一、Challenge(论文要解决什么问题?为什么难?)
1️⃣ 论文要解决的核心问题
SAM(Segment Anything Model)虽然具有强大的 zero-shot 分割能力,但它依赖人工输入 prompt(点或框)。
问题是:
如何在不人工点击的情况下,高效、自动地为 SAM 生成"必要且有效"的 prompt?
2️⃣ 为什么这是一个有挑战性的问题?
论文指出两个核心矛盾(见图1,第2页):
(1)Unintelligent Automation(非智能自动化)
SAM 原生提供 AMG(Automatic Mask Generation),即网格搜索点提示:
- 稀疏网格(16×16)→ 漏掉小物体
- 稠密网格(32×32)→ 生成大量冗余 mask
👉 因果关系:
因为网格是均匀采样 → 不考虑语义信息 → 所以要么漏检,要么冗余。
这是一个典型的:
覆盖率 vs 冗余率的内在矛盾
(2)Time and Resource Inefficiency(时间和资源效率问题)
另一类方法(OAS)使用 YOLOv8 先检测 bounding box,再作为 prompt。
问题:
- 目标检测模型很大
- 计算开销高
- 和 SAM 不协同
👉 因果逻辑:
因为额外引入检测模型 → 计算量大 → 延迟高 → 不适合边缘设备
3️⃣ 这个问题为什么难?
核心难点在于:
难点1:如何知道"哪些点值得作为 prompt"?
prompt 不是随机点,而是:
- 需要在物体内部
- 需要代表关键区域
- 需要避免重复分割
这本质是:
从连续图像空间中,找出离散且最优的语义锚点
难点2:如何避免"重复分割"?
即:
- 同一个物体被多个点重复触发
- 生成相同 mask
因为:
SAM 是 prompt-driven 的 → 同一区域多次提示 → 重复 mask
4️⃣ 这个问题的价值
为什么值得解决?
- 自动标注
- 工业视觉
- 医疗影像
- 边缘设备(如 Jetson Nano)
论文在 Edge Device 实验中展示:
AoP-SAM 在 Jetson Orin Nano 上 latency 仅 0.65s,而 OAS(Box) 需要 1.16s(见表4,第7页)。
👉 这说明:
自动 prompt + 高效过滤 → 才能真正落地。
二、Finding(核心洞察)
⚠️ 注意:finding 不是技术细节,而是"看问题的方式"。
🌟 核心 Finding
prompt 生成不应该独立于 SAM,而应该"利用 SAM 自己已经计算出的 image embedding 来预测 prompt 位置"。
换句话说:
不需要额外检测模型,只需要利用 SAM 已经算出来的特征图,就能知道哪里该放 prompt。
这就是论文的关键洞察。
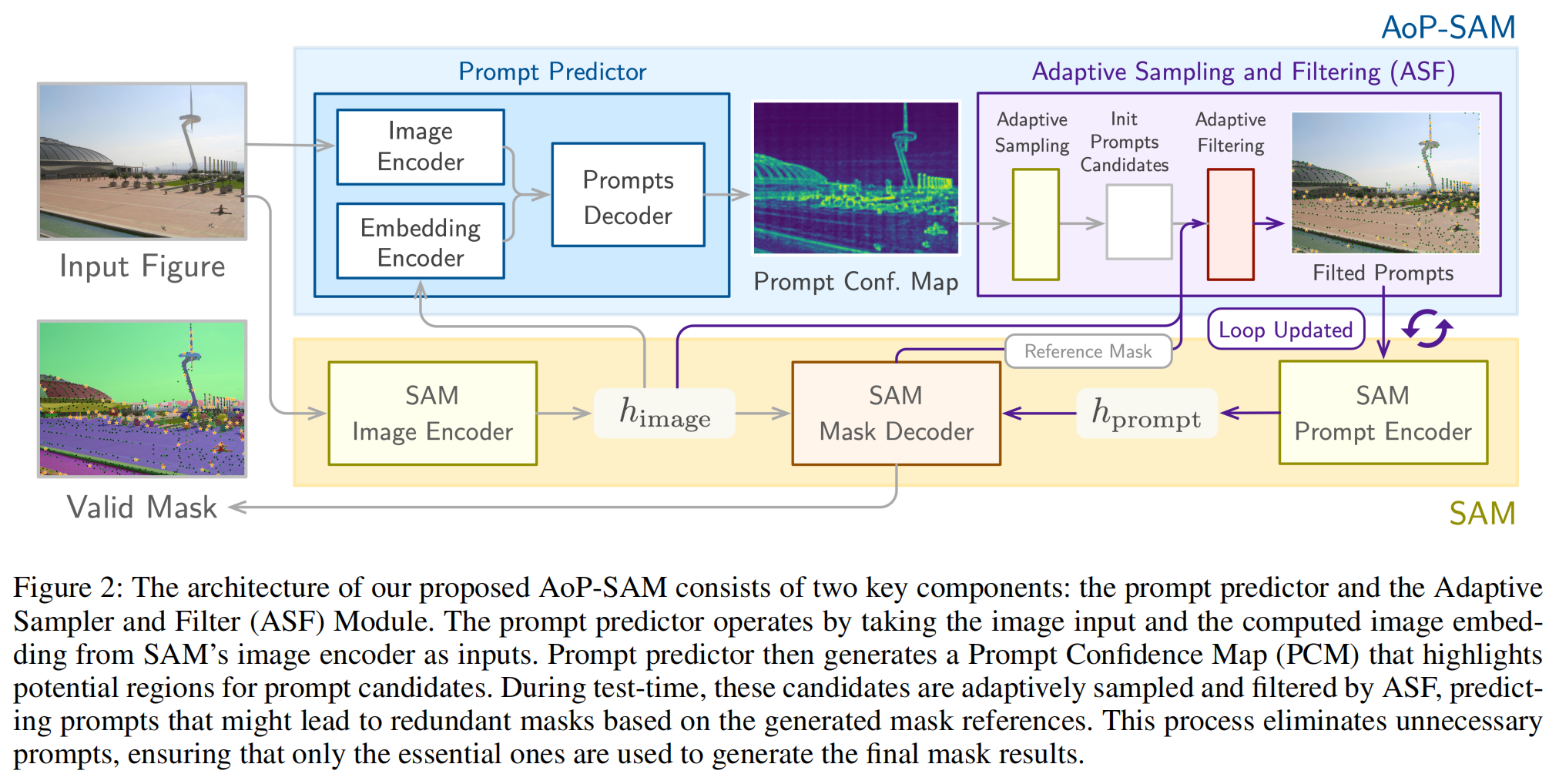
一、整体结构:上下两层 + 左右两块
这张图可以理解为一个 两层系统 + 双模块协作结构:
上层:AoP-SAM(自动化模块)
├── Prompt Predictor
└── Adaptive Sampling & Filtering (ASF)
下层:原始 SAM 框架换句话说:
