文章目录
- 引言
- 设计说明
-
- [RAG 检索的核心问题](#RAG 检索的核心问题)
- [Advisor 模式的优势](#Advisor 模式的优势)
- 原理方案
-
- [QuestionAnswerAdvisor 的工作流程](#QuestionAnswerAdvisor 的工作流程)
- [默认 Prompt 模板](#默认 Prompt 模板)
- [SearchRequest 的核心参数](#SearchRequest 的核心参数)
- 源码解析
-
- [基础版本:v1.0 的 RAG 接口](#基础版本:v1.0 的 RAG 接口)
- [进阶版本:v2.0 的来源过滤](#进阶版本:v2.0 的来源过滤)
- [filter expression 语法](#filter expression 语法)
- 检索结果的传递机制
- 调试技巧
-
- [开启 Spring AI 的 Advisor debug 日志](#开启 Spring AI 的 Advisor debug 日志)
- [直接调用 VectorStore 验证](#直接调用 VectorStore 验证)
- 验证结果
- 优化建议
-
- [增强版 RetrievalAugmentationAdvisor](#增强版 RetrievalAugmentationAdvisor)
- [Rerank 二次精排](#Rerank 二次精排)
- 小结
引言
文档入库只是 RAG 的一半,更关键的另一半在检索。当用户提问时,系统需要在毫秒级时间内从向量库中召回最相关的若干片段,再将这些片段拼接到 Prompt 中,引导大模型基于事实回答。
Spring AI 通过 QuestionAnswerAdvisor 将这一切封装成了一行链式调用。本篇将深入解析它的工作原理、核心参数,以及如何通过 SearchRequest 精细控制检索行为。
设计说明
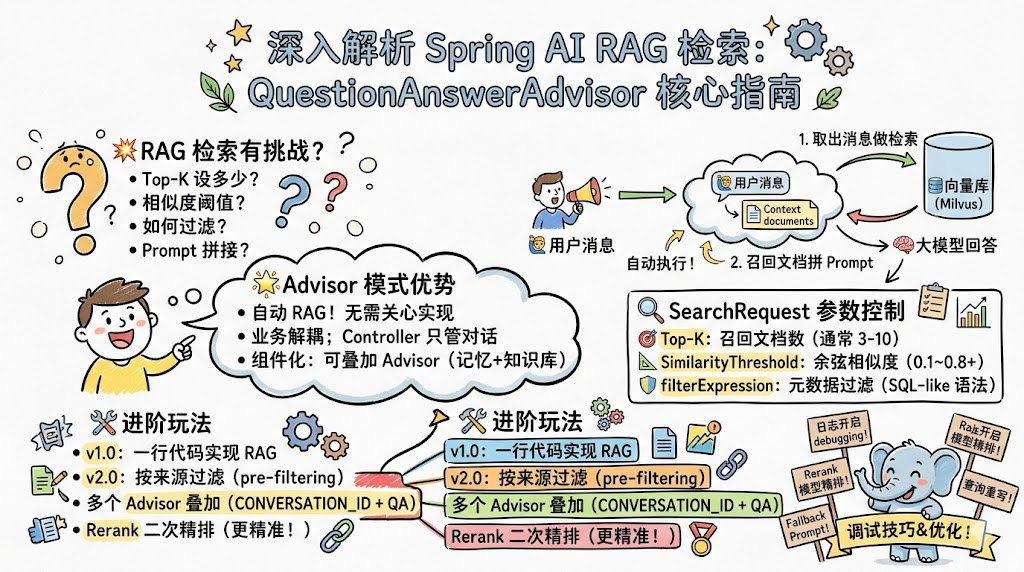
RAG 检索的核心问题
把"检索"做好,要回答几个问题:
- 召回多少:Top-K 设多少?太少漏,太多噪音
- 召回精度:相似度阈值设多少?阈值高漏召回,阈值低引入无关内容
- 如何过滤:能否限定只在某些文档范围内检索?
- 如何拼接:检索到的文档怎么塞进 Prompt?
Advisor 模式的优势
Spring AI 的 Advisor 类似 AOP 切面------你不用关心检索的具体实现,只需要在 ChatClient 调用链中挂上 QuestionAnswerAdvisor,它就会在请求发出前自动完成:
Java
[用户消息] → QuestionAnswerAdvisor.before()
├─ 用 user message 做向量检索
├─ 把召回的文档拼接到 user prompt 末尾
└─ 继续走后续 Advisor → ChatModel这种设计的好处:
- 业务代码与检索逻辑解耦,Controller 只关心"发起对话"
- 多个 Advisor 可以叠加(记忆 + RAG + 日志),互不干扰
- 检索参数可以通过
SearchRequest灵活调整
原理方案
QuestionAnswerAdvisor 的工作流程
Java
ChatClient.prompt().user(message).advisors(qa).stream().content()
│
▼
QuestionAnswerAdvisor.before()
│
├─ 1. 取出 user message
├─ 2. VectorStore.similaritySearch(searchRequest)
├─ 3. 将 Documents 拼接成 context 字符串
├─ 4. 用模板渲染 augmented user message
└─ 5. 替换原 user message
│
▼
[其他 Advisor] → ChatModel
│
▼
QuestionAnswerAdvisor.after()
│
└─ 将 retrieved documents 存入 context
供后续 Advisor 使用默认 Prompt 模板
QuestionAnswerAdvisor 内置了一个默认模板,将检索到的文档作为上下文注入:
Java
{query}
Context information is below.
