
jina-embeddings-v5-text 岁在丙午,开年即战。Jina AI 的五代目向量模型春节期间正式发布。1B 参数内世界第一,全面刷新向量模型的性能天花板!
-
jina-embeddings-v5-text-small(677M 参数):MMTEB 67.0 排名第8,MTEB 英文 71.7,全面超越流行的qwen3-embedding-0.6b -
jina-embeddings-v5-text-nano(239M 参数):MMTEB 65.5 排名第11,MTEB 英文 71.0 -
我们的五代目也同时发布了 vLLM, GGUF 和 MLX 版本,为本地端运行提供最大的支持。
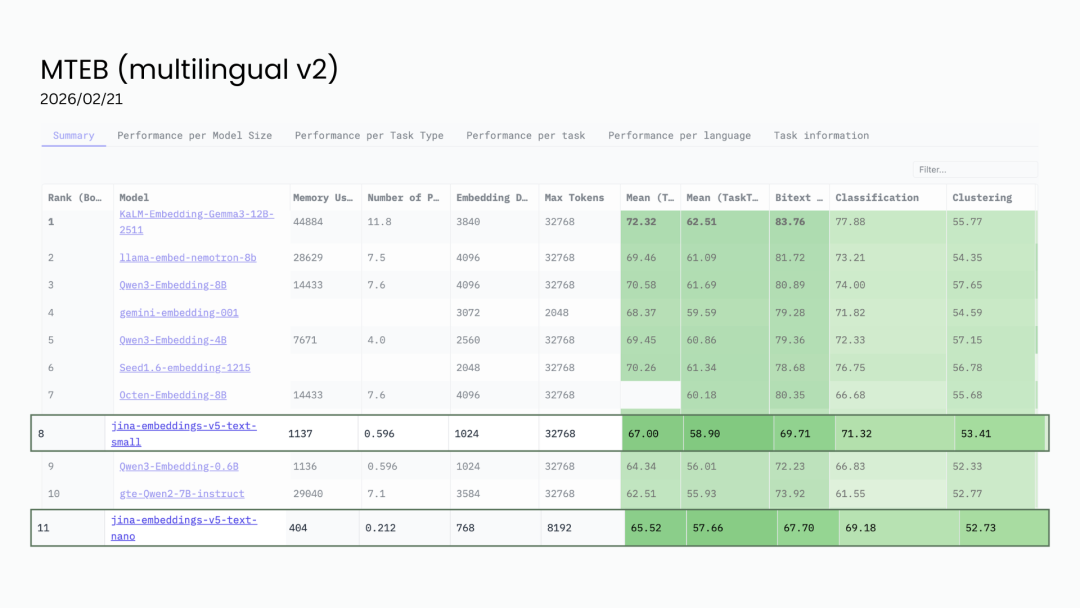
2026年2月21日的 MMTEB 多语言排行榜 消息来源:Hugging Face
资源链接:
HF 🤗 https://huggingface.co/collections/jinaai/jina-embeddings-v5-text
魔搭 🧙 https://modelscope.cn/organization/jinaai
技术报告 📖 https://arxiv.org/abs/2602.15547
API 💻 https://jina.ai/embeddings/
Small 版本支持 32K token 上下文 (nano 为 8K)、4 个任务专用 LoRA 适配器 (检索、文本匹配、分类、聚类),以及从 1024 到 32 维的 Matryoshka 维度截断。
Nano 版本仅 239M 参数,检索质量却能匹配参数量两倍于它的同类模型。
和前几代模型对比,v5-text-small 在检索任务上与 jina-embeddings-v4(3.8B)持平,体积只有后者的 1/5.6 ;在所有任务上全面超越 jina-embeddings-v3(572M),参数量相当。
| 特性 | v5-text-small | v5-text-nano |
|---|---|---|
| 基座模型 | Qwen3-0.6B-Base |
EuroBERT-210m |
| 参数量 | 677M | 239M |
| 向量维度 | 1024 | 768 |
| 上下文长度 | 32,768 | 8,192 |
| 语言数 | 119(Qwen3 tokenizer) | 15+(EuroBERT tokenizer) |
| 池化方式 | Last-token | Last-token |
| LoRA 适配器 | 4 个(检索、文本匹配、分类、聚类) | |
| Matryoshka 维度 | 32-1024 | 32-768 |
| MMTEB 分数 | 67.0 | 65.5 |
| MTEB 英文 | 71.7 | 71.0 |
| 许可证 | CC BY-NC 4.0 |
Benchmark 性能表现
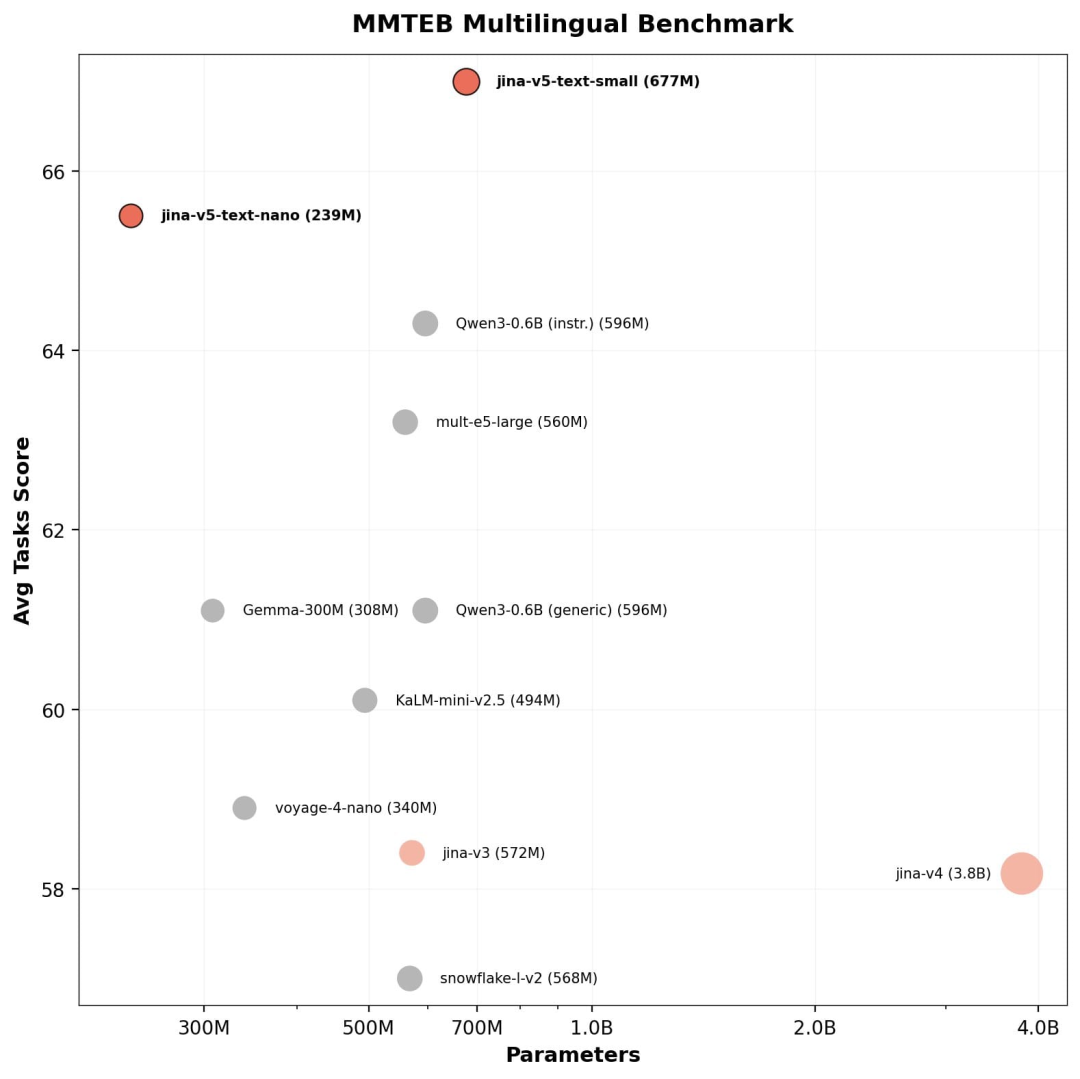 MMTEB 多语言评测
MMTEB 多语言评测
v5-text-small 在 MMTEB 多语言评测上取得 67.0 (131 个任务、9 种任务类型的平均分),超出同量级第二名 Qwen3-0.6B(指令版,64.3)2.7 分。nano 模型以 239M 参数取得 65.5,超越了多个参数量两倍于它的模型。
small在中文评测上得分 73.7,优于 v3 和 Gemma-300M。Qwen3-0.6B 在中文单项上更强(76.3),这不意外,Qwen3 底座本身有大量中文预训练数据。但 v5-text-small 胜在均衡,中文以外语言覆盖和任务泛化能力更广。
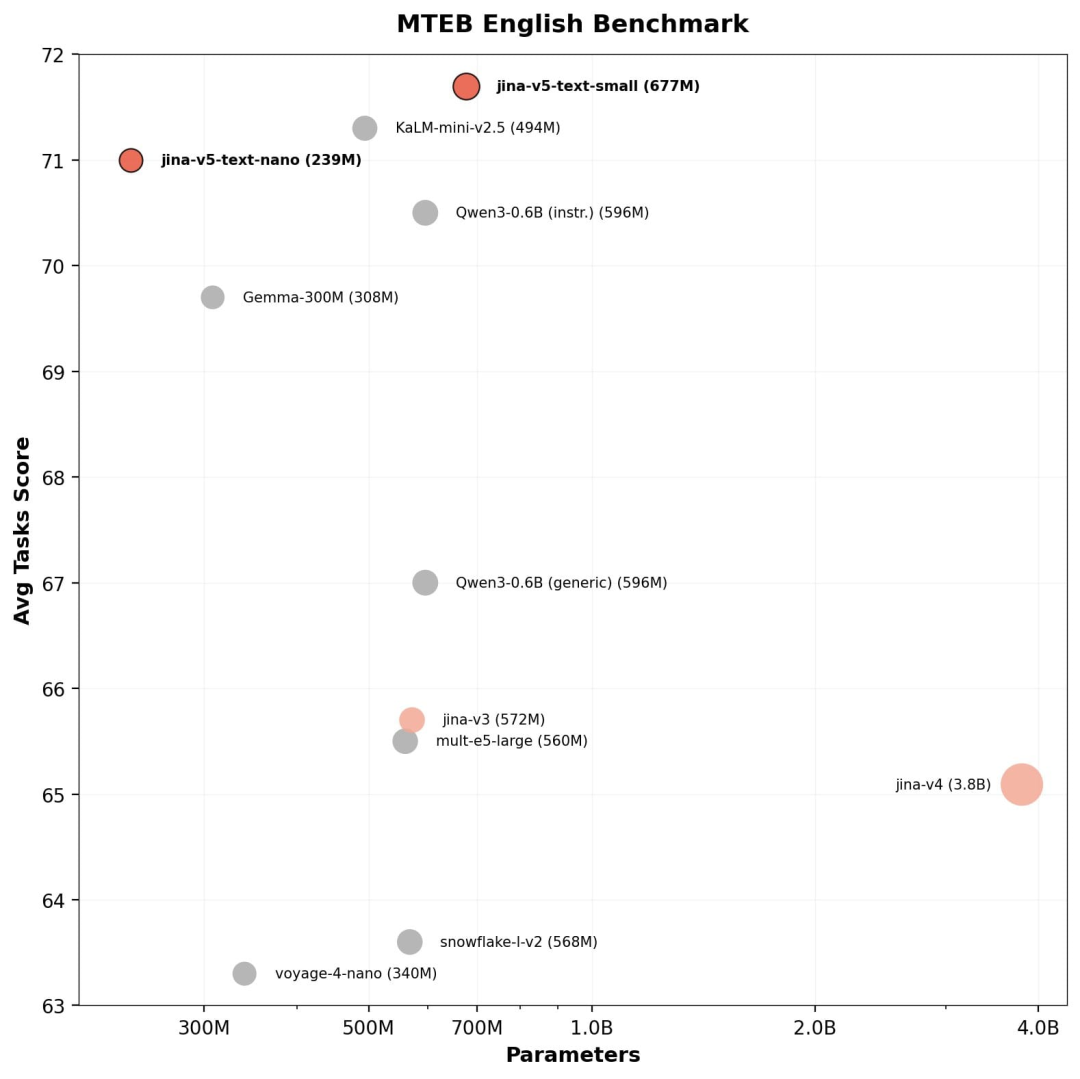 MTEB 英文
MTEB 英文
在 MTEB 英文评测里,v5-text-small以 71.7 领跑所有 1B 以下多语言模型 (41 个任务、7 种任务类型平均),其后是 KaLM-mini-v2.5(71.3)和 v5-text-nano(71.0)。239M 的 nano 与 494M 的 KaLM 表现相当,但参数量不到后者一半。nano 在检索(58.8)和重排序(49.2)上超越了所有 500M 以下的竞品。
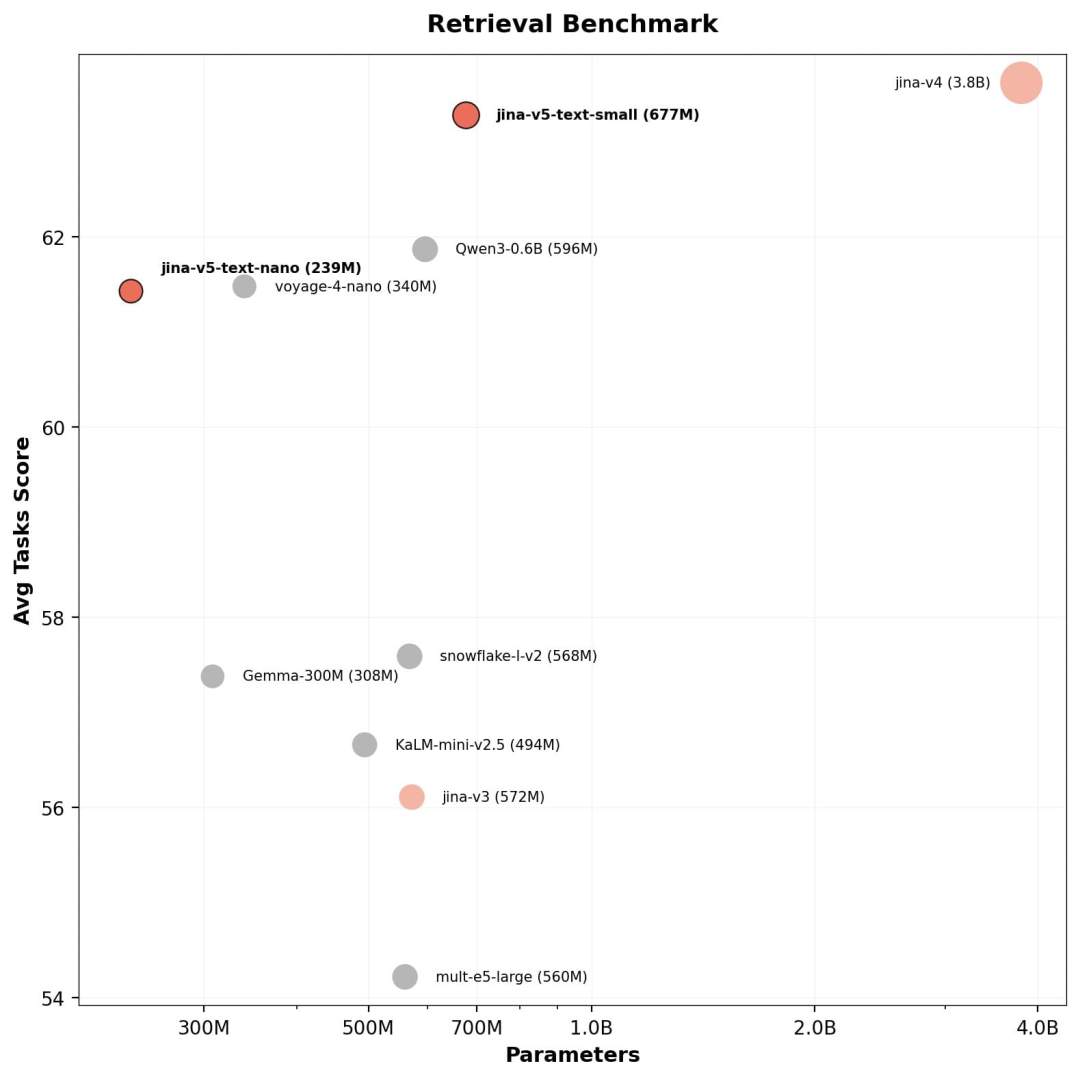 检索任务
检索任务
v5-text-small 在五个检索 benchmark(MTEB 多语言、MTEB 英文、RTEB、BEIR、LongEmbed)的任务级平均分达到 63.28 ,在所有 4B 以下的模型中最高,与 jina-embeddings-v4(3.8B,63.62)几乎持平,但体积仅为后者的 1/5.6。
其中,RTEB(面向企业检索场景的 benchmark)得分 66.84,BEIR(大规模英文零样本评测)得分 56.67,均超越了同量级的 Qwen3-0.6B。500M 以下模型中,nano(61.43)超越了 Gemma-300M(59.66)和 KaLM-mini-v2.5(56.58),在 BEIR 的分数更是该量级最高。
模型架构
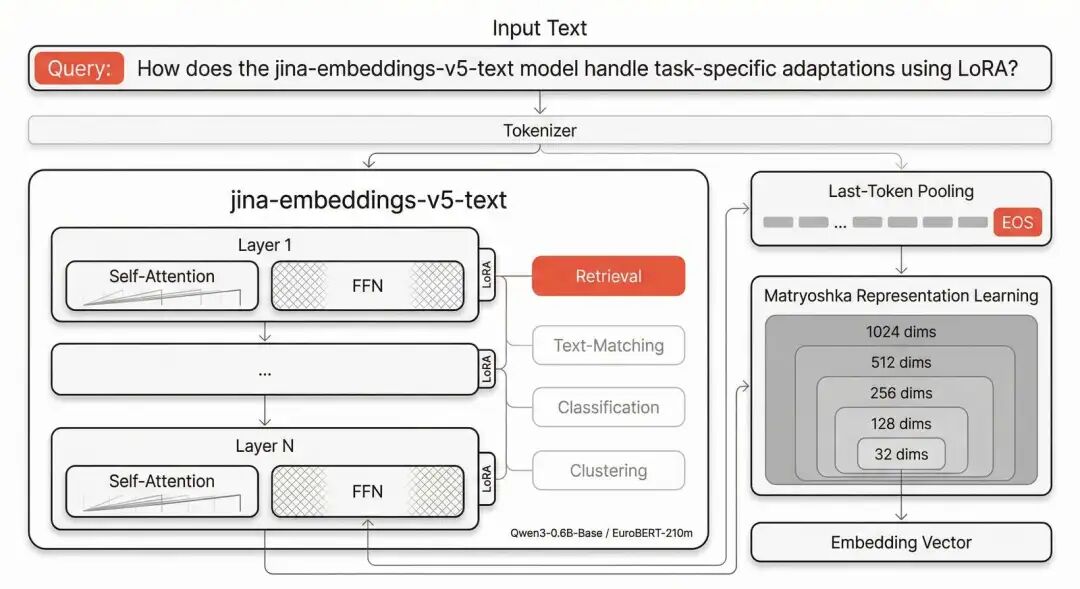
v5-text 采用 decoder-only 骨干网络,通过 last-token pooling(取序列末尾 EOS token 的隐藏状态)生成向量,取代了传统的 mean pooling。和 Qwen3-Embedding、EmbeddingGemma 等近期模型的选择一致,也更契合 decoder-only 架构的特性。
四个轻量级 LoRA 适配器注入每一层 Transformer,分别对应检索、文本匹配、分类和聚类,用户在推理时按需切换。这一设计延续自 jina-embeddings-v3,用独立适配器替代指令微调,化解多任务间的优化冲突。
对于非对称检索任务,通过文本前缀区分输入角色:query 使用 "Query:" 前缀,document 使用 "Document:" 前缀。文本匹配、分类、聚类任务统一使用 "Document:" 前缀。
此外,模型支持 Matryoshka Representation Learning(MRL),可对向量维度进行截断,从 1024 维到 32 维,以满足不同效率需求。
上下文长度方面,small 支持 32K tokens,nano 支持 8K tokens。前者相较 v3 的 8K 扩展了 4 倍。
快速开始
Elastic Inference Service
生产环境首选的接入方式是由 Elastic Inference Service(EIS)提供的推理服务,内置弹性伸缩,在 Elastic 部署中直接生成向量,无需自行管理推理基础设施。
go
PUT _inference/text_embedding/jina-v5
{
"service": "elastic",
"service_settings": {
"model_id": "jina-embeddings-v5-text-small"
}
}详见 EIS 文档:https://www.elastic.co/docs/explore-analyze/elastic-inference/eis
Jina Embedding API
Jina 官方托管 API,按 token 计价,开箱支持任务选择、维度截断和批量处理,无需 GPU。
go
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "jina-embeddings-v5-text-small",
"task": "retrieval.query",
"dimensions": 1024,
"input": ["What is knowledge distillation?"]
}'请前往 jina.ai/embeddings 获取 API Key。
Hugging Face + sentence-transformers
本地部署,完整控制推理流程。模型权重已在 Hugging Face 公开,原生兼容 sentence-transformers。
go
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer(
"jinaai/jina-embeddings-v5-text-small-retrieval",
model_kwargs={"dtype": torch.bfloat16},
)
query_emb = model.encode("What is knowledge distillation?", prompt_name="query")
doc_embs = model.encode(["Knowledge distillation transfers...", "Venus is..."], prompt_name="document")
similarity = model.similarity(query_emb, doc_embs)vLLM
适合高吞吐生产场景。vLLM 原生支持 v5-text 的 last-token pooling。
go
from vllm import LLM
from vllm.config.pooler import PoolerConfig
model = LLM(
model="jinaai/jina-embeddings-v5-text-small-retrieval",
dtype="float16",
runner="pooling",
pooler_config=PoolerConfig(seq_pooling_type="LAST", normalize=True),
)
outputs = model.encode(["Query: climate change impacts"], pooling_task="embed")面向 llama.cpp 和 MLX 等本地推理场景,每个任务适配器的 LoRA 权重已预先合并到基座模型中,生成独立的完整权重文件。每个任务(检索、文本匹配、分类、聚类)各对应一个独立仓库,推理时无需额外加载 LoRA,开箱即用。
llama.cpp (GGUF)
在 CPU 或边缘设备上运行量化模型,我们为每个模型提供 14 种 GGUF 量化方案,从 F16 到 IQ1_S,覆盖不同精度需求。
go
llama-server -hf jinaai/jina-embeddings-v5-text-small-retrieval-GGUF:Q4_K_M \
--embedding --pooling last -ub 32768MLX
面向 Apple Silicon 的原生推理。所有任务适配器均提供全精度、4-bit 和 8-bit 量化版本。
go
import mlx.core as mx
from tokenizers import Tokenizer
from model import JinaEmbeddingModel
import json
with open("config.json") as f:
config = json.load(f)
model = JinaEmbeddingModel(config)
weights = mx.load("model-4bit.safetensors")
model.load_weights(list(weights.items()))
tokenizer = Tokenizer.from_file("tokenizer.json")
texts = ["Query: What is machine learning?"]
embeddings = model.encode(texts, tokenizer)从 Hugging Face 下载:jinaai/jina-embeddings-v5-text-small-retrieval-mlx(文本匹配、分类、聚类适配器同样可用)。
训练方法
两个模型均从 Qwen3-Embedding-4B(一个参数量大得多的成熟向量模型)蒸馏而来。small 版本以 Qwen3-0.6B-Base 为骨干,nano 以 EuroBERT-210m 为骨干。训练过程结合了两路互补的监督信号:
第一阶段:向量蒸馏(Embedding Distillation)
核心目标是让小模型(学生)无需指令模板,就能逼近 4B 教师模型的向量空间。
蒸馏阶段的训练数据涵盖超过 300 个数据集、30+ 种语言的文本对。这一策略在标注数据稀缺的语言和任务上尤其有效,教师模型提供的监督信号弥补了标注数据的不足。
针对 v5-text-small,我们还进行了额外的 长上下文训练:使用专门构造的长文本数据集,降低训练时的 RoPE θ 值并扩大最大序列长度,获得更好的长文本外推能力。
第二阶段:任务专用对比学习(Task-specific Contrastive Loss)
蒸馏完成后冻结骨干权重,为四个任务类别分别训练 LoRA 适配器,每个适配器使用不同的损失函数和训练数据。
检索适配器在标注的 query-document 对上使用 InfoNCE loss,配合 hard negative mining 和 in-batch negatives,同时保留蒸馏损失,防止适配器训练偏离骨干已建立的向量空间。
消融实验表明,两种方法的组合稳定优于任一单独使用:MTEB 英文检索上,组合方案达到 60.1 nDCG@10,纯蒸馏 58.6,纯对比学习仅 54.3(同一骨干网络)。
训练中还引入了 GOR(Generalized Orthogonal Regularization,广义正交正则化) ,让向量在各维度上分布更均匀。GOR 对 benchmark 分数提升有限,其核心价值在于:二值量化几乎无损,对于内存受限的部署环境下,这是个关键特性。
在训练过程中,我们还有几个重要发现:
-
蒸馏和对比学习的互补性远超预期。从 loss 组合中拿掉任何一个组件,全线性能立刻下降,没有冗余项。
-
任务专用 LoRA 适配器以几乎可忽略的参数开销,表现优于多任务联合训练。
-
GOR 正则化对 benchmark 提升有限,但能让二值量化几乎无损,移除 GOR 后,量化劣化增加超 50%。对实际部署的意义远大于全精度场景下那点边际收益。
结语
2026年,向量模型正在发生巨大的角色转型。
过去,向量模型作为独立的召回单元。今天,大模型在 Agentic 工作流中把向量模型当做小工具调用从而完成检索、记忆管理和分类。OpenClaw、OpenViking 等项目把向量模型当作 Agent 上下文管理的核心记忆层。向量模型正在从搜索引擎的固定后端变成上下文窗口里的灵活小工具:去重、过滤、压缩 token,一切只为更好的 Context。
在这种范式下,单次调用的推理成本和延迟跟 Benchmark 分数一样重要。端侧检索、页内搜索、边缘部署,都要求模型塞进严苛的内存预算。Matryoshka 维度让一个模型同时覆盖高精度检索和超快近似搜索,无需重新训练;配合 GGUF 量化压到 1--2 bit,生产环境下向量服务的实际内存开销直降一个数量级。
v5-text 就是为这个趋势而生的:够小、够快、够准。
我们正在开发 jina-embeddings-v5-multimodal,将同一架构扩展至视觉与跨模态检索。早期实验验证,在不损失文本性能的前提下对齐视觉编码器完全可行。敬请期待!