单机多卡,多机多卡
- DP: Server + 若干 Worker,每个 Worker 都要保存完整的模型参数+激活值+优化器状态(动量+方差),最后计算梯度的时候各个 Worker 计算各自的梯度再往 Server 传递,并且由 Server 进行聚合以及分发
- DDP: Distributed Data Parallel,针对 DP 主 Server 的通信带宽瓶颈,因此采用如 Ring-All-Reduce,假设有 GPU 0~3 都作为 Worker,那么先通过 Reduce-Scatter,把总数据分为 3 份,各自计算 loss 的梯度为(A,B,C),然后按照如图顺序发送各部分
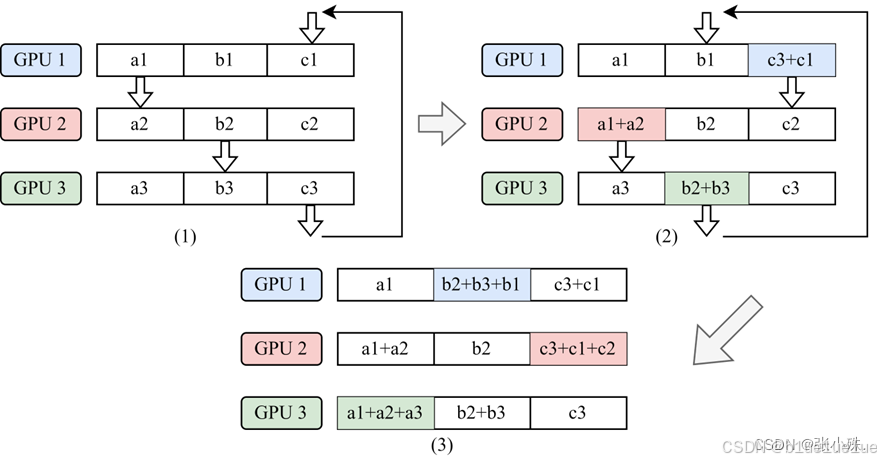 最后按照 All-Gather,每个工作节点将包含最终结果的块数据块交换, 这样所有的结点就会得到一个完整的结果
最后按照 All-Gather,每个工作节点将包含最终结果的块数据块交换, 这样所有的结点就会得到一个完整的结果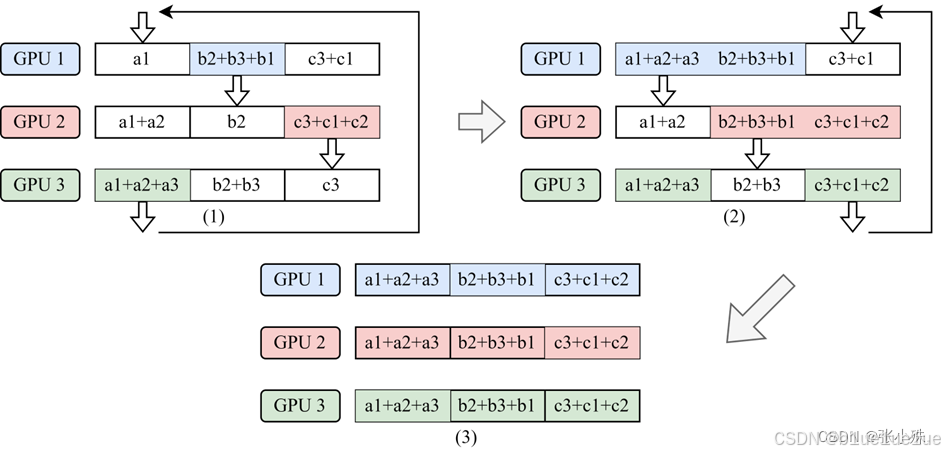
