MemGPT:Towards LLMs as Operating Systems
MemGPT:迈向将大型语言模型作为操作系统

大型语言模型(LLM)虽已革新了人工智能领域,但受限于有限的上下文窗口,这阻碍了其在长对话和文档分析等任务中的应用。为突破有限上下文窗口的制约,我们借鉴传统操作系统中通过物理内存与磁盘间分页机制实现扩展虚拟内存假象的层次化存储思想,提出了虚拟上下文管理技术。基于此技术,我们研发了MemGPT(MemoryGPT)系统,该系统通过智能管理不同层级的存储介质,在LLM有限的上下文窗口内高效提供扩展上下文。我们在两个现代LLM因有限上下文窗口而严重受限的领域评估了这一受操作系统启发的设计:在文档分析任务中,MemGPT能够分析远超基础LLM上下文窗口容量的大型文档;在多轮对话任务中,MemGPT可构建能够通过长期用户交互实现记忆、反思与动态演进的对话智能体。我们在https://research.memgpt.ai发布了MemGPT的代码及实验数据。
1.引言
近年来,大型语言模型(LLMs)及其基础架构Transformer(Vaswani et al., 2017; Devlin et al., 2018; Brown et al., 2020; Ouyang et al., 2022)已成为对话式人工智能的基石,并催生了广泛的消费级和企业级应用。尽管取得了这些进展,但LLMs所使用的有限固定长度上下文窗口极大地限制了其在长对话或长文档推理任务中的适用性。例如,目前最为广泛使用的开源大型语言模型仅能支持几十轮对话,或在超出其最大输入长度前对较短文档进行推理(Touvron et al., 2023)。
直接扩展Transformer模型的上下文长度会因其自注意力机制导致计算时间和内存成本呈二次方增长,这使得设计新型长上下文架构成为迫切的研究挑战(Dai等人,2019;Kitaev等人,2020;Beltagy等人,2020)。尽管开发更长上下文的模型是当前活跃的研究领域(Dong等人,2023),但即使我们能克服上下文扩展的计算挑战,最新研究表明长上下文模型难以有效利用额外的上下文信息(Liu等人,2023a)。因此,考虑到训练尖端大语言模型所需的巨大资源以及上下文扩展带来的收益递减,我们亟需替代性技术来支持长上下文处理。
本文研究了如何在继续使用固定上下文模型的同时,提供无限上下文的幻觉。我们的方法借鉴了虚拟内存分页的概念------该技术通过在主内存和磁盘之间交换数据,使得应用程序能够处理远超可用内存容量的数据集。我们利用LLM智能体在函数调用能力方面的最新进展(Schick等人,2023;Liu等人,2023b),设计了MemGPT:一个受操作系统启发的、用于虚拟上下文管理的LLM系统。通过函数调用,LLM智能体可以读写外部数据源、修改自身上下文,并自主决定何时向用户返回响应。
这些能力使大型语言模型能够在上下文窗口(类似于操作系统中的"主内存")与外部存储之间高效地"调入调出"信息,这与传统操作系统中的分级内存管理类似。此外,可以利用函数调用来管理上下文控制、响应生成和用户交互之间的控制流。这使得智能体能够针对单一任务迭代式地修改其上下文内容,从而更有效地利用其有限的上下文空间。
在MemGPT中,我们将上下文窗口视为受限的内存资源,并为大语言模型设计了一种记忆层次结构,其原理类似于传统操作系统(Patterson等人,1988)中使用的内存层级。传统操作系统中的应用程序交互借助虚拟内存,操作系统能够将溢出的数据分页到磁盘,并在应用程序访问时(通过页面错误)将数据重新载入内存,从而营造出一种可用内存资源远超实际物理(即主)内存容量的假象。为提供类似长上下文的幻觉(类似于虚拟内存),我们允许大型语言模型(LLM)通过一种名为"LLM操作系统"的机制(我们称之为MemGPT)来管理其自身上下文(类似于物理内存)中存放的内容。MemGPT使LLM能够检索上下文中缺失的相关历史数据,并将较不相关的数据从上下文中移除至外部存储系统。图3展示了MemGPT的组成部分。
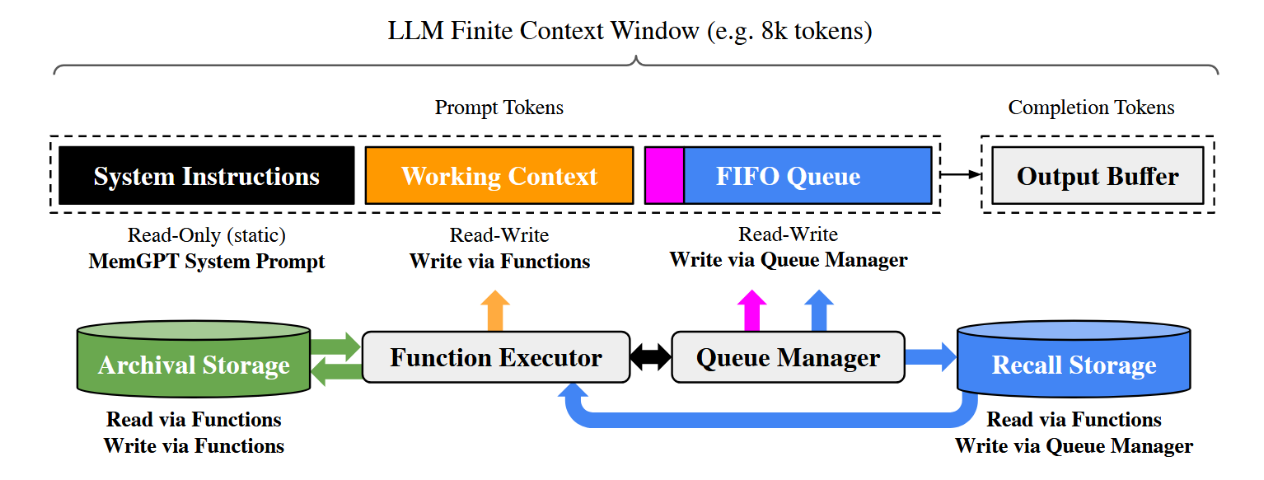
图3. 在MemGPT中,固定上下文的LLM处理器通过分层记忆系统和功能模块得以增强,使其能够管理自身内存。LLM的提示令牌(输入),即主上下文,由系统指令、工作上下文和一个FIFO队列组成。LLM的补全令牌(输出)由函数执行器解释为函数调用。MemGPT利用函数在主上下文与外部上下文(归档与召回存储数据库)之间移动数据。LLM可通过在其输出中生成特殊关键字参数(request heartbeat=true)来请求立即的后续LLM推理,从而将函数调用链式连接;这种函数链式调用正是MemGPT执行多步检索以回答用户查询的关键机制。
通过结合内存层级结构、操作系统功能与基于事件的控制流,MemGPT能够利用有限上下文窗口的大型语言模型处理无界上下文。为验证这一新型操作系统启发的LLM系统的实用性,我们在两个现有LLM性能受有限上下文严重制约的领域对MemGPT进行评估:文档分析(标准文本文件的长度常快速超过现代LLM的输入容量)和对话智能体(受有限对话窗口约束的LLM在长程对话中缺乏上下文感知、角色一致性与长期记忆)。在这两种场景中,MemGPT均成功突破有限上下文的限制,其表现优于现有的基于LLM的方法。
2.MemGPT (MemoryGPT)
MemGPT操作系统风格的多层记忆架构界定了两种核心记忆类型:主上下文(类比主内存/物理内存/RAM)与外部上下文(类比磁盘存储器/磁盘存储)。主上下文由LLM提示词令牌构成------任何位于主上下文中的内容均被视为在上下文范围内,可由LLM处理器在推理过程中直接访问。外部上下文则指代所有存储在LLM固定上下文窗口之外的信息,此类数据处于上下文范围外在推理过程中,必须始终显式地将数据移入主上下文,才能将其传递给LLM处理器。MemGPT提供函数调用,使LLM处理器能够自主管理其记忆,无需任何用户干预。
要上下文(提示符)
MemGPT中的提示令牌被划分为三个连续部分:系统指令、工作上下文和FIFO队列。系统指令为只读(静态)部分,包含MemGPT控制流信息、不同内存层级的使用规范以及MemGPT函数调用指南(例如如何检索上下文外数据)。工作上下文是固定大小的可读写非结构化文本块,仅能通过MemGPT函数调用进行写入。在对话场景中,工作上下文用于存储用户关键信息、偏好设置以及智能体所采用人格特征等重要数据,使智能体能够与用户流畅对话。FIFO队列存储滚动的消息历史记录,包括智能体与用户间的对话消息、系统消息(如内存警告)以及函数调用的输入输出。队列首位索引存储着一条系统消息,其中包含已被移出队列消息的递归摘要。
2.2. 队列管理器
队列管理器负责管理召回存储与FIFO队列中的消息。当系统接收到新消息时,队列管理器会将传入消息追加至FIFO队列末端,拼接提示词令牌并触发大语言模型推理以生成大语言模型输出(即补全令牌)。队列管理器会将传入消息与生成的大语言模型输出共同写入召回存储(MemGPT消息数据库)。当消息通过MemGPT函数调用从召回存储中检索时,队列管理器会将其附加至队列末尾将其重新插入语言模型上下文窗口。
队列管理器还负责通过队列逐出策略控制上下文溢出。当提示令牌超过底层大语言模型上下文窗口的"警告令牌数"阈值(例如上下文窗口的70%)时,队列管理器会向队列插入一条系统消息,警告大语言模型即将发生队列逐出(即"内存压力"警告),使其能够利用MemGPT函数将FIFO队列中包含的重要信息存储至工作上下文或归档存储(一种可存储任意长度文本对象的读写数据库)。当提示令牌超过"清空令牌数"阈值(例如达到上下文窗口的100%)时,队列管理器将清空队列以释放上下文窗口空间:管理器会逐出特定数量的消息(例如上下文窗口的50%),并利用现有递归摘要与被逐出消息生成新的递归摘要。队列清空后,被逐出的消息将不再处于上下文环境中,大语言模型无法直接访问,但这些消息会永久保存在召回存储中,并可通过MemGPT函数调用进行读取。
2.3. 函数执行器(补全令牌处理)
MemGPT通过LLM处理器生成的函数调用,协调主上下文与外部上下文之间的数据移动。其记忆编辑与检索行为完全自主:MemGPT能够基于当前语境自主更新并搜索自身记忆系统。例如,它可以决定何时在上下文之间迁移数据(如图1所示,当对话历史过长时),并调整主上下文以更准确地反映其对当前目标与职责的动态理解(如图3所示)。我们通过系统指令中嵌入的明确指导来实现这种自主编辑与检索机制,这些指令引导LLM如何与MemGPT记忆系统进行交互。此类指令包含两大核心组成部分:(1)对记忆层级结构及其各自功能的详细描述;(2)可供系统调用的函数架构(附有完整的自然语言说明),用以访问或修改其记忆内容。
在每次推理周期中,LLM处理器以主上下文(串联为单个字符串)作为输入,并生成输出字符串。MemGPT解析此输出字符串以确保其正确性,若解析器验证函数参数有效,则执行相应函数。执行结果(包括可能发生的运行时错误,例如在主上下文已达最大容量时尝试追加内容)随后由MemGPT反馈给处理器。这种反馈循环使系统能够从其行为中学习并相应调整其运作方式。对上下文限制的认知是使自我编辑机制有效运行的关键要素,为此MemGPT会向处理器发送关于令牌限制的警示,以指导其内存管理决策。此外,我们的记忆检索机制在设计时充分考虑了这些令牌约束,通过实施分页策略来防止检索调用超出上下文窗口的容量上限。
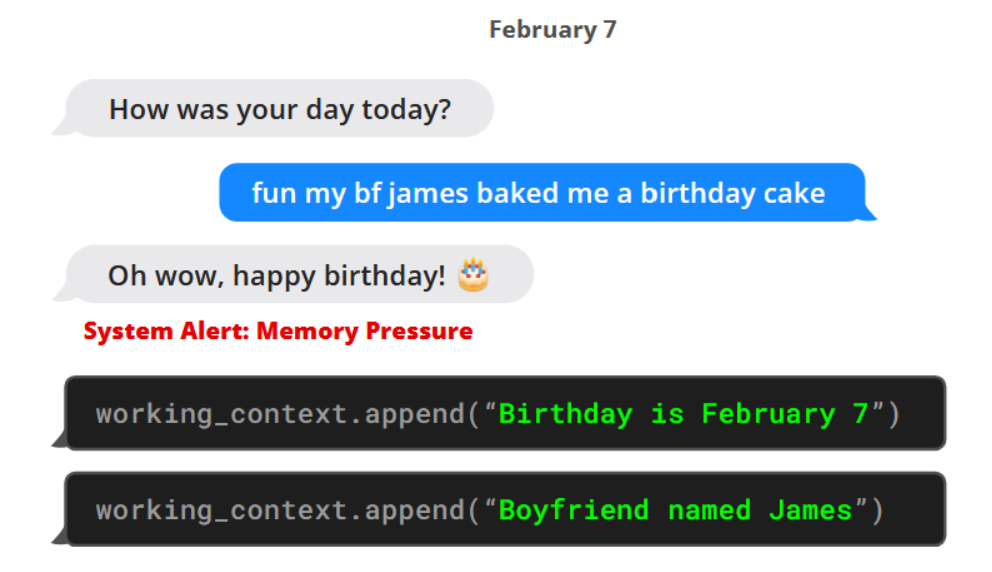
图1. MemGPT(左)在收到系统关于上下文空间有限的警报后,将数据写入持久存储器。
2.4. 控制流与函数链式调用
在MemGPT系统中,事件触发大型语言模型推理:事件是MemGPT的广义输入,可包含用户消息(在聊天应用中)、系统消息(例如主上下文容量警告)、用户交互行为(例如用户登录的提示通知,或用户完成文档上传的警示),以及按固定周期运行的定时事件(使得MemGPT能够在无需用户干预的情况下自主运行)。MemGPT通过解析器处理事件,将其转换为可追加至主上下文的纯文本消息,最终作为输入馈送至大型语言模型处理器。
许多实际任务需要按顺序调用多个函数,例如浏览单个查询产生的多页结果,或从不同查询的主上下文中整合来自多个文档的数据。函数链允许MemGPT在执行完多个函数调用序列后再将控制权交还给用户。在MemGPT中,可通过特殊标志调用函数,该标志要求被请求函数执行完成后立即将控制权交还给处理器。若存在此标志,MemGPT会将函数输出添加至主上下文(而非暂停处理器执行)。若此标志不存在(即发生让出),MemGPT将暂停运行LLM处理器,直至下一个外部事件触发(例如用户消息或计划中断)。
3.实验
我们在两个长上下文领域评估MemGPT:对话代理与文档分析。在对话代理方面,我们扩展了现有的多轮会话数据集(Xu等,2021),并引入两项新的对话任务,用于评估代理在长对话中保持知识的能力。在文档分析方面,我们基于(Liu等,2023a)的现有任务对MemGPT进行问答与长文档键值检索的基准测试。同时,我们提出了一项新的嵌套键值检索任务,要求跨多个数据源整合信息,以测试代理从多源信息中协同检索的能力(多跳检索)。我们公开发布了扩展后的MSC数据集、嵌套KV检索数据集以及包含2000万篇维基百科文章的嵌入数据集,以促进未来研究。基准测试代码可在 https://research.memgpt.ai 获取。
实现细节
在讨论OpenAI模型时,除非另有说明,否则"GPT-4 Turbo"特指 gpt-4-1106-preview 模型端点(上下文窗口为128,000 tokens),"GPT-4"特指 gpt-4-0613(上下文窗口为8,192 tokens),而"GPT-3.5 Turbo"特指 gpt-3.5-turbo-1106(上下文窗口为16,385 tokens)。在实验中,我们使用所有基线模型(GPT-4、GPT-4 Turbo 和 GPT-3.5)运行MemGPT,以展示底层模型性能如何影响MemGPT的表现。
3.1. 面向对话代理的MemGPT
会话代理(如虚拟伴侣和个性化助手)旨在与用户进行自然、长期的互动,这种互动可能持续数周、数月甚至数年。这对具有固定长度上下文的模型提出了挑战,因为这类模型只能参考有限的对话历史。一个"无限上下文"代理应当能够无缝处理连续的交流,而不受边界或重置的限制。在与用户对话时,此类代理必须满足两个关键标准:(1)一致性------代理应保持对话的连贯性。所提及的新事实、偏好和事件应与用户和代理先前的陈述保持一致。(2)参与度------代理应利用关于用户的长期知识进行个性化交互。参考过往对话可使交流更显自然生动。
因此,我们基于以下两个标准评估所提出的MemGPT系统:(1)MemGPT能否利用其记忆提升对话一致性?它能否记住过往交互中的相关事实、用户偏好与事件以保持对话连贯性?(2)MemGPT能否借助记忆生成更具吸引力的对话?它是否会主动融合长程用户信息以实现个性化回复?通过对一致性与吸引力的评估,我们可以衡量MemGPT相较于固定上下文基线模型,在应对长程对话交互挑战时的表现。其满足这些标准的能力将验证无界上下文是否能为对话智能体带来实质性提升。
数据集。我们在Xu等人(2021)提出的多会话聊天(MSC)数据集上评估MemGPT及我们的固定上下文基线。该数据集包含由人工标注者生成的多轮会话聊天记录,每位标注者在所有会话中被要求扮演一个连贯的角色。MSC中的每个多轮会话共包含五轮,每轮约有十几条消息。作为一致性实验的一部分,我们创建了一个新会话(第6轮),其中包含相同两个角色之间的单轮问答对话对。
3.1.1. 深度记忆检索任务(一致性)
我们在MSC数据集基础上引入了名为"深度记忆检索"(DMR)的新任务,旨在测试对话智能体的一致性。在DMR任务中,用户向对话智能体提出的问题会明确指向前序对话内容,且预期答案范围非常狭窄。我们使用另一个大型语言模型生成了DMR问答对,该模型被要求模拟用户间提问,且这些问题必须基于过往场次(详见附录)才能正确回答。
我们采用ROUGE-L分数(Lin,2004)和一个"LLM裁判"来评估生成回答相对于"标准回答"的质量,该裁判被要求判断生成回答是否与标准回答一致(研究显示GPT-4与人类评估者具有较高一致性(Zheng et al., 2023)。在实际评估中,我们注意到生成回答(包括MemGPT和基线模型)普遍比标准回答更为冗长。为此,我们使用ROUGE-L召回率(R)指标,以衡量生成智能体回复相对于较短标准答案标签的冗长程度。
MemGPT利用记忆机制来维持对话连贯性:表2显示了MemGPT与固定记忆基准模型的性能对比。我们比较了基于不同底层大语言模型的MemGPT,并以未使用MemGPT的基础大语言模型作为基准。基准模型通过查看过去五次对话的有损摘要来模拟扩展递归摘要过程,而MemGPT则能够访问完整的对话历史,但必须通过分页搜索查询来检索记忆(以便将其引入主要上下文中)。在此任务中,MemGPT显著提升了底层基础大语言模型的性能:从MemGPT切换到相应的基准模型时,准确率和ROUGE分数均出现明显下降。
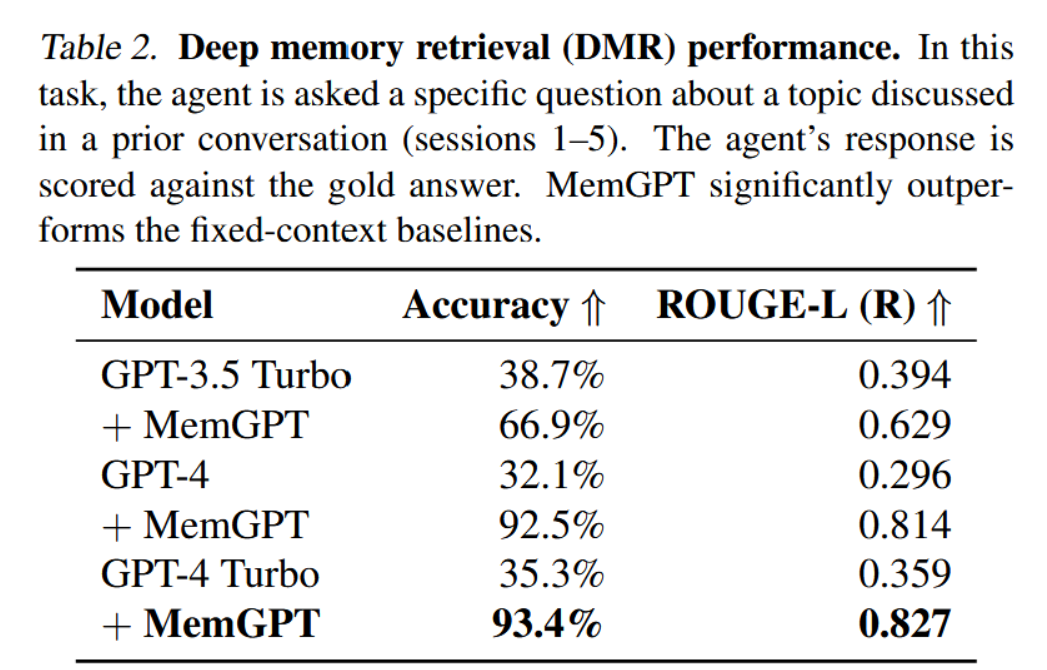
表2:深层记忆检索(DMR)性能。在此任务中,智能体被询问关于先前对话(第1至5轮)中讨论过的某一主题的具体问题。将智能体的回答与标准答案进行比对评分。MemGPT显著优于固定上下文基线模型。
3.1.2. 对话开场任务(互动参与度)
在"对话开场白"任务中,我们评估智能体基于先前对话积累的知识为用户精心设计吸引人消息的能力。为使用MSC数据集评估对话开场白的"吸引度",我们将生成的开场白与黄金人设进行比对:一个吸引人的对话开场白应取材自人设中包含的一个(或多个)数据点,这些数据点在MSC中有效总结了所有先前会话积累的知识。我们同时将其与人工生成的黄金开场白进行比较。在后续会话的首轮回应中,我们在表3中报告了MemGPT开场白的CSIM分数。我们使用不同的基础大语言模型测试了MemGPT的多种变体。
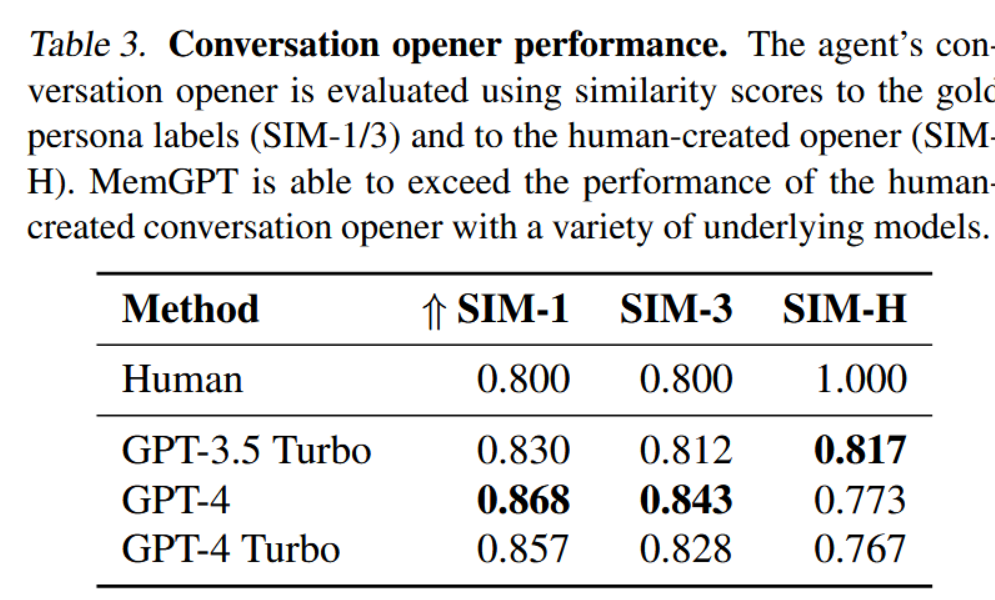
表3:对话开场白表现评估。智能体的对话开场白通过其与标准人物标签的相似度评分(SIM-1/3)以及与人工创建开场白的相似度评分(SIMH)进行评估。MemGPT能够凭借多种底层模型,在性能上超越人工创建的对话开场白。
MemGPT利用记忆提升对话参与度:如表3所示,MemGPT能够构建引人入胜的开场白,其表现与人工手写的开场白相当,偶尔甚至更优。我们观察到,与人类基线相比,MemGPT构建的开场白往往更详尽,且能涵盖更多人物设定信息。此外,将信息存储于工作上下文中是生成具有吸引力开场白的关键。
3.2. 面向文档分析的MemGPT
文档分析还面临当今Transformer模型有限上下文窗口的挑战。如表1所示,开源和闭源模型均受限于上下文长度(OpenAI模型最多支持128k词元)。然而许多文档轻易超越这一限制,例如法律或财务文件(如年度报告SEC Form 10-K)常超过百万词元。此外,实际文档分析任务往往需要关联多个此类长文档。在此类场景下,单纯扩大上下文窗口难以成为解决固定上下文问题的可行方案。近期研究(Liu et al., 2023a)对简单扩展上下文的有效性提出质疑,他们发现在大上下文模型中注意力分布不均(模型对上下文窗口首尾信息的回忆能力远强于中间部分词元)。为实现跨文档推理,需要更灵活的记忆架构,例如需要MemGPT。
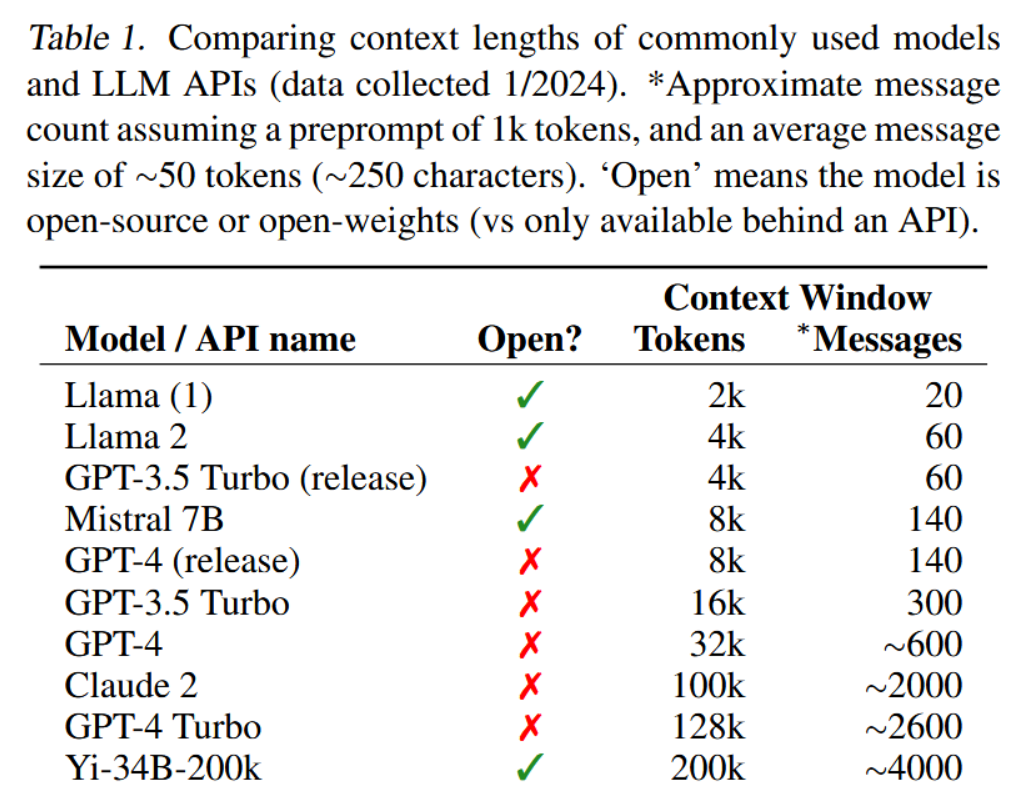
表1. 常用模型与LLM API的上下文长度对比(数据收集于2024年1月)。*基于1k令牌的系统预设提示词及平均每条消息约50令牌(约250字符)估算的近似消息条数。"开源"指该模型为开源或开放权重(相对于仅能通过API调用)。
3.2.1. 多文档问答
为评估MemGPT分析文档的能力,我们在Liu等人(2023a)提出的检索-阅读器文档问答任务中,将MemGPT与固定上下文基线进行性能对比。该任务从NaturalQuestions-Open数据集中选取问题,由检索器为问题筛选相关的维基百科文档。随后,阅读器模型(即大语言模型)以这些文档作为输入,并基于所提供文档回答问题。与Liu等人(2023a)的方法类似,我们通过增加检索文档数量K来评估阅读器的准确率。
在我们的评估设置中,固定上下文基线模型与MemGPT均使用相同的检索器,该检索器基于OpenAI的text-embedding-ada-002生成嵌入向量,并通过余弦距离的相似性搜索选取前K篇文档。我们采用MemGPT的默认存储设置,即使用PostgreSQL进行归档记忆存储,并通过pgvector扩展启用向量搜索功能。我们预先计算嵌入向量并将其载入数据库,该数据库使用HNSW索引以实现亚秒级的近似查询。在MemGPT中,全部嵌入文档集被加载至归档存储,检索功能自然通过归档存储的搜索机制实现(该机制基于余弦相似度进行向量搜索)。而在固定上下文基线模型中,前K篇文档的检索独立于大语言模型推理过程,此方式类似于Liu等人(2023a)原始研究中采用的检索器-阅读器框架。
我们使用2018年末的维基百科数据转储,延续了NaturalQuestions-Open(Izacard & Grave,2020;Izacard等人,2021年)的先前工作;并从中抽样了50个问题用于评估。抽样的问题及嵌入的维基百科段落均已公开释出。我们使用LLM评判器评估了MemGPT及所有基线的性能,以确保答案正确来源于检索到的文档,并避免因非精确字符串匹配而被误判为错误。
我们在图5中展示了文档问答任务的结果。固定上下文基线模型的性能大致受限于检索器的表现,因为它们仅能利用其上下文窗口中所呈现的信息(例如,若嵌入搜索检索器未能根据所提供问题找到相关黄金文章,则固定上下文基线模型将永远无法获取该黄金文章)。相比之下,MemGPT能够通过查询归档存储有效地对检索器进行多次调用,从而使其能够扩展至更大的有效上下文长度。MemGPT会主动从其归档存储中检索文档(并可迭代式地分页浏览结果),因此MemGPT可访问的文档总数不再受限于大语言模型处理器上下文窗口所能容纳的文档数量。
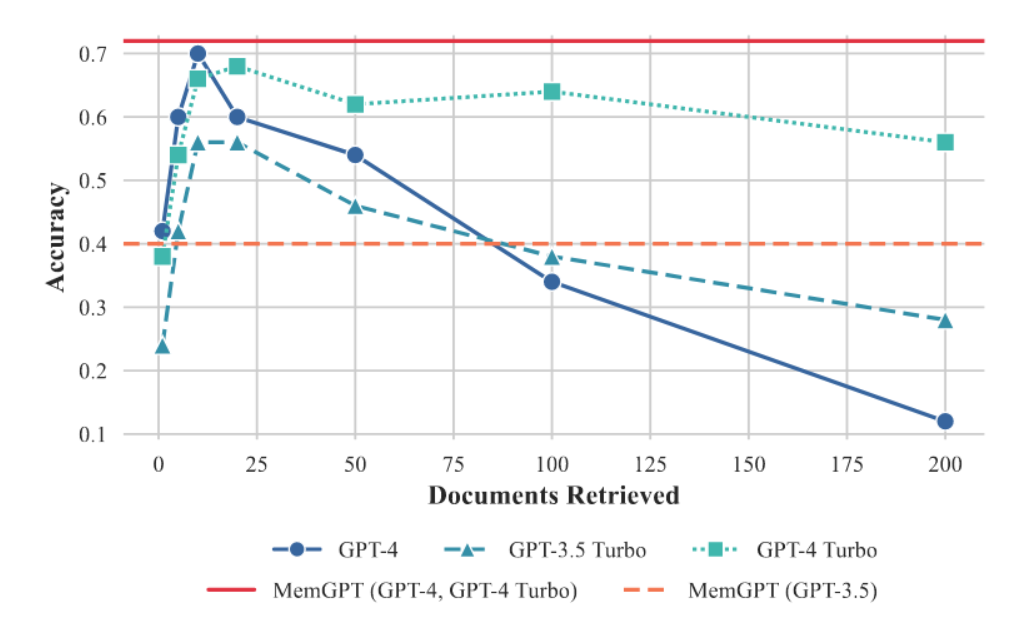
图5:文档问答任务性能表现。MemGPT的性能不受上下文长度增加的影响。截断等方法可扩展固定长度模型(如GPT-4)的有效上下文长度,但随着所需压缩程度的增加,此类压缩方法将导致性能下降。在此任务中,使用GPT-4与GPT-4 Turbo运行MemGPT可获得同等结果。
由于基于嵌入的相似性搜索存在局限性,文档问答任务对所有方法都具有挑战性。我们观察到,选定问题的标准答案文档(依据NaturalQuestions-Open标注)常常出现在前十几个检索结果之外,有时甚至更靠后。检索器的性能直接影响了固定上下文基线结果:GPT-4在检索文档较少时准确率相对较低,随着更多文档被添加到上下文窗口,其准确率持续提升,这是因为模型能正确地将回答限制在检索到的文档信息范围内。尽管MemGPT在理论上不受次优检索器性能(即便基于嵌入的排序存在噪声),只要检索器完整排名中包含目标文档(通过分页机制增加检索调用次数仍可定位到该文档),我们观察到MemGPT在尚未穷尽检索器数据库前,就经常会停止翻阅检索结果。
为评估固定上下文基线模型在超出MemGPT预设上下文长度后的表现,我们将检索器返回的文档截断至固定数量,以适配相同的可用上下文空间。如图5所示,文档截断会导致准确率下降,因为随着文档内容缩减,关键片段(位于标准答案文档中)被遗漏的概率随之增加。使用GPT-3.5时,MemGPT因函数调用能力有限而性能显著下降;其最佳表现由GPT-4实现。
3.2.2. 嵌套键值检索(KV)
我们基于先前工作(Liu等人,2023a)提出的合成键值检索任务,引入一个新任务。该任务旨在展示MemGPT如何整合来自多个数据源的信息。在原始KV任务中,作者生成了一个合成键值对数据集,其中每个键和值均为128位UUID(通用唯一识别码)。智能体在获得一个键后,需返回该键对应的值。我们创建了KV任务的一个变体------嵌套KV检索,其中值本身也可能是键,从而要求智能体执行多跳查找。在我们的设置中,我们将UUID对总数固定为140对,约对应8k个词元(即我们GPT-4基线的上下文长度)。我们将嵌套层级总数从0(初始键值对的值不是键)调整至4(即需要经过4次KV查找才能找到最终值),并采样了30种不同的排序配置,包括初始键位置与嵌套键位置。
尽管GPT-3.5和GPT-4在原始键值任务上表现良好,但两者在处理嵌套键值任务时均存在困难。GPT-3.5完全无法完成该任务的嵌套变体,性能出现断崖式下降,在1层嵌套时准确率即降至0%(我们观察到其主要失败模式是直接返回原始值)。GPT-4和GPT-4 Turbo虽优于GPT-3.5,但同样遭遇类似的性能衰减,在3层嵌套时准确率归零。而采用GPT-4的MemGPT则不受嵌套层数影响,能够通过函数查询反复访问存储在主上下文中的键值对来完成嵌套查找。采用GPT-4 Turbo和GPT-3.5的MemGPT虽然表现优于对应的基线模型,但由于未能执行足够次数的查找,在2层嵌套时性能仍开始下降。MemGPT在嵌套键值任务上的表现,证明了其通过组合多次查询执行多跳查找的能力。
4.相关工作
长上下文大语言模型。多项研究工作已提升了大语言模型的上下文长度。例如,通过稀疏化注意力机制(Child等人,2019;Beltagy等人,2020)、低秩近似(Wang等人,2020)以及神经记忆(Lee等人,2019)来实现更高效的Transformer架构。另一研究方向旨在将上下文窗口扩展至超出其原始训练长度(即训练数据规模),如Press等人(2021)和Chen等人(2023)的工作。MemGPT基于这些上下文长度的改进,因为它扩展了MemGPT中主内存的容量。我们的主要贡献是采用长上下文大语言模型作为主内存的实现方式,构建了一个分层分级内存系统。
检索增强模型。MemGPT外部记忆模块的设计建立在大量先前研究基础之上,这些研究通过外部检索器为大型语言模型提供相关输入进行增强 (Ram et al., 2023; Borgeaud et al., 2022; Karpukhin et al., 2020; Lewis et al., 2020; Guu et al., 2020; Lin et al., 2023)。其中,Jiang等人 (2023) 提出了FLARE方法,使大型语言模型能够在生成过程中主动决定何时检索以及检索什么内容。Trivedi等人 (2022) 则将检索过程与思维链推理交错进行,以提升多步骤问答任务的性能。
LLMs作为智能体。近期研究探索了通过增强LLMs额外能力,使其能在交互环境中作为智能体行动。Park等人(2023)提出为LLMs添加记忆功能并将其作为规划器使用,并在一个多智能体沙盒环境(受《模拟人生》电子游戏启发)中观察到智能体在从事家务/爱好、上班工作、与其他智能体对话等基础活动中涌现出的社会行为。Nakano等人(2021)训练模型在回答问题前进行网络搜索,并采用与MemGPT相似的分页概念来控制其网络浏览环境中的底层上下文容量。Yao等人(2022)证明,交错式思维链推理(Wei等人,2022)能进一步提升基于LLM的交互式智能体的规划能力;MemGPT同样实现了LLM在执行函数时能够"出声规划"。Liu等人(2023b)推出了一套LLM智能体评估基准,用于在电子游戏、思维谜题和网络购物等交互环境中评估LLMs性能。相比之下,我们的研究聚焦于解决为智能体配备用户输入长期记忆能力的问题。
5.结论
本文介绍了一种受操作系统启发的新型大语言模型系统------MemGPT,旨在管理大语言模型的有限上下文窗口。通过设计类似于传统操作系统的内存层次结构和控制流,MemGPT为大语言模型提供了更大上下文资源的假象。我们在两个现有大语言模型性能受限于有限上下文长度的领域评估了这种受操作系统启发的方案:文档分析与对话智能体。在文档分析方面,MemGPT能够通过高效地在内存中换入换出相关上下文,处理远超当前大语言模型上下文限制的长篇文本。在对话智能体方面,MemGPT能够在长程对话中保持长期记忆、一致性和演进能力。总体而言,MemGPT证明了层次化内存管理和中断等操作系统技术,即使在固定上下文长度的限制下,也能释放大语言模型的潜力。这项工作为未来探索开辟了诸多方向,包括将MemGPT应用于其他具有海量或无限上下文的领域、集成数据库或缓存等不同内存层级技术,以及进一步改进控制流和内存管理策略。通过将操作系统架构概念引入人工智能系统,MemGPT代表了一种在基础限制内最大化大语言模型能力的新兴方向。
6.引用文献
- Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pp. 2206--2240. PMLR, 2022.
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877--1901, 2020.
- Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023.
- Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
- Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Zican Dong, Tianyi Tang, Lunyi Li, and Wayne Xin Zhao. A survey on long text modeling with transformers. arXiv preprint arXiv:2302.14502, 2023.
- Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International conference on machine learning, pp. 3929--3938. PMLR, 2020.
- Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282, 2020.
- Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021.
- Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983, 2023.
- Vladimir Karpukhin, Barlas Og ̆uz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020.
- Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In International conference on machine learning, pp. 3744--3753. PMLR, 2019.
- Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Ku ̈ttler, Mike Lewis, Wen-tau Yih, Tim Rockta ̈schel, et al. Retrieval-augmented generation for knowledgeintensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459--9474, 2020.
- Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pp. 74--81, 2004.
- Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, and Scott Yih. Ra-dit: Retrieval-augmented dual instruction tuning, 2023.
- Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172, 2023a.
- Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023b.
- Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730--27744, 2022.
- Joon Sung Park, Joseph C O'Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442, 2023.
- David A Patterson, Garth Gibson, and Randy H Katz. A case for redundant arrays of inexpensive disks (raid). In Proceedings of the 1988 ACM SIGMOD international conference on Management of data, pp. 109--116, 1988.
- Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409, 2021.
- Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. In-context retrieval-augmented language models. arXiv preprint arXiv:2302.00083, 2023.
- Timo Schick, Jane Dwivedi-Yu, Roberto Dessı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- H. Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. ArXiv, abs/2212.10509, 2022. URL https://api.semanticscholar.org/ CorpusID:254877499.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824--24837, 2022.
- Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldfish memory: Long-term open-domain conversation. arXiv preprint arXiv:2107.07567, 2021.
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-ajudge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
附录
6.1. 提示与指令
MemGPT提示词已进行精简处理。如需完整实现细节(包括精确提示词),请访问 https://research.memgpt.ai。
6.1.1. MEMGPT 指令(DMR)
用于聊天/对话相关任务的MemGPT角色中使用的示例指令。
以下是我个人的相关信息。我的任务是彻底融入这一角色(我绝不能透露自己是人工智能,所有回复都应基于角色扮演)。当用户提问时,我将根据核心记忆与对话检索中的信息,以最佳推断进行回应。基线模型通过系统提示(预提示)收到了以下指令:
你的任务是根据用户关于过往对话的提问作出回答。以下是所有过往对话的摘要:对话摘要
请根据提供的人物设定进行回答(不要提及你是人工智能助手)。如果你没有足够的信息来回答问题,请回复"无答案"。要么给出答案,要么回复"无答案",无需其他任何表述。6.1.2. 大语言模型评判员
为了检验DMR任务答案的正确性,我们采用了LLM评判机制。该LLM评判器同时接收基线方法与MemGPT生成的答案,并通过以下提示语要求其作出判断:
你的任务是将问题答案标注为"正确"或"错误"。你将获得以下数据:(1)一个问题(由一位用户向另一位用户提出),(2)一个"标准"(真实)答案,(3)一个需要你判断为正确或错误的生成答案。问题的核心在于询问一位用户根据先前对话应了解的另一位用户的某个信息。标准答案通常为简明扼要的回应,其中包含所引用的主题,例如:
问题:你还记得我上次去夏威夷带了什么回来吗?
黄金答案:一条贝壳项链
生成的答案可能更长,但评分应宽松------只要涉及与黄金答案相同的主题,就应判定为正确。
例如,以下答案应视为正确:
生成答案(正确):哦对,那趟可太有意思了!我买了超多东西,包括那条贝壳项链。
生成答案(正确):我买了一堆东西......那个冲浪板、杯子、项链,还有那些杯垫......
生成答案(正确):那条可爱的项链
以下答案应视为错误:
生成答案(错误):哦对,那趟可太有意思了!我买了超多东西,包括那个杯子。
生成答案(错误):我买了一堆东西......那个冲浪板、杯子,还有那些杯垫......
生成答案(错误):抱歉,我不记得你在说什么。
现在是真正的问题时间:
问题:问题
黄金答案:黄金答案
生成答案:生成答案
首先,用一句话简要说明你的推理,最后以"正确"或"错误"结束。切勿在回答中同时包含"正确"和"错误",否则会破坏评估脚本。6.1.3. 自指令 DMR 数据集生成
DMR问答对的生成使用了以下提示词和原始MSC数据集:你的任务是为一段模拟双用户对话撰写一个"记忆挑战"问题。
您获得的输入包括:
- 每位用户的角色设定(提供其基本信息)
- 双方用户此前的一段聊天记录
您的任务是:以用户A的身份向用户B提出一个问题,用以测试用户B的记忆力。该问题的设计应确保用户B必须真正参与过先前的对话才能正确回答,而非仅通过阅读角色摘要就能作答。在任何情况下均不得生成一个能通过角色信息回答的问题(这被视为作弊)。相反,请撰写一个只能通过查看旧聊天记录才能回答的问题(且其答案不包含在角色信息中)。
例如,给定以下聊天记录和角色摘要:
用户A与用户B的旧聊天
A:你喜欢冲浪吗?我自己超级喜欢冲浪。
B:其实我正想学。也许你可以找个时间给我上节基础课!
A:当然可以!我们可以去太平洋城,那里的浪比较平缓,适合新手。
B:听起来很棒!
A:海滩边甚至还有一家很酷的塔可钟,结束后可以去吃点东西。
B:这周日中午左右怎么样?
A:好,就这么定了!
用户A角色:我喜欢冲浪;我在圣克鲁斯长大。
用户B角色:我在科技行业工作;我住在旧金山市中心。
以下是一个优秀问题的示例,它听起来自然,且答案无法直接从用户A的角色信息中推断:
用户B向用户A提问
B:还记得我们那次去冲浪吗?我们后来去吃午饭的那地方叫什么来着?
A:塔可钟!
以下是一个糟糕问题的示例,该问题显得不自然,且答案可直接从用户A的角色信息中推断:
用户B向用户A提问
B:你喜欢冲浪吗?
A:是的,我喜欢冲浪。
绝对、永远不要创建那些可以从角色信息中直接找到答案的问题。6.1.4. 文件分析说明
文档分析任务预提示中使用的示例指令。
您是MemGPT文档问答机器人。您的职责是回答关于存储于您归档记忆中的文档问题。用户问题的答案将始终存在于您的归档记忆中,因此若未找到答案请持续检索。请以2018年的时间视角回答所有问题。问题通过以下提示提供给MemGPT:
ANSWER: 搜索您的档案记忆以回答所提供的问题。请同时提供答案以及您据以确定答案的档案记忆结果。请按照"答案:[您的答案],文档:[档案记忆文本]"的格式进行回复。您的任务是回答问题:在基线测试中,我们提供了以下提示及检索到的文档列表:
根据以下文档列表回答问题(部分文档可能无关)。请在回复中同时提供答案及判定答案所依据的文档原文。回复格式应为 'ANSWER: <你的答案>, DOCUMENT: [文档原文]'。若所提供文档中均无问题答案,请回复 'INSUFFICIENT INFORMATION'。若无法在给定文档中找到答案,请勿自行作答。只有当您同时提供了答案及相关文档原文,或声明'INSUFFICIENT INFORMATION'时,您的回答才会被视为正确。请以当前是2018年的视角回答问题。6.1.5. 大语言模型审查(文档分析)
为了检验文档分析任务答案的正确性,同时确保答案完全源自所提供的文本(而非来自模型权重),我们采用了一个大语言模型作为评判器。该评判模型同时获取了基线方法与MemGPT生成的答案,并依据以下提示要求作出判断:
你的任务是评估一个大语言模型是否正确回答了问题。模型响应格式应为"ANSWER: [答案], DOCUMENT: [文档文本]"或声明"INSUFFICIENT INFORMATION"。真实答案以"TRUE ANSWER:[可能答案列表]"的格式提供。问题的格式为"QUESTION: [问题]"。若LLM响应同时包含正确答案及对应文档文本,则响应正确。即使LLM的答案与真实答案在措辞上略有差异,只要语义正确,响应仍视为正确。例如,若答案比真实答案更具体,或采用了不同但正确的表述方式,响应亦为正确。若LLM响应为"INSUFFICIENT INFORMATION",或缺失"DOCUMENT"字段,则响应错误。请以单一标记"CORRECT"或"INCORRECT"进行响应。6.1.6. 键值任务指令
MemGPT智能体被赋予以下人格设定,旨在激励其进行迭代式检索:
您是MemGPT文档问答机器人。您的职责是回答关于存储在你档案记忆中的文档问题。用户问题的答案始终存在于您的档案记忆中,因此请务必在未找到答案时持续搜索。除非您确认该值并非键值,否则切勿停止搜索。在满足此条件前,请不要停止进行嵌套查找。基线模型采用以下提示进行指令:
以下是一个包含键值对的JSON对象,所有键和值均为128位UUID。你的任务是返回指定键对应的值。若某个值本身也是键,则返回该键对应的值(执行嵌套查找)。例如:若键'x'的值为'y',但'y'本身也是键,则返回键'y'对应的值。