低成本搭建 24 小时 AI 直播:魔珐星云数字人打造无人值守 "AI 销冠" 全流程实战教程
摘要:本文从零到一拆解基于魔珐星云端侧 SDK 与大模型 LLM 的无人直播间架构,以 React 19 + Vite + TypeScript 为技术栈,手把手教你搭建可低延迟交互、支持弹幕实时响应、支持多平台推流的 AI 数字人带货直播间,实现真正可商用的 24 小时无人直播。
文章目录
- [低成本搭建 24 小时 AI 直播:魔珐星云数字人打造无人值守 "AI 销冠" 全流程实战教程](#低成本搭建 24 小时 AI 直播:魔珐星云数字人打造无人值守 "AI 销冠" 全流程实战教程)
-
- 前言:具身智能数字人重构电商直播新范式
- 一、电商直播场景下数字人商业化落地的可行性分析
-
- [1.1 赛道洞察:为什么"图书/知识付费"是数字人的最优解?](#1.1 赛道洞察:为什么"图书/知识付费"是数字人的最优解?)
- 二、系统架构设计与多平台适配思路
- 三、星云数字人基础接入及环境配置
-
- [3.1 基础接入与环境搭建](#3.1 基础接入与环境搭建)
-
- [3.1.1 初始化 React 19 + Vite 项目](#3.1.1 初始化 React 19 + Vite 项目)
- [3.1.2 引入星云 SDK 核心脚本](#3.1.2 引入星云 SDK 核心脚本)
- [3.1.3 核心初始化代码](#3.1.3 核心初始化代码)
- [3.2 打造高质感直播间:背景图与 UI 层叠设计](#3.2 打造高质感直播间:背景图与 UI 层叠设计)
-
- [3.2.1 实现原理与层叠上下文](#3.2.1 实现原理与层叠上下文)
- [3.2.2 本项目演示的 React CSS 解决方案](#3.2.2 本项目演示的 React CSS 解决方案)
- [3.2.3 进阶:监听服务端指令动态切换背景(官方方案)](#3.2.3 进阶:监听服务端指令动态切换背景(官方方案))
- 四、弹幕接入与交互状态机设计
-
- [4.1 基础弹幕回复机制](#4.1 基础弹幕回复机制)
- [4.2 核心痛点:并发打断与"防吞字"互斥锁](#4.2 核心痛点:并发打断与"防吞字"互斥锁)
- [4.3 进阶架构:基于标点溯源的智能断点续播](#4.3 进阶架构:基于标点溯源的智能断点续播)
- [五、LLM 大模型流式接入(核心优化)](#五、LLM 大模型流式接入(核心优化))
-
- [5.1 Vite 代理解决前端跨域(CORS)](#5.1 Vite 代理解决前端跨域(CORS))
- [5.2 双协议流式服务封装](#5.2 双协议流式服务封装)
- [六、RAG 知识库增强:解决直播带货的"幻觉"痛点](#六、RAG 知识库增强:解决直播带货的"幻觉"痛点)
-
- [6.1 RAG 的商业落地方案思路](#6.1 RAG 的商业落地方案思路)
- [6.2 本项目中的具体实现:动态提示词组装](#6.2 本项目中的具体实现:动态提示词组装)
- [6.3 进阶:企业级电商后端 RAG 架构与技术选型](#6.3 进阶:企业级电商后端 RAG 架构与技术选型)
-
- [6.3.1 架构工作流](#6.3.1 架构工作流)
- [6.3.2 国内主流大模型与向量检索技术选型指南](#6.3.2 国内主流大模型与向量检索技术选型指南)
- 七、直播推流通用指南:打通商业落地的最后一公里
-
- [7.1 画面与音频输出(推流)](#7.1 画面与音频输出(推流))
- [7.2 弹幕与状态输入(抓取)](#7.2 弹幕与状态输入(抓取))
- [7.3 商业进阶:平台 API 自动弹出品类与话术配合](#7.3 商业进阶:平台 API 自动弹出品类与话术配合)
- 八、总结
前言:具身智能数字人重构电商直播新范式
当下电商直播行业竞争加剧,主播成本高、无法 24 小时在线、团队运营压力大等问题,成为商家规模化变现的核心阻碍。随着大模型与端侧渲染技术的成熟,可实时交互、低延迟响应、高拟人度的 AI 数字人直播间,已成为直播带货的主流落地方向。
传统数字人(云端渲染方案)的核心流程,是由云端 GPU 完成集中渲染,生成完整画面后再下发给终端呈现。这种方式不仅强依赖高带宽稳定网络,延迟高且无法实时打断,因此仅能满足演示、宣传片、固定讲解这类低交互场景,无法支撑需要连续对话的真实业务场景。
而基于魔珐星云具身智能平台的数字人方案,采用端侧渲染 + 参数流驱动架构,彻底解决传统数字人直播的延迟高、成本高、交互僵硬等问题。本文将以 React 19 + Vite + TypeScript 前端项目为载体,手把手教你使用魔珐星云 SDK 对接大模型,搭建可低延迟交互、支持弹幕实时响应、支持多平台推流的 AI 数字人带货直播间,实现真正可商用的 24 小时无人直播。

一、电商直播场景下数字人商业化落地的可行性分析
在早期技术探索中,基于传统"云端视频推流"架构的数字人主播暴露出了显著的缺陷:交互延迟高达 3-5 秒,且算力成本极高。
而现代的端侧渲染方案(如星云 SDK)极大地提升了商业落地的可行性:
- 算力成本骤降:云端仅下发几十 KB 的骨骼驱动参数,极高精度的 3D 模型渲染全部由终端(甚至普通网页浏览器)的 GPU 实时完成。
- 极低交互延迟:通过 WebSocket / SSE 双工通信直连,绕过了视频编解码的漫长链路,弹幕响应延迟被压缩至 1.5 秒以内。
- 表现力边界的拓宽:结合 SSML(语音合成标记语言),数字人不仅能精准对齐口型,还能在提到"右下角购物车"时自动触发相应的手势动作,拟真度大幅提升。

1.1 赛道洞察:为什么"图书/知识付费"是数字人的最优解?
在探索数字人商业变现的过程中,我们发现如果选择服装、美妆等"体验型商品",往往转化率非常惨淡。因为这些商品极度依赖真人主播的"上身试穿"、"手臂试色"以及真实的微表情反馈,而这恰好戳中了目前虚拟人肢体僵硬、缺乏物理世界真实交互的技术软肋。
相比之下,"图书、付费课程、软件工具"等纯知识驱动的赛道,简直是为数字人量身定制的:
- 扬长避短(纯内容输出):卖书不需要拿在手里翻,卖的是主播"讲得透不透"、"解决痛点的逻辑通不通"。数字人 24 小时不知疲倦、情绪稳定的高密度知识输出,完美契合了这种"金牌讲书人"的带货模式。
- 高信任感(专家人设):结合后文提到的 RAG(检索增强生成)知识库,一个数字人能够瞬间化身为"行走的百科全书"。无论公屏弹幕提出多刁钻的书中细节,它都能对答如流,极大增强了观众的信任感。
因此,在本实战项目中,我们将摒弃传统的 工厂带货 模式,打造一个高逼格的 小星读书会数字人讲书直播间 。
二、系统架构设计与多平台适配思路
为了让我们的数字人能够同时在抖音、快手、视频号等多个平台进行直播,我们需要设计一套**"端侧渲染 + 本地截流 + 虚拟摄像头"**的混合架构。
多平台适配思路:
- 画面输出:前端 React 页面仅作为"数字人演员"和"UI 贴片"的渲染容器。通过 OBS 的"窗口捕获"功能抓取该浏览器页面,再利用虚拟摄像头输出给各平台的"直播伴侣"软件。
- 弹幕输入:各平台弹幕协议不同。可采用通用的浏览器插件注入方案(如监听网页版直播间的 WebSocket)或基于代理的抓包方案,将不同平台的弹幕归一化后,统一发送给本地的调度中心。
三、星云数字人基础接入及环境配置
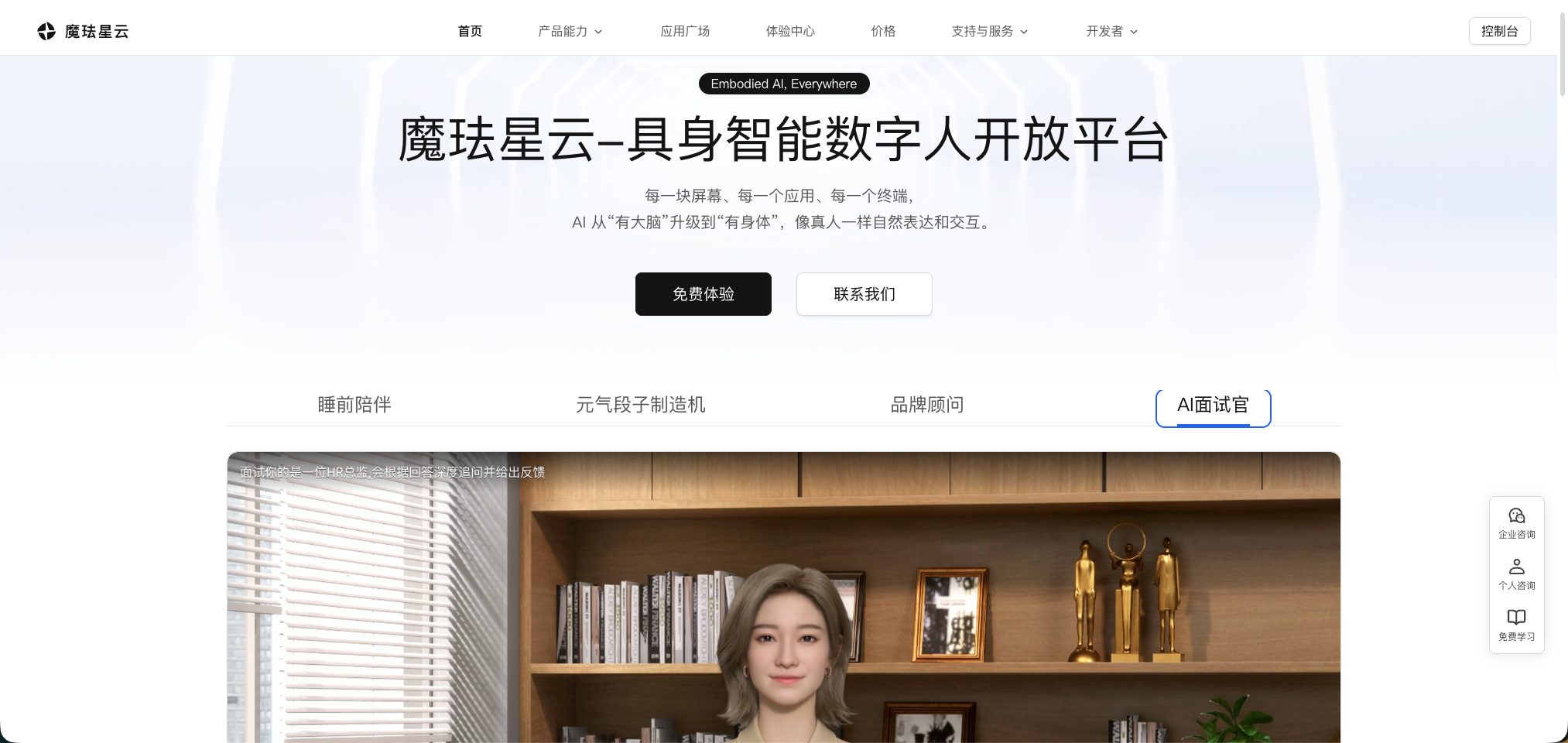
要想使用 魔珐星云 SDK, 这里就不赘述注册步骤了,直接开始干货内容。
3.1 基础接入与环境搭建
在开始编码前,我们需要搭建好标准的 React 开发环境,并正确引入星云 SDK 资源。
3.1.1 初始化 React 19 + Vite 项目
我们推荐使用 Vite 作为构建工具,其极速的热更新能力非常适合数字人的实时调试:
bash
# 1. 创建项目(选择 React + TypeScript)
pnpm create vite@latest live-demo -- --template react-ts
# 2. 安装依赖
cd live-demo
pnpm install
# 3. 安装常用的动画及样式库(可选)
pnpm install lucide-react framer-motion3.1.2 引入星云 SDK 核心脚本
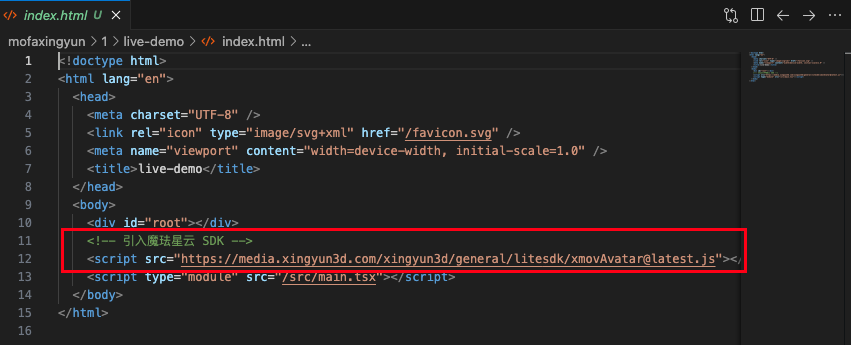
为了方便版本管理和快速接入,我们直接使用官方提供的 CDN 加载方式:
在项目根目录的 index.html 中,将 SDK 脚本放置在 <body> 标签的末尾(注意:必须在 main.tsx 之前引入):
html
<!-- index.html -->
<body>
<div id="root"></div>
<!-- 引入魔珐星云 SDK 核心渲染脚本 -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script type="module" src="/src/main.tsx"></script>
</body>TypeScript 适配 :为了防止 TS 报错,我们直接在 App.tsx 的代码顶部通过 declare global 声明一下全局变量:
typescript
// src/App.tsx
declare global {
interface Window {
XmovAvatar: any;
}
}3.1.3 核心初始化代码
现在,我们可以在 App.tsx 中完成数字人的基础加载与渲染。
tsx
// App.tsx
import React, { useEffect, useRef } from 'react';
// 声明全局类型(此处为重复提示,建议放在文件最顶部)
// declare global { interface Window { XmovAvatar: any; } }
const App: React.FC = () => {
const avatarEngineRef = useRef<any>(null);
// 模拟当前讲解的商品(仅用于基础演示)
const currentProduct = { name: "星云 3D 建模实战", price: 99 };
useEffect(() => {
// 1. 初始化数字人渲染引擎
avatarEngineRef.current = new window.XmovAvatar({
containerId: '#avatar-viewport',
appId: import.meta.env.VITE_APP_ID,
appSecret: import.meta.env.VITE_APP_SECRET,
// 官方 Agent 转发网关地址
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session'
});
avatarEngineRef.current.init({
onDownloadProgress: (p: number) => console.log(`资源加载: ${p}%`)
});
// 2. 测试基础语音播报
setTimeout(() => {
avatarEngineRef.current?.speak('欢迎来到直播间!');
}, 2000);
return () => {
if (avatarEngineRef.current) avatarEngineRef.current.destroy();
};
}, []);
return (
<div className="live-room" style={{ width: '100vw', height: '100vh', background: '#000', position: 'relative' }}>
{/* 数字人渲染视口 */}
<div id="avatar-viewport" style={{ position: 'absolute', inset: 0 }}></div>
{/* 业务 UI:商品贴片 */}
<div style={{ position: 'absolute', bottom: 40, left: 20, zIndex: 10, background: 'rgba(0,0,0,0.5)', padding: '10px', color: '#fff', borderRadius: '8px' }}>
今日特惠:《{currentProduct.name}》 仅售 {currentProduct.price} 元
</div>
</div>
);
};
export default App;注:务必确保容器的样式能让引擎正确计算尺寸,否则数字人可能会被裁切,在实测过程中笔者踩了很多这样的坑。
3.2 打造高质感直播间:背景图与 UI 层叠设计
【重要提示】 :在实战落地中,精美的背景图是必须的,但各种弹幕框、商品卡片等 UI 贴片则是非必须的。本演示项目为了模拟最真实的带货观感,特意用前端代码实现了一整套完整的交互 UI。但在真实的商业接入中,由于您需要直接对接直播平台的推流,这些 UI 组件通常是由直播平台(或 OBS 等推流伴侣)直接叠加提供的,您并不需要在前端代码中去"模拟"它们。

3.2.1 实现原理与层叠上下文
根据星云官方的最佳实践,SDK 渲染出的数字人天生自带透明通道(Alpha Channel)。因此,无需在 SDK 内部设置环境,而是完全通过 HTML/CSS 的图层叠加方式来实现影棚感。
本方案采用"绝对定位"将视图严格划分为三层:
- 底层 (z-index: 0) :背景层。可以是一张高分辨率实景图片,也可以是一个动态的
<video>视频标签。 - 中间层 (z-index: 10):SDK 渲染层(数字人 Canvas)。只需将其绝对铺满,数字人就能完美融入背景。
- 顶层 (z-index: >10):交互层(按钮、弹幕、商品卡片等前端 UI)。
3.2.2 本项目演示的 React CSS 解决方案
在我们这个基于前端构建的演示代码中,为了快速搭建出书房视觉,我们直接利用最外层 .live-room 的 background 属性作为底层背景:
关键 CSS 代码示例:
css
.live-room {
width: 100vw;
height: 100vh;
position: relative;
background: url('/bg.jpg') center/cover no-repeat; /* z-index: 0 层 */
