这个项目叫 free-claude-code ,GitHub 地址:github.com/Alishahryar1/free-claude-code。
截至 2026-04-28,它已经收获 3k+ Star、592 Fork,在过去两周内以几乎病毒式的速度在开发者社区扩散。我在 X(前 Twitter)上看到有人发帖说:
"Goodbye Claude Code subscription fees. Someone just built a proxy that runs Claude Code completely free... and it's wild."
然后我就去看了。然后我就睡不着了。
这个项目是干什么的?
一句话:它是一个本地 FastAPI 代理服务器,拦截 Claude Code 的 Anthropic API 请求,悄悄转发给免费/低成本的替代后端。
Claude Code 本人完全不知道发生了什么------它以为自己还在愉快地和 Anthropic 服务器通信,实际上请求已经被偷梁换柱,转到了 NVIDIA NIM、OpenRouter、DeepSeek、LM Studio 或 llama.cpp。
Claude pro 和 max 充值的话对国内用户不太友好,想体验正版的还是推荐代订阅,地址:claudemax.shop
整个架构如下:
架构示意:
css
Claude Code CLI/VSCode
↓ Anthropic API 格式
Free Claude Code 代理 (:8082)
├── 格式转换 + 路由
├── 请求拦截优化(5 类本地响应)
└── Thinking Token 处理
↓ OpenAI 兼容格式
NVIDIA NIM / OpenRouter / DeepSeek / LM Studio / llama.cpp最精妙的设计:Claude Code 客户端全程以为自己在和 Anthropic 通信,代理层完全透明。不需要修改 Claude Code 本身,不需要 fork,不需要打补丁------只需要设置两个环境变量。
为什么这件事值得认真对待?
让我先算一笔账。
我是个同时做量化策略和维护内部工具链的人,Claude Code 对我来说不是"玩具",是每天必用的生产工具。原来用 Claude Max 计划,每个月 $100--200。
用这个方案: $0。
NVIDIA NIM 提供每分钟 40 次免费请求,对于日常开发来说绰绰有余(你一分钟能发出去 40 次 API 请求吗?大多数时候你还在想怎么写需求描述呢)。
五大后端,各有绝活
表格1:后端提供商全对比
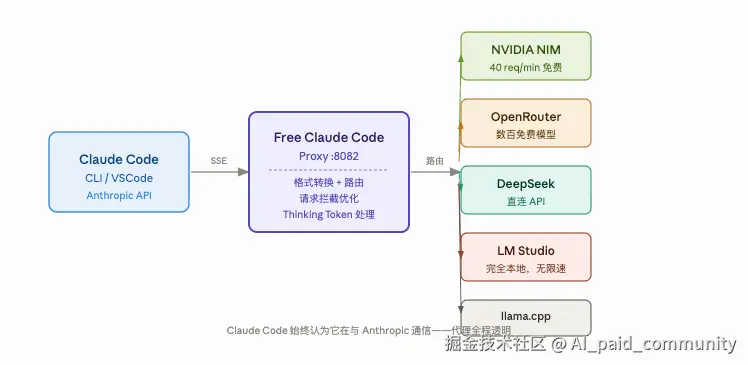
NVIDIA NIM(强烈推荐) :免费、40 req/min,可以跑 Kimi K2 Thinking、GLM-5、Qwen3.5-397B 等主流模型。对大多数开发者来说,这个配额根本用不完。申请 API Key 只需要去 build.nvidia.com/settings/api-keys,两分钟搞定。
OpenRouter:免费模型选择丰富,包括 DeepSeek R1 free、Step-3.5-flash free、GPT-OSS-120B free 等,适合想"大乱炖"、多模型切换的玩家。缺点是免费模型的稳定性参差不齐。
DeepSeek :直连 API,deepseek-chat 和 deepseek-reasoner 都支持,价格比 Opus 便宜一个数量级,推理任务特别好使。
LM Studio / llama.cpp:完全本地运行,无限速,对隐私敏感的场景(金融数据处理、内部代码库)是真正的救星。代价是你需要有块够用的 GPU------作为一个量化狗,这个条件我勉强满足。
安装配置:比你想象的简单 10 倍
整个流程说起来简单到让人不敢置信:
Step 1:安装 uv(Python 包管理器)