---------------------
{question_answer_context}
---------------------
Given the context information and no prior knowledge, answer the query.{query} 是用户的原始问题,{question_answer_context} 是召回的所有文档拼接。这个模板保证了大模型"基于上下文回答"而不是凭借训练时的知识。
SearchRequest 的核心参数
java
SearchRequest.builder()
.query("用户的问题")
.similarityThreshold(0.1) // 相似度阈值
.topK(5) // 召回数量
.filterExpression("source in [...]") // 元数据过滤
.build();similarityThreshold:余弦相似度阈值,0~1 之间。值越高匹配越严格。常见取值:
| 阈值 | 适用场景 |
|---|---|
| 0.1~0.3 | 召回为先,宁可多召回也不漏 |
| 0.5~0.7 | 平衡精度和召回 |
| 0.8+ | 严格匹配,类似关键词检索 |
topK:召回的文档数量。一般 3~10 之间,过多会稀释语义,过少容易漏关键信息。
filterExpression:基于元数据的过滤表达式,使用类似 SQL 的语法。这是实现"在指定文件范围内检索"的关键。
源码解析
基础版本:v1.0 的 RAG 接口
java
@Operation(summary = "rag post", description = "Rag对话接口POST版本")
@PostMapping(value = "/rag")
@Loggable
public Flux<String> generatePost(@RequestParam String message) throws IOException {
Long userId = BaseContext.getCurrentId();
return chatClient.prompt()
.user(message)
.system(a -> a.param("current_data", LocalDate.now().toString()))
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId))
.advisors(QuestionAnswerAdvisor
.builder(vectorStore)
.searchRequest(
SearchRequest.builder()
.query(message)
.similarityThreshold(0.1)
.topK(5)
.build()
)
.build())
.stream()
.content();
}关键点解析:
- 链式 Advisor 注册 :
.advisors(QuestionAnswerAdvisor.builder(vectorStore)...)在请求级别添加 RAG 能力 - VectorStore 注入 :
vectorStore是 Spring 自动装配的 Milvus 实例 - 流式输出 :
.stream().content()返回Flux<String>,配合 SSE 实现打字机效果 - 多 Advisor 叠加:CONVERSATION_ID 和 QuestionAnswerAdvisor 同时生效,对话既有记忆又有知识库支持
进阶版本:v2.0 的来源过滤
v2.0 在 RAG 接口中增加了 sources 参数,允许用户限定检索范围:
java
@PostMapping(value = "/rag")
@Loggable
public Flux<String> generatePost(
@RequestParam(value = "sources", required = false) List<String> sources,
@RequestParam(value = "message", defaultValue = "你好") String message) {
// 敏感词前置过滤
List<SensitiveWord> list = sensitiveWordService.list();
for (SensitiveWord sensitiveWord : list) {
if (message.contains(sensitiveWord.getWord())) {
return Flux.just("包含敏感词:" + sensitiveWord.getWord());
}
}
return processNormalRagQuery(sources, message);
}
private Flux<String> processNormalRagQuery(List<String> sources, String message) {
Long userId = BaseContext.getCurrentId();
ChatClient.ChatClientRequestSpec clientRequestSpec = chatClient.prompt()
.user(message)
.system(a -> a.param("current_data", LocalDate.now().toString()))
.advisors(a -> a.param("userMessage", message))
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, userId));
// 如果指定了 sources,使用 filter expression 限定检索范围
if (sources != null && !sources.isEmpty()) {
SearchRequest.Builder searchRequestBuilder = SearchRequest.builder()
.query(message)
.similarityThreshold(0.1)
.topK(5)
.filterExpression("source in " + JSON.toJSONString(sources));
clientRequestSpec = clientRequestSpec
.system(a -> a.param("rag_message", """
如果涉及RAG,请提供文件来源,我会提供给你文件来源,
请严格基于知识库内容回答用户问题,
不要添加任何知识库之外的信息。
"""))
.advisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(searchRequestBuilder.build())
.build());
}
return clientRequestSpec.stream().content();
}filterExpression 详解:
java
.filterExpression("source in " + JSON.toJSONString(sources))如果 sources = ["spring-ai.pdf", "rag-guide.pdf"],则最终表达式为:
source in ['spring-ai.pdf','rag-guide.pdf']Milvus 会在向量检索之前先按这个条件过滤元数据,再做相似度计算。这种"先过滤后检索"的方式比"先检索后过滤"效率高得多。
filter expression 语法
Spring AI 的 filter expression 是数据库无关的抽象语法,常见用法:
java
// 等于
.filterExpression("source == 'doc.pdf'")
// 不等于
.filterExpression("category != 'archive'")
// IN 集合
.filterExpression("source in ['a.pdf','b.pdf']")
// 数值比较
.filterExpression("year >= 2024")
// AND / OR 组合
.filterExpression("source == 'doc.pdf' && page > 10")底层会被翻译成 Milvus 的 boolean expression 语法。
检索结果的传递机制
QuestionAnswerAdvisor 在检索完成后,会把 Documents 存入请求上下文:
java
// QuestionAnswerAdvisor 内部代码(简化)
context.put(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS, documents);后续的 Advisor(比如 v2.0 的 MetadataAwareQuestionAnswerAdvisor)可以从 context 中取出这些 Documents 做二次处理:
java
List<Document> documents = (List<Document>) baseRequest.context()
.get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS);这是 Advisor 之间协作的标准方式。
调试技巧
开启 Spring AI 的 Advisor debug 日志
yaml
logging:
level:
org.springframework.ai.chat.client.advisor: debugSimpleLoggerAdvisor 会打印完整的请求体,包括拼接后的 Prompt:
Java
==> Request:
User: 用户原始问题
Context information is below.
---------------------
[Document 1 内容]
[Document 2 内容]
...
---------------------
==> Response:
[LLM 流式回复]通过观察日志,可以判断:
- 是否成功召回了相关文档
- 召回的文档是否真的包含答案
- Prompt 是否过长(超 token)
直接调用 VectorStore 验证
如果怀疑检索本身有问题,可以绕过 Advisor 直接测试:
java
List<Document> docs = vectorStore.similaritySearch(
SearchRequest.builder()
.query("测试问题")
.topK(5)
.similarityThreshold(0.1)
.build()
);
docs.forEach(doc -> {
System.out.println("Score: " + doc.getMetadata().get("distance"));
System.out.println("Source: " + doc.getMetadata().get("source"));
System.out.println("Text: " + doc.getText());
System.out.println("---");
});验证结果
基础 RAG 测试
前置条件:已上传一份《Spring AI 入门指南》的 PDF。
请求:
Java
POST /api/v1/ai/rag?message=Spring AI的ChatClient怎么用?预期响应(流式):
Java
ChatClient 是 Spring AI 提供的高级抽象,用于简化与大语言模型的交互。
你可以通过 ChatClient.builder(chatModel) 来创建实例...回答的内容应该来自上传的 PDF,而不是大模型的原始知识。
来源过滤测试
请求:
Java
POST /api/v1/ai/rag?sources=spring-ai.pdf&sources=rag-guide.pdf&message=什么是RAG?只会从这两个文件中检索,不会被其他文档干扰。
阈值调整对比
降低阈值(0.1 → 召回宽松):
Java
召回 5 条,包含部分弱相关内容提高阈值(0.7 → 召回严格):
Java
可能召回 0 条,AI 回复"无法在知识库中找到相关信息"阈值的选择需要根据实际数据测试。
优化建议
增强版 RetrievalAugmentationAdvisor
QuestionAnswerAdvisor 是基础款,Spring AI 还提供了 RetrievalAugmentationAdvisor,支持更多高级特性:
java
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
// 检索为空时,返回提示
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(PromptTemplate.builder()
.template("用户查询位于知识库之外。礼貌地告知用户您无法回答")
.build())
.build())
// 查询重写
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(ChatClient.builder(chatModel))
.build())
.build();它的优势:
- 检索为空时可以走 fallback prompt,避免大模型胡编
- 支持 query rewrite,让模糊问题变清晰再去检索
Rerank 二次精排
DashScope 提供了 RerankModel,可以对召回结果做二次排序:
java
@Autowired
private DashScopeRerankModel dashScopeRerankModel;
RetrievalRerankAdvisor retrievalRerankAdvisor = new RetrievalRerankAdvisor(
vectorStore,
dashScopeRerankModel,
SearchRequest.builder().topK(200).build()
);策略是:先 topK=200 粗召回,再用 rerank 模型精排取 top 5。这种"召回-精排"两阶段架构是搜索系统的标准做法。
小结
本篇深入解析了 RAG 的检索阶段:
QuestionAnswerAdvisor用一行代码就把向量检索注入到对话流程中SearchRequest提供了 topK、相似度阈值、filter expression 等精细控制- v2.0 通过 sources 参数 + filter expression 实现了"在指定文件范围内检索"
- 进阶方案:
RetrievalAugmentationAdvisor、Rerank 模型、查询重写
下一篇将聚焦内容安全------敏感词过滤的设计与实现。