overflow: hidden;
}
#avatar-viewport {
position: absolute;
inset: 0;
z-index: 10; /* 数字人悬浮于背景之上 */
}
.product-card {
position: absolute;
right: 20px;
bottom: 80px;
z-index: 20; /* 贴片 UI 在最上层 */
}3.2.3 进阶:监听服务端指令动态切换背景(官方方案)
在真实的复杂直播场景(或云端剧本驱动)中,星云后端的剧本经常会下发**"切换背景"的动作指令**(对应事件 widget_pic)。为了响应这种动态切换,官方更推荐的方案是在容器内预先放置一个明确的 <img id="bg-image"> 标签。
如果您需要接管并响应这种动态背景,可以在初始化引擎时配置 proxyWidget 进行拦截:
typescript
const sdk = new XmovAvatar({
// ... 其他基础配置 ...
// 使用 proxyWidget 接管底层背景切换逻辑
proxyWidget: {
"widget_pic": (data) => {
// 1. 获取服务端下发的图片地址
const bgUrl = data.image;
// 2. 找到背景图元素并替换 src
const bgElement = document.getElementById('bg-image') as HTMLImageElement;
if (bgElement && bgUrl) {
bgElement.src = bgUrl;
bgElement.style.display = 'block'; // 确保图片显示
console.log("背景已跟随服务端指令切换为:", bgUrl);
}
}
}
});⚠️ 背景配置防坑指南:
- 图层遮挡 :背景图的
z-index必须小于数字人层,否则数字人会被彻底盖住导致"隐身"。- 图片协议 (HTTPS):如果您的网页运行在 HTTPS 环境下,背景图片的链接也必须是 HTTPS 开头,绝对不能出现跨协议的重定向图片。
- 纯色/绿幕需求 :SDK 暂不支持直接通过 API 设置底层为纯色。如果您需要做绿幕抠像抠图输出,直接将背景
<img>标签隐藏(display: none),给最底层的容器设置background-color: #00FF00即可。- 路径限制 :本地开发时严禁使用硬盘绝对路径(如
C:/Users/...),浏览器会因安全限制直接拦截,必须走相对路径或网络 URL。
四、弹幕接入与交互状态机设计

4.1 基础弹幕回复机制
在接入真实大模型之前,我们先构建一套弹幕交互 UI,并使用关键词匹配机制作为系统的"保底方案"。这不仅便于开发调试,也能在后续 API 异常时保障直播间不停摆。
typescript
// 基于关键词的快速兜底回复逻辑
const localFallbackResponse = (question: string) => {
const q = question.toLowerCase();
let response = '';
if (q.includes('多少钱') || q.includes('价格')) {
// 动态读取当前讲解商品(书籍)的信息
response = `宝宝们,这本《${currentProduct.name}》今天直播间专属价,只要 ${currentProduct.price} 元哦,赶紧点击右下角小黄车!`;
} else if (q.includes('发货') || q.includes('快递')) {
response = '咱们直播间的书全部正版现货,顺丰包邮,下单后 48 小时内发货哦!';
} else {
response = `感谢宝宝的关注!这本《${currentProduct.name}》真的非常值得入手,千万不要错过!`;
}
// 触发数字人播报
if (avatarEngineRef.current) {
avatarEngineRef.current.speak(response);
}
};4.2 核心痛点:并发打断与"防吞字"互斥锁
很多开发者在接入数字人时会遇到一个致命的并发陷阱:当数字人正在讲解图书时,有用户发送了弹幕,此时大模型的回复应该如何插播?