pip install uvStep 2:克隆项目,配置 .env
bash
git clone https://github.com/Alishahryar1/free-claude-code.git
cd free-claude-code
cp .env.example .env编辑 .env,以 NVIDIA NIM 为例:
ini
NVIDIA_NIM_API_KEY="nvapi-你的key"
MODEL_OPUS="nvidia_nim/moonshotai/kimi-k2-thinking"
MODEL_SONNET="nvidia_nim/mistralai/devstral-2-123b-instruct-2512"
MODEL_HAIKU="nvidia_nim/stepfun-ai/step-3.5-flash"
MODEL="nvidia_nim/z-ai/glm4.7"
ENABLE_THINKING=trueStep 3:启动代理服务器
yaml
# 终端1:启动代理
uv run uvicorn server:app --host 0.0.0.0 --port 8082Step 4:启动 Claude Code
ini
# 终端2:启动 Claude Code
ANTHROPIC_AUTH_TOKEN="freecc" ANTHROPIC_BASE_URL="http://localhost:8082" claude就这样。 Claude Code 已经在用你配置的免费后端了,界面和功能完全一致。
如果你和我一样懒,可以直接包安装:
bash
uv tool install git+https://github.com/Alishahryar1/free-claude-code.git
fcc-init # 初始化配置
free-claude-code # 启动服务推荐的模型组合搭配
图表2:三套推荐方案
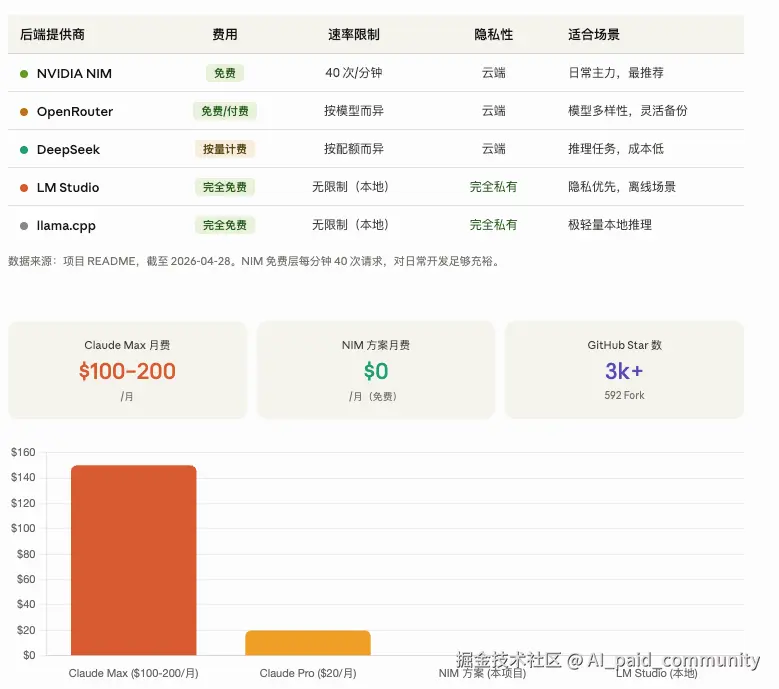
根据实测和社区反馈,给三种使用场景的推荐组合:
方案一:NIM 全套(零成本日常主力)
这是我自己在用的配置:
- Opus(重任务)→
kimi-k2-thinking:复杂重构、架构设计,有 Thinking 模式加持,推理深度足够 - Sonnet(日常)→
devstral-2-123b:Mistral 的专业编码 Agent 模型,123B 参数,日常写代码扔这里就行 - Haiku(快速)→
step-3.5-flash:闪电快,用来做简单任务、快速问答
方案二:NIM + OpenRouter 混合
Opus 用 NIM 的 Kimi K2,Sonnet 用 OpenRouter 的 DeepSeek R1 free,Haiku 拉本地 LM Studio。适合想要多样性、同时有点本地算力的用户。
方案三:纯本地(极致隐私)
如果你的代码库里有敏感数据(比如我的策略参数),全本地是唯一选择:
- Opus → MiniMax-M2.5-GGUF
- Sonnet → Qwen3.5-35B-A3B-GGUF
- Haiku → GLM-4.7-Flash-GGUF
需要的 GPU 显存:至少 24GB 起,48GB 比较舒服。
项目的"隐藏黑科技":不只是简单转发
我仔细看了一遍源码,发现这个项目做的事情远比"简单代理"复杂:
1. 请求优化拦截(Request Optimization)
Claude Code 在运行过程中会发出大量"配额探测"请求------问模型"你能用吗"、"帮我生成个标题"、"猜一下文件路径"......这些请求占了不少配额,但不需要真正的 LLM 来回答。
项目把这 5 类请求直接在本地拦截响应,省配额、降延迟:
ini
FAST_PREFIX_DETECTION = true # 前缀探测本地处理
ENABLE_NETWORK_PROBE_MOCK = true # 网络探测本地模拟
