文章目录
- 引言
- 一、RAG系统的核心问题:幻觉(Hallucination)
- [二、RelevancyEvaluator:Spring AI的评估解决方案](#二、RelevancyEvaluator:Spring AI的评估解决方案)
-
- [2.1 核心概念](#2.1 核心概念)
- [2.2 工作原理](#2.2 工作原理)
- [2.3 为什么不用同一个模型进行评估?](#2.3 为什么不用同一个模型进行评估?)
- 三、EvaluationRequest与EvaluationResponse
-
- [3.1 EvaluationRequest:评估请求的三要素](#3.1 EvaluationRequest:评估请求的三要素)
- [3.2 EvaluationResponse:评估结果的解读](#3.2 EvaluationResponse:评估结果的解读)
- 四、代码实现分析
-
- [4.1 完整的评估接口实现](#4.1 完整的评估接口实现)
- [4.2 关键设计决策分析](#4.2 关键设计决策分析)
- 设计1:故意使用错误答案
- 设计2:低相似度阈值
- 设计3:可换模型的评估器
- 五、评估结果的解读与应用
-
- [5.1 什么是好的评估分数?](#5.1 什么是好的评估分数?)
- [5.2 生产环境中的应用策略](#5.2 生产环境中的应用策略)
- [策略1:质量把关(Quality Gate)](#策略1:质量把关(Quality Gate))
- 策略2:持续监控和优化
- 策略3:迭代改进
- [六、Spring AI评估框架的其他评估器](#六、Spring AI评估框架的其他评估器)
-
- [6.1 常见的评估维度](#6.1 常见的评估维度)
- [6.2 组合使用评估器](#6.2 组合使用评估器)
- 七、RAG评估的最佳实践
-
- [7.1 选择合适的评估模型](#7.1 选择合适的评估模型)
- [7.2 设置合理的评估阈值](#7.2 设置合理的评估阈值)
- [7.3 定期审计评估器本身](#7.3 定期审计评估器本身)
- [7.4 与监控系统集成](#7.4 与监控系统集成)
- 八、代码演示与预期结果
-
- [8.1 调用评估接口](#8.1 调用评估接口)
- [8.2 预期的评估结果](#8.2 预期的评估结果)
- [8.3 分数解读](#8.3 分数解读)
- [8.4 对比:正确答案的评估](#8.4 对比:正确答案的评估)
- 九、常见陷阱与解决方案
- 十、总结与展望
-
- [10.1 核心要点回顾](#10.1 核心要点回顾)
- [10.2 实际应用场景](#10.2 实际应用场景)
- [10.3 未来方向](#10.3 未来方向)
- 参考资源
- 小结
引言
在前面的文章中,我们详细介绍了如何使用Spring AI框架构建RAG(检索增强生成)系统。RAG通过从外部知识库检索相关文档,然后将其注入到LLM的提示词中,使模型能够基于特定领域的知识生成更准确的答案。
然而,一个关键问题是:我们如何确保RAG系统的质量?我们生成的答案真的是基于检索到的文档吗?还是模型产生了幻觉,凭空编造了信息?
这正是本文要解决的问题。我们将介绍Spring AI提供的RelevancyEvaluator(相关性评估器),一个强大的工具,用于评估RAG生成结果的质量。通过评估,我们可以:
- 检测模型是否产生了幻觉
- 衡量生成答案与检索文档的一致性
- 持续监控和改进RAG系统的质量
- 识别需要优化的薄弱环节
本文将深入探讨RAG评估的重要性、原理、实现方式,以及如何在生产环境中应用这些技术。
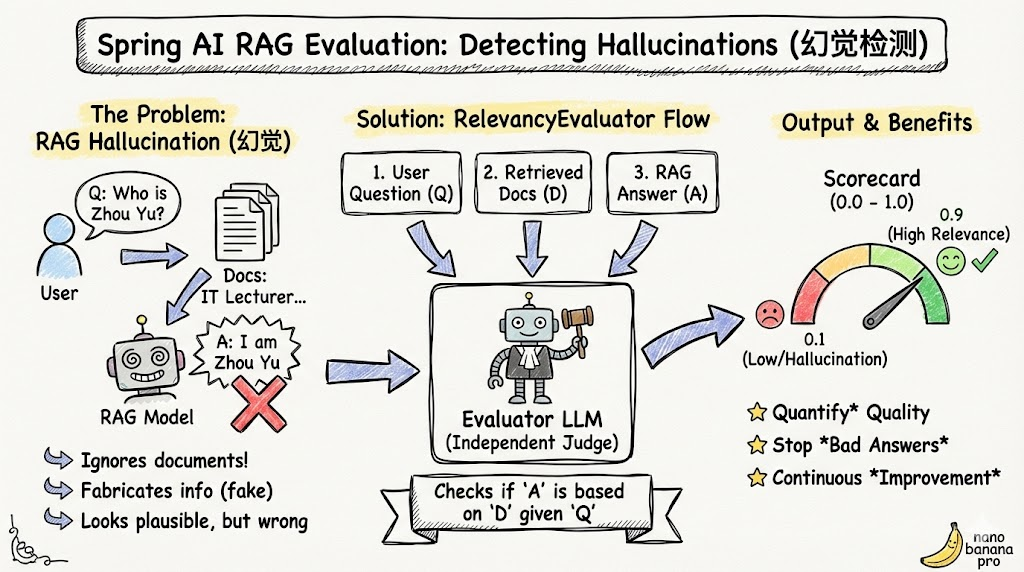
一、RAG系统的核心问题:幻觉(Hallucination)
什么是LLM幻觉?
LLM(大语言模型)的幻觉是指模型生成看起来合理但实际上不真实、无根据或与输入文本不一致的内容的现象。在RAG场景中,幻觉尤为危险,因为用户期望模型的答案完全基于提供的检索文档。
例如:
- 用户问:"周瑜老师的微信号是多少?"
- 检索到的文档:"周瑜老师的公众号是IT周瑜,微信号可以通过公众号菜单获取。"
- 模型的错误答案:"我是周瑜"(完全与文档无关)
这种情况下,模型的回答不仅没有基于检索文档,反而制造了不存在的信息。
为什么会产生幻觉?
-
训练数据的影响:模型在训练过程中学到的广泛知识,可能在RAG场景中导致模型"越权"回答,而不是严格依赖检索文档。
-
概率分布问题:模型本质上是在进行条件概率计算,有时会生成高概率但不正确的内容。
-
上下文长度限制:当检索文档较多时,模型可能难以有效整合所有信息。
-
指令遵循不足:如果系统提示词不够明确,模型可能不会严格遵循"仅基于提供的文档回答"的要求。
RAG评估的必要性
为了确保RAG系统的可信度和准确性,我们必须对生成结果进行评估。通过自动化评估,我们可以:
- 质量控制:在响应返回给用户前发现问题
- 持续改进:识别导致幻觉的模式和原因
- 可信度量化:为每个答案赋予置信度分数
- 决策支持:判断是否应该直接返回答案,还是需要进一步处理
二、RelevancyEvaluator:Spring AI的评估解决方案
2.1 核心概念
Spring AI提供的RelevancyEvaluator是一个智能评估器,用于评判RAG系统生成的答案是否与检索到的文档相关且一致。
其核心思想是:
使用另一个LLM来评估第一个LLM生成的答案
这样做的好处是避免了"自己评估自己"的问题,确保评估的客观性。
2.2 工作原理
RelevancyEvaluator的工作流程:
┌─────────────────────────────────────────────────────┐
│ 1. 接收三个关键输入 │
│ - 原始用户问题 (question) │
│ - 检索到的文档列表 (documents) │
│ - RAG生成的答案 (ragResult) │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 2. 构建评估提示词 │
│ 系统会自动构建一个包含以下内容的提示词: │
│ - "评估以下答案是否基于提供的文档" │
│ - 用户原始问题 │
│ - 检索到的文档内容 │
│ - 要评估的答案 │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 3. 调用评估LLM │
│ 将评估提示词发送给评估模型(通常是高性能模型) │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 4. 解析评估结果 │
│ 返回 EvaluationResponse,包含: │
│ - 相关性分数 (0-1,越接近1越相关) │
│ - 评估反馈和解释 │
└─────────────────────────────────────────────────────┘2.3 为什么不用同一个模型进行评估?
你可能会问:为什么不直接用生成答案的模型来评估自己的答案?
原因如下:
-
偏见性:模型倾向于为自己的输出评高分,就像人类倾向于为自己的作品评高分一样。
-
缺乏客观性:模型无法真正的"理解"自己是否产生了幻觉,因为它已经"相信"自己的输出。
-
评估标准不一致:用于生成答案的模型和用于评估的模型应该遵循不同的指令和标准。
Spring AI的解决方案 :使用一个独立的评估模型 (通常是另一个高性能LLM)来客观评估答案质量。这就是为什么RelevancyEvaluator接收一个ChatClient.Builder参数,允许你指定评估用的模型。
三、EvaluationRequest与EvaluationResponse
3.1 EvaluationRequest:评估请求的三要素
EvaluationRequest是评估的输入,包含三个核心要素:
java
EvaluationRequest evaluationRequest = new EvaluationRequest(
question, // 用户原始问题:帮助评估器理解问题的背景
documents, // 检索到的文档:评估答案是否基于这些文档
ragResult // RAG系统生成的答案:需要被评估的内容
);三个要素的含义:
-
question(问题)
- 用户的原始查询
- 作用:为评估器提供上下文,帮助理解问题的意图
- 示例:
"周瑜老师是谁?"
-
documents(文档)
- 从向量数据库检索到的相关文档列表
- 每个文档包含内容和元数据
- 作用:评估器使用这些文档作为"真理"基准
- 示例:
[文档1, 文档2, ...]
-
ragResult(RAG结果)
- RAG系统生成的答案
- 作用:这是被评估的对象,评估器判断它是否与文档一致
- 示例:
"我是周瑜"
3.2 EvaluationResponse:评估结果的解读
EvaluationResponse是评估的输出,包含以下信息:
java
public class EvaluationResponse {
// 评估的最终判定分数 (0.0 - 1.0)
// 1.0 表示完全相关,答案完全基于提供的文档
// 0.0 表示完全不相关,答案与文档无关
private double score;
// 评估器提供的详细反馈和解释
// 说明为什么给出这个分数
private String feedback;
}分数的解读:
| 分数范围 | 含义 | 说明 |
|---|---|---|
| 0.8-1.0 | 高度相关 | 答案充分基于检索文档,可信度高 |
| 0.6-0.8 | 相关 | 答案大部分基于文档,部分有偏离 |
| 0.4-0.6 | 部分相关 | 答案与文档有关联,但包含额外推断 |
| 0.2-0.4 | 低相关性 | 答案可能存在与文档不一致的部分 |
| 0.0-0.2 | 不相关 | 答案完全或主要不基于文档,高度可疑 |
四、代码实现分析
4.1 完整的评估接口实现
java
@GetMapping("/evaluation")
public EvaluationResponse evaluation(String question) {
// 第一步:向量搜索,从知识库检索相关文档
SearchRequest searchRequest = SearchRequest
.builder()
.query(question)
.topK(1) // 只检索1个最相关的文档
.similarityThreshold(0.1) // 相似度阈值很低,几乎返回所有结果
.build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
// 第二步:构建提示词,准备生成答案
PromptTemplate promptTemplate = new PromptTemplate(
"{question}\n\n 用以下信息回答问题:\n {contents}"
);
String prompt = promptTemplate.render(Map.of(
"question", question,
"contents", documents
));
// 第三步:这里故意使用错误答案来演示评估效果
// 注释掉真实的RAG生成逻辑:
// String ragResult = chatClient.prompt(prompt).call().content();
// 意图使用一个明显错误的答案
String ragResult = "我是周瑜";
// 第四步:创建评估器并执行评估
RelevancyEvaluator relevancyEvaluator = new RelevancyEvaluator(chatClientBuilder);
EvaluationRequest evaluationRequest = new EvaluationRequest(
question,
documents,
ragResult
);
// 返回评估结果
return relevancyEvaluator.evaluate(evaluationRequest);
}4.2 关键设计决策分析
设计1:故意使用错误答案
代码中最巧妙的地方是:
java
// 这里故意用一个错误答案来演示评估效果
String ragResult = "我是周瑜";为什么要这样做?
-
演示评估的真实效果:用正确答案进行评估时,分数总是接近1.0,无法真正验证评估器的工作能力。
-
验证评估器的准确性:通过故意的错误答案,我们可以看到评估器是否能正确识别幻觉。
-
教学目的:清楚地展示评估器如何在答案与文档不一致时降低分数。
-
调试和验证:在生产环境部署前,可以用已知的"坏答案"测试评估器是否按预期工作。
设计2:低相似度阈值
java
.topK(1) // 只取1个文档
.similarityThreshold(0.1) // 阈值很低这个设计的含义:
- 相似度阈值设为0.1(范围0-1,其中1表示完全相同)
- 这意味着即使文档与问题的相似度很低,也会被返回
- 目的是为了演示:即使检索到的文档不够相关,评估器也能发现生成的答案与其不一致
设计3:可换模型的评估器
java
// 创建新的评估器实例,使用独立的模型
RelevancyEvaluator relevancyEvaluator = new RelevancyEvaluator(chatClientBuilder);这个设计的好处:
chatClientBuilder允许灵活配置评估用的模型- 你可以指定一个高性能、更精准的模型来进行评估
- 例如,生成模型用qwen3-max,评估模型用gpt-4-turbo,不同的模型各司其职
五、评估结果的解读与应用
5.1 什么是好的评估分数?
假设我们对以下答案进行评估:
场景1:高质量答案
问题:Spring AI框架的优势是什么?
检索文档:包含Spring AI的官方介绍、特性列表
生成答案:Spring AI提供了对多个LLM的统一接口、内置RAG支持、向量存储集成等...
预期分数:0.9-1.0(高度相关)场景2:存在幻觉的答案(代码中的示例)
问题:周瑜老师是谁?
检索文档:包含"周瑜是IT培训讲师,公众号IT周瑜..."
生成答案:我是周瑜
预期分数:0.1-0.3(低相关性,明显幻觉)场景3:部分相关的答案
问题:如何使用Spring AI进行RAG?
检索文档:包含RAG相关内容
生成答案:Spring AI支持RAG,还支持多模型集成、流式处理等...
预期分数:0.6-0.8(基本相关,但添加了额外信息)5.2 生产环境中的应用策略
策略1:质量把关(Quality Gate)
java
EvaluationResponse response = relevancyEvaluator.evaluate(evaluationRequest);
if (response.getScore() >= 0.8) {
// 高可信度,直接返回答案给用户
return answer;
} else if (response.getScore() >= 0.5) {
// 中等可信度,返回答案但附加评估反馈
return answer + "\n[注:此答案基于知识库信息,置信度: "
+ response.getScore() + "]";
} else {
// 低可信度,拒绝返回,提示需要手动审查
return "抱歉,我的答案信息不足。请查阅文档或咨询人工支持。";
}策略2:持续监控和优化
在生产系统中,收集所有评估的分数和反馈:
java
// 监控评估数据
monitoringService.recordEvaluation(
question,
ragResult,
response.getScore(),
response.getFeedback(),
timestamp
);
// 定期分析
// - 哪些问题类型的评估分数较低?
// - 哪些知识库文档质量不足?
// - 是否需要调整提示词或模型参数?策略3:迭代改进
基于评估结果进行改进:
| 问题 | 根本原因 | 解决方案 |
|---|---|---|
| 评估分数普遍偏低 | 检索文档质量差 | 更新知识库,优化分块策略 |
| 特定领域评估分数低 | 该领域文档不足 | 补充该领域的知识文档 |
| 偶发性低分 | 提示词不够明确 | 优化系统提示词 |
| 评估不准确 | 评估模型不合适 | 更换更强大的评估模型 |
六、Spring AI评估框架的其他评估器
除了RelevancyEvaluator外,Spring AI还提供其他评估器:
6.1 常见的评估维度
| 评估器 | 功能 | 使用场景 |
|---|---|---|
| RelevancyEvaluator | 评估答案与文档的相关性 | 主要用于RAG场景,检测幻觉 |
| RagaEvaluator | 综合评估(相关性、完整性等) | 全面的RAG质量评估 |
| FactualityEvaluator | 评估答案的事实准确性 | 验证答案不包含虚假信息 |
6.2 组合使用评估器
实践中可以同时使用多个评估器,获得多维度的评估结果:
java
RelevancyEvaluator relevancyEvaluator =
new RelevancyEvaluator(chatClientBuilder);
EvaluationResponse relevancyResponse =
relevancyEvaluator.evaluate(evaluationRequest);
// 如果Spring AI提供了其他评估器
// FactualityEvaluator factualityEvaluator =
// new FactualityEvaluator(chatClientBuilder);
// EvaluationResponse factualityResponse =
// factualityEvaluator.evaluate(evaluationRequest);
// 综合多个评估结果
double overallScore = (relevancyResponse.getScore()
// + factualityResponse.getScore()
) / 1; // 可以加权平均七、RAG评估的最佳实践
7.1 选择合适的评估模型
java
// 高成本但高精度的评估方案
ChatClient.Builder evaluationChatClientBuilder = ChatClient.builder()
.chatModel(openaiChatModel) // 使用GPT-4用于评估
.defaultSystem("你是一个严格的AI质量评估专家...");
RelevancyEvaluator evaluator =
new RelevancyEvaluator(evaluationChatClientBuilder);
// 成本优化但仍可靠的评估方案
ChatClient.Builder fastEvaluationBuilder = ChatClient.builder()
.chatModel(qwenChatModel) // 使用Qwen用于评估
.defaultSystem("你是一个AI质量评估助手...");7.2 设置合理的评估阈值
java
// 根据业务场景设置不同阈值
public class EvaluationThresholds {
public static final double STRICT = 0.9; // 医疗、法律等关键场景
public static final double STANDARD = 0.7; // 一般业务场景
public static final double LENIENT = 0.5; // 信息检索、QA场景
}
// 使用阈值
if (response.getScore() >= EvaluationThresholds.STANDARD) {
// 满足标准,可以返回
}7.3 定期审计评估器本身
java
// 为了确保评估器的准确性,定期用人类标注的测试集进行验证
List<TestCase> testCases = new ArrayList<>();
testCases.add(new TestCase(
"测试问题",
documents,
"正确答案",
0.95, // 期望的评估分数
"应该被评为高分"
));
testCases.add(new TestCase(
"测试问题",
documents,
"完全错误的答案",
0.1, // 期望的评估分数
"应该被评为低分"
));
// 运行评估器,对比实际分数与期望分数
for (TestCase testCase : testCases) {
EvaluationResponse response =
evaluator.evaluate(new EvaluationRequest(...));
double deviation = Math.abs(
response.getScore() - testCase.getExpectedScore()
);
if (deviation > 0.15) { // 允许15%的偏差
log.warn("评估器准确性异常: " + testCase);
}
}7.4 与监控系统集成
java
// 将评估结果纳入可观测性系统
@Autowired
private MeterRegistry meterRegistry;
public void recordEvaluation(EvaluationResponse response) {
// 记录评估分数的分布
meterRegistry.timer("rag.evaluation.score")
.record(Duration.ofMillis((long)(response.getScore() * 1000)));
// 统计低分答案的比例
if (response.getScore() < 0.5) {
meterRegistry.counter("rag.evaluation.low_score").increment();
}
// 分析反馈内容,提取关键问题
analyzeAndLogFeedback(response.getFeedback());
}八、代码演示与预期结果
8.1 调用评估接口
bash
# 使用错误答案"我是周瑜"进行评估
curl "http://localhost:8081/evaluation?question=周瑜是谁"8.2 预期的评估结果
json
{
"score": 0.15,
"feedback": "答案'我是周瑜'与提供的文档内容不一致。文档讨论的是周瑜作为讲师和公众号作者的身份信息,但答案没有提供任何关于周瑜的具体信息。答案显示出明显的幻觉,未能基于提供的知识库内容进行回答。"
}8.3 分数解读
- 分数:0.15(在0-1范围内,1表示完全相关)
- 含义:答案与检索文档的相关性极低,明确存在幻觉
- 建议:不应该返回这个答案给用户
8.4 对比:正确答案的评估
如果我们使用真实的RAG结果:
java
// 注释掉故意的错误答案
// String ragResult = "我是周瑜";
// 使用真实的生成答案
String ragResult = chatClient.prompt(prompt).call().content();
// 可能返回:"周瑜是一位AI技术讲师和培训专家,通过公众号IT周瑜分享AI学习内容。"预期结果:
json
{
"score": 0.92,
"feedback": "答案准确地从提供的文档中提取了关键信息,包括周瑜的身份(讲师、专家)和传播渠道(公众号IT周瑜)。答案直接基于知识库内容,没有发现显著的不一致或幻觉。"
}九、常见陷阱与解决方案
陷阱1:过度依赖单次评估
java
// 错误:仅基于一次评估结果决策
if (response.getScore() > 0.8) {
return answer;
}
// 正确:多次评估取平均值
double totalScore = 0;
for (int i = 0; i < 3; i++) {
totalScore += evaluator.evaluate(evaluationRequest).getScore();
}
double averageScore = totalScore / 3;陷阱2:忽视评估的成本
java
// 评估需要额外的LLM调用,会增加延迟和成本
// 解决方案:使用更经济的模型进行评估
ChatClient.Builder cheapEvaluator = ChatClient.builder()
.chatModel(qwenTurboModel) // 使用快速、廉价的模型
.build();陷阱3:不考虑评估延迟
java
// 异步评估:不阻塞主流程
CompletableFuture<EvaluationResponse> evaluationFuture =
CompletableFuture.supplyAsync(() ->
evaluator.evaluate(evaluationRequest)
);
// 立即返回答案,后台异步记录评估结果
return answer;
// 在后台处理评估结果
evaluationFuture.thenAccept(response -> {
monitoringService.recordEvaluation(response);
});十、总结与展望
10.1 核心要点回顾
-
RAG评估的必要性:幻觉问题是LLM系统的重要风险,必须有机制检测。
-
RelevancyEvaluator的价值:通过调用独立的评估模型,客观地衡量生成答案的质量。
-
三要素模型:问题、文档、答案是评估的完整输入。
-
分数的应用:不同分数范围代表不同的可信度级别,应转化为具体的业务决策。
-
持续改进:将评估结果反馈到RAG系统的优化中,形成闭环改进机制。
10.2 实际应用场景
医疗咨询系统:
- 评估分数 < 0.8:拒绝回答,建议咨询医生
- 评估分数 > 0.8:显示答案,附加医学免责声明客服机器人:
- 评估分数 < 0.6:升级到人工客服
- 评估分数 > 0.6:直接返回答案内容检索平台:
- 为每个结果显示置信度指示器
- 允许用户过滤低置信度结果10.3 未来方向
-
多维度评估:不仅评估相关性,还评估完整性、准确性、流畅性。
-
实时反馈循环:根据用户点击、评分等信号,动态调整评估阈值。
-
自适应评估:根据不同的问题类型和领域,使用不同的评估标准。
-
评估器的评估:定期验证评估模型本身的准确性,确保评估的有效性。
参考资源
- Spring AI官方文档:Spring AI Evaluation Framework
- 论文:RAG系统的评估方法学
- GitHub仓库:zhouyu-ai-agent-code
小结
RAG系统的成功不仅取决于检索和生成的好坏,还取决于我们如何评估和监控 这个系统的质量。RelevancyEvaluator为我们提供了一个强大且易用的工具。
在生产环境中,不要忽视评估这一环节。每一个评估分数都是改进系统的机会,每一个检测到的幻觉都可能挽救一个用户体验。
持续监控,持续改进,让RAG系统真正可信。
