前言:看这篇文章先要学会"【初识Linux】:追溯历史演进,上手基础指令"这篇文章的内容,本篇主要讲解一下基础的开发工具,这是以后开发程序必备的。Linux的学习前后关联很强,如果有看不懂的记得先跳过。
目录
[1. 什么是软件包](#1. 什么是软件包)
[2. Linux软件生态](#2. Linux软件生态)
[3. yum具体操作](#3. yum具体操作)
[(1) 基础"增删改查"](#(1) 基础“增删改查”)
[(3) 如何配置"镜像源"](#(3) 如何配置“镜像源”)
[1. vim的基本概念及使用](#1. vim的基本概念及使用)
[2. vim的操作](#2. vim的操作)
[第四部分:Visual Block (可视化块模式)](#第四部分:Visual Block (可视化块模式))
[3. 多文件编辑与多窗口功能](#3. 多文件编辑与多窗口功能)
[4. 配置vim](#4. 配置vim)
[1. g++编译选项](#1. g++编译选项)
[(3) 汇编 (Assembly)](#(3) 汇编 (Assembly))
[(4) 链接 (Linking)](#(4) 链接 (Linking))
[2. 动静态库的简单理解](#2. 动静态库的简单理解)
[3. gcc扩展选项](#3. gcc扩展选项)
[1. makefile的用法](#1. makefile的用法)
[2. make推导原理](#2. make推导原理)
[1. 前备语法知识](#1. 前备语法知识)
[(1)\r (回车) 与 \n (换行) 的区别](#(1)\r (回车) 与 \n (换行) 的区别)
[(2) 缓冲区刷新机制 (Buffering)](#(2) 缓冲区刷新机制 (Buffering))
[(3) printf函数的宽度与对齐](#(3) printf函数的宽度与对齐)
[2. 程序实现](#2. 程序实现)
[1. 什么是版本控制器](#1. 什么是版本控制器)
[2. Git常见命令](#2. Git常见命令)
[(1)git add(圈地)](#(1)git add(圈地))
[(2)git commit(封箱)](#(2)git commit(封箱))
[(3)git push(发货)](#(3)git push(发货))
[1. 准备知识](#1. 准备知识)
[2. 常用指令](#2. 常用指令)
[3. 高阶用法](#3. 高阶用法)
[(2)set var (修改变量)](#(2)set var (修改变量))
一、软件包管理器
1. 什么是软件包
在Linux下安装软件,一个通常的办法是下载到程序的源代码,并进行编译,得到可执行程序。但是这样太麻烦了,于是有些人把一些常用的软件提前编译好,做成软件包(可以理解成windows上的安装程序)放在一个服务器上,通过包管理器可以很方便的获取到这个编译好的软件包,直接进行安装。软件包和软件包管理器,就好比 "App" 和 "应用商店" 这样的关系。
- yum(Yellow dog Updater, Modified)是Linux下非常常用的一种包管理器。主要应用在Fedora, RedHat, Centos等发行版上。
- Ubuntu:主要使用apt(Advanced Package Tool)作为其包管理器。apt同样提供了自动解决依赖关系、下载和安装软件包的功能
2. Linux软件生态
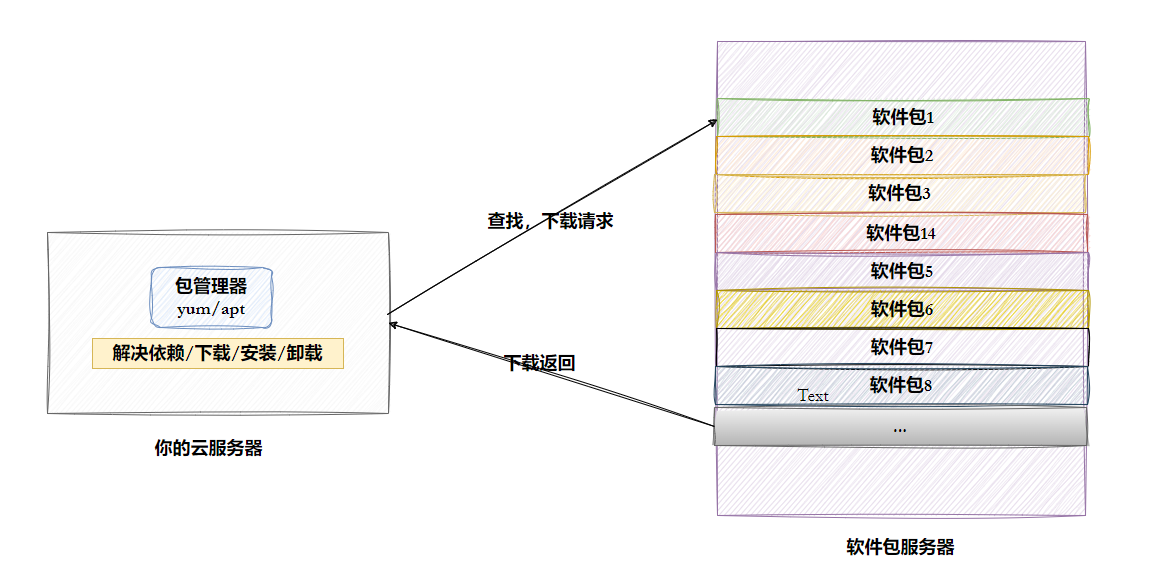
(1)Linux上软件的下载过程
-
输入命令 :如
sudo apt/yum install nginx。 -
索引查询:管家去本地的"菜单"(软件包列表)里找 Nginx 在哪。
-
解析依赖:发现 Nginx 需要 A 库,管家自动把 A 也加入下载名单。
-
从镜像源下载 :从远端服务器把所有需要的
.deb或.rpm拖回来。(包格式) -
解压与配置:自动把文件放到对应目录,并配置好基础环境。
(2)为什么有人免费提供软件和服务器?
这听起来像是在做慈善,但背后有深层的开源文化和商业逻辑:
- 开源精神:像 Linux、Python 这种项目,开发者认为"分享代码能让世界更美好"。大家互相修 Bug,软件会进化得极快。
- 企业赞助:像红帽 (RedHat)、Canonical (Ubuntu 背后公司)、Google、华为等公司,需要一个稳定的生态。他们提供服务器(镜像站)是为了吸引开发者使用他们的标准。
- 品牌与人才:发布高质量开源软件是顶尖程序员的"名片",也是公司技术实力的证明。
- 公益组织:很多大学(如清华、科大)提供镜像站,是为了方便国内用户,减少国际带宽消耗。
(3)什么是软件包依赖问题?
