目录
- [什么是 OpenClaw?](#什么是 OpenClaw?)
-
- 快速开始
- 核心概念
- [OpenClaw 能做什么?](#OpenClaw 能做什么?)
- [第一次运行:Onboard 向导](#第一次运行:Onboard 向导)
-
- 接入国内应用:钉钉、飞书、企业微信
- [飞书 / 企业微信:moltbot-china 插件合集](#飞书 / 企业微信:moltbot-china 插件合集)
- [安全:高权限 Agent 必须有"牢笼"](#安全:高权限 Agent 必须有“牢笼”)
- 推荐实践路线
- 目录结构
-
- 核心目录
-
- [1. `src/` - 核心源代码目录](#1.
src/- 核心源代码目录) - [2. `extensions/` - 扩展插件目录](#2.
extensions/- 扩展插件目录) - [3. `apps/` - 应用程序目录](#3.
apps/- 应用程序目录) - [4. `skills/` - 技能目录](#4.
skills/- 技能目录) - [5. `docs/` - 文档目录](#5.
docs/- 文档目录) - [6. `ui/` - Web UI 前端](#6.
ui/- Web UI 前端) - [7. `scripts/` - 脚本目录](#7.
scripts/- 脚本目录) - [8. `test/` - 测试目录](#8.
test/- 测试目录) - [9. `dist/` - 构建输出目录](#9.
dist/- 构建输出目录) - [10. `Swabble/` - macOS 语音唤醒项目](#10.
Swabble/- macOS 语音唤醒项目)
- [1. `src/` - 核心源代码目录](#1.
- 配置文件
- 关键概念
- 数据存储位置
- 核心概念
-
- [Gateway 架构](#Gateway 架构)
-
- 组件与数据流
-
- Gateway(守护进程)
- [客户端(mac 应用 / CLI / Web 管理界面)](#客户端(mac 应用 / CLI / Web 管理界面))
- [节点(macOS / iOS / Android / 无头模式)](#节点(macOS / iOS / Android / 无头模式))
- WebChat
- 连接生命周期(单客户端)
- Wire协议(概要)
- [配对 + 本地信任机制](#配对 + 本地信任机制)
- 协议类型系统与代码生成
- 远程访问
- 运维快照
- 硬性规定
- [Gateway 架构通俗解释(基于源码)](#Gateway 架构通俗解释(基于源码))
- [Agent 运行时](#Agent 运行时)
-
- [Bootstrap 文件(自动注入)](#Bootstrap 文件(自动注入))
- 内置工具
- Skills(技能)
- [pi-mono 集成](#pi-mono 集成)
- 会话(Sessions)
- [流式过程中进行引导(Steering while streaming)](#流式过程中进行引导(Steering while streaming))
- [模型引用(Model refs)](#模型引用(Model refs))
- 最小配置(Configuration)
- Memory(记忆)
-
- 何时写入记忆
- 自动记忆刷新(压缩前提示)
- 向量记忆搜索
-
- [QMD 后端(实验性)](#QMD 后端(实验性))
- 额外的记忆路径
- [Gemini 嵌入(原生)](#Gemini 嵌入(原生))
- 记忆工具的工作原理
- 索引内容(以及时机)
- [混合搜索(BM25 + 向量)](#混合搜索(BM25 + 向量))
- [嵌入缓存(Embedding Cache)](#嵌入缓存(Embedding Cache))
- 会话记忆搜索(实验性功能)
- [SQLite 向量加速(sqlite-vec)](#SQLite 向量加速(sqlite-vec))
- 本地嵌入模型自动下载
- [自定义 OpenAI 兼容端点示例](#自定义 OpenAI 兼容端点示例)
- [Agent 循环(Agent Loop)](#Agent 循环(Agent Loop))
- [流式与块分割(Streaming and Chunking)](#流式与块分割(Streaming and Chunking))
-
- 块式流(频道消息)
- 块分割算法(低/高界限)
- 合并块(Coalescing)
- [模拟人类节奏(Human-like pacing)](#模拟人类节奏(Human-like pacing))
- "流块或一次输出"
- [Telegram 预览流(Token-ish)](#Telegram 预览流(Token-ish))
- 多agent(Multi-agent)
-
- 路径(快速映射)
- 单Agent模式(默认)
- 代理辅助工具
- 快速开始
-
- [1. 创建每个代理的工作区](#1. 创建每个代理的工作区)
- [2. 创建频道账户](#2. 创建频道账户)
- [3. 添加代理、账户和绑定](#3. 添加代理、账户和绑定)
- [4. 重启并验证](#4. 重启并验证)
- [多代理 = 多用户,多人格](#多代理 = 多用户,多人格)
- [一个 WhatsApp 号码,多个人(DM 分流)](#一个 WhatsApp 号码,多个人(DM 分流))
- 路由规则(消息如何选择代理)
- [多账户 / 多手机号](#多账户 / 多手机号)
- 平台示例
- [示例:WhatsApp 日常聊天 + Telegram 深度工作](#示例:WhatsApp 日常聊天 + Telegram 深度工作)
- [示例:同一频道,一个 peer 路由到 Opus](#示例:同一频道,一个 peer 路由到 Opus)
- [绑定到 WhatsApp 群组的家庭代理](#绑定到 WhatsApp 群组的家庭代理)
- 每代理沙箱和工具配置
- 结尾
-
- [Little Wins](#Little Wins)
-
- shell工具
- [skill 调用](#skill 调用)
什么是 OpenClaw?

OpenClaw 是一个自托管网关,可将你常用的聊天应用 ------ WhatsApp、Telegram、Discord、iMessage 等 ------ 连接到 AI 编码 Agent(例如 Pi)。
你只需在自己的电脑(或服务器)上运行一个 Gateway 进程,它就会成为消息应用与始终在线的 AI 助手之间的桥梁。
适合谁?
希望拥有一个可随时通过任意设备发送消息的个人 AI 助手,同时不放弃数据控制权、也不依赖托管服务的开发者和高级用户。
它有什么不同?
- 自托管:运行在你的硬件上,遵循你的规则
- 多渠道:一个 Gateway 同时服务 WhatsApp、Telegram、Discord 等多个平台
- 原生 Agent 架构:专为编码 Agent 设计,支持工具调用、会话、记忆、多 Agent 路由
- 开源:MIT 许可证,社区驱动
你需要什么?
- Node 22+、一个 API Key(推荐 Anthropic),以及 5 分钟时间。
工作原理:
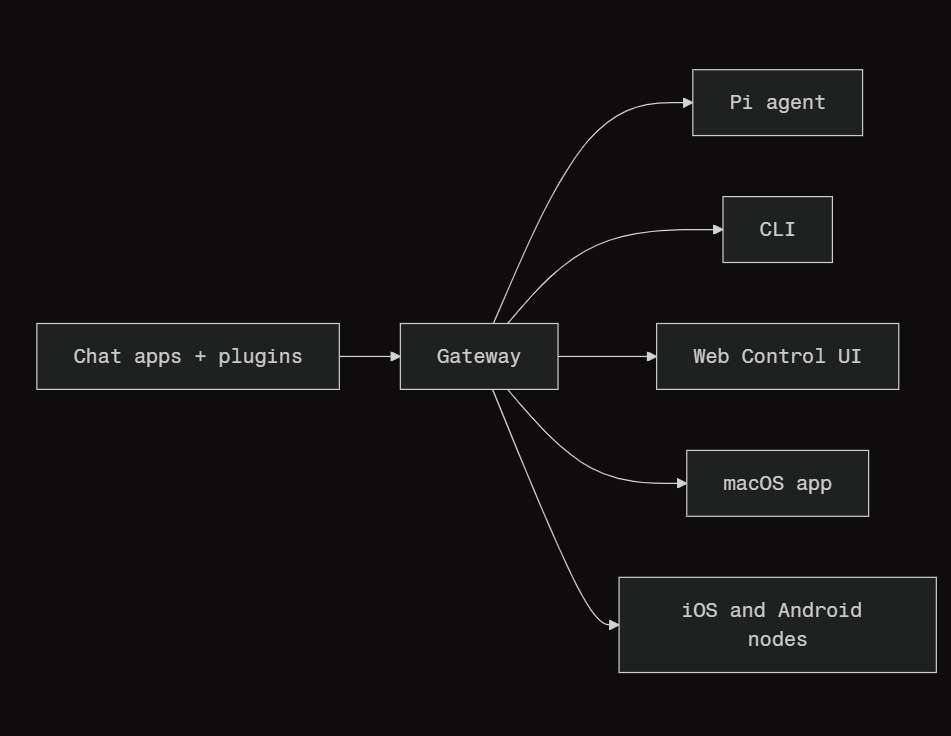
Gateway 是会话管理、路由控制和渠道连接的唯一权威中心。
核心能力:
-
多渠道网关:通过单个 Gateway 进程连接 WhatsApp、Telegram、Discord 和 iMessage。
-
插件渠道:通过扩展包添加 Mattermost 等更多平台支持。
-
多 Agent 路由:按 Agent、工作空间或发送者进行会话隔离。
-
媒体支持:支持发送和接收图片、音频和文档。
-
Web 控制界面:浏览器仪表盘,管理聊天、配置、会话和节点。
-
移动节点:支持 iOS 和 Android 节点配对,并支持 Canvas 功能。
快速开始
1. 安装 OpenClaw
bash
npm install -g openclaw@latest2. 初始化并安装服务
向导会引导你完成网关、工作区、通道与技能的配置,并安装系统服务(launchd / systemd 用户服务),使网关在后台常驻(别在你本机上执行):
bash
openclaw onboard --install-daemon3. 配对 WhatsApp 并启动 Gateway
按提示完成扫码或登录,凭证会保存在 ~/.openclaw/credentials。
bash
openclaw channels login
openclaw gateway --port 18789在 Gateway 启动后,打开浏览器控制界面。
-
本地默认地址:http://127.0.0.1:18789/
-
远程访问:通过 Web 界面或 Tailscale。
配置(可选)
配置文件位于:
~/.openclaw/openclaw.json如果你不做任何配置,OpenClaw 会使用内置的 Pi 二进制文件(RPC 模式),并为每个发送者创建独立会话。
如果你希望加强访问控制,可以从 channels.whatsapp.allowFrom 和群组提及规则开始。
示例:
json
{
"channels": {
"whatsapp": {
"allowFrom": ["+15555550123"],
"groups": { "*": { "requireMention": true } }
}
},
"messages": {
"groupChat": {
"mentionPatterns": ["@openclaw"]
}
}
}其他安装方式请参考官网:https://docs.openclaw.ai/install
核心概念
Channels(渠道)
通过单个 Gateway 同时连接 WhatsApp、Telegram、Discord 和 iMessage。
Plugins(插件)
通过扩展添加 Mattermost 等更多平台。
Routing(路由)
支持多 Agent 路由,并实现会话隔离。
Media(媒体)
支持图片、音频和文档的发送与接收。
Apps and UI(应用与界面)
提供 Web 控制界面和 macOS 伴随应用。
Mobile nodes(移动节点)
支持 iOS 和 Android 节点,并提供 Canvas 功能。
完整功能列表:
- 通过 WhatsApp Web(Baileys)实现 WhatsApp 集成
- Telegram 机器人支持(grammY)
- Discord 机器人支持(channels.discord.js)
- Mattermost 机器人支持(插件方式)
- 通过本地 imsg CLI(macOS)实现 iMessage 集成
- 基于 RPC 模式的 Pi Agent 桥接,支持工具流式调用
- 长响应支持流式输出与分块处理
- 多 Agent 路由:按工作空间或发送者隔离会话
- 通过 OAuth 实现 Anthropic 与 OpenAI 的订阅认证
- 会话机制:私聊会合并为共享主会话;群聊独立隔离
- 群聊支持基于"@提及"的激活机制
- 支持图片、音频和文档媒体传输
- 可选语音留言转写钩子
- WebChat 和 macOS 菜单栏应用
- iOS 节点:支持配对与 Canvas 画布
- Android 节点:支持配对、Canvas、聊天与相机功能
⚠️ 旧版 Claude、Codex、Gemini 和 Opencode 路径已被移除。目前仅保留 Pi 作为唯一的编码 Agent 路径。
OpenClaw 能做什么?
