
在之前的文章 "Jina-VLM:小型多语言视觉语言模型",我们介绍了 JINA-VLM 小型多语言视觉语言模型。在今天的文章中,我们讲使用一个 Python 应用来展示如何使用它。
下载代码
首先我们克隆代码:
git clone https://github.com/liu-xiao-guo/jina_vlm_demo
$ tree -L 3
.
├── README.md
├── app.py
├── images
│ ├── chenglong.png
│ ├── carjpg.jpg
│ ├── girl.jpeg
│ └── mask.png
├── pics
│ ├── car.png
│ ├── girl.png
│ └── jackie.png
└── requirements.txt如上所示,我们有一个目录叫做 images, 它里面含有我们需要进行对话的图片。 app.py 是我们的应用。在文件中,还有一个叫做 ,env 的配置文件:
,env
JINA_API_KEY=<Your Jina API Key at jina.ai>我们需要在 jina.ai,里申请一个免费的 key。
应用设计
我们的 app.py 代码是这样的:
import streamlit as st
from PIL import Image
import os
import io
import base64
import requests
from dotenv import load_dotenv
# --- Page Configuration ---
st.set_page_config(
page_title="Jina VLM Image Chat",
page_icon="🤖",
layout="wide"
)
# --- Main Application UI ---
st.title("🖼️ Jina VLM Image Chat")
st.write("Select an image from the sidebar and ask questions about it!")
# --- API Key Loading ---
load_dotenv() # Load variables from .env file
JINA_API_KEY = os.getenv("JINA_API_KEY")
JINA_API_URL = "https://api-beta-vlm.jina.ai/v1/chat/completions"
if not JINA_API_KEY:
st.error("JINA_API_KEY not found. Please create a .env file and add your key.")
st.info("Example .env file content: JINA_API_KEY=\"your_api_key_here\"")
st.stop()
# --- Image Selection Sidebar ---
st.sidebar.title("Image Selection")
IMAGE_DIR = "images"
# Check if the image directory exists to avoid errors.
if not os.path.isdir(IMAGE_DIR):
st.sidebar.error(f"Image directory '{IMAGE_DIR}' not found.")
st.sidebar.info("Please create an 'images' folder and add some pictures to it.")
image_files = []
else:
# Get a list of valid image files from the directory.
image_files = [f for f in os.listdir(IMAGE_DIR) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))]
if not image_files:
st.sidebar.warning("No images found in the 'images' directory.")
selected_image_name = None
else:
selected_image_name = st.sidebar.selectbox(
"Choose an image:",
image_files
)
# --- Image and Chat State Management ---
# Clear chat history if the selected image changes.
if "last_seen_image" not in st.session_state:
st.session_state.last_seen_image = None
if selected_image_name != st.session_state.last_seen_image:
st.session_state.messages = [] # Reset chat history
st.session_state.last_seen_image = selected_image_name
# Clear image bytes if no image is selected
if selected_image_name is None:
st.session_state.current_image_bytes = None
else:
# Load and store the new image in session state
image_path = os.path.join(IMAGE_DIR, selected_image_name)
try:
image = Image.open(image_path).convert("RGB")
# Convert image to bytes to store in session state (more robust)
img_byte_arr = io.BytesIO()
image.save(img_byte_arr, format='PNG')
st.session_state.current_image_bytes = img_byte_arr.getvalue()
except Exception as e:
st.sidebar.error(f"Error opening image: {e}")
st.session_state.current_image_bytes = None
# Rerun to update the UI immediately after image change
if "messages" in st.session_state and len(st.session_state.messages) > 0:
st.rerun()
# Display the selected image in the sidebar
if st.session_state.get("current_image_bytes"):
st.sidebar.image(
st.session_state.current_image_bytes,
caption=st.session_state.last_seen_image,
width='stretch' # Make image fill the sidebar width
)
# --- Chat Interface ---
# Initialize chat history in session state if it doesn't exist.
if "messages" not in st.session_state:
st.session_state.messages = []
# Display past messages from the chat history.
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Handle user input from the chat box.
if prompt := st.chat_input("Ask a question about the image..."):
# Check if an image is selected before proceeding.
if not st.session_state.get("current_image_bytes"):
st.warning("Please select an image from the sidebar first.")
else:
# Add user message to history and display it.
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# Prepare for and generate the model's response.
with st.chat_message("assistant"):
message_placeholder = st.empty()
message_placeholder.markdown("Thinking... 🤔")
try:
# Retrieve the image from session state and base64 encode it.
image_bytes = st.session_state.current_image_bytes
base64_image = base64.b64encode(image_bytes).decode('utf-8')
image_url = f"data:image/png;base64,{base64_image}"
# Prepare headers and payload for the Jina API
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}"
}
payload = {
"model": "jina-vlm",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_url}}
]
}],
"max_tokens": 1024
}
# Make the API request
response = requests.post(JINA_API_URL, headers=headers, json=payload)
response.raise_for_status() # Raise an exception for bad status codes
# Extract the response content
response_data = response.json()
assistant_response = response_data['choices'][0]['message']['content']
message_placeholder.markdown(assistant_response)
# Add assistant response to chat history.
st.session_state.messages.append({"role": "assistant", "content": assistant_response})
except Exception as e:
error_message = f"An error occurred while generating the response: {e}"
message_placeholder.error(error_message)
st.session_state.messages.append({"role": "assistant", "content": error_message})运行应用
我们可以使用如下的命令来运行:
(.venv) $ streamlit run app.py运行后,我们可以看到如下的画面:
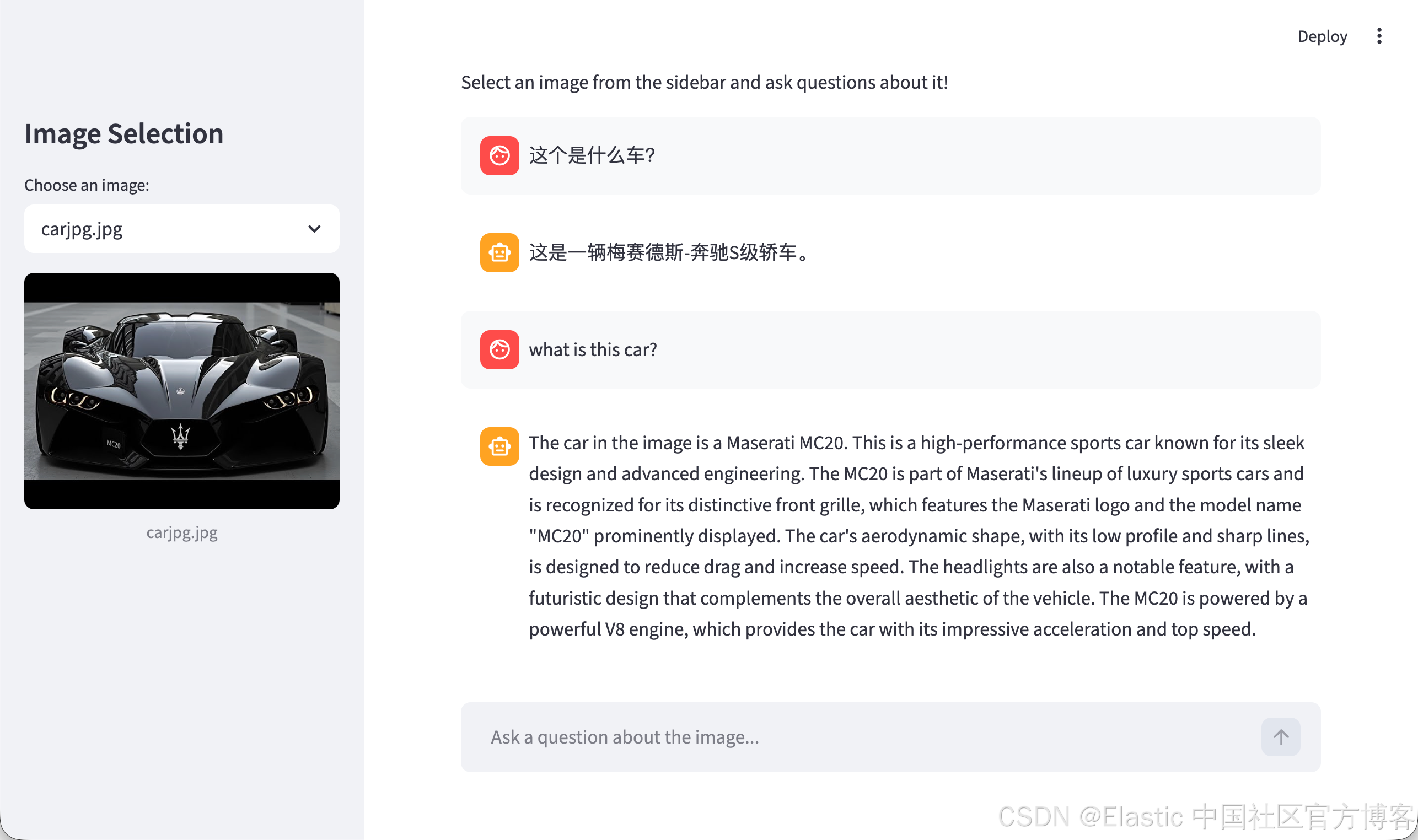
在左边,我们选中所需要的图片。在右边,我们可以看到聊天的记录。我们可以针对图片来进行提问:
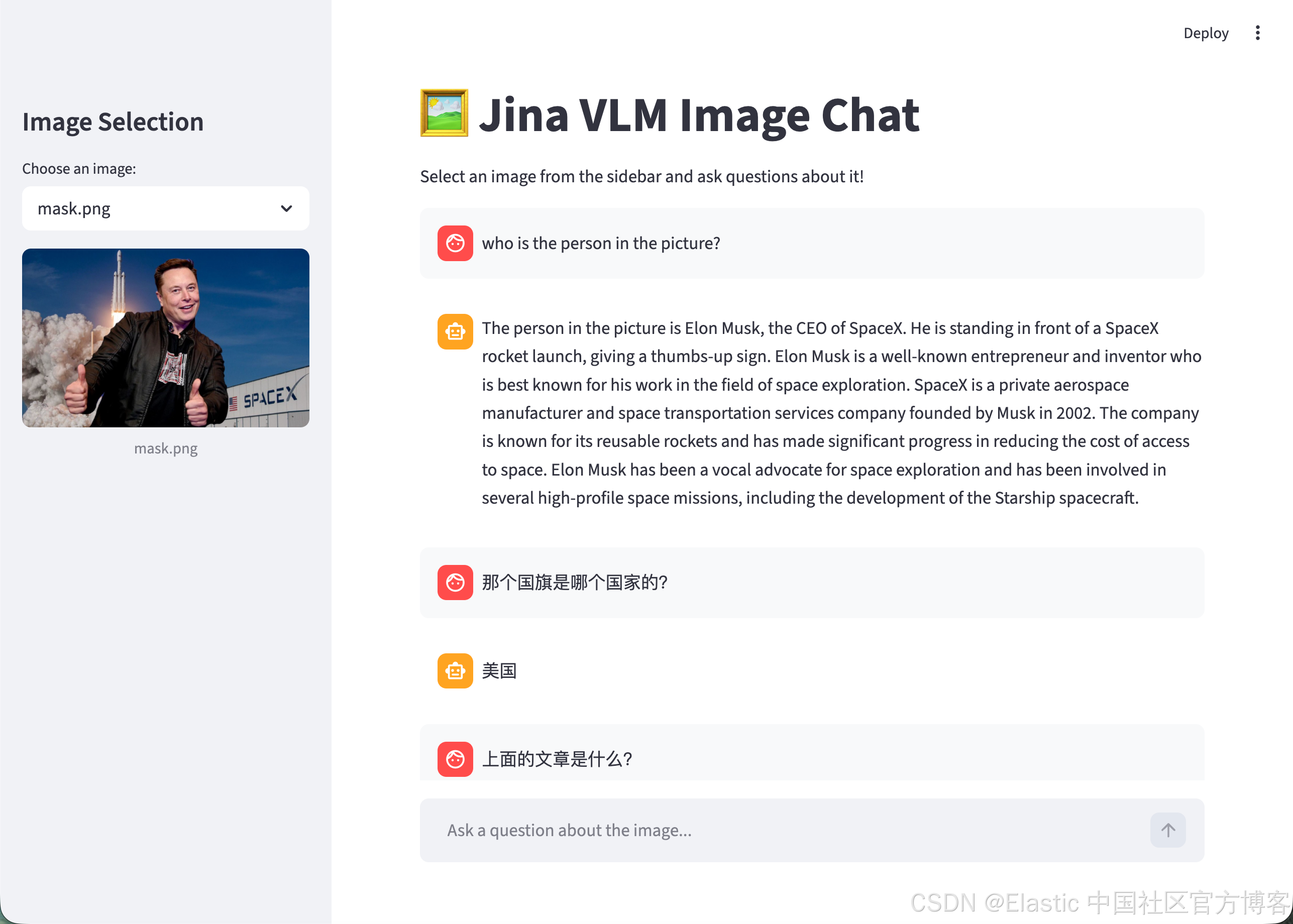
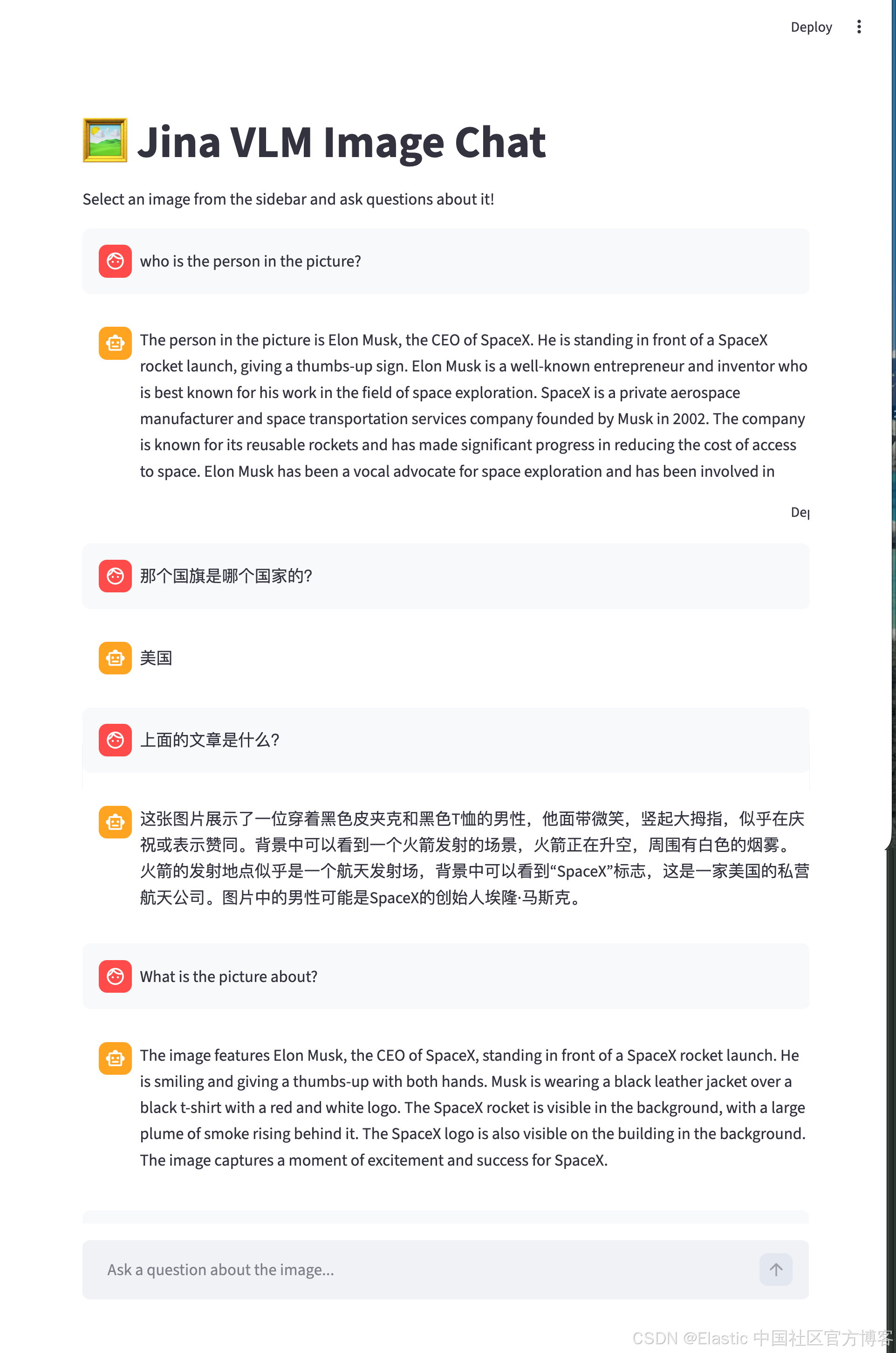
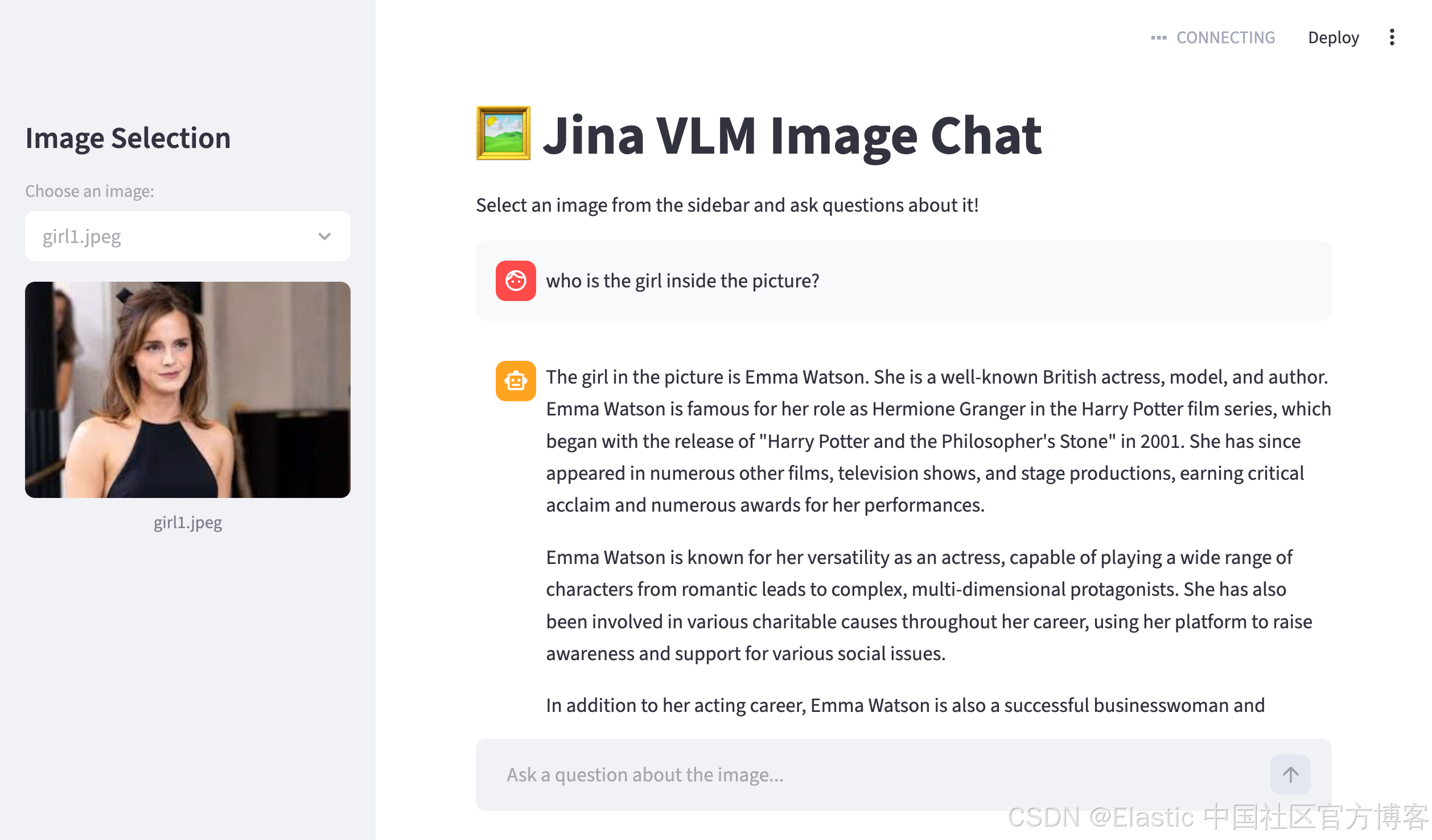
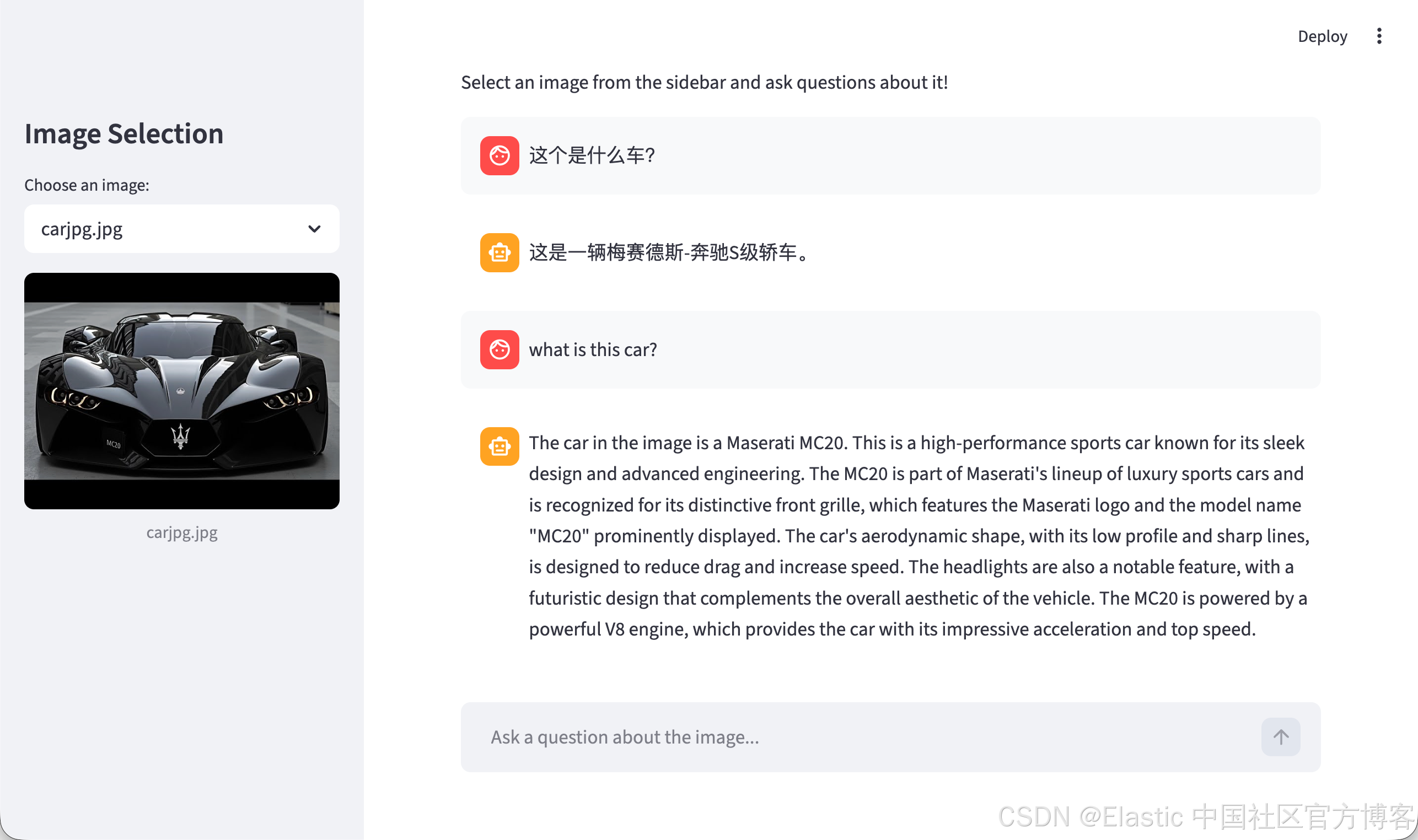
祝大家学习愉快!