在AI技术飞速迭代的当下,全自动化AI Agent已从概念走向实用,它无需人工干预,能自主规划任务、调用工具、处理异常,甚至在失败后自我恢复,广泛适用于内容创作、数据同步、自动化运营、代码调试等多个场景。很多开发者渴望搭建自定义的全自动化AI Agent,但往往陷入"工具堆砌"的误区,忽略了流程可控、安全隔离与长期可维护性的核心需求。事实上,依托当前成熟的开源生态,我们无需从零造轮子,只需理清模块逻辑、选对技术路径,就能快速构建一套稳定可用的全自动化AI Agent系统。
一、核心认知:全自动AI Agent,是编排系统而非单一模型
搭建全自动化AI Agent,本质是构建一套"智能编排系统",而非单纯部署一个AI模型。一个能投入实际使用的全自动AI Agent,核心是围绕"决策-执行-记忆-触发"形成闭环,其架构可拆解为7个关键模块,各模块相互支撑、缺一不可,而开源生态已为每个模块提供了成熟的组件选择,无需我们重复开发。
1.1 全自动AI Agent核心架构拆解
核心架构包含7大关键模块,各模块功能与开源组件对应关系如下:
全自动AI Agent核心架构
LLM接入层统一模型调用接口开源组件:Ollama、vLLM、TGI
Agent Runtime决策循环与错误恢复核心开源组件:LangGraph、AutoGen、CrewAI
Tools工具体系Agent的行动能力开源组件:LangChain Tools、MCP
Memory记忆层任务状态与知识留存开源组件:LlamaIndex、Qdrant、Milvus
Workflow编排层实现自动触发开源组件:n8n、Temporal、Airflow
Sandbox执行隔离安全防护开源组件:Docker、K8s
Observability可观测层问题定位与优化开源组件:Langfuse、Arize Phoenix
二、前期准备:明确边界,规避后期返工
在正式搭建前,我们必须先明确"自动化边界"与风险等级,这是避免后续返工的关键。首先要界定Agent的权限:是否允许其写入文件、发送消息、执行系统命令甚至完成下单操作?哪些动作属于高风险操作,需要额外的校验机制?其次要规划异常处理方案:当工具调用失败、模型响应超时或任务执行出错时,是选择重试、降级、报警还是回滚?最后要考虑数据隐私与多租户需求:是否涉及敏感数据,是否需要将模型与数据本地化部署?
记住,全自动不等于无约束,生产环境中更推荐"低风险自动化+高风险闸门"的模式,在效率与安全之间找到平衡。
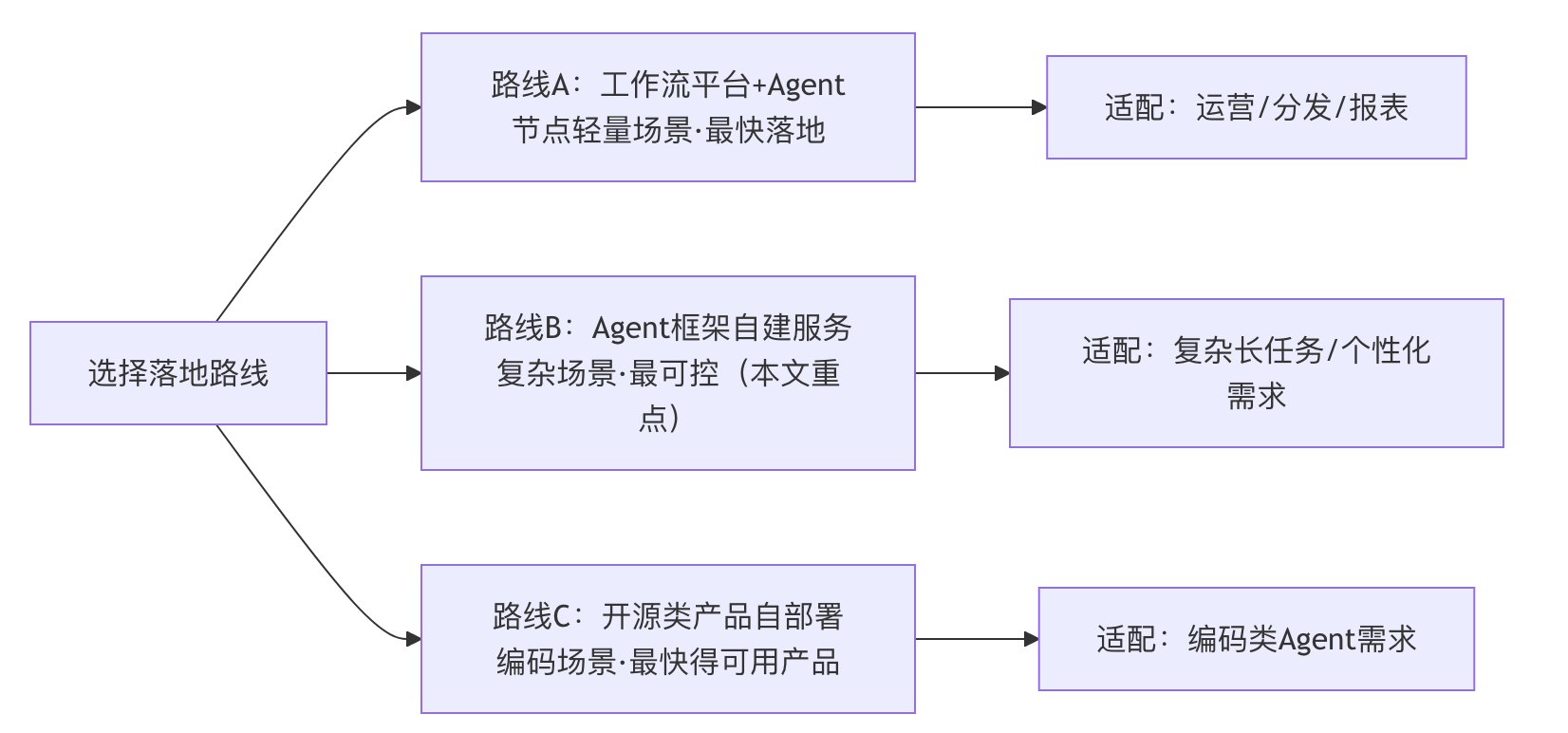
三、路线选择:三大开源路径,按需适配场景
选择一条合适的落地路线至关重要。不同场景对应不同的技术路径,盲目追求"全能"只会增加搭建难度,以下三条主流开源路线可按需选择,按"从快到稳"排序,覆盖大多数使用场景。
3.1 路线A:工作流平台+Agent节点(最快落地)
适合自动化运营、内容分发、数据同步、报表生成等轻量场景,核心组合为n8n(触发与编排)+LLM节点(或自建agent-service)+向量库(可选),优势是上手快、节点生态丰富,无需深入开发就能实现基础的全自动需求。
