2.1 基于物品的协同过滤 (ItemCF)
2.1.1 ItemCF原理
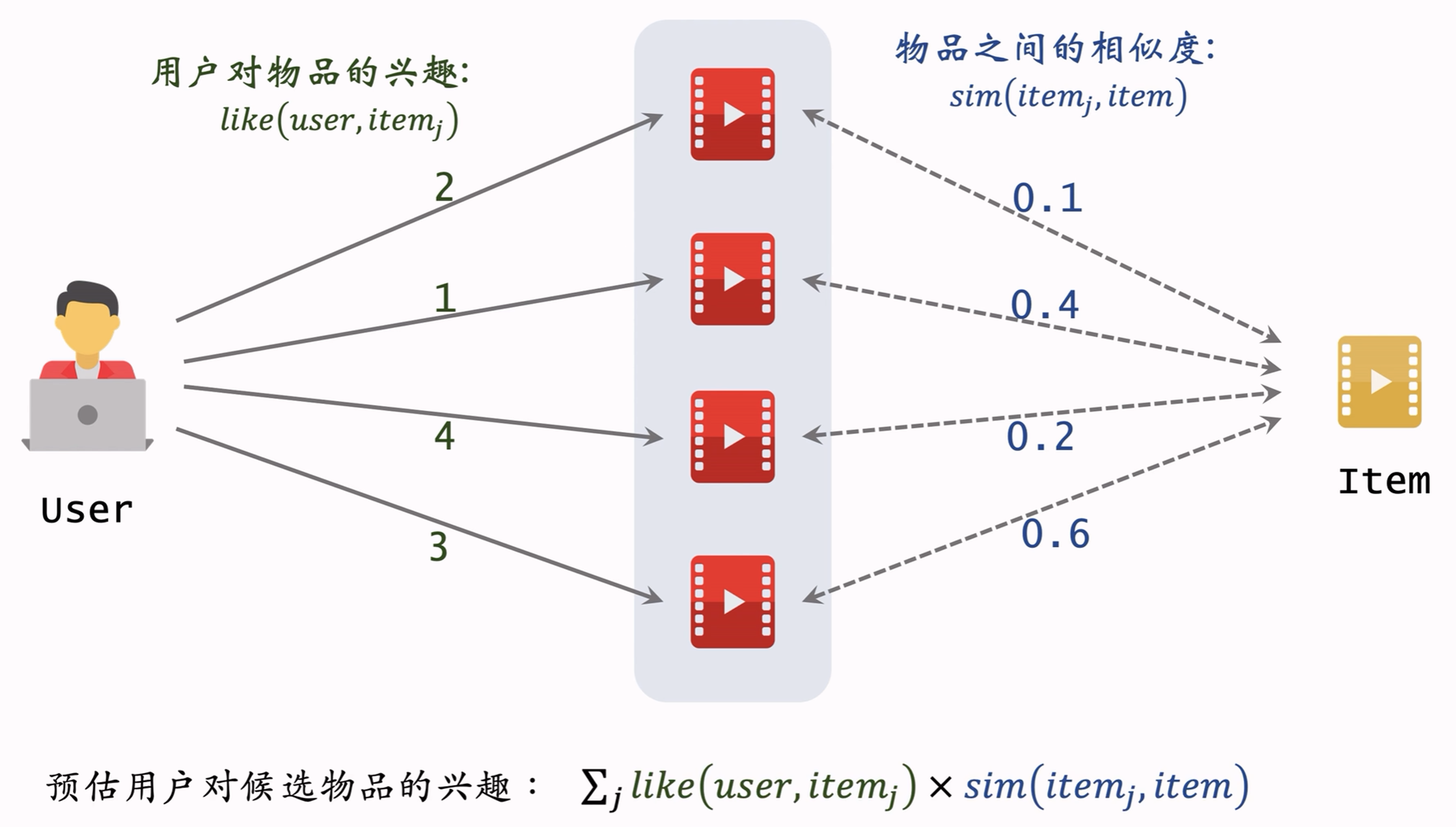
2.1.2 物品相似度
两个物品的受众重合度越高,两个物品越相似。
喜欢物品 i 1 i_1 i1的用户记作集合 W 1 W_1 W1,喜欢物品 i 2 i_2 i2的用户记作集合 W 2 W_2 W2,定义交集 V = W 1 ∩ W 2 V=W_1\cap W_2 V=W1∩W2。两个物品的相似度为:
sim ( i 1 , i 2 ) = ∣ V ∣ ∣ W 1 ∣ ⋅ ∣ W 2 ∣ \text{sim}(i_1,i_2)=\frac{|V|}{\sqrt{|W_1|\cdot|W_2|}} sim(i1,i2)=∣W1∣⋅∣W2∣ ∣V∣
该公式没有考虑用户喜欢物品的程度(只要喜欢就按1计算,只要不喜欢就按0计算) 。如果考虑用户的喜欢程度:
sim ( i 1 , i 2 ) = ∑ v ∈ V like ( v , i 1 ) ⋅ like ( v , i 2 ) ∑ u 1 ∈ W 1 like 2 ( u 1 , i 1 ) ⋅ ∑ u 2 ∈ W 2 like 2 ( u 2 , i 2 ) \text{sim}(i_1,i_2)=\frac{\sum_{v\in V} \text{like}(v,i_1)\cdot \text{like}(v,i_2)}{\sqrt{\sum_{u_1\in W_1} \text{like}^2(u_1,i_1)}\cdot\sqrt{\sum_{u_2\in W_2} \text{like}^2(u_2,i_2)}} sim(i1,i2)=∑u1∈W1like2(u1,i1) ⋅∑u2∈W2like2(u2,i2) ∑v∈Vlike(v,i1)⋅like(v,i2)
- 只有不喜欢物品时, like ( u , i ) = 0 \text{like}(u,i)=0 like(u,i)=0;
- 本质上是基于用户行为向量的余弦相似度。向量视角分析,对于物品 i 1 i_1 i1,构造一个向量: x i 1 = ( like ( u 1 , i 1 ) , ⋯ , like ( u n , i 1 ) x_{i_1}=(\text{like}(u_1,i_1),\cdots,\text{like}(u_n,i_1) xi1=(like(u1,i1),⋯,like(un,i1),同理构造 x i 2 = ( like ( u 1 , i 2 ) , ⋯ , like ( u n , i 2 ) x_{i_2}=(\text{like}(u_1,i_2),\cdots,\text{like}(u_n,i_2) xi2=(like(u1,i2),⋯,like(un,i2),这两个向量每一维代表一个用户。该公式等价于: cos ( θ ) = x i 1 x i 2 ∥ x i 1 ∥ ∥ x i 2 ∥ \cos(\theta)=\frac{x_{i_1}x_{i_2}}{\|x_{i_1}\|\|x_{i_2}\|} cos(θ)=∥xi1∥∥xi2∥xi1xi2;
- 直观上,该相似度在衡量两个物品在"用户偏好方向"上的夹角是否接近。
2.1.3 ItemCF流程
离线索引
索引的意义:避免枚举所有的物品,在离线部分承担计算压力。
- 建立用户→物品的索引:记录每个用户最近点击、交互过的物品ID,找到用户近期感兴趣的内容;
- 建立物品→物品的索引:计算物品之间的相似度,找到与该物品相似的k个物品(2.1.2节)。
在线召回
已有索引时,在线部分计算量被减小。
- 给定用户ID,通过用户→物品索引找到用户近期感兴趣的物品列表(last-n);
- 对于last-n列表中的每个物品,通过物品→物品索引找到top-k相似物品;
- 对于取回的nk个相似物品,用公式预估用户对物品的兴趣分数(2.1.1节);
- 返回分数最高的若干个物品,作为推荐结果。
2.2 Swing召回通道
ItemCF通过计算不同物体间喜爱的用户群体的重合程度计算物品相似度,但忽略了一种情况:重合的用户群体可能本身就是一个现实生活中互相认识互相熟悉的小圈子(有微信群、QQ群等,一个物品直接被分享到圈子中),此时不能通过本身属于同一个小圈子的用户集合来判断物品相似度。
Swing通过在计算物体相似度时对用户集合设定一个权重解决该问题。
用户 u 1 u_1 u1喜欢的物品记作 J 1 J_1 J1,用户 u 2 u_2 u2喜欢的物品记作集合 J 2 J_2 J2。
定义两个用户的重合度:
overlap ( u 1 , u 2 ) = ∣ J 1 ∩ J 2 ∣ \text{overlap}(u_1,u_2)=|J_1\cap J_2| overlap(u1,u2)=∣J1∩J2∣
用户 u 1 u_1 u1和 u 2 u_2 u2重合度高,则他们可能来自一个小圈子,需要降低他们的权重。
喜欢物品 i 1 i_1 i1的用户记作集合 W 1 W_1 W1,喜欢物品 i 2 i_2 i2的用户记作集合 W 2 W_2 W2。定义交集 V = W 1 ∩ W 2 V=W_1\cap W_2 V=W1∩W2。两个物品的相似度为:
sim ( i 1 , i 2 ) = ∑ u 1 ∈ V ∑ u 2 ∈ V = 1 α + overlap ( u 1 , u 2 ) 。 \text{sim}(i_1,i_2)=\sum_{u_1\in V}\sum_{u_2\in V} =\frac{1}{\alpha+\text{overlap}(u_1,u_2)}。 sim(i1,i2)=u1∈V∑u2∈V∑=α+overlap(u1,u2)1。
其中 α \alpha α是需要通过实验调节的参数。
2.3 基于用户的协同过滤 (UserCF)
UserCF观察其他与自己兴趣相似的用户感兴趣的笔记,若自己没看过这篇笔记,则会推荐给自己。
2.3.1 UserCF原理
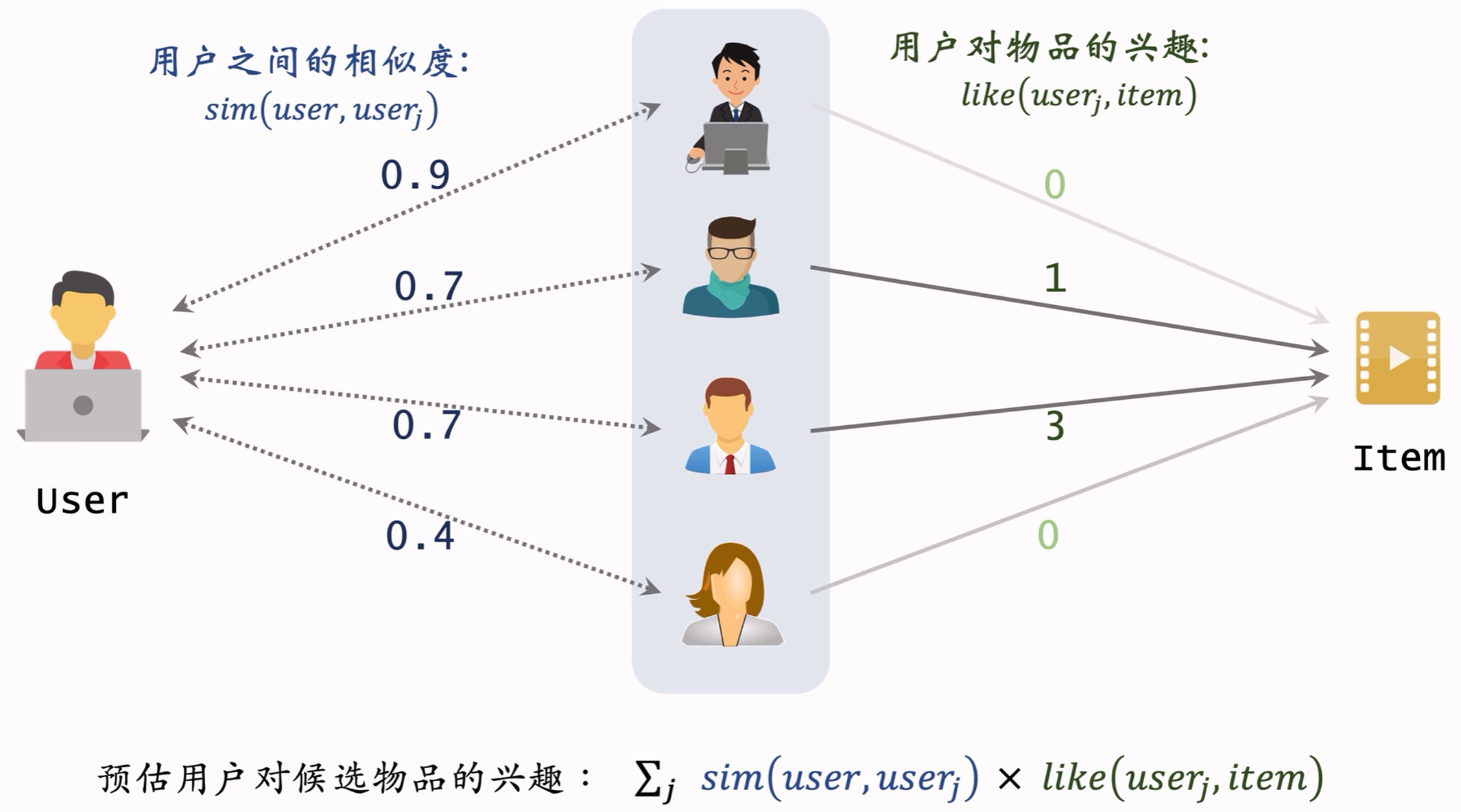
2.3.2 用户相似度