- FSDP:Fully Shared Distributed Parallel,针对 DDP,要求每张显卡始终得完整放下模型权重、优化器状态以及完整梯度,仅在最后算完梯度后,大家进行一次 Ring-All-Reduce,而 FSDP,他把 All-reduce 这个大动作也进行了拆分,任何一张卡在静态时刻,只保留 1/N 的权重和优化器状态,每个 Layer 进行前向传播的时候,会先通过 All-gather,临时凑齐这一 Layer 的权重进行计算,对激活值保存,而临时从别的节点拉取的这一 Layer 的权重则在算完之后立马把它丢掉,并且每张显存独立计算不同的数据,如 GPU0 算 "小明在上学",GPU1 算"今天天气不错",因此对于激活值同样不需要传递,在大规模训练(大 Batch Size)时,传递权重的开销反而比 TP 传递激活值 "划算"。
- TP:Tensor Parallel,张量并行,如 vllm,对于每一个 Layer 额外拆分为若干次核心计算 ,他会把矩阵乘法拆成小矩阵,每个矩阵直接计算对应的激活值再做 All-Reduce,而不会额外如 FSDP 一样先凑齐这一 Layer 的全部参数,因为涉及到频繁的 All-Reduce,因此对于通信的延迟要求会更高,因为后面每一次的计算都需要依赖上一步的结果,而 FSDP 因为预取(Prefetching,GPU 在计算第一层时,已经知道第二层需要哪些参数了,可以先后台拉取第二层参数),所以对延迟要求不高。
- PP: Pipeline Parallel,流水线并行,第一层参数全部给卡 A,第二层参数全部给卡 B,后面的激活值计算需要依赖前面的结果,会造成大量"气泡"(空闲等待),可以通过流水线并行方式增加利用率。


现代LLM 架构
- Rope:旋转位置编码,相比于传统位置编码把位置向量加到词嵌入上,他在计算自注意力时才会加上 Query 和 Key 的相对位置信息,此外 Rope 本质上等价于把 feature_dim 分成 feature_dim/2 组,然后每两个维度的 feature_dim 