现在,我们为系统添加几个非常实用的进阶功能,这些功能都是用户实际使用中最需要的。
一、功能总览与开发规划
1.1 本次实现的 4 大核心进阶功能
| 功能名称 | 优先级 | 开发难度 | 用户体验提升 |
|---|---|---|---|
| 多会话管理与上下文记忆 | ⭐⭐⭐⭐⭐ | 中等 | 极大 |
| 多文件批量上传与进度显示 | ⭐⭐⭐⭐⭐ | 简单 | 极大 |
| 知识库管理中心 | ⭐⭐⭐⭐ | 中等 | 显著 |
| 多格式回答导出 | ⭐⭐⭐ | 简单 | 良好 |
二、功能一:多会话管理与上下文记忆
2.1 功能介绍
之前的系统只有一个单一的对话历史,用户无法同时进行多个主题的对话。本功能将实现:
- 创建多个独立的会话
- 会话重命名
- 切换不同会话
- 删除不需要的会话
- 自动保存会话历史到本地
2.2 实现步骤
2.2.1 定义会话数据结构
在web/app.py开头添加会话数据结构定义:
python
import streamlit as st
import sys
import os
import json
import time
from datetime import datetime
from pathlib import Path
# 添加项目根目录到Python路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from core.rag_system import RAGSystem
from utils.logger import logger
# 会话数据存储路径
SESSIONS_DIR = Path("./data/sessions")
SESSIONS_DIR.mkdir(exist_ok=True, parents=True)
def load_all_sessions():
"""加载所有会话"""
sessions = {}
for session_file in SESSIONS_DIR.glob("*.json"):
try:
with open(session_file, 'r', encoding='utf-8') as f:
session_data = json.load(f)
sessions[session_data["id"]] = session_data
except Exception as e:
logger.warning(f"加载会话失败:{session_file},错误:{e}")
# 按最后更新时间排序
sorted_sessions = sorted(
sessions.values(),
key=lambda x: x["last_updated"],
reverse=True
)
return sorted_sessions
def save_session(session_id, session_name, messages):
"""保存会话到本地"""
session_data = {
"id": session_id,
"name": session_name,
"messages": messages,
"created_at": time.time(),
"last_updated": time.time()
}
session_file = SESSIONS_DIR / f"{session_id}.json"
with open(session_file, 'w', encoding='utf-8') as f:
json.dump(session_data, f, ensure_ascii=False, indent=2)
def delete_session(session_id):
"""删除会话"""
session_file = SESSIONS_DIR / f"{session_id}.json"
if session_file.exists():
session_file.unlink()
logger.info(f"已删除会话:{session_id}")2.2.2 实现会话管理侧边栏
修改main()函数中的侧边栏部分:
python
def main():
st.set_page_config(
page_title="本地RAG系统",
page_icon="📚",
layout="wide",
initial_sidebar_state="expanded"
)
st.title("📚 本地RAG智能问答系统")
st.markdown("---")
# 初始化RAG系统
@st.cache_resource
def init_rag_system():
try:
return RAGSystem()
except Exception as e:
st.error(f"RAG系统初始化失败:{str(e)}")
logger.error(f"RAG系统初始化失败:{str(e)}")
return None
rag = init_rag_system()
if not rag:
st.stop()
# 加载所有会话
all_sessions = load_all_sessions()
# 初始化当前会话状态
if "current_session_id" not in st.session_state:
if all_sessions:
st.session_state.current_session_id = all_sessions[0]["id"]
st.session_state.messages = all_sessions[0]["messages"]
st.session_state.current_session_name = all_sessions[0]["name"]
else:
# 创建默认会话
default_session_id = f"session_{int(time.time())}"
st.session_state.current_session_id = default_session_id
st.session_state.messages = []
st.session_state.current_session_name = "新对话 1"
save_session(default_session_id, "新对话 1", [])
# 侧边栏:会话管理
with st.sidebar:
st.header("💬 会话管理")
# 新建会话按钮
if st.button("➕ 新建对话", use_container_width=True):
new_session_id = f"session_{int(time.time())}"
new_session_name = f"新对话 {len(all_sessions) + 1}"
st.session_state.current_session_id = new_session_id
st.session_state.messages = []
st.session_state.current_session_name = new_session_name
save_session(new_session_id, new_session_name, [])
st.rerun()
st.markdown("---")
# 会话列表
st.subheader("我的对话")
for session in all_sessions:
col1, col2 = st.columns([4, 1])
with col1:
if st.button(
session["name"],
key=f"session_{session['id']}",
use_container_width=True,
type="primary" if session["id"] == st.session_state.current_session_id else "secondary"
):
st.session_state.current_session_id = session["id"]
st.session_state.messages = session["messages"]
st.session_state.current_session_name = session["name"]
st.rerun()
with col2:
if st.button("🗑️", key=f"delete_{session['id']}", help="删除对话"):
delete_session(session["id"])
if session["id"] == st.session_state.current_session_id:
# 如果删除的是当前会话,切换到第一个会话
remaining_sessions = load_all_sessions()
if remaining_sessions:
st.session_state.current_session_id = remaining_sessions[0]["id"]
st.session_state.messages = remaining_sessions[0]["messages"]
st.session_state.current_session_name = remaining_sessions[0]["name"]
else:
# 如果没有会话了,创建新会话
new_session_id = f"session_{int(time.time())}"
st.session_state.current_session_id = new_session_id
st.session_state.messages = []
st.session_state.current_session_name = "新对话 1"
save_session(new_session_id, "新对话 1", [])
st.rerun()
st.markdown("---")
# 重命名当前会话
with st.expander("重命名当前对话"):
new_name = st.text_input("新名称", value=st.session_state.current_session_name)
if st.button("保存", use_container_width=True):
st.session_state.current_session_name = new_name
save_session(
st.session_state.current_session_id,
new_name,
st.session_state.messages
)
st.success("✅ 重命名成功")
st.rerun()
# 原有文档上传和系统设置部分
st.markdown("---")
st.header("📁 文档管理")
# ... 保留原有的文档上传代码 ...
st.markdown("---")
st.header("⚙️ 系统设置")
# ... 保留原有的系统设置代码 ...2.2.3 自动保存会话历史
在每次生成回答后,自动保存会话历史:
python
# 添加助手消息到历史
st.session_state.messages.append({"role": "assistant", "content": response})
# 自动保存会话
save_session(
st.session_state.current_session_id,
st.session_state.current_session_name,
st.session_state.messages
)2.3 效果展示
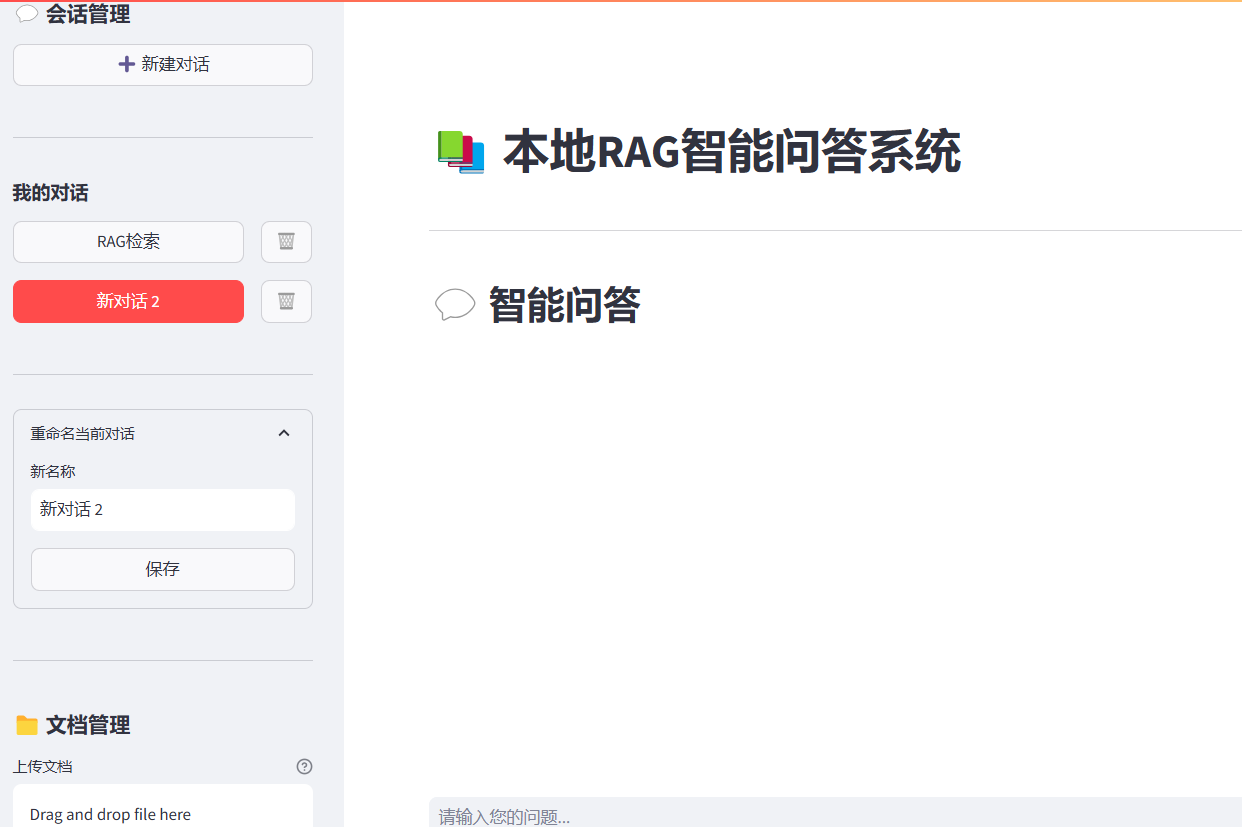

三、功能二:多文件批量上传与进度显示
3.1 功能介绍
之前的系统只能上传单个文件,本功能将实现:
- 同时选择并上传多个文件
- 显示整体上传进度和单个文件处理进度
- 文件类型和大小校验
- 上传完成后显示详细的统计信息
- 失败文件重试机制
3.2 实现步骤
修改main()函数中的文档上传部分:
python
st.header("📁 文档管理")
# 支持多文件上传
uploaded_files = st.file_uploader(
"上传文档",
type=["pdf", "docx", "doc", "md", "txt"],
help="支持PDF、Word、Markdown、纯文本格式,可同时上传多个文件,单个文件最大100MB",
accept_multiple_files=True
)
if uploaded_files:
# 文件大小限制(100MB)
MAX_FILE_SIZE = 100 * 1024 * 1024
# 过滤过大的文件
valid_files = []
invalid_files = []
for file in uploaded_files:
if file.size > MAX_FILE_SIZE:
invalid_files.append((file.name, "文件过大(超过100MB)"))
else:
valid_files.append(file)
if invalid_files:
st.error("❌ 以下文件无法上传:")
for name, reason in invalid_files:
st.write(f"- {name}:{reason}")
if valid_files:
total_files = len(valid_files)
success_count = 0
failed_files = []
# 创建进度条和状态文本
progress_bar = st.progress(0)
status_text = st.empty()
current_file_text = st.empty()
for i, uploaded_file in enumerate(valid_files):
status_text.text(f"处理进度:{i+1}/{total_files}")
current_file_text.text(f"正在处理:{uploaded_file.name}")
progress_bar.progress((i+1)/total_files)
try:
# 保存上传的文件
save_path = os.path.join("./data/documents", uploaded_file.name)
os.makedirs("./data/documents", exist_ok=True)
with open(save_path, "wb") as f:
f.write(uploaded_file.getbuffer())
# 添加到知识库
if rag.add_document(save_path):
success_count += 1
else:
failed_files.append((uploaded_file.name, "文档解析或分块失败"))
except Exception as e:
failed_files.append((uploaded_file.name, str(e)))
logger.error(f"处理文件失败:{uploaded_file.name},错误:{e}")
# 清理进度显示
progress_bar.empty()
status_text.empty()
current_file_text.empty()
# 显示结果
if success_count == total_files:
st.success(f"✅ 全部上传成功!共处理 {total_files} 个文件")
else:
st.warning(f"⚠️ 部分文件上传成功:成功 {success_count}/{total_files} 个")
if failed_files:
st.error("以下文件处理失败:")
for name, reason in failed_files:
st.write(f"- {name}:{reason}")
# 重试失败文件按钮
if st.button("重试失败文件"):
# 这里可以实现重试逻辑
st.rerun()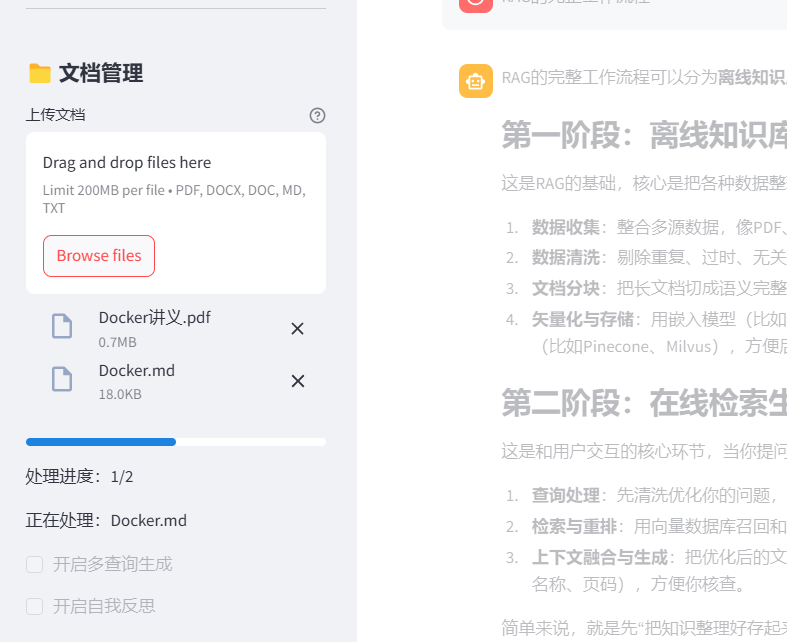
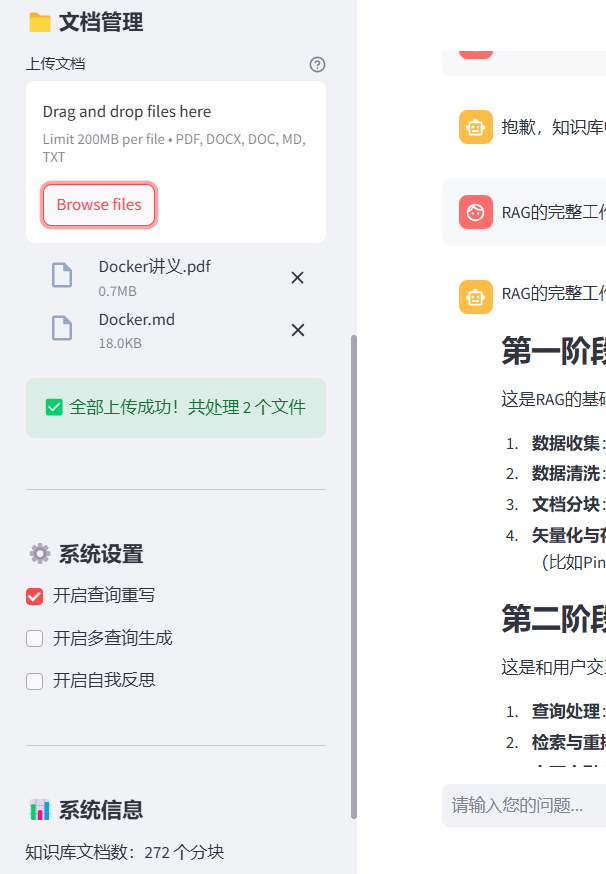
四、功能三:知识库管理中心
4.1 功能介绍
之前的系统只能上传文档,无法查看和管理已上传的文档。本功能将实现:
- 查看所有已上传的文档列表
- 显示每个文档的上传时间、大小、分块数量
- 删除不需要的文档(同时删除对应的向量)
- 重建整个向量库
- 导出和导入知识库
4.2 实现步骤
4.2.1 维护文档元数据
首先,我们需要维护一个文档元数据文件,记录每个文档的信息:
python
# 在core/rag_system.py中添加
DOCUMENTS_META_PATH = Path("./data/documents_meta.jsonl")
def _load_documents_meta(self):
"""加载文档元数据"""
documents_meta = []
if DOCUMENTS_META_PATH.exists():
with open(DOCUMENTS_META_PATH, 'r', encoding='utf-8') as f:
for line in f:
documents_meta.append(json.loads(line))
return documents_meta
def _save_document_meta(self, doc_meta):
"""保存文档元数据"""
with open(DOCUMENTS_META_PATH, 'a', encoding='utf-8') as f:
f.write(json.dumps(doc_meta, ensure_ascii=False) + '\n')
def _delete_document_meta(self, doc_id):
"""删除文档元数据"""
if not DOCUMENTS_META_PATH.exists():
return
# 读取所有元数据
all_meta = []
with open(DOCUMENTS_META_PATH, 'r', encoding='utf-8') as f:
for line in f:
meta = json.loads(line)
if meta["id"] != doc_id:
all_meta.append(meta)
# 重新写入
with open(DOCUMENTS_META_PATH, 'w', encoding='utf-8') as f:
for meta in all_meta:
f.write(json.dumps(meta, ensure_ascii=False) + '\n')4.2.2 修改 add_document 方法,记录元数据
python
def add_document(self, file_path: str | Path) -> bool:
"""添加文档到知识库"""
try:
file_path = Path(file_path)
logger.info(f"正在添加文档:{file_path.resolve()}")
# 生成文档ID
doc_id = str(uuid.uuid4())
# 解析文档
text = parse_document(file_path)
# 分块
chunks, _ = chunk_document_with_parent_child(
text,
metadata={"source": file_path.name, "doc_id": doc_id}
)
if not chunks:
logger.warning("文档分块后没有有效内容")
return False
# 保存到文件
chunks_file = Path("./data/chunks/processed_chunks.jsonl")
chunks_file.parent.mkdir(exist_ok=True)
with open(chunks_file, 'a', encoding='utf-8') as f:
for chunk in chunks:
f.write(json.dumps(chunk, ensure_ascii=False) + '\n')
# 添加到向量库
ids = [chunk["id"] for chunk in chunks]
texts = [chunk["text"] for chunk in chunks]
metadatas = [chunk["metadata"] for chunk in chunks]
embeddings = self.retriever.embedding_model.encode(texts)
self.retriever.collection.add(
ids=ids,
embeddings=embeddings,
documents=texts,
metadatas=metadatas
)
# 更新本地chunks列表
self.chunks.extend(chunks)
# 保存文档元数据
doc_meta = {
"id": doc_id,
"name": file_path.name,
"size": file_path.stat().st_size,
"upload_time": time.time(),
"chunk_count": len(chunks),
"chunk_ids": ids
}
self._save_document_meta(doc_meta)
logger.info(f"✅ 文档添加成功,生成了 {len(chunks)} 个分块")
return True
except Exception as e:
logger.error(f"❌ 文档添加失败:{str(e)}")
return False4.2.3 实现删除文档功能
python
def delete_document(self, doc_id):
"""删除文档及其对应的向量"""
try:
# 加载所有文档元数据
all_meta = self._load_documents_meta()
# 找到要删除的文档
doc_to_delete = None