- 原因:Linux 讲究"不重复造轮子"。软件 A 可能用到了处理图片的 B 库,而 B 库又用到了数学计算的 C 库。
- 冲突:如果你装软件 X 需要 C 库的版本 1.0,而装软件 Y 需要 C 库的版本 2.0,系统可能就会"打架"。
- 现代解决方案:现在的 apt 和 dnf 已经非常聪明,能自动计算并解决绝大多数依赖。而像 Docker、Snap 或 Flatpak 这种技术,干脆把所有依赖打包成一个"集装箱",彻底解决了冲突问题。
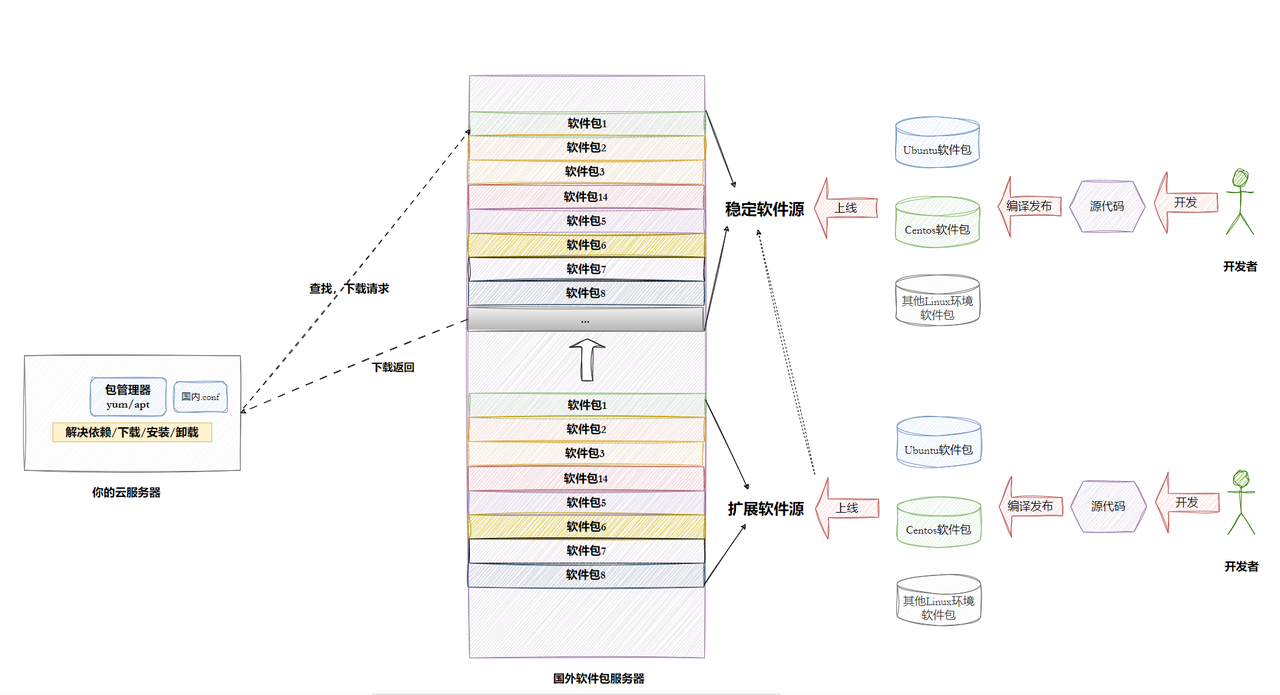
(4)镜像源 (Mirror Sites)
官方的软件服务器通常在国外,下载速度慢得让人抓狂。 镜像源就是官方仓库的"克隆版"。为什么用它? 离你更近,下载速度从几 KB 飙升到几 MB。
- 原理:同步服务器每天定时从官方服务器拉取更新,保持内容一致。
- 常用镜像站:阿里云 (Aliyun)、腾讯云 (Tencent)、清华大学 (TUNA)、中科大 (USTC)。
在 Linux 中,下载安装软件是一场由包管理器 主导的自动化接力:首先,系统根据配置文件中的镜像源 地址,在本地索引清单 中检索目标软件及其依赖项 ;接着,包管理器自动计算并从远端服务器下载所有必要的
.deb或.rpm压缩包,并通过 GPG 数字签名 校验其安全性;随后,系统将这些包解压并按照标准层级结构(如/bin、/lib)分发到各系统目录,完成配置脚本的执行与服务注册;最终,由于 Linux 采用共享库机制,多个软件可以共用同一套底层组件,既节省了空间又方便了统一安全更新,从而构建起一个高效、安全且高度模块化的软件生态。
3. yum具体操作
(1) 基础"增删改查"
这是最常用的四个指令:
-
安装软件:
bashsudo yum install <软件名> # 示例:sudo yum install nginx -
卸载软件:
bashsudo yum remove <软件名> -
更新软件:
bashsudo yum update <软件名> # 更新指定软件 sudo yum update # 更新系统内所有可更新的软件 -
查询软件:
bashyum search <关键词> # 在仓库中搜索 yum info <软件名> # 查看软件的详细描述信息
(2)进阶操作:清理与列表
有时候系统占用空间太大或者索引乱了,就需要这些:
-
清理缓存:
bashyum clean all # 清除下载的缓存包和旧的索引文件 yum makecache # 重新生成一份最新的索引(下载镜像源的"菜单") -
查看已安装软件:
bashyum list installed # 列出所有已经装上的软件
(3) 如何配置"镜像源"
如果你的 yum 下载很慢,说明它在访问国外的官方源。我们需要把它改成国内的。
操作步骤(以 CentOS 7 为例):
- 备份原有的源配置(防止改错):
bash
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup- 下载新的镜像源文件(以阿里云为例):
bash
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo- 刷新缓存:
bash
yum clean all
yum makecache二、编辑器Vim
1. vim的基本概念及使用
vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以在终端运行,也可以运行于x window、 mac os、 windows。
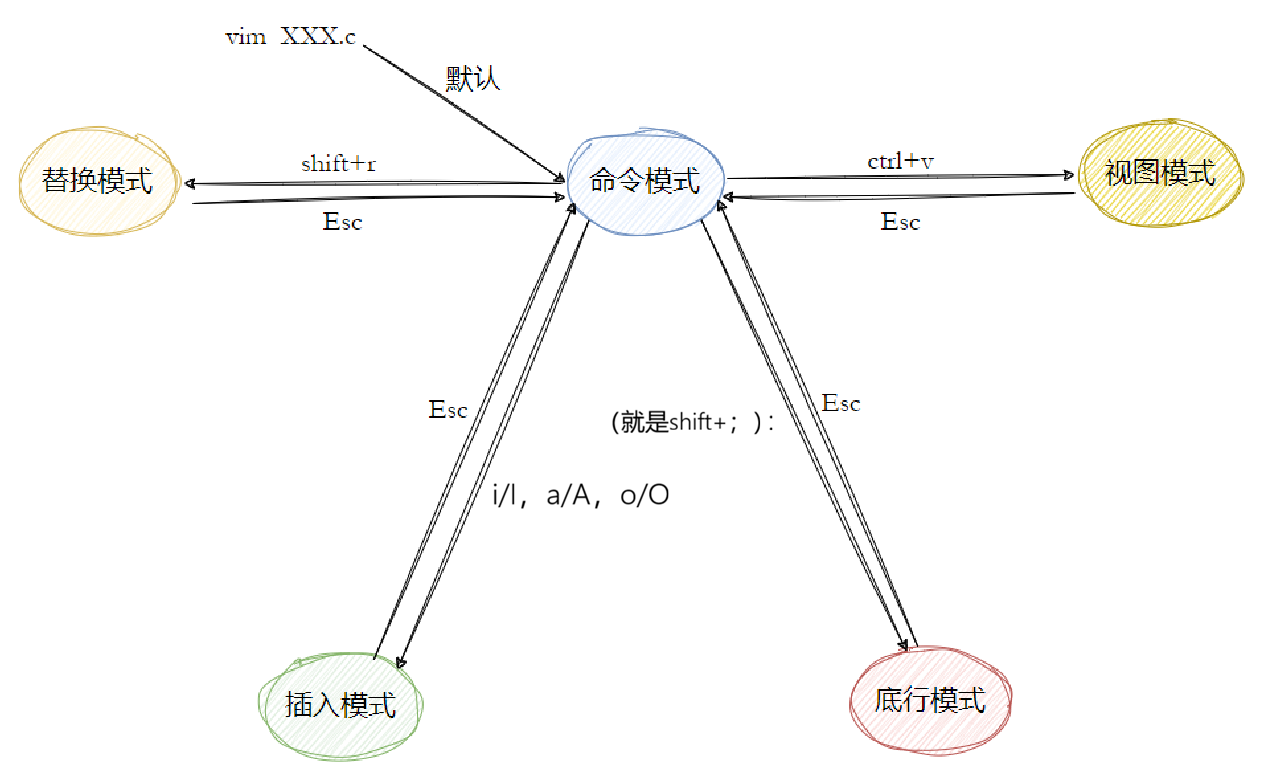
基本上 vi 共分为 3 种模式,分别是一般命令模式 、编辑模式( 包含插入模式与替换模式**)** 与命令行模式, 还有一种视图模式,在某些特定的场景下很有用
(1)一般命令模式 (command mode)
以 vi 打开一个文件就直接进入一般命令模式了(这是默认的模式,也简称为一般模式)。在这个模式中,你可以使用 【上下左右】 按键来移动光标,你可以使用 【删除字符】 或 【删除整行】 来处理文件内容,也可以使用 【复制、粘贴】 来处理你的文件内容。
(2)编辑模式 (insert mode)
在一般命令模式中可以进行删除、复制、粘贴等操作,但是却无法编辑文件的内容。要等到你按下 【i, I, o, O, a, A, r, R】 等任何一个字母之后才会进入编辑模式。注意了,通常在 Linux 中,按下这些按键时,在界面的左下方会出现 【INSERT】 或 【REPLACE】 的字样,此时才可以进行编辑。而如果要回到一般命令模式时,则必须按下 【Esc】 这个按键即可退出编辑模式。
(3)底行模式 (command-line mode)
在一般模式当中,输入 【: / ?】 三个中的任何一个按钮,就可以将光标移动到最下面那一行。在这个模式当中,可以提供你 【查找数据】 的操作,而读取、保存、批量替换字符、退出 vi、显示行号等的操作则是在此模式中完成。
(4)可视化模式 (visual mode)
在一般命令模式中,如果你需要对一个特定的文本区域(而不仅仅是单行或单个字符)进行操作,就可以进入可视化模式。这个模式允许你通过移动光标来"高亮"选中一段文字,然后统一进行删除、复制、更改或格式化。
2. vim的操作
第一部分:命令模式 (移动光标、搜索替换、删除复制粘贴)
(1)光标移动
| 按键 | 功能说明 |
|---|---|
| h 或 左箭头 | 光标向左移动一个字符 |
| j 或 下箭头 | 光标向下移动一个字符 |
| k 或 上箭头 | 光标向上移动一个字符 |
| l 或 右箭头 | 光标向右移动一个字符 |
| Ctrl + f | 屏幕【向下】翻一页 (Page Down) |
| Ctrl + b | 屏幕【向上】翻一页 (Page Up) |
| Ctrl + d | 屏幕【向下】移动半页 |
| Ctrl + u | 屏幕【向上】移动半页 |
| + | 光标移动到非空格符的下一行 |
| - | 光标移动到非空格符的上一行 |