形成一个封闭的二维平面,按照相对位置以及 feature_dim 的 i 计算角度 θ 并旋转 ,768 个 feature_dim 分成 384 组,每组学习不同波长的相对位置信息 (低频)
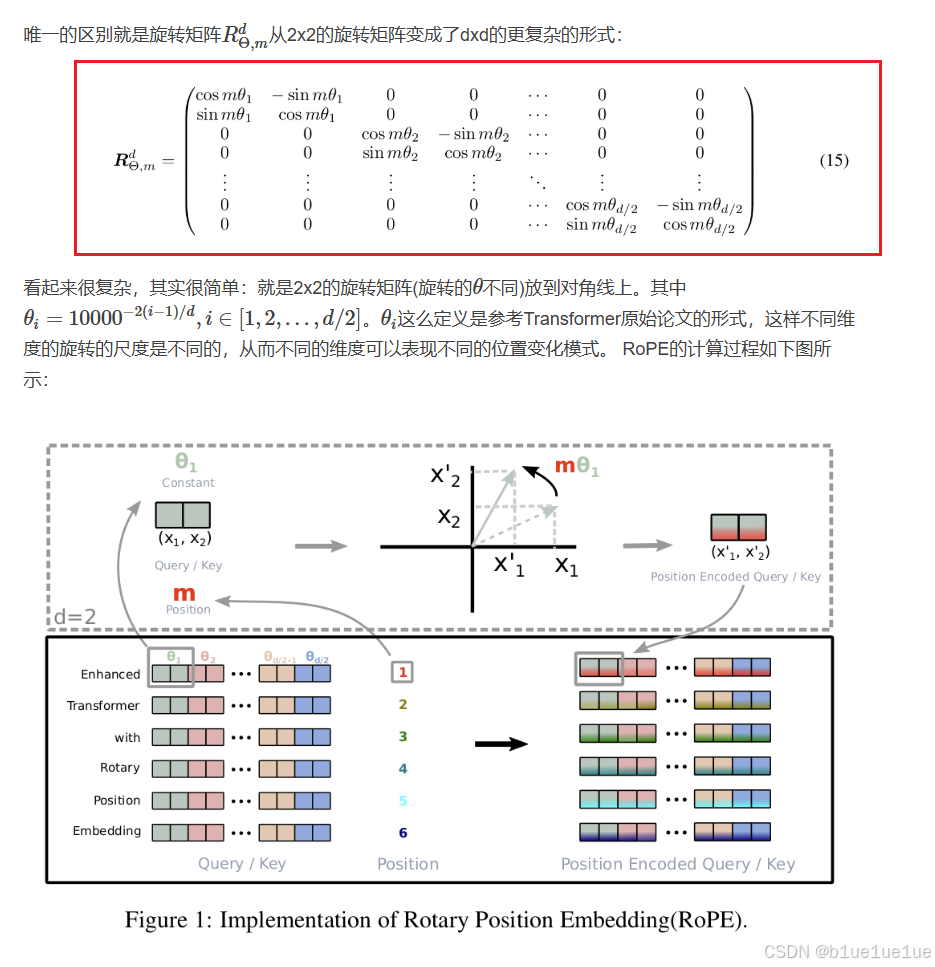
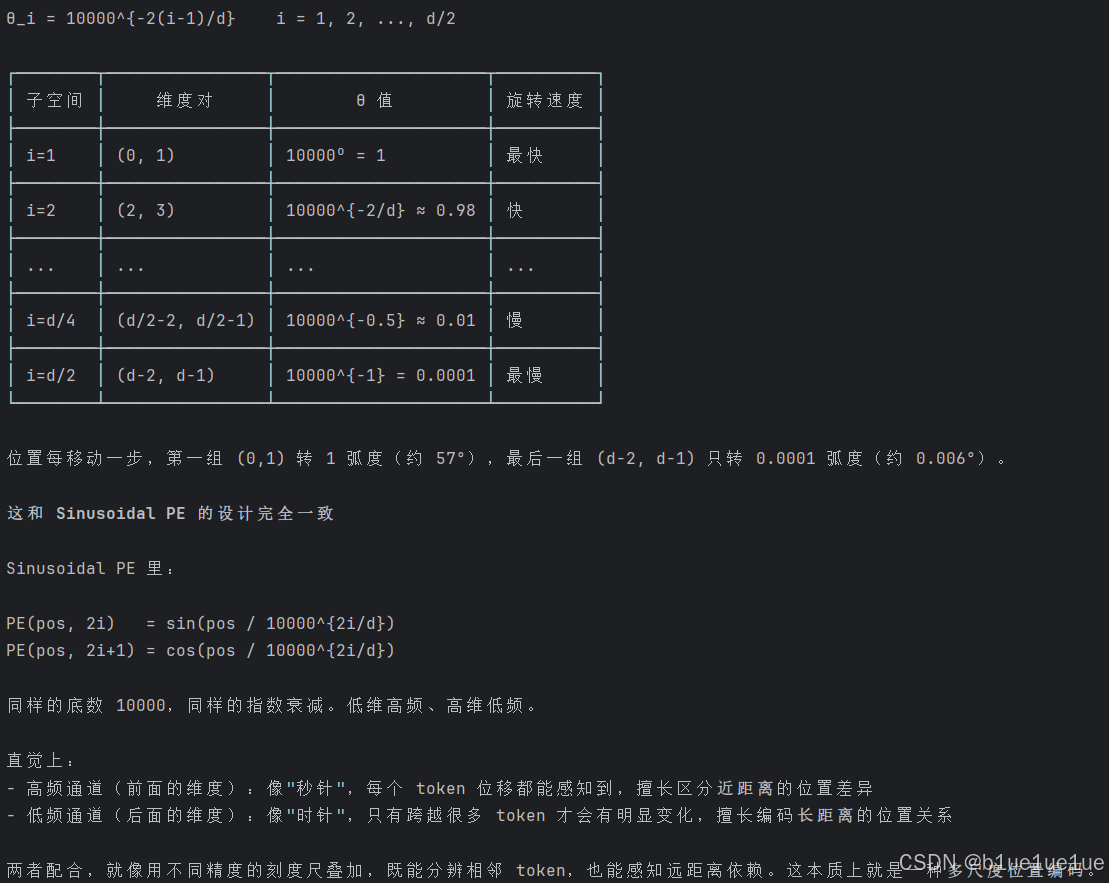
- RMSNorm+PreNorm:LayerNorm 在注意力计算完计算残差之后,x+1=LayerNorm(x+f(x)),需要归一化以保证激活值符合正态分布,但是大家在后来发现,模型并不在乎向量是不是以 0 为中心,只在乎它的"长度"不要爆炸(1. 前向传播时,每层输入的特征 x 稳定,2. 反向传播时梯度稳定),因此大家除以 RMS 均方根归一化即可; 此外在 LayerNorm+PostNorm 的组合里面,当前 layer 学到的 f(x)还需要经过归一化,第一层学习到的残差,经过 96layer 的归一化后其原始学习到的特征被扭曲,导致梯度衰减,因此使用 