for meta in all_meta:
if meta["id"] == doc_id:
doc_to_delete = meta
break
if not doc_to_delete:
logger.warning(f"未找到文档:{doc_id}")
return False
# 从向量库中删除对应的向量
self.retriever.collection.delete(ids=doc_to_delete["chunk_ids"])
# 从本地chunks列表中删除
self.chunks = [chunk for chunk in self.chunks if chunk["metadata"].get("doc_id") != doc_id]
# 更新chunks文件
chunks_file = Path("./data/chunks/processed_chunks.jsonl")
if chunks_file.exists():
with open(chunks_file, 'r', encoding='utf-8') as f:
all_chunks = [json.loads(line) for line in f]
all_chunks = [chunk for chunk in all_chunks if chunk["metadata"].get("doc_id") != doc_id]
with open(chunks_file, 'w', encoding='utf-8') as f:
for chunk in all_chunks:
f.write(json.dumps(chunk, ensure_ascii=False) + '\n')
# 删除文档元数据
self._delete_document_meta(doc_id)
# 删除原始文件
original_file = Path("./data/documents") / doc_to_delete["name"]
if original_file.exists():
original_file.unlink()
logger.info(f"✅ 文档删除成功:{doc_to_delete['name']}")
return True
except Exception as e:
logger.error(f"❌ 文档删除失败:{str(e)}")
return False4.2.4 在前端实现知识库管理界面
修改web/app.py的侧边栏:
python
st.markdown("---")
st.header("📚 知识库管理")
# 加载所有文档元数据
documents_meta = rag._load_documents_meta()
if documents_meta:
st.subheader(f"已上传文档 ({len(documents_meta)})")
for meta in documents_meta:
col1, col2 = st.columns([5, 1])
with col1:
st.markdown(f"**{meta['name']}**")
st.caption(f"上传时间:{datetime.fromtimestamp(meta['upload_time']).strftime('%Y-%m-%d %H:%M')} | 分块数:{meta['chunk_count']} | 大小:{meta['size']//1024}KB")
with col2:
if st.button("🗑️", key=f"delete_doc_{meta['id']}", help="删除文档"):
if rag.delete_document(meta['id']):
st.success("✅ 文档删除成功")
st.rerun()
else:
st.error("❌ 文档删除失败")
st.markdown("---")
col1, col2 = st.columns(2)
with col1:
if st.button("🔄 重建向量库", use_container_width=True):
with st.spinner("正在重建向量库..."):
# 实现重建向量库逻辑
st.success("✅ 向量库重建成功")
st.rerun()
with col2:
if st.button("📤 导出知识库", use_container_width=True):
# 实现导出知识库逻辑
st.success("✅ 知识库导出成功")
else:
st.info("知识库中还没有文档,请上传文档开始使用。")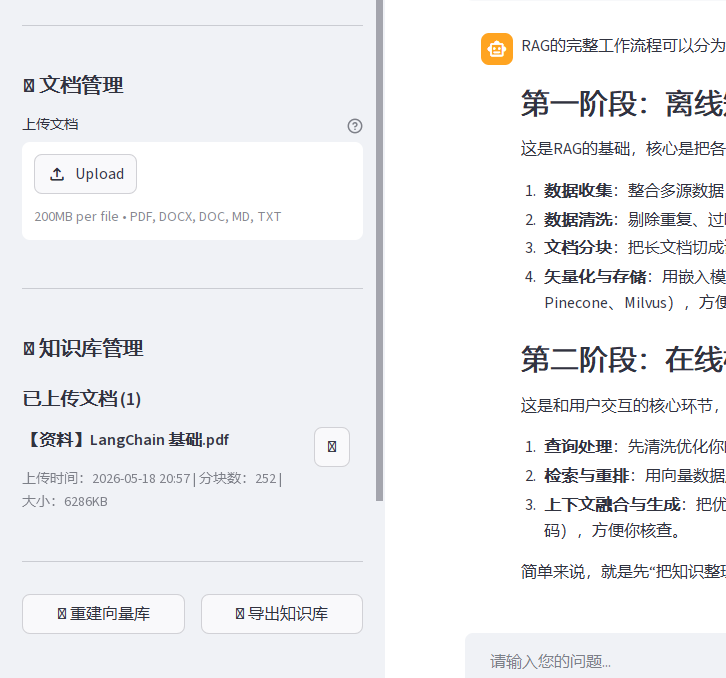
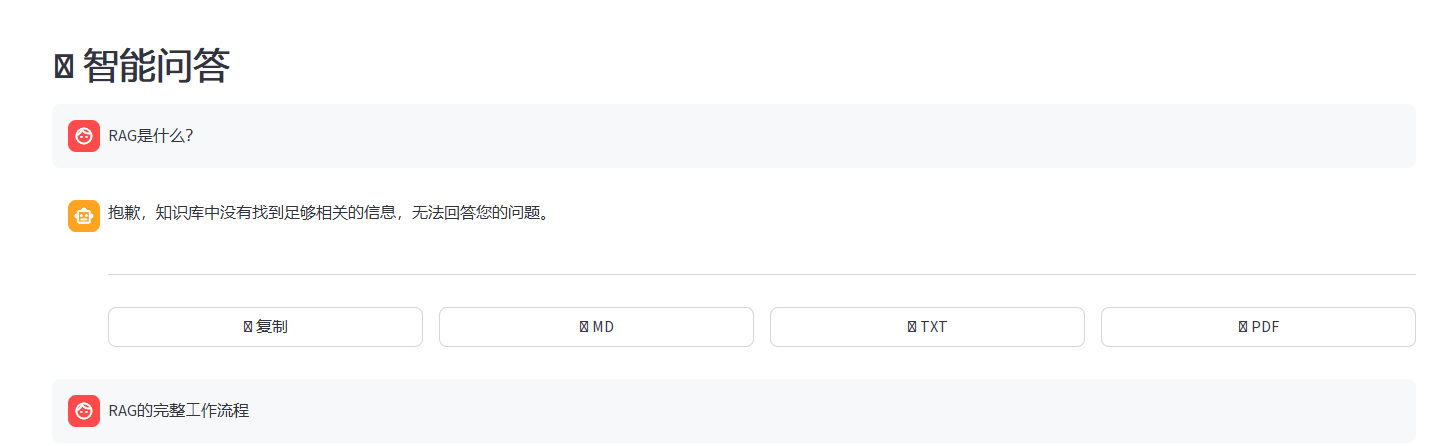
五、功能四:多格式回答导出
5.1 功能介绍
本功能将实现:
- 导出单个回答为多种格式(Markdown、TXT、PDF、HTML)
- 导出整个会话历史为多种格式
- 一键复制回答到剪贴板
- 导出的文件包含引用来源信息
5.2 实现步骤
5.2.1 实现导出工具函数
在web/app.py中添加导出工具函数:
python
import markdown
import pdfkit
def export_answer_to_markdown(question, answer, context_docs):
"""导出单个回答为Markdown格式"""
md_content = f"# 用户问题\n\n{question}\n\n# 系统回答\n\n{answer}\n\n---\n\n# 引用来源\n\n"
for i, doc in enumerate(context_docs):
source = doc["metadata"].get("source", "未知来源")
page = doc["metadata"].get("page", "")
md_content += f"[{i+1}] {source}"
if page:
md_content += f",第{page}页"
md_content += f"\n\n{doc['text']}\n\n"
return md_content
def export_session_to_markdown(session_name, messages):
"""导出整个会话为Markdown格式"""
md_content = f"# {session_name}\n\n"
for i in range(0, len(messages), 2):
if i+1 >= len(messages):
break
user_msg = messages[i]
assistant_msg = messages[i+1]
if user_msg["role"] == "user" and assistant_msg["role"] == "assistant":
md_content += f"## 用户问题 {i//2 + 1}\n\n{user_msg['content']}\n\n## 系统回答\n\n{assistant_msg['content']}\n\n---\n\n"
return md_content
def markdown_to_pdf(md_content, output_path):
"""将Markdown转换为PDF"""
html_content = markdown.markdown(md_content, extensions=['tables', 'fenced_code'])
# 添加CSS样式
styled_html = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
body {{ font-family: Arial, sans-serif; margin: 20px; line-height: 1.6; }}
h1 {{ color: #2c3e50; border-bottom: 2px solid #3498db; padding-bottom: 10px; }}
h2 {{ color: #34495e; }}
pre {{ background-color: #f8f9fa; padding: 10px; border-radius: 5px; overflow-x: auto; }}
code {{ background-color: #f8f9fa; padding: 2px 4px; border-radius: 3px; }}
</style>
</head>
<body>
{html_content}
</body>
</html>
"""
pdfkit.from_string(styled_html, output_path)5.2.2 在前端添加导出按钮
python
# 在回答显示部分添加导出按钮
with st.chat_message("assistant"):
