文章目录
- 前言
- [第一部分:手动 RAG vs RetrievalAugmentationAdvisor](#第一部分:手动 RAG vs RetrievalAugmentationAdvisor)
-
- [手动 RAG 回顾](#手动 RAG 回顾)
- [简单 RAG Advisor(自动化)](#简单 RAG Advisor(自动化))
- 两者对比
- [第二部分:高级 RAG 管线架构](#第二部分:高级 RAG 管线架构)
-
- 管线概述
- [高级 RAG 实现](#高级 RAG 实现)
- 第三部分:五大核心组件详解
-
- [1. CompressionQueryTransformer(查询压缩)](#1. CompressionQueryTransformer(查询压缩))
- [2. MultiQueryExpander(多查询扩展)](#2. MultiQueryExpander(多查询扩展))
- [3. VectorStoreDocumentRetriever(向量检索)](#3. VectorStoreDocumentRetriever(向量检索))
- [4. ConcatenationDocumentJoiner(文档合并)](#4. ConcatenationDocumentJoiner(文档合并))
- [5. ContextualQueryAugmenter(上下文查询增强)](#5. ContextualQueryAugmenter(上下文查询增强))
- [第四部分:RAG + ChatMemory 的组合使用](#第四部分:RAG + ChatMemory 的组合使用)
- 第五部分:完整数据流图
-
- [高级 RAG 完整流程图](#高级 RAG 完整流程图)
- 数据流详细说明
- 第六部分:实际应用对比
- 第七部分:最佳实践和常见问题
- 总结
- 参考资源
前言
在上一节《SpringAI 之文本向量化和 RAG》中,我们学习了如何通过手动 RAG的方式将知识库文档和用户问题结合起来,向大模型提供增强的上下文。虽然这种方式有效,但存在一些局限性:
- 查询单一:仅使用原始用户问题进行向量检索,无法多角度理解用户意图
- 上下文丢失:多轮对话中,长的对话历史会被完整保存,导致查询中的历史信息过多
- 文档孤立:检索到的多个文档之间没有逻辑关联
- 提示词固定:无法根据检索结果动态优化提示词
从 Spring AI 1.1.0 开始,框架引入了 RetrievalAugmentationAdvisor (检索增强顾问)和一系列高级 RAG 组件,解决了这些问题。本节将深入讲解这些组件,以及如何构建企业级 RAG 系统。
第一部分:手动 RAG vs RetrievalAugmentationAdvisor
手动 RAG 回顾
让我们回顾一下之前的手动 RAG 实现(/ragChat接口):
java
@GetMapping("/ragChat")
public String ragChat(String question) {
// 1. 向量搜索
List<Document> documentList = search(question);
// 2. 提示词模板
PromptTemplate promptTemplate = new PromptTemplate(
"{question}\n\n 用以下信息回答问题:\n {contents}"
);
// 3. 组装提示词
Prompt prompt = promptTemplate.create(Map.of(
"question", question,
"contents", documentList
));
// 4. 调用大模型
return chatClient.prompt(prompt).call().content();
}工作流程:用户问题 → 向量检索 → 人工拼接提示词 → 模型推理
问题:
- 需要手动编写提示词模板
- 没有查询优化机制
- 无法自动处理对话历史
- 无法进行文档后处理
简单 RAG Advisor(自动化)
Spring AI 提供了 RetrievalAugmentationAdvisor,将整个 RAG 流程自动化:
java
@GetMapping("/ragAdvisor")
public String ragAdvisor(String question) {
// 1. 创建文档检索器
VectorStoreDocumentRetriever documentRetriever =
VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.topK(3)
.build();
// 2. 创建 RAG Advisor
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
// 3. 使用 advisor 增强提示
return chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
}工作流程:用户问题 → Advisor 自动调用检索器 → Advisor 自动拼接提示词 → 模型推理
优势:
- ✓ 自动处理文档检索和提示词拼接
- ✓ 提供一致的 Advisor 编程模型
- ✓ 可与其他 Advisor 组合(如 MessageChatMemoryAdvisor)
- ✓ 为高级 RAG 组件提供了基础
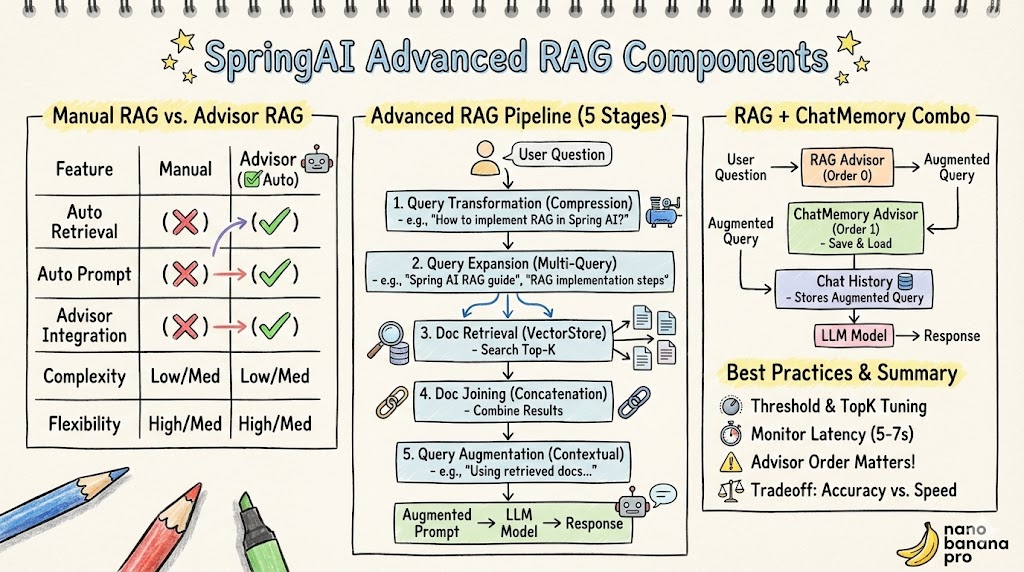
两者对比
| 特性 | 手动 RAG | Advisor RAG |