| n<space> | n为数字。光标向右移动这一行的 n 个字符 |
| 0 (数字) | 移动到这一行的最前面字符处 |
| $ | 移动到这一行的最后面字符处 |
| H | 光标移动到屏幕最上方那一行的第一个字符 |
| M | 光标移动到屏幕中央那一行的第一个字符 |
| L | 光标移动到屏幕最下方那一行的第一个字符 |
| G | 移动到这个文件的最后一行 |
| nG | 移动到这个文件的第 n 行 (配合 :set nu) |
| gg | 移动到这个文件的第一行 (相当于 1G) |
| n<Enter> | 光标向下移动 n 行 |
(2)查找与替换
| 按键 | 功能说明 |
|---|---|
| /word | 向光标【之下】寻找名为 word 的字符串 |
| ?word | 向光标【之上】寻找名为 word 的字符串 |
| n | 重复前一个查找操作 (同向) |
| N | 反向进行前一个查找操作 |
| :n1,n2s/w1/w2/g | 在第 n1 与 n2 行之间寻找 w1 并替换为 w2 举例来说,在 100 到 200 行之间查找 vbird 并替换为 VBIRD ,则":100,200s/vbird/ VBIRD/g" |
| :1,$s/w1/w2/g | 从第一行到最后一行寻找 w1 并替换为 w2 |
| :1,$s/w1/w2/gc | 替换前显示提示字符给用户确认 (confirm) |
(3)删除、复制与粘贴
| 按键 | 功能说明 |
|---|---|
| x 与 X | x 为向后删除一个字符;X 为向前删除一个字符 |
| nx | 连续向后删除 n 个字符 |
| dd | 删除(剪切)光标所在的那一整行 |
| ndd | 删除(剪切)从光标所在的向下 n 行 |
| d1G | 删除光标所在到第一行的所有数据 |
| dG | 删除光标所在到最后一行的所有数据 |
| d$ | 删除光标所在处,到该行的最后一个字符 |
| d0 | 删除光标所在处,到该行的最前面一个字符 |
| yy | 复制光标所在的那一行 |
| nyy | 复制光标所在的向下 n 行 |
| y1G | 复制光标所在行到第一行的所有数据 |
| yG | 复制光标所在行到最后一行的所有数据 |
| y0 | 复制光标所在字符到行首的所有数据 |
| y$ | 复制光标所在字符到行尾的所有数据 |
| p 与 P | p 粘贴在下一行;P 粘贴在上一行 |
| J | 将光标所在行与下一行数据结合成同一行 |
| c | 重复删除多个数据 (如 10cj 删除 10 行并进入编辑模式) |
| u | 复原前一个操作 (Undo) |
| Ctrl + r | 重做上一个操作 (Redo) |
| . (小数点) | 重复前一个动作 |
第二部分:一般模式切换到插入或替换的编辑模式
| 按键 | 功能说明 |
|---|---|
| i 与 I | 进入插入模式 (Insert mode): i 从目前光标处插入;I 从目前所在行的第一个非空格符处开始插入 |
| a 与 A | 进入插入模式 (Insert mode): a 从目前光标处的下一个字符开始插入;A 从光标所在行的最后一个字符处开始插入 |
| o 与 O | 进入插入模式 (Insert mode): o 在目前光标所在的下一行插入新的一行;O 在目前光标所在的上一行插入新的一行 |
| r 与 R | 进入替换模式 (Replace mode): r 取代光标所在的那个字符一次;R 一直取代文字直到按 Esc 为止 |
| Esc | 退出编辑模式,回到一般命令模式 |
上面这些按键中,在vim界面的左下角处会出现--INSERT一或I--REPLACE--]的字样。由名称就知道该操作了吧!特别注意的是,我们上面也提过,你想要在文件里面输入字符时,一定要在左下角处看到INSERT或REPLACE才能输入。
第三部分:底行模式 (保存、退出与环境设置)
| 命令 | 功能说明 |
|---|---|
| :w | 将编辑的数据写入硬盘文件中 |
| :w! | 若文件属性为只读,强制写入该文件 (视权限而定) |
| :q | 退出 vi |
| :q! | 若曾修改过文件又不想保存,强制退出不保存 |
| :wq | 保存后退出 (若为 :wq! 则为强制保存后退出) |
| ZZ | 这是大写的 Z。若文件没有更改则不保存退出;若已更改则保存退出 |
| :w filename | 将编辑的数据另存为另一个文件 |
| :r filename | 在编辑的数据中,读入另一个文件的数据,加在光标所在行后面 |
| :n1,n2 w filename | 将 n1 到 n2 的内容保存为 filename 这个文件 |
| :! command | 暂时退出 vi 到命令行模式下执行 command 并显示结果 (如 :! ls /home) |
| :set nu | 显示行号 |
| :set nonu | 取消显示行号 |
第四部分:Visual Block (可视化块模式)
| 模式名称 | 快捷键 | 选中范围描述 |
|---|---|---|
| 字符选择 | v (小写) | 以字符为单位灵活选择 |
| 行选择 | V (大写) | 选中整行,光标上下移动增加行 |
| 块选择 | Ctrl + v | 选中一个矩形垂直区域 |
| 复制块 | y | 选中区域后按下 y,该矩形块会被存入剪贴板(寄存器) |
| 剪切块 | d 或 x | 选中区域后按下 d,删除该区域并存入剪贴板 |
| 粘贴块 | p 或 P | 将光标移至目标位置,按下 p (后粘贴) 或 P (前粘贴) |
如何添加多行注释?
- 定位光标:把光标停在你要注释的第一行的最前面。
- 开启块模式:按下 Ctrl + v。
- 垂直选中:按 j(或者下箭头)一直移动到最后一行。你会看到所有行的第一个字符都被选中了。
- 准备插入:按下大写的 I(注意是 Shift + i)。此时光标会回到第一行。
- 输入内容:输入 C++ 的注释符 //。
- 触发同步:最后按 两下 Esc。
如何删除多行注释?
- 定位光标:把光标停在第一行注释符 // 的第一个斜杠上。
- 开启块模式:按下 Ctrl + v。
- 精准选中:先按 l(向右)选中两个斜杠。再按 j(向下)拉到底。
- 一键删除:直接按 d 键。所有的注释符就瞬间消失了。
特别注意,在vim中,【数字】是很有意义的,数字通常代表重复做几次的意思,也有可能是代表去到第几个什么什么的意思。举例来说,要删除(剪切)50行,则是用【50dd】。数字加在操作之前,那我要向下移动20行呢?那就是【20j】即可。
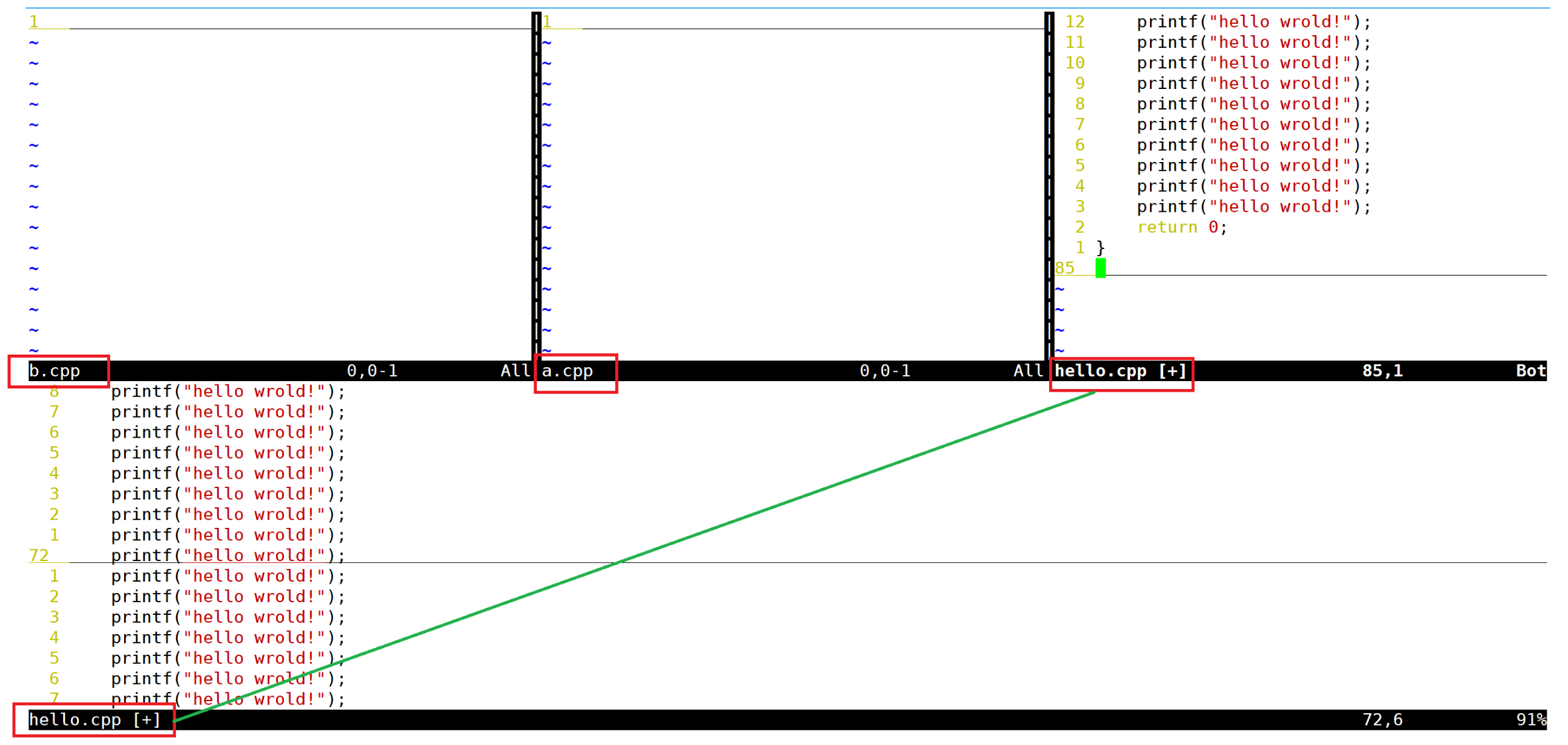
3. 多文件编辑与多窗口功能
(1)多文件编辑
当你需要同时打开多个文件(例如:一个源代码文件 main.c 和一个头文件 header.h)时,可以使用以下方法。
bash
vim file1.txt file2.txt file3.txt核心指令(底行模式)
-
:n(next):切换到下一个文件。 -
:N:切换到上一个文件。 -
:files或:ls:列出当前所有打开的文件,正在编辑的文件前会有一个%a标志。
(2)多窗口功能
当我有一个文件非常的大,我查看到后面的数据时,想要对照前面的数据,是否需要使用ctri+f 与ctrl+b(或PageUp、PageDown功能键)来跑前跑后查看?我有两个需要对照着看的文件,不想使用前一小节提到的多文件编辑功能怎么办?
在一般窗口界面下的编辑软件大多有【划分窗口】或是【冻结窗口】的功能来将一个文件划分成多个窗口的展现,那么vim能不能达到这个功能?可以,但是如何划分窗口并放入文件?很简单,在命令行模式输入【:sp 文件名】即可。这个filename可有可无,如果想要在新窗口启动另一个文件就加入文件名,否则仅输入:sp时,出现的则是同一个文件在两个窗口间。
| 按键 | 功能 |
|---|---|
| :(v)sp filename | sp水平分割窗口。如果不加文件名,则水平拆分当前文件。 vsp垂直分割窗口(最常用,适合宽屏)。 |
先按 Ctrl + w,然后按方向键 |
调整光标位置 |
先按 Ctrl + w,然后按+/-/= |
调整窗口大小 |
| :q | 关闭当前所在窗口 |
| :only | 仅保留当前窗口,关闭其他所有窗口。 |
4. 配置vim
在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为:".vimrc"。例如,/root目录下,通常已经存在一个.vimrc文件,如果不存在,则创建之。切换用户成为自己执行 su ,进入自己的主工作目录,执行 cd ~。打开自己目录下的.vimrc文件,执行 vim .vimrc。在里边就可以添加各种配置了,下面我展示一下我的配置。
bash
" --- 基础设置 ---
set number " 显示行号 (对应表格中的 :set nu)
set relativenumber " 显示相对行号(方便 20j 这种跳行操作)
set syntax=on " 开启语法高亮
set encoding=utf-8 " 使用 utf-8 编码
set cursorline " 高亮显示当前行
" --- 缩进设置 ---
set tabstop=4 " Tab 键宽度设置为 4 个空格
set shiftwidth=4 " 自动缩进宽度设置为 4 个空格
set expandtab " 将 Tab 转换为空格
set autoindent " 自动缩进
" --- 搜索设置 ---
set hlsearch " 高亮显示搜索结果
set incsearch " 开启增量搜索(边输入边匹配)
set ignorecase " 搜索时忽略大小写
set smartcase " 如果搜索词包含大写,则不忽略大小写
" --- 辅助功能 ---
set showmode " 底部显示当前模式(INSERT, REPLACE 等)
set showcmd " 底部显示输入的命令
set wildmenu " 命令模式下 Tab 补全提示
" --- C++ 风格缩进 ---
set cindent " 使用 C 语言类型的自动缩进
set cinoptions=g0,:0,N-s,(0 " 调整 C++ 作用域、冒号等缩进细节
" --- 括号自动补全 ---
" 输入左括号自动补全右括号并把光标移到中间
inoremap ( ()<ESC>i
inoremap [ []<ESC>i
inoremap { {<CR>}<ESC>O
inoremap ' ''<ESC>i
inoremap " ""<ESC>i
" --- 增强显示 ---
set ruler " 在右下角显示光标位置
set laststatus=2 " 总是显示状态栏三、编译器gcc/g++
1. g++编译选项
(1)预处理 (Preprocessing)
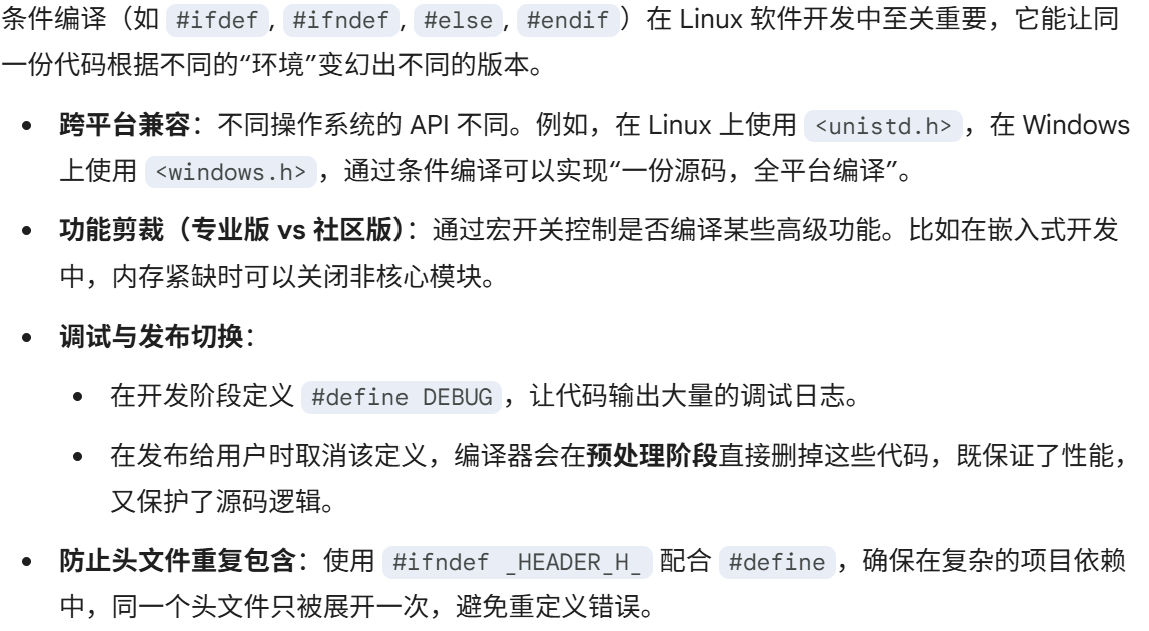
这是**"整理素材"**的阶段。编译器还没开始读你的核心逻辑,它先处理那些以 # 开头的指令。
-
头文件展开 :把
#include <stdio.h>里的内容直接"复制粘贴"到你的代码顶端。 -
宏替换 :把代码里定义的
#define MAX 100全部换成数字100。 -
去注释 :把所有
//和/* */的文字删掉(机器不需要读你的备注)。 -
条件编译 :根据
#ifdef等判断哪些代码留下,哪些删掉。 -
结果 :生成一个后缀名为
.i的文件。
bash
gcc -E test.c -o test.i为什么要有条件编译?