从功能上讲,OpenClaw 远不止是个"聊天机器人",而是一个 AI 助手操作层(Orchestration Layer):
多通道统一入口:
国外 IM 渠道:
Telegram、WhatsApp、Discord、Slack、LINE、Google Chat 等。
本地入口:
- Web 控制台(浏览器访问)
- Web 聊天界面
- 终端 TUI(命令行聊天界面)
国内渠道(通过第三方插件 / 扩展):
- 钉钉
- 飞书
- 企业微信
- 社区正在开发 QQ 机器人等更多入口
你可以在配置中指定:
- 启用 / 禁用哪些通道
- 哪些用户、群组可以访问(白名单 / 配对模式)
- 群聊中是否必须 @ 机器人才会响应
主动式 AI:不再只是"你问我答"
OpenClaw 内置定时任务与事件触发能力,可以变成一个"主动帮你干活"的秘书。例如:
基于 Cron 的定时任务:
- 每天固定时间推送「今日待办 + 日程 + 邮件摘要」
- 将 GitLab / GitHub 通知汇总成日报
基于事件的触发:
- 被邮件、Webhook、系统事件唤起,自动执行某些 Workflow
支持多 Agent 路由:
- "生活助理"负责日程与家庭事项
- "开发助理"专注代码与部署
- "团队助理"关注项目进度与会议纪要
能动型 Agent:真正"帮你干活"
在获得你的授权后,Agent 可以:
- 执行命令:通过 node-pty 等方式实现伪终端,执行 shell / 命令行
- 读写文件:查看、修改本地项目文件、配置与日志
- 操控浏览器:使用 Playwright / CDP 控制浏览器,访问网页、登录后台、自动填写表单
- 访问 API / 服务:调用邮件、日历、GitHub、云厂商 API 等外部服务
简单来说,Agent 可以做任何你能在电脑上完成的事情:
只要电脑能做的,它都可以代你完成。
当然,这也是安全风险最大的部分。因此 OpenClaw 提供了严格的权限控制与沙箱机制(详见后文"安全章节")。
Live Canvas / A2UI:从聊天到"可视化工作台"
OpenClaw 具备 Live Canvas(又称 A2UI,Agent-to-UI)能力:
- Agent 不再只返回纯文本,而是返回结构化的"UI 描述"
- 前端 Canvas Host 将其渲染为可交互画布
例如:
- 任务看板、图表、统计面板
- 可点击的按钮、切换器、表格等交互组件
这使其非常适合构建"个人或团队的 AI 控制面板",例如:
- 项目进度仪表板
- 日程 + 待办 + 邮件一体化看板
第一次运行:Onboard 向导
在终端执行:
bash
openclaw onboard1️⃣ 安全声明
系统会提示:Agent 可能具备以下能力:
- 执行命令
- 访问文件
- 操控本地环境
请确认理解风险后继续。
2️⃣ 配置模型
-
Claude Pro / Max 用户可使用
setup-token -
也可以填写:
- Claude / OpenAI / 国内代理 API Key
- 自定义
baseUrl
3️⃣ 暂不配置消息通道
建议先不要接入 Telegram / Slack 等通道,
先使用 Web 控制台完成测试。
向导完成后,会输出 Web UI 地址:
Web UI: http://127.0.0.1:18789/
Web UI (with token): http://127.0.0.1:18789/?token=xxx在浏览器中打开带 token 的地址,发送一条测试消息即可。
考虑到国内对境外 IM 的使用限制,更现实稳定的方式是:
- 在本地或 NAS 上运行 OpenClaw
- 通过浏览器 + 局域网访问 Web 控制台
找到配置文件(视安装版本而定):
~/.openclaw/openclaw.json
~/.clawdbot/clawdbot.json修改 gateway 段:
json
{
"gateway": {
"mode": "local",
"bind": "lan",
"port": 18789,
"auth": {
"mode": "token",
"token": "使用 openssl rand -hex 32 生成"
}
}
}重启网关:
bash
openclaw gateway restart在手机 / 平板访问:
假设局域网 IP 为:
192.168.1.100访问:
http://192.168.1.100:18789/?token=你的token只要在同一 Wi-Fi 下,即可像访问"家庭版 ChatGPT + 控制台"一样使用。
⚠ 安全提醒
- 仅本机使用时,建议保持
bind=loopback更安全 - 18789 端口可改为其他端口
- 必须确保防火墙配置正确
接入国内应用:钉钉、飞书、企业微信
在"浏览器 + LAN"稳定运行后,可按需接入国内 IM。
路线一:钉钉 + 阿里云 AppFlow(低代码)
1️⃣ 在 钉钉 开放平台创建企业内部应用:
-
开启机器人能力
-
开启 AI 卡片能力
-
获取:
- ClientID
- ClientSecret
- AI 卡片模板 ID
2️⃣ 在 OpenClaw 中启用 HTTP 响应路径(如 /dingtalk)
3️⃣ 在 阿里云 AppFlow 控制台使用模板:
- 一端配置钉钉凭证
- 一端配置 OpenClaw 网关地址 + token
启用后,在钉钉群中 @ 机器人即可触发闭环。
路线二:插件方式(更灵活)
安装插件:
bash
openclaw plugins install @openclaw-china/dingtalk配置:
bash
openclaw config set channels.dingtalk '{
"enabled": true,
"clientId": "dingXXXX",
"clientSecret": "your-app-secret",
"enableAICard": true
}' --json细化权限:
json
{
"channels": {
"dingtalk": {
"dmPolicy": "pairing",
"groupPolicy": "allowlist",
"requireMention": true
}
}
}适合有一定 Node / 运维能力的团队。
飞书 / 企业微信:moltbot-china 插件合集
社区项目支持:
- 飞书
- 企业微信
- 钉钉(未来支持 QQ 等)
安装:
bash
openclaw plugins install @openclaw-china/channels飞书配置:
bash
openclaw config set channels.feishu '{
"enabled": true,
"appId": "cli_xxxxxx",
"appSecret": "your-app-secret"
}' --json企业微信配置:
bash
openclaw config set channels.wecom '{
"enabled": true,
"webhookPath": "/wecom",
"token": "your-token",
"encodingAESKey": "43-char-key"
}' --json在企业微信后台配置回调 URL:
https://你的域名/wecom安全:高权限 Agent 必须有"牢笼"
OpenClaw 可能具备:
- 执行系统命令
- 读写文件
- 控制浏览器
- 调用敏感 API(云账号 / 支付 / CI/CD)
必做三件事:
① 不暴露公网
- 使用
bind=loopback - 或 内网 + VPN / Tailscale
- 公网必须配合防火墙 + IP 白名单
② 强制认证
gateway.auth.mode=token或password- 使用高强度随机值
- 定期更换
③ 收紧通道策略
- 私聊:
dmPolicy=pairing或allowlist - 群聊:
groupPolicy=allowlist + requireMention=true - 限制高危工具的可调用通道
⚠ 不建议在存有重要资料的主力办公电脑上运行。
推荐使用:
- 独立电脑
- 云服务器
- 虚拟机
- Docker
安装后建议立即运行:
bash
openclaw security audit
openclaw security audit --deep
openclaw security audit --fix可自动检查:
- 是否缺少认证
- 凭证目录权限是否过宽
- 通道策略是否存在风险
OpenClaw 的能力高度依赖 Skills(插件)生态。
社区技能超过 500+,涵盖:
- DevOps & Cloud(GitHub / GitLab / 部署脚本)
- 办公协作(日历 / 待办 / Notion)
- 数据分析(CSV / Excel / 报表)
- 个人效率(邮件整理 / 计划复盘)
添加 Skills 步骤:
1️⃣ 创建技能文件
每个技能是一个 Markdown 文件,放在:
~/openclaw/skills/2️⃣ 启动自动加载
加载顺序:
<workspace>/skills~/.openclaw/skills- Bundled skills
同名技能按优先级覆盖。
3️⃣ 额外目录
在配置文件中增加:
skills.load.extraDirs4️⃣ 使用 ClawHub
默认安装到:
./skills
bash
npx clawhub@latest install sonoscli实用建议:
- 初期只装 1--3 个关键技能
- 每个逐个调试
- 涉及生产数据必须审查源码
推荐实践路线
个人 / 家庭用户:
- 用 nvm 安装 Node 22+
npm i -g openclawopenclaw onboard- 本机测试
- 调整为 LAN 模式
- 运行安全审计
- 少量添加技能
小团队 / 创业公司:
- 使用 Docker 部署
- 内网 + VPN
- 优先接入钉钉或飞书
- 创建不同用途的 Agent(独立 workspace)
- 接入日志系统
安全敏感企业:
- 部署在隔离网络
- 开启 Docker/Nix 沙箱
- 全部通道使用 allowlist
- 安全部门参与技能审查
- 定期深度审计
OpenClaw(原 Clawdbot / Moltbot)代表一种新形态:
不是再造一个 ChatGPT 网站,而是:
在你的机器、你的网络、你的规则下,构建一个真正能帮你工作的本地 AI 中枢。
从"浏览器 + 局域网"开始,逐步加入 Skills 与国内通道(钉钉、飞书、企微),你可以把它塑造成深度融入你工作流的"数字同事"。
如果愿意为环境与安全多投入一些耐心,这将是一项长期、值得的技术投资。
目录结构
核心目录
1. src/ - 核心源代码目录
主要源代码目录,包含:
src/cli/- CLI 命令行接口- 程序构建、命令注册、依赖注入
- 使用 Commander.js 框架
src/commands/- CLI 命令实现gateway、agent、message、onboard等命令
src/gateway/- Gateway 核心- WebSocket 控制平面、协议定义、会话管理
- Gateway 是 OpenClaw 的控制中心
src/channels/- 消息通道实现- 内置通道:
telegram、discord、slack、signal、imessage、web(WhatsApp) - 通道路由、消息处理、配对机制
- 内置通道:
src/plugins/- 插件系统- 插件运行时、插件 SDK、插件加载
src/config/- 配置管理- 配置文件加载、路径解析、配置验证
src/infra/- 基础设施代码- 二进制管理、环境变量、错误处理、端口管理、运行时检查
src/media/- 媒体处理管道- 图片/音频/视频处理、转录钩子
src/memory/- 记忆系统- 会话记忆、长期记忆存储
src/process/- 进程管理- 执行工具、进程监督、沙箱管理
src/terminal/- 终端输出- 表格渲染、主题颜色、进度条
src/wizard/- 引导向导- 首次设置向导、配置流程
2. extensions/ - 扩展插件目录
可选功能以插件形式存在:
extensions/msteams/- Microsoft Teams 集成extensions/matrix/- Matrix 协议支持extensions/zalo/、extensions/zalouser/- Zalo 集成extensions/voice-call/- 语音通话功能extensions/bluebubbles/- BlueBubbles(iMessage)支持extensions/open-prose/- Prose 技能系统extensions/nostr/- Nostr 协议支持extensions/copilot-proxy/- Copilot 代理- 其他扩展...
3. apps/ - 应用程序目录
平台应用:
apps/macos/- macOS 菜单栏应用- Swift 代码,提供菜单栏控制、Voice Wake、Talk Mode、WebChat
apps/ios/- iOS 节点应用- Canvas、Voice Wake、Talk Mode、相机功能
apps/android/- Android 节点应用- Canvas、Talk Mode、相机、屏幕录制
apps/shared/- 共享代码库OpenClawKit- 跨平台共享 Swift 代码
4. skills/ - 技能目录
Agent 可用技能:
skills/github/- GitHub 集成skills/notion/- Notion 集成skills/slack/- Slack 技能skills/spotify-player/- Spotify 播放控制skills/obsidian/- Obsidian 笔记集成skills/bear-notes/- Bear 笔记应用skills/apple-reminders/- Apple 提醒事项- 其他技能...
每个技能包含 SKILL.md 文件,描述技能的功能和使用方法。
5. docs/ - 文档目录
项目文档:
docs/channels/- 各通道文档docs/tools/- 工具文档docs/platforms/- 平台特定文档docs/zh-CN/- 中文文档(自动生成)docs/.i18n/- 国际化配置
6. ui/ - Web UI 前端
Web 控制界面和 WebChat:
- React/TypeScript 前端代码
- Control UI 和 WebChat 界面
7. scripts/ - 脚本目录
构建、测试、部署脚本:
scripts/bundle-a2ui.sh- A2UI 打包脚本scripts/package-mac-app.sh- macOS 应用打包scripts/test-*.sh- 各种测试脚本scripts/docs-*.mjs- 文档处理脚本
8. test/ - 测试目录
测试文件(通常与源代码文件同目录,使用 *.test.ts 命名)
9. dist/ - 构建输出目录
TypeScript 编译后的 JavaScript 代码(不提交到 Git)
10. Swabble/ - macOS 语音唤醒项目
独立的 macOS 语音唤醒守护进程(Swift),使用 Apple Speech.framework
配置文件
package.json- Node.js 项目配置和依赖tsconfig.json- TypeScript 配置vitest.config.ts- 测试配置docker-compose.yml- Docker 配置.github/- GitHub Actions 工作流和模板
关键概念
- Gateway - WebSocket 控制平面,所有客户端通过 Gateway 通信
- Channels - 消息通道(WhatsApp、Telegram、Slack 等)
- Sessions - Agent 会话,每个会话有独立的上下文
- Skills - Agent 可调用的功能模块
- Nodes - 设备节点(macOS/iOS/Android),执行本地操作
- Plugins - 扩展系统,可选功能以插件形式提供
数据存储位置
运行时数据存储在 ~/.openclaw/:
~/.openclaw/openclaw.json- 主配置文件~/.openclaw/workspace/- Agent 工作空间~/.openclaw/sessions/- 会话数据~/.openclaw/credentials/- 凭证存储
核心概念
Gateway 架构
一个长期运行的 Gateway 进程负责管理所有消息通道(WhatsApp 通过 Baileys、Telegram 通过 grammY、Slack、Discord、Signal、iMessage、WebChat)。
控制平面客户端(macOS 应用、CLI、Web UI、自动化程序)通过 WebSocket 连接到 Gateway,使用配置的绑定地址(默认 127.0.0.1:18789)。
节点(macOS / iOS / Android / 无头模式)同样通过 WebSocket 连接,但会声明角色为 node,并显式声明其能力(caps)和可执行命令。
每个主机只运行一个 Gateway;它是唯一会建立 WhatsApp 会话的组件。
Canvas 主机由 Gateway 的 HTTP 服务器提供,路径如下:
/__openclaw__/canvas/(可由 Agent 编辑的 HTML / CSS / JS)/__openclaw__/a2ui/(A2UI 主机)
它们与 Gateway 使用相同端口(默认 18789)。
组件与数据流
Gateway(守护进程)
- 维护各类提供商连接
- 提供类型化的 WebSocket API(请求、响应、服务器推送事件)
- 使用 JSON Schema 校验入站帧
- 发送事件,例如:agent、chat、presence、health、heartbeat、cron
客户端(mac 应用 / CLI / Web 管理界面)
- 每个客户端建立一个 WebSocket 连接
- 发送请求(health、status、send、agent、system-presence)
- 订阅事件(tick、agent、presence、shutdown)
节点(macOS / iOS / Android / 无头模式)
-
使用
role: node连接到同一个 WebSocket 服务器 -
在连接时提供设备身份标识;配对基于设备进行(角色为 node),审批记录存储在设备配对存储中
-
暴露命令,例如:
canvas.*camera.*screen.recordlocation.get
协议细节:
Gateway 协议
WebChat
- 静态 UI,通过 Gateway 的 WebSocket API 获取聊天历史并发送消息
- 在远程部署场景中,通过与其他客户端相同的 SSH / Tailscale 隧道连接
连接生命周期(单客户端)
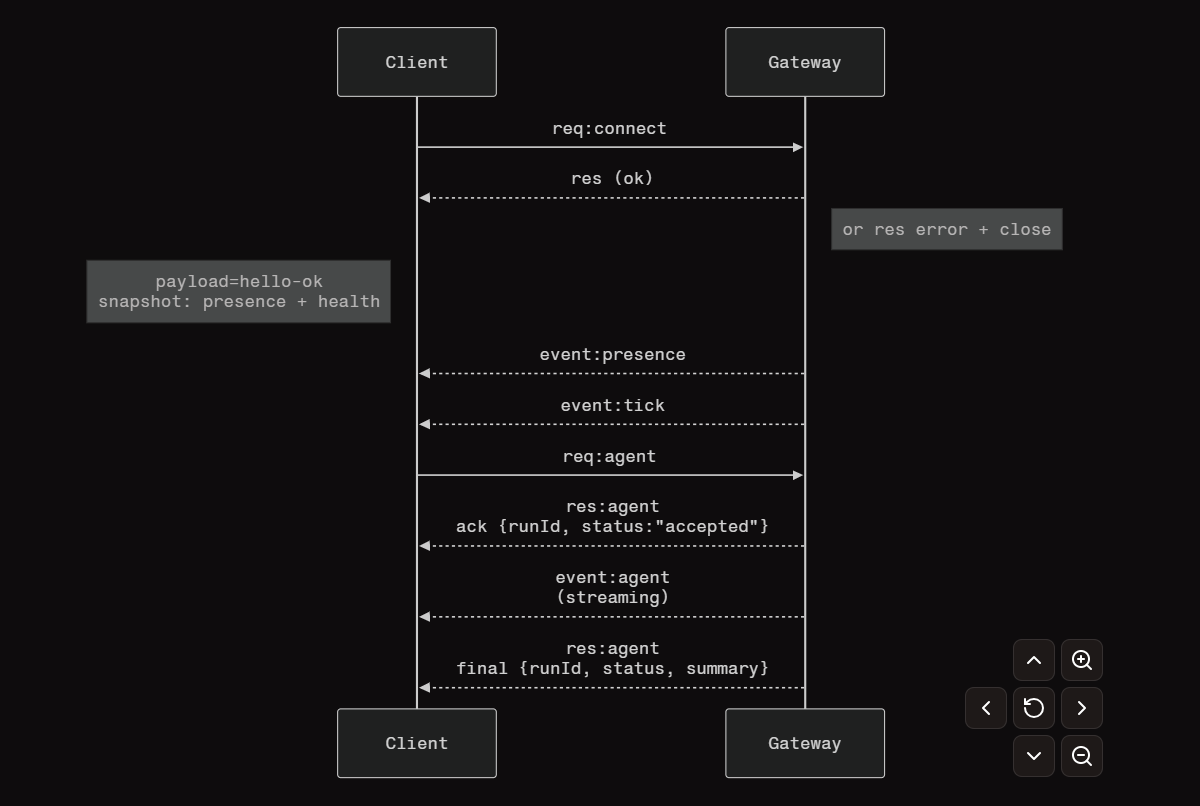
Wire协议(概要)
传输方式: WebSocket,使用文本帧承载 JSON 负载。
首帧必须为 connect。
完成握手后:
-
请求(Requests)
{type:"req", id, method, params}→
{type:"res", id, ok, payload|error} -
事件(Events)
{type:"event", event, payload, seq?, stateVersion?}
如果设置了 OPENCLAW_GATEWAY_TOKEN(或使用 --token 参数),则
connect.params.auth.token 必须匹配,否则连接会被关闭。
对于具有副作用的方法(如 send、agent),必须提供**幂等键(Idempotency keys)**以支持安全重试;服务器会维护一个短生命周期的去重缓存。
节点必须在 connect 时包含:
role: "node"- 以及
caps/commands/permissions信息
配对 + 本地信任机制
所有 WebSocket 客户端(操作端 + 节点)在连接时都必须包含设备身份标识。
- 新设备 ID 需要通过配对审批;
- Gateway 会为后续连接签发设备令牌(device token)。
本地连接(回环地址或 Gateway 主机自身的 tailnet 地址)可以自动审批,以保证同主机体验流畅。
非本地连接 必须对 connect.challenge 随机数进行签名,并且需要显式审批。
无论本地还是远程连接,gateway.auth.* 认证机制始终适用。
协议类型系统与代码生成
- 协议由 TypeBox schema 定义
- 从 TypeBox 生成 JSON Schema
- 再从 JSON Schema 生成 Swift 模型
远程访问
推荐方式: Tailscale 或 VPN
替代方式: SSH 隧道
bash
ssh -N -L 18789:127.0.0.1:18789 user@host通过隧道连接时,握手与认证 token 机制保持一致。
在远程部署场景中,可以启用:
- TLS
- 可选的证书固定(pinning)
运维快照
启动:
bash
openclaw gateway(前台运行,日志输出到 stdout)
健康检查:
通过 WebSocket 的 health 方法(也包含在 hello-ok 响应中)。
进程监管:
使用 launchd / systemd 实现自动重启。
硬性规定
- 每台主机仅允许一个 Gateway 管理单个 Baileys 会话。
- 握手是强制性的;任何非 JSON 或首帧非
connect的连接都会被立即关闭。 - 事件不会被重放;客户端在检测到事件间隙时必须主动刷新状态。
Gateway 架构通俗解释(基于源码)
一、Gateway 是什么?
Gateway 是一个长期运行的 Node.js 进程,同时提供:
- HTTP 服务器(处理网页、API、Canvas)
- WebSocket 服务器(处理实时通信)
两者共享同一个端口(默认 18789)。
二、启动流程(基于 server.impl.ts)
typescript
// 1. 调用 startGatewayServer() (第162行)
startGatewayServer(port = 18789, opts)
// 2. 创建运行时状态 (第353行)
createGatewayRuntimeState({
// 这会创建 HTTP 服务器和 WebSocket 服务器
})
// 3. 创建通道管理器 (第405行)
channelManager = createChannelManager(...)
// 4. 附加 WebSocket 处理器 (第541行)
attachGatewayWsHandlers({ wss, ... })三、HTTP 和 WebSocket 的关系
源码位置:src/gateway/server-runtime-state.ts
typescript
// 第122行:创建 HTTP 服务器
const httpServer = createGatewayHttpServer({...})
// 第159行:创建 WebSocket 服务器(不直接监听端口)
const wss = new WebSocketServer({
noServer: true, // 关键:不自己监听端口
maxPayload: MAX_PAYLOAD_BYTES,
})
// 第164行:将 WebSocket 附加到 HTTP 服务器
attachGatewayUpgradeHandler({
httpServer: server, // 共享同一个 HTTP 服务器
wss,
...
})要点:
- HTTP 服务器监听端口(如 18789)
- WebSocket 服务器不独立监听,通过 HTTP 升级(upgrade)建立连接
- 两者共用同一端口,WebSocket 连接通过 HTTP 升级请求建立
四、连接建立流程(基于 ws-connection.ts)
源码位置:src/gateway/server/ws-connection.ts 第103行
typescript
wss.on("connection", (socket, upgradeReq) => {
// 1. 生成连接ID和挑战随机数
const connId = randomUUID();
const connectNonce = randomUUID();
// 2. 立即发送挑战事件(第163-167行)
send({
type: "event",
event: "connect.challenge",
payload: { nonce: connectNonce, ts: Date.now() },
});
// 3. 等待客户端发送 connect 请求
// 处理逻辑在 message-handler.ts
})五、握手验证(基于 message-handler.ts)
源码位置:src/gateway/server/ws-connection/message-handler.ts 第203-299行
typescript
// 第206行:验证第一帧必须是 connect 请求
if (!isRequestFrame || parsed.method !== "connect") {
// 关闭连接
close(1008, "invalid handshake");
return;
}
// 第273行:协议版本协商
if (maxProtocol < PROTOCOL_VERSION || minProtocol > PROTOCOL_VERSION) {
close(1002, "protocol mismatch");
return;
}
// 第290行:角色验证(只能是 operator 或 node)
const role = roleRaw === "operator" || roleRaw === "node" ? roleRaw : null;
if (!role) {
close(1008, "invalid role");
return;
}
// 第342行:认证检查
const authResult = await authorizeGatewayConnect({...})六、Canvas 路径处理
源码位置:src/gateway/server-http.ts 第90-98行
typescript
function isCanvasPath(pathname: string): boolean {
return (
pathname === A2UI_PATH || // "/__openclaw__/a2ui/"
pathname.startsWith(`${A2UI_PATH}/`) ||
pathname === CANVAS_HOST_PATH || // "/__openclaw__/canvas/"
pathname.startsWith(`${CANVAS_HOST_PATH}/`) ||
pathname === CANVAS_WS_PATH // Canvas WebSocket
);
}Canvas 通过 HTTP 服务器提供,与 Gateway 使用同一端口。
七、消息类型(基于协议定义)
源码位置:src/gateway/protocol/schema/frames.ts
三种消息类型:
- 请求(Request)
typescript
{
type: "req",
id: "唯一ID",
method: "方法名",
params: {...}
}- 响应(Response)
typescript
{
type: "res",
id: "对应请求的ID",
ok: true/false,
payload: {...} // 成功时
error: {...} // 失败时
}- 事件(Event)
typescript
{
type: "event",
event: "事件名",
payload: {...},
seq?: number,
stateVersion?: {...}
}八、角色系统(基于 message-handler.ts)
源码位置:src/gateway/server/ws-connection/message-handler.ts 第290行
typescript
// 只允许两种角色
const role = roleRaw === "operator" || roleRaw === "node" ? roleRaw : null;
// Operator(操作端)
// - 可以调用所有 Gateway 方法
// - 需要声明 scopes(权限范围)
// Node(节点)
// - 声明 caps(能力)、commands(命令)、permissions(权限)
// - 只能被调用,不能主动调用 Gateway 方法九、设备配对机制
源码位置:src/gateway/server/ws-connection/message-handler.ts 第329-450行
typescript
// 第329行:获取设备信息
const deviceRaw = connectParams.device;
// 第342行:检查是否有设备令牌
const hasDeviceTokenCandidate = Boolean(
connectParams.auth?.token && device
);
// 设备配对流程:
// 1. 客户端发送设备身份(device.id + publicKey + signature)
// 2. Gateway 检查是否已配对
// 3. 未配对 → 需要审批
// 4. 已配对 → 颁发设备令牌(deviceToken)本地连接(127.0.0.1)可自动审批,远程连接需要显式审批。
十、实际工作示例
场景:CLI 连接到 Gateway
1. CLI 建立 WebSocket 连接
ws://127.0.0.1:18789
2. Gateway 立即发送挑战(ws-connection.ts:163)
Gateway → CLI: {type:"event", event:"connect.challenge", payload:{nonce:"..."}}
3. CLI 发送 connect 请求(message-handler.ts:206)
CLI → Gateway: {
type: "req",
method: "connect",
params: {
role: "operator",
scopes: ["operator.read", "operator.write"],
device: {id: "...", publicKey: "...", signature: "..."}
}
}
4. Gateway 验证并响应(message-handler.ts:成功路径)
Gateway → CLI: {
type: "res",
ok: true,
payload: {
type: "hello-ok",
protocol: 3,
auth: {deviceToken: "..."} // 如果已配对
}
}
5. 连接建立,可以正常通信十一、关键代码位置总结
| 功能 | 文件位置 | 关键行数 |
|---|---|---|
| Gateway 启动入口 | src/gateway/server.impl.ts |
162 |
| HTTP/WS 服务器创建 | src/gateway/server-runtime-state.ts |
122, 159 |
| WebSocket 连接处理 | src/gateway/server/ws-connection.ts |
103 |
| 握手验证 | src/gateway/server/ws-connection/message-handler.ts |
206-299 |
| HTTP 请求处理 | src/gateway/server-http.ts |
476 |
| 协议定义 | src/gateway/protocol/schema/frames.ts |
全部 |
十二、重要不变量
- 每台主机只有一个 Gateway
- 源码:
src/gateway/server/http-listen.ts第26行检查EADDRINUSE
- 源码:
- 首帧必须是
connect- 源码:
message-handler.ts第206-243行,否则关闭连接
- 源码:
- 事件不重放
- 客户端需主动刷新状态(如通过
health方法)
- 客户端需主动刷新状态(如通过
总结:
Gateway 是一个 HTTP + WebSocket 服务器:
- HTTP 服务器处理网页、API、Canvas
- WebSocket 服务器通过 HTTP 升级建立,处理实时通信
- 所有客户端通过 WebSocket 连接,首帧必须是
connect - 支持两种角色:
operator(控制端)和node(设备节点) - 设备需要配对才能连接(本地自动,远程需审批)
Agent 运行时
OpenClaw 运行一个内嵌的 Agent 运行时,源自 pi-mono。
OpenClaw 使用单一的 Agent 工作区目录(agents.defaults.workspace)作为 Agent 的唯一工作目录(cwd),用于工具执行与上下文环境。
推荐做法:
使用 openclaw setup 在缺失时创建 ~/.openclaw/openclaw.json,并初始化工作区文件。
如果启用了 agents.defaults.sandbox,则非主会话 可以在
agents.defaults.sandbox.workspaceRoot 下使用独立的每会话工作区(详见 Gateway 配置)。
Bootstrap 文件(自动注入)
在 agents.defaults.workspace 目录中,OpenClaw 期望存在以下用户可编辑文件:
AGENTS.md------ 操作说明 + "记忆"SOUL.md------ 人设、边界、语气TOOLS.md------ 用户维护的工具说明(例如 imsg、sag、使用约定等)BOOTSTRAP.md------ 首次运行的一次性仪式(完成后会删除)IDENTITY.md------ Agent 名称 / 氛围 / emojiUSER.md------ 用户档案 + 偏好的称呼方式
在新会话的第一轮对话中,OpenClaw 会将这些文件的内容直接注入到 Agent 上下文中。
规则如下:
- 空文件会被跳过
- 大文件会被裁剪,并添加截断标记,以保持提示词精简(需要时可读取完整文件)
- 如果文件缺失,OpenClaw 会注入一行"缺失文件"标记(并且
openclaw setup会创建安全的默认模板)
BOOTSTRAP.md 仅在全新工作区 (不存在其他 bootstrap 文件)时创建。
如果在完成首次仪式后删除该文件,它不会在后续重启时重新创建。
如果希望完全禁用 bootstrap 文件创建(例如已预置好工作区),可以设置:
json
{ agent: { skipBootstrap: true } }内置工具
核心工具(read / exec / edit / write 以及相关系统工具)始终可用,但受工具策略限制。
apply_patch 是可选工具,受 tools.exec.applyPatch 开关控制。
TOOLS.md 并不决定哪些工具存在;它仅用于说明你希望如何使用这些工具。
Skills(技能)
OpenClaw 会从以下三个位置加载技能(若名称冲突,以工作区中的为准):
- 内置(Bundled):随安装包提供
- 本地管理目录(Managed/local) :
~/.openclaw/skills - 工作区目录(Workspace) :
<workspace>/skills
技能可以通过配置或环境变量进行启用/禁用控制(详见 Gateway 配置中的 skills)。
pi-mono 集成
OpenClaw 复用了 pi-mono 代码库中的部分组件(如模型与工具),但:
- 会话管理由 OpenClaw 自行实现
- 服务发现由 OpenClaw 管理
- 工具绑定由 OpenClaw 控制
不使用:
- pi-coding agent runtime
~/.pi/agent<workspace>/.pi配置
会话(Sessions)
会话记录以 JSONL 格式存储在:
~/.openclaw/agents/<agentId>/sessions/<SessionId>.jsonl- Session ID 由 OpenClaw 生成并保持稳定
- 不会读取旧版 Pi/Tau 的会话目录
流式过程中进行引导(Steering while streaming)
当队列模式(queue mode)为 steer 时:
-
新收到的消息会被注入到当前运行中
-
每次工具调用完成后都会检查队列
-
如果存在排队消息:
- 当前 assistant 消息剩余的工具调用会被跳过
- 这些被跳过的工具会返回错误结果:
"Skipped due to queued user message." - 然后将排队的用户消息注入
- 再生成新的 assistant 响应
当队列模式为 followup 或 collect 时:
- 新消息会暂存
- 等当前回合结束后
- 启动一个新的 agent 回合,并携带排队的消息
详见 Queue 文档(包括模式、去抖动 debounce 与容量上限行为)。
Block Streaming(分块流式):
-
在一个 assistant 块完成时立即发送
-
默认关闭(
agents.defaults.blockStreamingDefault: "off") -
分块边界可通过
agents.defaults.blockStreamingBreak调整:text_end(默认)message_end
-
块大小通过
agents.defaults.blockStreamingChunk控制(默认 800--1200 字符)- 优先按段落切分
- 其次换行
- 最后按句子
-
使用
agents.defaults.blockStreamingCoalesce合并流式块,减少单行刷屏(基于空闲时间合并后发送) -
非 Telegram 渠道必须显式设置
*.blockStreaming: true才会启用分块回复 -
详细工具摘要在工具启动时立即发送(无 debounce)
-
Control UI 在可用时通过 agent 事件流式展示工具输出
模型引用(Model refs)
配置中的模型引用(例如 agents.defaults.model 和 agents.defaults.models)会按第一个 / 分割解析。
推荐格式:
provider/model如果模型 ID 本身包含 /(例如 OpenRouter 风格),必须包含 provider 前缀,例如:
openrouter/moonshotai/kimi-k2如果省略 provider:
- OpenClaw 会将其视为别名
- 或视为默认 provider 下的模型
- 仅当模型 ID 本身不包含
/时可行
最小配置(Configuration)
至少需要设置:
agents.defaults.workspacechannels.whatsapp.allowFrom(强烈推荐设置)
Memory(记忆)
OpenClaw 的记忆是存放在代理工作区中的纯 Markdown 文件。
这些文件才是唯一的真实来源(source of truth);模型只会"记住"被写入磁盘的内容。
记忆搜索工具由当前启用的记忆插件提供(默认:memory-core)。
可通过以下配置禁用记忆插件:
json
plugins.slots.memory = "none"默认工作区布局包含两层记忆:
memory/YYYY-MM-DD.md
- 每日日志(仅追加写入)。
- 在每次会话开始时,建议读取今天 + 昨天的日志。
MEMORY.md(可选)
- 整理后的长期记忆。
- 仅在主私有会话中加载(绝不在群组上下文中加载)。
这些文件位于工作区(agents.defaults.workspace,默认 ~/.openclaw/workspace)。
OpenClaw 为这些 Markdown 文件提供两个面向代理的工具:
memory_search
- 基于语义索引的记忆检索(semantic recall)。
memory_get
- 读取指定 Markdown 文件或特定行范围。
现在,当文件不存在时(例如当天尚未创建日志),memory_get 会优雅降级:
- 不再抛出
ENOENT错误 - 返回
{ text: "", path }
无论是内置管理器还是 QMD 后端都会如此处理。
这样代理可以自然处理"尚未记录任何内容"的情况,而无需用 try/catch 包裹工具调用。
何时写入记忆
- 决策、偏好、长期有效的事实 → 写入
MEMORY.md - 日常笔记、运行中的上下文 → 写入
memory/YYYY-MM-DD.md - 如果有人说"记住这个" → 必须写入文件(不要只保存在上下文中)
这一机制仍在演进中。
主动提醒模型存储记忆通常是有帮助的------模型会知道该如何处理。
如果你希望某件事"长期有效",就明确要求机器人写入记忆文件。
自动记忆刷新(压缩前提示)
当会话接近自动上下文压缩(auto-compaction)时,OpenClaw 会触发一个静默的代理回合,提醒模型在压缩前写入长期记忆。
默认提示说明模型可以回复,但通常正确响应是 NO_REPLY,这样用户不会看到该回合。
相关配置项:agents.defaults.compaction.memoryFlush
json
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 20000,
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 4000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
}
}
}
}机制说明:
-
软阈值触发条件:
当会话 token 估算值超过
contextWindow - reserveTokensFloor - softThresholdTokens时触发刷新。 -
默认静默:
提示中包含
NO_REPLY,因此不会向用户发送任何内容。 -
双提示机制:
包括一个 user prompt 和一个 system prompt,共同附加提醒。
-
每个压缩周期只触发一次:
在
sessions.json中记录。 -
工作区必须可写:
若会话在沙箱中运行且
workspaceAccess为"ro"或"none",则不会触发刷新。
向量记忆搜索
OpenClaw 可以为 MEMORY.md 和 memory/*.md 构建一个小型向量索引,使语义查询能够找到相关笔记,即便表述不同。
默认行为:
- 默认启用
- 监听记忆文件变化(防抖处理)
- 配置路径:
agents.defaults.memorySearch(不是顶层memorySearch)
嵌入模式:
-
默认使用远程 embeddings
-
如果未设置
memorySearch.provider,OpenClaw 会自动选择:local:如果配置了memorySearch.local.modelPath且文件存在openai:如果可解析到 OpenAI Keygemini:如果可解析到 Gemini Keyvoyage:如果可解析到 Voyage Key
-
如果都未配置,记忆搜索保持禁用,直到手动配置
本地模式:
- 使用
node-llama-cpp - 可能需要
pnpm approve-builds批准构建 - 使用
sqlite-vec(如可用)加速 SQLite 内的向量搜索
远程嵌入:
-
需要嵌入提供商的 API Key
-
OpenClaw 可从以下位置解析 Key:
auth配置文件models.providers.*.apiKey- 环境变量
-
注意事项:
- Codex OAuth 仅适用于 chat/completions,不可用于记忆搜索 embeddings
- Gemini:使用
GEMINI_API_KEY或models.providers.google.apiKey - Voyage:使用
VOYAGE_API_KEY或models.providers.voyage.apiKey - 自定义 OpenAI 兼容端点:设置
memorySearch.remote.apiKey(可选memorySearch.remote.headers)
QMD 后端(实验性)
通过设置 memory.backend = "qmd",可以将内置的 SQLite 索引器替换为 QMD:一种本地优先的搜索 sidecar,结合了 BM25、向量检索和重排序。Markdown 文件仍然是唯一的真实来源;OpenClaw 调用 QMD 来进行检索。
前置条件:
-
默认禁用,需要显式开启:
memory.backend = "qmd" -
单独安装 QMD CLI:
bashbun install -g https://github.com/tobi/qmd # 或下载 release 并确保 qmd 可执行文件在网关 PATH 中 -
QMD 需要一个支持扩展的 SQLite 构建(macOS 可通过
brew install sqlite) -
完全本地运行:Bun + node-llama-cpp,并在首次使用时自动从 HuggingFace 下载 GGUF 模型(无需 Ollama 守护进程)
-
网关通过设置
XDG_CONFIG_HOME和XDG_CACHE_HOME将 QMD 运行在自包含的目录:
~/.openclaw/agents/<agentId>/qmd/ -
支持系统:macOS 和 Linux(安装 Bun + SQLite 后即可);Windows 推荐通过 WSL2
Sidecar 的运行方式:
-
网关在
~/.openclaw/agents/<agentId>/qmd/创建自包含的 QMD home(存放配置、缓存和 SQLite 数据库) -
通过
qmd collection add将memory.qmd.paths(以及默认工作区记忆文件)加入集合 -
启动和间隔更新执行:
qmd update + qmd embed(间隔可配置:memory.qmd.update.interval,默认 5 分钟) -
网关启动时初始化 QMD 管理器,即使在首次
memory_search调用前,周期性更新计时器也已激活 -
启动刷新默认后台运行,聊天启动不被阻塞;若希望保持旧的阻塞行为,可设置:
jsonmemory.qmd.update.waitForBootSync = true -
搜索通过
memory.qmd.searchMode运行(默认qmd search --json,也支持vsearch和query)- 若选定模式在 QMD 构建中不支持某些标志,OpenClaw 会自动重试
qmd query - 若 QMD 失败或二进制缺失,自动回退到内置 SQLite 管理器,保证记忆工具继续工作
- 若选定模式在 QMD 构建中不支持某些标志,OpenClaw 会自动重试
-
当前不提供 QMD embed 批量大小调节;批处理行为由 QMD 自身控制
-
首次搜索可能较慢:QMD 可能首次下载 GGUF 模型(重排序/查询扩展)
-
OpenClaw 运行 QMD 时会自动设置
XDG_CONFIG_HOME/XDG_CACHE_HOME -
若希望预下载模型,可在代理的 XDG 目录下执行一次查询以"预热"索引
示例:手动对齐 OpenClaw 使用的状态目录:
bash
STATE_DIR="${OPENCLAW_STATE_DIR:-$HOME/.openclaw}"
export XDG_CONFIG_HOME="$STATE_DIR/agents/main/qmd/xdg-config"
export XDG_CACHE_HOME="$STATE_DIR/agents/main/qmd/xdg-cache"
# 可选:强制刷新索引 + embedding
qmd update
qmd embed
# 触发首次模型下载 / 预热索引
qmd query "test" -c memory-root --json >/dev/null 2>&1配置项(memory.qmd.*):
- command (默认
qmd):覆盖可执行路径 - searchMode (默认
search):选择用于memory_search的 QMD 命令(search/vsearch/query) - includeDefaultMemory (默认
true):自动索引MEMORY.md+memory/**/*.md - paths\[\]:添加额外目录/文件(可选 pattern 与稳定名称)
- sessions :选择是否将会话 JSONL 索引到 QMD 集合中(
enabled、retentionDays、exportDir) - update:控制刷新周期和维护行为(interval, debounceMs, onBoot, waitForBootSync, embedInterval, commandTimeoutMs, updateTimeoutMs, embedTimeoutMs)
- limits:限制检索结果大小(maxResults, maxSnippetChars, maxInjectedChars, timeoutMs)
- scope :同
session.sendPolicy架构,默认仅 DM,可放宽以在群组/通道展示 QMD 命中 - match.keyPrefix / match.rawKeyPrefix:匹配会话键前缀,用于范围过滤
当 scope 拒绝搜索时,OpenClaw 会记录警告并标记通道/聊天类型,便于调试空结果。
- 工作区外的片段会显示为
qmd/<collection>/<relative-path>,memory_get会识别前缀并读取对应 QMD collection 根目录 - 当
memory.qmd.sessions.enabled = true时,OpenClaw 会将清理后的会话记录 导出到专用 QMD 集合,以便memory_search回忆最近对话,而不触及内置 SQLite 索引 - 当
memory.citations = auto/on时,memory_search的 snippet 会附加Source: <path#line>;若设为off,路径元数据仅内部使用(memory_get仍可访问路径,系统提示会告知代理不要引用)
示例配置:
json
memory: {
backend: "qmd",
citations: "auto",
qmd: {
includeDefaultMemory: true,
update: { interval: "5m", debounceMs: 15000 },
limits: { maxResults: 6, timeoutMs: 4000 },
scope: {
default: "deny",
rules: [
{ action: "allow", match: { chatType: "direct" } },
{ action: "deny", match: { keyPrefix: "discord:channel:" } },
{ action: "deny", match: { rawKeyPrefix: "agent:main:discord:" } }
]
},
paths: [
{ name: "docs", path: "~/notes", pattern: "**/*.md" }
]
}
}引用与回退:
memory.citations在任何后端下均有效(auto/on/off)- 当 QMD 运行时,状态标记为
status().backend = "qmd",便于诊断显示使用的引擎 - 若 QMD 子进程退出或 JSON 输出不可解析,搜索管理器会记录警告并回退至内置 Markdown embedding 以保证记忆工具继续可用
额外的记忆路径
如果你想索引默认工作区布局之外的 Markdown 文件,可以添加显式路径:
json
agents: {
defaults: {
memorySearch: {
extraPaths: ["../team-docs", "/srv/shared-notes/overview.md"]
}
}
}说明:
- 路径可以是绝对路径或相对于工作区的相对路径。
- 目录会递归扫描
.md文件。 - 仅索引 Markdown 文件。
- 符号链接(文件或目录)会被忽略。
Gemini 嵌入(原生)
将 provider 设置为 gemini,直接使用 Gemini embeddings API:
json
agents: {
defaults: {
memorySearch: {
provider: "gemini",
model: "gemini-embedding-001",
remote: {
apiKey: "YOUR_GEMINI_API_KEY"
}
}
}
}说明:
remote.baseUrl可选,默认为 Gemini API 基础 URL。remote.headers可用于添加额外请求头。- 默认模型:
gemini-embedding-001。
如果你想使用自定义 OpenAI 兼容端点(如 OpenRouter、vLLM 或代理),可用 OpenAI provider 的 remote 配置:
json
agents: {
defaults: {
memorySearch: {
provider: "openai",
model: "text-embedding-3-small",
remote: {
baseUrl: "https://api.example.com/v1/",
apiKey: "YOUR_OPENAI_COMPAT_API_KEY",
headers: { "X-Custom-Header": "value" }
}
}
}
}如果不想设置 API Key,可以使用:
memorySearch.provider = "local"- 或
memorySearch.fallback = "none"
回退机制(Fallbacks):
memorySearch.fallback可选值:openai、gemini、local或none- 仅在主嵌入提供商失败时才使用回退
批量索引(OpenAI + Gemini + Voyage):
-
默认关闭
-
设置
agents.defaults.memorySearch.remote.batch.enabled = true可启用大规模索引 -
默认行为会等待批处理完成,可根据需要调整:
remote.batch.waitremote.batch.pollIntervalMsremote.batch.timeoutMinutes
-
设置
remote.batch.concurrency控制并行批处理作业数量(默认 2) -
批量模式适用于
memorySearch.provider = "openai"或"gemini",并使用对应 API Key -
Gemini 批量作业使用异步 embeddings 批量端点,需要 Gemini Batch API 支持
OpenAI 批量优势:
- 支持大量请求异步处理,速度快且成本低
- 批量 API 提供折扣,通常比同步请求更经济
参考文档:
配置示例:
json
agents: {
defaults: {
memorySearch: {
provider: "openai",
model: "text-embedding-3-small",
fallback: "openai",
remote: {
batch: { enabled: true, concurrency: 2 }
},
sync: { watch: true }
}
}
}工具:
memory_search--- 返回包含文件路径 + 行号范围的 snippetmemory_get--- 按路径读取记忆文件内容
本地模式:
- 设置
agents.defaults.memorySearch.provider = "local" - 提供
agents.defaults.memorySearch.local.modelPath(GGUF 或 hf: URI) - 可选:设置
agents.defaults.memorySearch.fallback = "none"避免远程回退
记忆工具的工作原理
- memory_search 对 Markdown 块(约 400 token,重叠 80 token)进行语义搜索,来源于
MEMORY.md和memory/**/*.md。返回信息包括 snippet 文本(约 700 字符上限)、文件路径、行号范围、分数、提供商/模型,以及是否从本地回退到远程 embeddings。不返回完整文件内容。 - memory_get 读取指定的记忆 Markdown 文件(相对于工作区路径),可选从起始行开始读取 N 行。超出
MEMORY.md/memory/以外的路径会被拒绝。 - 两个工具仅在
memorySearch.enabled对该 agent 返回true时启用。
索引内容(以及时机)
- 文件类型 :仅 Markdown (
MEMORY.md、memory/**/*.md) - 索引存储 :每个 agent 对应的 SQLite 文件,路径默认
~/.openclaw/memory/<agentId>.sqlite,可通过agents.defaults.memorySearch.store.path配置 - 新鲜度 :
MEMORY.md+memory/文件变化触发 watcher 标记索引为脏(防抖 1.5 秒)。同步在会话启动、搜索或定时器触发时异步执行。会话记录使用 delta 阈值触发后台同步。 - 重新索引触发条件:索引存储嵌入提供商/模型 + 端点指纹 + 块分割参数。任何变化都会触发 OpenClaw 自动重置并重新索引整个存储。
混合搜索(BM25 + 向量)
启用时,OpenClaw 将两种信号结合:
- 向量相似度(语义匹配,可词汇不同)
- BM25 关键字相关性(精确 token,如 ID、环境变量、代码符号)
如果平台不支持全文搜索(FTS5),则降级为向量搜索。
为什么要混合?
-
向量搜索擅长"意思相同但表达不同":
- "Mac Studio gateway host" ↔ "the machine running the gateway"
- "debounce file updates" ↔ "avoid indexing on every write"
-
但对精确信号 token 较弱:
- ID(如 a828e60, b3b9895a...)
- 代码符号(memorySearch.query.hybrid)
- 错误字符串("sqlite-vec unavailable")
-
BM25 正好相反:精确 token 强,意译弱
-
混合搜索是折中方案,兼顾自然语言查询与"针眼式"查询
结果合并(当前设计):
实现思路:
-
从向量和 BM25 两端各取候选池:
- 向量:按余弦相似度选 top
maxResults * candidateMultiplier - BM25:按 FTS5 BM25 排名选 top
maxResults * candidateMultiplier(排名越低越好)
- 向量:按余弦相似度选 top
-
将 BM25 排名转换为 0~1 分数:
texttextScore = 1 / (1 + max(0, bm25Rank)) -
以块 ID 联合候选项并计算加权分数:
textfinalScore = vectorWeight * vectorScore + textWeight * textScore
注意:
vectorWeight + textWeight在配置解析时归一化为 1.0- 若嵌入不可用或返回零向量,仍运行 BM25
- FTS5 创建失败时保持向量搜索(不报错)
未来可扩展:如 RRF(Reciprocal Rank Fusion)或分数归一化(min/max、z-score)
后处理管道:
向量 + 关键字得分合并后,可进行两级可选后处理:
Vector + Keyword → Weighted Merge → Temporal Decay → Sort → MMR → Top-K Results- 默认关闭,可独立启用
MMR 重排序(多样性):
- 解决重复或高度相似的 snippet 问题
- 示例:搜索 "home network setup",可能返回五条几乎相同的每日笔记
- MMR(最大边际相关)重排序平衡相关性与多样性
原理:
-
根据原始分数(向量 + BM25 加权)评分
-
迭代选择最大化公式的结果:
λ × relevance − (1−λ) × max_similarity_to_selected -
相似度使用 Jaccard 文本相似度
-
λ 控制权衡:
- λ = 1 → 仅相关性
- λ = 0 → 最大多样性
- 默认 λ = 0.7(轻微偏相关性)
示例("home network setup"):
| 文件 | 原文 | 无 MMR | 启用 MMR(λ=0.7) |
|---|---|---|---|
| memory/2026-02-10.md | 配置 Omada 路由器,VLAN10 IoT | 1 | 1 |
| memory/2026-02-08.md | 配置 Omada 路由器,VLAN10 IoT | 2(重复) | ---(被剔除) |
| memory/2026-02-05.md | 配置 AdGuard DNS 192.168.10.2 | 3 | 3 |
| memory/network.md | 路由器:Omada ER605,AdGuard:192.168.10.2 | 4 | 2 |
MMR 确保 agent 获取不同信息,而非重复。
何时启用 :当 memory_search 返回大量重复 snippet 时,尤其每日笔记会重复信息
时间衰减(新近性提升):
-
每日笔记随时间累积,旧笔记可能覆盖新信息
-
时间衰减按结果年龄指数衰减得分:
decayedScore = score × e^(-λ × ageInDays) λ = ln(2) / halfLifeDays -
默认半衰期 30 天:
| 时间 | 得分占比 |
|---|---|
| 今天 | 100% |
| 7 天前 | 84% |
| 30 天前 | 50% |
| 90 天前 | 12.5% |
| 180 天前 | 1.6% |
- 永久文件不衰减:
MEMORY.md、memory/ 下非日期文件 - 日期文件使用文件名日期,其他源(如会话记录)使用修改时间
示例(今天 2 月 10 日):
| 文件 | 内容 | 原分数 | 衰减后 |
|---|---|---|---|
| memory/2025-09-15.md | Rod 周一到周五工作 | 0.91 | 0.03 |
| memory/2026-02-10.md | Rod 今日 standup | 0.82 | 0.82 |
| memory/2026-02-03.md | Rod 新团队 standup | 0.80 | 0.68 |
旧笔记自动排到后面
何时启用:当 agent 有大量每日笔记且旧信息覆盖新信息时
- 半衰期 30 天适合每日笔记密集场景
- 若经常引用旧笔记,可增加半衰期(如 90 天)
配置示例
json
agents: {
defaults: {
memorySearch: {
query: {
hybrid: {
enabled: true,
vectorWeight: 0.7,
textWeight: 0.3,
candidateMultiplier: 4,
mmr: {
enabled: true,
lambda: 0.7
},
temporalDecay: {
enabled: true,
halfLifeDays: 30
}
}
}
}
}
}- MMR 独立启用:适合大量相似笔记,但年龄不重要
- 时间衰减独立启用:适合新近性重要,但结果已多样
- 同时启用:适合长期运行、每日笔记密集的 agent
嵌入缓存(Embedding Cache)
OpenClaw 可以将文本块的嵌入向量缓存到 SQLite,这样在重新索引或频繁更新(尤其是会话记录)时,就不会重复为未改变的文本生成嵌入。
配置示例:
json
agents: {
defaults: {
memorySearch: {
cache: {
enabled: true,
maxEntries: 50000
}
}
}
}会话记忆搜索(实验性功能)
你可以选择索引会话记录,并通过 memory_search 查询。这是一个实验性功能,需要手动启用。
json
agents: {
defaults: {
memorySearch: {
experimental: { sessionMemory: true },
sources: ["memory", "sessions"]
}
}
}注意事项:
-
会话索引需要手动启用(默认关闭)
-
会话更新经过防抖处理,异步索引,一旦超过 delta 阈值则触发(尽力而为)
-
memory_search不会因索引阻塞;结果可能在后台同步完成前略显过时 -
结果仅包含 snippet,
memory_get仍仅限 memory 文件 -
会话索引是按 agent 隔离的,仅索引该 agent 的会话日志
-
会话日志保存在磁盘:
~/.openclaw/agents/<agentId>/sessions/*.jsonl- 任何拥有文件系统访问权限的进程或用户都可以读取
- 为更严格的隔离,可在不同 OS 用户或主机上运行 agent
delta 阈值示例:
json
agents: {
defaults: {
memorySearch: {
sync: {
sessions: {
deltaBytes: 100000, // ~100 KB
deltaMessages: 50 // JSONL 行数
}
}
}
}
}SQLite 向量加速(sqlite-vec)
- 当可用时,OpenClaw 会将嵌入存储在 SQLite 虚拟表(
vec0)中,并在数据库内执行向量距离查询 - 这样可以在不将所有嵌入加载到 JS 的情况下保持搜索速度
可选配置示例:
json
agents: {
defaults: {
memorySearch: {
store: {
vector: {
enabled: true,
extensionPath: "/path/to/sqlite-vec"
}
}
}
}
}注意事项:
enabled默认true;关闭后搜索回退为 JS 内存余弦相似度- 如果
sqlite-vec缺失或加载失败,OpenClaw 会记录错误并继续使用 JS 回退 extensionPath可覆盖内置路径,用于自定义构建或非标准安装
本地嵌入模型自动下载
-
默认本地嵌入模型:
hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf(约 0.6 GB) -
当
memorySearch.provider = "local"时,node-llama-cpp会解析modelPath;如果 GGUF 文件缺失,会自动下载到缓存(或local.modelCacheDir,如果设置了),然后加载 -
下载可在重试时恢复
-
原生构建要求:
bashpnpm approve-builds # 选择 node-llama-cpp pnpm rebuild node-llama-cpp -
回退:如果本地嵌入失败且
memorySearch.fallback = "openai",OpenClaw 会自动切换到远程 embeddings(默认openai/text-embedding-3-small,除非覆盖),并记录原因
自定义 OpenAI 兼容端点示例
json
agents: {
defaults: {
memorySearch: {
provider: "openai",
model: "text-embedding-3-small",
remote: {
baseUrl: "https://api.example.com/v1/",
apiKey: "YOUR_REMOTE_API_KEY",
headers: {
"X-Organization": "org-id",
"X-Project": "project-id"
}
}
}
}
}注意事项:
remote.*优先于models.providers.openai.*remote.headers会与 OpenAI 默认头合并,冲突时以remote为准- 若不设置
remote.headers,则使用 OpenAI 默认 headers
Agent 循环(Agent Loop)
Agent 循环是一个完整的"真实"运行流程:从输入 → 上下文组装 → 模型推理 → 工具执行 → 流式回复 → 持久化。它是将消息转换为操作和最终回复的权威路径,同时保持会话状态的一致性。
在 OpenClaw 中,一个循环是每个会话的单次串行执行,会在模型思考、调用工具和流式输出时发出生命周期和流事件。
入口点:
- Gateway RPC :
agent和agent.wait - CLI :
agent命令
工作原理
-
agent RPC
- 验证参数
- 解析会话 (
sessionKey/sessionId) - 持久化会话元数据
- 立即返回
{ runId, acceptedAt }
-
agentCommand
-
运行 agent:
- 解析模型和默认思考/verbose 配置
- 加载技能快照
- 调用
runEmbeddedPiAgent(pi-agent-core 运行时) - 如果嵌入循环未发出生命周期结束/错误事件,则手动发出
-
-
runEmbeddedPiAgent
- 通过每会话 + 全局队列进行串行化运行
- 解析模型和授权配置,构建 pi 会话
- 订阅 pi 事件并流式传递助手/工具增量
- 执行超时检测,超时则中止运行
- 返回 payloads + 使用元数据
-
subscribeEmbeddedPiSession
-
将 pi-agent-core 事件桥接到 OpenClaw agent 流:
- 工具事件 →
stream: "tool" - 助手增量 →
stream: "assistant" - 生命周期事件 →
stream: "lifecycle"(phase:"start"|"end"|"error")
- 工具事件 →
-
-
agent.wait
- 使用
waitForAgentJob - 等待指定 runId 的生命周期结束/错误
- 返回
{ status: ok|error|timeout, startedAt, endedAt, error? }
- 使用
队列与并发:
- 每个会话键(session lane)串行化执行,并可选通过全局 lane 控制
- 防止工具或会话冲突,保持会话历史一致
- 消息通道可选择队列模式(collect / steer / followup),以供 lane 系统使用
会话与工作区准备:
- 解析并创建工作区;沙箱运行可能重定向到沙箱工作区根目录
- 加载技能(或从快照复用),注入到环境和 prompt
- 解析并注入 bootstrap/context 文件到系统 prompt 报告
- 获取会话写锁;在流式传递前打开并准备 SessionManager
Prompt 组装 + 系统 Prompt:
- 系统 Prompt 由 OpenClaw 基础 Prompt、技能 Prompt、bootstrap 上下文和每次运行的覆盖配置组成
- 强制执行模型特定的限制和压缩保留 token
Hook 点(可拦截的位置)
OpenClaw 提供两类 Hook 系统:
- 内部 Hook(Gateway hooks):针对命令和生命周期事件的事件驱动脚本。
- 插件 Hook(Plugin hooks):在 agent/工具生命周期和 gateway 流程中的扩展点。
内部 Hook(Gateway hooks):
- agent:bootstrap:在构建 bootstrap 文件、系统 prompt 最终生成前运行,可用于添加或移除 bootstrap 上下文文件。
- 命令 Hook :如
/new、/reset、/stop等命令事件(详见 Hooks 文档)。 - 参见 Hooks 获取配置和示例。
插件 Hook(agent + gateway 生命周期):
在 agent 循环或 gateway 流程中运行:
- before_model_resolve:会话前(无消息)运行,可确定性地覆盖 provider/model。
- before_prompt_build:会话加载后(含消息)运行,可在提交 prompt 前注入 prependContext/systemPrompt。
- before_agent_start:旧兼容 Hook,可能在任一阶段运行,推荐使用上面的显式 Hook。
- agent_end:会话完成后检查最终消息列表和运行元数据。
- before_compaction / after_compaction:观察或标注压缩周期。
- before_tool_call / after_tool_call:拦截工具参数和结果。
- tool_result_persist:在工具结果写入会话记录前同步转换。
- message_received / message_sending / message_sent:入站和出站消息 Hook。
- session_start / session_end:会话生命周期边界。
- gateway_start / gateway_stop:Gateway 生命周期事件。
流式与部分回复
- 助手增量(assistant deltas)从 pi-agent-core 流式输出,并作为
assistant事件发出。 - 块式流(block streaming)可在
text_end或message_end发出部分回复。 - 推理流(reasoning streaming)可以作为独立流或块式回复发出。
- 详见 Streaming 获取块分割和块式回复行为。
工具执行 + 消息工具
- 工具开始/更新/结束事件在
tool流中发出。 - 工具结果在日志记录/发出前,会对大小和图片负载进行清理。
- 消息工具发送会被跟踪,以避免重复助手确认。
回复塑形与抑制
最终输出由以下内容组成:
- 助手文本(可选推理内容)
- 内联工具摘要(当 verbose + 允许时)
- 模型报错时的助手错误文本
处理规则:
NO_REPLY被视为静默标记,从输出中过滤。- 消息工具重复项会从最终 payload 列表中移除。
- 如果没有可渲染 payload 且工具报错,则发出回退工具错误回复(除非消息工具已发送用户可见回复)。
压缩 + 重试
- 自动压缩会发出
compaction流事件,并可能触发重试。 - 重试时,会重置内存缓冲和工具摘要以避免重复输出。
- 详见 Compaction 获取压缩流程。
事件流(当前)
- lifecycle :由
subscribeEmbeddedPiSession发出(agentCommand 作为回退) - assistant:来自 pi-agent-core 的流式增量
- tool:来自 pi-agent-core 的流式工具事件
聊天频道处理
- 助手增量缓冲为聊天增量消息(chat delta messages)。
- 会话结束/错误时发出聊天最终消息(chat final)。
超时设置
- agent.wait 默认 30 秒(仅等待),可通过
timeoutMs参数覆盖。 - Agent runtime :
agents.defaults.timeoutSeconds默认 600 秒,在runEmbeddedPiAgent超时定时器中强制执行。
可能提前终止的情况
- Agent 超时(Abort)
- AbortSignal(取消)
- Gateway 断开或 RPC 超时
agent.wait超时(仅等待,不停止 agent)
流式与块分割(Streaming and Chunking)
OpenClaw 提供两层不同的"流式"机制:
- 块式流(Block streaming / channels):随着助手输出生成,按完整块发送消息。这些是正常的频道消息,而不是 token 增量。
- 类 token 流(Token-ish streaming / Telegram 专用):在生成过程中,用部分文本更新临时预览消息。
当前没有真正的 token-delta 流到频道消息,Telegram 的预览流是唯一的部分流界面。
块式流(频道消息)
块式流会在文本生成过程中,以粗粒度块发送助手输出。
模型输出流程示意:
Model output
└─ text_delta/events
├─ (blockStreamingBreak=text_end)
│ └─ chunker 随缓冲增长输出块
└─ (blockStreamingBreak=message_end)
└─ chunker 在 message_end 时刷新
└─ 频道发送(块式回复)图例:
text_delta/events:模型流事件(非流式模型可能稀疏)chunker:EmbeddedBlockChunker,应用最小/最大字符限制 + 分块偏好channel send:实际发出的消息(块式回复)
控制项:
agents.defaults.blockStreamingDefault:"on"/"off"(默认 off)- 频道覆盖:
*.blockStreaming(可对每个频道或账号强制开启/关闭) agents.defaults.blockStreamingBreak:"text_end" 或 "message_end"agents.defaults.blockStreamingChunk:{ minChars, maxChars, breakPreference? }agents.defaults.blockStreamingCoalesce:{ minChars?, maxChars?, idleMs? }(合并流式块后发送)- 频道硬上限:
*.textChunkLimit(如channels.whatsapp.textChunkLimit) - 频道块模式:
*.chunkMode(长度优先,换行优先分段,再按长度分块) - Discord 软上限:
channels.discord.maxLinesPerMessage(默认 17),用于拆分长回复防止 UI 截断
分界语义:
text_end:块随 chunker 输出立即流出,每次 text_end 刷新message_end:等待助手消息完成后再刷新缓冲输出- 当缓冲文本超出 maxChars 时,
message_end仍会使用 chunker 分块,多块输出
块分割算法(低/高界限)
由 EmbeddedBlockChunker 实现:
- 低界限:缓冲区 >= minChars 才输出(除非强制)
- 高界限:优先在 maxChars 前分块;若强制,maxChars 处分块
- 分块偏好:段落 → 换行 → 句子 → 空格 → 强制断
- 代码块:不在代码块内部分割;若 maxChars 强制断,先关闭再重开代码块,保证 Markdown 合法
maxChars会限制在频道textChunkLimit内
合并块(Coalescing)
当块式流启用时,OpenClaw 可以在发送前合并连续块,减少"单行刷屏",仍保持渐进输出。
- 合并等待空闲间隔(idleMs)
- 缓冲区超过 maxChars 会强制刷新
- minChars 防止过小片段发送(最终刷新会发送剩余文本)
- 合并规则由
blockStreamingChunk.breakPreference决定(段落 → \n\n,换行 → \n,句子 → 空格) - 频道覆盖可通过
*.blockStreamingCoalesce设置(含 per-account 配置) - Signal/Slack/Discord 默认 minChars 提升到 1500(可覆盖)
模拟人类节奏(Human-like pacing)
- 块式流可在块间增加随机暂停(第一块后)
- 配置:
agents.defaults.humanDelay(可 per-agent 覆盖) - 模式:off(默认)、natural(800--2500ms)、custom(minMs/maxMs)
- 仅适用于块式回复,不影响最终回复或工具摘要
"流块或一次输出"
- 流块 :
blockStreamingDefault: "on"+blockStreamingBreak: "text_end",按生成流出 - 一次输出 :
blockStreamingBreak: "message_end",完成后一次刷新(可能多块) - 不流式 :
blockStreamingDefault: "off",仅最终回复 - 注意 :非 Telegram 频道需显式设置
*.blockStreaming: true才启用;Telegram 可单独开启实时预览(channels.telegram.streamMode)
Telegram 预览流(Token-ish)
-
Telegram 是唯一支持实时预览的频道
-
使用 Bot API
sendMessage(首次)+editMessageText(后续更新) -
配置:
channels.telegram.streamMode:"partial" | "block" | "off"partial:更新最新流式文本block:按块更新(同块分割规则)off:不预览流
-
预览块配置(仅 streamMode=block):
channels.telegram.draftChunk(默认 minChars: 200, maxChars: 800) -
预览流独立于块式流
-
Telegram 块式流显式开启时,跳过预览流避免重复
-
最终文本仅更新预览消息
-
非文本或复杂内容则回退到正常最终消息发送
-
/reasoning stream可写入实时推理(仅 Telegram)
流程示意:
Telegram
└─ sendMessage(临时预览消息)
├─ streamMode=partial → 编辑最新文本
└─ streamMode=block → chunker + 编辑更新
└─ 最终文本回复 → 同一消息上最终编辑
└─ 回退:清理预览 + 正常最终发送(媒体/复杂内容)图例:
- preview message:生成中更新的临时 Telegram 消息
- final edit:在同一预览消息上进行最终文本编辑
多agent(Multi-agent)
目标:在一个运行的 Gateway 中支持多个隔离代理(各自独立的 workspace + agentDir + sessions),同时支持多个频道账户(例如两个 WhatsApp)。入站消息通过绑定路由到特定代理。
什么是"一个代理"?
代理是一个完全独立的智能体,拥有自己的:
- 工作区(Workspace):文件、AGENTS.md / SOUL.md / USER.md、本地笔记、角色设定规则
- 状态目录(agentDir):存储认证信息、模型注册和每个代理的配置
- 会话存储(Session store) :聊天记录和路由状态,位于
~/.openclaw/agents/<agentId>/sessions - 认证信息 :每个代理独立读取
~/.openclaw/agents/<agentId>/agent/auth-profiles.json,主代理凭证不会自动共享。切勿在多个代理间复用 agentDir(会导致认证/会话冲突)。若要共享凭证,可手动复制auth-profiles.json到其他代理的 agentDir - 技能(Skills) :每个代理通过 workspace 下的
skills/文件夹管理,公共技能位于~/.openclaw/skills(参考 "Skills: per-agent vs shared")
Gateway 可以同时托管一个(默认)或多个代理。
工作区注意事项:每个代理的 workspace 是默认当前工作目录(cwd),而非严格沙箱。相对路径解析在 workspace 内,但绝对路径可能访问宿主其他位置,除非启用沙箱。参考 Sandboxing。
路径(快速映射)
| 类型 | 默认路径 / 描述 |
|---|---|
| 配置 | ~/.openclaw/openclaw.json(或 OPENCLAW_CONFIG_PATH) |
| 状态目录 | ~/.openclaw(或 OPENCLAW_STATE_DIR) |
| 工作区 | ~/.openclaw/workspace(或 ~/.openclaw/workspace-<agentId>) |
| 代理目录 | ~/.openclaw/agents/<agentId>/agent(或 agents.list[].agentDir) |
| 会话 | ~/.openclaw/agents/<agentId>/sessions |
单Agent模式(默认)
如果不做任何配置,OpenClaw 运行单代理:
agentId默认main- 会话键值格式:
agent:main:<mainKey> - 工作区默认
~/.openclaw/workspace(若设置OPENCLAW_PROFILE则为~/.openclaw/workspace-<profile>) - 状态默认
~/.openclaw/agents/main/agent
代理辅助工具
- 使用代理向导添加新隔离代理:
bash
openclaw agents add work- 然后添加绑定(或由向导自动完成)以路由入站消息
- 验证绑定情况:
bash
openclaw agents list --bindings快速开始
1. 创建每个代理的工作区
- 使用向导或手动创建工作区:
bash
openclaw agents add coding
openclaw agents add social- 每个代理拥有自己的 workspace,包括 SOUL.md、AGENTS.md、可选 USER.md,以及专用的 agentDir 和会话存储(
~/.openclaw/agents/<agentId>)
2. 创建频道账户
-
每个代理在目标频道创建一个账户:
- Discord:每个代理一个 bot,启用 Message Content Intent,复制每个 token
- Telegram:每个代理通过 BotFather 创建 bot,复制 token
- WhatsApp:每个账号绑定一个手机号
bash
openclaw channels login --channel whatsapp --account work- 参考频道指南:Discord / Telegram / WhatsApp
3. 添加代理、账户和绑定
- 在
agents.list下添加代理 - 在
channels.<channel>.accounts下添加频道账户 - 通过绑定将它们关联(示例略)
4. 重启并验证
bash
openclaw gateway restart
openclaw agents list --bindings
openclaw channels status --probe多代理 = 多用户,多人格
使用多代理时,每个 agentId 都是一个完全隔离的人格:
这允许多个人共享同一个 Gateway 服务器,同时保持各自的 AI "大脑"和数据隔离。
一个 WhatsApp 号码,多个人(DM 分流)
你可以在同一个 WhatsApp 账号下,将不同的私聊(DM)路由到不同代理。
- 匹配条件:发送者 E.164 格式(如
+15551234567) +peer.kind: "direct" - 回复仍来自同一个 WhatsApp 号码(不支持每个代理单独发信身份)
重要细节:私聊会折叠到代理的主会话键(main session key),要实现真正隔离,每个人最好对应一个代理。
示例配置:
json5
{
agents: {
list: [
{ id: "alex", workspace: "~/.openclaw/workspace-alex" },
{ id: "mia", workspace: "~/.openclaw/workspace-mia" }
]
},
bindings: [
{
agentId: "alex",
match: { channel: "whatsapp", peer: { kind: "direct", id: "+15551230001" } }
},
{
agentId: "mia",
match: { channel: "whatsapp", peer: { kind: "direct", id: "+15551230002" } }
}
],
channels: {
whatsapp: {
dmPolicy: "allowlist",
allowFrom: ["+15551230001", "+15551230002"]
}
}
}注意事项:
- DM 访问控制是全局的(针对 WhatsApp 账号),而非每个代理
- 对于共享群组,绑定群组到某个代理,或者使用 Broadcast 群组
路由规则(消息如何选择代理)
-
绑定是确定性的,最具体规则优先:
peer精确匹配(DM / 群 / 频道 id)parentPeer匹配(线程继承)guildId + roles(Discord 角色路由)guildId(Discord)teamId(Slack)accountId(频道账户匹配)- 频道级别匹配(
accountId: "*") - 回退到默认代理(
agents.list[].default,否则取列表第一个,默认main)
-
同一层级匹配多个绑定时,配置中靠前的优先
-
如果绑定指定多个匹配字段(如
peer + guildId),需同时满足(AND 语义)
多账户 / 多手机号
- 支持多账户的频道(如 WhatsApp)使用
accountId区分每个登录实例 - 每个
accountId可路由到不同代理,实现一个服务器托管多个手机号而不会混合会话
概念:
- agentId:一个"脑"(workspace、每代理认证、每代理会话存储)
- accountId:一个频道账户实例(如 WhatsApp 个人 vs 企业账号)
- binding:通过 (channel, accountId, peer) 以及可选 guild/team id 路由入站消息到代理
- 私聊会话折叠 :
agent:<agentId>:<mainKey>(每代理"main"会话,session.mainKey)
平台示例
Discord:每代理一个 bot
- 每个 Discord bot 对应唯一
accountId - 绑定账户到代理,保持每个 bot 的 allowlist
json5
{
agents: {
list: [
{ id: "main", workspace: "~/.openclaw/workspace-main" },
{ id: "coding", workspace: "~/.openclaw/workspace-coding" }
]
},
bindings: [
{ agentId: "main", match: { channel: "discord", accountId: "default" } },
{ agentId: "coding", match: { channel: "discord", accountId: "coding" } }
],
channels: {
discord: {
groupPolicy: "allowlist",
accounts: {
default: { token: "DISCORD_BOT_TOKEN_MAIN", guilds: { ... } },
coding: { token: "DISCORD_BOT_TOKEN_CODING", guilds: { ... } }
}
}
}
}注意事项:
- 邀请每个 bot 到对应 guild,并启用 Message Content Intent
- token 存放在
channels.discord.accounts.<id>.token(默认账户可使用DISCORD_BOT_TOKEN)
Telegram:每代理一个 bot
json5
{
agents: {
list: [
{ id: "main", workspace: "~/.openclaw/workspace-main" },
{ id: "alerts", workspace: "~/.openclaw/workspace-alerts" }
]
},
bindings: [
{ agentId: "main", match: { channel: "telegram", accountId: "default" } },
{ agentId: "alerts", match: { channel: "telegram", accountId: "alerts" } }
],
channels: {
telegram: {
accounts: {
default: { botToken: "123456:ABC...", dmPolicy: "pairing" },
alerts: { botToken: "987654:XYZ...", dmPolicy: "allowlist", allowFrom: ["tg:123456789"] }
}
}
}
}- 每个代理在 BotFather 创建一个 bot,并复制 token
- token 存放在
channels.telegram.accounts.<id>.botToken(默认账户可用TELEGRAM_BOT_TOKEN)
WhatsApp:每代理一个号码
- 启动 Gateway 前绑定账户:
bash
openclaw channels login --channel whatsapp --account personal
openclaw channels login --channel whatsapp --account biz- 示例
~/.openclaw/openclaw.json配置(JSON5):
json5
{
agents: {
list: [
{
id: "home",
default: true,
name: "Home",
workspace: "~/.openclaw/workspace-home",
agentDir: "~/.openclaw/agents/home/agent"
},
{
id: "work",
name: "Work",
workspace: "~/.openclaw/workspace-work",
agentDir: "~/.openclaw/agents/work/agent"
}
]
},
bindings: [
{ agentId: "home", match: { channel: "whatsapp", accountId: "personal" } },
{ agentId: "work", match: { channel: "whatsapp", accountId: "biz" } },
{ agentId: "work", match: { channel: "whatsapp", accountId: "personal", peer: { kind: "group", id: "1203630...@g.us" } } }
],
tools: {
agentToAgent: { enabled: false, allow: ["home", "work"] }
},
channels: {
whatsapp: {
accounts: {
personal: { /* 可选覆盖,默认路径: ~/.openclaw/credentials/whatsapp/personal */ },
biz: { /* 可选覆盖,默认路径: ~/.openclaw/credentials/whatsapp/biz */ }
}
}
}
}- 默认情况下,代理间消息必须显式开启并在 allowlist 中才可发送
示例:WhatsApp 日常聊天 + Telegram 深度工作
按频道拆分:将 WhatsApp 路由到快速的日常代理,将 Telegram 路由到 Opus 代理。
json5
{
agents: {
list: [
{
id: "chat",
name: "Everyday",
workspace: "~/.openclaw/workspace-chat",
model: "anthropic/claude-sonnet-4-5"
},
{
id: "opus",
name: "Deep Work",
workspace: "~/.openclaw/workspace-opus",
model: "anthropic/claude-opus-4-6"
}
]
},
bindings: [
{ agentId: "chat", match: { channel: "whatsapp" } },
{ agentId: "opus", match: { channel: "telegram" } }
]
}说明:
- 如果某个频道有多个账户,需要在绑定中添加
accountId(例如{ channel: "whatsapp", accountId: "personal" }) - 若要将某个单独的 DM/群组路由到 Opus,而其他消息仍走 chat,可添加
match.peer绑定;peer 绑定总是优先于全频道规则
示例:同一频道,一个 peer 路由到 Opus
保持 WhatsApp 使用快速代理,但将某个 DM 路由到 Opus:
json5
{
agents: {
list: [
{ id: "chat", name: "Everyday", workspace: "~/.openclaw/workspace-chat", model: "anthropic/claude-sonnet-4-5" },
{ id: "opus", name: "Deep Work", workspace: "~/.openclaw/workspace-opus", model: "anthropic/claude-opus-4-6" }
]
},
bindings: [
{ agentId: "opus", match: { channel: "whatsapp", peer: { kind: "direct", id: "+15551234567" } } },
{ agentId: "chat", match: { channel: "whatsapp" } }
]
}注意:peer 绑定总是优先,因此应放在全频道规则之前。
绑定到 WhatsApp 群组的家庭代理
为单个 WhatsApp 群组绑定一个专用家庭代理,设置 mention 控制和更严格的工具策略:
json5
{
agents: {
list: [
{
id: "family",
name: "Family",
workspace: "~/.openclaw/workspace-family",
identity: { name: "Family Bot" },
groupChat: { mentionPatterns: ["@family", "@familybot", "@Family Bot"] },
sandbox: { mode: "all", scope: "agent" },
tools: {
allow: ["exec", "read", "sessions_list", "sessions_history", "sessions_send", "sessions_spawn", "session_status"],
deny: ["write", "edit", "apply_patch", "browser", "canvas", "nodes", "cron"]
}
}
]
},
bindings: [
{ agentId: "family", match: { channel: "whatsapp", peer: { kind: "group", id: "120363999999999999@g.us" } } }
]
}说明:
- 工具允许/禁止列表针对 工具 而非技能;如果技能需要执行二进制程序,确保
exec被允许,并且二进制文件存在于沙箱中 - 若要严格控制群组访问,可设置
agents.list[].groupChat.mentionPatterns并保持频道的群组 allowlist
每代理沙箱和工具配置
从 v2026.1.6 开始,每个代理可以拥有独立的沙箱和工具限制:
json5
{
agents: {
list: [
{
id: "personal",
workspace: "~/.openclaw/workspace-personal",
sandbox: { mode: "off" } // 个人代理无沙箱
// 工具无限制,所有工具可用
},
{
id: "family",
workspace: "~/.openclaw/workspace-family",
sandbox: {
mode: "all", // 始终沙箱化
scope: "agent", // 每代理一个容器
docker: { setupCommand: "apt-get update && apt-get install -y git curl" } // 可选一次性容器初始化
},
tools: {
allow: ["read"], // 只允许 read 工具
deny: ["exec", "write", "edit", "apply_patch"] // 禁止其他工具
}
}
]
}
}说明:
setupCommand位于sandbox.docker下,仅在容器创建时执行一次- 当沙箱范围为
"shared"时,sandbox.docker.*的每代理覆盖将被忽略
优点:
- 安全隔离:限制不受信任代理可用的工具
- 资源控制:沙箱特定代理,同时其他代理仍可在主机上运行
- 灵活策略:每个代理可拥有不同权限
注意:
tools.elevated是全局的、基于发送者的权限,不可按代理单独配置- 若需每代理边界,请使用
agents.list[].tools禁止exec - 针对群组,请使用
agents.list[].groupChat.mentionPatterns,确保 @ 提及映射到目标代理
结尾
回顾这次对 OpenClaw 的学习体验,不得不承认,它的文档较为零散,自学曲线陡峭,外部教程也多停留在"能做什么"的层面,很少有人深入讲解背后的实现逻辑。我目前的重点仍然是理解 agent 构建的思路,而实际部署方面,我打算先在 阿里云 用十块钱体验一个月,实战感受才是最直接的学习方式。
阅读源码的过程尤其启发我。例如 Dockerfile.sandbox 的写法让我意识到,Shell 命令可以直接在 Docker 沙箱中执行,这不仅保障了环境隔离,也拓展了 agent 的可操作能力。这种发现的乐趣,恰恰是自学过程中最值得珍视的部分。学习,从来不是一蹴而就的,它是由无数个小积累堆砌而成的。每天多懂一点,每次能解决一点新的疑问,你就已经在稳步前进。或许最终,你会发现,理解 OpenClaw 的过程,不仅是在掌握工具,更是在培养一种解决问题和拆解复杂系统的思维方式。
Little Wins
shell工具
OpenClaw 的 "shell 命令" 是通过 exec 工具跑的,真正执行的位置有三种:
host: "sandbox"(默认):在 Docker 容器里执行,也就是"沙箱里"host: "gateway":直接在运行 Gateway 的那台机器上执行(本机 shell)host: "node":转发到配对的节点(macOS / Android 等)上执行
具体用哪个,由 tools.exec.host / exec.host 参数 + 沙箱配置共同决定。
Shell 到底是在哪里跑的?
核心实现在 src/agents/bash-tools.exec.ts 和 bash-tools.exec-runtime.ts:
-
createExecTool(...)决定 host:ts// 345-347 行(bash-tools.exec.ts 中) const configuredHost = defaults?.host ?? "sandbox"; const requestedHost = normalizeExecHost(params.host) ?? null; let host: ExecHost = requestedHost ?? configuredHost;可以看到:
- 如果没有特别配置,默认
host = "sandbox" - 你在调用工具时传
host: "gateway"/"node",才会切到其他宿主
- 如果没有特别配置,默认
-
最后真正起子进程的地方在
runExecProcess:ts// 388-401 行(bash-tools.exec-runtime.ts) if (opts.sandbox) { // 在 Docker 里跑 argv: [ "docker", ...buildDockerExecArgs({ containerName, command, workdir, env, tty }), ], env: process.env, } else { // 在本机 shell 里跑 const { shell, args: shellArgs } = getShellConfig(); const childArgv = [shell, ...shellArgs, execCommand]; ... }也就是说:
- 有
opts.sandbox→ 用docker ...去 exec:命令在 Docker 容器内执行 - 没有
opts.sandbox→ 用本机 shell (/bin/bash等) 跑
- 有
-
host和sandbox的关系:ts// 372 行左右(bash-tools.exec.ts) const sandbox = host === "sandbox" ? defaults?.sandbox : undefined;host === "sandbox"时才会带上sandbox配置,进而触发runExecProcess(..., sandbox: ...)host === "gateway"或"node"时,不会给sandbox,就不会进 Docker 分支
那沙箱是什么?什么时候会用到?
沙箱相关入口在 src/agents/sandbox.ts,它只是把一堆 ./sandbox/* 模块导出来。
比较关键的是 src/agents/sandbox/context.ts:
-
resolveSandboxContext(...)会根据当前会话 + 配置判断要不要为这个 session 准备沙箱:tsconst runtime = resolveSandboxRuntimeStatus({ cfg, sessionKey }); if (!runtime.sandboxed) return null; const cfg = resolveSandboxConfigForAgent(config, runtime.agentId); ... const containerName = await ensureSandboxContainer({ ... }); -
resolveSandboxConfigForAgent(在sandbox/config.ts)从openclaw.json里的:tscfg.agents.defaults.sandbox cfg.agents.list[...].sandbox // 针对某个 agent 覆盖推导出:
mode: "off" | "non-main" | "all"docker如何配workspaceAccess是none/ro/rw- 等等
因此:
- 如果配置里
agents.defaults.sandbox.mode是"off",那即使你host: "sandbox",也不会真的有可用沙箱上下文 - 常见安全配置是:
mode: "non-main":主会话在宿主机上跑,其他会话在 Docker 沙箱里跑mode: "all":所有会话都在沙箱里跑
resolveSandboxRuntimeStatus 会根据当前 sessionKey 是不是 main、当前 agent 是谁等,决定 runtime.sandboxed 是 true 还是 false。
沙箱是怎么实现的?(Docker 细节)
真正的 Docker 操作在 src/agents/sandbox/docker.ts:
-
最底层是
execDockerRaw:ts// 28-35 行 const child = spawn("docker", args, { stdio: ["pipe", "pipe", "pipe"], });用
node:child_process.spawn("docker", [...])调 Docker CLI。 -
创建容器的参数在
buildSandboxCreateArgs里(237 行起):tsargs = ["create", "--name", name, ...] args.push("--label", "openclaw.sandbox=1"); args.push("--label", `openclaw.sessionKey=${scopeKey}`); ... // 关键安全选项在 resolveSandboxDockerConfig 里 -
resolveSandboxDockerConfig(sandbox/config.ts)定义了 默认安全限制:ts// 72-81 行 return { image: ... DEFAULT_SANDBOX_IMAGE, containerPrefix: DEFAULT_SANDBOX_CONTAINER_PREFIX, workdir: DEFAULT_SANDBOX_WORKDIR, readOnlyRoot: true, tmpfs: ["/tmp", "/var/tmp", "/run"], network: "none", // 默认无网络 user: ..., capDrop: ["ALL"], // 丢弃所有 Linux capabilities env: { ... }, ... binds: ... // 只挂你允许的目录 }
这几个点很关键:
network: "none":容器默认没有网络readOnlyRoot: true+tmpfs:根文件系统只读,可写区在内存盘capDrop: ["ALL"]:全部 Capabilities 丢弃,限制对内核敏感操作binds受validateSandboxSecurity校验(sandbox/docker.ts245 行):- 会拒绝危险的挂载、网络模式、seccomp/apparmor 配置
文件系统隔离是怎么做的?
还是在 sandbox/context.ts → ensureSandboxWorkspaceLayout:
-
决定几个目录:
tsagentWorkspaceDir // 你的真实工作区(~/.openclaw/workspace/...) workspaceRoot // sandbox 根目录 sandboxWorkspaceDir // 具体这个 session/agent 的 sandbox 目录 workspaceDir // 对 agent 暴露的"当前工作目录"
关键逻辑:
- 若
workspaceAccess !== "rw":- 把 agent 的 workspace 内容 同步 一份到
sandboxWorkspaceDir(只读 / 只在沙箱里改)
- 把 agent 的 workspace 内容 同步 一份到
- 实际执行时:
- 宿主机 workdir 指向 sandbox workspace / agent workspace(二选一)
- 容器内 workdir 始终指向
cfg.docker.workdir
sandboxContext.fsBridge(154 行)则用一个 "FS bridge" 把文件读写映射到正确的沙箱目录
总结一下:沙箱通过"单独的目录 + Docker bind mount"来隔离文件系统,只把你允许的部分映射进去。
host=node 的情况(顺带说一下)
在 bash-tools.exec.ts 425 行之后:
- 当
host === "node"时:- 列出已配对节点:
listNodes({}) - 选择一个支持
system.run的节点 - 把你的命令转成对应平台的 argv(
buildNodeShellCommand) - 然后通过 Gateway 的
node.invoke调用节点上的system.run
- 列出已配对节点:
也就是说:
host=node 时,命令既不在 Gateway 进程里执行,也不在 Docker 容器里执行,而是在那个"节点进程(比如 macOS app / Android node host)"上执行。
skill 调用
Skill 在 OpenClaw 里不是一个"内建 tool 名字叫 skill"的东西,而是一整套"外部能力插件系统"。核心逻辑是:
- 每个 skill 是一个独立目录(通常带
SKILL.md、脚本/二进制等) - Gateway 在启动/刷新时扫描这些目录 ,解析
SKILL.md,形成一个 "技能快照 + 文本提示 + 命令列表" - 这些信息被塞进 Agent 的 system prompt 里的
<available_skills> ... </available_skills>区域,让大模型自己"决定用哪个技能" - 真正"执行 skill"时,通常是通过已经有的
exec(shell 执行工具)+ node.invoke 等工具 去调用 skill 对应的二进制 / 脚本,而不是有一个通用的skill.runtool 像 OpenCode 那样
也就是说:OpenClaw 里 Skill 本质上是"通过文件系统 + shell/Docker/node 执行包装起来的外部程序",Agent 通过普通工具(exec、node.invoke 等)来调用它们,Skill 系统负责扫描、过滤、拼好 prompt 和 UI 配置。
Skill 是怎么被"发现"和注入给 Agent 的?
看 src/agents/skills.ts 和 src/agents/skills/workspace.ts:
buildWorkspaceSkillSnapshot/loadWorkspaceSkillEntries:
ts
// workspace.ts (221+)
function loadSkillEntries(workspaceDir: string, opts?: { ... }): SkillEntry[] {
// 1. 决定 skills 根目录
// 2. 找到含有 SKILL.md 的子目录
// 3. 读取/解析 SKILL.md,生成 SkillEntry
}这段逻辑会:
- 从 workspace 根目录、bundled skills 目录等位置找子目录
- 只认带
SKILL.md的目录是一个 skill - 做各种限制(数量、单个 SKILL.md 大小等,防止 prompt 爆炸)
- 然后
buildWorkspaceSkillsPrompt把这些 SkillEntry 拼接成一段系统提示(system prompt):
ts
// workspace.ts 中(未贴全):
buildWorkspaceSkillsPrompt(...) // 返回一大段 <available_skills> ... 的文本- 最终这段 prompt 会被塞进
system-prompt.ts:
ts
// src/agents/system-prompt.ts 里
const skillsSection = buildSkillsSection({ skillsPrompt, ... })也就是你在源码里看到的:
text
<available_skills>
<skill>
<name>github</name>
...
</skill>
...
</available_skills>这一块和 "OpenCode 里有一个 skill 描述块" 类似,但在 OpenClaw 里,skill 本身不是一个独立的 "tool 名字叫 skill"------它只是通过 prompt 注入,让大模型知道:有哪些技能、叫什么、怎么用。
Skill 什么时候真的"跑起来"?(执行层)
Skill 的真正执行,通常有几种模式(由每个 skill 的 SKILL.md 决定):
-
本机脚本/二进制:
- 通过
exec工具(前面我们分析过的bash-tools.exec.ts/exec-runtime.ts) - 可以跑在
host="sandbox"的 Docker 里,也可以host="gateway"在本机,或者host="node"在节点
- 通过
-
远程 HTTP / API:
- 有些 skill 会描述"调用某个 HTTP endpoint",Agent 再用已有的 HTTP 工具(OpenClaw 侧是用 Node 内部的 HTTP client,而不是 model tool)去请求
- 这类通常不需要额外的"skill 工具",只是 skill 的逻辑里写清楚"调用哪儿"
-
通过节点(node.invoke)调用设备能力:
- 比如 camera、screen、canvas 等
- skill 只是把这些命令组合起来用
Skill 系统本身不提供一个统一的 runtime 像 skill.run,而是:
- 用
skills/*/SKILL.md描述:这个 skill 是什么、期望输入/输出是什么、一般调用步骤是什么 - 然后依靠已有的执行通道:
exec/node.invoke/ 内置 HTTP 客户端等
你可以在 skills/skill-creator/ 里看到官方推荐你写 skill 的方式------那一套脚手架会帮你:
- 生成
SKILL.md - 生成对应的脚本/入口
- (必要时)帮你准备 Docker / 依赖安装说明
那有没有像 "opencode 的 skill tool" 那种统一调用入口?
严格说,没有一个统一的 skill.run 工具暴露给大模型,而是:
- 发现/过滤/描述 skill → 由
src/agents/skills/*完成(生成 prompt + 元数据) - 真正执行时,各个 skill 自己约定使用哪些底层工具 :
- 绝大多数 "系统外部动作" 还是通过我们刚分析过的
exec(shell + sandbox + node)完成 - 或者通过 Gateway 提供的其他工具(browser、nodes、sessions_* 等)
- 绝大多数 "系统外部动作" 还是通过我们刚分析过的
换句话说:
在 OpenClaw 里,"Skill 系统 = 文件系统 + 元数据 + prompt 注入 + 可选的安装/健康检查",
而执行 依赖的是已经存在的通用工具(尤其是
exec),而不是再造一个通用的 "skill tool"。
对比一下"opencode skill tool"模型
你可能熟悉的是这种设计:
-
有一个类似
skill/run_skill的统一工具:json{ "tool": "run_skill", "arguments": { "name": "...", "input": "..." } } -
runtime 里面按名字查 skill,然后帮你执行
而 OpenClaw 的思路是:
- 用
SKILL.md清晰地把 skill 的用法喂给大模型(在 system prompt 里) - 模型直接"像人一样"调用它描述的命令(通常是 shell / HTTP / node.invoke),而不是通过一个
skill.run抽象层 - Skill 系统重点做的是:
- 哪些 skill 能用(OS、安装情况、allowlist)
- 把 skill 说明塞到 prompt 里
- 在聊天界面里注册
/skill、/demo_skill之类的命令
比如 skills/peekaboo/SKILL.md,它本身就比较复杂,而且是典型的"外部 CLI + 权限 + OS 限制"型 skill,很适合画整条链路。
yaml
---
name: peekaboo
description: Capture and automate macOS UI with the Peekaboo CLI.
homepage: https://peekaboo.boo
metadata:
{
"openclaw":
{
"emoji": "👀",
"os": ["darwin"],
"requires": { "bins": ["peekaboo"] },
"install":
[
{
"id": "brew",
"kind": "brew",
"formula": "steipete/tap/peekaboo",
"bins": ["peekaboo"],
"label": "Install Peekaboo (brew)",
},
],
},
}
----
Gateway 启动 / 刷新时:发现并加载
peekabooskill相关代码:
src/agents/skills.ts+src/agents/skills/workspace.ts+src/agents/skills/types.ts-
Gateway 启动(
startGatewayServer)时,会为每个 agent 准备 skill 快照:- 入口在
buildWorkspaceSkillSnapshot/loadWorkspaceSkillEntries(workspace.ts)
- 入口在
-
loadSkillEntries(...)做的事情大致是:-
在多个 root 下扫描:
- 用户 workspace 里的
skills/*/SKILL.md - bundled skills 目录(仓库里自带的
skills/peekaboo/这类)
- 用户 workspace 里的
-
对每个
SKILL.md:-
解析 frontmatter(YAML 头)
-
填一个
SkillEntry:tstype SkillEntry = { skill: Skill; // pi-coding-agent 那边的抽象 frontmatter: ParsedSkillFrontmatter; metadata?: OpenClawSkillMetadata; // 就是 SKILL.md 里的 openclaw 段 }
-
-
使用
SkillEligibilityContext过滤:tstype SkillEligibilityContext = { remote?: { platforms: string[]; // 当前 OS,比如 "darwin" hasBin: (bin: string) => boolean; // 系统里有没有某个命令 hasAnyBin: (bins: string[]) => boolean; }; };结合
OpenClawSkillMetadata.requires:tsrequires?: { bins?: string[]; // 必须存在的二进制(这里是 "peekaboo") anyBins?: string[]; env?: string[]; config?: string[]; };→ 如果当前不是 macOS,或者系统里找不到
peekaboo这个 bin,就不会把这个 skill 纳入"可用技能列表"。
-
-
通过这一轮过滤后,
peekaboo才会出现在 Agent 的 skill 列表里。
-
-
给大模型看的 system prompt:注入
peekaboo说明相关代码:
src/agents/system-prompt.ts+src/agents/skills/workspace.ts-
上一步的
SkillEntry列表,会被buildWorkspaceSkillsPrompt(...)组装成一段文本:- 里边包含:
name: peekaboodescription: ...- 一些使用示例(你在 SKILL.md 下半部分看到的那些命令示例)
- 这段文本会被包在一个
<available_skills> ... </available_skills>区块里。
- 里边包含:
-
在组 agent 的 system prompt 时(
system-prompt.ts):- 用
buildSkillsSection({ skillsPrompt })把这整块拼进 system prompt - 所以 大模型开局就能看到一个"技能总览",里面有 peekaboo 的文档。
- 用
这一层很像你在别的框架里看到的 "tools 描述块",但在 OpenClaw 里是走 system prompt 文本,而不是单独的 JSON schema。
-
-
用户发话 → 触发 agent
举个例子,你在 WhatsApp / WebChat 里说:
"用 peekaboo 帮我在 Safari 登录某个网站"
通路(我们只看核心部分):
- 消息从通道(WhatsApp/Telegram/...)进来 → Gateway → auto-reply → 路由到了一个 agent session
- 这个 session 已经带着上面那份 system prompt(包含 peekaboo 技能说明)
-
大模型"决定用 peekaboo"并构造 tool 调用
这里没有一个统一叫
skill的 tool。大模型是这么用 peekaboo 的:
-
它在 prompt 里看到:
- 有一个 skill 叫
peekaboo - 描述:"macOS UI automation CLI,命令行示例......"
- 有一个 skill 叫
-
它根据任务(比如网页登录)判断:
- 需要一个能操纵 macOS UI 的 CLI
- SKILL.md 已经给了它很多 bash 示例(
peekaboo click .../peekaboo type ...)
-
然后它会构造一个
exec工具调用(也就是我们之前看过的 bash 工具):- 伪代码形式大概是:
json{ "tool": "exec", "arguments": { "command": "peekaboo app launch \"Safari\" --open https://example.com && peekaboo see --app Safari ...", "workdir": "...", "host": "sandbox" | "gateway" | "node", "timeout": 600 } }这一步是 Pi agent 栈和大模型内部约定的,不在这个仓库里直接写成 JSON,但执行效果就是这么一条
exec调用。
关键点:Skill 自己不会"直接变成一个 tool 名字",而是给模型提供足够清晰的 CLI 文档,让模型用现有的
exec/node.invoke之类的工具去调用它。 -
-
Gateway 侧接到
exec调用:选宿主 + 决定是否进沙箱相关代码:
src/agents/bash-tools.exec.ts+bash-tools.exec-runtime.ts+agents/sandbox/*-
Pi agent 调用到
exec工具实现,也就是createExecTool(...).execute(...)这段:ts// bash-tools.exec.ts 里 const configuredHost = defaults?.host ?? "sandbox"; const requestedHost = normalizeExecHost(params.host) ?? null; let host: ExecHost = requestedHost ?? configuredHost; // "sandbox" | "gateway" | "node"- 默认是
host="sandbox"(Docker 容器) - 也可以配置成
gateway或node(比如你想在 macOS 节点上直接跑)
- 默认是
-
如果
host === "sandbox",会拿 agent 的 sandbox 配置:tsconst sandbox = host === "sandbox" ? defaults?.sandbox : undefined; ... if (sandbox) { const resolved = await resolveSandboxWorkdir(...); workdir = resolved.hostWorkdir; containerWorkdir = resolved.containerWorkdir; }这些配置来自前面说的
agents.defaults.sandbox.*和 agent 专用的sandbox字段。
-
-
真正跑 shell:
runExecProcess+ProcessSupervisor+ Docker
相关代码: src/agents/bash-tools.exec-runtime.ts + src/process/supervisor/* + src/agents/sandbox/docker.ts
-
exec工具最终会调用runExecProcess(...):ts// bash-tools.exec-runtime.ts const spawnSpec = (() => { if (opts.sandbox) { return { mode: "child", argv: [ "docker", ...buildDockerExecArgs({ containerName: opts.sandbox.containerName, command: execCommand, // 就是那个 "peekaboo ..." 命令 workdir: opts.containerWorkdir ?? opts.sandbox.containerWorkdir, env: opts.env, tty: opts.usePty, }), ], env: process.env, }; } const { shell, args: shellArgs } = getShellConfig(); const childArgv = [shell, ...shellArgs, execCommand]; ... })();- 有 sandbox:
- 真实执行的是:
docker exec ... <execCommand> <execCommand>里包含peekaboo ...
- 真实执行的是:
- 没有 sandbox:
- 真实执行的是:
/bin/bash -lc "<execCommand>"这类本机 shell 命令
- 真实执行的是:
- 有 sandbox:
-
子进程实际由
ProcessSupervisor管:ts// process/supervisor/supervisor.ts const adapter = input.mode === "pty" ? createPtyAdapter({ shell, args: [...shellArgs, ptyCommand], ... }) : createChildAdapter({ argv: input.argv, cwd: input.cwd, env: input.env, ... }); ... adapter.onStdout(chunk => input.onStdout?.(chunk)); ... waitPromise = adapter.wait() // 等进程结束- 这一层负责:
- 起进程
- 收集 stdout/stderr
- 超时 / 无输出超时 / 手动取消
- 把状态回传给上层(
exec工具 → Agent → 大模型)
- 这一层负责:
-
如果是
host="node"的情况(比如你让 exec 绑定到 macOS 节点):bash-tools.exec.ts里会走host === "node"分支:- 找到合适的 node(必须支持
system.run) - 把命令封装成
node.invoke参数,实际上调用的是节点进程那边的system.run
- 找到合适的 node(必须支持
- 这时
peekaboo命令就不是在 Gateway 机器里执行,而是在那个 macOS 节点上执行
-
执行结果如何回到大模型 / 用户这边?
ProcessSupervisor结束时返回 exit 信息:- exitCode、exitSignal、durationMs、stdout/stderr 等
runExecProcess把这些填进ExecProcessOutcome并更新 session 状态:status: "completed" | "failed"aggregated: <合并后的输出>
exec工具的onUpdate回调会把 tail 输出 + 状态通过 Pi agent 的 tool 回调返回给大模型- 大模型看到
peekaboo命令的输出(例如--json下来的 JSON),再继续下一步决策:- 比如再发一条
exec命令点击另外一个按钮 - 或者总结结果,用自然语言回答你
- 比如再发一条
-
整条链路一口气 recap(以
peekaboo为例)-
启动时 :
扫描
skills/peekaboo/SKILL.md→ 解析 metadata(os、requires、install) → 结合当前 OS 和是否存在peekaboo二进制 → 若满足条件,则把它作为一个可用 skill 加入 skill 快照。 -
构建 prompt :
把
peekaboo的说明 + 示例塞进<available_skills>区块 → 注入 agent 的 system prompt。 -
你发一句话 :
消息通过通道 → Gateway → agent session → 大模型看到 prompt,知道有
peekaboo这门"本地 UI 自动化 CLI"。 -
大模型决策 :
判断需要操作 macOS UI → 参考 SKILL.md 里的 CLI 示例 → 生成一个
exec工具调用,命令形如peekaboo ...。 -
Gateway 执行 :
exec工具根据配置选host = sandbox/gateway/node→- sandbox:用 Docker exec,在沙箱容器里跑
peekaboo ... - gateway:直接在 Gateway 主机本机 shell 里跑
- node:转成
node.invoke,在某个 macOS 节点上跑
- sandbox:用 Docker exec,在沙箱容器里跑
-
进程管理与结果 :
ProcessSupervisor管这个子进程的生命周期 → 输出通过exec工具回给大模型 → 大模型继续下一步或直接回复你。
-