文章目录
-
- 一、为什么需要激活函数?
- 二、激活函数的生物学灵感
- 三、激活函数的核心作用:注入非线性
- 四、常见激活函数详解
-
- [1. Sigmoid 函数](#1. Sigmoid 函数)
- [2. ReLU 函数](#2. ReLU 函数)
- 五、代码实战:激活函数如何改变网络能力?
-
- [1. 准备数据](#1. 准备数据)
- [2. 定义一个简单的神经网络](#2. 定义一个简单的神经网络)
- [3. 可视化结果](#3. 可视化结果)
- 六、激活函数在网络中的位置
- 总结
- 彩蛋:代码逐行解释
在上一章中,我们已经知道,如果没有激活函数,无论神经网络堆叠多少层,它最终都只是一个线性模型,无法拟合复杂的非线性规律。这一章,我们将从生物神经元的工作机制出发,揭开激活函数的神秘面纱,理解它如何为神经网络注入"灵魂",并通过代码直观感受它的作用。
一、为什么需要激活函数?
我们先来看一个直观的例子。假设我们有一个两层的神经网络:
- 第一层: r 1 = b 1 + w 11 x 1 + w 12 x 2 r_1 = b_1 + w_{11}x_1 + w_{12}x_2 r1=b1+w11x1+w12x2, r 2 = b 2 + w 21 x 1 + w 22 x 2 r_2 = b_2 + w_{21}x_1 + w_{22}x_2 r2=b2+w21x1+w22x2
- 第二层: z 1 = b ˉ 1 + w ˉ 11 r 1 + w ˉ 12 r 2 z_1 = \bar{b}1 + \bar{w}{11}r_1 + \bar{w}_{12}r_2 z1=bˉ1+wˉ11r1+wˉ12r2
如果我们把第一层的结果代入第二层,就会发现:
z 1 = b ˉ 1 + w ˉ 11 ( b 1 + w 11 x 1 + w 12 x 2 ) + w ˉ 12 ( b 2 + w 21 x 1 + w 22 x 2 ) = ( b ˉ 1 + w ˉ 11 b 1 + w ˉ 12 b 2 ) ⏟ b ? + ( w ˉ 11 w 11 + w ˉ 12 w 21 ) ⏟ α 1 x 1 + ( w ˉ 11 w 12 + w ˉ 12 w 22 ) ⏟ α 2 x 2 \begin{aligned} z_1 &= \bar{b}1 + \bar{w}{11}(b_1 + w_{11}x_1 + w_{12}x_2) + \bar{w}{12}(b_2 + w{21}x_1 + w_{22}x_2) \\ &= \underbrace{(\bar{b}1 + \bar{w}{11}b_1 + \bar{w}{12}b_2)}{b_?} + \underbrace{(\bar{w}{11}w{11} + \bar{w}{12}w{21})}{\alpha_1}x_1 + \underbrace{(\bar{w}{11}w_{12} + \bar{w}{12}w{22})}_{\alpha_2}x_2 \end{aligned} z1=bˉ1+wˉ11(b1+w11x1+w12x2)+wˉ12(b2+w21x1+w22x2)=b? (bˉ1+wˉ11b1+wˉ12b2)+α1 (wˉ11w11+wˉ12w21)x1+α2 (wˉ11w12+wˉ12w22)x2
最终的输出 z 1 z_1 z1 仍然是输入 x 1 , x 2 x_1, x_2 x1,x2 的线性组合。这意味着,没有激活函数的多层神经网络,本质上和一层神经网络没有区别 ,它永远无法拟合像 y = x 3 + 2 x 2 y = x^3 + 2x^2 y=x3+2x2 这样的非线性函数。
二、激活函数的生物学灵感
生物神经元给了我们破解"线性陷阱"的灵感。
- 生物神经元并非简单地传递信号,它有自己的"决定权"。
- 当它接收到的刺激(信号总和)低于某个阈值时,它会保持抑制,不产生任何神经冲动。
- 当刺激高于这个阈值时,它才会被激活,产生一个强烈的神经冲动并传递出去。
这种"阈值判断"的机制,本质上就是一种非线性 行为。激活函数,就是在人工神经网络中模拟这种行为的数学工具。它对线性组合的结果 r r r 进行一次"筛选",决定这个神经元是否被激活,以及激活的强度。
三、激活函数的核心作用:注入非线性
激活函数的核心作用,就是为神经网络引入非线性因素,打破"线性陷阱"。
- 打破线性组合:如果没有激活函数,多层网络等价于单层网络。激活函数的存在,使得每一层的输出都成为上一层输出的非线性变换,从而让整个网络可以逼近任意复杂的非线性函数。
- 万能近似定理:一个包含足够多隐藏层和非线性激活函数的前馈神经网络,可以在紧集上以任意精度逼近任何连续函数。这是深度学习强大能力的理论基石。
- 可导性 :激活函数最重要的特性是可求导。在梯度下降优化过程中,我们需要计算损失函数对参数的梯度,这依赖于激活函数的导数。
四、常见激活函数详解
1. Sigmoid 函数
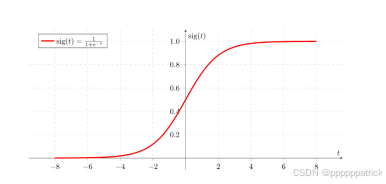
Sigmoid 是最经典的激活函数之一,它将输入映射到 (0, 1) 区间,非常适合表示概率。
-
公式 :
S ( x ) = 1 1 + e − x = e x e x + 1 S(x) = \frac{1}{1 + e^{-x}} = \frac{e^x}{e^x + 1} S(x)=1+e−x1=ex+1ex -
图像 :一条"S"形曲线,输入为0时输出为0.5,输入趋向正无穷时输出趋近1,输入趋向负无穷时输出趋近0。
-
优点:
- 输出范围在 (0, 1) 之间,可作为概率使用。
- 函数平滑,易于求导。
-
缺点:
- 梯度消失 :当输入 x x x 很大或很小时,函数的梯度(斜率)会变得非常小,导致梯度下降更新缓慢,网络难以训练。
- 输出不是以0为中心,会影响后续层的梯度方向。
2. ReLU 函数
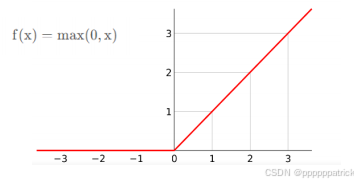
ReLU(Rectified Linear Unit)是目前深度学习中最常用的激活函数,它解决了Sigmoid的梯度消失问题。
-
公式 :
f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) -
图像 :一条在x<0时为0,x≥0时为y=x的折线。
-
优点:
- 缓解梯度消失:在正区间,梯度恒为1,避免了梯度消失。
- 计算速度极快,只需要一个阈值判断。
-
缺点:
- 神经元死亡:当学习率设置过大时,大量神经元的输入可能会恒为负,导致其梯度永远为0,参数永远无法更新,这些神经元就"死亡"了。
五、代码实战:激活函数如何改变网络能力?
代码部分本阶段可以不用看懂,看懂结果就好
想要代码逐行解释的,可以翻到文章最后。
我们通过一个简单的例子,直观地感受一下激活函数的作用。我们的目标是让神经网络拟合一个非线性函数 y = x 3 + 2 x 2 y = x^3 + 2x^2 y=x3+2x2。
1. 准备数据
python
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.linspace(-4, 10, 500)
y_true = x**3 + 2 * x**2
plt.figure(figsize=(12, 4))
plt.plot(x, y_true, label='True function: $y = x^3 + 2x^2$')
plt.title('Target Non-linear Function')
plt.legend()
plt.show()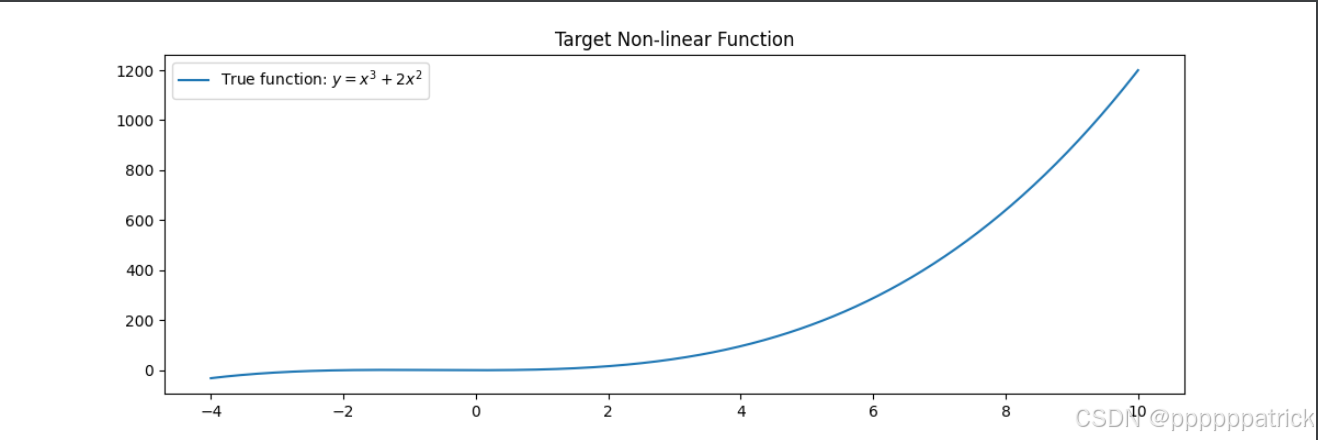
2. 定义一个简单的神经网络
我们定义一个两层的全连接网络,通过控制是否使用激活函数,来观察拟合效果的差异。
python
import torch
import torch.nn as nn
import torch.optim as optim
# 将数据转换为PyTorch张量
x_tensor = torch.tensor(x, dtype=torch.float32).unsqueeze(1)
y_tensor = torch.tensor(y_true, dtype=torch.float32).unsqueeze(1)
# 定义网络
class SimpleNet(nn.Module):
def __init__(self, activation=None):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(1, 64) # 第一层
self.activation = activation # 激活函数
self.fc2 = nn.Linear(64, 1) # 第二层
def forward(self, x):
x = self.fc1(x)
if self.activation:
x = self.activation(x)
x = self.fc2(x)
return x
# 训练函数
def train_model(activation, epochs=1500):
model = SimpleNet(activation)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(epochs):
optimizer.zero_grad()
y_pred = model(x_tensor)
loss = criterion(y_pred, y_tensor)
loss.backward()
optimizer.step()
return model(x_tensor).detach().numpy()
# 训练不同配置的网络
y_pred_no_act = train_model(None) # 无激活函数
y_pred_1_sigmoid = train_model(nn.Sigmoid()) # 1个Sigmoid
y_pred_4_relu = train_model(nn.ReLU()) # 使用ReLU3. 可视化结果
python
plt.figure(figsize=(18, 5))
# 无激活函数
plt.subplot(1, 3, 1)
plt.plot(x, y_true, 'b-', label='True')
plt.plot(x, y_pred_no_act, 'r-', label='Predicted')
plt.title('No Activation Function')
plt.legend()
# 1个Sigmoid
plt.subplot(1, 3, 2)
plt.plot(x, y_true, 'b-', label='True')
plt.plot(x, y_pred_1_sigmoid, 'r-', label='Predicted')
plt.title('With 1 Sigmoid Layer')
plt.legend()
# 使用ReLU
plt.subplot(1, 3, 3)
plt.plot(x, y_true, 'b-', label='True')
plt.plot(x, y_pred_4_relu, 'r-', label='Predicted')
plt.title('With ReLU Activation')
plt.legend()
plt.tight_layout()
plt.show()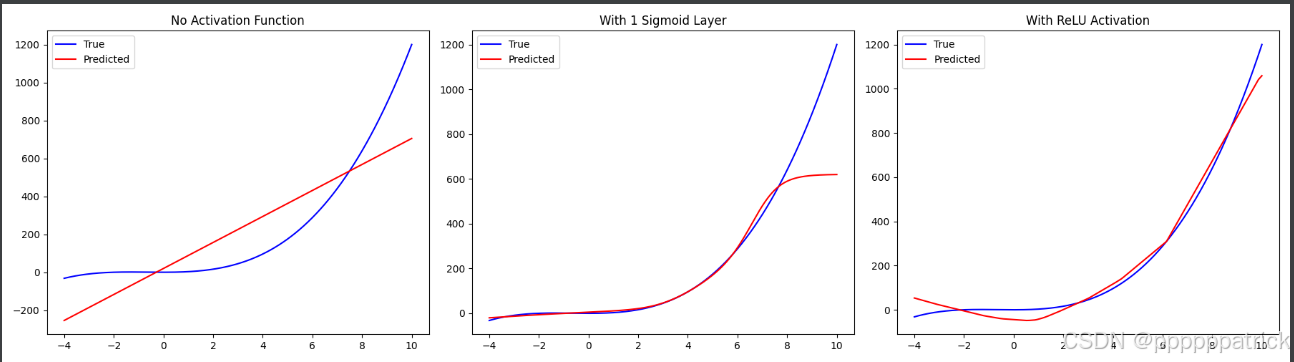
从可视化结果中,我们可以清晰地看到:
- 无激活函数:网络只能拟合出一条直线,完全无法捕捉到目标函数的曲线形态。
- 有激活函数(Sigmoid/ReLU):网络能够很好地拟合出非线性的曲线,尤其是ReLU,拟合效果非常出色。
这直观地证明了:激活函数是神经网络具备强大拟合能力的关键。
六、激活函数在网络中的位置
在神经网络的计算流程中,激活函数通常位于线性层之后:
- 线性组合: r i = b i + ∑ j w i j x j r_i = b_i + \sum_j w_{ij}x_j ri=bi+∑jwijxj
- 激活变换: a i = σ ( r i ) a_i = \sigma(r_i) ai=σ(ri)
这个过程可以用向量形式简洁地表示为:
a = σ ( r ) \boldsymbol{a} = \sigma(\boldsymbol{r}) a=σ(r)
在多层网络中,每一层的输出 a a a 都会作为下一层的输入 x x x,形成一个"线性组合 -> 非线性激活 -> 线性组合 -> ..."的迭代过程。
总结
激活函数是深度学习的"非线性魔法":
- 它从生物神经元的"阈值判断"机制中获得灵感,为神经网络注入了非线性因素。
- 它打破了"线性陷阱",使得多层神经网络真正具备了逼近任意复杂函数的能力。
- Sigmoid 和 ReLU 是两种最具代表性的激活函数,ReLU 因其高效性和对梯度消失的缓解,成为了现代网络的首选。
彩蛋:代码逐行解释
整体功能先说明
这段代码的核心目标是:通过对比"无激活函数""Sigmoid激活""ReLU激活"三种神经网络的拟合效果,直观证明激活函数为神经网络注入非线性的核心作用 ,具体是拟合非线性函数 y = x 3 + 2 x 2 y = x^3 + 2x^2 y=x3+2x2。
逐行详细解释
python
import torch- 功能:导入PyTorch核心库,PyTorch是深度学习主流框架,提供张量运算、神经网络构建、自动求导等核心功能。
- 实战作用:后续所有的张量定义、网络搭建、梯度下降都依赖这个库。
python
import torch.nn as nn- 功能:导入PyTorch的神经网络模块(nn = neural network)。
- 实战作用 :
nn.Module(所有网络的基类)、nn.Linear(全连接层)、nn.Sigmoid/ReLU(激活函数)、nn.MSELoss(损失函数)都来自这个模块。
python
import torch.optim as optim- 功能:导入PyTorch的优化器模块。
- 实战作用 :后续用
optim.Adam(主流优化器)实现梯度下降,更新网络参数。
python
import numpy as np- 功能:导入NumPy库,Python科学计算的核心库,用于生成数据、数值运算。
- 实战作用 :生成拟合用的输入数据
x和真实标签y_true。
python
import matplotlib.pyplot as plt- 功能:导入Matplotlib绘图库,用于可视化数据和拟合结果。
- 实战作用:最后画出"真实函数曲线"和"不同网络的预测曲线",直观对比效果。
python
x = np.linspace(-4, 10, 500)- 语法解析 :
np.linspace(起始值, 终止值, 样本数)→ 生成指定范围内的等间距数值。 - 具体含义 :在
[-4, 10]区间内生成500个均匀分布的数值,作为神经网络的输入特征。 - 实战作用:500个样本足够密集,能画出平滑的函数曲线,避免样本太少导致的可视化失真。
python
y_true = x**3 + 2 * x**2- 语法解析 :
x**3表示x的三次方,2 * x**2表示2倍x的平方,NumPy数组支持逐元素运算。 - 具体含义 :根据非线性函数 y = x 3 + 2 x 2 y = x^3 + 2x^2 y=x3+2x2,计算每个输入
x对应的真实输出(标签)。 - 实战作用 :这是我们要让神经网络拟合的"目标",后续用
y_true计算预测误差(损失)。
python
# 将数据转换为PyTorch张量
x_tensor = torch.tensor(x, dtype=torch.float32).unsqueeze(1)- 分步解析 :
torch.tensor(x, dtype=torch.float32):将NumPy数组x转换为PyTorch张量,指定数据类型为32位浮点数(深度学习主流精度,平衡精度和速度)。.unsqueeze(1):给张量增加一个维度,维度位置为1。- 原
x的形状:(500,)(一维数组,500个元素); - 转换后形状:
(500, 1)(二维张量,500行1列,对应"500个样本,每个样本1个特征")。
- 原
- 实战作用 :PyTorch的
nn.Linear层要求输入必须是二维张量(样本数×特征数) ,不能是一维数组,所以必须用unsqueeze扩维。
python
y_tensor = torch.tensor(y_true, dtype=torch.float32).unsqueeze(1)- 解析 :和
x_tensor逻辑完全一致,将真实标签y_true转换为形状为(500, 1)的32位浮点张量。 - 实战作用:后续计算损失函数时,要求预测值和真实值的形状、数据类型完全一致,否则会报错。
python
# 定义网络
class SimpleNet(nn.Module):- 语法解析 :定义一个名为
SimpleNet的类,继承自nn.Module(PyTorch所有神经网络的基类)。 - 核心规则 :自定义网络必须继承
nn.Module,且必须实现__init__(初始化层)和forward(前向传播)两个方法。 - 实战作用:搭建一个两层的全连接网络,用于拟合目标函数。
python
def __init__(self, activation=None):- 语法解析 :定义类的初始化方法,参数
activation用于指定激活函数(默认值None表示无激活函数)。 - 实战作用 :通过传入不同的激活函数(
None/nn.Sigmoid()/nn.ReLU()),构建三种不同的网络配置,方便对比。
python
super(SimpleNet, self).__init__()- 语法解析 :调用父类
nn.Module的初始化方法,这是PyTorch自定义网络的"必写步骤"。 - 实战作用 :初始化
nn.Module的内部参数(如网络层的权重、偏置),如果不写,后续网络层无法正常工作。
python
self.fc1 = nn.Linear(1, 64) # 第一层- 语法解析 :
nn.Linear(in_features, out_features)→ 定义全连接层(也叫线性层),参数含义:in_features=1:输入特征数(对应x_tensor的列数,每个样本1个特征);out_features=64:输出特征数(该层有64个神经元,输出64维特征)。
- 实战作用:第一层将1维输入映射为64维特征,增加网络的拟合能力(64个神经元足够拟合简单的三次函数)。
- 参数初始化 :
nn.Linear会自动随机初始化权重(w)和偏置(b),无需手动设置。
python
self.activation = activation # 激活函数- 解析 :将初始化方法传入的
activation参数保存为类的属性,后续前向传播时使用。 - 实战作用:灵活控制网络是否使用激活函数、使用哪种激活函数。
python
self.fc2 = nn.Linear(64, 1) # 第二层- 语法解析 :
in_features=64(输入为第一层的64维输出),out_features=1(输出1维,对应目标函数的单值输出)。 - 实战作用:第二层将64维特征映射回1维输出,得到最终的预测值。
python
def forward(self, x):- 语法解析 :定义网络的前向传播方法(
forward是PyTorch的固定命名,不能改),参数x是网络的输入张量。 - 核心规则 :PyTorch会自动根据
forward方法构建反向传播的计算图,无需手动写反向传播。
python
x = self.fc1(x)- 解析 :将输入
x传入第一层全连接层,计算线性组合: x f c 1 = x ⋅ w f c 1 + b f c 1 x_{fc1} = x \cdot w_{fc1} + b_{fc1} xfc1=x⋅wfc1+bfc1。 - 形状变化 :输入
(500, 1)→ 输出(500, 64)。
python
if self.activation:- 解析 :判断是否传入了激活函数(
activation不为None时执行后续代码)。 - 实战作用:实现"有无激活函数"的分支逻辑。
python
x = self.activation(x)- 解析 :将第一层的输出传入激活函数,进行非线性变换。
- 若
activation=nn.Sigmoid(): x = σ ( x f c 1 ) x = \sigma(x_{fc1}) x=σ(xfc1); - 若
activation=nn.ReLU(): x = max ( 0 , x f c 1 ) x = \max(0, x_{fc1}) x=max(0,xfc1); - 若
activation=None:跳过这一步,直接进入第二层。
- 若
- 形状变化 :激活函数是逐元素运算,形状保持
(500, 64)不变。
python
x = self.fc2(x)- 解析 :将激活后的特征(或第一层直接输出)传入第二层全连接层,计算最终预测值: y p r e d = x ⋅ w f c 2 + b f c 2 y_{pred} = x \cdot w_{fc2} + b_{fc2} ypred=x⋅wfc2+bfc2。
- 形状变化 :输入
(500, 64)→ 输出(500, 1)(和真实标签y_tensor形状一致)。
python
return x- 解析:返回网络的最终预测值。
python
# 训练函数
def train_model(activation, epochs=1500):- 语法解析 :定义训练函数,参数:
activation:传入激活函数(控制网络配置);epochs=1500:训练轮数(默认1500轮,足够网络收敛)。
- 实战作用:封装训练逻辑,避免重复代码,方便调用不同激活函数的网络。
python
model = SimpleNet(activation)- 解析 :实例化
SimpleNet类,创建一个指定激活函数的网络模型。 - 实战作用 :每次调用
train_model都会创建一个全新的网络(权重随机初始化),保证不同配置的网络训练公平。
python
criterion = nn.MSELoss()- 语法解析 :实例化均方误差损失函数(MSE = Mean Squared Error),公式: L o s s = 1 N ∑ ( y p r e d − y t r u e ) 2 Loss = \frac{1}{N}\sum (y_{pred} - y_{true})^2 Loss=N1∑(ypred−ytrue)2。
- 实战作用:衡量预测值和真实值的差距,是回归任务(预测连续值)的首选损失函数。
python
optimizer = optim.Adam(model.parameters(), lr=0.01)- 语法解析 :
optim.Adam:选择Adam优化器(比传统梯度下降更高效、稳定);model.parameters():获取网络中所有可训练的参数(fc1和fc2的w和b);lr=0.01:学习率(超参数),控制每次参数更新的步长。
- 实战作用:构建优化器,用于后续反向传播更新参数。
python
for epoch in range(epochs):- 解析 :循环训练
epochs轮,每一轮都会完成"前向传播→计算损失→反向传播→更新参数"的完整流程。
python
optimizer.zero_grad()- 核心作用:清空优化器中所有参数的梯度。
- 关键原因:PyTorch的梯度会累加(如果不清空,本轮梯度会加上上一轮的梯度),导致梯度计算错误,必须在每轮训练前清空。
python
y_pred = model(x_tensor)- 解析 :将输入
x_tensor传入模型,执行前向传播,得到预测值y_pred。 - 形状 :
(500, 1),和y_tensor一致。
python
loss = criterion(y_pred, y_tensor)- 解析 :计算预测值
y_pred和真实值y_tensor的均方误差损失。 - 数值含义:损失值越小,说明预测值越接近真实值,网络拟合效果越好。
python
loss.backward()- 核心作用 :自动反向传播,计算损失函数对所有可训练参数的梯度(
∂Loss/∂w、∂Loss/∂b)。 - 底层逻辑:PyTorch通过计算图自动求导,无需手动推导梯度公式,这是框架的核心优势。
python
optimizer.step()- 核心作用 :根据反向传播得到的梯度,更新网络的参数(
w和b),公式: w = w − l r ⋅ ∂ L o s s / ∂ w w = w - lr \cdot ∂Loss/∂w w=w−lr⋅∂Loss/∂w, b = b − l r ⋅ ∂ L o s s / ∂ b b = b - lr \cdot ∂Loss/∂b b=b−lr⋅∂Loss/∂b。 - 实战作用 :每执行一次
step(),网络参数就会向"损失减小"的方向更新一步,逐步拟合目标函数。
python
return model(x_tensor).detach().numpy()- 分步解析 :
model(x_tensor):训练完成后,用最终的网络参数重新预测输入x_tensor的输出;.detach():将预测张量从计算图中分离(切断梯度关联),避免后续转换NumPy时报错;.numpy():将PyTorch张量转换为NumPy数组,方便后续Matplotlib绘图(Matplotlib不支持张量绘图)。
- 实战作用:返回训练后的网络预测结果,用于可视化对比。
python
# 训练不同配置的网络
y_pred_no_act = train_model(None) # 无激活函数- 解析 :调用
train_model,传入activation=None,训练"无激活函数"的网络,返回预测结果。
python
y_pred_1_sigmoid = train_model(nn.Sigmoid()) # 1个Sigmoid- 解析 :传入
nn.Sigmoid(),训练"第一层后加Sigmoid激活"的网络。
python
y_pred_4_relu = train_model(nn.ReLU()) # 使用ReLU- 解析 :传入
nn.ReLU(),训练"第一层后加ReLU激活"的网络。
核心关键点回顾
- 张量维度 :
unsqueeze(1)是关键,保证输入符合nn.Linear的维度要求(样本数×特征数); - 激活函数逻辑 :通过
if self.activation实现分支,对比有无激活的差异; - 训练流程 :
zero_grad() → 前向传播 → 计算损失 → backward() → step()是PyTorch训练的固定流程; - 数据转换 :
detach().numpy()是张量转NumPy的标准操作,避免梯度关联导致的报错。
通过这些代码,能清晰看到:无激活函数的网络只能拟合直线,而加了Sigmoid/ReLU的网络能拟合非线性曲线,这正是激活函数的核心价值。