说起本地知识库,可能很多人会觉得这是个很高大上的技术活儿,好像只有专业团队才能搞定。但今天要介绍的 RAGFlow,正在让这件事变得前所未有的简单------哪怕你是技术小白,只要跟着步骤来,也能搭建起属于自己的本地知识库系统。
为什么选择 RAGFlow
在说怎么搭建之前,先聊聊为什么 RAGFlow 能成为当前最火的本地知识库方案。
RAGFlow 是由 Infinity Intelligence 开发的一款开源 RAG(检索增强生成)引擎,目前在 GitHub 上已经收获了超过 80,000 颗星标。它的核心优势在于对文档的深度理解能力------不仅仅是简单的关键词匹配,而是真正能读懂文档的结构、表格、图片和排版格式。
拿一个实际场景来举例:假设你上传了一份包含复杂表格的 PDF 年度报告,传统的 RAG 方案可能会把表格内容切得七零八落,导致检索时无法获取完整的表格信息。而 RAGFlow 能够识别表格结构,保留表格的完整性,让问答更加准确。
目前的 v0.25.0 版本带来了多项重要更新,包括全新的解析管道、7 个新的文档解析模板,以及对 Seafile、RSS、DingTalk 等数据源的支持。知识图谱生成效率相比之前提升了 14 倍,从 8550 秒锐减至 608 秒。
硬件与软件环境准备
搭建本地知识库,硬件是基础。很多人担心自己的电脑能不能跑起来,这里给一个参考:
最低配置要求:
-
CPU:4 核以上
-
内存:16GB 以上
-
磁盘:50GB 可用空间
-
显卡:如果要跑本地大模型(推荐),建议 NVIDIA 显卡,7B 参数模型需要 RTX 3060 Ti 或更高
当然,如果你不想在本地跑大模型,也可以选择调用云端 API(比如 OpenAI、DeepSeek、火山引擎等),这样对显卡要求就低很多,普通电脑也能流畅运行。
软件环境方面,你需要准备:
-
Docker Desktop(版本 24.0.0 或更高)
-
Docker Compose(版本 2.26.1 或更高)
-
Git(用于下载源码)
Windows 用户直接去 Docker 官网下载 Docker Desktop 安装包,一路下一步即可。需要注意的是,如果你电脑上之前安装过 VMware 等虚拟机软件,可能需要先卸载,因为 Docker 默认使用 Hyper-V,可能会产生冲突。
Docker 环境配置
Docker 安装完成后,有一步至关重要的配置:设置 vm.max_map_count。这个参数对 Elasticsearch 的正常运行至关重要,如果不设置,启动 RAGFlow 时可能会遇到"Can't connect to ES cluster"的错误。
Windows 用户打开 PowerShell 或命令提示符,执行:
wsl -d docker-desktop -u root
sysctl -w vm.max_map_count=262144Mac 用户执行:
docker run --rm --privileged --pid=host alpine sysctl -w vm.max_map_count=262144Linux 用户编辑 /etc/sysctl.conf 文件,添加一行:
vm.max_map_count=262144
下载并启动 RAGFlow
环境配置好后,接下来就是下载 RAGFlow 了。打开终端,执行以下命令:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
git checkout -f v0.25.0这里指定了 v0.25.0 版本,这是目前最新的稳定版本。如果你想要最新功能,可以不执行 git checkout 命令,使用 nightly 版本。
启动服务之前,你需要修改 .env 配置文件。主要修改以下几项:
如果你在国内,需要取消注释 HF_ENDPOINT 这一行,设置为国内镜像:
HF_ENDPOINT=https://hf-mirror.com然后执行启动命令:
docker compose -f docker-compose.yml up -d注意:如果你有 NVIDIA 显卡,使用 docker-compose-gpu.yml 可以获得更好的性能。没有显卡的用户使用 docker-compose.yml 即可。
启动完成后,查看日志确认服务状态:
docker logs -f docker-ragflow-server-1
看到下面这样的输出就说明启动成功了:
基础配置:让系统跑起来
服务启动成功后,打开浏览器访问 http://服务器IP(默认端口 80),会看到登录页面。首次使用需要注册账号,点击注册后登录即可。
登录后第一件事是配置大语言模型。点击右上角的 Logo,选择"模型供应商"
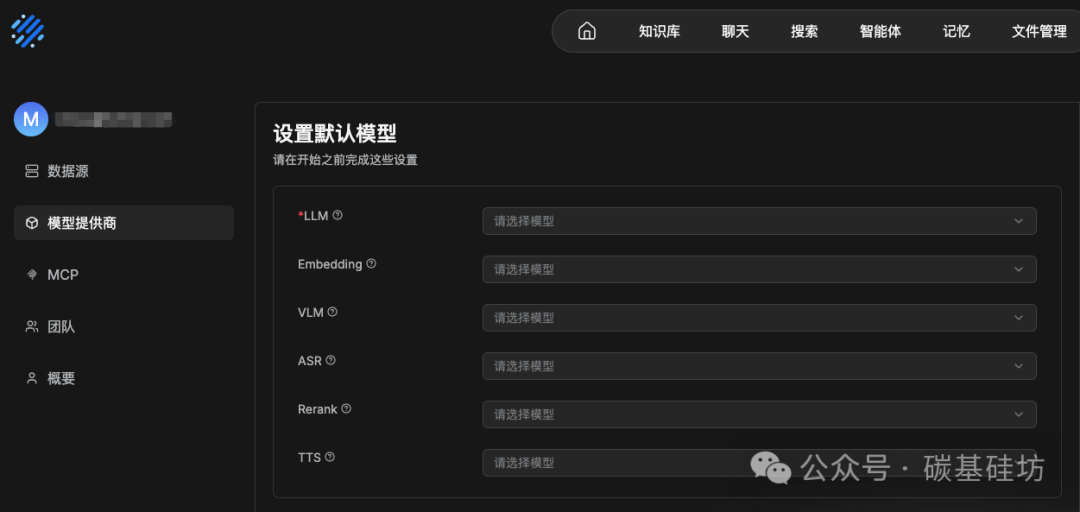
RAGFlow 支持非常丰富的大模型选择:
-
云端 API:OpenAI GPT 系列、Anthropic Claude、DeepSeek、通义千问、火山引擎、豆包等
-
本地部署:通过 Ollama 支持 DeepSeek、Qwen、Llama 等开源模型
如果你选择使用 Ollama 本地部署模型,需要先下载安装 Ollama,然后在终端中下载所需模型:
ollama run qwen3.5:9b在 RAGFlow 中添加 Ollama 时,基础 URL 填写 http://host.docker.internal:11434,API Key 留空,最大 token 数根据模型能力设置。
配置完成后,还需要进行系统模型设置,分别选择默认的聊天模型、嵌入模型等。
创建你的第一个知识库
模型配置好后,就可以创建知识库了。点击页面上方的"知识库"选项卡,然后点击"创建知识库"。
进入配置页面后,需要设置以下参数:
嵌入模型选择:这个一旦选择并用于解析文件后就无法更改,所以要根据实际需求选择合适的模型。常用的嵌入模型包括 BGE、Text2Vec 等。
分段方法:RAGFlow 提供了多种分段模板,适应不同的文档布局:
-
naive_:通用文档,适合大多数场景
-
table_:带表格的文档
-
paper_:学术论文
-
book_:书籍
-
laws_:法律法规
-
presentation_:PPT 和幻灯片
-
manual_:用户手册
-
qa_:问答格式文档
配置完成后,进入知识库的详情页面。
上传文档与解析
点击"+ 添加文件",RAGFlow 支持多种格式:
-
文档:PDF、DOC、DOCX、TXT、MD
-
表格:CSV、XLSX
-
图片:JPEG、JPG、PNG
-
幻灯片:PPT、PPTX
上传完成后,点击文件右侧的"播放"按钮开始解析。解析过程会根据文档大小和复杂度耗时不同,首次使用时会下载相关模型,请确保网络连接正常。
解析完成后,可以点击文件查看分段结果。RAGFlow 会展示文档被切分的各个片段,你可以预览每个片段的内容,确认切分是否符合预期。
如果发现切分不够精确,可以双击某个分段,手动添加关键词或修改内容。这个过程叫做"干预解析",是 RAGFlow 的一大特色------它让你能够精细控制知识库的质量。
开始对话
知识库准备就绪后,点击"聊天"选项卡,创建一个新的对话。
在聊天设置中,需要指定要关联的知识库。还可以设置"空回复"行为------选择"不启用"时,如果检索不到相关信息,系统会如实告诉你"我不知道";选择启用后,系统会尝试在没有检索结果时基于自身能力回答。
配置完成后,就可以在对话框中提问了。RAGFlow 会从你的知识库中检索相关片段,结合大语言模型生成回答,并且会标注引用的来源,让你知道答案来自哪份文档的哪个部分。
数据源扩展:连接更多内容
v0.25.0 版本支持从多种在线数据源同步数据:
-
AWS S3
-
Google Drive
-
Notion
-
Confluence
-
Discord
-
Seafile
-
RSS
-
钉钉
这意味着你不必手动上传所有文档,可以让 RAGFlow 自动从这些平台同步最新内容到知识库中。对于团队协作场景,这个功能非常实用。
常见问题与解决方案
启动时报错"Can't connect to ES cluster":这是因为 vm.max_map_count 没有正确设置,回到前面的配置步骤重新设置即可。
文件解析卡在 1% 不动:如果使用的是精简版镜像,可能需要手动下载嵌入模型。检查日志确认具体原因。
解析在接近完成时卡住:检查 Docker 日志,查看是否有内存不足或网络超时的问题。
友情提示:
知识库的质量很大程度上取决于文档的质量和分段策略。在创建知识库前,建议先整理好文档格式,去除无关内容,这样才能获得最佳的问答效果。