AoP-SAM 并没有改动 SAM 本体,而是在上层增加一个"智能提示生成系统"。
二、从左到右:完整信息流解析
我们沿着箭头走一遍。
🔵 第一部分:Prompt Predictor(左上蓝色区域)
输入:
- 原始图像(Input Figure)
- SAM Image Encoder 生成的 embedding
注意:
图中有一条箭头从 SAM Image Encoder → Embedding Encoder,说明:
Prompt Predictor 不是独立网络,而是复用 SAM 的 image embedding。
内部结构:
1️⃣ Image Encoder(小CNN)
提取图像的空间特征。
2️⃣ Embedding Encoder
处理 SAM 的 ViT embedding。
这一步非常关键:
它不是从零预测,而是利用 SAM 已经计算好的高语义特征。
3️⃣ Prompts Decoder
将两种特征融合后:
输出:
Prompt Confidence Map(PCM)
图中那张热力图就是 PCM。
绿色亮区域 = 高概率应该放 prompt 的地方。
🔵 第二部分:Adaptive Sampling & Filtering (ASF)(右上紫色区域)
这是整个系统的"智能控制器"。
它分两步:
Step 1️⃣ Adaptive Sampling
从 PCM 里:
- 找局部极大值
- 生成初始 prompt candidates
图中灰色块:
Init Prompts Candidates这些点是"候选"。
Step 2️⃣ Adaptive Filtering
核心创新在这里。
看图中紫色箭头回路。
流程是:
- 用一部分 prompt 送入 SAM
- 得到 mask(Reference Mask)
- 根据 mask 生成 Elimination Map
- 过滤剩余候选 prompt
- 更新 prompt pool
- 循环
图中写着:
Loop Updated这是一个 迭代循环系统。
三、下层:原始 SAM 的工作流
黄色区域是 SAM:
Image Encoder → h_image
Prompt Encoder → h_prompt
Mask Decoder → 输出 mask关键点:
SAM 的 image encoder 只运行一次。
之后:
- 每次 prompt 只经过 prompt encoder + mask decoder
- 这样可以高效多次生成 mask
四、最重要:这张图真正表达的思想
这张图本质表达的是:
1️⃣ Prompt 生成是"闭环系统"
传统方法:
生成所有 prompt → 全部送进 SAM → 再过滤AoP-SAM:
生成一部分 → 生成 mask → 根据 mask 过滤剩余 prompt → 再生成这是:
coarse-to-fine(由粗到细)策略
2️⃣ 信息是双向流动的
普通方法:
Image → Prompt → Mask
AoP-SAM:
Image → Prompt → Mask
Mask → 反过来影响 Prompt
这就是图中紫色回环。
3️⃣ 它解决了什么结构性问题?
之前的矛盾是:
- 多 prompt = 高覆盖率
- 少 prompt = 高效率