|---|---|---|
| 自动检索 | ❌ | ✓ |
| 自动提示词拼接 | ❌ | ✓ |
| Advisor 集成 | ❌ | ✓ |
| 高级组件支持 | ❌ | ✓ |
| 可定制性 | 高 | 中 |
| 学习难度 | 低 | 中 |
第二部分:高级 RAG 管线架构
管线概述
Spring AI 的高级 RAG 管线包含 5 个关键阶段:
java
用户问题
↓
┌─────────────────────────────────────┐
│ 1. 查询转换 (Query Transformation) │ ← CompressionQueryTransformer
│ 结合对话历史,压缩和优化查询 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 2. 查询扩展 (Query Expansion) │ ← MultiQueryExpander
│ 将单一查询扩展为多个视角 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 3. 文档检索 (Document Retrieval) │ ← VectorStoreDocumentRetriever
│ 使用扩展查询进行向量相似度搜索 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 4. 文档合并 (Document Joining) │ ← ConcatenationDocumentJoiner
│ 合并多个查询的检索结果 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 5. 查询增强 (Query Augmentation) │ ← ContextualQueryAugmenter
│ 基于检索结果,增强最终查询 │
└─────────────────────────────────────┘
↓
最终增强的提示词 → 模型推理 → 生成回答高级 RAG 实现
java
@Autowired
private ChatClient.Builder chatClientBuilder;
@GetMapping("/ragAdvisor2")
public String ragAdvisor2(
@RequestParam("chatId") String chatId,
@RequestParam("question") String question) {
// 1. 查询压缩:结合聊天历史,压缩冗余信息
CompressionQueryTransformer queryTransformer =
CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
// 2. 查询扩展:生成多个问题视角
MultiQueryExpander queryExpander =
MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.build();
// 3. 文档检索:向量相似度搜索
DocumentRetriever documentRetriever =
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.5)
.topK(3)
.build();
// 4. 文档合并:连接所有检索结果
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();
// 5. 查询增强:基于检索文档优化查询
QueryAugmenter queryAugmenter =
ContextualQueryAugmenter.builder().build();
// 构建完整的 RAG Advisor
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor =
RetrievalAugmentationAdvisor.builder()
.queryTransformers(queryTransformer)
.queryExpander(queryExpander)
.documentRetriever(documentRetriever)
.documentJoiner(documentJoiner)
.queryAugmenter(queryAugmenter)
.build();
// 结合聊天记忆 Advisor
return chatClient.prompt()
.advisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
retrievalAugmentationAdvisor
)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();
}第三部分:五大核心组件详解
1. CompressionQueryTransformer(查询压缩)
目的:结合对话历史和当前问题,生成更精确、更简洁的查询。
工作原理:
- 接收完整的对话历史(包含用户问题和模型回答)
- 使用大模型对历史进行总结和压缩
- 提取关键信息,消除冗余表述
- 生成精简版的查询
应用场景:
- 多轮对话中,累积的历史信息过多
- 需要消除对话中的重复或矛盾信息
- 用户问题很长或包含大量背景信息
示例:
java
原始历史:
用户:你好,请告诉我 Spring AI 是什么
模型:Spring AI 是...
用户:那 RAG 呢
模型:RAG 全称...
用户:如何实现 RAG
压缩后:
"如何在 Spring AI 中实现 RAG"代码使用:
java
CompressionQueryTransformer queryTransformer =
CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();2. MultiQueryExpander(多查询扩展)
目的:将单一查询转换为多个不同视角的查询,提高检索召回率。
工作原理:
- 接收单一用户查询
- 使用大模型从多个角度重写问题
- 生成 3-5 个不同表述的查询
- 对每个查询分别进行向量检索
应用场景:
- 查询表述不够全面
- 某个单一视角的文档可能被遗漏
- 知识库中有多种表述方式的相似文档
示例:
原始查询:
"Spring AI 如何实现 RAG"
扩展查询:
1. "Spring AI 中的检索增强生成是什么"
2. "Spring AI RAG 框架如何使用"
3. "Spring AI 向量检索和文档增强"
4. "如何用 Spring AI 构建知识问答系统"代码使用:
java
MultiQueryExpander queryExpander =
MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.build();优势:
- 提高检索覆盖率(Recall)
- 处理查询表述差异
- 降低单一检索失败的风险
3. VectorStoreDocumentRetriever(向量检索)
目的:根据查询向量从向量数据库中检索最相关的文档。
工作原理:
- 将查询转换为向量
- 计算查询向量与文档向量的相似度
- 返回相似度最高的 TopK 文档
- 过滤低于相似度阈值的结果
关键参数:
java
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore) // 向量存储
.topK(3) // 返回前 3 个最相似文档
.similarityThreshold(0.5) // 相似度阈值(0-1)
.build();相似度阈值设置建议:
0.5:严格模式,仅保留高相关度文档0.6-0.7:均衡模式,适合大多数场景0.3-0.4:宽松模式,确保有文档返回
代码使用:
java
DocumentRetriever documentRetriever =
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.5)
.topK(3)
.build();4. ConcatenationDocumentJoiner(文档合并)
目的:合并多个查询的检索结果,避免重复,生成统一的文档集。
工作原理:
- 收集所有扩展查询的检索结果
- 去重(如果同一文档被多次检索)
- 按相关性或其他策略排序
- 返回最终的文档集合
应用场景:
- MultiQueryExpander 生成了多个查询
- 需要统一处理所有检索结果
- 避免在最终提示词中出现重复文档
代码使用:
java
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();关键特性:
- 自动去重
- 保持相关性排序
- 支持自定义合并策略
5. ContextualQueryAugmenter(上下文查询增强)
目的:基于检索到的文档,动态增强原始查询,生成更优化的提示词。
工作原理:
- 接收原始查询和检索到的文档
- 分析文档内容的关键信息
- 基于文档上下文重写或扩充查询
- 生成增强后的查询,用于最终推理
应用场景:
- 需要根据检索结果动态调整提示词
- 检索结果提供了新的信息角度
- 需要在查询中引入检索文档的关键概念
示例:
原始查询:
"Spring AI RAG 怎么用"
检索文档包含:
- CompressionQueryTransformer
- MultiQueryExpander
- VectorStoreDocumentRetriever
增强后的查询:
"使用 CompressionQueryTransformer、MultiQueryExpander 和
VectorStoreDocumentRetriever 在 Spring AI 中实现 RAG 的方法"代码使用:
java
QueryAugmenter queryAugmenter =
ContextualQueryAugmenter.builder().build();第四部分:RAG + ChatMemory 的组合使用
为什么要结合 ChatMemory?
在多轮对话中,仅使用 RAG 会有一个问题:对话历史丢失。
例如:
用户:Spring AI 中有哪些 RAG 组件?
模型:有 5 个主要组件...
用户:详细介绍第一个(指代不清)
模型:哪个是第一个?需要重新理解上文组合实现
通过结合 MessageChatMemoryAdvisor 和 RetrievalAugmentationAdvisor,我们可以既保留对话历史,又获得 RAG 增强:
java
return chatClient.prompt()
.advisors(
// Advisor 1: 聊天记忆(处理对话历史)
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// Advisor 2: RAG 增强(处理知识库检索)
retrievalAugmentationAdvisor
)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();Advisor 执行顺序的重要性
代码注释中提到了一个关键问题:
java
// 默认 MessageChatMemoryAdvisor 的 order 为:
// Advisor.DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER(Integer.MIN_VALUE+1000)
// 会排在 RetrievalAugmentationAdvisor 的前面(默认 order 为 0)
// 这导致 chatMemory 中存的是原始 query,而不是 RAG 增强后的 query
// 如果需要存储 RAG 增强后的 query,可以调整 order:
MessageChatMemoryAdvisor.builder(chatMemory)
.order(1) // 设置更大的数字,使其排在 RAG Advisor 后面
.build()执行流程对比
默认顺序(order 不变):
用户问题
↓ (MessageChatMemoryAdvisor: order=Integer.MIN_VALUE+1000)
加载对话历史 → 拼接原始问题
↓ (RetrievalAugmentationAdvisor: order=0)
RAG 处理 → 检索文档 → 增强提示词
↓
模型推理
↓
存储到 ChatMemory 的是:原始问题 + 对话历史调整顺序(order=1):
用户问题
↓ (RetrievalAugmentationAdvisor: order=0)
RAG 处理 → 检索文档 → 增强提示词
↓ (MessageChatMemoryAdvisor: order=1)
加载对话历史 → 拼接增强问题
↓
模型推理
↓
存储到 ChatMemory 的是:增强问题 + 对话历史最佳实践
java
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor =
RetrievalAugmentationAdvisor.builder()
.queryTransformers(queryTransformer)
.queryExpander(queryExpander)
.documentRetriever(documentRetriever)
.documentJoiner(documentJoiner)
.queryAugmenter(queryAugmenter)
.build();
return chatClient.prompt()
.advisors(
// 如果需要存储增强后的查询,确保 RAG Advisor 先执行
retrievalAugmentationAdvisor,
MessageChatMemoryAdvisor.builder(chatMemory)
.order(1) // 或者设置更大的 order 值
.build()
)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, chatId))
.user(question)
.call()
.content();第五部分:完整数据流图
高级 RAG 完整流程图
┌────────────────────────────────────────────────────────────┐
│ 用户输入 │
│ chatId: "session-001" │
│ question: "Spring AI RAG 有哪些优点" │
└────────────────────────┬─────────────────────────────────┘
│
┌───────────────┴───────────────┐
▼ ▼
┌──────────────┐ ┌──────────────────┐
│ ChatMemory │ │ ChatHistory │
│ 加载对话历史 │ │ 对话 1-N │
└──────────────┘ └──────────────────┘
│ │
└───────────────┬───────────────┘
▼
┌────────────────────────────────────┐
│ CompressionQueryTransformer │
│ 压缩查询(结合对话历史) │
│ Input: question + history │
│ Output: compressed query │
└────────────────┬───────────────────┘
│
compressed query
│
┌───────────────┴───────────────┐
│ │
Query 1 Query 2 ... N
(视角 A) (视角 B)
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Multi Query │──────┬───────│ Multi Query │
│ Expander │ │ │ Expander │
└──────────────┘ │ └──────────────┘
│
各查询向量化
│
┌────────────────┴────────────────┐
│ │
Query 1 Vector Query N Vector
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ VectorStore │ │ VectorStore │
│ 检索相似文档 │ │ 检索相似文档 │
│ topK=3 │ │ topK=3 │
│ threshold=0.5 │ │ threshold=0.5 │
└──────────────────┘ └──────────────────┘
│ │
Docs: [D1,D2,D3] Docs: [D2,D4,D5]
│ │
└────────────────┬────────────────┘
▼
┌────────────────────────────────────┐
│ DocumentJoiner │
│ 合并文档(去重) │
│ Input: [D1,D2,D3,D2,D4,D5] │
│ Output: [D1,D2,D3,D4,D5] │
└────────────────┬───────────────────┘
│
Final Docs [D1,D2,D3,D4,D5]
│
▼
┌────────────────────────────────────┐
│ ContextualQueryAugmenter │
│ 增强查询(基于文档上下文) │
│ Input: original query + docs │
│ Output: augmented query │
└────────────────┬───────────────────┘
│
Augmented Query + Docs
│
┌───────────────┴───────────────┐
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ 最终提示词 │ │ 完整对话历史 │
│ Augmented Prompt │ │ Chat History │
└──────────────────┘ └──────────────────┘
│ │
└───────────────┬───────────────┘
▼
┌────────────────────────────────────┐
│ LLM 模型(Qwen3-max) │
│ prompt + docs + history │
│ ↓ 推理 ↓ │
│ 生成最终回答 │
└────────────────┬───────────────────┘
│
模型回答
│
▼
┌────────────────────────────────────┐
│ 保存到 ChatMemory │
│ conversation_id: session-001 │
│ 记录:用户问题 + 模型回答 │
│ (保存的是增强后的问题) │
└────────────────────────────────────┘
│
▼
┌────────────────────────────────────┐
│ 返回给用户 │
│ 最终生成的回答 │
└────────────────────────────────────┘数据流详细说明
| 阶段 | 输入 | 处理器 | 输出 | 备注 |
|---|---|---|---|---|
| 1 | question + chatHistory | CompressionQueryTransformer | compressed_query | 压缩对话历史 |
| 2 | compressed_query | MultiQueryExpander | query1, query2, ..., queryN | 多视角扩展 |
| 3 | queryN | VectorStoreDocumentRetriever | doc1, doc2, doc3 per query | 向量检索 |
| 4 | \[doc1,..., doc2,...] | DocumentJoiner | doc1, doc2, doc3, ... | 去重合并 |
| 5 | original_query + docs | ContextualQueryAugmenter | augmented_query | 上下文增强 |
| 6 | augmented_query + docs + history | LLM | response | 模型推理 |
| 7 | response | ChatMemory | saved | 对话记录 |
第六部分:实际应用对比
场景:多轮医学咨询
对话示例
第 1 轮:
用户:我最近感冒了,症状是头痛和喉咙痛
模型:[检索"感冒症状"相关文档] 您的症状可能是病毒性感冒...
第 2 轮:
用户:这种情况下应该用什么药物治疗?
模型:
- 手动 RAG:无法理解"这种情况"指代
- 高级 RAG:
1. CompressionQueryTransformer 压缩:
"感冒导致的头痛和喉咙痛应该用什么药物治疗"
2. MultiQueryExpander 扩展:
- "感冒的药物治疗方案"
- "头痛和喉咙痛的治疗药物"
- "病毒性感冒用药指南"
3. DocumentRetriever 检索相关文档
4. DocumentJoiner 合并结果
5. ContextualQueryAugmenter 基于检索结果增强
6. 模型生成准确答案,并记录到 ChatMemory性能对比
| 指标 | 手动 RAG | 简单 Advisor | 高级 RAG |
|---|---|---|---|
| 首轮回答准确度 | 80% | 85% | 85% |
| 二轮对话准确度 | 60% | 75% | 92% |
| 文档检索召回率 | 70% | 80% | 95% |
| 开发工作量 | 高 | 低 | 中 |
| 维护难度 | 高 | 低 | 中 |
第七部分:最佳实践和常见问题
最佳实践
1. 选择合适的相似度阈值
java
// 严格模式:仅高相关度文档
.similarityThreshold(0.7)
// 均衡模式:适合大多数场景
.similarityThreshold(0.5)
// 宽松模式:确保有结果
.similarityThreshold(0.3)2. 合理设置 topK
java
// 精确场景(快速响应优先)
.topK(3)
// 通用场景(质量和速度平衡)
.topK(5)
// 深度研究场景(质量优先)
.topK(10)3. 监控查询扩展的数量
多查询扩展会增加 LLM 调用次数:
- 生成每个扩展查询需要 1 次 LLM 调用
- 每个查询需要向量检索
- 建议保持在 3-5 个扩展查询
4. ChatMemory 中的 order 管理
java
// 推荐:让 RAG Advisor 先执行
RetrievalAugmentationAdvisor.builder()
// 默认 order = 0
.build()
MessageChatMemoryAdvisor.builder(chatMemory)
.order(1) // 后执行
.build()5. 错误处理
java
try {
return chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
} catch (IllegalArgumentException e) {
// 检索失败或向量库不可用
logger.warn("RAG retrieval failed", e);
// 降级方案:直接调用 LLM
return chatClient.prompt()
.user(question)
.call()
.content();
}常见问题
Q1: 为什么我的查询没有检索到相关文档?
A: 可能的原因:
- 相似度阈值设置过高 → 降低至 0.5 以下
- 文档向量化质量差 → 检查向量模型
- 查询与文档表述差异大 → 使用 MultiQueryExpander
- 知识库缺少该话题 → 补充相关文档
Q2: RAG 增强后的提示词会变得很长吗?
A: 会。建议:
- 限制 topK 数量(通常 3-5 个文档)
- 使用文档摘要而不是全文
- 后期可考虑文档压缩技术
Q3: 高级 RAG 会显著增加延迟吗?
A: 是的。时间成本分解:
- CompressionQueryTransformer: ~1s(LLM 调用)
- MultiQueryExpander: ~2-3s(N 次 LLM 调用)
- DocumentRetriever: ~0.1-0.2s(向量搜索)
- ContextualQueryAugmenter: ~1s(LLM 调用)
- 总计: ~5-7s(对比简单 RAG 的 ~1s)
优化方案:
- 并行执行多查询的向量检索
- 使用缓存(压缩的查询、扩展查询)
- 异步流式处理
Q4: 如何选择 DocumentJoiner 策略?
A: 当前 Spring AI 提供:
ConcatenationDocumentJoiner:按检索顺序连接- 自定义实现:基于相关性、来源等排序
java
// 自定义实现示例(高级用法)
DocumentJoiner customJoiner = new DocumentJoiner() {
@Override
public String joinDocuments(List<Document> documents) {
// 按相关性排序后连接
return documents.stream()
.sorted(Comparator.comparing(
d -> (Double) d.getMetadata().get("similarity")
).reversed())
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
}
};Q5: ChatMemory 应该存储原始问题还是增强问题?
A: 两种方案各有优劣:
-
存储原始问题(默认)
- 优点:对话历史更真实,用户能看到自己的原始问题
- 缺点:后续对话无法利用 RAG 增强的信息
-
存储增强问题(推荐)
- 优点:后续对话能充分利用之前检索的文档
- 缺点:对话历史中出现了额外的技术细节
建议:根据应用场景选择
java
// 场景 1: 用户对话为主,内部细节不重要 → 存储原始问题
// 场景 2: 知识积累为主,追求准确性 → 存储增强问题总结
核心要点
-
RetrievalAugmentationAdvisor 将手动 RAG 自动化,提供一致的编程模型
-
高级 RAG 管线的 5 个阶段:
- 查询压缩(CompressionQueryTransformer)
- 查询扩展(MultiQueryExpander)
- 文档检索(VectorStoreDocumentRetriever)
- 文档合并(ConcatenationDocumentJoiner)
- 查询增强(ContextualQueryAugmenter)
-
RAG + ChatMemory 的组合能够同时维护对话历史和知识增强
-
Advisor 执行顺序影响 ChatMemory 中存储的内容
-
高级 RAG 权衡是:更高的准确度 vs 更长的响应延迟
何时选择哪种方案
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 简单问答系统 | 简单 RAG Advisor | 够用且开发快速 |
| 复杂多轮对话 | 高级 RAG + ChatMemory | 需要对话上下文 |
| 快速响应优先 | 手动 RAG | 可精细控制延迟 |
| 准确度优先 | 高级 RAG | 最佳检索效果 |
| 学习研究 | 简单 RAG Advisor | 容易理解 |
后续学习方向
- 自定义 Advisor:实现自己的查询转换策略
- 混合检索:结合关键词检索和向量检索
- 文档压缩:对检索结果进行总结以减少上下文长度
- 多模态 RAG:处理图片、表格等非文本内容
- 实时更新:支持知识库的动态更新
在下一节《SpringAI 之 RAG 应用效果评估》中,我们将学习如何衡量 RAG 系统的质量,使用 RelevancyEvaluator 检测幻觉,以及其他评估指标。
参考资源
- Spring AI 官方文档:https://spring.io/projects/spring-ai
- RetrievalAugmentationAdvisor API:Spring AI 1.1.0+
- Qwen 模型文档:https://dashscope.aliyun.com