ENABLE_TITLE_GENERATION_SKIP = true # 标题生成跳过
ENABLE_SUGGESTION_MODE_SKIP = true # 建议模式跳过
ENABLE_FILEPATH_EXTRACTION_MOCK = true # 文件路径提取本地处理2. Thinking Token 处理
有些模型(比如 kimi-k2-thinking)输出 <think> 标签格式的思考过程,Anthropic API 格式用的是原生 thinking blocks。代理自动完成格式转换,让 Claude Code 看到的永远是它习惯的格式。
3. 工具调用解析(Heuristic Tool Parser)
有些模型在输出 tool call 时用的是纯文本格式,而不是结构化的 JSON。代理内置了启发式解析器,自动把文本格式的工具调用转成结构化 tool use。这解决了很多开源模型接入 Agent 框架时的兼容性问题。
4. 智能限速(Smart Rate Limiting)
- 主动滚动窗口限速(proactive rolling-window throttle)
- 响应式 429 指数退避(reactive exponential backoff on 429)
- 可选并发上限(PROVIDER_MAX_CONCURRENCY)
遇到 API 限速不会直接崩,会优雅等待重试。
5. Discord / Telegram Bot 集成
这个功能让我眼前一亮:可以把 Claude Code 接到 Discord 或 Telegram 频道,远程给 Claude 发任务,看着它实时工作。
ini
# Discord 配置
MESSAGING_PLATFORM="discord"
DISCORD_BOT_TOKEN="你的 bot token"
ALLOWED_DISCORD_CHANNELS="频道ID"
CLAUDE_WORKSPACE="./agent_workspace"配置好之后,你可以在手机上的 Discord 给 Claude 发一个需求,它会在服务器上开始写代码,实时把进展(包括 Thinking Token 和工具调用)发回频道。支持多并发 session,支持 tree-based 分支对话。
这个功能对于"睡觉前给 AI 分配任务,早上起来看结果"的使用场景太适合了。量化策略回测可以这样搞,我已经在实测了。
我的实测体验
说说我真正用下来的感受。
测试环境:NVIDIA NIM,kimi-k2-thinking 作为 Opus,devstral-2-123b 作为 Sonnet
任务1:重构一个 500 行的 Python 数据清洗脚本
效果:和原生 Opus 4.6 相比,kimi-k2-thinking 在这个任务上几乎无缝。理解代码逻辑的速度很快,生成的重构方案也有理由、有注释。偶尔会有思考过程冗长的问题,但 Claude Code 界面下这不碍事。
任务2:给一个 FastAPI 项目添加 JWT 认证中间件
效果:Sonnet 级别用 devstral-2-123b,这个场景基本无感差异。生成的代码可以直接跑,不需要二次修改。
任务3:复杂的多文件架构重构
这里出现了一些差距。kimi-k2-thinking 在跨文件依赖理解上偶尔会遗漏,需要我补充提示。原生 Opus 4.7 在这个场景明显更稳。但考虑到价格是 0vs200/月,这点差距......接受了。
速度感受:比原生 Claude Code 慢一点,主要是网络多了一跳(本地代理 → NIM API)。但不明显,正常写代码感知不到。
几个需要注意的坑
坑1:Thinking 模式只对特定模型有效
如果你把 ENABLE_THINKING=true 但用的是不支持推理的模型(比如 step-3.5-flash),会报错。记得按模型设置:
| 模型 | ENABLE_THINKING |
|---|---|
| kimi-k2-thinking | true |
| kimi-k2.5 | false |
| devstral-2-123b | false |
| step-3.5-flash | false |
坑2:ANTHROPIC_BASE_URL 别加 /v1
正确:http://localhost:8082
错误:http://localhost:8082/v1
这坑了我半个小时。代理自己处理路径,不要在 base URL 里加 /v1。
坑3:环境变量作用域
在终端1 export 了环境变量,在终端2 里用 claude 是看不到的。要么在同一个终端里设,要么写进 .bashrc/.zshrc,要么直接在命令行前缀带上变量(推荐方式)。
坑4:VSCode 扩展的登录屏
如果 VSCode 里弹出登录屏,点"Anthropic Console"授权一下就行------点完它会在浏览器里让你买会员,直接无视浏览器,回 VSCode 看,扩展已经在工作了。
金融行业开发者特别提示
我特别想跟做量化、做数据分析、做 Fintech 后端的朋友多说几句。
如果你有数据合规顾虑,选本地方案(LM Studio + Qwen3.5/MiniMax GGUF),代码完全不出本机网络,GDPR 和数据本地化要求都能满足。
如果你的工作流是"策略 → 代码 → 回测"循环,Discord Bot 功能太合适了:睡前在手机上发任务给 Claude,早上起来看回测代码已经写好了。当然,要配合好工作目录权限,别让 AI 在错误的地方乱写文件。
如果你的团队有多人用 Claude Code ,可以在服务器上起一个 free-claude-code 实例,通过 ANTHROPIC_AUTH_TOKEN 设置访问令牌,团队成员共享这个代理,不用每人都申请 NIM 账号。
坦率说:这方案有局限
说了这么多好处,也要诚实地说说局限:
1. 模型能力上限:NIM 上的免费模型,综合能力比不上 Claude Opus 4.7。特别是在需要极高精度的复杂推理任务上,差距是真实存在的。
2. 网络稳定性:多了一层本地代理,如果代理进程崩了,Claude Code 也跟着断。需要自己做进程守护(pm2、systemd 都行)。
3. 免费配额有波动:OpenRouter 的免费模型偶尔会限速或者暂时下线,NIM 的免费层配额在高峰时段也可能紧张。不是银行级别的 SLA。
4. 本地方案需要算力:LM Studio 全本地跑主力模型,起步 24GB 显存,不是所有人都有条件。
结语:这是属于穷人的反击
我知道 Anthropic 的订阅费有其合理性------训练和运行顶级模型需要巨大的算力投入。
但我也觉得,当一个开发者花了几个月钱包里没有余粮,还是要每天对着 AI 写代码的时候,能有这样一个工具是值得高兴的事情。
free-claude-code 在本质上是一个大模型"插座适配器" ------它让 Claude Code 这个优秀的客户端,可以接上各种各样的电源,而不是被锁死在一家供应商的插座里。
3k Star 不是因为大家都想薅羊毛,而是因为开发者工具应该有选择权。
这个项目仍在快速迭代:502 次 Commit,最近一次更新在几天前。Pull Request 里还有人在提 Groq、Together AI 的 Provider 支持。
如果你用得顺手,给作者点个 Star,或者提个 PR------这才是开源精神的底色。
数据来源:GitHub 项目页面(2026-04-28)、NVIDIA NIM 官方文档、项目 README、Medium 评测文章、社区实测反馈。代码配置以项目最新 README 为准。
作者碎碎念:写这篇文章时我的 Claude Code(跑在 devstral-2-123b 上)已经帮我改完了今天的三个 bug,一分钱没花。省下来的订阅费我去买了顿好吃的。人生很短,要快乐。点个赞比什么都实在。