(2)编译 (Compilation)
这是**"翻译官"**的工作。编译器检查你的语法对不对,然后把 C 语言翻译成汇编语言。
-
语法检查:如果你少写了个分号,这一步就会报错。
-
翻译 :汇编语言是比 C 语言更底层的语言,它直接描述 CPU 的动作(如
mov,push,add)。 -
结果 :生成一个后缀名为
.s的文件。
bash
gcc -S test.i -o test.s(3) 汇编 (Assembly)
这是**"编码器"**的工作。汇编语言虽然底层,但人类还能勉强看懂。现在要把汇编翻译成真正的二进制指令。
-
转换:将汇编指令逐句转换成机器码(0 和 1)。
-
结果 :生成一个后缀名为
.o(Object File)的目标文件。它是二进制的,但还不能运行。
bash
gcc -c test.s -o test.oC/C++编译为什么要先变成汇编?
将 C/C++ 先转换为汇编是为了实现架构解耦与工程分工:通过汇编语言这一"人类可读的指令抽象层",编译器可以专注于语法解析与逻辑优化,而将繁琐的二进制转换交给专门的汇编器,既降低了跨平台开发的复杂度,也为开发者提供了底层的调试透明度与性能调优窗口。
什么是编译器的自举?要实现一个语言的自举,通常需要经历一个递归演进的过程。假设我们要让一种新语言 L 实现自举,阶段一,借壳生蛋(The Seed) :开发者先用一种现有的语言(比如 C 或汇编)编写 L 语言的一个简化版编译器(编译器 A)。此时,编译器 A 的二进制文件是由 C 编译器生成的。阶段二,自我重写(The Shift) :开发者用 L 语言重新编写 L 编译器的源代码(源代码 B)。然后,使用阶段一得到的二进制编译器 A 来编译源代码 B。结果就是得到了一个由 L 语言编写、并由 L 编译器生成的二进制文件(编译器 B)。**阶段三,完全自举(Full Bootstrap):**由于编译器 B 已经具备了处理 L 语法的功能,此后所有的编译器更新和优化都可以直接用 L 编写,并由编译器 B 自己编译自己。
为什么要搞自举?
- 语言能力的终极测试:如果一个编译器能编译自己,说明这种语言的逻辑表达能力、内存管理和复杂计算已经足够成熟,足以处理真实世界的重型任务。
- 生态闭环:开发者只需要掌握 L 语言,就可以改进 L 编译器,而不需要再去学习 C 或汇编。
- 优化循环:当你改进了编译器的优化算法,你重新编译一次编译器本身,编译器执行得更快,进而导致它以后生成的程序也更快。
(4) 链接 (Linking)
这是**"拼图重组"**的最后一步,也是最关键的一步。
-
合并模块 :你的程序可能用到了
printf函数。这个函数的二进制实现并不在你的test.o里,而是在系统的标准库(如libc.so)里。 -
地址重定向 :链接器负责把你的
test.o和系统库文件"缝合"在一起,给函数调用分配准确的内存地址。 -
结果 :生成最终的可执行文件 (Linux 下默认叫
a.out,你也可以指定名字)。
bash
gcc test.o -o my_program
bash
[yhz@VM-0-5-opencloudos ~]$ cd lesson6
[yhz@VM-0-5-opencloudos lesson6]$ cat test.c
#include <stdio.h>
int main()
{
printf("hello!");
return 0;
}
[yhz@VM-0-5-opencloudos lesson6]$ ll
total 4
-rwxrwxrwx 1 yhz yhz 71 Feb 12 21:00 test.c
[yhz@VM-0-5-opencloudos lesson6]$ gcc -E test.c -o test.i
[yhz@VM-0-5-opencloudos lesson6]$ ll
total 24
-rwxrwxrwx 1 yhz yhz 71 Feb 12 21:00 test.c
-rw-r--r-- 1 yhz yhz 18790 Feb 12 21:02 test.i
[yhz@VM-0-5-opencloudos lesson6]$ gcc -S test.c -o test.s
[yhz@VM-0-5-opencloudos lesson6]$ ll
total 28
-rwxrwxrwx 1 yhz yhz 71 Feb 12 21:00 test.c
-rw-r--r-- 1 yhz yhz 18790 Feb 12 21:02 test.i
-rw-r--r-- 1 yhz yhz 495 Feb 12 21:03 test.s
[yhz@VM-0-5-opencloudos lesson6]$ gcc -c test.c -o test.o
[yhz@VM-0-5-opencloudos lesson6]$ gcc test.o -o test
[yhz@VM-0-5-opencloudos lesson6]$ ll
total 40
-rwxr-xr-x 1 yhz yhz 8120 Feb 12 21:05 test
-rwxrwxrwx 1 yhz yhz 71 Feb 12 21:00 test.c
-rw-r--r-- 1 yhz yhz 18790 Feb 12 21:02 test.i
-rw-r--r-- 1 yhz yhz 1536 Feb 12 21:04 test.o
-rw-r--r-- 1 yhz yhz 495 Feb 12 21:03 test.s
[yhz@VM-0-5-opencloudos lesson6]$ ./test
hello!
[yhz@VM-0-5-opencloudos lesson6]$ gcc test.c -o test2
#直接一步到位
[yhz@VM-0-5-opencloudos lesson6]$ ll
total 48
-rwxr-xr-x 1 yhz yhz 8120 Feb 12 21:05 test
-rwxr-xr-x 1 yhz yhz 8120 Feb 12 21:11 test2
-rwxrwxrwx 1 yhz yhz 71 Feb 12 21:00 test.c
-rw-r--r-- 1 yhz yhz 18790 Feb 12 21:02 test.i
-rw-r--r-- 1 yhz yhz 1536 Feb 12 21:04 test.o
-rw-r--r-- 1 yhz yhz 495 Feb 12 21:03 test.s
[yhz@VM-0-5-opencloudos lesson6]$ ./test2
hello!2. 动静态库的简单理解
(1)库的概念
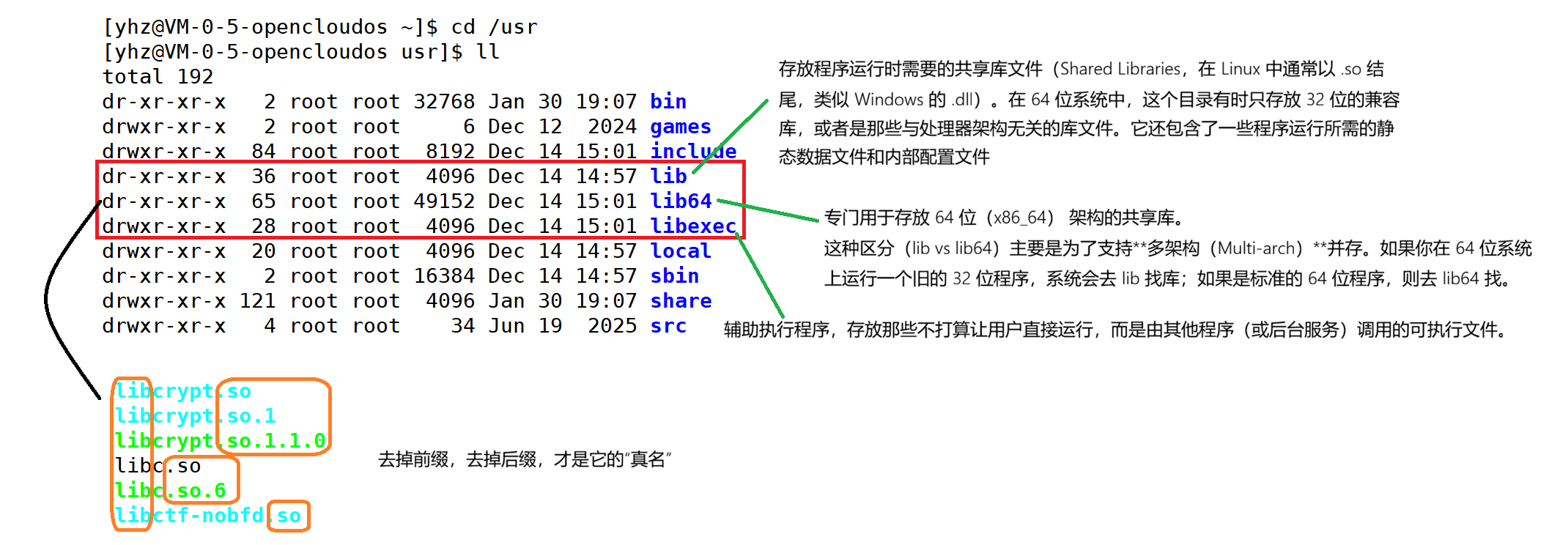
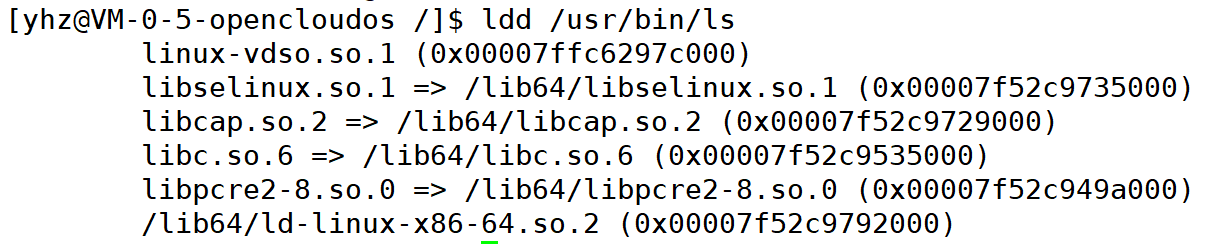
我们的C程序中,并没有定义"printf"的函数实现,且在预编译中包含的"stdio.h"中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实"printf"函数的呢?最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径"/usr/lib"下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数"printf"了,而这也就是链接的作用。
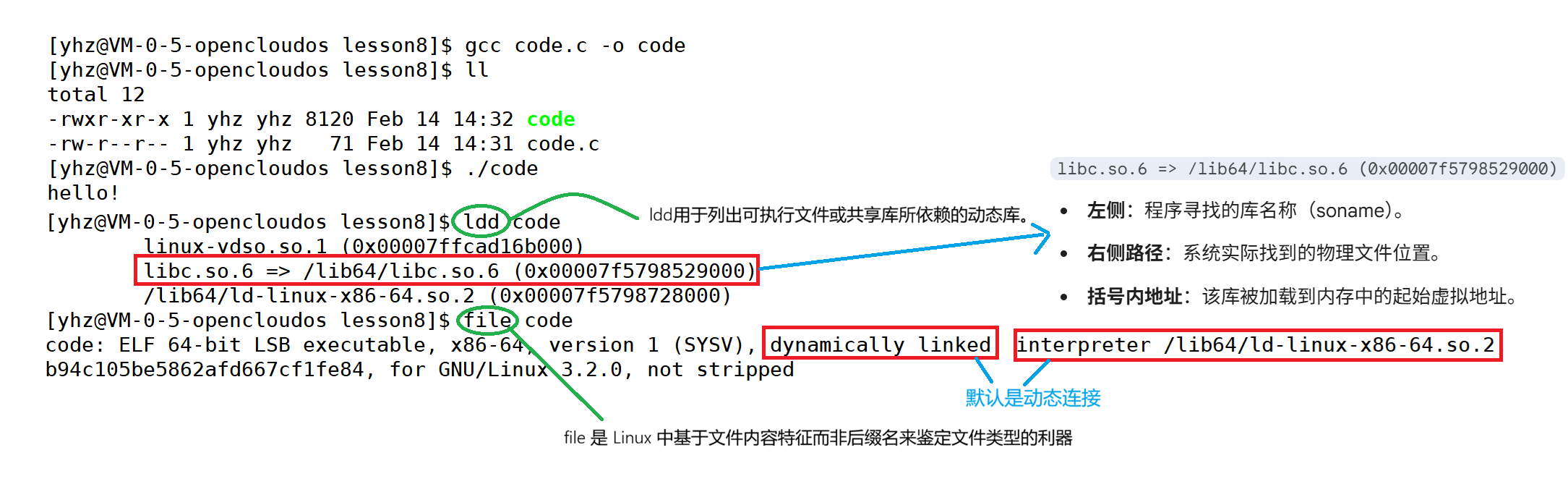
(2)动态库与动态链接
动态库/共享库(在Linux下通常以.so结尾)是动态链接机制的核心产物。你可以把它理解为一种特殊的、可执行的目标文件,它不是被复制到最终的程序中,而是被设计出来供多个正在运行的程序同时使用。
动态链接就像是将程序所需的公共功能比作分布在城市各处的公共图书馆,程序本身不携带沉重的书籍,而只保留一份索引,待到运行时才由系统"导航员"负责按需检索并加载相关知识到内存中。动态链接将将分散的代码和数据组装成可执行文件的过程推迟到程序加载或运行时,链接器在编译时仅检查动态库(.so)的接口,并将库的依赖信息记录在可执行文件中,生成一个"半成品",当程序被执行时,由系统加载的动态链接器(ld-linux.so)负责将所需的共享库加载到内存,并通过延迟绑定等技术完成最终的符号解析和地址重定位,使得多个程序可以共享内存中的同一份库代码。
我们很多指令就是用C语言写的
优点:
- 可执行文件小:只包含自己的代码,不包含库代码。
- 节省内存:系统只需将动态库(如 libc.so)加载到物理内存一次,所有运行中的程序共享这份代码(共享内存页)。
- 更新方便:更新动态库文件 (.so) 后,下次运行程序时,新程序会自动使用新版库(前提是接口兼容)。
缺点:
- 部署复杂:必须确保目标系统存在正确版本的动态库(所谓的"依赖地狱")。
- 启动稍慢:程序启动时需要动态链接器工作,进行符号查找和重定位(尽管有延迟绑定优化)。
- 性能略有损失:通过 PLT/GOT 的间接调用比直接调用多一次寻址,有一定微小开销
(3)静态库与静态链接
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为".a"。静态链接 发生在编译的最终阶段 ,链接器(ld)直接将程序所需的库代码从静态库(.a)中复制 出来,与目标文件(.o)合并,经过符号解析和地址重定位后,生成一个完全独立、自包含的可执行文件。
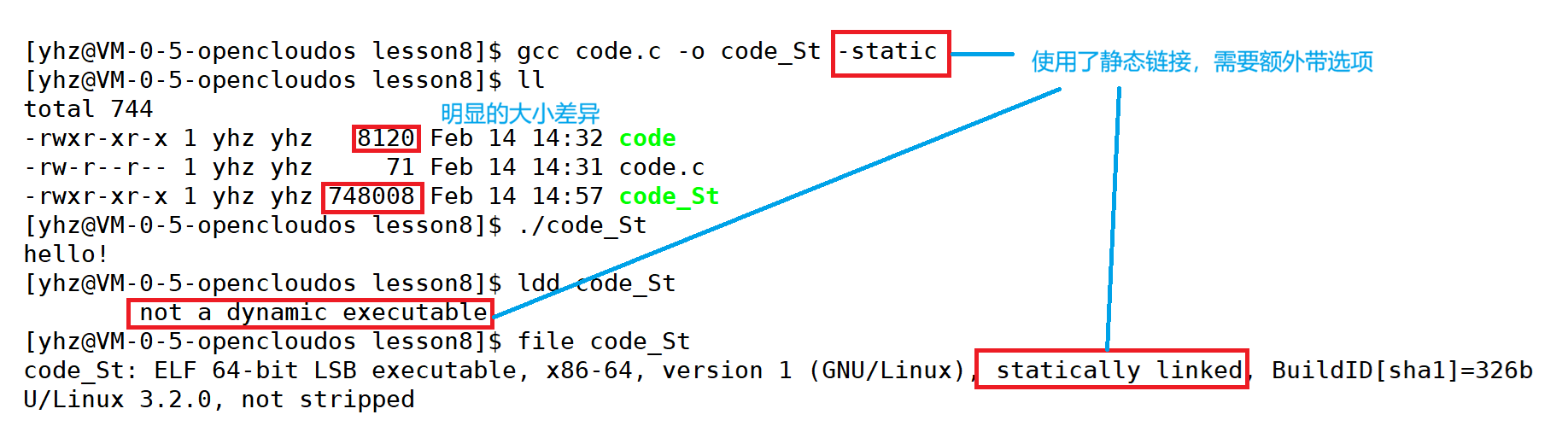
优点:
- 部署简单:可执行文件包含了所有运行所需,不依赖外部环境。
- 运行速度快:函数调用在编译时已解析为绝对地址,没有运行时查找开销。
- 移植性好:只要目标系统架构相同,拷贝过去就能运行。
缺点:
- 体积大:每个程序都包含公共库(如 libc)的副本,浪费磁盘空间。
- 内存占用高:如果多个程序同时运行,它们各自持有的公共库代码会在物理内存中重复加载,浪费内存。
- 更新困难:如果库(如 libc)有安全更新,必须重新链接所有依赖它的静态链接程序,然后重新部署。
一般云服务器是不自带静态库的,需要自己安装
bashsudo yum install glibc-static libstdc++-static -y
(4)动态库的本质
- 位置无关 :这是它的核心特性。动态库被编译成了一种特殊代码,使得它被加载到内存的任何地址都能正确执行。这为它在多进程间的共享打下了基础。
- 物理内存的共享 :动态库的代码段被设计为可共享 的。如果系统里同时运行着100个进程,它们都依赖
libc.so,那么物理内存中只存在一份libc.so的代码副本 。这100个进程通过虚拟内存机制,共享这同一份物理内存页。这是它被称为"共享库"的原因。 - 独立更新能力 :因为程序不包含库代码,只包含引用,所以修复动态库的Bug(如
libc.so的安全漏洞)时,只需要替换硬盘上的这一个.so文件,然后重启程序。所有依赖它的程序会自动获得修复,无需重新编译。
从技术底层来看,库(Library) 不仅仅是代码的集合,它是二进制级别的模块化封装 。它是将源代码经过预处理、编译生成的多个目标文件(
.o文件)打包后的产物,旨在实现"一次编译,到处链接"。
3. gcc扩展选项
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
- -S 编译到汇编语言不进行汇编和链接
- -c 编译到目标代码
- -o 文件输出到 文件
- -static 此选项对生成的文件采用静态链接
- -g 生成调试信息。GNU 调试器可利用该信息。
- -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库。
- -O0/O1/O2O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
- -w 不生成任何警告信息。
- -Wall 生成所有警告信息。
四、自动化构建make/Makefile
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为一种在工程方面的编译方法。
make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建。
1. makefile的用法
(1)核心规则
bash
目标(target): 依赖(prerequisites)
<Tab>命令(command)-
目标 :通常是要生成的文件名(如可执行文件或
.o文件),也可以是一个"伪目标",代表一个操作标签。 -
依赖:生成目标所依赖的文件或其他目标。
-
命令 :通过依赖生成目标需要执行的Shell命令。命令行前面必须是一个 Tab 键,不能是空格
假设我们有
main.c和hello.c两个源文件,一个基础的 Makefile 可以这样写:
bash# 最终目标:生成可执行文件 app app: main.o hello.o gcc main.o hello.o -o app # main.o 的生成规则 main.o: main.c gcc -c main.c -o main.o # hello.o 的生成规则 hello.o: hello.c gcc -c hello.c -o hello.o # 清理规则(伪目标) clean: rm -f app *.o在命令行输入
make,它会找到第一个目标app,发现依赖.o文件不存在,就会先执行下面的规则生成.o文件,最后生成app。输入make clean,就会执行rm命令。
(2)伪目标
它本质上只是一个标签 或名字 ,而不是一个真正的文件名, 使用 .PHONY 来明确告诉 make。在第一节我们讲了文件的三个时间,如果不是伪目标,它只用改动了时间才会被执行(具体后面会讲),而伪目标每次都会被执行,伪目标可以有依赖项。
bash
.PHONY: force
force: # 这个目标永远都会执行
# 利用这个特性强制重新编译
main.o: main.c force
gcc -c main.c -o main.o
# 每次 make 都会重新编译 main.o,因为 force 总是"新的"
cpp
.PHONY: clean cleanall cleanall # 可以连续声明多个
.PHONY: all clean install # 或者一行写多个(3)进阶用法:简化与通用

2. make推导原理
(1)基于文件时间戳的增量编译
这是 Make 实现"只编译修改过的文件"这一核心功能的基础。
-
当
make执行一条规则时,它会比较目标文件 和依赖文件的最后修改时间。 -
如果依赖文件比目标文件新 (意味着你修改了代码后还没重新编译),或者目标文件不存在 (首次编译),那么
make就认为目标需要更新,于是执行规则中定义的命令。 -
如果目标文件比所有依赖文件都新 ,说明自上次编译后没有改动过任何文件,
make就会跳过这条规则,什么都不做。这在大型项目中能节省大量编译时间。
(2)依赖链的递归推导
- make会在当前目录下找名字叫"Makefile"或"makefile"的文件。如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到 app 这个文件,并把这个文件作为最终的目标文件。
- 如果 app 文件不存在,或是 app 所依赖的后面的 main.o ,hello.o 文件的文件修改时间要比 app 这个文件新(可以用 touch 测试),那么,他就会执行后面所定义的命令来生成 app 这个文件。
- 如果 app 所依赖的 main.o ,hello.o 文件不存在,那么 make 会在当前文件中找目标为 myproc.o 文件的依赖性,如果找到则再根据那一个规则生成 main.o ,hello.o 文件。(这有点像是一个堆栈的过程)