RMSNorm+PreNorm,x+1=x+f(PreNorm(x)),此时 f 函数本身学习到的特征不会被扭曲,然后引入的新问题是 x 激活值本身虽然越深层其值越大,因此梯度也越大,但是受 Adam 优化器本身自适应控制梯度与学习率关系,其梯度可控

- SwiGLU(Swish-Gated Linear Unit):两个通道,原始 X ,以及黄色的 SiLU ,前者是学习到的特征,后者是Swish 函数,的作用就像一个"门",根据输入信号的强弱,输出一个 0 到 1 权重,决定信息的"通过率",它的公式是 x*sigomid(x),相比 Relu 提供了更高级的开关控制。
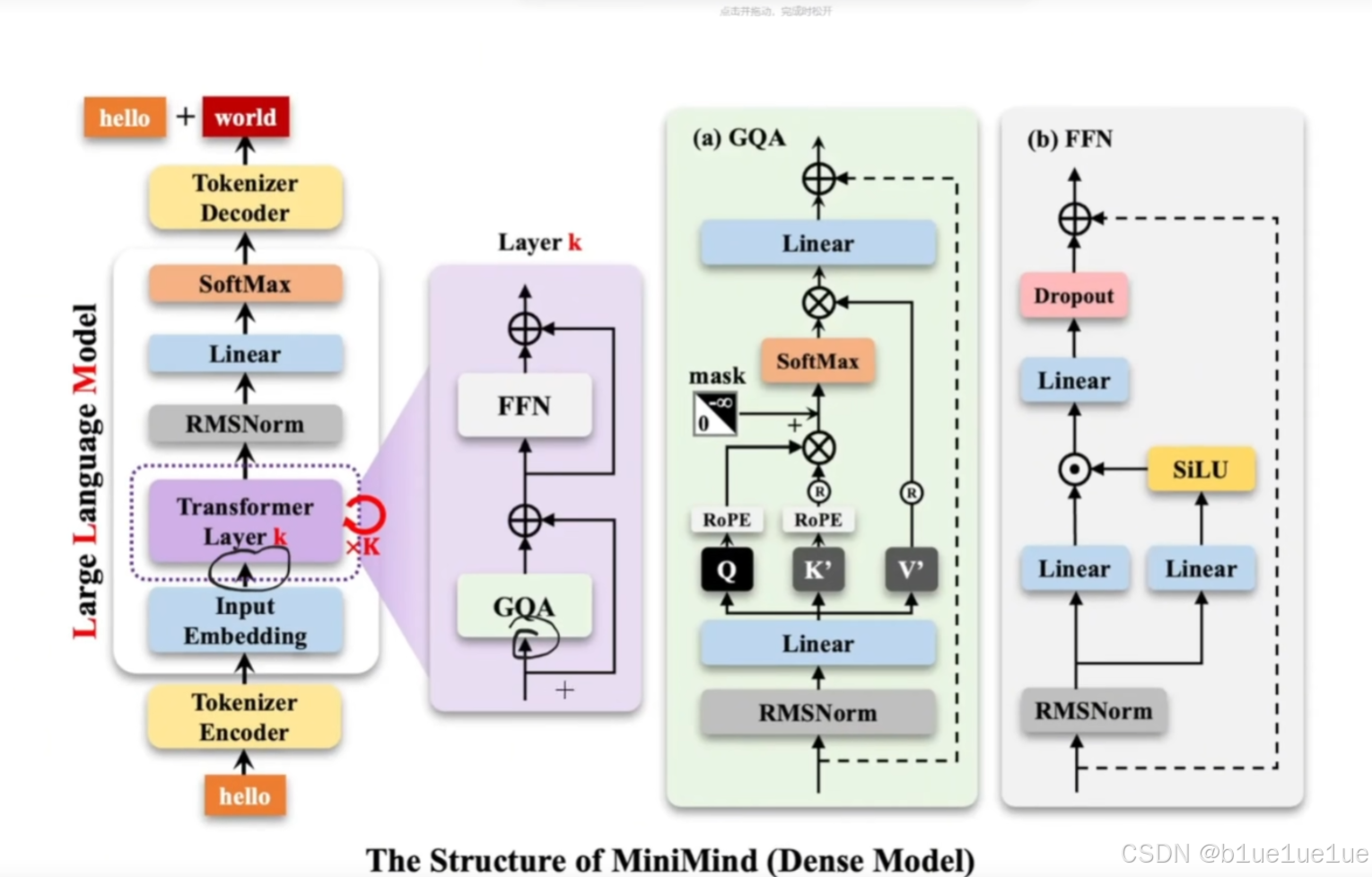
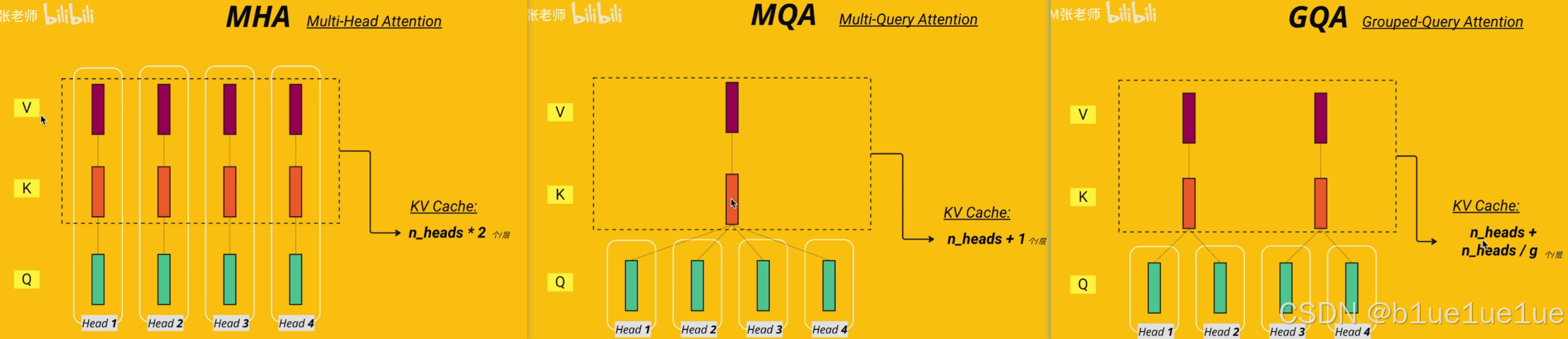
- 多头注意力: 主要针对 GQA,在 LLM 计算 Self Attention 时,KV Cache 复用,多个 Query (如4,8,16)作为一组 Group 共享 KV 头,节省缓存。