3.2 路线B:Agent框架自建服务(最可控、最通用)
适合复杂长任务、需要严谨状态机与重试机制、需自定义工具安全策略的场景,核心组合为LangGraph(推荐)/AutoGen/CrewAI + FastAPI/Node服务 + 数据库 + 队列,优势是可控性强、扩展性好,能适配个性化需求,也是本文重点讲解的路线。
3.3 路线C:开源类产品直接自部署(最快得可用产品)
适合想要快速获得类似Claude Code、Devin那样的编码Agent的场景,核心组合为OpenHands/OpenDevin,叠加自身的模型与工具环境,优势是落地最快,能快速得到可用的产品形态。
四、分步搭建:基于路线B,从零实现全自动AI Agent
以下基于路线B(Agent框架自建服务),结合开源组件,分步实现全自动化AI Agent,兼顾可控性与扩展性,全程可落地、可复用。
4.1 第一步:模型服务部署与标准化接入
模型是AI Agent的"大脑",但我们无需绑定某一款模型,关键是实现接口标准化,为后续模型替换提供便利。部署方式分为云端与本地两种,核心是给Agent Runtime暴露一个OpenAI-Compatible的Base URL,后续更换模型只需修改配置,无需改动上层逻辑。
-
云端部署:直接使用OpenAI、Anthropic、Gemini、DeepSeek等成熟API,专注于编排系统搭建即可。
-
本地部署:适合有隐私需求的场景,推荐Ollama(上手最简单,一键安装)、vLLM(吞吐强,适合服务化)、TGI(成熟稳定,适配多模型)。例如,本地部署Ollama后,只需简单命令启动模型,通过标准化接口调用,即可快速让Agent拥有思考能力。
4.2 第二步:构建可控决策循环------状态机驱动(核心)
Agent Runtime是全自动化的核心,其关键是将"决策循环"做成状态机,避免出现循环失控、重复调用工具、越改越错等问题。很多开发者搭建的Agent无法实现真正的全自动,核心原因就是决策逻辑依赖"prompt魔法",缺乏可控的流程约束。
LangGraph的核心价值,就是将Agent的决策循环从不可控的prompt驱动,转化为可控的状态机驱动。我们可以用状态机/图的方式,显式定义Agent的每一个行为节点,同时设置预算约束,从根本上避免循环失控。
4.2.1 Agent决策循环状态机流程图
执行正常,任务完成
执行异常/未完成
Start 启动任务
Plan 任务规划调整步骤重新执行
Act 执行动作调用工具完成步骤
Reflect 反思修复检查执行结果,处理错误
Done 终止任务输出最终结果
状态机核心约束:为每一步设置预算,包括token上限、工具调用次数、最长运行时间,确保决策循环可控。
4.3 第三步:搭建规范工具体系,筑牢执行基础
如果说状态机是Agent的"决策中枢",那么工具体系就是Agent的"手脚",其可靠性直接决定了Agent的实用价值。搭建工具体系时,绝不能简单地将一堆函数塞给模型,而要构建一套规范的"工具执行管道",具备Schema校验、权限管控、副作用隔离等核心能力。