- 当然,你的C文件和H文件是存在的,于是 make 会生成 main.o hello.o 文件,然后再用 main.o hello.o 文件声明 make 的终极任务,也就是执行文件 app 了。
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起,我就不工作了。
bash
#后面进度条的例子
[yhz@VM-0-5-opencloudos progressbarv2]$ make
g++ main.c -o proc
[yhz@VM-0-5-opencloudos progressbarv2]$ ./proc
[======......][100%][|]
download 1030.00MB Done
[yhz@VM-0-5-opencloudos progressbarv2]$ make clean
rm -f proc五、进度条程序练习
1. 前备语法知识
(1)\r (回车) 与 \n (换行) 的区别
这是实现进度条在"原地"变长的核心技巧。
-
\n:将光标移到下一行的行首。如果使用它,进度条会像刷屏一样,每一帧都占一行。 -
\r:将光标移回当前行 的行首 。由于光标回到了开头,下一次printf的内容会直接覆盖掉当前行已经显示的文字。 -
覆盖逻辑 :
printf本身并不具备"擦除"功能,它只是简单的"重写"。如果你新打印的字符串比旧的短,旧字符串末尾多出的部分就会残留下来(就像你之前遇到的90现象)。
(2) 缓冲区刷新机制 (Buffering)
-
行缓冲 (Line Buffering) :标准输出(
stdout)通常是行缓冲的。这意味着,除非程序读到了\n,或者缓冲区满了,否则数据会暂时存在内存里,不发给屏幕。 -
进度条的冲突 :因为我们要用
\r留在同一行,没有\n触发刷新,系统可能会一直攒着数据不显示,直到程序结束。 -
fflush(stdout):它的作用是强行"冲刷"缓冲区,告诉系统:"不管有没有换行符,立刻把现在缓冲区里的东西打印出来!"
(3) printf函数的宽度与对齐
-
右对齐(默认) :
%5d表示该整数至少占用 5 个字符宽。如果数字只有两位,左边会补空格。 -
左对齐 :使用负号
-。例如%-5d也会占用 5 个字符宽,但数字靠左,空格补在右边。 -
补零 :使用
0。例如%05d,如果数字不足 5 位,左边会用0填充(常用于日期或编号)。
2. 程序实现
(1)实现结果
(2)简易版
cpp
#include<stdio.h>
#include<unistd.h>
#include<string>
int main()
{
std::string buff;
char rev[4]={'|','/','-','\\'};
for(int i=0;i<=100;i++)
{
printf("[%-100s][%-3d%%][%c]\r",buff.c_str(),i,rev[i%4]);
fflush(stdout);
buff+="=";
usleep(100000);
}
printf("\n");
return 0;
}这个思路很简单,分三部分打印就行,但是现实中我们要根据下载速度,每次下载时的网速来确定,这样直接拿个循环下载肯定扯,下面我们来模拟实际情况
(3)实用版
cpp
//p.h
#include <stdio.h> // printf 和 fflush
#include <unistd.h> // usleep
#include <string> // string
using namespace std;
void progress(int sum, int cut)
{
// 1. 准备旋转光标和百分比逻辑
string ves = "|/-\\";// 这里的 \\ 经过转义后代表一个真正的 \
int num = cut * 100 / sum;
// 2. 构造进度条字符串
// 直接构造一个含有 num 个 '=' 的字符串,比 for 循环累加更高效
string buff(num, '=');
// 3. 使用 printf 格式化输出
printf("[%-100s][%-3d%%][%c]\r", buff.c_str(), num, ves[num % 4]);
// 4. 强制刷新缓冲区,确保实时显示
fflush(stdout);
}
cpp
//main.c
#include "p.h"
double total = 1024.0;
double speed = 10.0;
void DownLoad()
{
double current = 0;
while(current <= total)
{
progress(total, current);
usleep(300000); // 充当下载数据
current += speed;
}
progress(total, total); // 防止除法向下取整到99
printf("\ndownload %.2lfMB Done\n", current);
}
int main()
{
DownLoad();
return 0;
}
bash
# makefile(标准)
# 1. 定义变量,方便后续修改
CC = g++
TARGET = proc
SRC = main.cpp
OBJ = $(SRC:.cpp=.o)
CFLAGS = -Wall -g # 开启警告并生成调试信息
# 2. 最终目标:链接
$(TARGET): $(OBJ)
$(CC) $(OBJ) -o $(TARGET)
# 3. 编译:将 .cpp 编为 .o
# 这里利用了推导原理:如果 main.cpp 或 p.h 变了,就会重新编译
%.o: %.cpp p.h
$(CC) $(CFLAGS) -c $< -o $@
# 4. 伪目标:清理生成文件
.PHONY: clean
clean:
rm -f $(TARGET) $(OBJ)六、版本控制器Git
1. 什么是版本控制器
为了能够更方便我们管理这些不同版本的文件,便有了版本控制器。所谓的版本控制器,就是能让你了解到一个文件的历史,以及它的发展过程的系统。通俗的讲就是一个可以记录工程的每一次改动和版本迭代的一个管理系统,同时也方便多人协同作业。目前最主流的版本控制器就是 Git 。Git 可以控制电脑上所有格式的文件,例如 doc、excel、dwg、dgn、rvt等等。对于我们开发人员来说,Git 最重要的就是可以帮助我们管理软件开发项目中的源代码文件!一般我们就用到两个网站一个是Gitee,一个是GitHub(这个是国外的,需要科技)。
2. Git常见命令
(1)git add(圈地)
作用: 把修改过的文件添加到"暂存区"(Index)。
常用命令: git add ./文件名 (点代表当前目录下所有改动)
比喻: 就像寄快递前,先把要寄的东西放进打包纸箱里。
(2)git commit(封箱)
作用: 把暂存区的内容正式提交到"本地仓库",并生成一个版本号。
常用命令: git commit -m "这里写你的提交说明"
注意: -m 后面必须写有意义的备注(如 "完成课后作业8"),否则以后翻看日志会很痛苦。
比喻: 胶带封箱,并在箱子上贴个标签写明里面是什么。
(3)git push(发货)
作用: 把本地仓库的记录上传到远程服务器(GitHub/Gitee)。
常用命令: git push
比喻: 快递员把箱子搬上车,运送到目的地。
bash
[yhz@VM-0-5-opencloudos linux-learning]$ touch test.cpp
[yhz@VM-0-5-opencloudos linux-learning]$ vim test.cpp
[yhz@VM-0-5-opencloudos linux-learning]$ ll -a
total 20
drwxr-xr-x 3 yhz yhz 79 Feb 14 18:41 .
