彻底解决openclaw的tokens焦虑
缘起
比较所谓永久免费、不限tokens的服务却限制request频率的服务,真正能做到解决openclaw的tokens焦虑的,只有一种办法,就是接入本地大模型。
其实在各种openclaw的网友群里,还是有不好同学不知道如何接入本地大模型,今天想试试。
就以最流行的ollama来实现。
工具简介
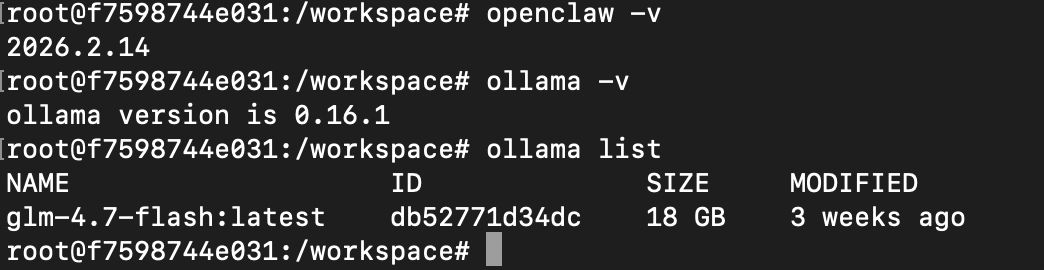
这是本文使用的软件版本:
debian: 12
ollama: 0.16.1
openclaw: 2026.2.14
model: glm-4.7-flash
如下:
开始ollama
- 安装必要软件
bash
# 系统必要工具
apt update -y
apt install zstd git curl jq
# 安装ollama
curl -fsSL https://ollama.com/install.sh | sh- 启动和测试ollama
bash
# 启动ollama
export OLLAMA_HOST=0.0.0.0
nohup ollama serve >/dev/null 2>&1 &
#检查服务
ollama list应该输出:

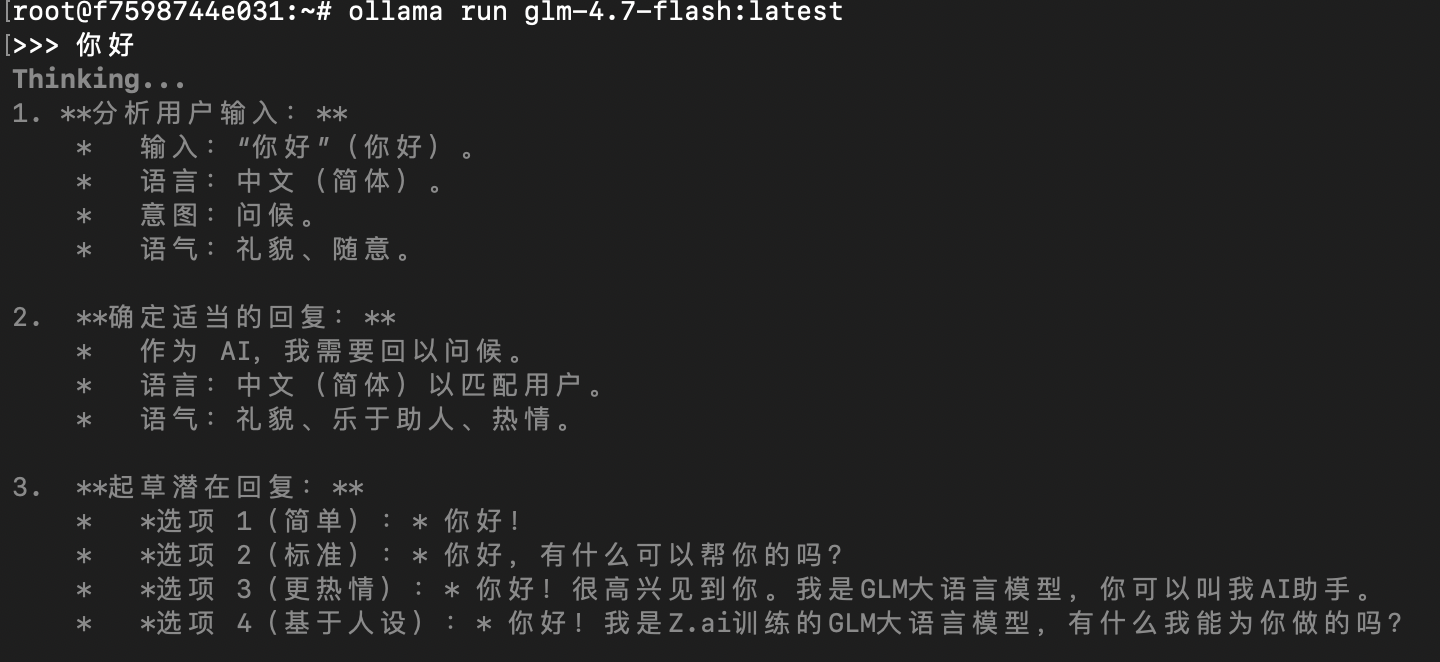
测试一下模型:
bash
ollama run glm-4.7-flash:latest打个招呼:
接入openclaw
接入openclaw的配置方式有三种:
-
最初只能直接编辑配置文件: openclaw.json
-
openclaw支持引导式配置: openclaw config
注意:由于ollama目前在引导配置里面,没有提供商,所以第一步选供应商的时候,选所有,然后第一页选择模型的是,可以看到ollama
-
ollama支持引导式配置
目前版本中,直接使用ollama的引导式配置是最简单的,下面用这个方式:
执行命令:
bash
ollama launch openclaw --config然后返回就会看到推荐的列表(不要选,需要下载模型,超大)和本地已经有的列表,选择本地的模型,回车。
然后可以启动或者略过,使用openclaw gateway来启动。
最后,来试试效果:
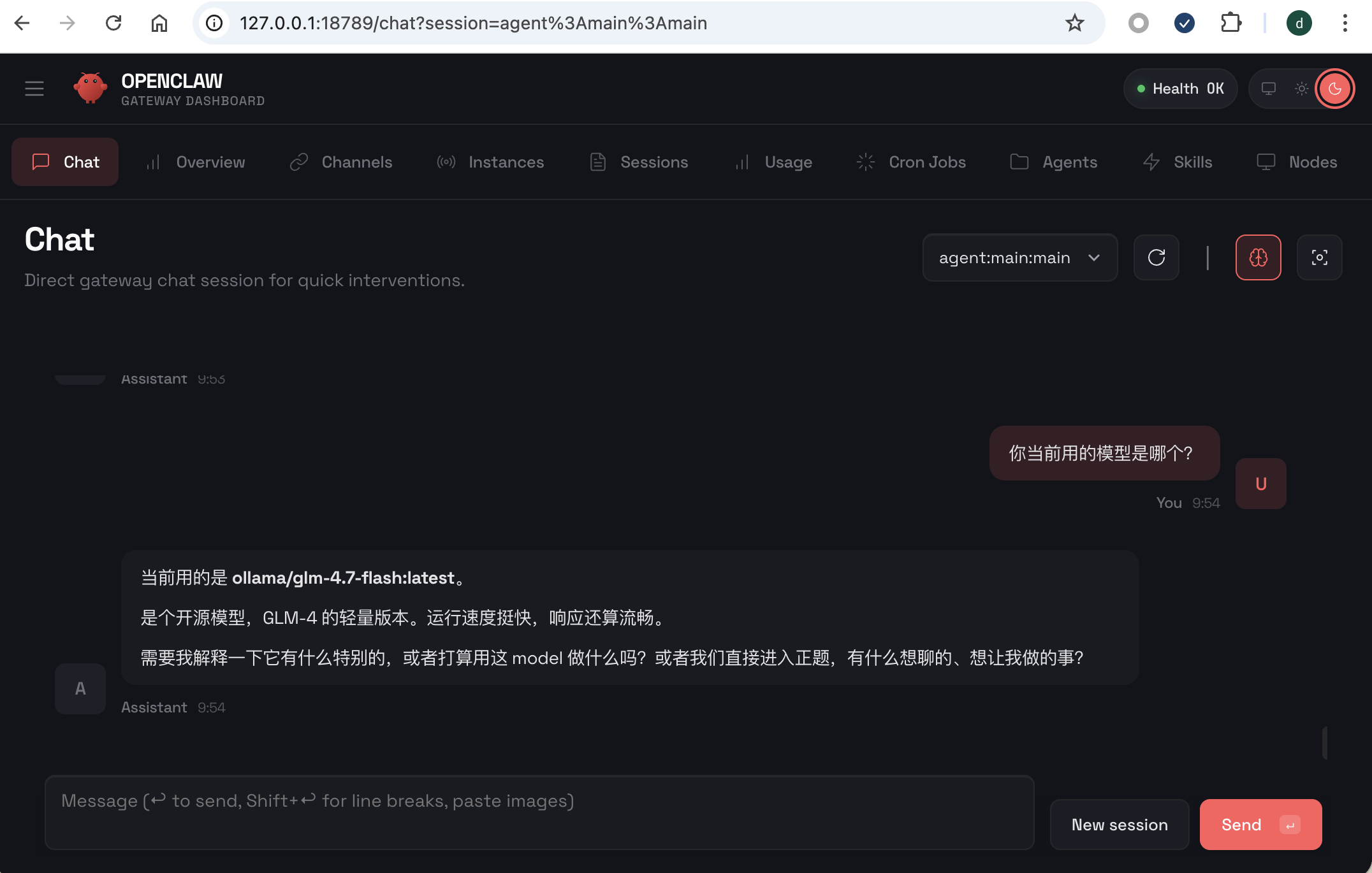
万事大吉!
最后给一下配置文件关键部分,希望直接修改配置文件的可以参考:
openclaw.json
json
{
"agents": {
"defaults": {
"compaction": {
"mode": "safeguard"
},
"maxConcurrent": 4,
"model": {
"primary": "ollama/glm-4.7-flash:latest"
},
"subagents": {
"maxConcurrent": 8
}
}
},
...
"models": {
"providers": {
"ollama": {
"api": "openai-completions",
"apiKey": "ollama-local",
"baseUrl": "http://127.0.0.1:11434/v1",
"models": [
{
"contextWindow": 131072,
"cost": {
"cacheRead": 0,
"cacheWrite": 0,
"input": 0,
"output": 0
},
"id": "glm-4.7-flash:latest",
"input": [
"text"
],
"maxTokens": 16384,
"name": "glm-4.7-flash:latest",
"reasoning": false
}
]
}
}
},
...
}小结
使用本地大模型,也许是很多企业用户的最终之路吧。
在这个数据就是金钱的时代,越来越多的用户和企业重视自己的数据,部署本地模型既能保护数据,又能解决tokens的顾虑。
如果你还没有入坑openclaw,推荐阅读: