一、激活函数的核心作用
在深度学习中,激活函数(Activation Function)是神经网络的核心组件之一。如果没有激活函数,无论网络堆叠多少层,都只是线性变换的叠加 ,最终输出仍是输入的线性组合。
这种线性模型连最简单的"异或(XOR)"问题都无法解决,更别说学习图像、语音、文本等复杂数据中的非线性模式 。
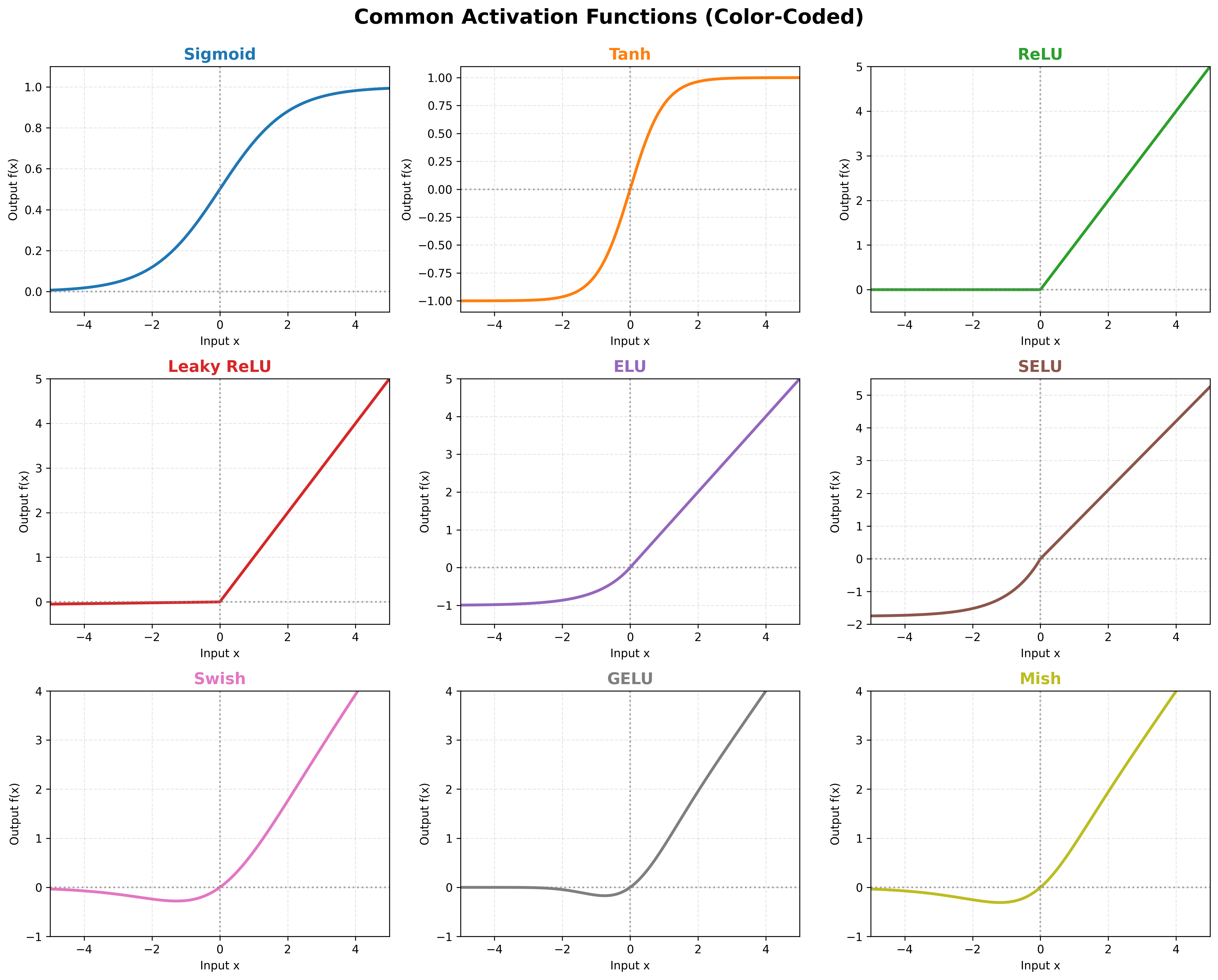
激活函数的主要价值在于为神经网络引入非线性,但它的作用远不止于此:
- 打破线性局限:让网络能拟合任意复杂的函数(通用逼近定理)。
- 控制梯度流动:缓解梯度消失或爆炸,加速模型收敛。
- 输出归一化:将输出映射到特定范围(如0,1或-1,1),便于概率解释或后续处理。
二、经典激活函数深度解析
| 激活函数 | 函数表达式 | 值域 |
|---|---|---|
| Sigmoid | f(x)=11+e−xf(x) = \frac{1}{1 + e^{-x}}f(x)=1+e−x1 | (0,1)(0, 1)(0,1) |
| Tanh | f(x)=tanh(x)=ex−e−xex+e−xf(x) = \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}f(x)=tanh(x)=ex+e−xex−e−x | (−1,1)(-1, 1)(−1,1) |
| ReLU | f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) | [0,+∞)[0, +\infty)[0,+∞) |
| Leaky ReLU | f(x)={xif x>0αxif x≤0f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \leq 0 \end{cases}f(x)={xαxif x>0if x≤0 | (−∞,+∞)(-\infty, +\infty)(−∞,+∞) |
| ELU | f(x)={xif x>0α(ex−1)if x≤0f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha (e^x - 1) & \text{if } x \leq 0 \end{cases}f(x)={xα(ex−1)if x>0if x≤0 | (−α,+∞)(-\alpha, +\infty)(−α,+∞) |
| SELU | f(x)=λ{xif x>0α(ex−1)if x≤0f(x) = \lambda \begin{cases} x & \text{if } x > 0 \\ \alpha (e^x - 1) & \text{if } x \leq 0 \end{cases}f(x)=λ{xα(ex−1)if x>0if x≤0 | (−λα,+∞)(-\lambda\alpha, +\infty)(−λα,+∞) |
| Softmax | f(xi)=exi∑jexjf(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}}f(xi)=∑jexjexi | (0,1)(0, 1)(0,1) |
| Swish | f(x)=x⋅sigmoid(x)=x1+e−xf(x) = x \cdot \text{sigmoid}(x) = \frac{x}{1 + e^{-x}}f(x)=x⋅sigmoid(x)=1+e−xx | (−∞,+∞)(-\infty, +\infty)(−∞,+∞) |
| GELU | f(x)=x⋅Φ(x)≈0.5x(1+tanh2/π(x+0.044715x3))f(x) = x \cdot \Phi(x) \approx 0.5x\left(1 + \tanh\left\\sqrt{2/\\pi}(x + 0.044715x\^3)\\right\right)f(x)=x⋅Φ(x)≈0.5x(1+tanh2/π (x+0.044715x3)) | (−∞,+∞)(-\infty, +\infty)(−∞,+∞) |
| Mish | f(x)=x⋅tanh(ln(1+ex))f(x) = x \cdot \tanh(\ln(1 + e^x))f(x)=x⋅tanh(ln(1+ex)) | (−∞,+∞)(-\infty, +\infty)(−∞,+∞) |
2.1 Sigmoid函数
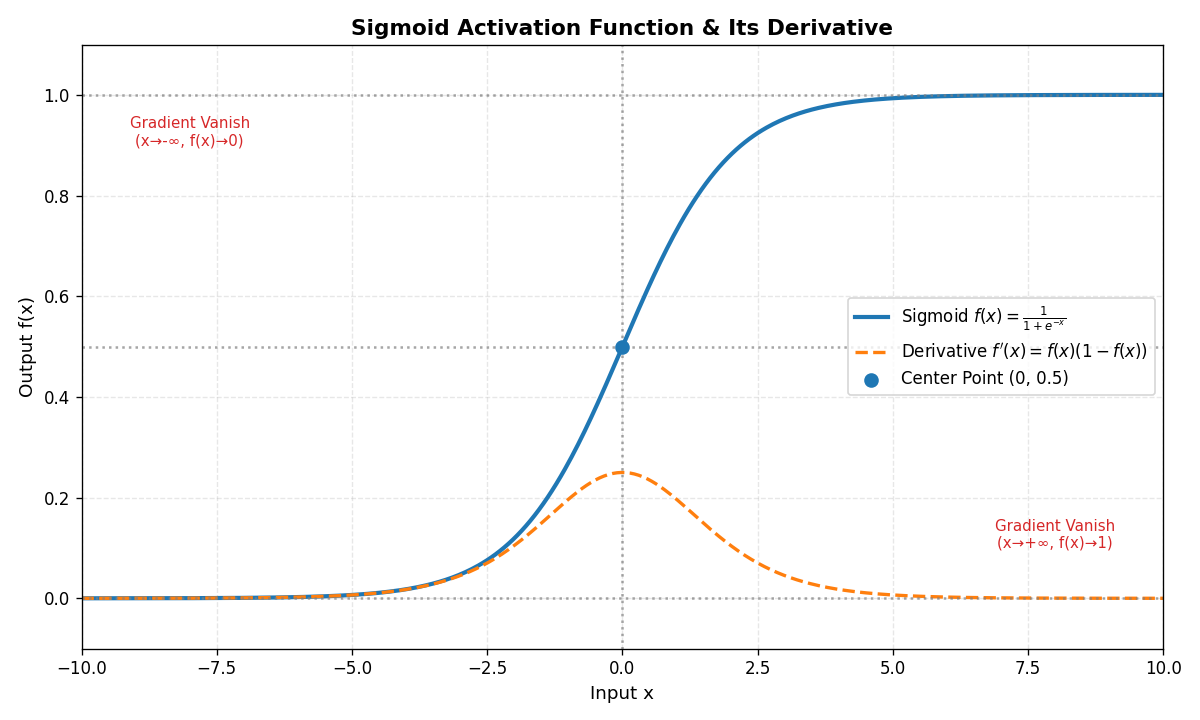
- 公式 :f(x)=11+e−x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
- 特点 :将输入映射到(0,1)(0,1)(0,1)区间,可解释为概率。
- 优点 :
- 输出平滑,易于求导。
- 适合二分类任务的输出层。
- 缺点 :
- 梯度消失:当xxx趋近于±∞±∞±∞时,梯度接近000,导致深层网络难以训练。
- 输出非零均值:会导致下一层输入的偏移,影响收敛速度。
- 适用场景:二分类任务的输出层(现已较少用于隐藏层)。
2.2 Tanh函数
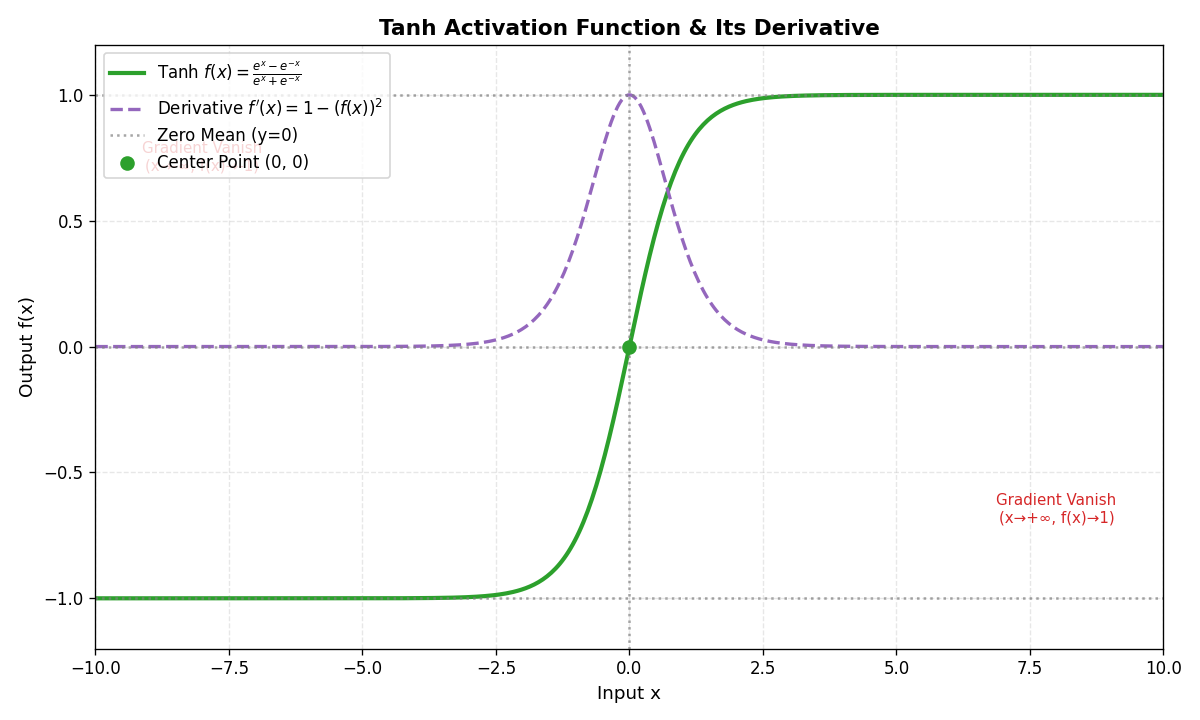
- 公式 :f(x)=tanh(x)=ex−e−xex+e−x f(x) = \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=tanh(x)=ex+e−xex−e−x
- 特点 :将输入映射到(−1,1)(-1,1)(−1,1)区间,输出均值为000。
- 优点 :
- 相比
Sigmoid,收敛速度更快(输出零均值)。 - 适合需要正负输出的场景。
- 相比
- 缺点:仍存在梯度消失问题。
- 适用场景:传统RNN的隐藏层(现已逐渐被更优的激活函数替代)。
2.3 ReLU
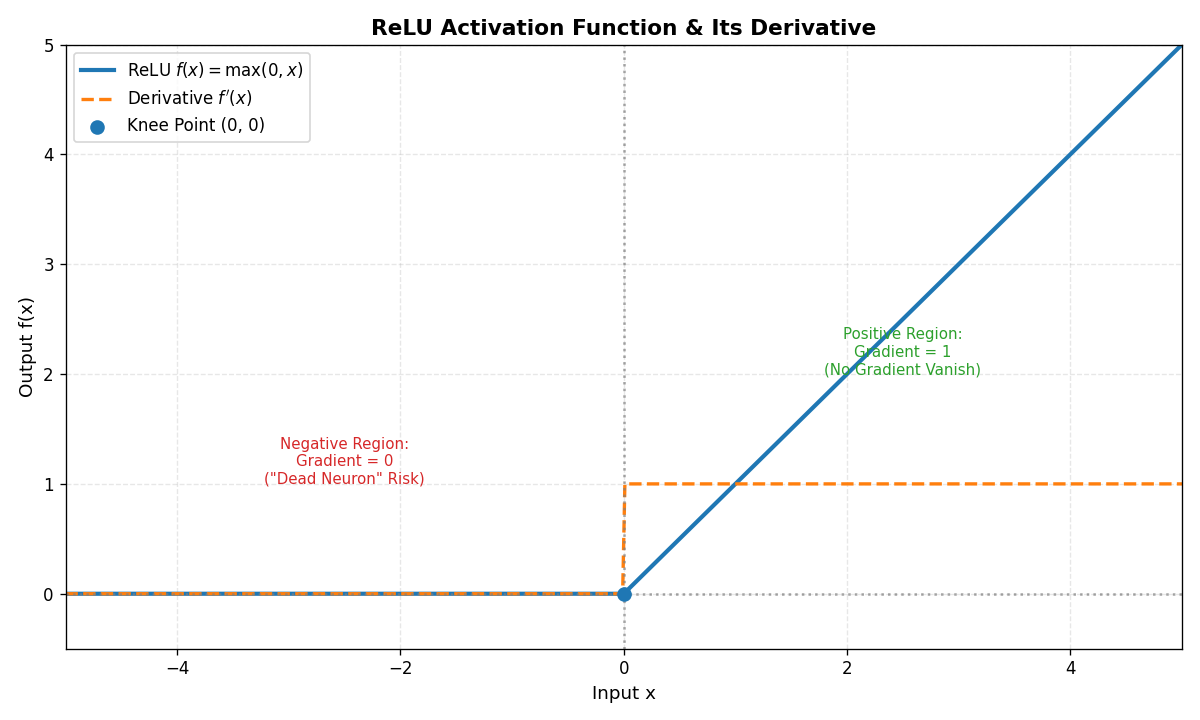
- 公式 :f(x)=max(0,x) f(x) = \max(0, x) f(x)=max(0,x)
- 特点 :当x>0x>0x>0时,梯度恒为1;x≤0x≤0x≤0时,输出为000。
- 优点 :
- 计算简单(仅需比较大小),训练速度快。
- 有效缓解梯度消失问题(在正区间)。
- 稀疏激活性:部分神经元输出为000,减少过拟合。
- 缺点 :
- "死亡神经元":当x≤0x≤0x≤0时,梯度为000,神经元可能永远无法更新。
- 适用场景:绝大多数深度神经网络的隐藏层(如CNN、DNN)。
2.4 Leaky ReLU
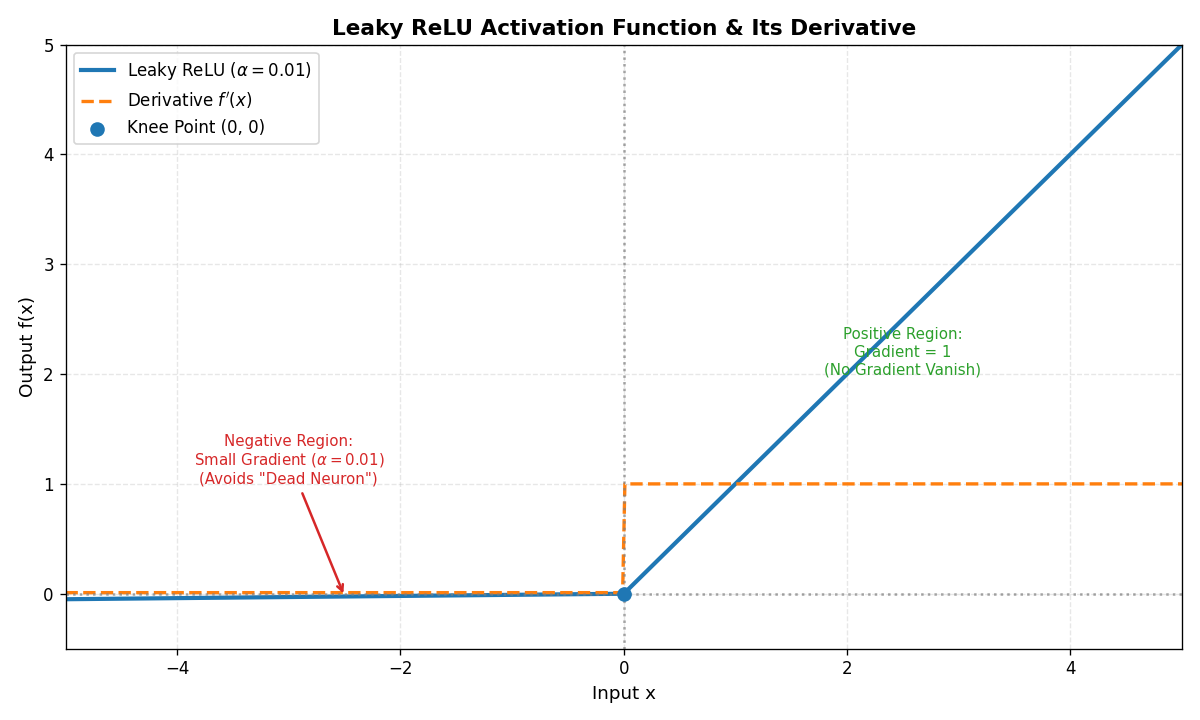