AoP-SAM 通过"迭代过滤"实现:
少 prompt 但覆盖率不降
五、逐块解释图中的关键标注
🔹 h_image
SAM image encoder 输出的 embedding。
是整张图的语义基础。
🔹 h_prompt
Prompt encoder 处理后的 prompt embedding。
🔹 Reference Mask
当前已经生成的 mask。
是 ASF 过滤的依据。
🔹 Filtered Prompts
最终保留的"必要 prompt"。
黑色星号。
六、这张图体现的三层创新
我们从结构上总结。
第一层创新:Embedding Reuse
Prompt Predictor 使用:
原图 + SAM embedding而不是:
额外检测模型第二层创新:Coarse-to-Fine Prompt Selection
先粗采样,再逐步精筛。
第三层创新:语义级去重
不是:
- 距离去重
- 网格去重
而是:
- mask-level 语义相似性去重
七、用一个类比帮助你彻底理解
想象你在给图片做标注。
传统方法:
先在整张图均匀打很多点,然后删除重复的。
AoP-SAM:
先根据图像内容判断哪里可能有物体 → 试探性分割 → 如果某区域已经分割出来,就不再在那附近打点。
它像一个:
会学习的点击机器人。
八、这张图的真正精华
如果用一句话总结这张图:
AoP-SAM 把"prompt 生成"从一个静态问题,变成了一个动态自适应系统。
九、你可以这样理解整个系统
完整因果链条:
Image
↓
SAM embedding
↓
Prompt Confidence Map
↓
Initial Prompts
↓
Generate Masks
↓
Compute Elimination Map
↓
Filter Prompts
↓
Loop
↓
Final Masks为什么这是颠覆性的?
之前方法:
- 网格法:无语义
- 检测法:额外模型
AoP-SAM 的视角是:
SAM 的 image encoder 已经很强大 → 它的 embedding 已经包含了物体信息 → 那为什么不直接用它来预测 prompt?
这是一种"资源重用"的思维方式。
更深层的 finding
第二个洞察:
冗余 prompt 可以通过 mask-level 语义相似性来过滤,而不是简单位置去重。
他们引入:
Prompt Elimination Map(第5页公式1-3)
通过:
- mask feature
- image feature
- cosine similarity
判断:
如果一个点生成的 mask 和已有 mask 语义相似 → 就删掉
这是"语义级去重",而非几何级去重。
为什么这个 finding 能解决 challenge?
| Challenge | Finding如何解决 |
|---|---|
| 网格无语义 | 用 image embedding 预测高置信区域 |
| 冗余 mask | 用语义相似度构建 elimination map |
| 检测模型开销大 | 不引入新大模型 |
| 边缘设备难部署 | 轻量CNN + reuse embedding |
三、方法(具体怎么做的?)
方法分为两个核心模块:
1️⃣ Prompt Predictor
2️⃣ ASF(Adaptive Sampling & Filtering)
见论文图2(第4页)。
Step 1:输入
输入包括:
- 原始图像
- SAM image encoder 生成的 embedding(64×64)
Step 2:Prompt Predictor
架构
两个 CNN encoder:
- 图像 encoder
- embedding encoder
然后:
- concat
- 卷积 decoder
- sigmoid
输出:
Prompt Confidence Map(PCM)
范围 0~1
表示:
每个像素成为 prompt 的概率
训练方式
- 使用 SA-1B 数据集中的点 prompt
- 生成 ground truth heatmap
- 用 Gaussian + uniform kernel 平滑
- MSELoss 训练
👉 重点:只训练小模型,不 fine-tune SAM。
Step 3:Adaptive Sampling
从 PCM 中:
- Gaussian smoothing
- 找 local maxima
- threshold
- minimum distance
得到候选 prompt 点。
Step 4:Adaptive Filtering(核心创新)
流程:
- 用当前 prompt 生成 mask
- 从 mask 提取 mask feature
- 与 image feature 做 cosine similarity
- 生成 Prompt Elimination Map
- 超过阈值的候选点删除
公式见第5页(公式1-3)。
整体流程总结
图像 → embedding → PCM → coarse sampling → mask生成 → elimination map → fine filtering → 输出 essential prompts
四、实验结果与结论
1️⃣ 整体性能(表1,第6页)
例如:
在 ViT-H + LVIS 上:
| 方法 | mIoU |
|---|---|
| AMG_S | 64.9 |
| AMG_D | 71.0 |
| OAS(Box) | 63.3 |
| AoP-SAM | 71.9 |
👉 AoP-SAM 最高
而且:
PeakMem 更低(5.5GB)
2️⃣ Component 分析(表2)
| 组件 | mIoU |
|---|---|
| Prompt Predictor | 57.2 |
| + Adaptive Sampling | 72.8 |
| + Adaptive Filtering | 71.3 |
说明:
- 仅 predictor 不够
- Sampling 提升最大
- Filtering 稍降mIoU但减少冗余
3️⃣ 超参数实验(表3)
Prompt Elimination Threshold
阈值降低 → 删除比例高 → 速度快 → 准确率略降
体现 trade-off。
4️⃣ Edge Device 实验(表4)
MobileSAM + Jetson Nano:
| 方法 | Latency |
|---|---|
| OAS(Box) | 1.16s |
| AoP-SAM | 0.65s |
PeakMem:
0.042GB(极低)
说明:
AoP-SAM 真的适合部署。
五、关键术语总结
1️⃣ Segment Anything Model (SAM)
任意分割模型
一个基于 prompt 的大规模分割基础模型。
例子:点击猫的耳朵 → 分割整只猫。
2️⃣ Prompt Engineering
提示工程
通过输入点、框等信息引导模型行为。
例:点在杯子上 → 只分割杯子。
3️⃣ Zero-shot Generalization
零样本泛化
无需针对新任务训练。
例:从未见过"水壶" → 仍能分割。
4️⃣ Prompt Confidence Map (PCM)
提示置信度图
每个像素成为 prompt 的概率。
例:物体中心区域概率高。
5️⃣ Adaptive Sampling
自适应采样
从置信图中选局部极大值。
6️⃣ Prompt Elimination Map
提示消除图
表示某区域是否会产生重复 mask。
7️⃣ mIoU (mean Intersection over Union)
平均交并比
衡量分割精度。
例:预测区域与真实区域重合度。
8️⃣ Inference Latency
推理延迟
生成 prompt 所需时间。
9️⃣ Peak Memory
峰值内存
最大显存占用。
六、总结一句话
AoP-SAM 的核心不是"如何生成更多 prompt",而是:
如何利用 SAM 已有的 embedding,智能地预测少而精的 prompt,并用语义级别的过滤避免重复。
它的价值在于:
- 不增加大模型
- 不破坏 zero-shot 能力
- 显著提升效率
- 可部署到边缘设备
这篇论文本质上是在解决:
Foundation Model 如何真正落地自动化的问题。