目录
[4. SELECT 基础 + WHERE(查询 + 条件过滤)](#4. SELECT 基础 + WHERE(查询 + 条件过滤))
[5. SELECT DISTINCT(去重查询)](#5. SELECT DISTINCT(去重查询))
[6. JOIN(多表关联查询)](#6. JOIN(多表关联查询))
[6.1.1 内连接](#6.1.1 内连接)
[6.1.2. 左连接](#6.1.2. 左连接)
[6.1.3. 右连接](#6.1.3. 右连接)
[5. GROUP BY(分组聚合)](#5. GROUP BY(分组聚合))
[6. ORDER BY(排序)](#6. ORDER BY(排序))
[7. LIMIT(限制结果行数)](#7. LIMIT(限制结果行数))
一、笛卡尔积
把两个集合里的元素,两两全部组合一遍。
举个例子
-
A={1,2}
-
B={x,y}
A×B={(1,x), (1,y), (2,x), (2,y)}
数据库里的含义
在 SQL 中:
-
笛卡尔积 = 两张表不加任何关联条件,直接全排列拼接
-
结果行数 = 表 1 行数 × 表 2 行数
-
不加 WHERE 或 JOIN 条件时,就会出现笛卡尔积,通常是错误 / 冗余的。
无添加任何条件会产生笛卡尔积
语法示例:
sql
-- 笛卡尔积查询(无关联条件)
SELECT
s.student_name,
c.course_name
FROM students s, courses c;执行结果:
| student_name | course_name |
|---|---|
| 张三 | 数学 |
| 张三 | 语文 |
| 张三 | 英语 |
| 李四 | 数学 |
| 李四 | 语文 |
| 李四 | 英语 |
添加where条件(我们日常业务中需要获得的数据)
sql
-- 正确的关联查询(避免笛卡尔积)
SELECT
s.student_name,
c.course_name
FROM students s
JOIN student_course sc ON s.student_id = sc.student_id
JOIN courses c ON sc.course_id = c.course_id;| student_name | course_name |
|---|---|
| 张三 | 数学 |
| 张三 | 英语 |
| 李四 | 语文 |
- 笛卡尔积本质:两个表无关联条件时,行数是两表行数的乘积,是所有行的两两组合。
- 实际应用:笛卡尔积通常是 SQL 编写错误(遗漏关联条件)导致的,会返回大量冗余数据。
- 正确做法 :使用
JOIN+ 关联条件(如主键 / 外键匹配),只获取有业务意义的组合数据。
二、基础语法
创建表
sql
-- 用户表
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT, -- 用户ID(主键、自增)
username VARCHAR(50) NOT NULL, -- 用户名
age INT, -- 年龄
city VARCHAR(50), -- 城市
create_time DATETIME DEFAULT NOW() -- 创建时间
);
-- 订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT, -- 订单ID(主键、自增)
user_id INT, -- 关联用户ID
order_amount DECIMAL(10,2), -- 订单金额
order_status TINYINT, -- 订单状态(0:未支付,1:已支付,2:已取消)
create_time DATETIME DEFAULT NOW(), -- 下单时间
FOREIGN KEY (user_id) REFERENCES users(user_id) -- 外键关联用户表
);1.INSERT(插入数据)
sql
-- 单条插入(指定字段)
INSERT INTO users (username, age, city) VALUES ('张三', 25, '北京');
-- 多条插入(高效批量插入)
INSERT INTO orders (user_id, order_amount, order_status)
VALUES
(1, 99.90, 1),
(1, 159.00, 1),
(2, 299.99, 0);
-- 插入时指定所有字段(需按表结构顺序)
INSERT INTO users VALUES (3, '李四', 30, '上海', '2026-02-22 10:00:00');2.DELETE(删除数据)
删除表中的记录,务必加 WHERE 条件,否则会删除全表数据:
sql
-- 删除指定记录:删除订单ID=2的订单
DELETE FROM orders WHERE order_id = 2;
-- 删除符合条件的记录:删除已取消(状态=2)的订单
DELETE FROM orders WHERE order_status = 2;
-- 清空表(慎用!删除全表数据,自增ID不会重置)
-- DELETE FROM users;
-- 若要重置自增ID,用 TRUNCATE TABLE users;3.UPDATE(更新数据)
修改表中已存在的记录,务必加 WHERE 条件,否则会更新全表:
sql
-- 更新单个字段:将用户ID=1的年龄改为26
UPDATE users SET age = 26 WHERE user_id = 1;
-- 更新多个字段:将订单ID=3的状态改为1(已支付)、金额改为289.99
UPDATE orders
SET order_status = 1, order_amount = 289.99
WHERE order_id = 3;
-- 结合子查询更新:将北京用户的订单状态改为1(谨慎使用)
UPDATE orders
SET order_status = 1
WHERE user_id IN (SELECT user_id FROM users WHERE city = '北京');4. SELECT 基础 + WHERE(查询 + 条件过滤)
sql
-- 基础查询:查询所有字段
SELECT * FROM users WHERE age > 25;
-- 指定字段查询:查询北京用户的用户名和年龄
SELECT username, age FROM users WHERE city = '北京';
-- 多条件组合:年龄20-30且城市为上海/北京
SELECT * FROM users WHERE age BETWEEN 20 AND 30 AND city IN ('上海', '北京');5. SELECT DISTINCT(去重查询)
sql
-- 查询所有有订单的用户ID(去重,避免重复显示同一用户)
SELECT DISTINCT user_id FROM orders;
-- 查询所有用户的城市(去重,只显示唯一的城市名)
SELECT DISTINCT city FROM users;6. JOIN(多表关联查询)
常用 INNER JOIN(内连接)、LEFT JOIN(左连接),关联多个表的字段:
sql
-- INNER JOIN:查询有订单的用户信息+订单金额(只显示两边都有数据的记录)
SELECT u.username, u.city, o.order_amount
FROM users u
INNER JOIN orders o ON u.user_id = o.user_id;
-- LEFT JOIN:查询所有用户信息+对应的订单金额(即使用户无订单也显示,订单金额为NULL)
SELECT u.username, o.order_amount
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id;表 1: students (学生表)
| student_id | name | class_id |
|---|---|---|
| 1 | 小明 | 1 |
| 2 | 小红 | 2 |
| 3 | 小刚 | 3 |
| 4 | 小丽 | NULL |
表 2: classes (班级表)
| class_id | class_name |
|---|---|
| 1 | 一年级一班 |
| 2 | 一年级二班 |
| 5 | 二年级一班 |
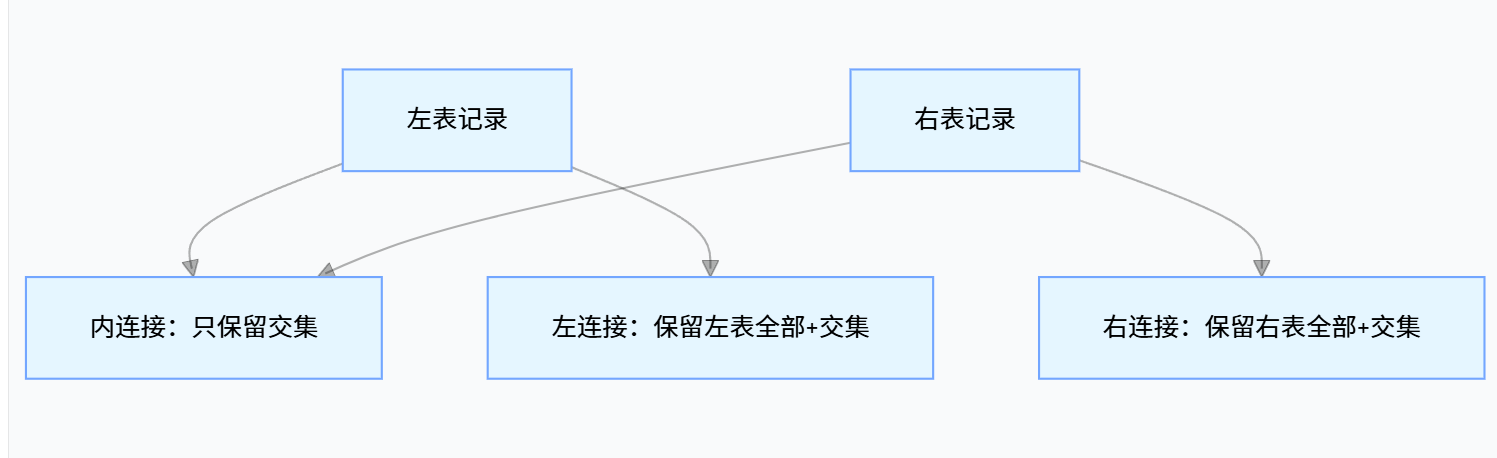
6.1.1 内连接
核心逻辑 :只返回两张表中匹配条件的记录,不匹配的记录会被完全排除。可以理解为:"找两个表的交集"。
语法示例:
sql
SELECT s.student_id, s.name, c.class_name
FROM students s
INNER JOIN classes c ON s.class_id = c.class_id;执行结果:
| student_id | name | class_name |
|---|---|---|
| 1 | 小明 | 一年级一班 |
| 2 | 小红 | 二年级二班 |
只有小明(class_id=1)和小红(class_id=2)在两张表中都有匹配的班级信息,所以只返回这两条。
6.1.2. 左连接
核心逻辑 :以左表 (写在 JOIN 左边的表)为基准,返回左表的所有记录,右表只返回匹配的记录;如果右表没有匹配的记录,对应字段显示 NULL。可以理解为:"左表全要,右表有匹配的就显示,没有就补 NULL"。
语法示例:
sql
SELECT s.student_id, s.name, c.class_name
FROM students s
LEFT JOIN classes c ON s.class_id = c.class_id;执行结果:
| student_id | name | class_name | |
|---|---|---|---|
| 1 | 小明 | 一年级一班 | |
| 2 | 小红 | 一年级二班 | |
| 3 | 小刚 | NULL | -- 班级表没有 class_id=3 |
| 4 | 小丽 | NULL | -- 小丽的 class_id 是 NULL |
6.1.3. 右连接
核心逻辑 :和左连接相反,以右表 (写在 JOIN 右边的表)为基准,返回右表的所有记录,左表只返回匹配的记录;如果左表没有匹配的记录,对应字段显示 NULL。可以理解为:"右表全要,左表有匹配的就显示,没有就补 NULL"。
语法示例:
sql
SELECT s.student_id, s.name, c.class_name
FROM students s
RIGHT JOIN classes c ON s.class_id = c.class_id;执行结果:
| student_id | name | class_name | |
|---|---|---|---|
| 1 | 小明 | 一年级一班 | |
| 2 | 小红 | 一年级二班 | |
| NULL | NULL | 二年级一班 | -- 班级表的 class_id=5 没有匹配的学生 |
总结
5. GROUP BY(分组聚合)
结合聚合函数(SUM/COUNT/AVG)对数据分组统计:
sql
-- 按用户ID分组,统计每个用户的订单总数和总金额
SELECT user_id,
COUNT(order_id) AS order_count, -- 订单数
SUM(order_amount) AS total_amount -- 总金额
FROM orders
GROUP BY user_id;
-- 按城市分组,统计每个城市的用户数(结合WHERE过滤年龄>20的用户)
SELECT city, COUNT(user_id) AS user_count
FROM users
WHERE age > 20
GROUP BY city;| 函数名 | 作用 | |
|---|---|---|
| COUNT() | 统计记录行数(非 NULL 值的数量) | |
| SUM() | 计算数值列的总和 | |
| AVG() | 计算数值列的平均值 | |
| MAX() | 找出列中的最大值 | |
| MIN() | 找出列中的最小值 | |
| GROUP_CONCAT() | 将分组内的字符串拼接成一个字符串(MySQL 特有) |
6. ORDER BY(排序)
对查询结果按指定字段升序(ASC,默认)/ 降序(DESC)排列:
sql
-- 按订单金额降序排列所有订单
SELECT * FROM orders ORDER BY order_amount DESC;
-- 按用户年龄升序、创建时间降序排列用户
SELECT * FROM users ORDER BY age ASC, create_time DESC;
-- 分组后排序:按总金额降序显示每个用户的订单统计
SELECT user_id, SUM(order_amount) AS total_amount
FROM orders
GROUP BY user_id
ORDER BY total_amount DESC;7. LIMIT(限制结果行数)
用于分页或只取前 N 条记录:
sql
-- 取前5条订单记录
SELECT * FROM orders LIMIT 5;
-- 分页查询(第2页,每页10条:跳过前10条,取接下来10条)
SELECT * FROM users LIMIT 10 OFFSET 10;
-- 简写:LIMIT 偏移量, 条数
SELECT * FROM users LIMIT 10, 10;三、SQL书写与执行顺序
| 书写顺序 | 关键字 / 子句 | 执行顺序 | 执行逻辑说明 |
|---|---|---|---|
| 1 | SELECT | 8 | 最后筛选要展示的列(包括计算列、别名) |
| 2 | DISTINCT | 9 | 对 SELECT 的结果去重 |
| 3 | FROM | 1 | 首先确定查询的数据源(表 / 视图 / 子查询) |
| 4 | JOIN ... ON | 2 | 关联 FROM 中的表,根据 ON 条件筛选符合的行 |
| 5 | WHERE | 3 | 对关联后的结果集进行行级过滤(不能用 SELECT 的别名、聚合函数) |
| 6 | GROUP BY | 4 | 按指定字段对 WHERE 过滤后的行分组 |
| 7 | HAVING | 5 | 对 GROUP BY 分组后的结果进行组级过滤(可使用聚合函数) |
| 8 | WINDOW FUNCTION | 6 | 窗口函数计算(如 ROW_NUMBER ()、RANK ()) |
| 9 | ORDER BY | 7 | 对最终结果集排序(可以使用 SELECT 的别名、聚合函数) |