- 公式 :f(x)={xif x>0αxif x≤0 f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha x & \text{if } x \leq 0 \end{cases} f(x)={xαxif x>0if x≤0(通常
α=0.01) - 特点 :在x≤0x≤0x≤0时,保留一个小的梯度αxαxαx,避免神经元死亡。
- 优点 :解决了
ReLU的"死亡神经元"问题。 - 缺点 :
α需手动设置,且理论上仍可能梯度消失。 - 适用场景:需要避免神经元死亡的场景(如某些生成模型)。
2.5 ELU
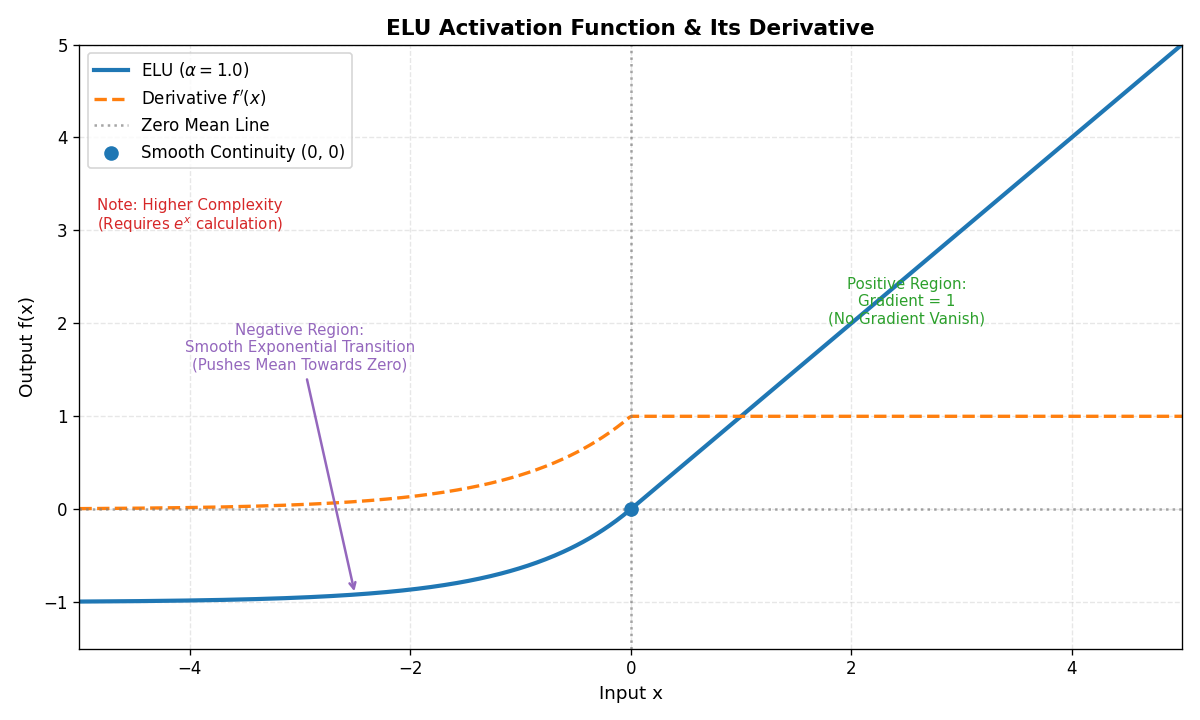
- 公式 :f(x)={xif x>0α(ex−1)if x≤0 f(x) = \begin{cases} x & \text{if } x > 0 \\ \alpha (e^x - 1) & \text{if } x \leq 0 \end{cases} f(x)={xα(ex−1)if x>0if x≤0
- 特点 :x≤0x≤0x≤0时,输出平滑过渡到负值,均值更接近000。
- 优点 :
- 缓解死亡神经元问题。
- 输出零均值,加速收敛。
- 缺点:计算复杂度较高(涉及指数运算)。
- 适用场景:对收敛速度要求高的场景。
2.6 SELU
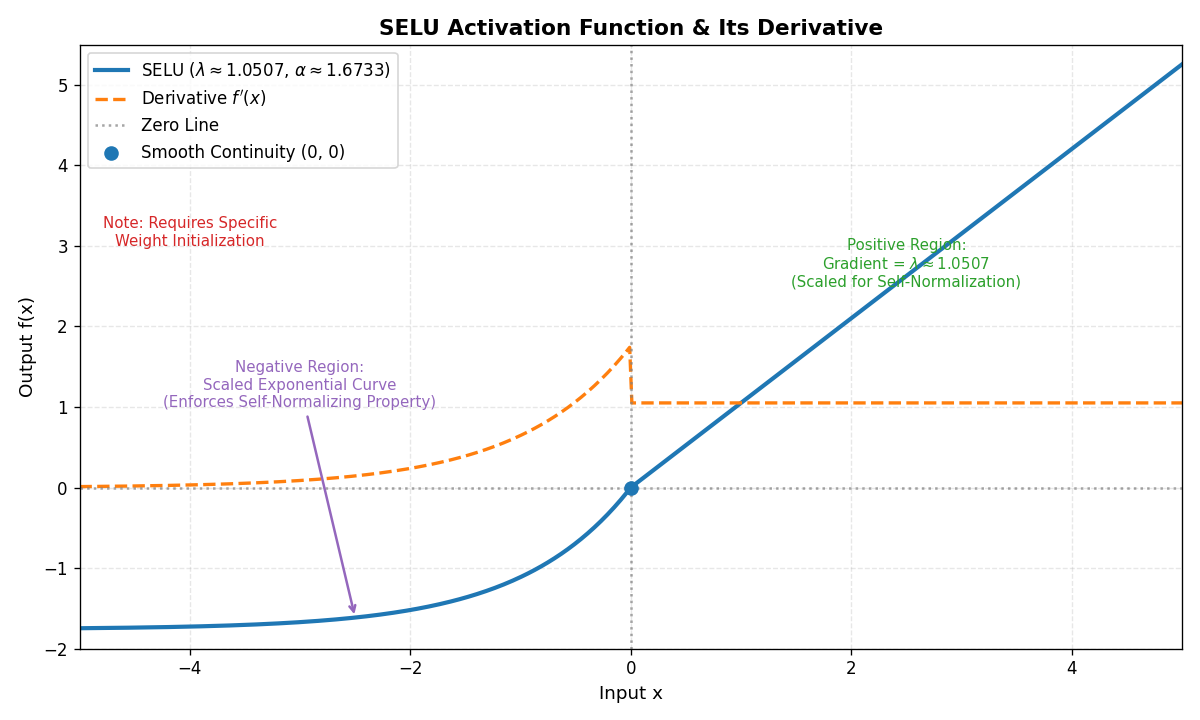
- 公式 :在
ELU基础上引入缩放因子:f(x)=λ{xif x>0α(ex−1)if x≤0 f(x) = \lambda \begin{cases} x & \text{if } x > 0 \\ \alpha (e^x - 1) & \text{if } x \leq 0 \end{cases} f(x)=λ{xα(ex−1)if x>0if x≤0(λ≈1.0507,α≈1.6733) - 特点:自归一化激活函数,能自动将输出均值和方差归一化。
- 优点 :
- 无需额外的归一化层(如
BatchNorm)。 - 适合极深网络(如100层以上)。
- 无需额外的归一化层(如
- 缺点:需配合特定的权重初始化方法。
- 适用场景:超深神经网络、自编码器。
2.7 Softmax函数
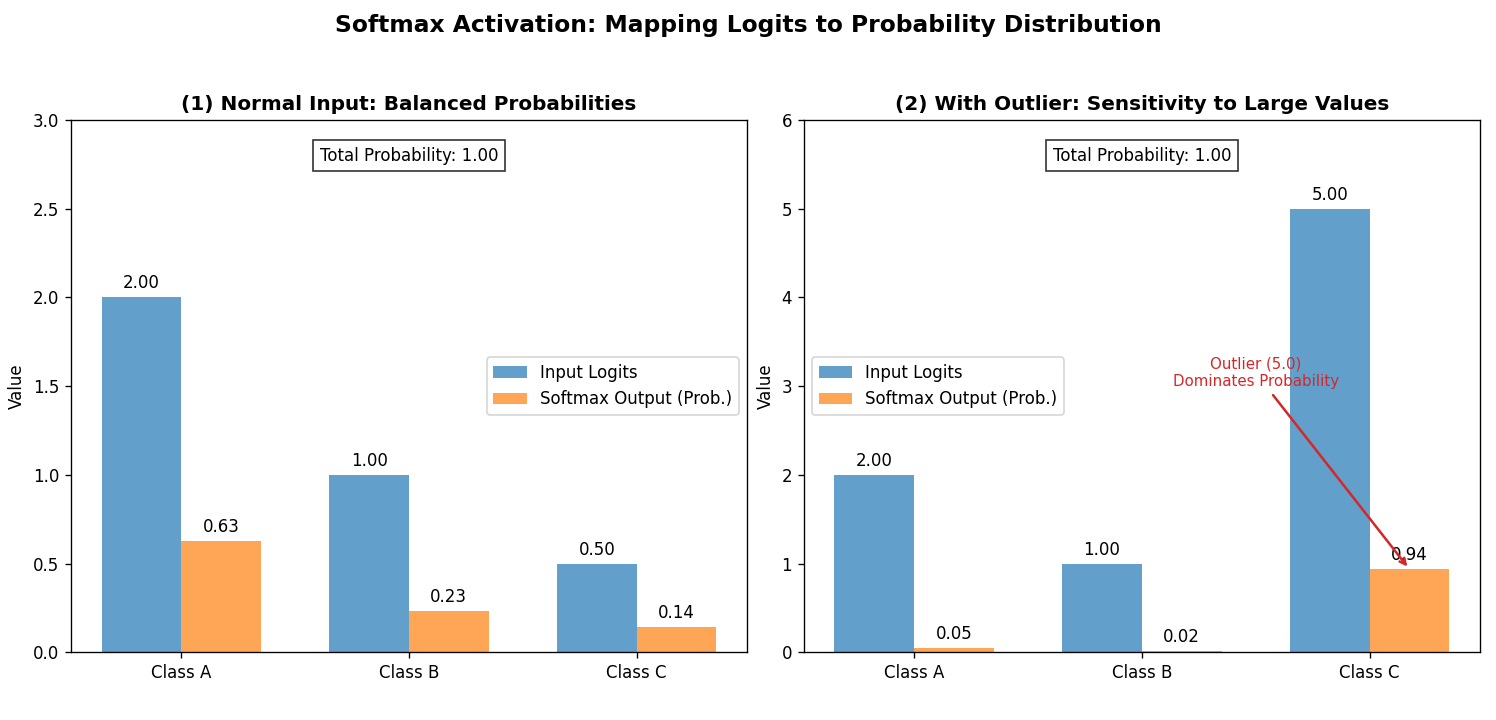
- 公式 :f(xi)=exi∑jexj f(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} f(xi)=∑jexjexi
- 特点 :将多分类输出映射为概率分布(总和为111)。
- 优点 :
- 输出可直接解释为类别概率。
- 适合多分类任务的输出层。
- 缺点:对异常值敏感(指数运算会放大差异)。
- 适用场景:多分类任务的输出层(如图像分类、文本分类)。
2.8 Swish函数
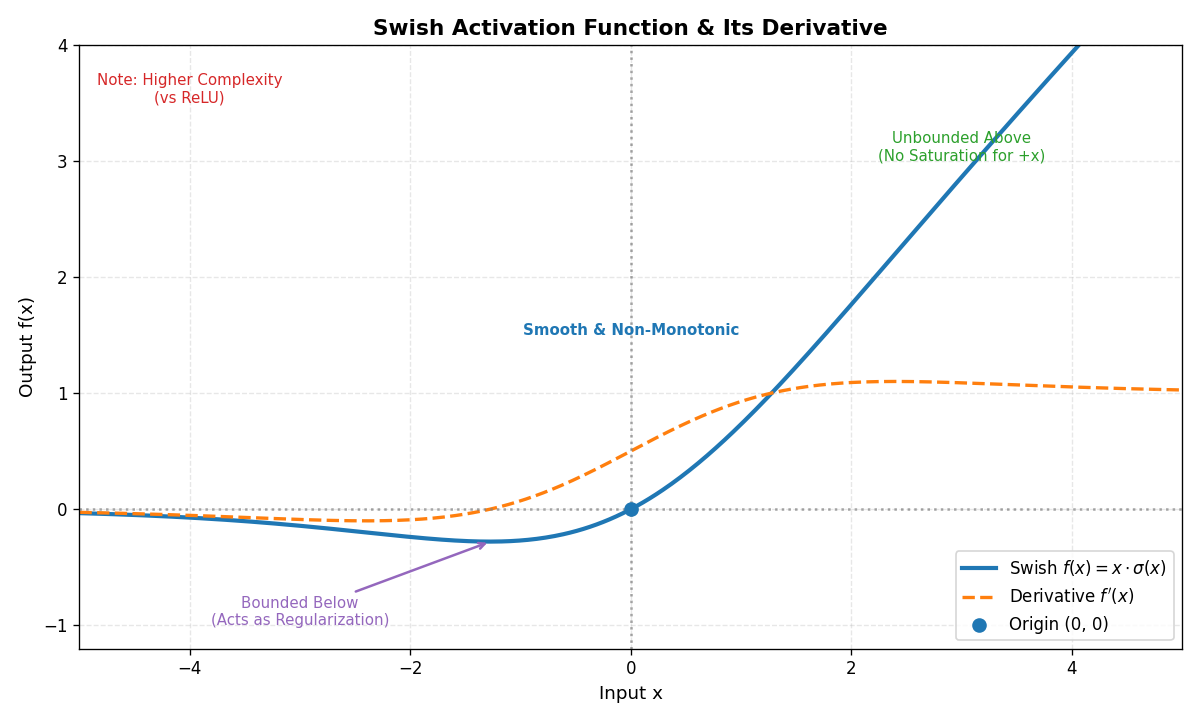
- 公式 :f(x)=x⋅sigmoid(x)=x1+e−x f(x) = x \cdot \text{sigmoid}(x) = \frac{x}{1 + e^{-x}} f(x)=x⋅sigmoid(x)=1+e−xx
- 特点 :平滑的非单调函数,在深层网络中表现优于
ReLU。 - 优点 :
