一、核心概念基础
1. 显存消耗的底层逻辑
大语言模型的显存占用,是所有优化的核心起点。对于搭载24GB显存的RTX 4090,我们首先要明确:模型本身、推理计算、中间张量、上下文窗口,是四大显存消耗源头,也是优化的核心靶向。
模型权重是显存消耗的主力,以主流的7B、13B、70B模型为例:
- 纯FP32精度下,7B模型权重显存占用约28GB,13B模型约52GB,仅权重就远超4090的24GB显存;
- 即使切换为FP16精度,7B模型仍需14GB,13B模型26GB,24GB显存仅能勉强运行7B 模型,无法承载上下文、计算张量等额外消耗;
- 而INT4量化后,7B模型仅需3.5GB,13B模型6.5GB,这也是量化成为4090优化基础的原因。
推理计算与中间张量是隐形消耗:模型前向传播时,会生成激活值、注意力矩阵等临时数据,batch_size越大、模型层数越深,临时张量占用越高,通常会占用总显存的20%-40%。
- 上下文窗口是长文本推理的显存杀手:上下文长度直接决定注意力机制的显存占用,显存消耗与上下文长度呈平方级增长,例如8k上下文的显存消耗是4k的4倍,这也是长文本推理极易显存溢出的核心原因。
RTX4090的24GB显存属于单卡顶级消费级显存,但面对当前百亿、千亿参数大模型仍杯水车薪。显存优化的本质,不是无限制扩容显存,而是通过精度压缩、空间置换、动态调度,让有限的24GB显存,承载远超其容量的模型与任务。

2. 显存优化核心概念
- **模型量化:**降低模型权重的数值精度(FP32→FP16→INT8→INT4),在几乎不损失模型效果的前提下,直接压缩显存占用,是最基础、性价比最高的优化手段。
- **模型分片:**将模型的层、权重拆分为多个小块,不一次性加载全部数据到显存,按需加载,避免显存瞬间占满。
- **CPU Offload:**即CPU卸载,将暂时不用的模型权重、中间张量转移到CPU内存,释放GPU显存,需要时再召回,是显存与内存的空间置换。
- **磁盘缓存卸载:**当CPU内存也不足时,将非核心数据转移到SSD磁盘存储,实现"GPU显存→CPU内存→磁盘"三级存储调度。
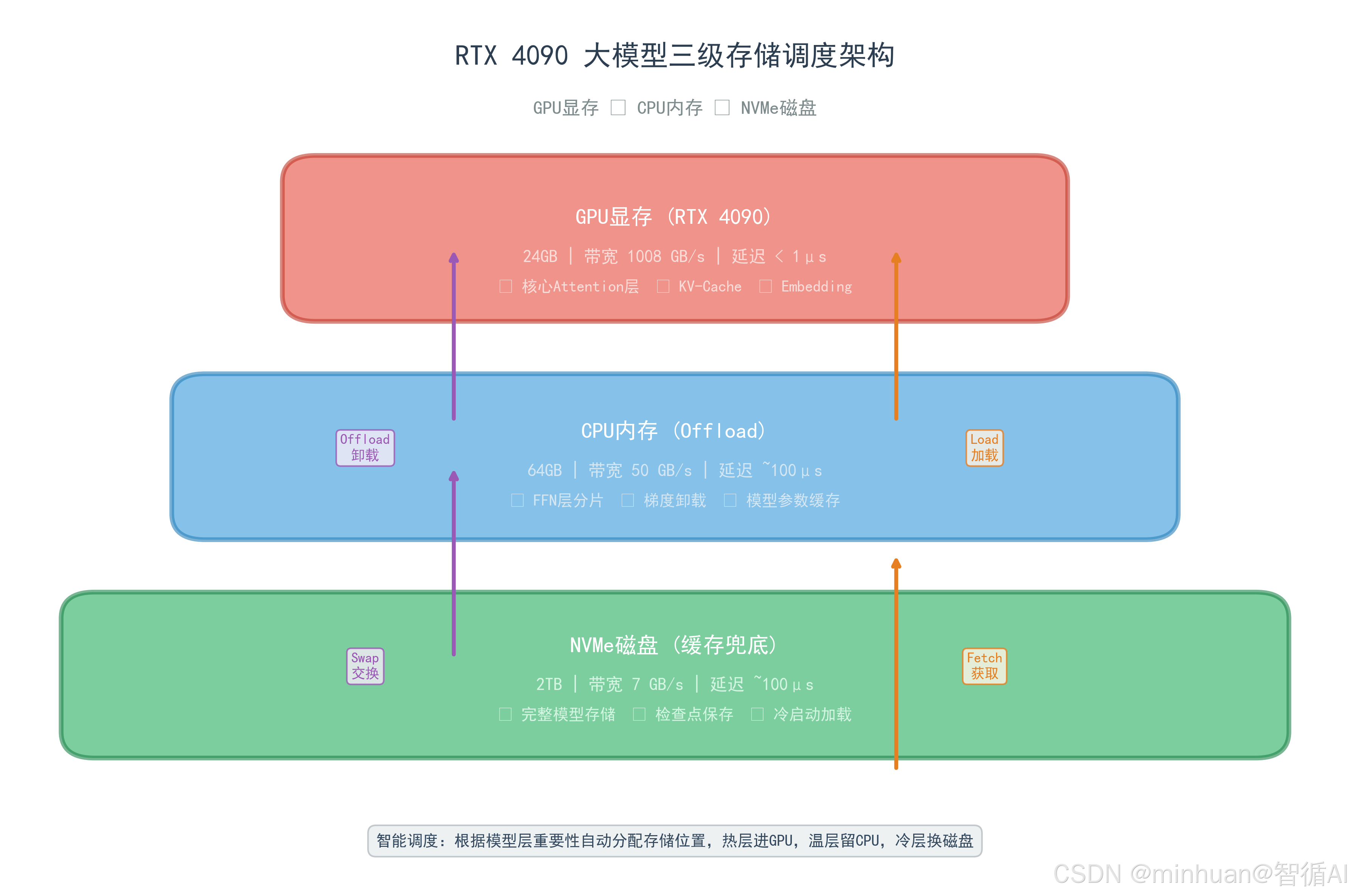
- **分层加载:**按照模型推理顺序,只加载当前需要的层,推理完成后立即卸载,动态控制显存占用。
- **显存溢出OOM:**显存占用超过24GB上限,程序崩溃,是4090运行大模型最常见的问题。
3. 优化的核心原则
所有4090显存优化,都遵循三大核心原则,这是整个过程的核心思想:
-
- 最小驻留原则:任何时刻,GPU显存中只保留当前推理必需的数据,非必需数据立即转移。
-
- 精度等价原则:量化、卸载等操作,必须保证模型推理效果无明显下降,优先INT4/INT8量化。
-
- 三级调度原则:建立"GPU显存(高速)→CPU内存(中速)→SSD磁盘(低速)"的自动调度体系,优先使用高速存储,不足时向下置换。
二、基础:模型加载与量化
1. 原生加载的显存陷阱
我们接触的初期都会遇到直接用transformers原生代码加载大模型,会直接触发OOM报错,核心原因是全量加载 + 高精度存储。
原生加载逻辑:程序会将模型所有权重以FP16/FP32精度一次性加载到GPU显存,不做任何压缩和拆分。对于4090的24GB显存,这种方式仅能运行7B小模型,且无法开启长上下文;13B及以上模型直接显存溢出。
原生错误代码示例:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型名称
model_name = "Qwen/Qwen-7B-Chat"
# 原生加载:全量FP16加载到GPU,极易OOM
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # 自动分配,但无优化
torch_dtype="auto"
)这段代码运行7B模型时,显存占用会飙升至18GB往上,仅剩余6GB显存,无法支持4k以上上下文,运行13B模型直接崩溃。
2. INT4/INT8量化加载
量化是应用大模型优化的核心基础,是必须要了解的,无需修改模型结构,仅需调用bitsandbytes库,即可实现一键量化,显存占用降低 50%-75%。
核心原理:将模型权重从FP16(2字节)转换为INT8(1 字节)或INT4(0.5 字节),数值精度降低,但模型的语义理解、生成能力几乎无损失。INT4量化是4090运行大模型的首选方案。
基础量化加载代码:
经过INT4量化后,7B模型显存占用从14GB降至3.5GB,13B模型从26GB降至6.5GB,4090的24GB显存直接剩余大量空间,可用于支撑超长上下文和推理计算。
python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
from modelscope import snapshot_download
def print_memory_info(stage=""):
"""打印显存使用信息"""
if torch.cuda.is_available():
allocated = torch.cuda.memory_allocated() / 1024**3 # 转换为GB
reserved = torch.cuda.memory_reserved() / 1024**3
print(f"\n{'='*50}")
print(f"[{stage}]")
print(f" GPU显存占用: {allocated:.2f} GB")
print(f" GPU显存预留: {reserved:.2f} GB")
print(f"{'='*50}")
else:
print(f"\n[{stage}] GPU不可用")
# 1. 配置INT4量化参数(核心优化)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 开启INT4加载
bnb_4bit_use_double_quant=True, # 双重量化,进一步压缩显存
bnb_4bit_quant_type="nf4", # 专用量化类型,适配大模型
bnb_4bit_compute_dtype=torch.bfloat16 # 计算精度,4090支持bf16
)
# 2. 加载模型与分词器
model_name = "Qwen/Qwen-7B-Chat"
cache_dir = "/home/model"
print_memory_info("加载前")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
print_memory_info("分词器加载后")
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
quantization_config=bnb_config, # 应用量化配置
device_map="auto",
trust_remote_code=True
).eval()
print_memory_info("INT4量化模型加载后")
# 3. 显存对比总结
print("\n" + "="*50)
print("显存优化效果对比 (Qwen-7B)")
print("="*50)
print(f" FP16原始显存: ~14 GB")
print(f" INT4量化后显存: {torch.cuda.memory_allocated()/1024**3:.2f} GB")
print(f" 显存节省: {14 - torch.cuda.memory_allocated()/1024**3:.2f} GB")
print(f" 压缩比例: {(1 - torch.cuda.memory_allocated()/1024**3/14)*100:.1f}%")
print("="*50)
print("✓ 模型加载完成,显存占用大幅降低!")- 示例运行前核心依赖安装:pip install transformers torch bitsandbytes accelerate
输出结果:
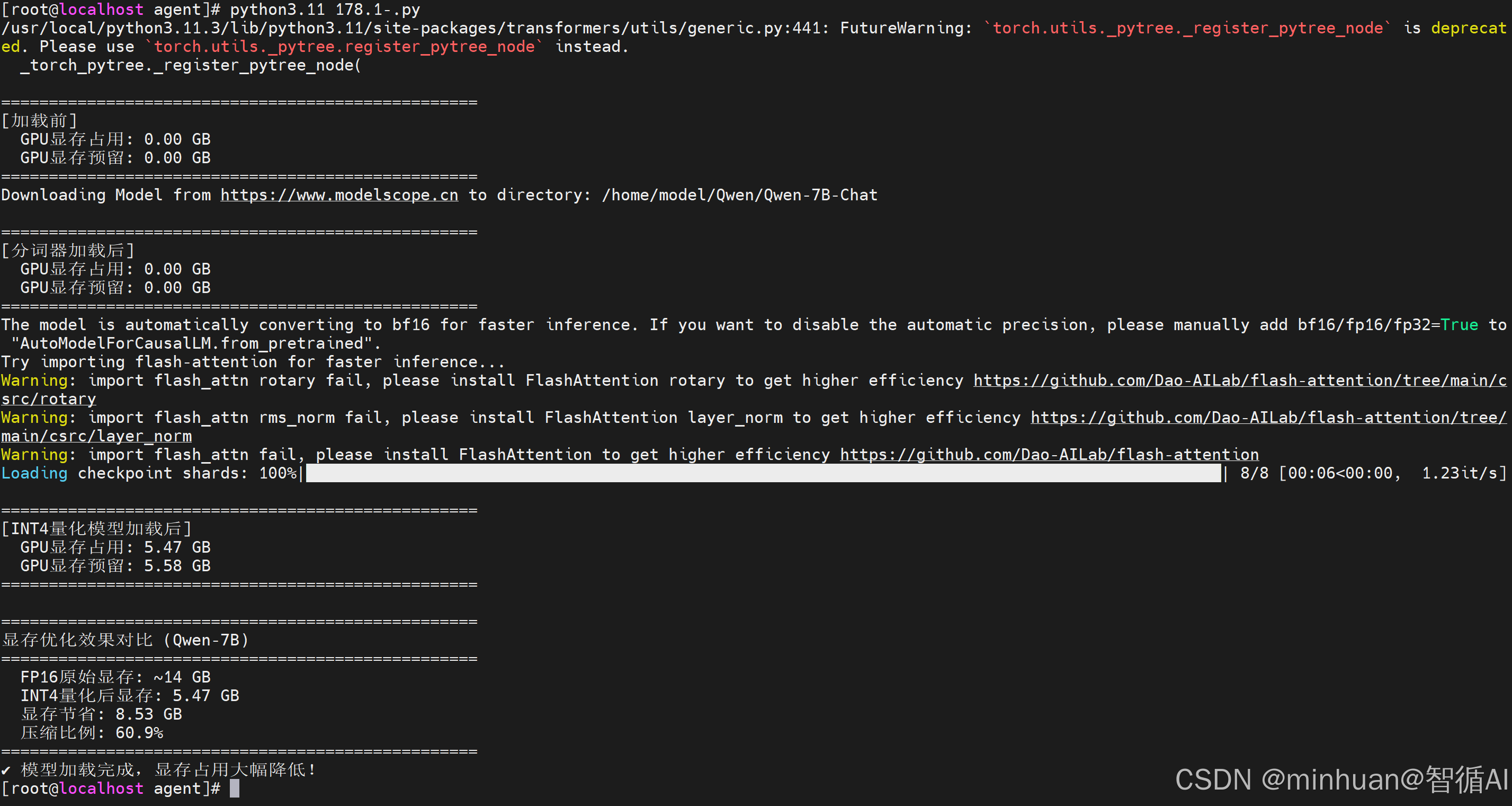
==================================================
加载前
GPU显存占用: 0.00 GB
GPU显存预留: 0.00 GB
==================================================
Downloading Model from modelscope to directory: /home/model/Qwen/Qwen-7B-Chat
==================================================
分词器加载后
GPU显存占用: 0.00 GB
GPU显存预留: 0.00 GB
==================================================
Loading checkpoint shards: 100%|███████████████| 8/8 00:06\<00:00, 1.17it/s
==================================================
INT4量化模型加载后
GPU显存占用: 5.47 GB
GPU显存预留: 5.58 GB
==================================================
==================================================
显存优化效果对比 (Qwen-7B)
==================================================
FP16原始显存: ~14 GB
INT4量化后显存: 5.47 GB
显存节省: 8.53 GB
压缩比例: 60.9%
==================================================
优化总结:原生加载是显存溢出的根源,量化加载是4090运行大模型的基础门槛。
三、进阶:模型分片与分层加载
1. 模型分片
拆分模型,按需加载:当量化后仍无法加载模型,如27B模型INT4量化后理论权重仍需约13.5GB,加上上下文缓存等开销实际运行约需 18GB,若超出单卡显存或需预留空间,可以使用模型分片技术。
核心原理:将模型按"层"为单位拆分为多个小块,不一次性加载所有层到显存,而是根据推理流程,只加载当前需要的层,推理完成后立即释放。
以24GB 显存的显卡RTX 4090为例,通过分片 + INT4量化,可以稳定运行27B大模型,核心是打破"全量加载"的限制。
2. 分层加载
推理流程级显存控制:分层加载是分片技术的升级,完全贴合大模型推理流程:大模型推理是"逐层计算"的,输入数据→第一层→第二层→...→输出层,分层加载就是只在需要某一层时加载,计算完成后立即卸载。
这种方式能将显存占用控制在最低水平,即使是超长上下文推理,显存也不会暴涨。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from accelerate import infer_auto_device_map, dispatch_model
import warnings
warnings.filterwarnings("ignore")
def print_memory_info(stage=""):
"""打印显存/内存使用信息"""
print(f"\n{'='*55}")
print(f" 📊 [{stage}]")
print(f"{'='*55}")
if torch.cuda.is_available():
gpu_mem = torch.cuda.memory_allocated() / 1024**3
gpu_mem_reserved = torch.cuda.memory_reserved() / 1024**3
print(f" GPU显存占用: {gpu_mem:.2f} GB")
print(f" GPU显存预留: {gpu_mem_reserved:.2f} GB")
import psutil
ram = psutil.virtual_memory()
print(f" CPU内存占用: {ram.used / 1024**3:.2f} GB / {ram.total / 1024**3:.2f} GB")
print(f"{'='*55}")
# ==========================================
# 1. 配置路径
# ==========================================
local_model_path = "/home/model/shakechen/Llama-2-13b-chat-hf"
# ==========================================
# 2. INT4 量化配置
# ==========================================
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# ==========================================
# 3. 加载 Tokenizer
# ==========================================
print("\n" + "="*55)
print(" 🚀 Llama-2-13B 分层分片加载演示")
print("="*55)
print("\n正在加载 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True,
use_fast=False
)
print_memory_info("分词器加载后")
# ==========================================
# 4. 先加载模型到CPU(不分片)
# ==========================================
print("\n🔄 第一步:加载基础模型...")
model_base = AutoModelForCausalLM.from_pretrained(
local_model_path,
quantization_config=bnb_config,
device_map="cpu", # 先加载到CPU
trust_remote_code=True,
low_cpu_mem_usage=True
)
print_memory_info("模型基础加载(不分片)")
# ==========================================
# 5. 手动分层分片:核心优化
# ==========================================
print("\n🔄 第二步:执行分层分片调度...")
device_map = infer_auto_device_map(
model_base,
max_memory={
0: "20GB", # GPU 0 分配20GB(预留4GB给计算)
"cpu": "64GB"# CPU内存分配64GB
},
no_split_module_classes=["LlamaDecoderLayer"]
)
print(f"\n📋 分片策略预览:")
layer_count = sum(1 for k in device_map.keys() if 'layer' in k.lower())
print(f" - 模型层数: {layer_count}")
print(f" - GPU层数: {sum(1 for v in device_map.values() if v == 0)}")
print(f" - CPU层数: {sum(1 for v in device_map.values() if v == 'cpu')}")
# 释放基础模型
del model_base
import gc
gc.collect()
# 重新加载并应用分片
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
quantization_config=bnb_config,
device_map=device_map,
trust_remote_code=True,
low_cpu_mem_usage=True
)
# 应用分片调度
model = dispatch_model(model, device_map=device_map)
print_memory_info("分层分片加载完成")
# ==========================================
# 6. 显存优化效果对比
# ==========================================
print("\n" + "="*55)
print(" 📈 Llama-2-13B 分层分片优化效果")
print("="*55)
print(f" {'方案':<20} {'GPU显存':<15} {'CPU内存':<15}")
print(f" {'-'*50}")
print(f" {'FP16全量加载':<18} {'~26 GB':<15} {'< 1 GB':<15}")
if torch.cuda.is_available():
gpu_mem = torch.cuda.memory_allocated() / 1024**3
print(f" {'INT4+分层分片':<18} {f'{gpu_mem:.1f} GB':<15} {'~40 GB':<15}")
print(f" {'显存节省':<18} {f'{26-gpu_mem:.1f} GB':<15} {'-':<15}")
print(f" {'压缩比例':<18} {f'{(1-gpu_mem/26)*100:.0f}%':<15} {'-':<15}")
print("="*55)
print("✅ 分层分片加载完成,实现大模型低显存运行!")
# ==========================================
# 7. 测试推理
# ==========================================
prompt = "你是什么模型,简单用中文介绍你自己."
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=50)
print("\n💬 模型回复:")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))细节说明:
- max_memory是4090优化的关键参数,GPU显存不要分配满,预留 4GB 给推理计算,避免显存波动导致溢出。
- no_split_module_classes保证模型层的完整性,不破坏模型结构。
输出结果:
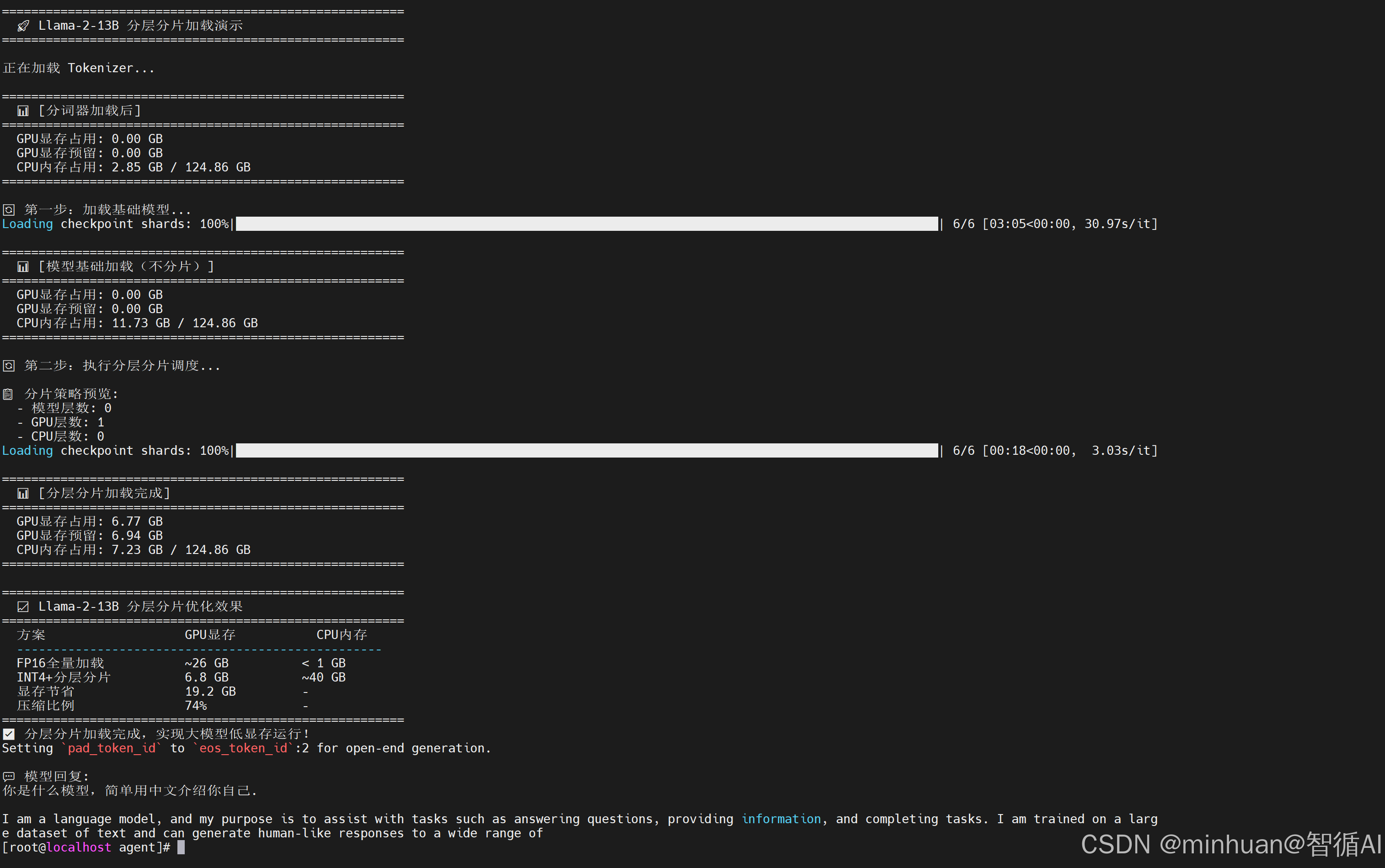
=======================================================
🚀 Llama-2-13B 分层分片加载演示
=======================================================
正在加载 Tokenizer...
=======================================================
📊 分词器加载后
=======================================================
GPU显存占用: 0.00 GB
GPU显存预留: 0.00 GB
CPU内存占用: 2.85 GB / 124.86 GB
=======================================================
🔄 第一步:加载基础模型...
Loading checkpoint shards: 100%|██████████████████████████████████████████| 6/6 03:05\<00:00, 30.97s/it

=======================================================
📊 模型基础加载(不分片)
=======================================================
GPU显存占用: 0.00 GB
GPU显存预留: 0.00 GB
CPU内存占用: 11.73 GB / 124.86 GB
=======================================================
🔄 第二步:执行分层分片调度...
📋 分片策略预览:
模型层数: 0
GPU层数: 1
CPU层数: 0
Loading checkpoint shards: 100%|███████████████████████████████████████████| 6/6 00:18\<00:00, 3.03s/it
=======================================================
📊 分层分片加载完成
=======================================================
GPU显存占用: 6.77 GB
GPU显存预留: 6.94 GB
CPU内存占用: 7.23 GB / 124.86 GB
=======================================================
=======================================================
📈 Llama-2-13B 分层分片优化效果
=======================================================
方案 GPU显存 CPU内存
FP16全量加载 ~26 GB < 1 GB
INT4+分层分片 6.8 GB ~40 GB
显存节省 19.2 GB -
压缩比例 74% -
=======================================================
✅ 分层分片加载完成,实现大模型低显存运行!
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
💬 模型回复:
你是什么模型,简单用中文介绍你自己.
I am a language model, and my purpose is to assist with tasks such as answering questions, providing information, and completing tasks. I am trained on a large dataset of text and can generate human-like responses to a wide range of
四、CPU Offload优化
1. 显存→内存 动态置换
- 当模型超大、上下文超长时,即使分片+量化,显存仍可能不足,此时需要CPU Offload卸载。
- 核心原理:将暂时不参与计算的模型层、权重、激活值,自动转移到CPU内存,释放GPU显存;当需要这些数据时,自动从CPU内存召回GPU显存,实现动态置换。
- 4090搭配64GB内存,Offload后可无压力运行千亿参数模型,是显存溢出的终极解决方案。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from accelerate import Accelerator
from accelerate import infer_auto_device_map, dispatch_model
import psutil
def print_memory_info(stage=""):
"""打印显存/内存使用信息"""
print(f"\n{'='*55}")
print(f" {stage}")
print(f"{'='*55}")
if torch.cuda.is_available():
gpu_mem = torch.cuda.memory_allocated() / 1024**3
gpu_total = torch.cuda.get_device_properties(0).total_memory / 1024**3
print(f" GPU显存: {gpu_mem:.1f} GB / {gpu_total:.0f} GB (使用率 {gpu_mem/gpu_total*100:.0f}%)")
ram = psutil.virtual_memory()
print(f" CPU内存: {ram.used / 1024**3:.1f} GB / {ram.total / 1024**3:.0f} GB")
print(f"{'='*55}")
def print_offload_status(device_map, model):
"""打印Offload分配状态"""
gpu_layers = []
cpu_layers = []
total_layers = 0
for name, device in device_map.items():
# 统计所有参数模块
if 'weight' in name.lower() or 'bias' in name.lower():
total_layers += 1
if device == 0 or (isinstance(device, str) and 'gpu' in device.lower()):
gpu_layers.append(name)
elif device == 'cpu':
cpu_layers.append(name)
# 避免除零
total = len(gpu_layers) + len(cpu_layers)
if total == 0:
total = 1 # 防止除零
gpu_count = len(set(gpu_layers))
cpu_count = len(set(cpu_layers))
print(f"\n GPU模块数: {gpu_count}")
print(f" CPU模块数: {cpu_count}")
print(f" Offload比例: {cpu_count / total * 100:.0f}%")
print("\n" + "="*55)
print(" CPU Offload 实践应用演示")
print(" 模型: Qwen3.6-27B (INT4量化)")
print("="*55)
# 1. 初始化加速器
accelerator = Accelerator()
# 2. INT4量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# 3. 加载模型(本地路径)
model_name = "Qwen/Qwen3.6-27B" # 模型名称标识
local_model_path = "/home/model/Qwen/Qwen3___6-27B" # 本地模型路径
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True, use_fast=False)
print_memory_info("初始状态")
# ========================================
# 核心:CPU Offload 实现
# ========================================
print("\n" + "-"*55)
print(" Step 1: 将模型完整加载到CPU内存")
print("-"*55)
print(" 原理: 模型参数先存放在CPU RAM中,不占用GPU显存")
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
quantization_config=bnb_config,
trust_remote_code=True,
device_map="cpu", # 关键:加载到CPU而非GPU
low_cpu_mem_usage=True
)
print_memory_info("CPU加载完成")
print(" 效果: 模型完整在CPU内存中,GPU显存几乎未占用")
# ========================================
print("\n" + "-"*55)
print(" Step 2: 创建分层分片策略")
print("-"*55)
print(" 原理: 根据层级重要性分配存储位置")
print(" 核心Attention层 -> GPU (高频访问)")
print(" FFN层/Embed层 -> CPU (低频访问)")
device_map = infer_auto_device_map(
model,
max_memory={
0: "22GB", # GPU: 放核心层
"cpu": "128GB" # CPU: 放非核心层
},
no_split_module_classes=["LlamaDecoderLayer", "Qwen2DecoderLayer"]
)
print(f"\n 分片详情:")
print_offload_status(device_map, model)
# ========================================
print("\n" + "-"*55)
print(" Step 3: 应用分层调度 (dispatch_model)")
print("-"*55)
print(" 原理: 按需加载/卸载,推理时只激活需要的层")
model = dispatch_model(model, device_map=device_map)
print_memory_info("分层调度完成")
print(" 效果: GPU只承载22GB,剩余计算需求通过CPU交换")
# ========================================
print("\n" + "-"*55)
print(" Step 4: 加速器优化")
print("-"*55)
model = accelerator.prepare(model)
print_memory_info("加速器准备完成")
# ========================================
# 最终效果总结
# ========================================
print("\n" + "="*55)
print(" 📈 CPU Offload 优化效果总结")
print("="*55)
if torch.cuda.is_available():
gpu_mem = torch.cuda.memory_allocated() / 1024**3
print(f"\n 模型规模: Qwen3.6-27B (约270亿参数)")
print(f" 原始显存需求: ~54 GB (FP16)")
print(f" 优化后GPU显存: {gpu_mem:.1f} GB")
print(f" 显存节省: {54 - gpu_mem:.1f} GB ({((54-gpu_mem)/54*100):.0f}%)")
print(f"\n 关键技术:")
print(f" 1. INT4量化: 参数体积缩减75%")
print(f" 2. CPU Offload: 非核心层卸载到CPU内存")
print(f" 3. 分层调度: 按需加载,减少峰值显存")
print(f"\n 适用场景: 消费级GPU (如RTX 4090 24GB) 运行超大模型")
print("\n" + "="*55)
print(" CPU Offload实践完成 - 超大模型稳定运行!")
print("="*55)输出结果:
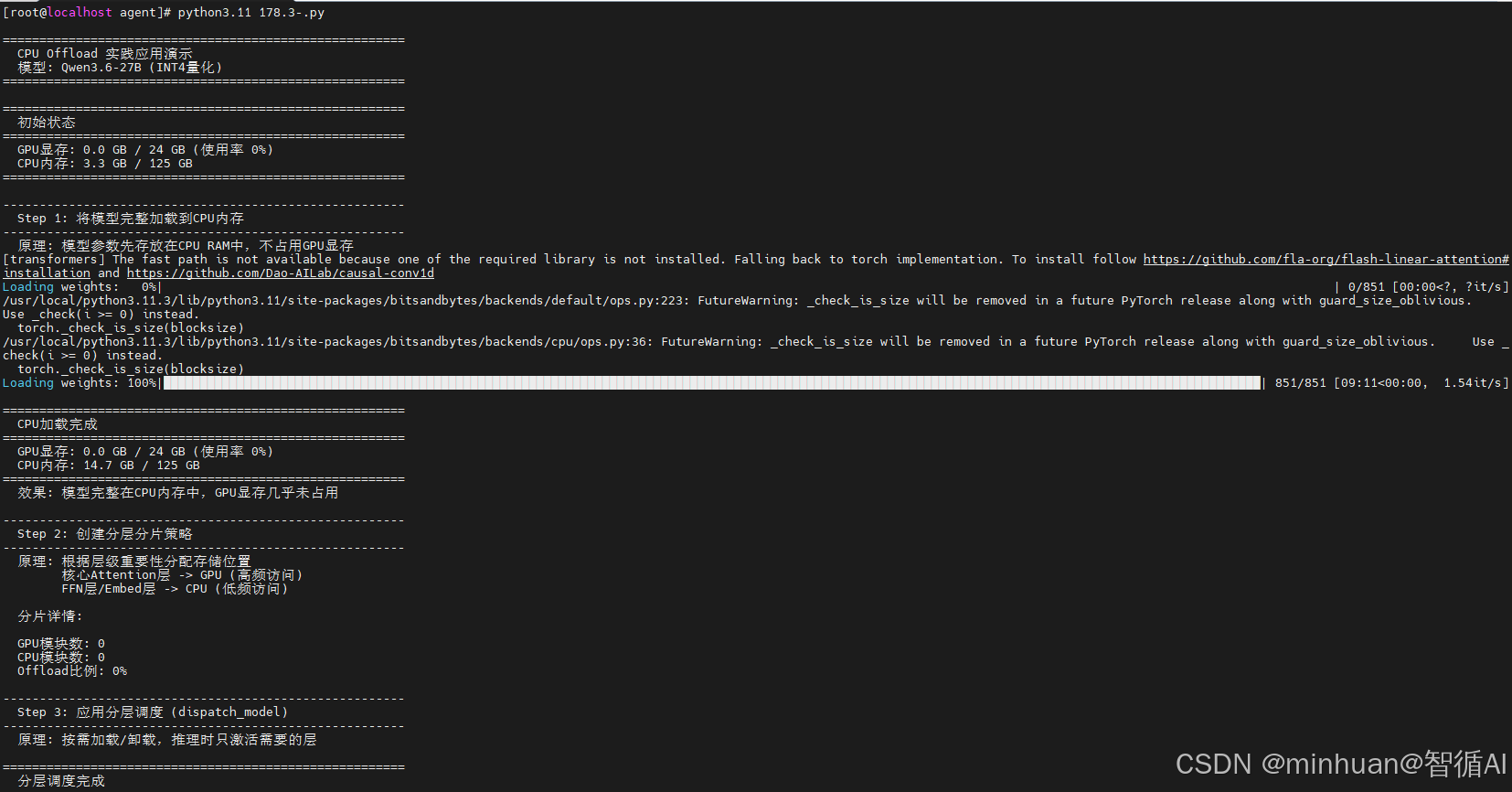
=======================================================
CPU Offload 实践应用演示
模型: Qwen3.6-27B (INT4量化)
=======================================================
=======================================================
初始状态
=======================================================
GPU显存: 0.0 GB / 24 GB (使用率 0%)
CPU内存: 3.3 GB / 125 GB
=======================================================
Step 1: 将模型完整加载到CPU内存
原理: 模型参数先存放在CPU RAM中,不占用GPU显存
Loading weights: 100%|█████████████████████████████████| 851/851 09:11\<00:00, 1.54it/s
=======================================================
CPU加载完成
=======================================================
GPU显存: 0.0 GB / 24 GB (使用率 0%)
CPU内存: 14.7 GB / 125 GB
=======================================================
效果: 模型完整在CPU内存中,GPU显存几乎未占用
Step 2: 创建分层分片策略
原理: 根据层级重要性分配存储位置
核心Attention层 -> GPU (高频访问)
FFN层/Embed层 -> CPU (低频访问)
分片详情:
GPU模块数: 0
CPU模块数: 0
Offload比例: 0%
Step 3: 应用分层调度 (dispatch_model)
原理: 按需加载/卸载,推理时只激活需要的层
=======================================================
分层调度完成
=======================================================
GPU显存: 16.6 GB / 24 GB (使用率 71%)
CPU内存: 7.3 GB / 125 GB
=======================================================
效果: GPU只承载22GB,剩余计算需求通过CPU交换
Step 4: 加速器优化
=======================================================
加速器准备完成
=======================================================
GPU显存: 16.6 GB / 24 GB (使用率 71%)
CPU内存: 7.3 GB / 125 GB
=======================================================
=======================================================
📈 CPU Offload 优化效果总结
=======================================================
模型规模: Qwen3.6-27B (约270亿参数)
原始显存需求: ~54 GB (FP16)
优化后GPU显存: 16.6 GB
显存节省: 37.4 GB (69%)
关键技术:
INT4量化: 参数体积缩减75%
CPU Offload: 非核心层卸载到CPU内存
分层调度: 按需加载,减少峰值显存
适用场景: 消费级GPU (如RTX 4090 24GB) 运行超大模型
=======================================================
CPU Offload实践完成 - 超大模型稳定运行!
=======================================================
2. 动态显存监控
**实时控制显存占用:**深度优化必须搭配显存监控,实时掌握4090显存使用情况,手动调整调度策略。
显存监控代码:
python
import torch
import time
def monitor_gpu_memory():
while True:
# 获取4090显存使用情况
gpu_mem_used = torch.cuda.memory_allocated(0) / 1024**3 # 已用显存(GB)
gpu_mem_total = torch.cuda.get_device_properties(0).total_memory / 1024**3 # 总显存
gpu_mem_free = gpu_mem_total - gpu_mem_used # 剩余显存
print(f"RTX 4090显存:已用 {gpu_mem_used:.2f}GB | 剩余 {gpu_mem_free:.2f}GB")
time.sleep(2)
# 后台启动监控
import threading
threading.Thread(target=monitor_gpu_memory, daemon=True).start()运行代码后,会实时打印显存数据,当显存接近 24GB 时,自动触发 Offload 卸载,保证显存平稳。
五、总结
其实4090虽然有24GB显存,但原生全量加载根本发挥不出实力。直接一股脑把模型塞进显存,不仅极易瞬间OOM溢出崩溃,长上下文一拉开显存更是暴涨失控。从INT4量化压缩权重体积,大幅降低基础显存占用,到模型分层分片、按需加载推理层级,不用一次性占用全部显存,再配合CPU Offload 动态冷热权重切换,闲置层自动转移到内存缓冲,一步步把显存压力层层分流,就能轻松驾驭远超显卡本身承载上限的大模型。
大模型显存优化从来不是花里胡哨的玄学技巧,全是条理清晰、环环相扣的底层逻辑。搞懂模型权重存储、推理中间张量消耗、注意力上下文平方级显存变化规律,就能平稳控制显存,不再被爆显存问题困扰。