🐼什么是存储过程
下来看看存储过程的定义:存储过程是⼀组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字和参数来执行,并获取相应的结果。我们发现存储过程跟函数的定义特别相似,是的,我们可以把存储过程理解为一组完成特定功能的数据库的函数。
🐼存储过程的作用
如果没有存储过程,那么我们的请求直接打向数据库中的表;有了存储过程,我们的请求是向存储过程发起的,存储过程又是一组编译好的数据库集,操作起来就很快了。
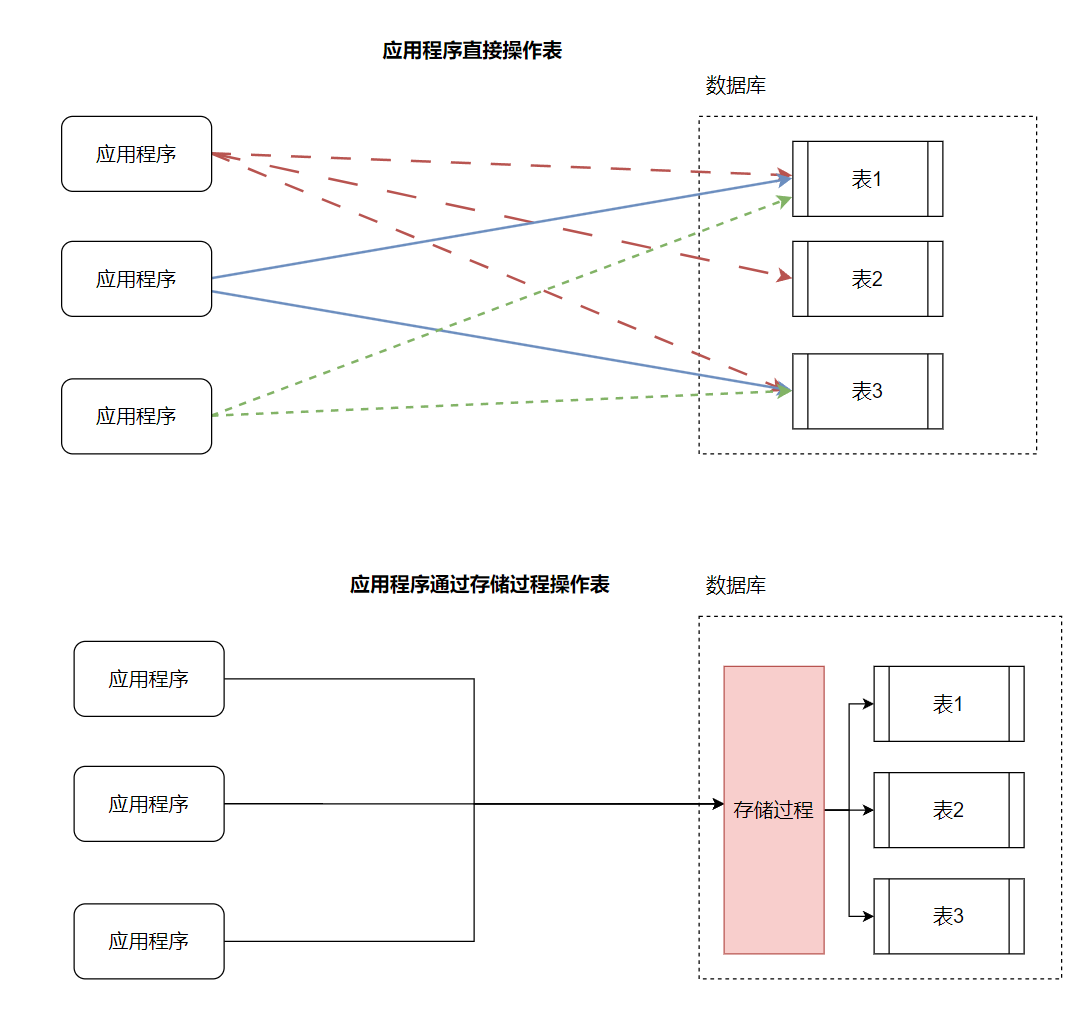
存储过程我们可以想象函数的作用:
其优点:
1.很好的封装性,把业务逻辑封装到数据库内部,减少了程序的复杂性
2.增加了存储过程这一层软件层,很好的保护了数据库
3.性能优化:存储过程在创建时编译并存储在数据库中,执行速度比单个SQL语句快。
4.代码重用:存储过程可以复用,减少重复代码,提高代码的可维护性。
缺点:
可移植性差:存储过程不能跨数据库移植,更换数据库时需要重新编写。
调试困难:只有少数数据库管理系统⽀持存储过程的调试,开发和维护困难。
不适合高并发场景:在高并发场景下,存储过程可能会增加数据库的压力,难以维护
🐼存储过程的创建/查看/删除
存储过程是procedure关键字,它的创建也是create关键字。
创建一个存储过程的标准过程是(最佳实践):
sql
-- 修改SQL语句结束标识符为 //
DELIMITER //
-- 创建存储过程
CREATE PROCEDURE 存储过程名 (参数列表)
BEGIN
-- SQL 语句
END //
-- 修改SQL语句结束标识符为 ;
DELIMITER ;其中delimiter // 是定义结束标识符。比如如果这样一段代码放在cmd命令上就会有语法错误,因为编译器不知道你的结束标志,这导致了你在写sql语句的过程中就结束了,执行不到END。
sql
create procedure p_cal_Sum()
BEGIN
-- 多条sql语句来实现一组特定功能
select name,chinese+math+english as total from exam; -- 走到这里就结束了
END;
-- 调用
CALL p_cal_Sum();所以在命令行中创建存储过程要先修改SQL语句结束标识符,比如 DELIMITER //,最后不要忘记,在定义回来 delimiter ;所以一定使用delimiter去定义结束符。
所以在生产环境或者业务环境,一定要在开头写DELIMITER //,结尾写DELIMITER ;
调用存储过程使用:
sql
-- 调⽤存储过程
CALL 存储过程名 (参数列表);存储过程本质就是编译好的一组sql集嘛,也要占磁盘空间的,查看存储过程是:
sql
-- 查看指定数据库中创建的存储过程
SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_SCHEMA = '数据库名';
-- 查看存储过程的定义
SHOW CREATE PROCEDURE 存储过程名;删除存储过程是:
sql
DROP PROCEDURE [IF EXISTS] 存储过程名;如果把上面的操作都写在一起:
sql
-- 创建一个存储过程
use topic01;
-- 先修改结束标识符
delimiter //
create procedure p_cal_Sum()
BEGIN
-- 多条sql语句来实现一组特定功能
select name,chinese+math+english as total from exam;
END //
-- 不要忘记修改回来
delimiter ;
-- 调用存储过程
CALL p_cal_Sum();
drop procedure if exists p_cal_Sum;