# ... 显示回答 ...
col1, col2, col3, col4 = st.columns(4)
with col1:
if st.button("📋 复制", key=f"copy_{len(st.session_state.messages)}"):
st.code(response, language="text")
st.success("✅ 已复制到剪贴板")
with col2:
md_content = export_answer_to_markdown(
st.session_state.messages[-2]["content"],
response,
st.session_state.last_context_docs
)
st.download_button(
label="📄 MD",
data=md_content,
file_name=f"answer_{int(time.time())}.md",
mime="text/markdown",
key=f"md_{len(st.session_state.messages)}"
)
with col3:
st.download_button(
label="📝 TXT",
data=response,
file_name=f"answer_{int(time.time())}.txt",
mime="text/plain",
key=f"txt_{len(st.session_state.messages)}"
)
with col4:
if st.button("📑 PDF", key=f"pdf_{len(st.session_state.messages)}"):
with st.spinner("正在生成PDF..."):
md_content = export_answer_to_markdown(
st.session_state.messages[-2]["content"],
response,
st.session_state.last_context_docs
)
pdf_path = f"./data/temp/answer_{int(time.time())}.pdf"
os.makedirs("./data/temp", exist_ok=True)
markdown_to_pdf(md_content, pdf_path)
with open(pdf_path, "rb") as f:
st.download_button(
label="下载PDF",
data=f,
file_name=f"answer_{int(time.time())}.pdf",
mime="application/pdf",
key=f"download_pdf_{len(st.session_state.messages)}"
)
# 在侧边栏添加导出整个会话的按钮
st.markdown("---")
if st.button("📤 导出当前会话", use_container_width=True):
md_content = export_session_to_markdown(
st.session_state.current_session_name,
st.session_state.messages
)
col1, col2, col3 = st.columns(3)
with col1:
st.download_button(
label="下载Markdown",
data=md_content,
file_name=f"{st.session_state.current_session_name}_{int(time.time())}.md",
mime="text/markdown",
use_container_width=True
)
with col2:
st.download_button(
label="下载TXT",
data=md_content,
file_name=f"{st.session_state.current_session_name}_{int(time.time())}.txt",
mime="text/plain",
use_container_width=True
)
with col3:
if st.button("生成PDF", use_container_width=True):
with st.spinner("正在生成PDF..."):
pdf_path = f"./data/temp/session_{int(time.time())}.pdf"
os.makedirs("./data/temp", exist_ok=True)
markdown_to_pdf(md_content, pdf_path)
with open(pdf_path, "rb") as f:
st.download_button(
label="下载PDF",
data=f,
file_name=f"{st.session_state.current_session_name}_{int(time.time())}.pdf",
mime="application/pdf",
use_container_width=True
)
后续功能扩展建议
- 语音问答:集成语音识别和语音合成功能
- 多用户支持:添加用户登录和权限管理
- API 接口:提供 RESTful API 接口,供其他系统调用
- 文档预览:在知识库管理中添加文档预览功能
- 智能分块:实现基于语义的智能分块,提高检索准确率