LLM 训练
- Mini Batch:LLM 训练输入一批 token,计算一批 loss,然而在 token 输入量较少时,计算的 loss 统计量不够,其噪声较大,而一次性并行计算 loss 时,增加单次处理的 token 数,其显存压力也大,因此采用 Mini Batch 的方式,每次统计一部分 Batch 的 梯度,然后若干次累加梯度,再一次性更新
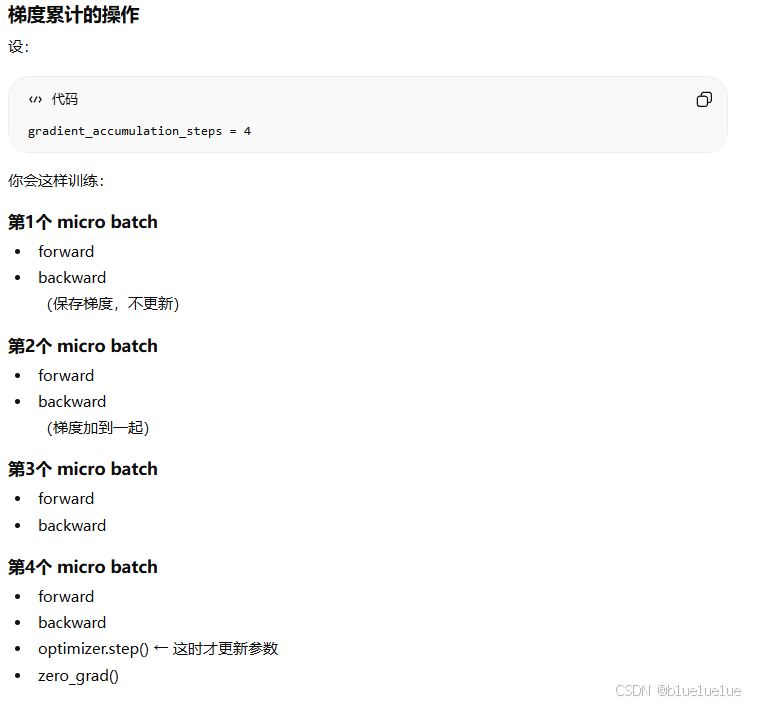
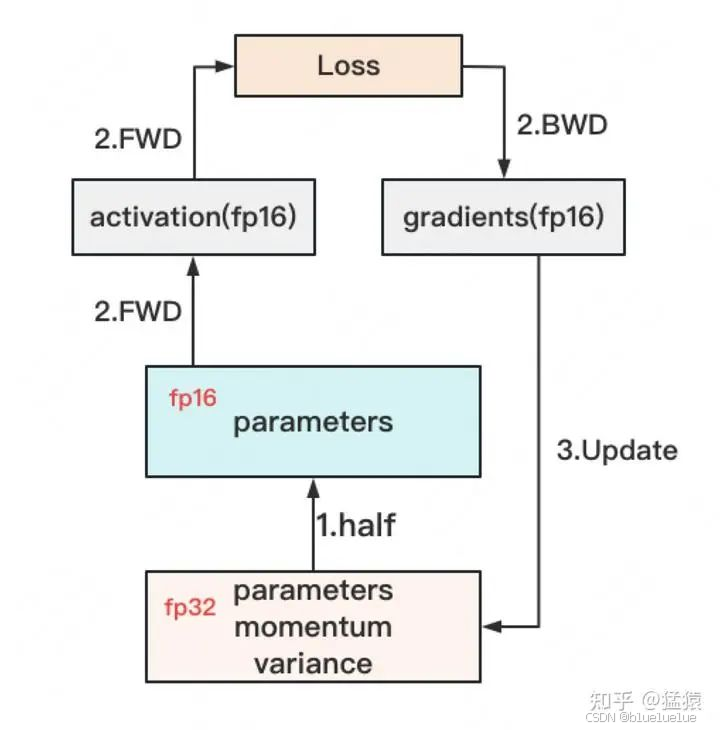
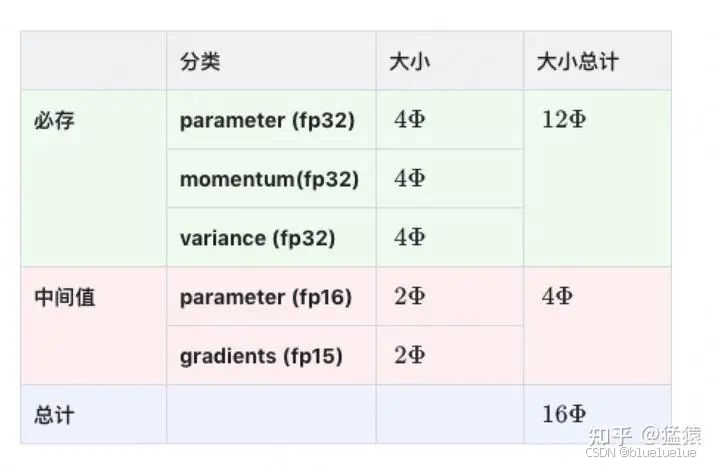
- Adam: 动量参数 β1 一般为 0.9,引入动量来考虑过去若干次更新时的梯度,自适应学习率参数 β2 一般为 0.99,引入均方差自适应调节学习率,在训练过程中优化器参数也要保存 动量以及方差

- 学习率余弦退火:Adam 的参数 alpha,前期学习率=1,后来慢慢衰减到0。

- 混合训练: