Kafka 完全掌握手册(Java后端版)
说明
本文档基于原有学习记录补充,面向Java后端小白,覆盖基础概念、安装部署、代码实战、面试考点,所有例子均为极简可运行版本,图片对应的核心逻辑用通俗语言拆解,确保从"看不懂"到"能落地、能面试"。
1. 什么是Kafka
1.1 核心定位
Kafka是分布式发布-订阅消息队列,核心设计目标是:高吞吐、高可用、持久化,专为大数据量、高并发场景设计(比如日志收集、业务解耦、流式处理)
通俗理解
把Kafka比作"快递中转站":
- 生产者 = 寄快递的人
- 消费者 = 收快递的人
- 主题 = 快递分类区(比如"生鲜区""电子产品区")
- 分区 = 分类区里的货架,每个货架只能一个人取(保证顺序)
1.2 应用场景
| 场景 | 举例 |
|---|---|
| 系统解耦 | 下单后,订单服务发消息给库存、支付、物流服务 |
| 流量削峰 | 秒杀活动,先把请求写入 Kafka,消费者慢慢处理 |
| 日志收集 | ELK 架构中,FileBeat 收集日志发 Kafka,Logstash 消费 |
| 流式处理 | 实时统计网站 PV/UV、订单实时分析 |
1.3 Kafka vs 其他MQ
| 特性 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 吞吐量 | 极高(百万级 / 秒) | 中(万级 / 秒) | 高(十万级 / 秒) |
| 持久化 | 磁盘文件(高效) | 内存 + 磁盘(一般) | 磁盘(高效) |
| 顺序性 | 分区级别保证 | 队列级别保证 | 消息组级别保证 |
| 适用场景 | 大数据、高吞吐 | 低延迟、小数据量 | 电商、金融(可靠性) |
1.4 来源/作者/市场情况
- 来源:LinkedIn(领英)开发,解决日志收集和消息传递问题
- 作者:Jay Kreps等,后捐给Apache基金会,成为顶级项目
- 市场:大数据领域绝对主流,互联网公司(阿里、腾讯、美团)均大规模使用
2. Kafka的基本概念
2.1 消息和批次
消息:相当于数据表中的一条记录,只接受字节数组,send:message{key(负责路由分配),value(byte [])}
批次:kafka发送消息是批次发送,后期调优是批量的大小和延迟,即批次和吞吐量
补充:通俗例子 + 面试考点
- 消息:你发一条"订单ID=123,金额=100"就是一条消息,Kafka只认字节数组,所以需要序列化
- 批次:你一次发100条订单消息,Kafka会打包成一个批次发送(减少网络IO)
- 面试考点:批次调优(
batch.size+linger.ms) batch.size:批次最大字节数(默认16KB),满了就发送linger.ms:批次最多等多久(默认0),哪怕没满也发送- -例子:设置
linger.ms=5,batch.size=32KB,Kafka会等5ms或攒够32KB再发,平衡延迟和吞吐量
2.2 主题和分区
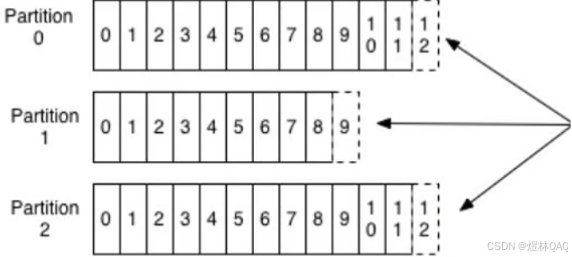
主题:是kafka的逻辑分配单元,比如数据库的表单,即kafka的数据发送到相应的主题中
分区:一个主题中包含多个分区(Parttion),分区是kafka物理存储单位,可以保证顺序存储,先进先出
注意:分区级别可以确保顺序,但是主题级别是无顺序,因为数据可以存在不一定哪个分区
补充:图片讲解 + 例子 + 面试考点
图片核心逻辑
- 图中能看到:1个主题(Topic)包含多个分区(Partition0/1/2),每个分区是独立的文件存储
- 每个分区内的消息是有序的(偏移量从0开始递增),但跨分区无序
通俗例子
- 主题="订单主题",分区=3个(相当于3个订单本)
- 生产者发消息:
- 消息1(订单1)→ 分区0(偏移量0)
- 消息2(订单2)→ 分区0(偏移量1)→ 分区0内顺序:1→2
- 消息3(订单3)→ 分区1(偏移量0)→ 主题级别顺序:1→3→2(无序)
面试高频问题
- 为什么要分多个分区?
- 并行处理:多个消费者可以同时消费不同分区(提高消费速度)
- 扩容:分区可以分布在不同Broker上,分摊存储和读写压力
- 如何保证主题级别消息有序?
- 方案:主题只设1个分区(但会失去并行性),或按业务Key路由到固定分区(比如订单ID取模)
2.3 生产者和消费者
生产者:可以将消息负载均衡的发送到一个主题中的不同分区,但是如何想叫消息有顺序的话可以将消息发送到一个主题中的固定分区中
消费者:消费者在一个分区中消息也具备顺序性
补充:例子 + 面试考点
生产者例子(顺序消息)
java
// 按订单ID取模,把同一用户的订单发到固定分区
String orderId = "123456";
int partition = Math.abs(orderId.hashCode()) % 3; // 3个分区
ProducerRecord<String, String> record = new ProducerRecord<>("order_topic", partition, "orderKey", "订单内容");
producer.send(record);面试考点
- 生产者如何选择分区?
- 指定分区→直接发
- 有Key→按Key的哈希值分配到固定分区
- 无Key→默认轮询分配(或粘性分区)
- 消费者为什么分区内有序?
- 一个分区只能被一个消费者组内的一个消费者消费,按偏移量递增读取
2.4 偏移量和消费者群组
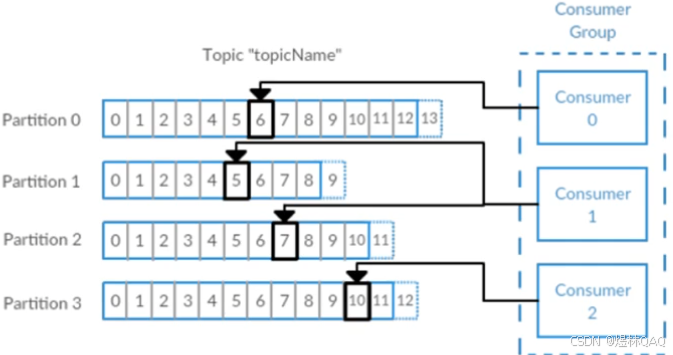
偏移量:消息在发送的时候分区里边的消息比如十条消息偏移量是九,在消费的时候消费偏移量是消费者在分区消费消息时消费到的位置,因为消息是持久化的,这样就可以防止消息重复消费
消费者群组:多个消费者可以组成一个消费者群组,一个消费者群组里一个分区只能匹配群组里边的一个消费者,但是一个消费者可以消费多个分区
疑问:消费者组每一个消费者绑定分区是绑定死的还是每次绑定都是不一样的
补充:图片讲解 + 疑问解答 + 面试考点
图片核心逻辑 - 图中能看到:
- 每个分区有自己的偏移量(Offset),比如分区0的偏移量到5,分区1到3
- 消费者组A有2个消费者,消费3个分区(消费者1消费分区0/1,消费者2消费分区2)
- 消费者组B独立消费同一主题,不影响组A
疑问解答
- 不是绑定死的!触发"重平衡"时会重新分配:
- 重平衡触发条件:消费者加入/退出组、分区数量变化、主题新增
- 例子:组A原本2个消费者消费3个分区,若新增1个消费者,会重新分配为"每个消费者1个分区"
通俗例子
- 消费者组="订单消费组",有2个消费者(客服1、客服2),订单主题有3个分区:
- 初始分配:客服1→分区0/1,客服2→分区2
- 客服1下线(重平衡):客服2→分区0/1/2(一个消费者消费所有分区)
面试高频问题
-
偏移量存在哪里?
-
Kafka 0.9前:存在Zookeeper
-
Kafka 0.9后:存在__consumer_offsets主题(内部主题) __
-
-
重复消费/漏消费的原因?
- 重复消费:偏移量提交成功,但业务处理失败
- 漏消费:业务处理成功,但偏移量提交失败
- 如何避免重复消费?
