数无限大,当任务过多的时候会导致创建大量的线程,导致服务器负载过高宕机。
69 你能设计实现一个线程池吗?【*】
线程池的主要目的是为了避免频繁地创建和销毁线程。
手撕线程池
(1)手写一个数据库连接池
70 线程池执行中断电了应该怎么处理?
线程池本身只能在内存中进行任务调度,并不会持久化,一旦断电,线程池里的所有任务和状态都会丢失。
我会考虑以下几个方面:
第一,持久化任务。可以将任务持久化到数据库或者消息队列中,等电恢复后再重新执行。
第二,任务幂等性,需要保证任务是幂等的,也就是无论执行多少次,结果都一致。
第三,恢复策略。当系统重启时,应该有一个恢复流程:检测上次是否有未完成的任务,将这些任务重新加载到线程池中执行,确保断电前的工作能够恢复。
并发容器和框架
71 并发容器有哪些?
Java 提供了多种并发容器,主要包括:
- ConcurrentHashMap:线程安全的哈希表,支持高并发读写操作。
- CopyOnWriteArrayList:写时复制的 ArrayList,适用于读多写少的场景。
- BlockingQueue:阻塞队列,常用实现有 ArrayBlockingQueue 和 LinkedBlockingQueue,适用于生产者-消费者场景。
- ConcurrentLinkedQueue:非阻塞的线程安全队列。
- ConcurrentSkipListMap:基于跳表实现的线程安全有序 Map。
72 说说 Java 的并发关键字?
最常用的有两个关键字,分别是:
- synchronized:用于方法或者代码块,确保同一时间只有一个线程可以执行被 synchronized 修饰的代码,适用于保护共享资源的访问。
- volatile:用于变量,确保变量的可见性,防止指令重排序,适用于状态标志等场景。
73 Fork/Join 框架了解吗?
关于 Fork/Join 框架,我了解一些,它是 Java 7 引入的一个并行框架,主要用于分治算法的并行执行。这个框架通过将大的任务递归地分解成小任务,然后并行执行,最后再合并结果,以达到最高效率处理大量数据的目的。
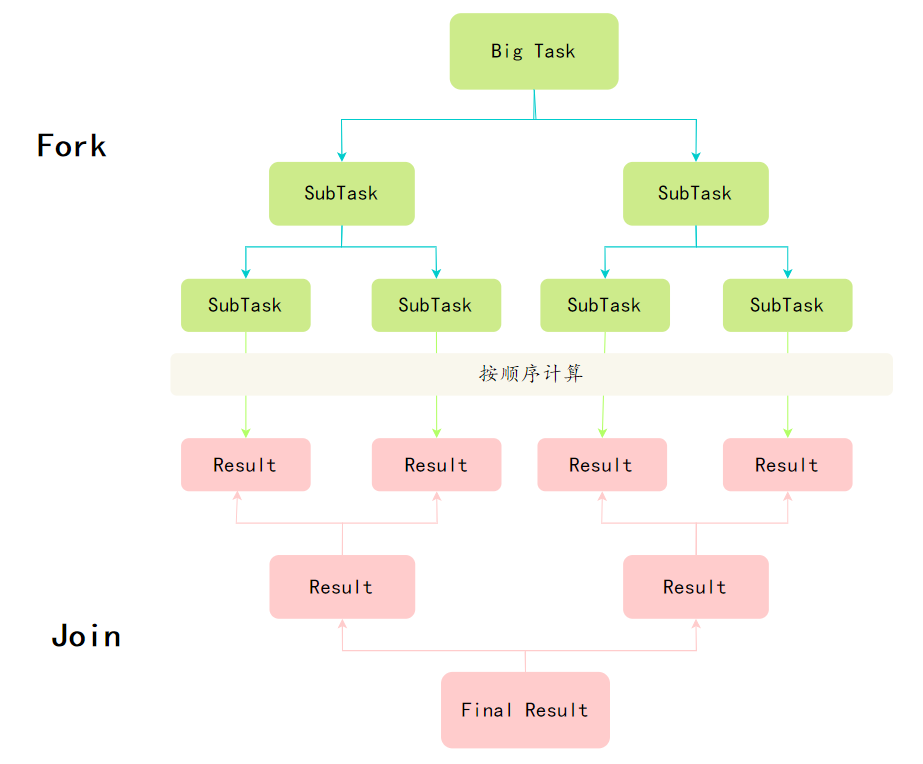
Fork/Join 框架的核心理念是分而治之,将大任务拆分为多个小任务并行处理,最后再将这些小任务的结果汇总。
就像是一个树形结构,根节点是一个大的任务,叶子节点是最小的子任务,每个任务都可能会被分裂成更小的子任务,直到达到某个临界点,任务再逐个执行。
具体来说,Fork/Join 包括两个主要的类:
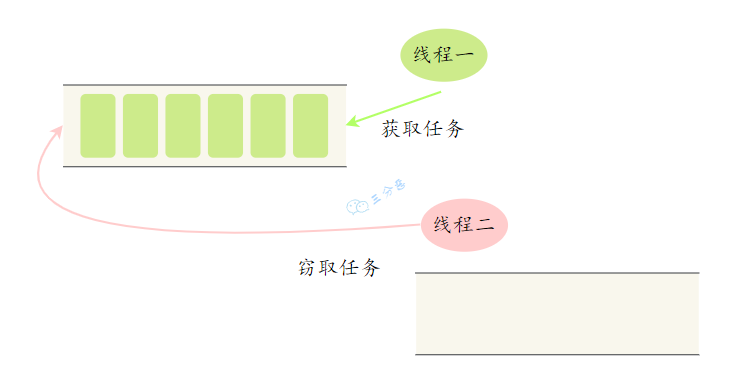
ForkJoinPool,一个特殊的线程池,底层使用了工作窃取算法,也就是当一个线程执行完自己的任务后,它可以窃取其他线程的任务,避免线程闲置。
RecursiveTask 和 RecursiveAction,分别用于有返回值和无返回值的任务,这两个类都继承自 ForkJoinTask。