打开Anaconda PowerShell
cd 进入指定该文件下,输入jupyter notebook,就能在该目录下打开
python
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({"类别":["小说", "散文随笔", "青春文学","传记"],
"书名":[np.nan, "《皮囊》", "《旅程结束时》", "《老舍自传》"],
"作者":["老舍", None, "张其鑫", "老舍"]})
import pandas as pd
df=pd.read_excel('线上课程-综合测试1-MG公司2019年销售数据试题.xlsx')
df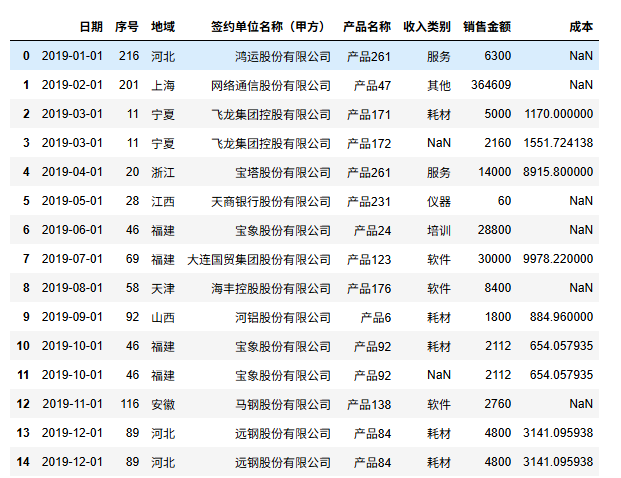
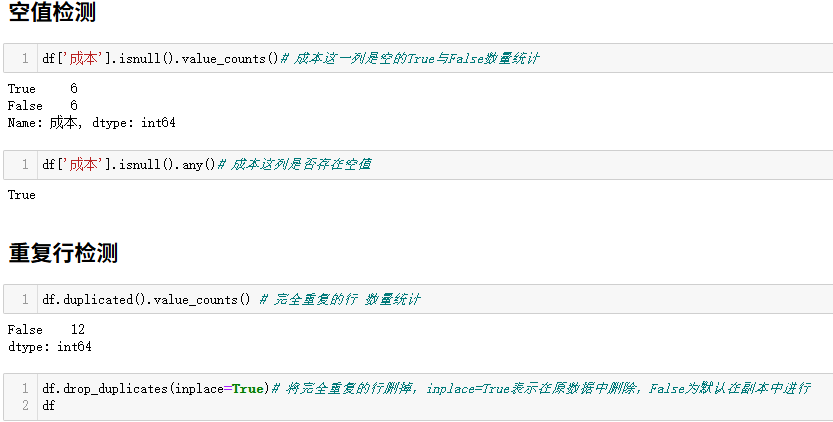
空值检测
python
df['成本'].isnull().value_counts()# 成本这一列是空的True与False数量统计
df['成本'].isnull().any()# 成本这列是否存在空值重复检测
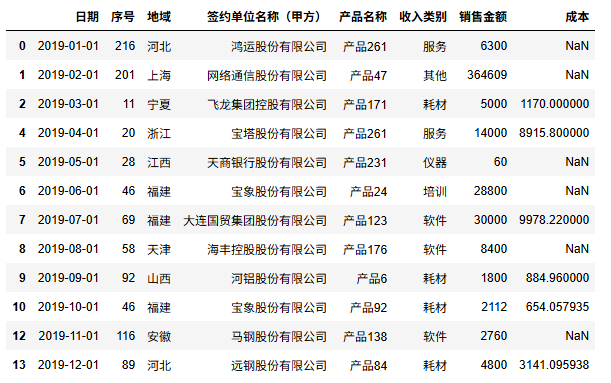
python
df.dropna(subset='收入类别',inplace=True) # subset检查"区域"这列的重复值情况
df