-
Schema校验:严格验证工具输入参数,避免模型乱填参数导致调用失败。
-
权限与策略管控:通过白名单、黑名单,为不同任务分配不同工具权限,限制高风险操作。
-
副作用隔离:对写入文件、发消息等不可逆操作,实现可回滚、可追踪。
-
幂等性设计:确保同一动作重复执行不会造成灾难。
-
超时与重试:为网络工具设置超时,重试采用退避策略,减少资源浪费。
-
审计日志:记录每一次工具调用的详细信息,便于问题定位。
此外,若想快速接入丰富工具生态,可优先考虑MCP(Model Context Protocol)现成服务,减少自主集成成本。
4.4 第四步:持久化记忆,实现断点续跑
全自动化AI Agent的"记忆",并非简单存储聊天记录,而是实现任务状态与知识的持久化,确保重启后不丢失进度、能复用历史知识。Agent的记忆分为三层,层层递进支撑任务执行,最小可用方案可采用"结构化状态+长期知识"的组合。
4.4.1 Agent记忆分层架构
Agent记忆体系
短期上下文当前会话任务信息、执行记录需定期裁剪/摘要,避免token溢出
工作状态任务进度、待办列表、失败原因、重试次数存储:Postgres、SQLite(单机优先)
长期记忆用户偏好、领域知识、历史工单、文档库技术:RAG+向量库(Qdrant/Milvus)+LlamaIndex
4.5 第五步:添加触发机制,实现真正全自动
没有触发机制,Agent只能依赖人工调用,无法自主启动任务。我们至少需要三种触发能力,结合开源组件,可根据需求复杂度选择适配方案,实际落地中常采用"n8n触发+自建agent-service执行"的组合,兼顾效率与可控性。
-
定时触发:通过Cron表达式,实现周期性任务(如日报生成、数据同步)。
-
事件触发:通过Webhook、消息队列、邮件等,实现"事件发生即执行"(如客服分流)。
-
长任务编排:支持跨多轮执行、断点续跑,适配长时间运行任务。
开源组件选择:简单场景用n8n(上手快、节点丰富);复杂长任务、高可靠性需求用Temporal(稳定性强)。
4.6 第六步:沙盒隔离,守住安全底线
当Agent具备执行系统命令、写入文件、联网等能力时,必须将其关进"沙盒",防范prompt注入、误操作等风险。沙盒隔离需满足最低安全要求,确保Agent运行在安全可控的环境中。
-
环境隔离:Agent运行在Docker/K8s容器中,与主机环境隔离。
-
文件与网络管控:只挂载必要文件目录(只读优先),网络出站设白名单。
-
资源配额:分配合理CPU、内存、磁盘,设置任务超时,避免资源耗尽。
-
敏感信息保护:通过环境变量/密钥管理注入敏感信息,不写入日志与记忆。
编码Agent额外建议:将代码执行、测试、构建等操作,放到单独隔离runner(如worker容器)中,提升安全等级。
4.7 第七步:可观测性建设,避免玄学debug
全自动系统必然会失败,可观测性能力至关重要------没有可观测性,问题出现后只能"玄学debug"。可观测性的核心是全链路追踪,记录Agent运行的每一个关键节点,结合开源工具,实现问题快速定位与迭代优化。
开源可观测工具推荐:Langfuse(支持LLM Trace、Prompt管理、任务回放,快速定位异常);Arize Phoenix(偏向模型与RAG评估、可视化,适合持续优化性能)。
4.8 第八步:自动评估与回归,保障稳定性
Agent的迭代优化需要规范机制,避免"修复一个问题,爆发另一个问题"。建议搭建"自动评估与回归"体系,确保稳定性持续提升:
-
工具单测:为每个工具编写测试用例,覆盖正常与失败场景。
-
任务回归集:固定一批真实任务场景,每次迭代后运行回归测试,避免功能退化。
-
离线评估:在沙盒环境中模拟工具调用,评估决策逻辑,提前发现问题。
五、MVP推荐:最小可用组合,快速落地
对于想要快速落地的开发者,推荐一套最小可用(MVP)技术组合,无需复杂配置,复制即可搭建可自动运行的AI Agent,兼顾效率与基础稳定性。
5.1 MVP核心组件组合
-
触发与编排:n8n(快速配置自动化流程)
-
Agent Runtime:LangGraph(服务化部署,可控决策循环)
-
存储:Postgres(状态)+Qdrant(可选,长期知识)
-
模型:云端API(快速验证)/本地Ollama(隐私需求)
-
可观测:Langfuse(节省排障时间)
5.2 MVP运行流程
n8n触发定时/事件(Webhook/邮件等)
调用自建agent-service
LangGraph驱动规划→工具调用→状态写入
任务完成,结果回传n8n
n8n发送通知邮件/飞书/Telegram
六、避坑指南:常见误区与解决方案
开源部署全自动化AI Agent时,很多开发者会陷入各类误区,导致系统不稳定、难以维护,以下是常见坑点及规避方案:
-
误区1:工具越多越智能------工具越多稳定性越差,优先做好白名单与分级权限,聚焦核心需求。
-
误区2:忽视状态持久化------不存储状态会导致重启丢进度,长任务必翻车,务必做好状态持久化。
-
误区3:缺乏预算控制------token、工具调用次数无上限,会导致成本与风险失控,需设置明确预算。
-
误区4:RAG当作万能药------RAG仅解决"知识检索",无法替代Agent的规划与执行能力,需合理定位其作用。
-
误区5:无观测与回放能力------问题出现后无法定位根源,系统沦为"玄学系统",务必接入Langfuse等工具。
七、总结:开源赋能,快速落地实用型全自动AI Agent
依托开源生态,搭建全自动化AI Agent并非遥不可及的技术难题,它不需要我们从零开发核心组件,只需理清模块逻辑、选对技术路径、做好安全与可观测性,就能快速落地实用的自定义Agent。从明确边界、选择路线,到部署模型、搭建状态机、完善工具与记忆体系,再到触发机制、安全隔离与迭代优化,每一步都有成熟的开源组件与实操方案支撑。
无论是简单的自动化运营,还是复杂的长任务处理,只要遵循这套思路,就能构建出稳定、可控、可扩展的全自动化AI Agent,让技术真正为效率赋能。若能结合具体场景(如全自动写日报、内容分发、CI报错修复、竞品信息抓取),还可进一步优化组件选型与流程设计,让Agent更贴合实际需求。