- 无上界(避免饱和),有下界(增加正则化)。
- 在某些任务上(如ImageNet)准确率超过
ReLU。
- 缺点 :计算复杂度高于
ReLU。 - 适用场景 :深度
CNN、Transformer(早期版本)。
2.9 GELU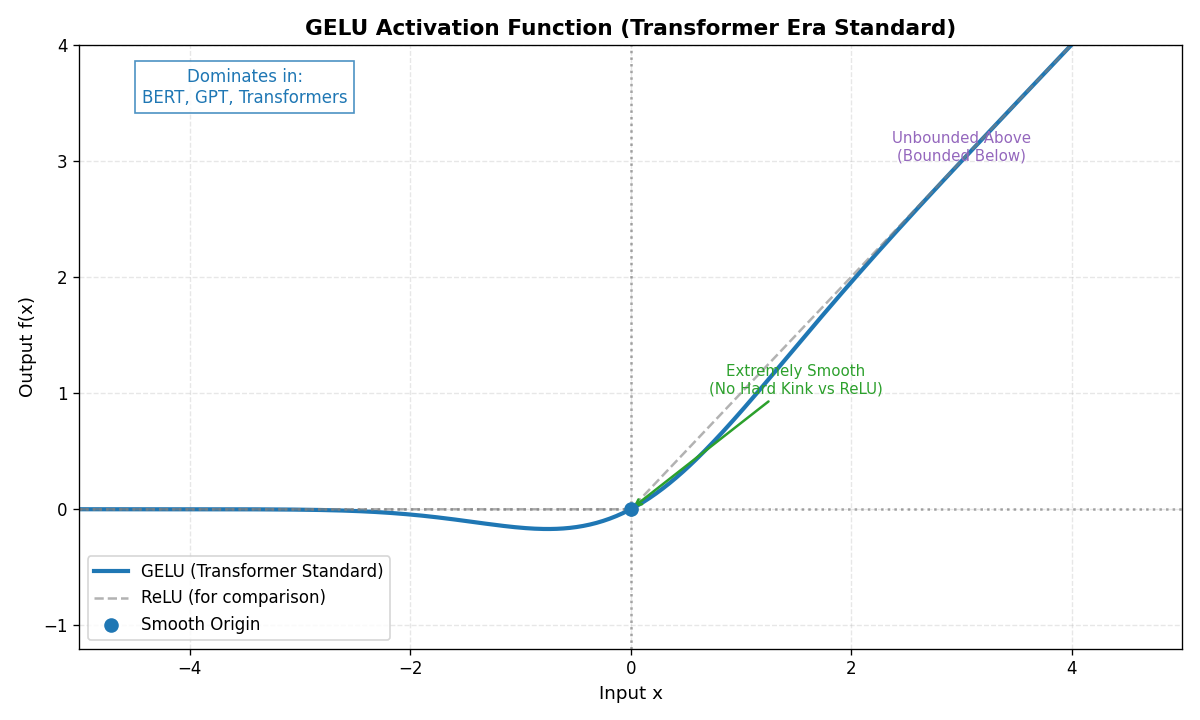
- 公式 :f(x)=x⋅Φ(x) f(x) = x \cdot \Phi(x) f(x)=x⋅Φ(x)(Φ是标准正态分布的累积分布函数)
近似公式:f(x)≈0.5x(1+tanh(2/π(x+0.044715x3))) f(x) \approx 0.5 x \left(1 + \tanh\left(\sqrt{2/\pi}(x + 0.044715x^3)\right)\right) f(x)≈0.5x(1+tanh(2/π (x+0.044715x3))) - 特点 :结合了
ReLU、Dropout和Zoneout的思想,随机"保留"神经元。 - 优点 :
- 在
NLP任务(如BERT、GPT)中表现极佳。 - 平滑的梯度,训练更稳定。
- 在
- 缺点:计算复杂度较高。
- 适用场景 :
Transformer架构(BERT、GPT系列)、NLP任务。
2.10 Mish函数
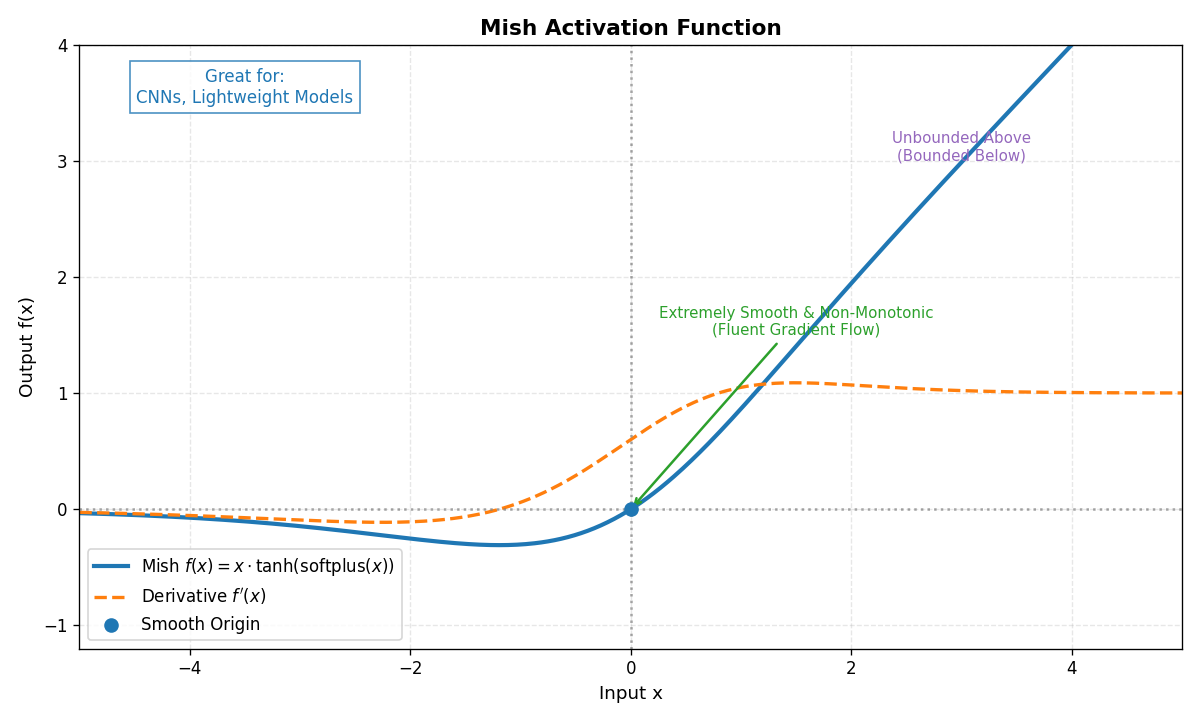
- 公式 :f(x)=x⋅tanh(softplus(x)) f(x) = x \cdot \tanh(\text{softplus}(x)) f(x)=x⋅tanh(softplus(x))
- 特点 :平滑的非单调函数,性能接近
GELU但计算更简单。 - 优点 :
- 在图像分类任务上有时优于
GELU。 - 无上界、有下界,梯度流畅。
- 在图像分类任务上有时优于
- 缺点 :仍比
ReLU复杂。 - 适用场景 :
CNN、轻量级模型。
三、激活函数的演进历程
- 早期(1980s-2010s):Sigmoid和Tanh主导,但受困于梯度消失。
- 突破(2011年):ReLU提出,彻底改变了深层网络的训练效率。
- 改良(2010s中期):Leaky ReLU、PReLU、ELU等解决ReLU的缺陷。
- 自归一化(2017年):SELU让超深网络无需BatchNorm。
- Transformer时代(2018年后):GELU成为NLP模型的标配,Swish、Mish等在CV领域崭露头角。
四、如何选择合适的激活函数
| 场景 | 推荐激活函数 | 理由 |
|---|---|---|
| 隐藏层(默认选择) | ReLU | 简单高效,是绝大多数任务的起点。 |
| 隐藏层(ReLU失效) | Leaky ReLU / PReLU | 当出现大量"死亡神经元"时,尝试带泄漏的变体。 |
| 超深网络(>50层) | SELU | 自归一化特性避免梯度消失/爆炸,无需额外归一化层。 |
| Transformer / NLP | GELU | BERT、GPT等模型的标准配置,训练稳定且性能优异。 |
| 二分类输出层 | Sigmoid | 输出概率,直接对应"是/否"两类。 |
| 多分类输出层 | Softmax | 输出多类别概率分布,总和为1。 |
| 轻量级模型(移动端) | ReLU / Mish | 平衡性能与计算效率,Mish在小模型上有时表现更好。 |