目录
1.摘要
针对大规模优化问题中大种群消耗过多适应度评估次数、导致进化不足的问题,本文提出了一种小规模学习粒子群算法(SSLPSO)。该方法每代仅更新最多两个代表性个体,以节省计算资源并延长有效进化过程,从而提升解的精度;同时结合代表个体选择机制、差异化学习策略以及基于进化状态的自适应调整机制,实现收敛性与多样性的动态平衡。
2.SSLPSO算法
代表性个体选择策略
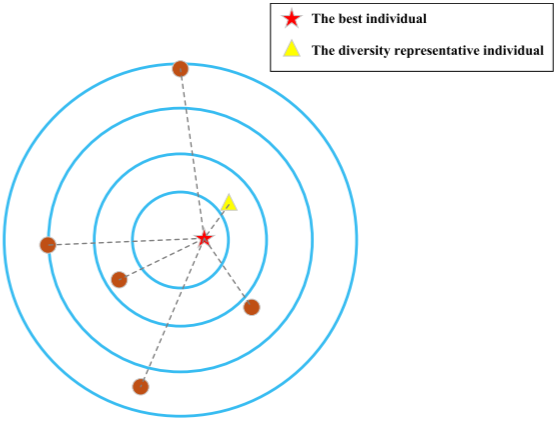
在大规模优化中,为兼顾收敛与多样性,SSLPSO算法分别选取两类代表个体进行更新:将适应度最差、但改进空间最大的个体作为收敛代表个体,以提升整体收敛速度;将距离最优个体最近的个体作为多样性代表个体,以增强种群探索能力并避免陷入局部最优。
代表性个体学习策略
在选定收敛代表个体与多样性代表个体后,RIL策略分别通过双学习样本机制进行更新。对于收敛代表个体,从适应度排名前10%与前β×NP个体中分别随机选取学习样本 e 1 e_1 e1与 e 2 e_2 e2,更新:
v c r d ( t + 1 ) = ω d v c r d ( t ) + r 1 d ( e 1 d ( t ) − x c r d ( t ) ) + ϕ r 2 d ( e 2 d ( t ) − x c r d ( t ) ) v_{cr}^d(t+1)=\omega^dv_{cr}^d(t)+r_1^d\big(e_1^d(t)-x_{cr}^d(t)\big)+\phi r_2^d\big(e_2^d(t)-x_{cr}^d(t)\big) vcrd(t+1)=ωdvcrd(t)+r1d(e1d(t)−xcrd(t))+ϕr2d(e2d(t)−xcrd(t))
x c r d ( t + 1 ) = x c r d ( t ) + v c r d ( t + 1 ) x_{cr}^d(t+1)=x_{cr}^d(t)+v_{cr}^d(t+1) xcrd(t+1)=xcrd(t)+vcrd(t+1)
对于多样性代表个体,则根据多样性指标从前10%与前β×NP个体中选取 e 3 e_3 e3与 e 4 e_4 e4,更新:
v d r d ( t + 1 ) = ω d v d r d ( t ) + r 1 d ( e 3 d ( t ) − x d r d ( t ) ) + ϕ r 2 d ( e 4 d ( t ) − x d r d ( t ) ) v_{dr}^d(t+1)=\omega^dv_{dr}^d(t)+r_1^d\big(e_3^d(t)-x_{dr}^d(t)\big)+\phi r_2^d\big(e_4^d(t)-x_{dr}^d(t)\big) vdrd(t+1)=ωdvdrd(t)+r1d(e3d(t)−xdrd(t))+ϕr2d(e4d(t)−xdrd(t))
x d r d ( t + 1 ) = x d r d ( t ) + v d r d ( t + 1 ) x_{dr}^d(t+1)=x_{dr}^d(t)+v_{dr}^d(t+1) xdrd(t+1)=xdrd(t)+vdrd(t+1)
其中 ω d \omega^d ωd为惯性权重, r 1 d , r 2 d ∈ 0 , 1 r_1^d,r_2^d\in0,1 r1d,r2d∈0,1, ϕ \phi ϕ为第二学习样本影响因子。学习样本在每一维度更新时重新选取,使代表个体能够融合优质个体与更广范围种群信息,从而分别强化收敛能力与多样性。

自适应策略调整
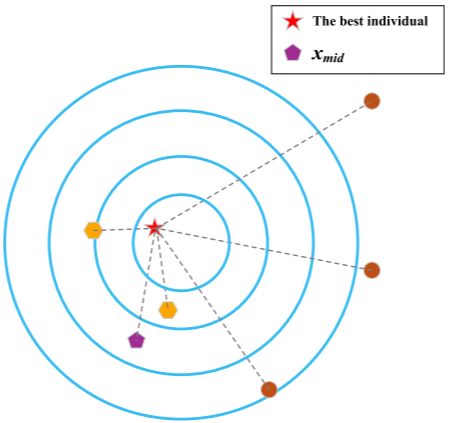
为协调收敛与多样性之间的影响,ASA机制根据种群多样性状态自适应决定更新策略:收敛代表个体始终更新;而多样性代表个体仅在种群出现多样性不足、趋于集中于同一区域时才更新。若种群仍在多个区域探索、多样性充足,则不更新多样性代表个体。


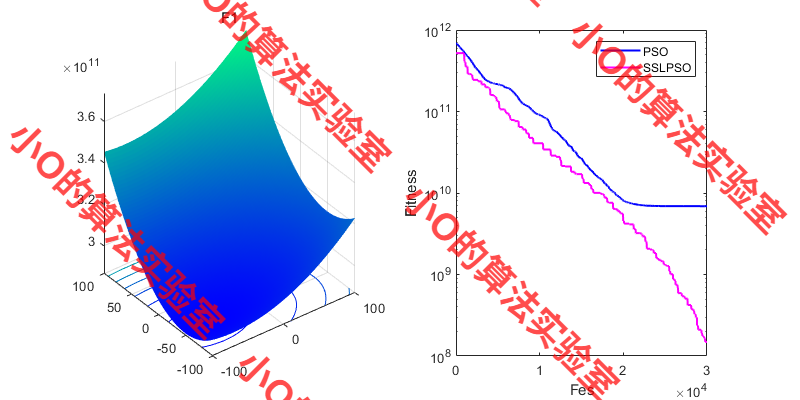
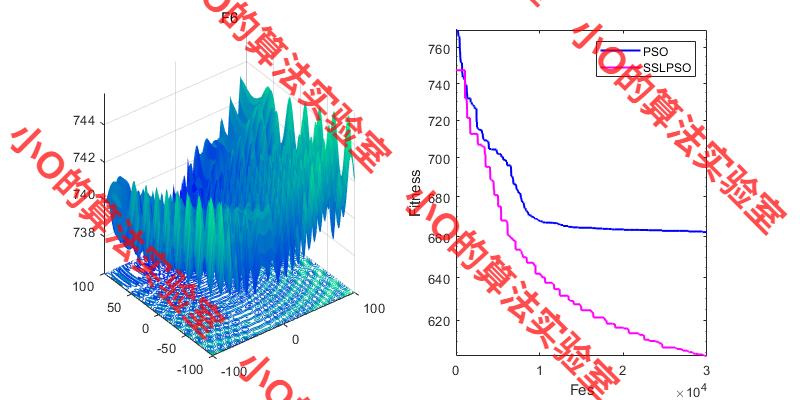
3.结果展示
4.参考文献
1 Liu S, Wang Z J, Kou Z, et al. Less is more: A small-scale learning particle swarm optimization for large-scale optimizationJ. IEEE Transactions on Cybernetics, 2025.
5.代码获取
xx
6.算法辅导·应用定制·读者交流
xx