- 消费端实现幂等(比如订单ID做唯一键,数据库插入前校验)
- 手动提交偏移量(业务处理完再提交)
2.5 Broker和集群
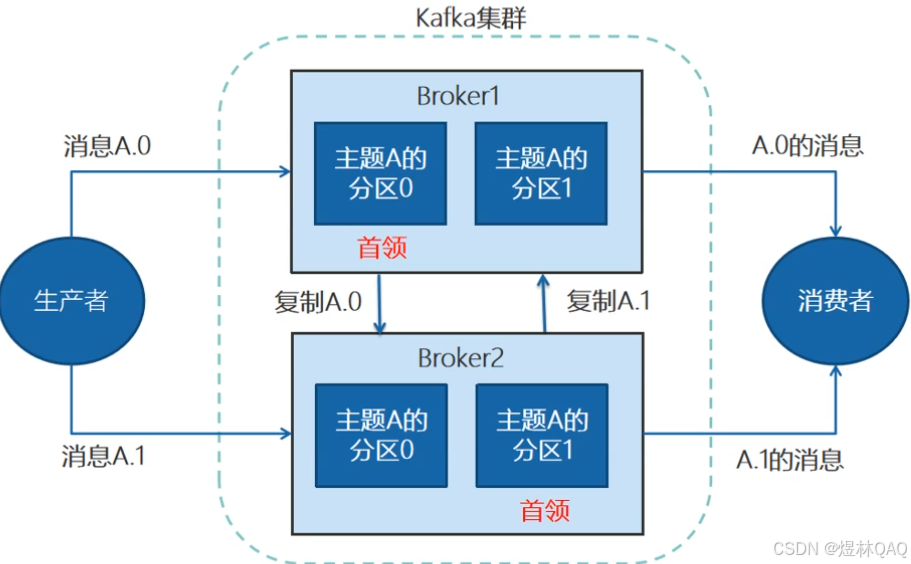 > Broker:一台独立的kafka服务
> Broker:一台独立的kafka服务
集群:把多台Broker集合在一起构建成集群
补充:图片讲解 + 集群核心逻辑
图片核心逻辑
- 图中能看到:多个Broker(服务器)组成集群,每个Broker有唯一ID(0/1/2)
- 主题的分区分布在不同Broker上(比如分区0在Broker0,分区1在Broker1)
集群核心优势
- 高可用:一台Broker宕机,其他Broker接管分区
- 高吞吐:读写压力分散到多台机器
2.6 复制与首领
复制:为了保证数据不丢失创建副本,但是不知道主次关系,所以有首领概念
首领:每个分区选择不同Broker当作首领这样的话可以保证数据最大化保护,生产和消费都是通过首领进行操作,副本是保存数据,不会丢失数据,提高容错
2.7 副本机制
只是走首领副本保存数据
补充:副本机制详解 + 面试考点
核心概念(面试必问)
- Leader副本(首领):对外提供读写,每个分区只有1个Leader
- Follower副本(跟随者):同步Leader的数据,不对外提供读写,Leader宕机后竞选为新Leader
- ISR(同步副本集):和Leader数据同步的副本(包括Leader自己),只有ISR内的副本能竞选Leader
通俗例子
- 分区0的副本数=3,分布在Broker0(Leader)、Broker1(Follower)、Broker2(Follower):
- -生产者发消息→Leader(Broker0)→Follower同步数据→Leader返回"发送成功"
- -若Broker0宕机→ISR内的Broker1竞选为新Leader→服务不中断
面试高频问题
-
副本数设置多少合适?
- 生产环境建议3(平衡可用性和存储成本),最少2(避免单点)
-
什么是"不完全首领选举"?
-
当ISR内没有可用副本时,允许非ISR内的副本成为Leader(可能丢失数据)
-
配置:
unclean.leader.election.enable=false(生产环境建议关闭)
-
-
最少同步副本(min.insync.replicas)
-
配置:
min.insync.replicas=2(副本数3),表示至少2个副本同步成功,生产者才认为消息发送成功 -
作用:防止Leader宕机后,只剩1个同步副本,数据丢失
3. Kafka版本
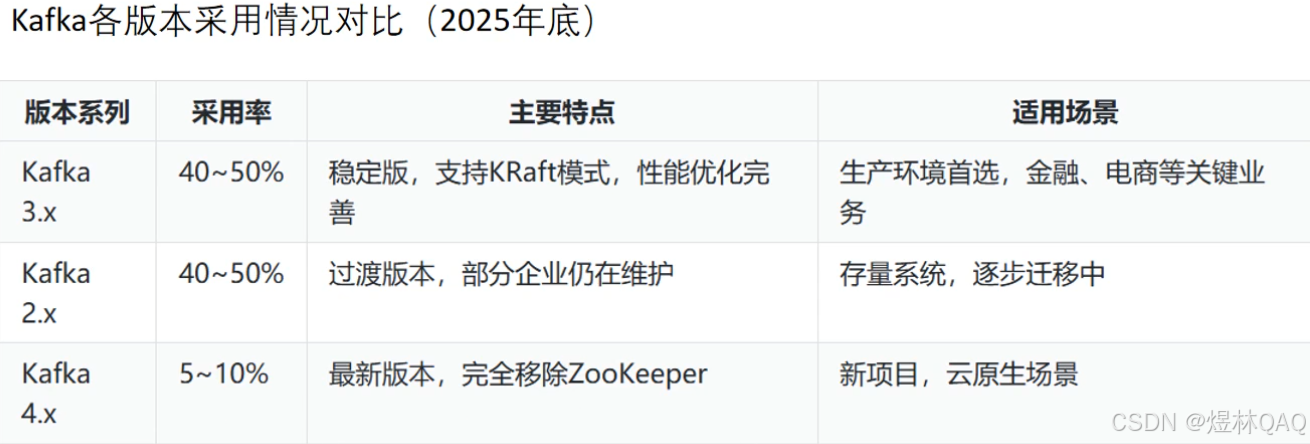
补充:版本核心差异(面试考点)
| 版本 | 核心变化 | 推荐场景 |
|---|---|---|
| 2.x | 依赖 Zookeeper,稳定成熟 | 老系统、保守型企业 |
| 3.x | 新增 KRaft 模式(可选无 Zookeeper) | 新系统、想简化部署 |
| 4.x | 完全移除 Zookeeper,只支持 KRaft | 全新项目、追求极简架构 |
版本选择建议(补充)
- 不建议直接上4.x(刚发布,生态适配待验证)
- 首选3.x(兼顾稳定性和新特性,KRaft模式可按需开启)
- 2.x适合维护老项目
4. Kafka安装
前提:安装响应版本的jdk
4.1 2.x的安装、管理和配置
补充:Windows安装常见问题排查
- 启动Zookeeper报错"端口被占用":
- 查看2181端口:
netstat -ano | findstr 2181 - 杀死占用进程:
taskkill /F /PID 进程ID
- 查看2181端口:
- 启动Kafka报错"Connection to zookeeper failed":
- 检查zookeeper.properties中
clientPort=2181是否正确 - 确保Zookeeper先启动,再启动Kafka
补充:Linux集群安装(面试常问,3节点示例)
步骤1:修改server.properties(每个Broker不同)
- Broker0:
properties
broker.id=0
listeners=PLAINTEXT://kafka01:9092
log.dirs=/data/kafka/logs
zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka
default.replication.factor=3 # 默认副本数- Broker1:
properties
broker.id=1
listeners=PLAINTEXT://kafka02:9092
log.dirs=/data/kafka/logs
zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka- Broker2:
properties
broker.id=2
listeners=PLAINTEXT://kafka03:9092
log.dirs=/data/kafka/logs
zookeeper.connect=kafka01:2181,kafka02:2181,kafka03:2181/kafka步骤2:启动集群
bash
# 所有节点启动Zookeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zk.log 2>&1 &
# 所有节点启动Kafka
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &步骤3:验证集群
bash
# 查看集群节点
./kafka-topics.sh --bootstrap-server kafka01:9092 --describe --topic new-topic
# 输出中会看到Replicas: 0,1,2(副本分布在3个Broker)补充:常用操作注释(原有命令补充注释)
bash
# 列出所有主题
./kafka-topics.sh --bootstrap-server localhost:9092 --list
# 查看主题详情(分区、副本、Leader分布)
./kafka-topics.sh --bootstrap-server localhost:9092 --describe
# 创建主题:3个分区、1个副本、名称new-topic
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic new-topic --partitions 3 --replication-factor 1
# 查看消费者组偏移量(面试常问)
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-group --describe
# 输出字段说明:
# CURRENT-OFFSET:消费者当前消费到的偏移量
# LOG-END-OFFSET:分区最新偏移量
# LAG:消费滞后数(越大说明消费越慢)
# 创建控制台生产者(测试用)
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
# 从头消费消息(测试用)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning4.2 3.x的安装、管理和配置
补充:KRaft模式核心优势
-
移除Zookeeper依赖,减少部署组件(少一个故障点)
-
元数据管理更高效(Controller直接管理,无需Zookeeper)
补充:Linux下KRaft模式启动
bash
# 1. 生成集群ID
kafka-storage.sh random-uuid
# 输出示例:abc12345-6789-0def-ghij-klmnopqrstuv
# 2. 格式化存储(用上面的集群ID)
kafka-storage.sh format --config config/kraft/server.properties --cluster-id abc12345-6789-0def-ghij-klmnopqrstuv
# 3. 启动Kafka(无需启动Zookeeper)
nohup bin/kafka-server-start.sh config/kraft/server.properties > kafka.log 2>&1 &4.3 4.x的安装、管理和配置
补充:4.x核心变化
- 彻底删除Zookeeper相关代码,配置更简化
- 推荐JDK17(性能更好)
- 兼容3.x的KRaft配置,迁移成本低
5. Kafka clients 版本兼容性
- Apache kafka 官方有明确的
向后兼容性保证 - 生产者/消费者客户端 可以
连接版本相同或更高的Broker - 但
不能保证新版客户端能连接旧版本的Broker
补充:实际开发避坑(面试考点)
- 客户端版本 ≠ Broker版本:
- 推荐:客户端版本 ≤ Broker版本(比如Broker3.9.1,客户端用3.9.1或3.8.0)
- 禁止:客户端4.x连接Broker2.x(大概率报错)
- Spring-Kafka版本适配:
| Spring-Kafka | Kafka Clients | Spring Boot |
|---|---|---|
| 3.3.x | 3.9.x | 3.2.x |
| 3.2.x | 3.8.x | 3.1.x |
6. Hello Kafka
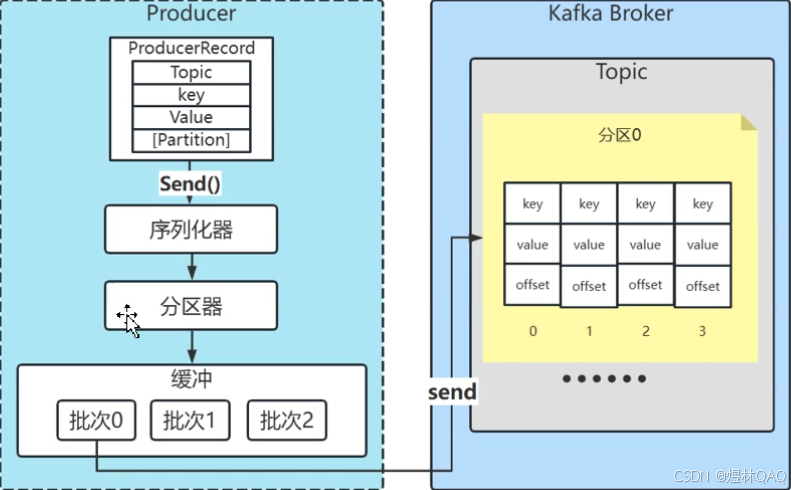
6.1 创建主题
补充:自动创建主题的风险(面试考点)
- 配置
auto.create.topics.enable=true(默认true):生产者发消息时,若主题不存在会自动创建(1个分区、1个副本) - 风险:生产环境容易出现"默认分区/副本数不合理"的问题
- 建议:生产环境设置
auto.create.topics.enable=false,手动创建主题(指定分区/副本数)
6.2 生产者发送消息(三种方式)
补充:代码完整注释 + 异常处理 + 面试考点
POM依赖(补充完整)
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.x</groupId>
<artifactId>demo_01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo_01</name>
<description>demo_01</description>
<properties>
<java.version>17</java.version>
<junit-jupiter.version>5.10.2</junit-jupiter.version>
</properties>
<dependencies>
<!-- ✅ 正确的 starter 名称是 spring-boot-starter-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- ✅ 正确的测试 starter 名称是 spring-boot-starter-test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>完整代码(带注释 + 异常处理)
java
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.Test;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaProducerTest {
// 通用配置(抽取出来,避免重复)
private Properties getProducerProps() {
Properties props = new Properties();
// Kafka服务器地址(集群用逗号分隔:kafka01:9092,kafka02:9092)
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
// Key序列化:把String转成字节数组
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// Value序列化:同上
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 消息确认机制(面试考点):all=等待所有ISR副本同步成功(最可靠)
props.put(ProducerConfig.ACKS_CONFIG, "all");
// 发送失败重试次数(避免网络抖动导致失败)
props.put(ProducerConfig.RETRIES_CONFIG, 3);
// 批次大小(默认16KB)
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// linger.ms:等待5ms再发送(攒批次,提高吞吐量)
props.put(ProducerConfig.LINGER_MS_CONFIG, 5);
return props;
}
/**
* 方式1:异步发送(无回调)
* 特点:发送后不管,不知道是否成功(生产环境不推荐)
*/
@Test
void producer1() {
KafkaProducer<String, String> producer = null;
try {
producer = new KafkaProducer<>(getProducerProps());
// 构建消息:主题名="iuit",Key="name",Value="小明"
ProducerRecord<String, String> record = new ProducerRecord<>("iuit", "name", "小明");
// 异步发送(无回调)
producer.send(record);
System.out.println("消息已发送(无回调,仅表示发送请求已提交)");
} catch (Exception e) {
// 捕获序列化/连接异常
System.err.println("发送消息失败:" + e.getMessage());
e.printStackTrace();
} finally {
// 关闭生产者(必须!否则消息可能留在缓冲区未发送)
if (producer != null) {
producer.close();
}
}
}
/**
* 方式2:同步发送(get()阻塞)
* 特点:等待发送结果,知道是否成功(适合重要消息,比如订单)
*/
@Test
void producer2() {
KafkaProducer<String, String> producer = null;
try {
producer = new KafkaProducer<>(getProducerProps());
ProducerRecord<String, String> record = new ProducerRecord<>("iuit", "name", "小王");
// 同步发送:get()会阻塞,直到收到Broker响应
RecordMetadata metadata = producer.send(record).get();
// 打印发送结果(面试常问:RecordMetadata包含哪些信息?)
System.out.println("消息发送成功!");
System.out.println("主题:" + metadata.topic());
System.out.println("分区:" + metadata.partition());
System.out.println("偏移量:" + metadata.offset());
} catch (InterruptedException | ExecutionException e) {
System.err.println("同步发送失败:" + e.getMessage());
e.printStackTrace();
} finally {
if (producer != null) {
producer.close();
}
}
}
/**
* 方式3:异步发送(带回调)
* 特点:非阻塞,成功/失败都有回调(生产环境推荐)
*/
@Test
void producer3() {
KafkaProducer<String, String> producer = null;
try {
producer = new KafkaProducer<>(getProducerProps());
ProducerRecord<String, String> record = new ProducerRecord<>("iuit", "name", "小张");
// 异步发送+回调
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
// 发送成功
System.out.println("回调:消息发送成功!分区=" + metadata.partition() + ", 偏移量=" + metadata.offset());
} else {
// 发送失败(比如Broker宕机、副本不足)
System.err.println("回调:消息发送失败!" + e.getMessage());
e.printStackTrace();
}
}
});
System.out.println("消息发送请求已提交(异步回调)");
// 休眠1秒,确保回调执行(测试用,生产环境无需)
Thread.sleep(1000);
} catch (Exception e) {
System.err.println("发送请求提交失败:" + e.getMessage());
e.printStackTrace();
} finally {
if (producer != null) {
producer.close();
}
}
}
}面试考点(生产者发送)
- ACKS配置的三种值?
- 0:生产者发完就认为成功(最快,可能丢数据)
- 1:Leader收到消息就返回(默认,Leader宕机可能丢)
- all/-1:所有ISR副本收到才返回(最可靠,最慢)
- 为什么需要重试?
- 网络抖动、Leader切换等临时故障,重试可提高成功率
- 注意:重试可能导致消息重复(需消费端幂等)
- 生产者如何保证消息不丢失?
- ACKS=all - 开启重试(retries>0)
- 确保生产者close()(刷缓冲区)
- 设置min.insync.replicas≥2
6.3 顺序保障
kafka消息发送的顺序保障
- 一个主题一个分区,主题就具备顺序性
- 就算一个主题多个分区,在一个分区内,消息也会具备顺序的
补充:顺序保障例子 + 面试考点
例子:订单状态流转(必须有序)
- 订单状态:创建→支付→发货→完成
- 实现:按订单ID哈希到固定分区
java
// 按订单ID路由到固定分区
public int getPartitionByOrderId(String orderId, int partitionCount) {
return Math.abs(orderId.hashCode()) % partitionCount;
}
// 发送订单消息
String orderId = "OD123456";
int partition = getPartitionByOrderId(orderId, 3); // 3个分区
ProducerRecord<String, String> record = new ProducerRecord<>("order_topic", partition, orderId, "支付成功");
producer.send(record);面试考点
- 为什么分区内有序?
- 生产者按顺序发消息到分区,Kafka按顺序写入磁盘,消费者按顺序读
- 什么情况下会破坏顺序?
- 生产者重试(比如消息1发送失败,重试后消息2先成功)
- 解决方案:设置
max.in.flight.requests.per.connection=1(单连接最多1个请求,保证顺序,但降低吞吐量)
6.4 生产和消费序列化器
kafka的序列化:
Avro:语言无关,序列化后体积小案例:
- LinkedIN:Avro
- 国内大厂:Avro、Protobuf、自定义、json序列化
补充:图片讲解 + 常见序列化方式代码示例
图片核心逻辑
- 图中展示了序列化的核心:把对象→字节数组(网络传输/存储),反序列化:字节数组→对象
- 不同序列化方式的对比:体积、速度、跨语言支持
示例1:JSON序列化(最常用,易调试)
java
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.Deserializer;
// 自定义JSON序列化器
public class JsonSerializer<T> implements Serializer<T> {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(String topic, T data) {
if (data == null) return null;
try {
return objectMapper.writeValueAsBytes(data);
} catch (Exception e) {
throw new RuntimeException("JSON序列化失败", e);
}
}
}
// 自定义JSON反序列化器
public class JsonDeserializer<T> implements Deserializer<T> {
private final ObjectMapper objectMapper = new ObjectMapper();
private Class<T> targetClass;
public JsonDeserializer(Class<T> targetClass) {
this.targetClass = targetClass;
}
@Override
public T deserialize(String topic, byte[] data) {
if (data == null) return null;
try {
return objectMapper.readValue(data, targetClass);
} catch (Exception e) {
throw new RuntimeException("JSON反序列化失败", e);
}
}
}
// 使用示例(生产者)
Properties props = new Properties();
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class.getName());
KafkaProducer<String, Order> producer = new KafkaProducer<>(props);
ProducerRecord<String, Order> record = new ProducerRecord<>("order_topic", new Order("OD123", 100.0));
producer.send(record);
// 使用示例(消费者)
Properties props = new Properties();
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class.getName());
// 指定反序列化的目标类(需自定义配置)
props.put("json.target.class", Order.class.getName());
KafkaConsumer<String, Order> consumer = new KafkaConsumer<>(props);示例2:Protobuf序列化(高性能,跨语言)
- 步骤1:定义.proto文件
protobuf
syntax = "proto3";
package com.kafka.demo;
message Order {
string order_id = 1;
double amount = 2;
}- 步骤2:生成Java类(用protoc工具)
- 步骤3:使用Protobuf序列化器
java
// 生产者
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ProtobufSerializer.class.getName());
ProducerRecord<String, Order> record = new ProducerRecord<>("order_topic", Order.newBuilder().setOrderId("OD123").setAmount(100.0).build());
// 消费者
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ProtobufDeserializer.class.getName());
props.put(ProtobufDeserializer.VALUE_PROTOBUF_TYPE, Order.class.getName());面试考点
- 为什么不推荐用Java默认序列化?
- 体积大、速度慢、不跨语言、版本兼容差
- 序列化方式怎么选?
- 调试优先:JSON
- 性能/跨语言优先:Protobuf/Avro
- 简单场景:String(比如日志)
6.5 分区器
分局上边配置新增
- 默认分区器会根据key的值进行分区匹配 -
- 轮询:将消息平均分配
- 统一粘性分区器:不管有没有key都会进行分区匹配
- 可以直接在发送中指定
- 自定义分区
补充:代码示例 + 面试考点
完整分区器示例
java
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
// 1. 默认分区器(DefaultPartitioner)
// 逻辑:有Key→哈希到固定分区;无Key→粘性分区(3.0+)
Properties props = new Properties();
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class.getName());
// 2. 轮询分区器(RoundRobinPartitioner)
// 逻辑:不管有没有Key,轮询分配到所有分区(保证均匀)
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class.getName());
// 3. 粘性分区器(UniformStickyPartitioner)
// 逻辑:无Key时,优先往一个分区发(攒批次),批次满了再换分区(提高吞吐量)
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UniformStickyPartitioner.class.getName());
// 4. 自定义分区器(按业务规则,比如按用户ID尾号)
public class UserIdPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取主题的所有分区
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
// 按用户ID尾号分区(假设Key是用户ID)
if (keyBytes == null || !(key instanceof String)) {
// 无Key→默认0分区
return 0;
}
String userId = (String) key;
int tailNum = Integer.parseInt(userId.substring(userId.length() - 1));
return tailNum % numPartitions;
}
@Override
public void close() {
// 关闭资源(如果有)
}
@Override
public void configure(Map<String, ?> configs) {
// 读取自定义配置(如果有)
}
}
// 使用自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, UserIdPartitioner.class.getName());面试考点
- 默认分区器的逻辑?
- Kafka 3.0前:无Key→轮询;有Key→哈希
- Kafka 3.0后:无Key→粘性分区(提高批次效率);有Key→哈希
- 粘性分区器的优势?
- 减少分区切换,攒更多批次,提高吞吐量
- 自定义分区器的使用场景?
- 按业务规则分区(比如按用户地域、订单类型)
6.6 缓冲\批次
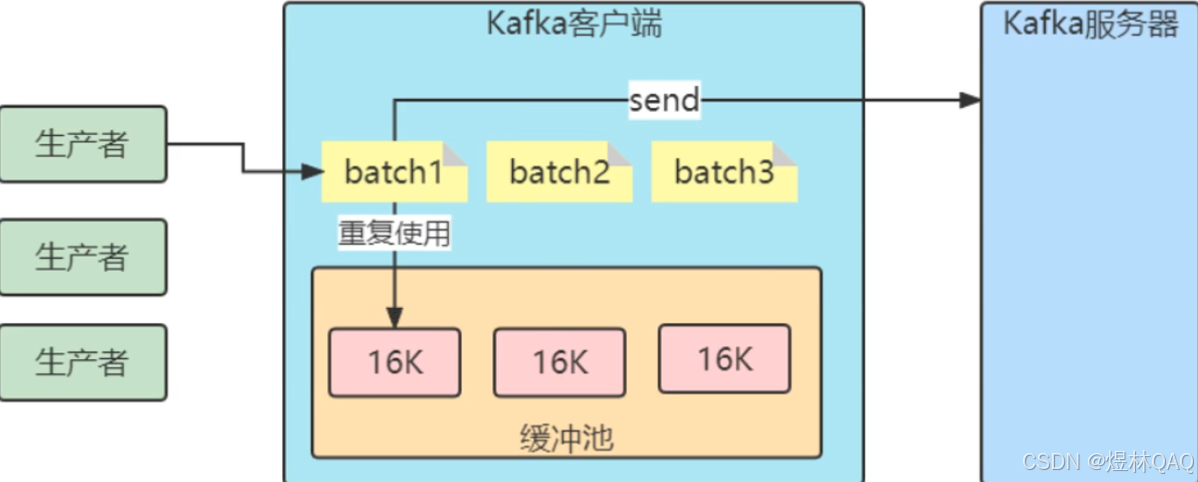
- buffer.memory
- batch.size
- linger.ms
补充:图片讲解 + 调优例子
图片核心逻辑
- 图中展示了生产者的缓冲区:
- 生产者发消息→先写入缓冲区(buffer.memory)
- 缓冲区按分区分批次(batch.size)
- 满足batch.size或linger.ms就发送批次
- 发送线程异步发送批次到Broker
调优例子(生产环境)
- 高吞吐场景(日志收集):
properties
buffer.memory=67108864 # 64MB(默认32MB)
batch.size=32768 # 32KB(默认16KB)
linger.ms=10 # 等待10ms(默认0)- 低延迟场景(订单):
properties
batch.size=8192 # 8KB
linger.ms=1 # 等待1ms
buffer.memory=33554432 # 默认32MB面试考点
- buffer.memory满了会怎样?
- 生产者send()会阻塞,直到缓冲区有空间(默认阻塞时间由
max.block.ms控制,超时抛异常)
- 生产者send()会阻塞,直到缓冲区有空间(默认阻塞时间由
- 批次调优的核心思路?
- 高吞吐:增大batch.size + 设linger.ms(牺牲一点延迟)
- 低延迟:减小batch.size + linger.ms=0(牺牲一点吞吐量)
7 消费者接受消息的基本流程
7.1 消费者和消费者组
核心规则:
- 一个分区只能被同一消费者组内的一个消费者独占消费
- 消费者数量 <= 分区数:每个消费者分配一个或者多个分区
- 消费者数量> 分区数:多个消费者处于空闲状态
- 不同消费者组可独立消费同一主题,互不影响
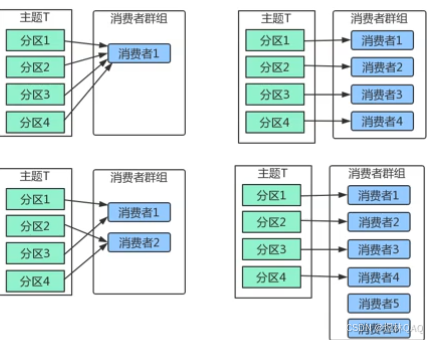
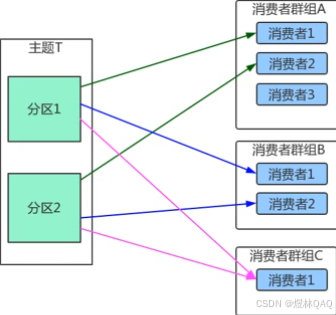
补充:图片讲解 + 面试考点
图片核心逻辑
- 图1:消费者组A有2个消费者,消费4个分区(消费者1→分区0/1,消费者2→分区2/3)
- 图2:消费者组B有3个消费者,消费4个分区(消费者1→0,消费者2→1,消费者3→2/3,无空闲)
- 核心:同一组内消费者和分区是"多对多",但分区只能被一个消费者消费
面试考点
- 消费者数量超过分区数有什么问题?
- 多余的消费者空闲(浪费资源),建议消费者数量≤分区数
- 不同消费者组消费同一主题,偏移量是否共享?
- 不共享!每个消费者组有自己的偏移量(__consumer_offsets主题按组存储) __
7.2 消费者配置
补充:分区分配策略图片讲解 + 代码示例
RangeAssignor(范围分配)


- 图片逻辑:按主题分配连续分区,比如2个消费者、5个分区→消费者1=0/1/2,消费者2=3/4(负载不均)
-
- 例子:
java
// 配置Range策略
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RangeAssignor.class.getName());RoundRobinAssignor(轮询分配)


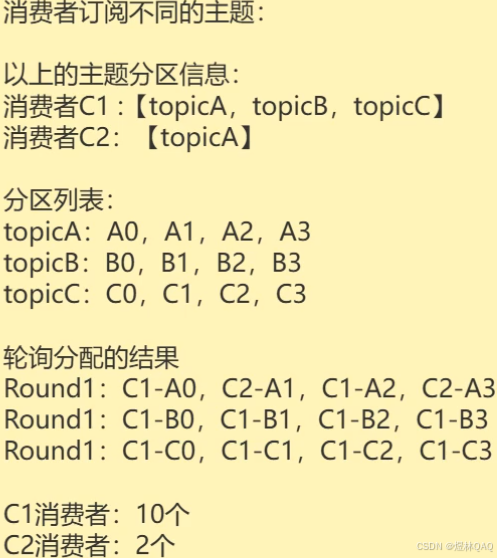
- 图片逻辑:跨主题轮询分配,比如2个消费者、5个分区→消费者1=0/2/4,消费者2=1/3(负载均匀)
- 缺点:消费者订阅不同主题时,分配不均
- 例子:
java
// 配置RoundRobin策略
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());StickyAssignor(粘性分配)


- 图片逻辑:初始分配均匀,重平衡时尽量保留原有分区(减少迁移)
- 例子:
java
// 配置Sticky策略(生产环境推荐)
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());CooperativeStickyAssignor(协作粘性分配)


- 图片逻辑:增强版Sticky,重平衡时只迁移必要分区,不中断其他分区消费(减少停顿)
- 例子:
java
// 配置CooperativeSticky策略
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, CooperativeStickyAssignor.class.getName());补充:消费者完整代码(带注释 + 面试考点)
java
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.junit.jupiter.api.Test;
import java.time.Duration;
import java.util.Collections;
import java.util.Map;
import java.util.Properties;
public class KafkaConsumerTest {
private Properties getConsumerProps() {
Properties props = new Properties();
// Kafka服务器地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
// 消费者组ID(必须!否则报错)
props.put(ConsumerConfig.GROUP_ID_CONFIG, "groupB");
// Key反序列化
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Value反序列化
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 分区分配策略(生产环境推荐Sticky)
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName());
// 首次消费偏移量:earliest=从头消费,latest=从最新消费(默认)
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 关闭自动提交(生产环境推荐手动提交)
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
// 每次拉取最大消息数(默认500,可根据业务调整)
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 100);
// 会话超时(默认45s,消费者心跳超时会触发重平衡)
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 30000);
// 拉取超时(消费者多久拉一次消息)
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000); // 5分钟
return props;
}
/**
* 基础消费(手动异步提交)
*/
@Test
void consumer01() {
KafkaConsumer<String, String> consumer = null;
try {
consumer = new KafkaConsumer<>(getConsumerProps());
// 订阅主题(支持正则,比如"order-*")
consumer.subscribe(Collections.singletonList("iuit"));
// 消费循环(生产环境是无限循环)
while (true) {
// 拉取消息(超时时间1秒)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
if (records.isEmpty()) {
continue; // 无消息,继续轮询
}
// 处理消息
for (ConsumerRecord<String, String> record : records) {
try {
// 业务处理(比如保存到数据库)
System.out.println("消费消息:key=" + record.key() + ", value=" + record.value() +
", partition=" + record.partition() + ", offset=" + record.offset());
} catch (Exception e) {
// 单个消息处理失败,可记录日志、重试或死信队列
System.err.println("处理消息失败:" + record.offset() + ", " + e.getMessage());
}
}
// 手动异步提交偏移量(非阻塞,不影响消费速度)
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
System.err.println("异步提交偏移量失败:" + exception.getMessage());
// 失败可记录日志,后续人工处理
} else {
System.out.println("异步提交偏移量成功:" + offsets);
}
});
// 测试用:消费10次退出
static int count = 0;
if (count++ >= 10) {
break;
}
}
} catch (Exception e) {
System.err.println("消费异常:" + e.getMessage());
e.printStackTrace();
} finally {
if (consumer != null) {
try {
// 关闭前同步提交(确保最后一批消息的偏移量提交成功)
consumer.commitSync();
} finally {
consumer.close(); // 关闭消费者,触发重平衡
}
}
}
}
/**
* 指定分区消费(不参与重平衡)
*/
@Test
void consumerAssign() {
KafkaConsumer<String, String> consumer = null;
try {
consumer = new KafkaConsumer<>(getConsumerProps());
// 直接分配分区(订阅特定分区,不触发重平衡)
TopicPartition partition0 = new TopicPartition("iuit", 0);
TopicPartition partition1 = new TopicPartition("iuit", 1);
consumer.assign(Collections.singletonList(partition0));
// 手动指定偏移量消费(从偏移量10开始)
consumer.seek(partition0, 10);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println("指定分区消费:" + record);
}
consumer.commitSync();
}
} finally {
if (consumer != null) {
consumer.close();
}
}
}
}补充:消费者面试高频问题
- 自动提交vs手动提交?
- 自动提交:简单,但可能重复消费(提交了偏移量,业务没处理完)
- 手动提交:可控,业务处理完再提交(推荐生产环境)
- 重平衡的影响?
- 消费停顿(消费者重新分配分区)
- 解决方案:
- 减少重平衡(避免频繁上下线消费者)
- 使用CooperativeSticky策略(减少分区迁移)
- 合理设置session.timeout.ms
- 消费者心跳机制?
- 消费者定期给Broker发心跳(默认3秒),证明自己存活
- 心跳超时(session.timeout.ms)→ Broker认为消费者死亡→触发重平衡
- 如何处理消费失败的消息?
- 重试(有限次数,比如3次)
- 死信队列(重试失败后,发送到专门的死信主题,人工处理)
- 记录日志+告警(避免丢失)
8. Kafka的SpringBoot实战
pom
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.x</groupId>
<artifactId>demo_01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo_01</name>
<description>demo_01</description>
<properties>
<java.version>17</java.version>
<junit-jupiter.version>5.10.2</junit-jupiter.version>
</properties>
<dependencies>
<!-- ✅ 正确的 starter 名称是 spring-boot-starter-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- ✅ 正确的测试 starter 名称是 spring-boot-starter-test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.3.11</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<version>3.3.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>补充
配置文件(application.yml)
yaml
spring:
application:
name: demo_01
kafka:
bootstrap-servers: localhost:9092 # kafka服务器地址
# 生产者配置
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
acks: all # 消息确认机制
retries: 3 # 发送失败重试次数
batch-size: 16384 # 批量发送大小(16KB)
buffer-memory: 33554432 # 发送缓冲区大小(32MB)
linger-ms: 5 # 等待5ms攒批次
# 消费者配置
consumer:
group-id: iuit-group # 默认消费者组
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 修正:之前是Serializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 修正:之前是Serializer
enable-auto-commit: false # 关闭自动提交
auto-commit-interval: 1000 # 自动提交间隔(关闭后无效)
auto-offset-reset: earliest # 首次消费从头开始
max-poll-records: 100 # 每次拉取100条
# 监听器配置
listener:
type: single # single=单条消费,batch=批量消费
ack-mode: manual_immediate # 手动立即提交
concurrency: 3 # 并发消费者数量(≤分区数)核心代码补充注释(生产者)
java
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
@Service
public class KafkaProducerService {
// 注入KafkaTemplate(SpringBoot自动配置)
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 同步发送(适合重要消息,比如订单)
*/
public void sendMessageSync(String topic, String message) {
try {
// get()阻塞等待结果
SendResult<String, String> result = kafkaTemplate.send(topic, message).get();
System.out.println("同步发送成功:" +
"主题=" + result.getRecordMetadata().topic() +
", 分区=" + result.getRecordMetadata().partition() +
", 偏移量=" + result.getRecordMetadata().offset());
} catch (Exception e) {
System.err.println("同步发送失败:" + e.getMessage());
// 发送失败处理(比如重试、记录日志)
}
}
/**
* 异步发送(适合非核心消息,比如日志)
*/
public void sendMessageAsync(String topic, String message) {
CompletableFuture<SendResult<String, String>> future = kafkaTemplate.send(topic, message);
// 回调处理
future.whenComplete((result, ex) -> {
if (ex == null) {
System.out.println("异步发送成功:" + result.getRecordMetadata());
} else {
System.err.println("异步发送失败:" + ex.getMessage());
}
});
}
/**
* 带Key发送(保证同一Key到固定分区)
*/
public void sendMessageWithKey(String topic, String key, String value) {
kafkaTemplate.send(topic, key, value);
}
/**
* 指定分区发送
*/
public void sendToPartition(String topic, Integer partition, String key, String value) {
kafkaTemplate.send(topic, partition, key, value);
}
/**
* 发送消息到死信队列(处理消费失败的消息)
*/
public void sendToDlq(String dlqTopic, String message) {
kafkaTemplate.send(dlqTopic, message);
}
}核心代码补充注释(消费者)
java
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
@Component
public class KafkaConsumerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class);
/**
* 基础消费(单条)
*/
@KafkaListener(topics = "iuit-topic", groupId = "iuit-group")
public void consumeMessage(String message) {
logger.info("基础消费:{}", message);
// 自动提交(若开启),这里配置的是手动提交,所以需要ack.acknowledge()
}
/**
* 完整消息消费(获取分区、偏移量等)
*/
@KafkaListener(topics = "iuit-topic", groupId = "iuit1-group")
public void consumeFullMessage(ConsumerRecord<String, String> record) {
logger.info("完整消息:topic={}, partition={}, offset={}, key={}, value={}",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
// 业务处理...
}
/**
* 批量消费(需要配置listener.type=batch)
*/
@KafkaListener(topics = "batch-topic", groupId = "batch-group", containerFactory = "batchFactory")
public void consumeBatchMessages(List<ConsumerRecord<String, String>> records) {
logger.info("批量消费:共{}条消息", records.size());
for (ConsumerRecord<String, String> record : records) {
try {
// 批量处理业务
logger.info("批量消息:{}", record.value());
} catch (Exception e) {
logger.error("批量处理消息失败:{}", e.getMessage());
}
}
}
/**
* 手动提交偏移量(生产环境推荐)
*/
@KafkaListener(topics = "manual-topic", groupId = "manual-group")
public void consumeWithManualCommit(ConsumerRecord<String, String> record, Acknowledgment acknowledgment) {
try {
// 业务处理
logger.info("手动提交消费:{}", record.value());
// 手动提交偏移量(必须!否则会重复消费)
acknowledgment.acknowledge();
} catch (Exception e) {
logger.error("处理消息失败:{}", e);
// 消费失败:不提交偏移量(会重试),或发送到死信队列
// sendToDlq("dlq-topic", record.value());
}
}
}Spring-Kafka面试考点
- @KafkaListener的核心参数?
- topics:订阅的主题 -
- groupId:消费者组
- containerFactory:自定义容器工厂(批量/单条、提交方式)
- 如何处理重复消费?
- 消费端幂等(数据库唯一键、Redis防重)
- 动提交偏移量(业务处理完再提交)
- Spring-Kafka的重试机制?
java
// 配置重试
@Bean
public RetryTemplate retryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
// 重试3次,间隔1秒
FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(1000);
retryTemplate.setBackOffPolicy(backOffPolicy);
retryTemplate.setRetryPolicy(new SimpleRetryPolicy(3));
return retryTemplate;
}
// 消费端使用重试
@KafkaListener(topics = "iuit-topic")
public void consumeWithRetry(String message) {
retryTemplate.execute(context -> {
// 业务处理
return null;
});
}- 死信队列如何实现? - 消费失败→发送到dlq-topic→单独的消费者处理死信消息
9 kafka消息发送和消费的过程
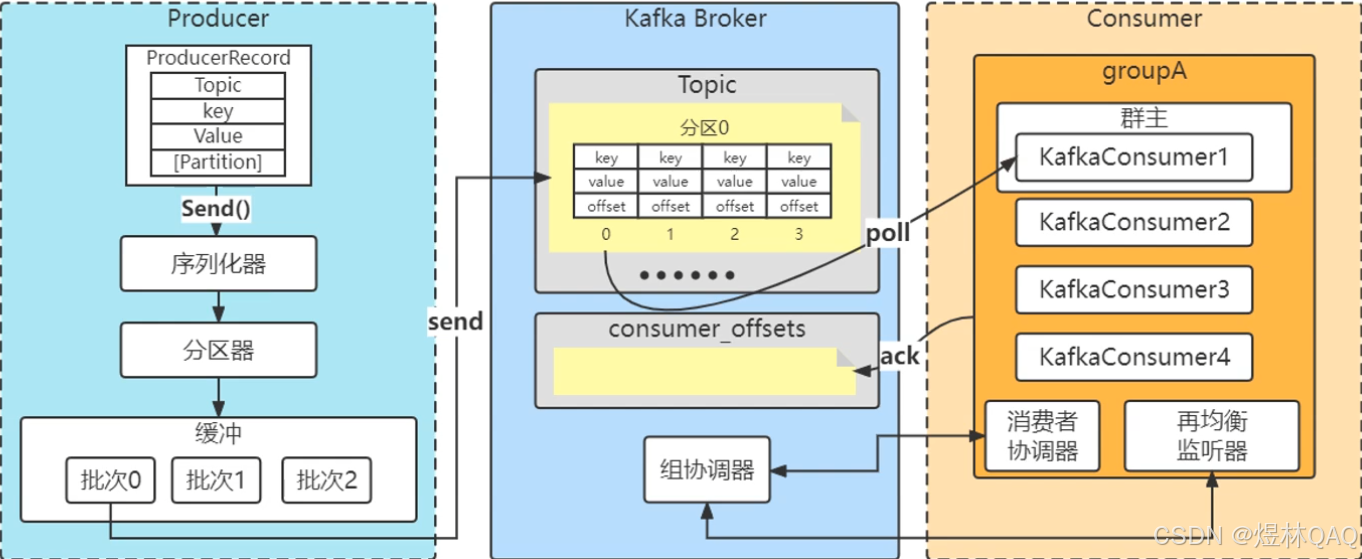
补充:图片讲解 + 完整流程(面试必背)
图片核心逻辑
- 生产者发送消息→Leader副本
- Follower副本同步Leader数据
- Leader返回成功给生产者
- 消费者从Leader拉取消息
- 消费者提交偏移量到__consumer_offsets主题
完整流程(面试口述版)
tex
生产者侧:
1. 生产者构建消息,经过序列化、分区器→确定目标分区
2. 消息写入生产者缓冲区(按分区分批次)
3. 批次满足条件(batch.size/linger.ms)→发送到Broker的Leader副本
4. Leader写入本地磁盘,Follower拉取Leader数据同步
5. 满足ACKS条件(比如all)→Leader返回成功给生产者
消费者侧:
1. 消费者加入组→Coordinator(Broker)触发重平衡→分配分区
2. 消费者向Leader拉取消息(按偏移量)
3. 消费者处理消息→手动/自动提交偏移量
4. 偏移量提交到__consumer_offsets主题(内部主题)面试考点:消息丢失/重复的全链路解决方案
| 环节 | 丢失原因 | 解决方案 |
|---|---|---|
| 生产者 | 未刷缓冲区、ACKS 配置不当 | ACKS=all、重试、close ()、min.insync.replicas≥2 |
| Broker | Leader 宕机、副本同步失败 | 副本数≥3、关闭 unclean.leader.election |
| 消费者 | 提前提交偏移量 | 手动提交、幂等消费 |
10. kafka集群原理
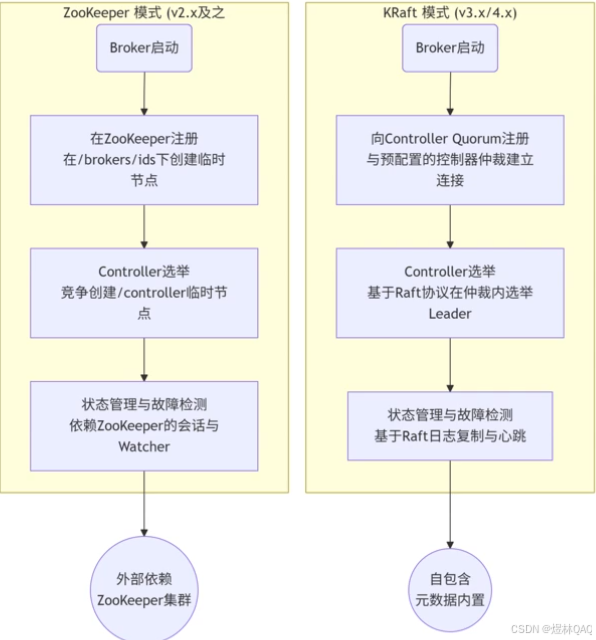
补充:图片讲解 + 核心机制(面试必问)
图片核心逻辑
- Controller选举:集群启动时,选一个Broker作为Controller(管理元数据)
- 副本同步:Follower从Leader拉取数据,维护ISR列表
- 分区分布:分区副本分布在不同Broker(高可用)
核心机制详解
-
Controller选举
- 触发条件:集群启动、Controller宕机
- 过程:Broker向Zookeeper(或KRaft)注册临时节点,第一个注册的成为Controller
- 作用:管理分区Leader选举、Broker上下线、元数据同步
-
ISR机制
- ISR(In-Sync Replica):和Leader数据同步的副本(延迟≤replica.lag.time.max.ms,默认10秒)
- 非ISR副本:同步延迟超过阈值,被踢出ISR
