-
-
物理优化
-
概念
-
物理优化是指在查询树上选择最优的查询路径,该查询路径中的物理访问代价最少,从而提升查询效率
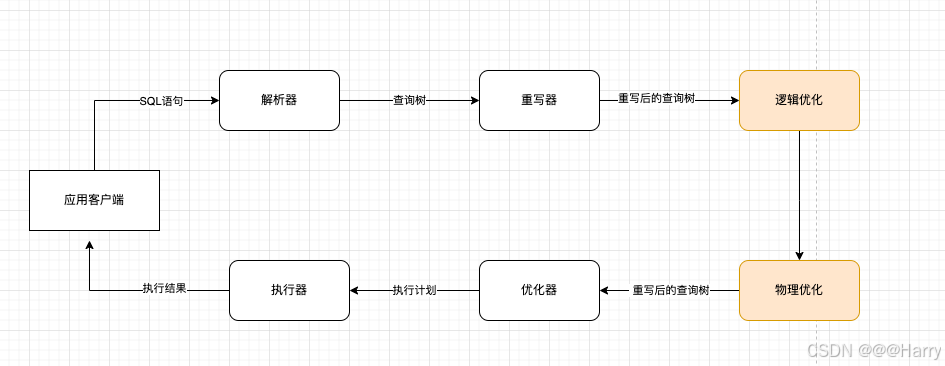
- sql语句的执行过程:客户端将sql语句给解析器,解析器检查sql语句的语义是否正确后,生成查询树给重写器,重写在根据系统表红的规则重写后查询给优化器,优化器生成执行计划给执行器,执行器将结果给客户端显示;那么物理优化的执行过程如图所所示:
-
单表的最优查询路径
-
在进行物理优化时,需要先找出最优的查询路径。由于单表在查询数据上就是叶子结点,而PostgreSQL采用的动态规划算法会最先访问叶子点,再由叶子节点向上层查找访问路径,所以对单表进行优化时实际上只涉及该表的扫描方式的选择,代码示例如下:
explain select * from test.demo where id ='1'; --执行计划 Seq Scan on demo (cost=0.00..0.00 rows=1 width=64) Filter: ((id)::text = '1'::text) -
因为对每个表都可以进行顺序扫描,所以在评估单表的扫描方式,默认都会评估顺序扫描表的代价。如果表中存在一个或多个索引,则需要比较各个索引扫描的代价。
-
物理优化时,先比较扫描表的两种方式(顺序扫描,索引扫描)的扫描代价,并选择其中的一个代价比较小的扫描方式作为该表的物理查询方式。数据的离散型、查询的命中行数以及总行数、表的大小等诸多因素都会影响到物理查询方式,因此表虽然创建了索引,却不一定能用到这个索引,示例代码和车查询计划如下:
CREATE UNIQUE INDEX demo_unique ON test.demo USING btree (id); --查询语句 explain select * from test.demo where id ='1'; --执行计划 Seq Scan on demo (cost=0.00..0.00 rows=1 width=64) Filter: ((id)::text = '1'::text) --虽然新建了索引,优化器最终的选择的扫描方式为顺序扫描。
-
-
-
两个表的最优查询路径
-
如果需要连接两个表,用户则需要考虑怎样连接使得查询效率最高,PostgreSQL有3种连接策略:
-
嵌套循环连接NestedLoop
-
嵌套循环连接会对外表进行扫描,对找到的每一行都需要在内表进行一次扫描,匹配时否满足连接条件。如果内表可以使用索引扫描,那么扫描的速度会加快。这种策略很耗时,但是在有些场景下,他是唯一的选择,以下语句需要对两个表做迪卡尔几的运损啊,因此只能选择嵌套循环连接,示例代码如下:
--sql语句 explain select a.* from test.demo a,test.demo_item b where a.id > b.id; --查询计划 Nested Loop (cost=0.00..24.62 rows=217 width=64) Join Filter: ((a.id)::text > (b.id)::text) -> Seq Scan on demo a (cost=0.00..0.00 rows=1 width=64) -> Seq Scan on demo_item b (cost=0.00..16.50 rows=650 width=32)
-
-
归并连接Merge Semi Join
-
再进行归并连接前,内表与外表分别对关联字段进行排序,然后对两个表进行同步向前forward扫描,皮盆时否满足条件的数据。与嵌套循环连接相比,归并连接更有吸引力,因为每个表都只需扫描一次。当表在排序时,可以通过排序步骤来完成。如果关联字段上有索引,那么会使用索引对表进行扫描,示例代码如下:
--sql语句,本地的数据库是禁用了归并连接,在看查询计划是则使用的是。hash连接方式。 explain select a.* from test.demo a where id in (select demo_id from test.demo_item ) ; --查询计划 Hash Join (cost=18.14..20.90 rows=1 width=64) Hash Cond: ((demo_item.demo_id)::text = (a.id)::text) -> HashAggregate (cost=18.12..20.12 rows=200 width=32) Group Key: (demo_item.demo_id)::text -> Seq Scan on demo_item (cost=0.00..16.50 rows=650 width=32) -> Hash (cost=0.00..0.00 rows=1 width=64) -> Seq Scan on demo a (cost=0.00..0.00 rows=1 width=64)
-
-
Hash连接 Hash join
-
Hash连接首先用的关联字段是Hash关键字,对内表进行扫描,并创建hash表;然后扫描外表,对扫描到的每个行,计算关联字段的hash值,并使用hash值快速定位hash表中的匹配行数据。示例代码如下:
--sql语句,本地的数据库是禁用了归并连接,在看查询计划是则使用的是。hash连接方式。 explain select a.* from test.demo a where id in (select demo_id from test.demo_item ) ; --查询计划 Hash Join (cost=18.14..20.90 rows=1 width=64) Hash Cond: ((demo_item.demo_id)::text = (a.id)::text) -> HashAggregate (cost=18.12..20.12 rows=200 width=32) Group Key: (demo_item.demo_id)::text -> Seq Scan on demo_item (cost=0.00..16.50 rows=650 width=32) -> Hash (cost=0.00..0.00 rows=1 width=64) -> Seq Scan on demo a (cost=0.00..0.00 rows=1 width=64)-
注意
- hash连接对于小表的连接查询效率更高。
-
-
-
超过两个表的最优查询路径
-
如果查询的表个数超过两个,那么在物理优化查询树时,会先将某两个表进行连接,在连接其他表节点或连接另外两表连接后的节点。这种连接方式可以有多种,那么就会有很多种可用的查询路径。理论上,查询优化器会检查每种可用的查询路径,最终选择代价比较小的路径。但是,每当多检查计算一种可能的查询路径的代价,就会消耗更多的时间和内存空间。如果当连接表个数时N,则最大的可能连接次数时N的阶乘,当涉及大量的连接操作时,找到最优的查询路径将非常的耗时。
-
为了在一定时间内决定使用一个合适的查询计划不一定是最佳的查询计划,PostgreSQL的物理优化会根据多表连接的个数来选择是使用动态规划算法还是遗传算法。
- 当连接表的个数小于数据配置中阀值geqo_threshold时,使用动态规划算法。
- 当连接表的个数大于数据配置中阀值geqo_threshold时,使用动态规划算法。
-
-
-
-
-
PostgreSQL- SQL语句的执行过程(二)
@@神农2026-02-20 10:53
相关推荐
早点睡啊Y5 分钟前
深入学LangChain官方文档:Observability 与 Studio——先看清 Agent 到底做了什么@insist12314 分钟前
信息系统管理工程师-数据层知识点详解:存储、数据库与信息安全她说可以呀17 分钟前
Redis集群Lorin 洛林27 分钟前
为什么大模型总会“胡说八道“?一文彻底搞懂 RAG 知识库原理!其实防守也摸鱼42 分钟前
GitHub开源项目破圈方法论:从技术自嗨到生态共赢羑悻的小杀马特1 小时前
AI判不了设备异常?缺的不是算法,是这层数据底座网安墨雨1 小时前
MySQL数据库 SQL语句详解JERRY. LIU1 小时前
VS CODE进行NRF CONNECT项目开发出现变量无法链接跳转问题及解决方法無a伟1 小时前
redis采用的单线程模型,为什么这么快?muddjsv2 小时前
SQLite与MySQL/PostgreSQL本质区别:运行模型、并发、部署、权限全方位对比