各位 CSDN 的开发者伙伴、AI 技术爱好者、AIGC 与数字人领域的同路人,大家好!
今天,我正式带着SeeDance 2.0,扎根 CSDN 这个国内最具活力的开发者社区,和所有深耕技术、热爱创作的你,开启一段关于 AI 舞蹈生成技术的探索与共建之旅。
在 AIGC 技术爆发式迭代的今天,数字内容创作的边界正在被不断打破。而舞蹈生成,作为融合音乐理解、动作动力学、人体美学与多模态生成技术的垂直赛道,始终有着极高的技术门槛。从初代模型动作僵硬、节拍错位、风格单一,到难以根治的动作穿模、泛化能力不足、落地部署门槛高等问题,无数开发者和创作者都曾在这条路上踩过坑、遇过坎。我们也一样,从 SeeDance 1.0 版本上线至今,始终扎根一线打磨算法、收集全场景用户反馈、逐个攻克核心技术痛点,终于在今天,把完成全链路深度升级的 SeeDance 2.0,正式带到了大家面前。
相较于初代版本,SeeDance 2.0 实现了从 "可生成" 到 "高精度、强可控、易落地" 的跨越式升级。我们重构了音乐 - 动作对齐核心算法,让舞蹈动作与音乐节拍、情绪风格的匹配度实现质的飞跃;优化了人体动力学约束模型,彻底解决了高频出现的肢体违和、动作穿模问题,支持古典舞、街舞、民族舞等数十种舞蹈风格的高精度生成;同时大幅降低了技术使用门槛,既提供了面向算法研究者的开源训练框架,也准备了面向内容创作者的开箱即用工具链,让不同技术背景的伙伴,都能轻松用上专业级的 AI 舞蹈生成能力。
选择 CSDN,是因为这里聚集了国内最纯粹的技术人、最有创造力的开发者。在这里,我们不会只做简单的功能宣发,而是会毫无保留地分享 SeeDance 2.0 背后的全链路技术细节:从核心算法的原理解析、模型训练的踩坑实录,到轻量化部署的全流程教程、多行业落地的实战案例,再到研发过程中遇到的技术难题与完整解决方案,都会以系列文章的形式持续更新。
无论你是刚入门 AIGC 领域的新手,想找到 AI 舞蹈生成的系统学习路径;是深耕多模态生成的算法工程师,想交流技术优化的核心思路;是数字内容行业的从业者,想探索 AI 舞蹈生成的商业落地场景;还是热爱开源的开发者,想一起完善项目、共建技术生态,我们都无比欢迎你的到来。你可以在评论区留下你的疑问、想法与需求,每一条留言我们都会认真回复;也可以关注后续更新,和我们一起打破 AI 舞蹈生成的技术壁垒,拓宽数字内容的创作边界。
技术的价值,从来都不在于闭门造车的孤芳自赏,而在于开放共享的双向奔赴。SeeDance 2.0 是我们交出的新答卷,而更精彩的故事,需要和 CSDN 的每一位同路人一起书写。再次感谢大家的关注与支持,期待和大家一起,在 AI 舞蹈生成的赛道上,同行共进,创见未来!
目录
一.什么是提示词?
1.大白话解释
当你要进行问生图时,你给大模型的描述。
2.举例
在即梦,随便找一个图片作品,点进去
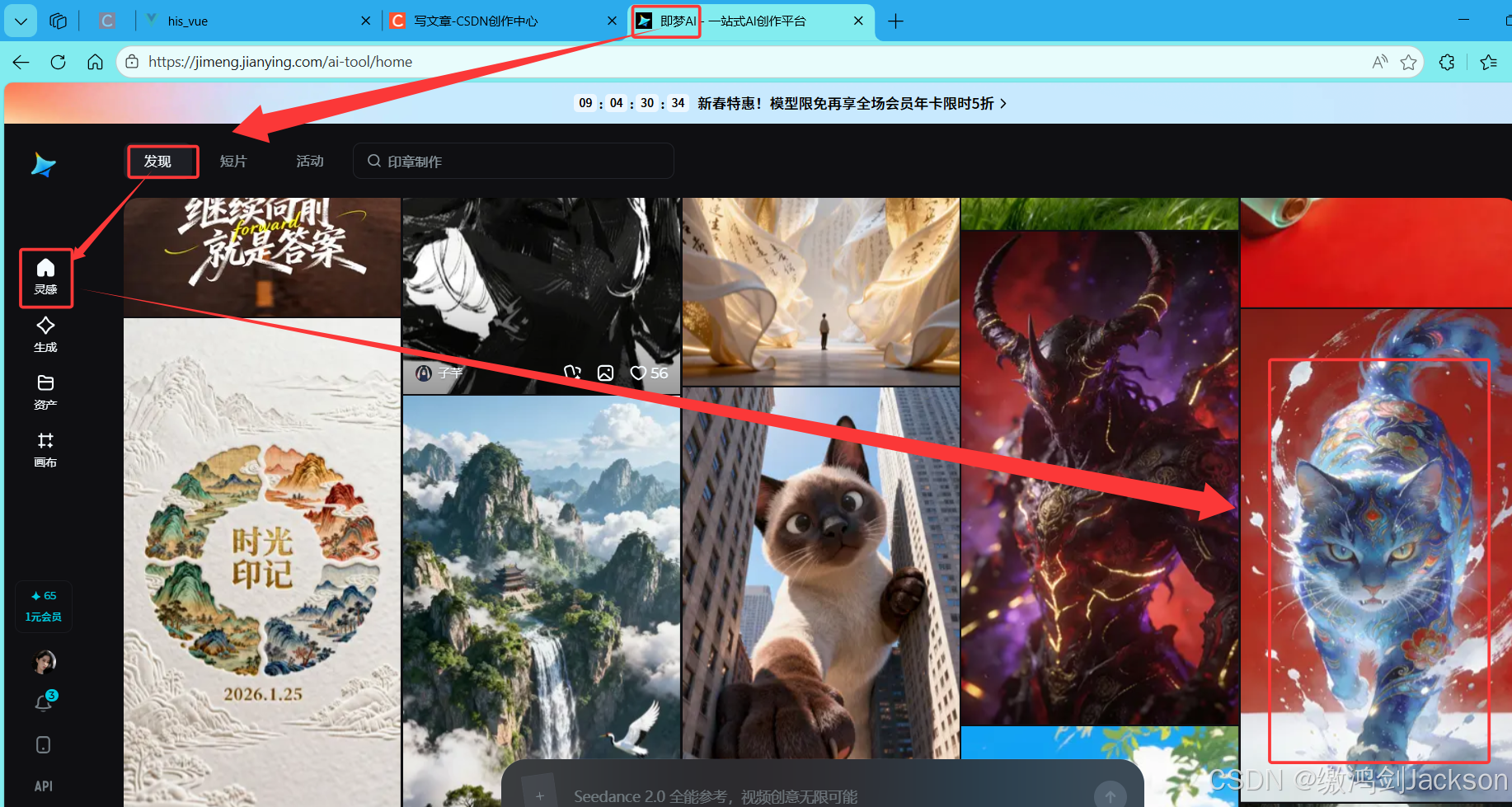
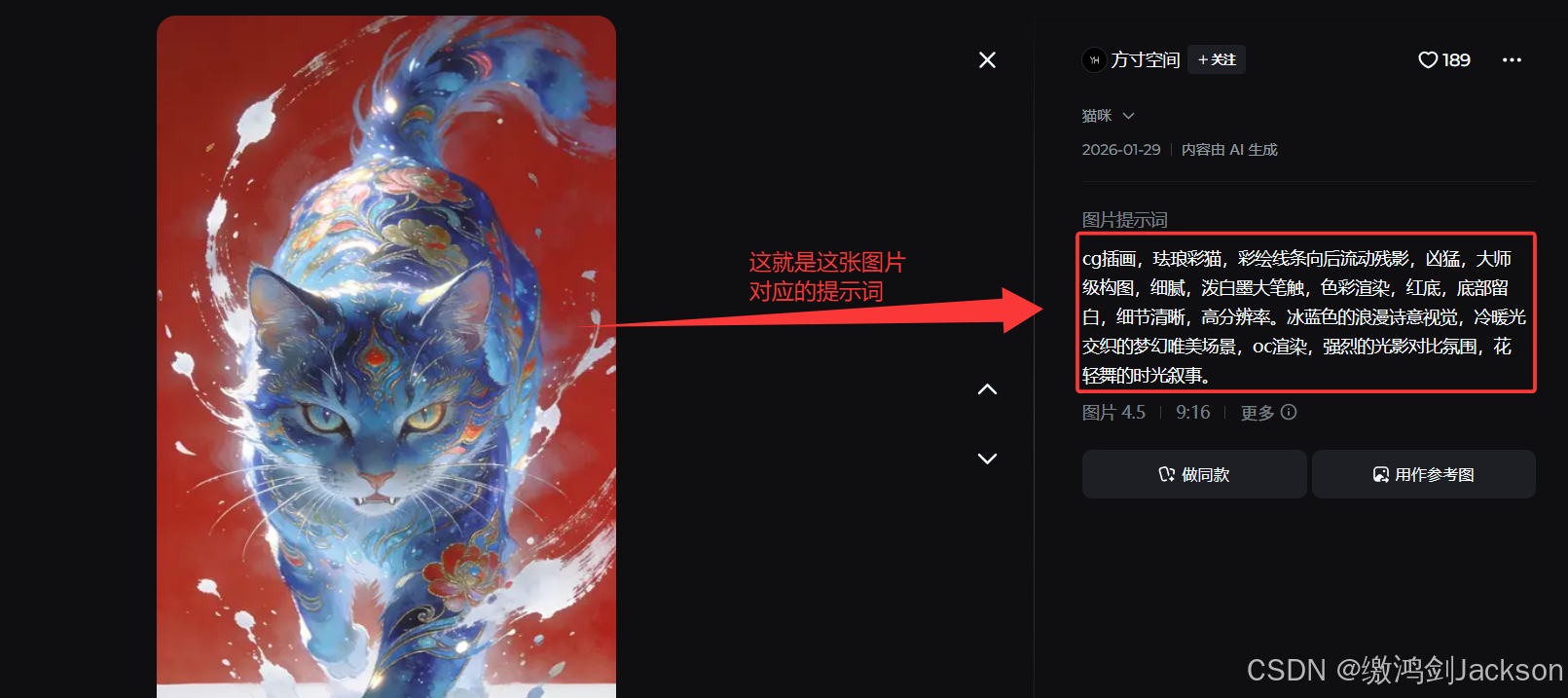
