这一篇,咱们聊聊怎么装 Ollama,并把那些动辄几个 G 的模型文件彻底安顿在 D 盘,同时通过手动导入的方法解决大文件限流网络问题。
为什么选择 Ollama
以前要在本地跑个 AI 模型,得配复杂的 Python 环境、装 CUDA 驱动,还要折腾各种依赖包。Ollama 的出现直接把这个门槛降到了零。它就像是模型界的 Docker,你只需要一行命令,它就能自动帮你调度显卡资源,把模型跑起来。
下载ollama
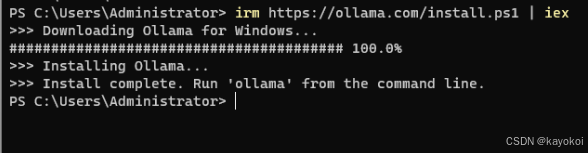
通过ollama部署模型

但是一般会有大文件限流下文会教大家跑满宽带的下载方法,就是部署会相对麻烦点需要手动导入
保卫 C 盘
Ollama 默认会把模型下载到 C 盘的用户目录下。现在的模型动不动就 5GB 起步,下几个模型 C 盘就得爆。所以在安装之前,咱们必须先给它改个家。
第一步,先在 D 盘的 developer 目录下建一个 ollama_models 文件夹。
第二步,用管理员身份打开 PowerShell 7,执行这行命令:
[Environment]::SetEnvironmentVariable("OLLAMA_MODELS", "D:\developer\ollama_models", "User")
这一步是永久性的环境变量修改。执行完之后,一定要记得彻底退出并重启 Ollama 软件。
解决下载慢:手动导入模型文件
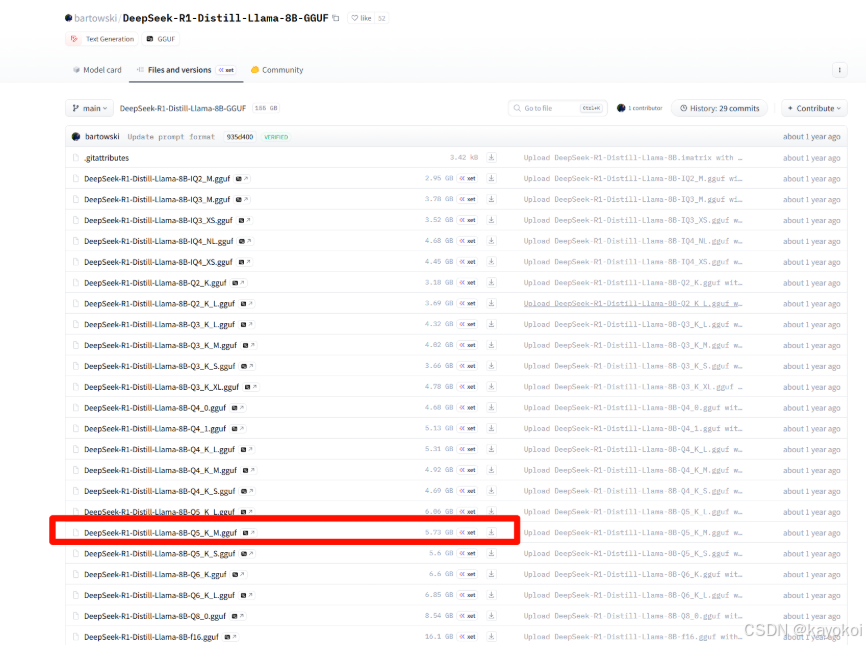
很多人抱怨用 Ollama 命令行下载模型慢得像便秘。其实有个极客通用的"作弊"法:直接去 Hugging Face 或者 ModelScope 下载 .gguf 格式的文件。这些平台支持多线程下载,速度能直接拉满。
博主是5060 8g GPU所以选择了deepseek-r1-8b
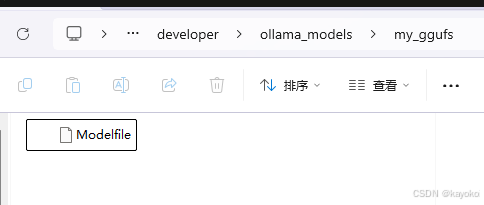
下好文件后,还不能直接用。得在存放 .gguf 文件的目录下建一个名字叫 Modelfile 的文件(注意没后缀),里面写上:
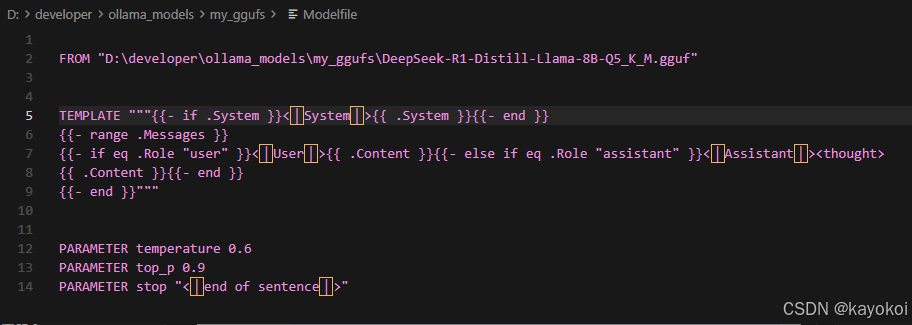
FROM "D:\你的路径\文件名.gguf"
然后回到终端,运行:
ollama create 模型名 -f Modelfile
创建完成后运行ollama run 模型名
然后就可以愉快得使用了