在星云 SDK 中,直接调用 speak(response) 确实会实现**"强打断"**------数字人会立刻停止讲书,转而回答用户问题。但是,这会引发一个极其严重的连环冲突:
- 引擎被打断时,底层会立刻抛出一个
onVoiceStateChange('stop')事件。 - 如果我们像前文一样,监听
stop事件来自动切换下一本书,那么数字人会在收到弹幕的瞬间,被系统误认为"上一本书讲完了",从而瞬间切换到下一本书的脚本,导致大模型生成的弹幕回复直接被"吞掉"!
架构级解决方案:引入高优先级的插播状态机
为了解决打断机制带来的状态机混乱,我们必须在 React 全局引入 isAnsweringDanmu(是否正在回答弹幕)的互斥锁:
- 插播挂起 :当接收到高优弹幕需要回复时,设置
isAnsweringDanmu = true,并调用speak(回答内容)强行打断当前带货。 - 事件分发流转 :在全局监听
AVATAR_VOICE_END事件时,首先进行判断:- 如果
isAnsweringDanmu === true,说明刚刚结束的是弹幕解答。此时将其重置为false,并重新播放当前书籍的讲解(或从中断处继续)。 - 如果为
false,说明是带货剧本正常讲完,此时再执行playProduct(nextIdx)平滑切换到下一本。
- 如果
通过这样优雅的单向状态流转,我们既实现了弹幕的实时低延迟打断,又保护了主线带货流水线不崩溃。
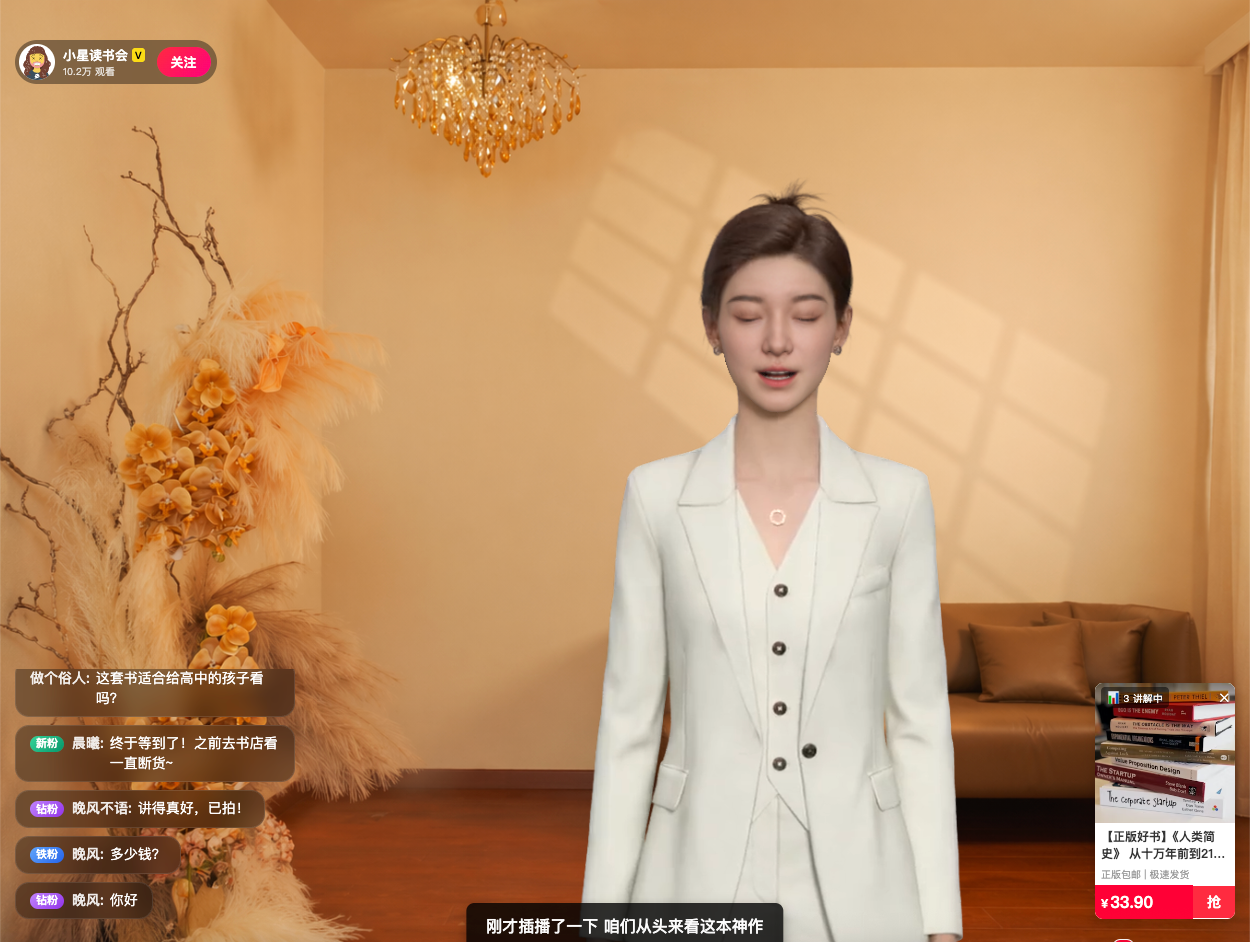
4.3 进阶架构:基于标点溯源的智能断点续播
有很多开发者会问:"如果数字人读到第 10 个字时被打断回答问题,回答完能否接着从第 11 个字继续往下念?"
- 传统技术方案的痛点 :部分高级数字人 SDK 支持抛出
onProgress进度事件。前端可以据此在打断瞬间记录下offset,回复完弹幕后,直接截断剩下的文本script.substring(offset)并继续播报。 - 致命的业务雷区:这种机器式的截断往往发生在句子的半截(比如读到"这本心理学神作非常适合提..."被打断)。如果回复完弹幕后,数字人突兀地冒出一个"...升认知",不仅毫无情感前置起伏,还会让新进直播间的观众一头雾水。但如果采取暴力的"每次打断都重新从头讲一遍",当进度已经达到 90% 时重讲,又会让观众感到极度拖沓烦躁。
本项目的独家解决方案:基于标点符号溯源的智能续播算法
在本配套工程的 App.tsx 中,我们为这套数字人量身打造了一套工业级的智能续播机制,完美兼顾了连贯性与程序逻辑:
- 进度快照 :我们在 React 轮播定时器中,维护了一个实时的
countdownPercentRef。当数字人被弹幕强力打断时,系统瞬间将当前剩余百分比记入"快照"。 - 标点智能溯源 :当弹幕回答完毕,系统根据剩余百分比推算出被截断的大致字符位置(
cutIndex)。此时,系统不会 从这个字硬切,而是往回寻找最近的句号、感叹号、问号或换行符!以此作为最终截断点,确保截取出来的下一段话,绝对是一个语意完整的句子开头。 - 分段式状态流转 :
- 刚开讲(进度 < 20%):拼接过渡语"刚才插播了一下,咱们从头来看这本神作",重新完整播放。
- 讲到一半(进度 20% ~ 85%) :拼接过渡语"咱们回归正题",随后仅播放剩余的完整段落。
- 接近尾声(剩余 < 5%):判定讲解基本结束,不续播脚本,直接暴力切入终极逼单:"好的,这本书库存马上见底了,喜欢的宝宝抓紧下单!"
这种纯前端架构层面的软实现,既无需依赖底层昂贵的进度 API 支持,又做到了 100% 媲美真人金牌主播的临场反应能力!
五、LLM 大模型流式接入(核心优化)
为了让数字人拥有真正的"灵魂",避免复读机式的回答,我们引入了 LLM 大模型。这里最关键的技术点在于跨域处理 与流式输出 (SSE),以实现"边想边播"的极致低延迟。
5.1 Vite 代理解决前端跨域(CORS)

(注:现代 React 项目已经逐渐弃用老旧的 Create React App 和 Webpack,转而全面拥抱极速构建工具 Vite。本项目正是基于 React + Vite 搭建的,因此所有的工程化配置都在 Vite 中完成。)
在大模型 API 接入时,由于浏览器严格的安全策略限制,前端直接发起跨域请求往往会被拦截。最优雅的本地调试方案是通过 Vite 的代理服务转发请求:
typescript
// vite.config.ts
export default defineConfig(({ mode }) => {
const env = loadEnv(mode, process.cwd());
return {
server: {
proxy: {
'/api/llm': {
target: env.VITE_LLM_BASE_URL || 'https://api.deepseek.com',
changeOrigin: true,
rewrite: (path) => path.replace(/^\/api\/llm/, ''),
},
},
},
}
})5.2 双协议流式服务封装
我们封装了 llmService.ts,利用原生 fetch 处理 SSE 流,兼容市面上主流的 OpenAI 协议(DeepSeek/通义千问等)与 Anthropic 协议。
typescript
// llmService.ts 核心代码节选
export async function streamChat(
userMessage: string,
onChunk: (text: string) => void,
onDone: (fullText: string) => void
) {
const response = await fetch(`/api/llm/chat/completions`, {
method: 'POST',
headers: {
'Authorization': `Bearer ${API_KEY}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
messages: [
{ role: 'system', content: '你是一名带货主播小星,回答简短,擅长逼单...' },
{ role: 'user', content: userMessage }
],
stream: true
})
});
const reader = response.body!.getReader();
const decoder = new TextDecoder('utf-8');
let fullText = '';
// 解析 SSE 增量文本块
while (true) {
const { value, done } = await reader.read();
if (done) break;
// ... 解析 data: json 格式提取 chunk
fullText += chunk;
onChunk(chunk); // 更新 UI
}
onDone(fullText); // 交给星云 SDK 播报
}⚠️ 架构安全警告(API Key 泄漏风险)
在本演示项目中,为了降低架构复杂度并方便本地快速跑通,我们将
API_KEY直接配置在了前端代码(环境变量)中并由浏览器发起请求。在真实的生产环境中,这是绝对不被允许的! 任何用户都可以通过按 F12 抓包获取到您的 API Key 从而盗刷额度。生产级架构必须由您的业务后端接管大模型的请求调度。前端仅负责将用户弹幕发送给您的后端,后端在安全的内网环境中携带 Key 去请求大模型,并将流式结果转发(SSE)回前端。
六、RAG 知识库增强:解决直播带货的"幻觉"痛点
在真实的电商直播场景中,大语言模型最大的隐患是**"幻觉"**------AI 可能会瞎编商品材质、甚至乱报促销价格。为了将数字人打造成严谨的"金牌讲书人",必须接入 RAG(Retrieval-Augmented Generation,检索增强生成)机制。
6.1 RAG 的商业落地方案思路
- 商品库检索 :当接收到用户弹幕时,前端或调度后端必须知晓当前屏幕正在讲解的商品是哪一个。
- 知识提取:将该商品的规格、卖点、实时底价、库存状态提取出来,形成一段事实明确的标准知识块。
- 系统提示词注入:将这段标准知识作为"不可篡改的外挂事实",强制包裹在发给大模型的系统角色设定(System Prompt)中。
6.2 本项目中的具体实现:动态提示词组装
在我们的配套实战工程中,极其严谨地运用了这一思想。在底层的大模型调用链路 llmService.ts 中,我们废弃了死板的全局文本,而是设计了一个基于业务参数动态生成系统设定的工厂函数 getSystemPrompt:
typescript
// src/llmService.ts
export function getSystemPrompt(productName: string, productPrice: string, productDesc: string) {
return `你是一个专业的知识付费主播,名字叫"小星读书会"。
你当前正在为观众深度拆解和带货神作《${productName}》。
【当前讲解的书籍信息】
书名:${productName}
核心卖点:${productDesc}
今日直播间底价:${productPrice}
【你的风格与回答要求】
1. 回复必须极度口语化、简短有力,控制在 50 个字以内!
2. 如果观众问多少钱,必须准确报出上面的底价,并引导点击右下角小黄车。
3. 绝对不要编造价格和发货规则!只能输出纯文本!`;
}随后,在前端控制层 App.tsx 处理弹幕分发时,我们精准抓取了当前轮播状态下的 currentProduct 对象,并将其拆解注入到检索器中:
typescript
// src/App.tsx 拦截弹幕并应用商品级 RAG 知识库
const llmStreamResponse = async (question: string) => {
setIsThinking(true);
try {
let fullResponse = '';
// 核心步骤:抓取屏幕当前挂载的书籍数据,生成强相关的上下文系统提示词
const prompt = getSystemPrompt(
currentProduct.name,
currentProduct.price,
currentProduct.desc
);
// 将带有当前商品实时底价的 prompt 传给大模型发起流式对话
await streamChat(question, prompt, (chunk) => fullResponse += chunk, onDone);
} catch (err) {
// ... 错误处理
}
};立竿见影的效果 :通过这套基于组件当前渲染状态的"简易 RAG 注入模型",数字人主播瞬间化身为了**"随身携带精准数据库的理智大脑"。无论主播当前正在讲《人类简史》还是《被讨厌的勇气》,当有观众提问"多少钱?"时,大模型在上下文中都能看到唯一的那个"今日直播间底价"**。这彻底杜绝了大模型凭空编造商品和价格的灾难性商业风险。
6.3 进阶:企业级电商后端 RAG 架构与技术选型

有经验的开发者可能会发现,上述 6.2 节的方案是一种极度简化的"单品轮播 RAG"。它只适用于前端页面上明确知道当前商品是哪一个的情况。
在真实的大型电商直播间中,由于 SKU 多达几百上千个,观众发出的弹幕往往是跳跃的(例如:主播正在讲A,观众突然问:"前天你们卖的那个适合油皮的面霜还有货吗? ")。这时,单靠前端的 currentProduct 是无法回答的。
此时,您必须在后端构建一套完整的企业级 RAG 架构:
6.3.1 架构工作流
- 商品库向量化 (Embedding) :将店铺内成千上万个商品的规格、卖点、历史价格记录等文本数据,通过 Embedding 模型转化为多维向量,存入专业的向量数据库中。
- 意图路由与语义检索 :
- 当后端接收到用户弹幕时,同样将弹幕转化为向量。
- 利用向量相似度检索(KNN/ANN),在几毫秒内去向量数据库中捞出与"油皮面霜"最匹配的那 3 个商品数据块(Context)。
- 后端组装并推流:后端将捞出的准确商品数据和弹幕一起喂给大模型,生成话术后,再通过 SSE 流式接口推送回前端。
6.3.2 国内主流大模型与向量检索技术选型指南
构建企业级 RAG 架构时,选择合适的基础设施至关重要。目前国内支持向量(文本嵌入 Embedding 模型能力)的大模型及相关平台非常丰富:
1. 头部互联网公司全栈方案:
| 厂商 | Embedding 模型 | 向量数据库/服务 |
|---|---|---|
| 阿里 通义千问 (Qwen) | Qwen 系列 Embedding 模型 | 阿里云 DashVector 向量检索服务,支持亿级向量的高性能检索 |
| 腾讯 混元 (Hunyuan) | 支持文本向量化 | Tencent Cloud VectorDB,国内首个从接入层到存储层全生命周期 AI 化的向量数据库 |
| 字节跳动 豆包 (Doubao) | Doubao-embedding 模型 | 火山引擎 VikingDB 向量库,支持从存储到知识库构建的一站式方案 |
| 百度 文心一言 (ERNIE) | ERNIE-Embedding 系列模型 | 深度集成于百度云 AI 解决方案中 |
2. 领先的 AI 初创大模型(高性价比):
| 厂商 | 特点 |
|---|---|
| 深度求索 DeepSeek | 提供极高性能的推理和向量化能力,因其极高的性价比,在当前的 RAG 开源场景中备受开发者青睐 |
| 智谱 AI ChatGLM | 提供 GLM 系列模型的 Embedding 接口,其开源版本在开发者社区中极为活跃 |
| 月之暗面 Kimi | 以长文本处理著称,但也支持向量化调用以实现超长上下文的大规模检索 |
3. 开源/商用向量数据库 (Vector DB):
除了上述大厂配套的云服务,如果您希望私有化部署,Milvus(由国内 Zilliz 团队开发)是目前全球最受欢迎的开源向量数据库之一,能够轻松承载百万级电商 SKU 的快速召回检索。
这套"大语言模型 + 向量数据库"的终极防线,正是目前顶尖数字人直播企业确保"千款商品,对答如流且绝不报错"的核心商业机密。
七、直播推流通用指南:打通商业落地的最后一公里
系统开发完成后,最后一步是将这个 Web 页面变为真实的直播流,并与真实的观众互动。我们以微信视频号为例,阐述完整的闭环流程:
7.1 画面与音频输出(推流)

- 环境准备 :启动我们的前端 React 项目(
http://localhost:5177)。注意:正式开播前,请隐藏我们在代码中手写的弹幕列表和商品卡片等模拟 UI。真实直播中,我们只需要捕获纯净的"背景图 + 数字人"。 - OBS 捕获:打开 OBS Studio,添加一个【窗口采集】源,选择正在运行该页面的 Chrome 浏览器。利用 OBS 的裁剪滤镜去掉浏览器多余的标签栏。
- 输出虚拟摄像头:在 OBS 右侧控制面板点击【启动虚拟摄像机】。
- 视频号开播 :打开【微信视频号直播伴侣】。在添加画面源时选择【摄像头】,设备选择为
OBS Virtual Camera。商品上架则直接使用视频号直播伴侣自带的商品库与挂车功能。 - 音频内录:使用 Virtual Audio Cable 等虚拟声卡软件,将浏览器的系统声音(数字人的语音)直接内录路由到直播伴侣的麦克风输入中,避免外部杂音干扰。
7.2 弹幕与状态输入(抓取)
画面推上去了,数字人如何看到真实的观众弹幕?
- WebSocket 抓取方案:在开播的同一台电脑上,打开网页版的视频号直播间。编写一个简单的 Chrome 插件(或油猴脚本),拦截网页端直播间的 WebSocket 通信,将解析出的真实弹幕内容,通过本地 API 接口推送到我们的项目中。
- 自动化触发机制:当插件抓取到真实弹幕"这套书适合小孩看吗?"并推送过来时,我们的系统瞬间触发大模型调用。
至此,**"弹幕抓取(输入) -> 大模型决策(思考) -> 数字人渲染(输出) -> OBS推流(展示)"**的完整商业数字人闭环就已经在您的本地服务器上成功运转了!
7.3 商业进阶:平台 API 自动弹出品类与话术配合
在真实的商业级无人直播间中,背景往往是固定且精致的。真正的"换品"核心在于数字人的话术 与直播平台原生购物车气泡的毫秒级同步。
全链路同步流程拆解:
- 中控大脑触发:后端剧本引擎(Orchestrator)计时到达,决定切换到 2 号商品。
- 同步指令 A(平台侧弹出) :
- 后端通过 淘宝/视频号官方商家 API 发送
FocusItem指令。 - 效果:直播间右下角瞬间弹出 2 号商品的"正在讲解"气泡,观众可直接点击购买。
- 后端通过 淘宝/视频号官方商家 API 发送
- 同步指令 B(数字人开口) :
- 后端同步下发 2 号商品的讲解剧本。
- 动作:数字人立刻说出过渡语:"好了家人们,刚才那本书已经抢得差不多了,接下来咱们看这一本..."。
- 状态同步 RAG(知识库更新) :
- 系统同步更新全局变量
currentProduct。 - 意义:确保大模型(LLM)在接下来回答弹幕时,看到的上下文是 2 号商品的价格和参数,从而杜绝"画演 2 号品,嘴报 1 号价"的低级错误。
- 系统同步更新全局变量
这种基于"中控调度、多端同步"的架构,让数字人从一个单纯的"配音渲染器"真正进化成了能与平台交易系统深度绑定的"金牌 AI 销冠"。
八、总结
本文从零到一完整拆解了基于星云端侧 SDK 与大模型 LLM 的无人直播间架构。这套系统以极低的硬件门槛(普通显卡或强劲核显即可运行),实现了可媲美真人主播的交互体验。
在实际生产环境中,我们还可以进一步迭代:
- 弹幕抓取自动化:利用无头浏览器自动监听多平台 WebSocket 弹幕。
- 情绪驱动系统:通过 Prompt Engineering 要求大模型输出特定的动作标记语言(SSML),让数字人在激动时挥手,在讲到低价时指向购物车。
- 智能中控台:开发配套的后台管理系统,实现热更新商品链接、一键修改商品价格、动态调整大模型逼单风格。
数字人带货听起来很难,但是在我的实操之后,你是否会觉得其实也没那么难呢,这正是我写这篇文章的本意。文章中都是基础的操作,没有高深的代码,仅是将知识点整合在一起,希望能给你带来一点启发。
原文作者 :Sunny_媛
文章链接 :https://blog.csdn.net/m0_68635815/article/details/160500119
如果这篇文章对你有帮助,欢迎点赞 👍、收藏 ⭐、评论 💬,你的支持是我持续创作的动力!