- 面试考点:ISR缩小到1会怎样?→设置min.insync.replicas≥2,生产者会报错(无法满足ACKS=all)
-
副本分布策略


- 图片逻辑:副本尽量分布在不同Broker、不同机架(容灾)
- 例子:3个Broker、副本数3→分区0的副本分布在Broker0(Leader)、Broker1、Broker2
面试高频问题
-
集群扩容步骤?
-
新增Broker节点(配置和原有节点一致)
-
启动Broker→自动加入集群
-
重新分配分区(kafka-reassign-partitions.sh)→把部分分区迁移到新Broker
-
-
Broker宕机后的恢复流程?
- Controller检测到Broker宕机→触发Leader重选举(从ISR中选)
- 消费者重平衡→重新分配分区
- 宕机Broker恢复后→作为Follower同步数据,加入ISR
11. Kafka的零拷贝
四次交换
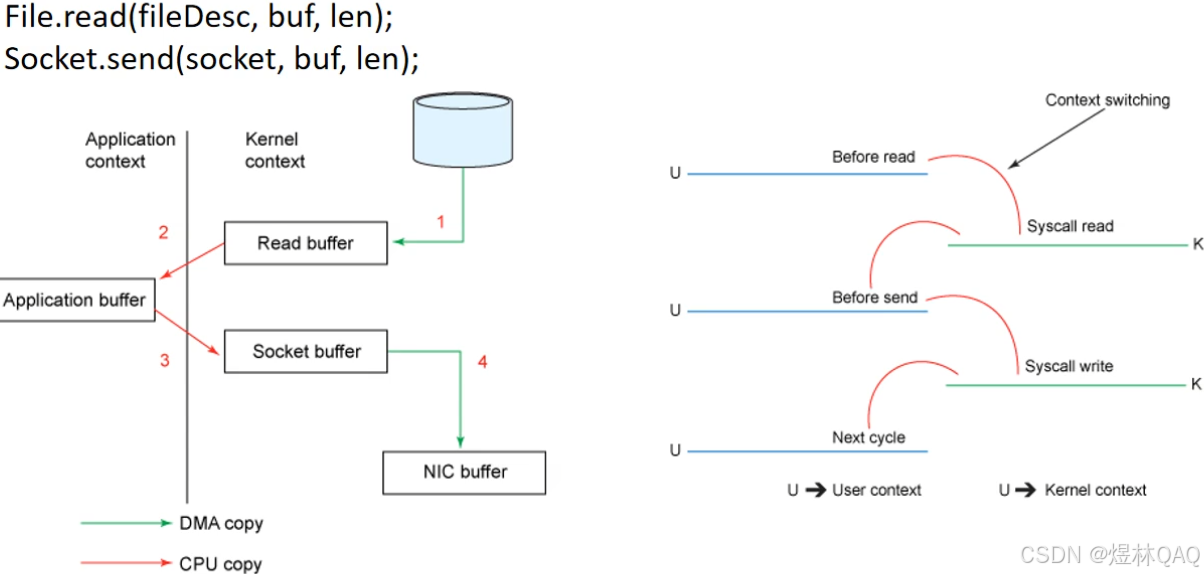
kafka的transferTo
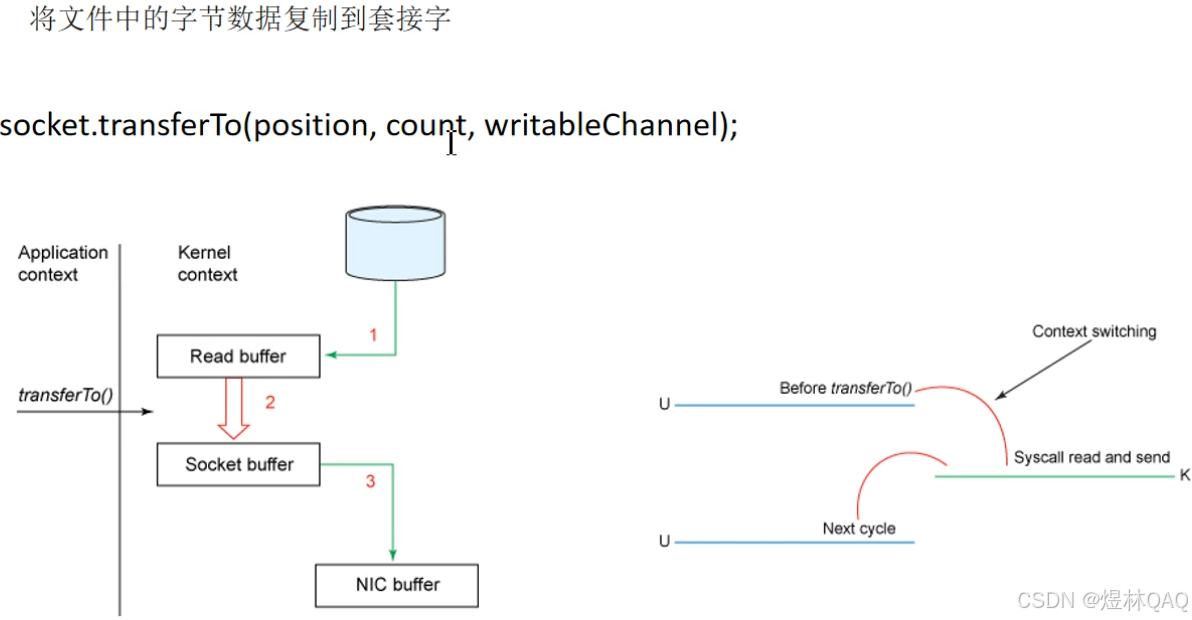
linux系统的改进
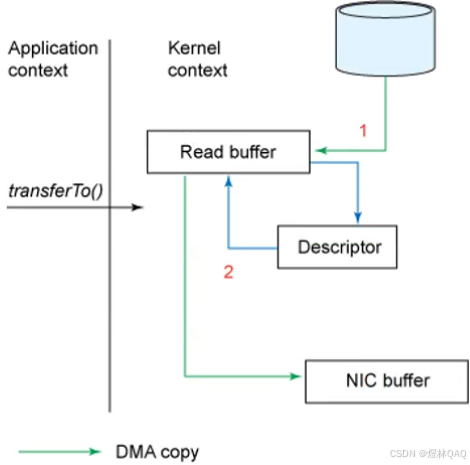
kafka的零拷贝运用
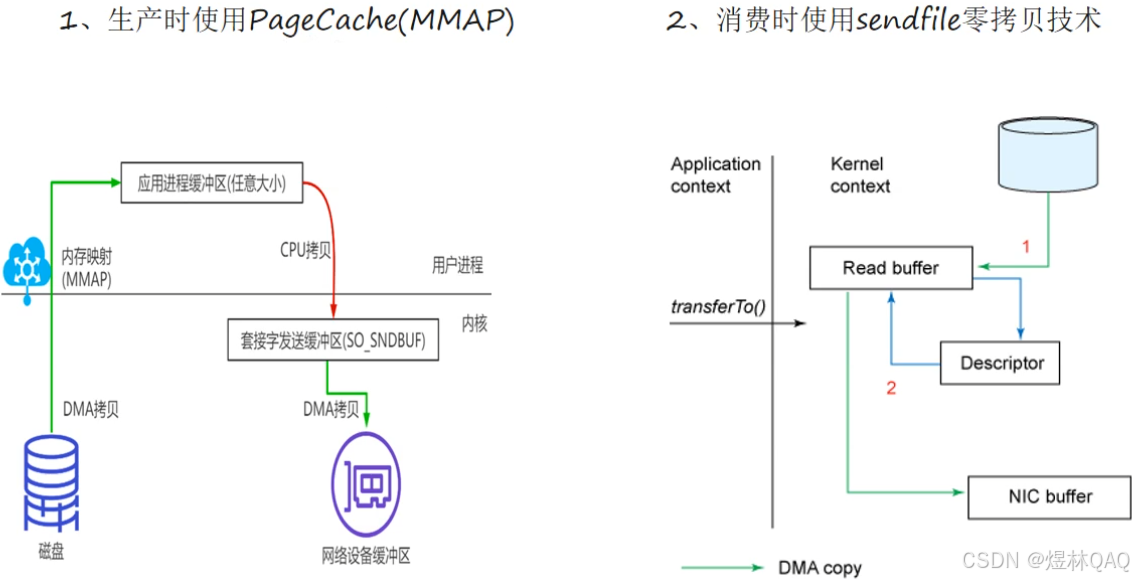
补充:通俗讲解 + 面试考点
零拷贝核心逻辑(大白话)
- 传统文件传输(四次拷贝):
- 磁盘→内核缓冲区(DMA拷贝)
- 内核缓冲区→用户缓冲区(CPU拷贝)
- 用户缓冲区→Socket缓冲区(CPU拷贝)
- Socket缓冲区→网卡(DMA拷贝)
- 问题:2次CPU拷贝,消耗资源,速度慢
- Kafka零拷贝(transferTo):
- 磁盘→内核缓冲区(DMA拷贝)
- 内核缓冲区→网卡(DMA拷贝,无CPU参与)
- 优势:减少2次CPU拷贝,提高吞吐量(尤其大文件/高吞吐场景)
图片讲解
- 图1(四次交换):展示传统方式的4次拷贝,2次CPU参与
- 图2(transferTo):展示零拷贝只有2次DMA拷贝,无CPU参与
- 图3(Linux改进):Linux的sendfile系统调用实现零拷贝
- 图4(Kafka运用):Kafka使用transferTo/sendfile,直接把磁盘文件发送到网卡,无需用户态拷贝
面试考点
- Kafka为什么适合日志收集?
- 零拷贝→高吞吐,能快速处理大量日志文件
- 持久化→日志不丢失
- 分区→并行消费
- 零拷贝的适用场景?
- 大文件传输(日志、视频)
- 高吞吐场景(百万级消息/秒)
12. 流式处理
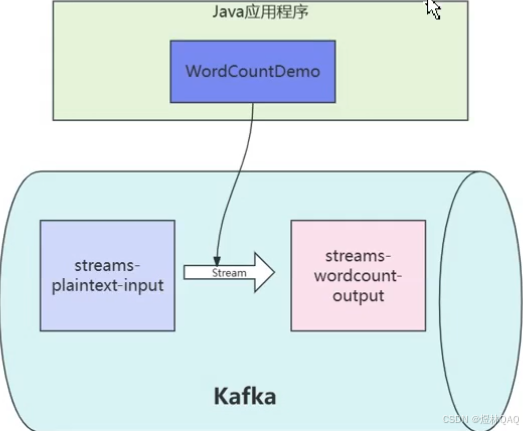
补充:简单代码示例 + 应用场景
核心概念(通俗)
- Kafka Streams:基于Kafka的流式处理库(轻量级,无需单独部署)
- 输入:Kafka主题
- 处理:过滤、聚合、关联等
- 输出:Kafka主题
单词计数示例(最简版)
java
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;
import java.util.Properties;
public class WordCountDemo {
public static void main(String[] args) {
// 配置
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-app"); // 应用ID(唯一)
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 构建拓扑
StreamsBuilder builder = new StreamsBuilder();
// 输入主题:streams-plaintext-input
KStream<String, String> input = builder.stream("streams-plaintext-input");
// 处理:拆分单词→计数
KTable<String, Long> wordCounts = input
.flatMapValues(value -> List.of(value.toLowerCase().split(" "))) // 拆分单词
.groupBy((key, word) -> word) // 按单词分组
.count(); // 计数
// 输出到主题:streams-wordcount-output
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
// 启动应用
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// 关闭钩子(优雅退出)
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
}测试步骤
- 创建输入/输出主题:
bash
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic streams-plaintext-input --partitions 1 --replication-factor 1
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic streams-wordcount-output --partitions 1 --replication-factor 1- 启动WordCountDemo
- 启动生产者发消息:
bash
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
# 输入:hello kafka hello world- 启动消费者看结果:
bash
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic streams-wordcount-output --from-beginning --property print.key=true --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
# 输出:
# hello 2
# kafka 1
# world 1应用场景(补充)
- 实时统计(PV/UV、订单量)
- 数据清洗(过滤、格式转换)
- 实时推荐(用户行为实时分析)
面试考点
- Kafka Streams vs Spark Streaming/Flink?
- Kafka Streams:轻量级、嵌入应用、低延迟、适合简单处理
- Spark/Flink:重量级、独立集群、适合复杂计算(窗口、状态管理)
面试高频问题汇总(补充)
基础概念
- Kafka的核心组件?(Producer/Consumer/Topic/Partition/Broker/Controller/ISR)
- 分区的作用?(并行、扩容、顺序)
- 消费者组的核心规则?(分区独占、偏移量独立)
可靠性
- 如何保证消息不丢失?(生产者ACKS=all、副本、手动提交)
- 如何保证消息不重复?(幂等、手动提交)
- 如何保证消息有序?(分区、单连接) ## 性能调优 1. 生产者调优参数?(batch.size、linger.ms、acks