二.大语言模型助力编写提示词
大语言模型:就是豆包那种的。
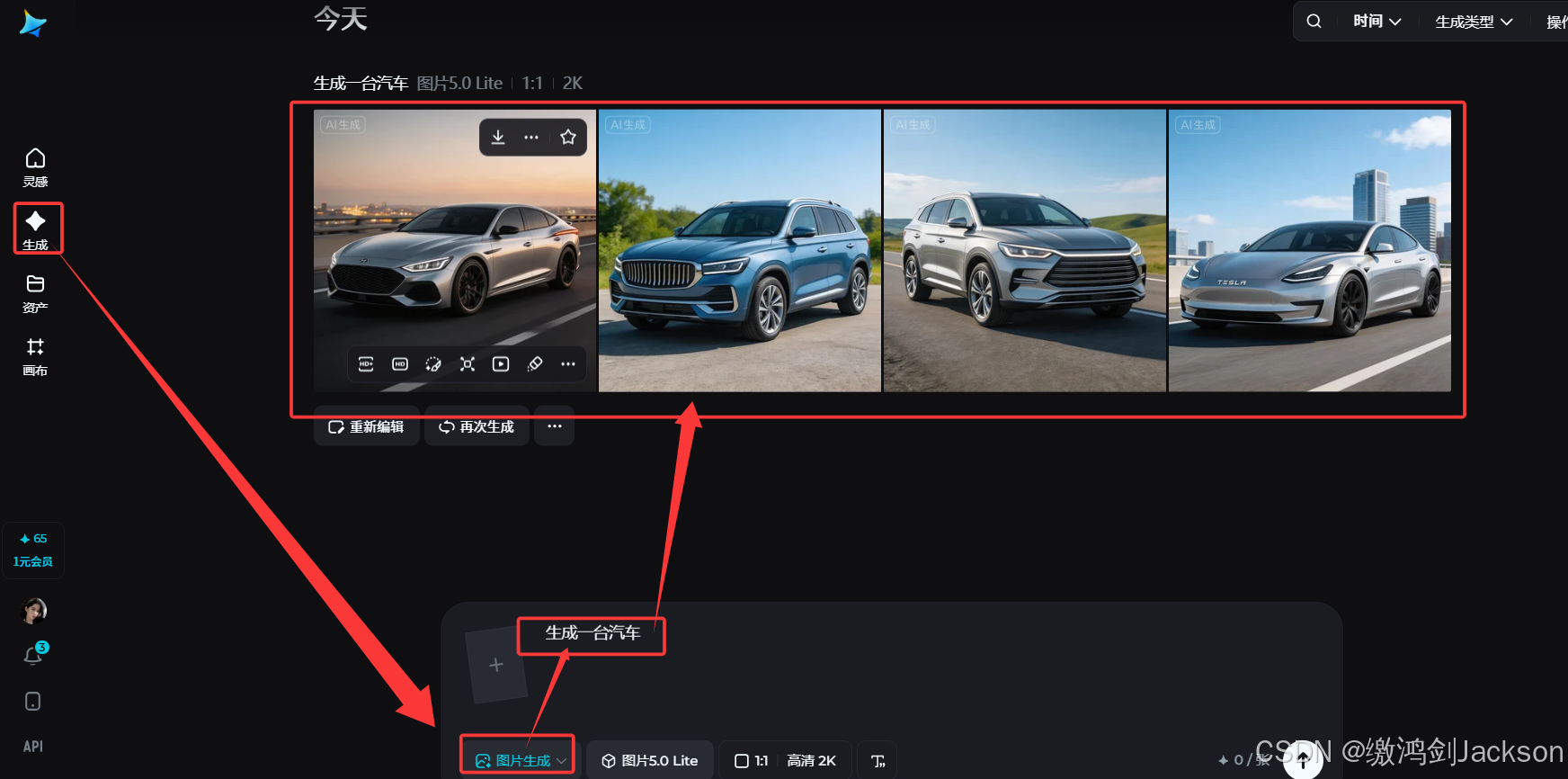
1.不用大语言模型优化提示词
此时提示词是"生成一台汽车"。
很简单,效果也一般。
2.使用大语言模型优化提示词

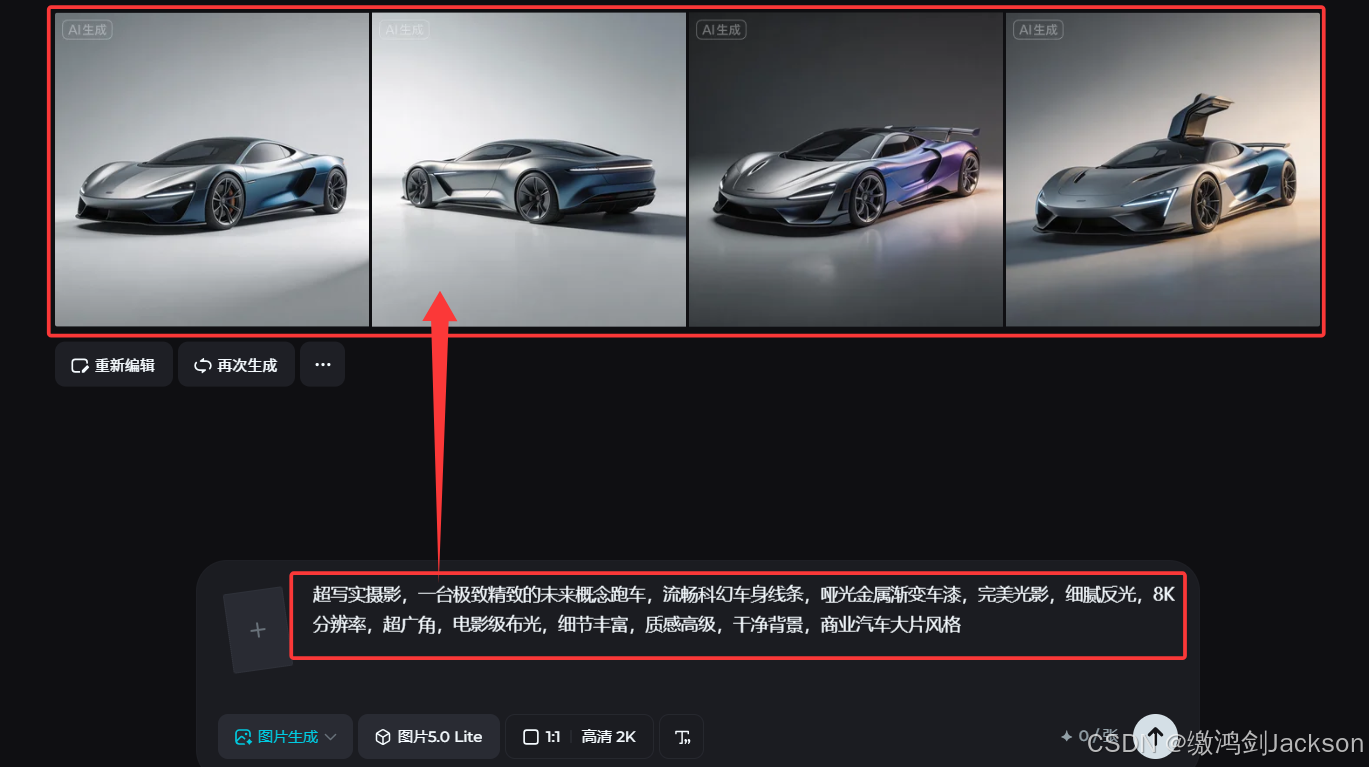
3.局限性
让AI生成的提示词,想要的图片质量很高,但是类型、细节啥的不可能100%符合我们心中所想。
三.提示词万能框架
【二】中的方法,不一定是我们想要的,但是我们自己按照这个框架编写,肯定是我们想要的。

四.案例
输入以下提示词:
肯豆风,现代化,专业摄影风格,正面视角,一个穿黑丝、高跟鞋、黑色上衣、黑长发、皮肤白皙、腿长、头冲着摄影师且躺着、腿交叉搭载凳子上的专业中国女模特,白色摄像棚背景,专业摄像设备,专业构图,现代质感,8K,大师级构图

可见此时效果的确不错