前言
- 会随着经验不断更新这篇博客,关于kafka的运用和实践。
1.什么是kafka
- kafka是分布式消息队列,它是一种在分布式场景下适用的消息队列,message queue
2.它解决了什么问题
- 它解决的核心问题就是
专门负责不同系统之间的传递数据
1.异步解耦
- 在前面秒杀优惠券场景下,我们通常的做法是通过lua脚本先去查询并扣除库存,然后将消息发送至Stream消息队列中,再由后台多开的线程进行读取消息,进行异步处理,进行落库,而kafka就可以替换redis中的stream消息队列,更加工程化,保证redis单一职责的架构模式
2.削峰填谷
- kafka相当于一个超大容量的缓冲池,能够将流量削平,慢慢消费直到落库
3.持久化
- kafka可以支持数据写磁盘,支持副本机制,宕机可恢复
4.分布式系统间的通信
- kafka适用于分布式场景下,我们之前用的阻塞队是放在jvm里面的,倘若部署在不同的机器上面,jvm都会不同,所以无法进行不同机器之间的交流,而kafka是一个独立的服务器,所有服务器都能访问
5.大规模日志和数据流处理
- 具体遇到我们再吸取经验,先大致了解一下

3.基本概念

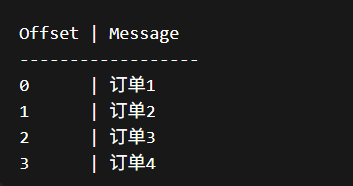
- offset 是 Kafka 每条消息在分区里的"编号"。
kafka中的结构
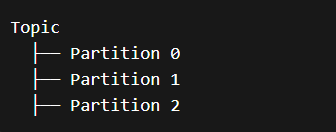
分区里面的结构
4.实现发送消息和接收消息的demo
- 1.如果你是windows系统,下载好docker desktop,选择AMD64,确保能够启动docker服务,如果是linux,直接启动docker就行了,下载kafka
- 2.书写docker-composer.yml
yml
# 表示这是个容器
services:
# zookeeper服务
zookeeper:
# 镜像选择 如果本地没有会自动pull
image: confluentinc/cp-zookeeper:7.6.0
# 环境变量
environment:
# zookeeper对外提供的客户端连接的端口是 2181
ZOOKEEPER_CLIENT_PORT: 2181
# zookeeper的心跳时间单位是 2000 ms -> 2s
ZOOKEEPER_TICK_TIME: 2000
# 宿主机的2181端口 映射到 容器的 2181端口
ports:
- "2181:2181"
# kafka服务
kafka:
# 镜像选择
image: confluentinc/cp-kafka:7.6.0
# 启动顺序 在zookeeper之后 不保证zookeeper启动成功
depends_on:
- zookeeper
# 将宿主机的9092端口 映射到 容器的 9092端口
ports:
- "9092:9092"
# 环境变量
environment:
# kafka的节点brokerId
KAFKA_BROKER_ID: 1
# kafka要连接zookeeper的地址 zookeeper 是 compose 的 service 名(容器网络 DNS 可解析)
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
# 两套监听:宿主机 + 容器内部
# 因为 Kafka 的客户端既可能来自宿主机,也可能来自容器内部网络,而不同网络环境下访问地址不同,
# 所以必须配置多个监听器和对应的广播地址。
# kafka在容器里的所有网卡都监听9092端口 在容器内部监听29092端口
KAFKA_LISTENERS: "PLAINTEXT://0.0.0.0:9092,PLAINTEXT_INTERNAL://0.0.0.0:29092"
# kafka返回给客户端(对外)的节点地址是advised里面的地址在 本机9092端口 容器里的kafka服务的29092端口使用
KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://kafka:29092"
# kafka的监听器使用明文协议 容器内部也使用明文协议
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT"
# 集群内部的节点名字 解决数据同步通道问题
KAFKA_INTER_BROKER_LISTENER_NAME: "PLAINTEXT_INTERNAL"
# 消费位移的副本数量 单机必须是 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
# kafka事务相关内部主题的副本数
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
# ISR = "正在同步的副本集合"(你可以先粗略理解为"可用副本") 单机只有一个
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
# consumer group 第一次 rebalance 时的等待时间 ms 重新分配分区的时间间隔
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0- 3.cd进docker-composer目录,docker composer up -d启动
KafkaDemoConsumer
java
package cn.fly.kafkademo.consumer;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class KafkaDemoConsumer {
@KafkaListener(topics = "demo-topic", groupId = "demo-group")
public void onMessage(String msg) {
System.out.println("我监听到了:topic为:demo-topic groupId为:demo-group的kafka消息");
System.out.println("✅ consumed: " + msg);
}
}KafkaDemoController
java
package cn.fly.kafkademo.controller;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
import lombok.*;
@RestController
@RequiredArgsConstructor
@RequestMapping("/kafka")
public class KafkaDemoController {
private final KafkaTemplate<String, String> kafkaTemplate;
@PostMapping("/send")
public String send(@RequestParam String msg) {
System.out.println(msg);
kafkaTemplate.send("demo-topic", msg);
return "sent: " + msg;
}
}application.yml
yml
spring:
kafka:
# kafka集群的入口
bootstrap-servers: localhost:9092
# 当前消费者属于哪个消费者组
consumer:
group-id: demo-group
# 当offset不存在时怎样读消息 earliest最早 latest最新 none报错
auto-offset-reset: earliest
producer:
# 生产者发送消息后多少节点确认才算成功
acks: allpom.xml
xml
<dependencies>
<!-- kafka依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- Web(做接口测试Kafka用) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>5.常见问题
1.你的maven是否配置正确
- 如果你的maven配置正确,还是启动不了,还是有依赖没导入,打开maven的生命周期,clean一遍,再compile一遍,重新加载maven,就可以了
2.为什么要双监听
- listeners 决定 Kafka 实际监听的端口;advertised.listeners 决定 Kafka 返回给客户端的可达地址。单机时两者常可一样,但在 Docker/内外网/NAT 场景下必须区分,否则客户端会拿到不可达的 broker 地址导致连接失败。比如 0.0.0.0:9092 表示容器里所有网卡都监听 9092。
3.什么是网卡
-
有一个误区,网卡和ip地址难道不一样吗?
-
不一样,网卡是一个网络接口,一个连通网络的实际通道,而ip地址就是这个通道的地址,网卡就是实际的房子,ip就是门牌号,同一个网卡可以有多个ip,而每个ip只能对应一个网卡
-
比如:0.0.0.0:9092 表示所有网卡的所有ip都可以监听9092端口,192.168.1.10:9092 表示只有这个ip对应的那个网卡才能监听9092端口
4.那既然listener已经能监听到kafka了 那为啥还要告诉客户端用哪个地址来连接我?
- listeners 决定"我在哪接电话"
advertised.listeners 决定"我告诉别人我的电话是多少",在分布式场景下,我的kafka假设我部署在公司私网地址里面,那客户端来访问kafka监听的端口,这个时候advertisedListener返回客户端你应该访问的地址,如果这个地址还是公司私网,那客户端根本连接不了,这说明,advertisedListener解决了kafka监听的地址,可能和kafka告诉客户端应该访问的地址不一致,导致客户端无法访问的问题

5.但是假设我的kafka就只部署在一台机器上呢?
- 如果kafka只部署在一台机器上,那么就可以一样,监听地址 = 客户端可达地址