用户 u 1 u_1 u1喜欢的物品记作集合 J 1 J_1 J1;
用户 u 2 u_2 u2喜欢的物品记作集合 J 2 J_2 J2;
定义交集 I = J 1 ∩ J 2 I=J_1\cap J_2 I=J1∩J2;
定义两个用户的相似度:
sim ( u 1 , u 2 ) = ∣ I ∣ ∣ J 1 ∣ ⋅ ∣ J 2 ∣ \text{sim}(u_1,u_2)=\frac{|I|}{\sqrt{|J_1|\cdot|J_2|}} sim(u1,u2)=∣J1∣⋅∣J2∣ ∣I∣
该公式存在不足:若物品本身热门,本身便有大部分用户喜欢,对计算用户相似度价值不大;冷门物品更能体现出用户兴趣的差异性。
做法:降低热门物品的权重(喜欢的用户越多,越热门)。
改写相似度公式:
sim ( u 1 , u 2 ) = ∑ l ∈ I 1 log ( 1 + n l ) ∣ J 1 ∣ ⋅ ∣ J 2 ∣ \text{sim}(u_1,u_2)=\frac{\sum_{l\in I} \frac{1}{\log(1+n_l)}}{\sqrt{|J_1|\cdot|J_2|}} sim(u1,u2)=∣J1∣⋅∣J2∣ ∑l∈Ilog(1+nl)1
其中 n l n_l nl是喜欢物品 l l l的用户数量。
2.3.3 UserCF流程
离线索引
索引的意义:避免枚举所有的物品,在离线部分承担计算压力。
- 建立用户→物品的索引:记录每个用户最近点击、交互过的物品ID,找到用户近期感兴趣的内容;
- 建立用户→用户的索引(与ItemCF不同):计算用户之间的相似度,找到与该用户相似的k个用户(2.3.2节)。
在线召回
已有索引时,在线部分计算量被减小。
- 给定用户ID,通过用户→用户索引找到top-k相似用户;
- 对于top-k用户中的每个用户,通过用户→物品索引找到用户感兴趣的物品列表(last-n);
- 对于取回的nk个相似物品,用公式预估用户对物品的兴趣分数(2.3.1节);
- 返回分数最高的若干个物品,作为推荐结果。