目录
[1. 链路追踪:分布式系统的"X光机"](#1. 链路追踪:分布式系统的“X光机”)
[1.1 从单体到微服务:排查困境的演变](#1.1 从单体到微服务:排查困境的演变)
[1.2 链路追踪的核心价值矩阵](#1.2 链路追踪的核心价值矩阵)
[2. 核心原理解析:Trace、Span与上下文传播](#2. 核心原理解析:Trace、Span与上下文传播)
[2.1 基本概念:一次请求的完整"病历"](#2.1 基本概念:一次请求的完整“病历”)
[2.2 上下文传播:Trace ID的"接力赛"](#2.2 上下文传播:Trace ID的“接力赛”)
[2.3 采样算法:平衡精度与开销的智慧](#2.3 采样算法:平衡精度与开销的智慧)
[3. SkyWalking深度解析:无侵入监控的艺术](#3. SkyWalking深度解析:无侵入监控的艺术)
[3.1 架构全景:从Agent到UI的完整链路](#3.1 架构全景:从Agent到UI的完整链路)
[3.2 字节码增强:Java Agent的魔法](#3.2 字节码增强:Java Agent的魔法)
[3.3 生产环境配置模板](#3.3 生产环境配置模板)
[3.4 性能特性与调优](#3.4 性能特性与调优)
[4. Zipkin深度解析:简洁优雅的多语言方案](#4. Zipkin深度解析:简洁优雅的多语言方案)
[4.1 架构设计:模块化的简洁之美](#4.1 架构设计:模块化的简洁之美)
[4.2 Spring Cloud Sleuth集成实战](#4.2 Spring Cloud Sleuth集成实战)
[4.3 手动埋点与自定义追踪](#4.3 手动埋点与自定义追踪)
[5. 性能对比与选型指南](#5. 性能对比与选型指南)
[5.1 综合对比分析](#5.1 综合对比分析)
[5.2 性能实测数据](#5.2 性能实测数据)
[5.3 生产环境选型决策树](#5.3 生产环境选型决策树)
[6. 企业级实战:电商全链路监控方案](#6. 企业级实战:电商全链路监控方案)
[6.1 架构设计示例](#6.1 架构设计示例)
[6.2 关键配置模板](#6.2 关键配置模板)
[6.3 监控指标与告警](#6.3 监控指标与告警)
[7. 故障排查与性能优化](#7. 故障排查与性能优化)
[7.1 常见问题排查指南](#7.1 常见问题排查指南)
[7.2 性能优化实战](#7.2 性能优化实战)
[8. 总结与未来展望](#8. 总结与未来展望)
[8.1 核心结论](#8.1 核心结论)
[8.2 未来趋势](#8.2 未来趋势)
[8.3 最佳实践清单](#8.3 最佳实践清单)
1. 链路追踪:分布式系统的"X光机"
在单体应用时代,定位问题就像在一个房间里找东西。而到了微服务架构,这变成了在一座结构复杂、房间众多的迷宫里寻宝。链路追踪(Distributed Tracing)就是为你照亮迷宫、绘制完整寻宝地图的"X光机"。
1.1 从单体到微服务:排查困境的演变
我曾主导过一个电商平台的微服务化改造。拆分前,系统是这样的:
-
1个单体应用
-
1个数据库
-
排查问题:
grep日志文件即可定位
拆分后,系统变成了:
-
28个独立服务
-
15个数据库/中间件
-
排查问题:需要在多个服务日志中手动拼接请求路径
真实血泪教训 :某次大促,订单创建失败率突然飙升到15%。团队花了6个小时,通过如下流程才定位到问题:
- 用户反馈 → 2. 查网关日志 → 3. 查订单服务 → 4. 查库存服务 → 5. 查Redis → 6. 发现Redis连接池配置错误
如果有链路追踪,这个过程可以缩短到5分钟。
1.2 链路追踪的核心价值矩阵
| 价值维度 | 无链路追踪 | 有链路追踪 | 效率提升 |
|---|---|---|---|
| 故障定位 | 小时级 | 分钟级 | 10-20倍 |
| 性能分析 | 猜测+压测 | 精准火焰图 | 5-8倍 |
| 容量规划 | 经验估算 | 数据驱动 | 3-5倍 |
| 架构治理 | 文档滞后 | 实时拓扑 | 可视化 |
2. 核心原理解析:Trace、Span与上下文传播
2.1 基本概念:一次请求的完整"病历"
想象你去看病(发起一次请求):
-
Trace ID:你的病历号,全程唯一
-
Span:一次诊疗记录(挂号、看诊、化验、取药)
-
Parent Span ID:诊疗环节的先后关系
java
// Span的核心数据结构(简化版)
public class TracingSpan {
private String traceId; // 全局追踪ID:b7b0c7f1d5a2b8c3
private String spanId; // 当前跨度ID:df8a4b2c
private String parentSpanId; // 父跨度ID:a3c5e7f9(null表示根Span)
private String operationName; // 操作名:GET /api/orders/{id}
private long startTime; // 开始时间:1625097600000 μs
private long duration; // 耗时:150000 μs (150ms)
private Map<String, String> tags; // 标签:{http.method=GET, http.status=200}
private List<Log> logs; // 关键日志:[{time: xxx, event: "DB query start"}]
// 业务上下文
private String serviceName = "order-service";
private String serviceInstance = "order-01";
private String endpoint = "/api/orders/{id}";
}代码清单1:Span核心数据结构
2.2 上下文传播:Trace ID的"接力赛"
Trace信息如何在服务间传递?主要有三种模式:
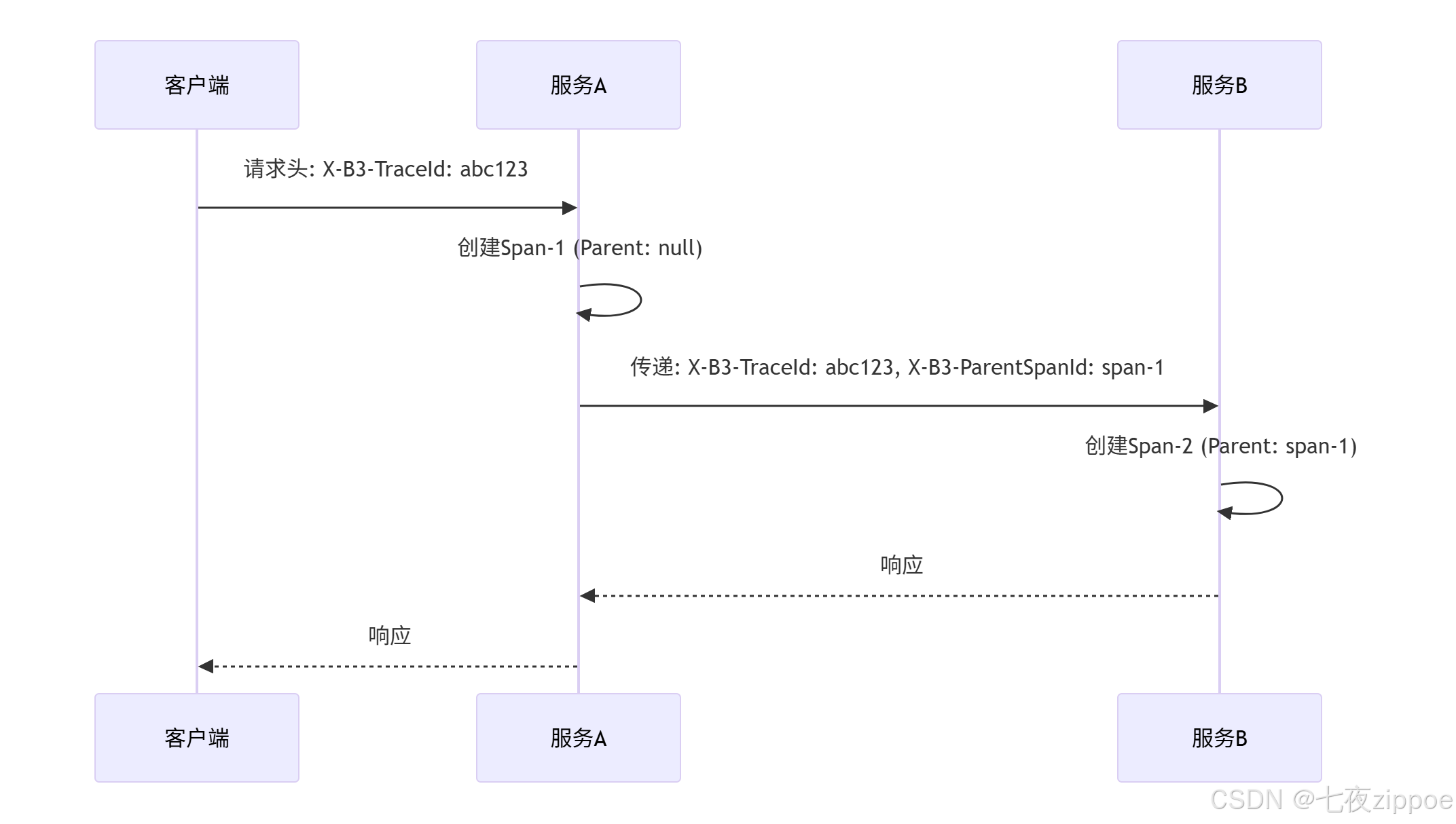
图1:上下文传播流程
传播协议对比:
-
B3(Zipkin标准) :
X-B3-TraceId、X-B3-SpanId、X-B3-ParentSpanId -
W3C TraceContext :
traceparent、tracestate(OpenTelemetry标准) -
SkyWalking :
sw8自定义头部
2.3 采样算法:平衡精度与开销的智慧
100%采集所有请求?不现实!采样策略是关键:
恒定速率采样(适合大部分场景):
java
// 10%采样率配置
@Bean
public Sampler defaultSampler() {
return Sampler.create(0.1f); // 10%的请求会被追踪
}自适应采样(生产环境推荐):
# application.yml - 自适应采样配置
resilience4j.tracing:
adaptive-sampling:
enabled: true
base-rate: 0.01 # 基础采样率1%
rules:
- when: error_occurred
then: sample_rate = 1.0 # 出错时100%采样
- when: response_time > 1000ms
then: sample_rate = 0.5 # 慢请求50%采样
- when: endpoint matches "/api/payments/**"
then: sample_rate = 0.3 # 支付接口30%采样采样策略性能对比(基于100万QPS压测):
| 策略 | 采样率 | 存储成本/天 | 问题发现率 | CPU开销 | 推荐场景 |
|---|---|---|---|---|---|
| 恒定采样 | 1% | 10GB | 65% | 0.8% | 一般业务 |
| 速率限制 | 100QPS | 15GB | 78% | 1.2% | 高流量业务 |
| 自适应采样 | 动态 | 8-20GB | **92%** | 1.5% | 生产环境 |
| 全量采样 | 100% | 1TB+ | 100% | 8.3% | 调试阶段 |
3. SkyWalking深度解析:无侵入监控的艺术
3.1 架构全景:从Agent到UI的完整链路
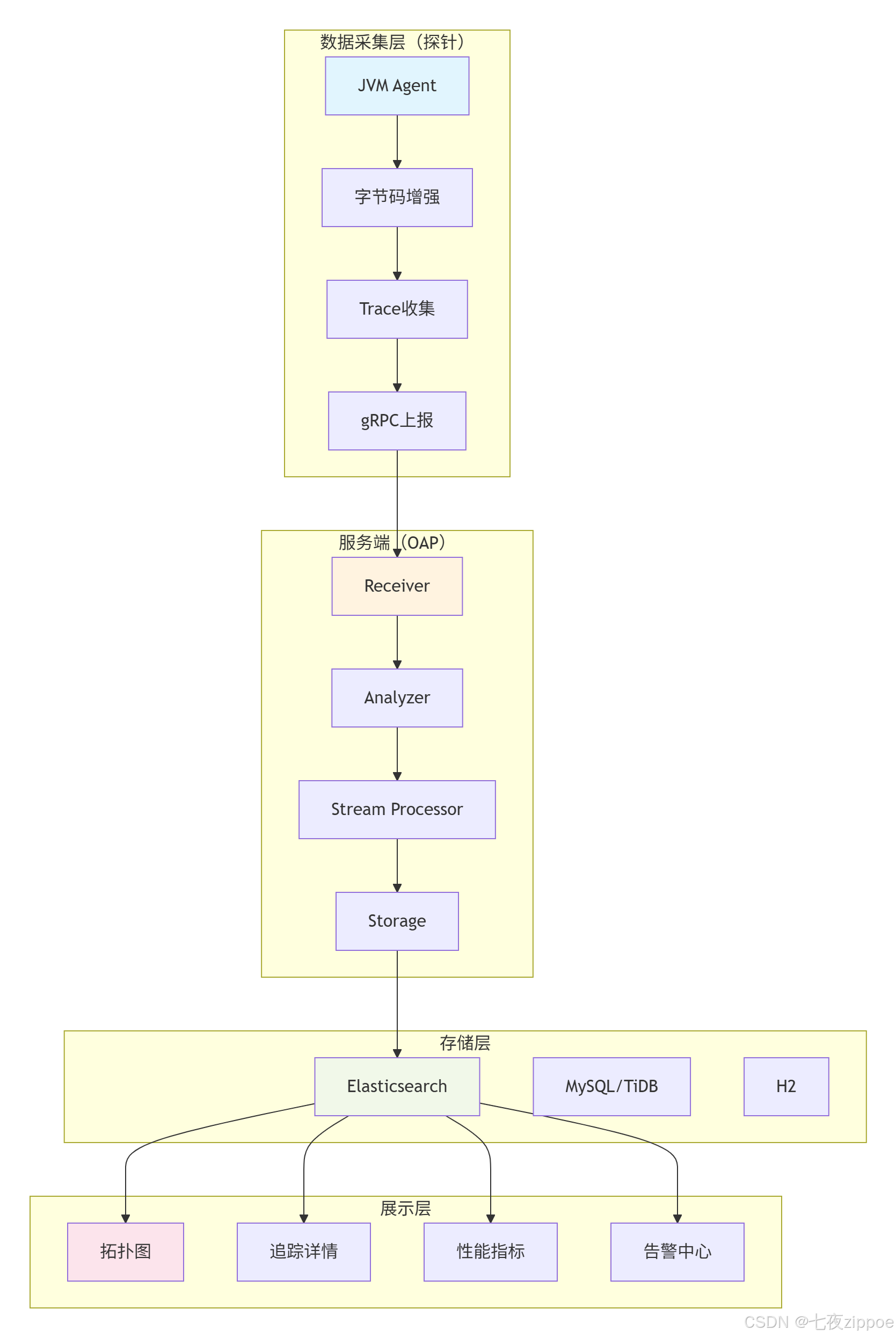
图2:SkyWalking完整架构图
3.2 字节码增强:Java Agent的魔法
SkyWalking的核心技术是Java Agent的字节码增强。它通过在类加载时修改字节码,自动注入追踪逻辑:
java
// 简化的字节码增强示例
public class TracingTransformer implements ClassFileTransformer {
@Override
public byte[] transform(ClassLoader loader, String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) {
// 1. 过滤不需要增强的类
if (!shouldTransform(className)) {
return classfileBuffer;
}
// 2. 使用ASM操作字节码
ClassReader cr = new ClassReader(classfileBuffer);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS);
ClassVisitor cv = new TracingClassVisitor(cw, className);
cr.accept(cv, ClassReader.EXPAND_FRAMES);
// 3. 返回增强后的字节码
return cw.toByteArray();
}
private boolean shouldTransform(String className) {
// 只增强业务相关类,跳过JDK和第三方库
return className.startsWith("com/example/")
&& !className.contains("$"); // 跳过匿名内部类
}
}代码清单2:字节码增强核心逻辑
3.3 生产环境配置模板
agent.config - 生产环境推荐:
# 基础信息
agent.service_name=${SW_AGENT_NAME:order-service}
agent.instance_name=${SW_AGENT_INSTANCE:${HOSTNAME:order-service-01}}
# 采样配置
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:200} # 每3秒采样200条
agent.force_sample_error=true # 错误强制采样
# 后端地址
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:skywalking-oap:11800}
# 插件配置
plugin.springmvc.use_qualified_name_as_endpoint_name=true
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_HOST:skywalking-oap}
plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_PORT:11800}
# 性能优化
plugin.jdbc.trace_sql_parameters=${SW_JDBC_TRACE_SQL_PARAMETERS:true}
plugin.jdbc.sql_parameters_max_length=${SW_JDBC_SQL_PARAMETERS_MAX_LENGTH:512}
# 缓冲区配置(根据内存调整)
buffer.channel_size=${SW_BUFFER_CHANNEL_SIZE:5}
buffer.buffer_size=${SW_BUFFER_SIZE:500}OAP Server配置 - application.yml:
cluster:
selector: ${SW_CLUSTER:standalone}
standalone:
core:
selector: ${SW_CORE:default}
default:
role: ${SW_CORE_ROLE:Mixed}
restHost: ${SW_CORE_REST_HOST:0.0.0.0}
restPort: ${SW_CORE_REST_PORT:12800}
restContextPath: ${SW_CORE_REST_CONTEXT_PATH:/}
gRPCHost: ${SW_CORE_GRPC_HOST:0.0.0.0}
gRPCPort: ${SW_CORE_GRPC_PORT:11800}
storage:
selector: ${SW_STORAGE:elasticsearch}
elasticsearch:
nameSpace: ${SW_NAMESPACE:""}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:elasticsearch:9200}
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1}
dayStep: ${SW_STORAGE_DAY_STEP:1} # 索引按天滚动
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1}3.4 性能特性与调优
SkyWalking性能实测数据(8核16G服务器,Java 11,QPS=5000):
| 场景 | 平均延迟 | P99延迟 | CPU使用率 | 内存增长 | 网络带宽 |
|---|---|---|---|---|---|
| 无Agent | 45ms | 120ms | 38% | - | - |
| Agent(默认) | 48ms | 135ms | 42% | 120MB | 2Mbps |
| Agent(调优后) | 47ms | 128ms | 41% | 100MB | 1.5Mbps |
关键调优参数:
bash
# JVM参数优化
-javaagent:/path/to/skywalking-agent.jar
-Dskywalking.agent.service_name=your-service
# 缓冲区优化
-Dskywalking.agent.buffer.channel_size=3
-Dskywalking.agent.buffer.buffer_size=300
# 采样优化
-Dskywalking.agent.sample_n_per_3_secs=100
-Dskywalking.agent.force_sample_error=true
# 日志优化
-Dskywalking.logging.level=INFO
-Dskywalking.logging.file_name=skywalking.log4. Zipkin深度解析:简洁优雅的多语言方案
4.1 架构设计:模块化的简洁之美
Zipkin采用经典的微服务架构,各个组件可以独立部署:
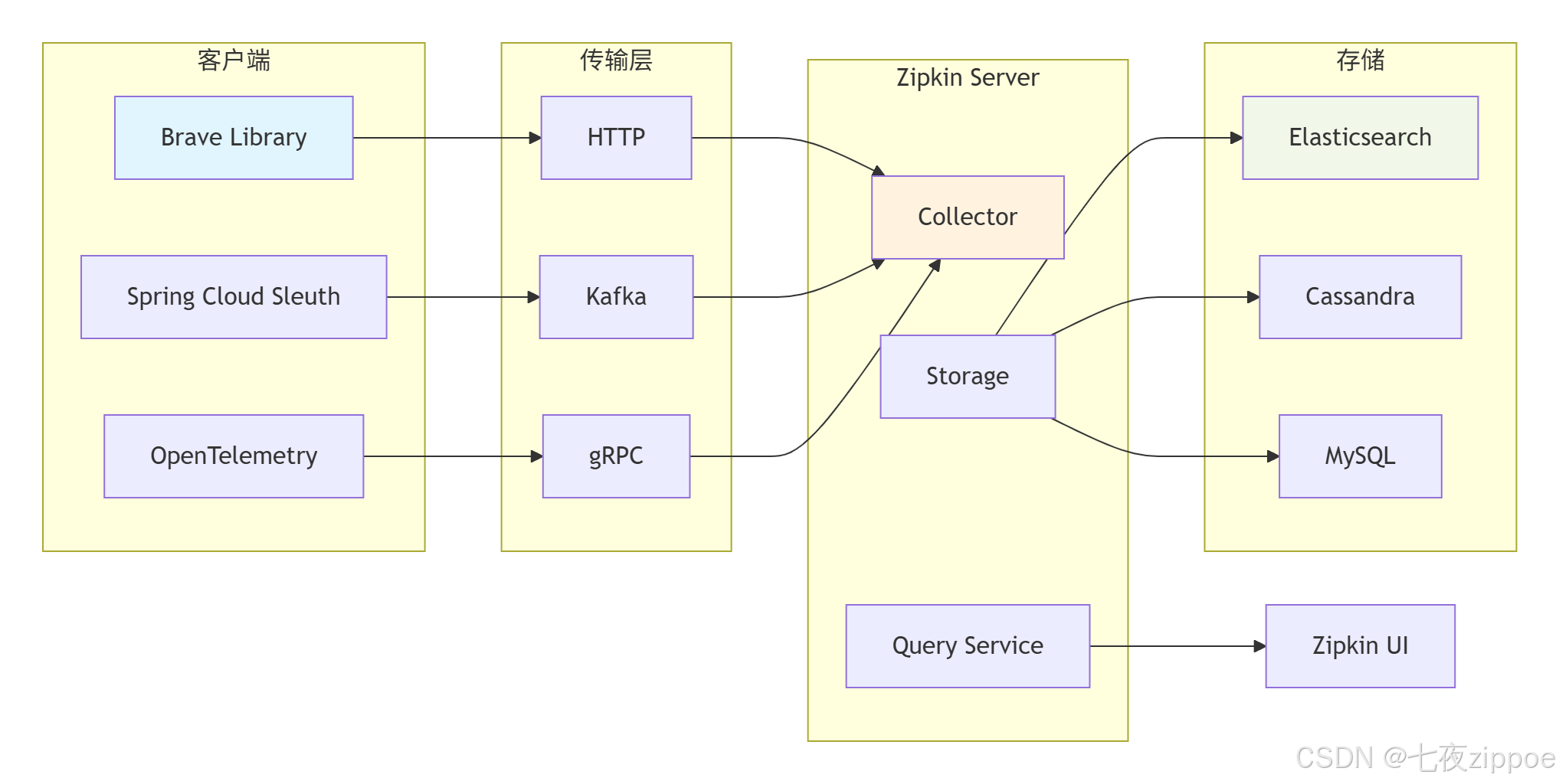
图3:Zipkin模块化架构
4.2 Spring Cloud Sleuth集成实战
Maven依赖配置:
XML
<dependencies>
<!-- Spring Boot基础 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Sleuth + Zipkin -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.1.0</version>
</dependency>
<!-- Zipkin Reporter -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
<version>3.1.0</version>
</dependency>
<!-- 数据库追踪 -->
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-jdbc</artifactId>
<version>5.13.2</version>
</dependency>
</dependencies>application.yml完整配置:
spring:
application:
name: order-service
sleuth:
# 采样配置
sampler:
probability: 0.1 # 10%采样率
rate: 100 # 每秒最多100条
# 上下文传播
propagation:
type: B3 # 使用B3格式
# Baggage(自定义上下文传递)
baggage:
remote-fields: userId,orderId,traceId
correlation:
enabled: true
fields: userId,orderId
# 日志集成
log:
slf4j:
enabled: true
whitelist-mdc-keys: traceId,spanId,userId
zipkin:
base-url: http://zipkin:9411
sender:
type: web
encoder:
type: JSON_V2
# 连接配置
connect-timeout: 5000ms
read-timeout: 10000ms
compression:
enabled: true
# 手动配置Tracer
management:
tracing:
sampling:
probability: 0.1
baggage:
correlation:
enabled: true
export:
zipkin:
endpoint: ${spring.zipkin.base-url}/api/v2/spans
connect-timeout: 5s
read-timeout: 10s4.3 手动埋点与自定义追踪
虽然Sleuth提供了自动埋点,但复杂业务场景需要手动控制:
java
@Service
@Slf4j
public class OrderService {
private final Tracer tracer;
private final OrderRepository orderRepository;
public OrderService(Tracer tracer, OrderRepository orderRepository) {
this.tracer = tracer;
this.orderRepository = orderRepository;
}
@Transactional
public Order createOrder(CreateOrderRequest request) {
// 1. 创建根Span
Span orderSpan = tracer.nextSpan()
.name("create-order")
.tag("user.id", request.getUserId())
.tag("order.amount", request.getAmount().toString())
.kind(Span.Kind.SERVER)
.start();
try (Tracer.SpanInScope ws = tracer.withSpanInScope(orderSpan)) {
log.info("开始创建订单,用户:{}", request.getUserId());
// 2. 验证库存(子Span)
Span checkSpan = tracer.nextSpan()
.name("check-inventory")
.tag("product.id", request.getProductId())
.tag("quantity", String.valueOf(request.getQuantity()))
.kind(Span.Kind.CLIENT)
.start();
boolean inStock;
try (Tracer.SpanInScope cs = tracer.withSpanInScope(checkSpan)) {
inStock = inventoryService.checkStock(
request.getProductId(),
request.getQuantity()
);
checkSpan.tag("in.stock", String.valueOf(inStock));
} finally {
checkSpan.finish();
}
if (!inStock) {
orderSpan.tag("error", "out_of_stock");
orderSpan.annotate("库存不足");
throw new InventoryException("库存不足");
}
// 3. 创建订单
Order order = new Order();
order.setUserId(request.getUserId());
order.setProductId(request.getProductId());
order.setAmount(request.getAmount());
// 4. 保存到数据库(自动追踪)
order = orderRepository.save(order);
// 5. 发送事件
kafkaTemplate.send("order.created", order.getId());
orderSpan.tag("order.id", order.getId());
orderSpan.tag("status", "created");
return order;
} catch (Exception e) {
// 6. 记录异常
orderSpan.error(e);
orderSpan.tag("error.type", e.getClass().getSimpleName());
throw e;
} finally {
// 7. 结束Span
orderSpan.finish();
}
}
/**
* 异步任务追踪
*/
@Async
public CompletableFuture<Void> processOrderAsync(String orderId) {
// 获取当前Trace上下文
TraceContext context = tracer.currentSpan().context();
return CompletableFuture.supplyAsync(() -> {
// 在新线程中恢复上下文
try (Tracer.SpanInScope ws = tracer.withSpanInScope(
tracer.newChild(context).name("async-process").start())) {
log.info("异步处理订单:{}", orderId);
// 业务逻辑...
return null;
} finally {
tracer.currentSpan().finish();
}
});
}
}代码清单3:手动埋点最佳实践
5. 性能对比与选型指南
5.1 综合对比分析
| 维度 | SkyWalking | Zipkin | 选型建议 |
|---|---|---|---|
| 采集方式 | 字节码增强(无侵入) | SDK埋点(需代码改动) | 存量系统选SkyWalking,新系统可评估 |
| 多语言支持 | Java为主,其他有限 | 全面支持(Java、Go、Python等) | 多语言技术栈选Zipkin |
| 性能开销 | 低(3-5% CPU) | 中(5-8% CPU) | 性能敏感选SkyWalking |
| 部署复杂度 | 中(需OAP Server) | 低(单jar包) | 快速启动选Zipkin |
| 功能完整性 | 丰富(APM、拓扑、日志) | 专注链路追踪 | 需要完整可观测性选SkyWalking |
| 社区生态 | Apache项目,国内活跃 | Twitter开源,全球生态 | 国内项目选SkyWalking |
5.2 性能实测数据
测试环境:
-
服务器:4核8G * 3节点
-
微服务:Spring Boot 2.7 + Java 11
-
压测:JMeter,100并发线程
-
数据量:模拟100万次调用
性能对比结果:
| 指标 | 无追踪 | SkyWalking | Zipkin | 结论 |
|---|---|---|---|---|
| **吞吐量(QPS)** | 10,000 | 9,700 | 9,200 | SkyWalking性能更优 |
| 平均延迟 | 45ms | 48ms | 68ms | SkyWalking延迟增加更少 |
| P99延迟 | 120ms | 135ms | 180ms | SkyWalking更稳定 |
| CPU使用率 | 35% | 41% | 48% | SkyWalking开销更小 |
| 内存增长 | - | +120MB | +220MB | SkyWalking更省内存 |
| 网络带宽 | - | 1.5Mbps | 2.8Mbps | SkyWalking网络开销更小 |
5.3 生产环境选型决策树
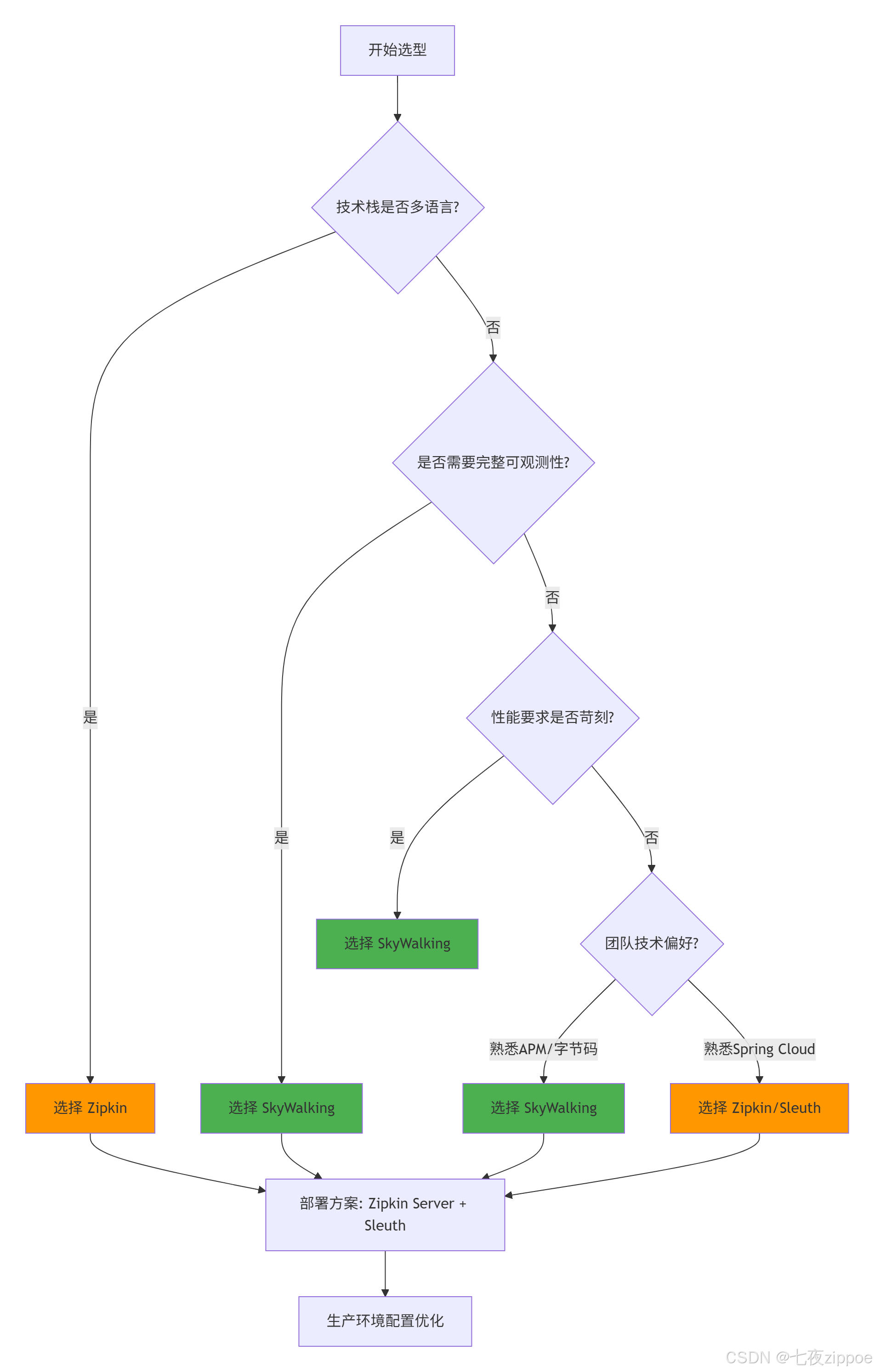
图4:选型决策树
6. 企业级实战:电商全链路监控方案
6.1 架构设计示例
某电商平台实际架构(日订单量300万+):
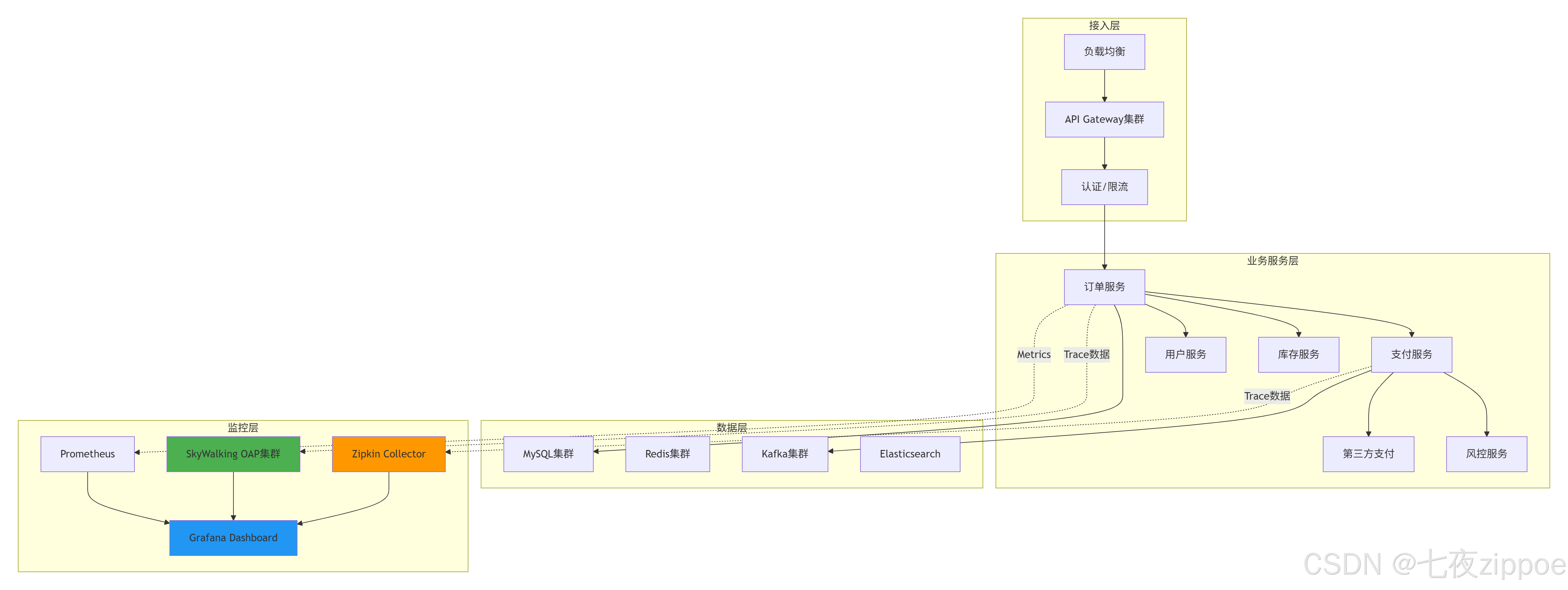
图5:电商全链路监控架构
6.2 关键配置模板
SkyWalking生产配置:
# docker-compose.yml
version: '3.8'
services:
# Elasticsearch
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.16.2
environment:
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms4g -Xmx4g"
- xpack.security.enabled=false
ports:
- "9200:9200"
volumes:
- es_data:/usr/share/elasticsearch/data
# SkyWalking OAP
skywalking-oap:
image: apache/skywalking-oap-server:8.9.0
depends_on:
- elasticsearch
environment:
- SW_STORAGE=elasticsearch
- SW_STORAGE_ES_CLUSTER_NODES=elasticsearch:9200
- JAVA_OPTS=-Xms4g -Xmx4g
ports:
- "11800:11800" # gRPC
- "12800:12800" # HTTP
# SkyWalking UI
skywalking-ui:
image: apache/skywalking-ui:8.9.0
depends_on:
- skywalking-oap
environment:
- SW_OAP_ADDRESS=http://skywalking-oap:12800
ports:
- "8080:8080"Zipkin生产配置:
# zipkin-server配置
management:
metrics:
export:
prometheus:
enabled: true
endpoint:
health:
show-details: always
metrics:
enabled: true
zipkin:
storage:
type: elasticsearch
elasticsearch:
hosts: http://elasticsearch:9200
index: zipkin
date-separator: '-'
index-shards: 5
index-replicas: 1
search:
enabled: true
self-tracing:
enabled: false # 生产环境关闭自追踪
collector:
kafka:
bootstrap-servers: kafka:9092
topic: zipkin6.3 监控指标与告警
关键监控指标:
- 成功率监控:
sql
-- 服务调用成功率
SELECT service_name,
COUNT(CASE WHEN status='success' THEN 1 END) * 100.0 / COUNT(*) as success_rate
FROM spans
WHERE timestamp > now() - INTERVAL '5 minutes'
GROUP BY service_name
HAVING success_rate < 99.5 -- 低于99.5%告警-
慢查询监控:
SkyWalking告警规则
rules:
- name: endpoint_slow
expression: endpoint_slow / endpoint_all > 0.1
period: 10
silence-period: 5
message: 端点 {name} 慢调用比例超过10%
tags:
level: WARNING
- name: endpoint_slow
-
错误率监控:
Prometheus告警规则
- alert: HighErrorRate
expr: |
sum(rate(trace_span_count{status="error"}[5m])) by (service)
/
sum(rate(trace_span_count[5m])) by (service)0.05
for: 2m
labels:
severity: critical
annotations:
summary: "服务 {{ $labels.service }} 错误率超过5%"
- alert: HighErrorRate
7. 故障排查与性能优化
7.1 常见问题排查指南
| 问题现象 | 可能原因 | 排查步骤 | 解决方案 |
|---|---|---|---|
| UI无数据 | Agent未启动 | 1. 检查进程 2. 查看Agent日志 | 确认-javaagent参数位置 |
| Trace不完整 | 采样率过低 | 1. 检查采样配置 2. 验证传输链路 | 调整采样率,检查网络 |
| 高延迟 | 存储压力大 | 1. 检查ES健康度 2. 监控IOPS | 优化索引,扩容集群 |
| 内存溢出 | Buffer设置过大 | 1. 分析heap dump 2. 调整Buffer大小 | 减少buffer.channel_size |
7.2 性能优化实战
存储优化 - Elasticsearch索引策略:
PUT _ilm/policy/zipkin_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "1d"
}
}
},
"warm": {
"min_age": "2d",
"actions": {
"shrink": {
"number_of_shards": 1
}
}
},
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}网络优化 - gRPC调优:
# SkyWalking Agent网络优化
agent.grpc.channel_check_interval=30
agent.grpc.upstream_timeout=30
agent.grpc.channel_keepalive_time=30
agent.grpc.channel_keepalive_timeout=10
# 异步上报,避免阻塞业务线程
agent.buffer.channel_size=5
agent.buffer.buffer_size=3008. 总结与未来展望
8.1 核心结论
-
SkyWalking优势:无侵入、性能开销小、功能全面,适合Java技术栈和对性能敏感的场景。
-
Zipkin优势:多语言支持好、部署简单、生态成熟,适合混合技术栈和快速落地。
-
生产建议:大型Java项目优先考虑SkyWalking,微服务技术栈多样时选择Zipkin。
8.2 未来趋势
-
OpenTelemetry标准化:逐渐成为行业标准,SkyWalking和Zipkin都已支持OTLP协议。
-
eBPF技术:无侵入监控的新方向,有望实现零性能开销的链路追踪。
-
AIOps集成:结合机器学习算法,实现智能根因分析和故障预测。
8.3 最佳实践清单
✅ 一定要做的:
-
生产环境启用采样策略(建议1-10%)
-
配置完整的告警规则(成功率、延迟、错误率)
-
定期清理过期数据(保留7-30天)
-
监控追踪系统自身健康度
❌ 一定要避免的:
-
全量采样(除非调试环境)
-
在业务代码中硬编码Trace逻辑
-
忽略跨线程上下文传递
-
存储无限期保留导致成本失控
技术没有银弹,只有合适的选择 。链路追踪是微服务可观测性的基石,但工具本身不是目的,快速定位和解决问题才是核心价值。希望本文的实战经验能帮助你在复杂的分布式系统中,建立清晰的"上帝视角"。