drwx------ 9 yhz yhz 4096 Feb 14 18:41 ..
-rw-r--r-- 1 yhz yhz 23 Feb 14 17:56 a.txt
-rw-r--r-- 1 yhz yhz 71 Feb 14 17:23 code.c
drwxr-xr-x 8 yhz yhz 185 Feb 14 17:57 .git
-rw-r--r-- 1 yhz yhz 350 Feb 14 17:17 .gitignore
-rw-r--r-- 1 yhz yhz 80 Feb 14 18:41 test.cpp
[yhz@VM-0-5-opencloudos linux-learning]$ git add test.cpp
#在你当前目录下的才能add
[yhz@VM-0-5-opencloudos linux-learning]$ git commit -m "second"
[master 06c239a] second
2 files changed, 7 insertions(+)
create mode 100644 a.txt
create mode 100644 test.cpp
[yhz@VM-0-5-opencloudos linux-learning]$ git push
Username for 'https://gitee.com': **************
Password for 'https://***********@gitee.com':
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 2 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (4/4), 454 bytes | 454.00 KiB/s, done.
Total 4 (delta 0), reused 0 (delta 0), pack-reused 0
remote: Powered by GITEE.COM [1.1.23]
remote: Set trace flag 06404fb6
To https://gitee.com/big-dreamer-zz/linux-learning.git
ba15558..06c239a master -> master(4)其他常见命令
| 命令 | 功能 | 常用场景 |
|---|---|---|
git status |
查看状态 | 确认哪些文件改动了、哪些还没 add、哪些准备 commit。这是最常用的命令。 |
git log |
查看日志 | 查看历史提交记录(谁在什么时候改了什么)。 |
git pull |
拉取更新 | 把 Gitee/GitHub 上最新的代码下载并合并到你本地。 |
(5).gitignore:排除不必要的文件
.gitignore 是一个文本文件,放在仓库根目录下。它告诉 Git 哪些文件不需要被追踪(比如临时文件、编译生成的二进制文件、私密配置等)。在 Linux 开发(如你的 linux-learning)中,编译会产生很多 .o 文件或可执行程序(如 a.out),这些不需要上传到云端。
常用配置示例:
bash
[yhz@VM-0-5-opencloudos linux-learning]$ ll -a
total 24
drwxr-xr-x 3 yhz yhz 79 Feb 14 18:41 .
drwx------ 9 yhz yhz 4096 Feb 14 18:58 ..
-rw-r--r-- 1 yhz yhz 23 Feb 14 17:56 a.txt
-rw-r--r-- 1 yhz yhz 71 Feb 14 17:23 code.c
drwxr-xr-x 8 yhz yhz 4096 Feb 14 18:58 .git
-rw-r--r-- 1 yhz yhz 350 Feb 14 17:17 .gitignore
-rw-r--r-- 1 yhz yhz 80 Feb 14 18:41 test.cpp
[yhz@VM-0-5-opencloudos linux-learning]$ vim .gitignore
# 忽略所有 .o 结尾的文件
*.o
# 忽略特定的可执行程序
a.out
my_process
# 忽略日志文件
*.log
# 忽略某个文件夹
temp/开始操作时先按官网步骤操作
先下载git: yum install git
七、调试器gdb/cgdb
1. 准备知识
在 Linux 环境下,gdb 是最强大的调试工具,而 cgdb 则是它的"增强版",带有一个高亮的代码窗口,非常适合初学者。程序的发布方式有两种, debug 模式和 release 模式, Linux gcc/g++ 出来的二进制程序,默认是 release 模式。要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项,如果没有添加,程序无法被编译。
2. 常用指令
| 命令类别 | 命令 | 简写 / 样例 | 作用说明 |
|---|---|---|---|
| 源码查看 | list / l |
l 10 |
显示源代码,从上次位置开始,每次列出 10 行。 |
list [函数名] |
l main |
列出指定函数的源代码。 | |
list [文件名:行号] |
l mycmd.c:1 |
列出指定文件的源代码。 | |
| 执行控制 | r / run |
run |
从程序开始连续执行。 |
n / next |
next |
单步执行,不进入函数内部(逐过程,类似 F10)。 | |
s / step |
step |
单步执行,进入函数内部(逐语句,类似 F11)。 | |
continue / c |
continue |
从当前位置开始连续执行程序(直到遇到下一个断点) | |
until [行号] |
until 20 |
执行到指定行号。 | |
finish |
finish |
执行到当前函数返回,然后停止。 | |
| 断点管理 | break / b [行号] |
b 10 |
在指定行号设置断点(也可指定文件 b test.c:10) |
break / b [函数名] |
b main |
在函数开头设置断点。 | |
info break / b |
info break |
查看当前所有断点的信息。 | |
delete / d breakpoints |
d breakpoints |
删除所有断点。 | |
delete / d [编号] |
d 1 |
删除序号为 n 的断点。 | |
disable breakpoints |
disable |
禁用所有断点。 | |
enable breakpoints |
enable |
启用所有断点。 | |
| 查看与修改 | print / p [表达式] |
p start+end |
打印表达式的值。 |
p [变量] |
p x |
打印指定变量的值。 | |
set var [变量]=[值] |
set var i=10 |
修改变量的值。 | |
display [变量名] |
display x |
跟踪显示变量值(每次停止时自动打印)。 | |
undisplay [编号] |
undisplay 1 |
取消对指定编号变量的跟踪显示。 | |
info / i locals |
info locals |
查看当前栈帧的局部变量值。 | |
| 堆栈与退出 | backtrace / bt |
backtrace |
查看当前执行栈的各级函数调用及参数。 |
quit |
quit |
退出 GDB 调试器。 |
3. 高阶用法
(1)watch
当你发现某个变量的值在莫名其妙的地方被修改了,但不确定是哪一行代码干的,用 watch 。
用法: watch 变量名
特点: 程序会继续运行,一旦该变量的值发生改变,程序就会立即停下来,并显示旧值和新值。
前提: 必须在程序运行(run)后,且变量在当前作用域内时才能设置。
(2)set var (修改变量)
如果你怀疑某个 Bug 是由特定变量值引起的,或者想跳过某些逻辑(比如强制让 if 成立),可以使用 set var。
用法: set var 变量名=值
样例: set var i=10
场景: 测试极端情况: 强制将 count 设为 0 看看是否会触发除零错误;快速修复验证: 在不重新编译的情况下,修改变量值看看逻辑是否恢复正常。
(3)条件断点
如果一个循环要跑 1000 次,但 Bug 只在 i=500 时出现,普通断点会让你按 c 按到手软。条件断点可以让程序只在满足特定条件时才停下。
用法: b 行号 if 条件
样例: b 15 if i==500
管理: 也可以给现有断点增加条件:condition 断点编号 条件。
(这里就先不演示了,太废人了,555...)
后记:除了多用多练没有其他办法,这些玩意儿以后还挺常用,你说说,刚学的时候确实恶心,但大家一定要坚持。我们在人生的道路中最重要的就是把握我们能把握的,不管是在学习,生活还是感情中,不去想我们是否能成功。如果对大家有帮助,麻烦大家点一个小心心吧!