Transformer为何选择LayerNorm?------ 一场真实的AI面试实录
1. 归一化到底是什么?
面试官:看你简历上写熟悉Transformer架构,那我们先聊聊归一化。先问个基础的问题:你能用大白话解释一下,归一化到底在干嘛吗?
候选人:嗯...归一化就是把数据标准化,让它们的范围变得一致?
面试官:方向对,但太抽象了。我换个问法------你上学时,语文满分150,数学满分100,英语满分120。如果直接加总分来排名,公平吗?
候选人:哦,我明白您的意思了!语文的权重天然就更大,不太公平。所以需要把每科都转换成某种标准分
面试官:对,这就是归一化的目的。具体怎么转换呢?
候选人:应该是...先算出平均分,然后看每个人偏离平均分多少,再除以标准差?
面试官 :没错,公式就是 (原始值 - 均值) / 标准差。那在神经网络里,归一化解决的是什么问题?
候选人:我想想...神经网络每一层的输出数值范围可能差异很大,有的特征值很大,有的很小。如果不归一化,那些数值大的特征会"喧宾夺主"?
面试官 :说得好。还有一点------如果数值分布不稳定,梯度也会忽大忽小,训练就容易震荡甚至发散**。归一化能让训练更稳定、更快收敛**。这个基础清楚了,我们往下走。
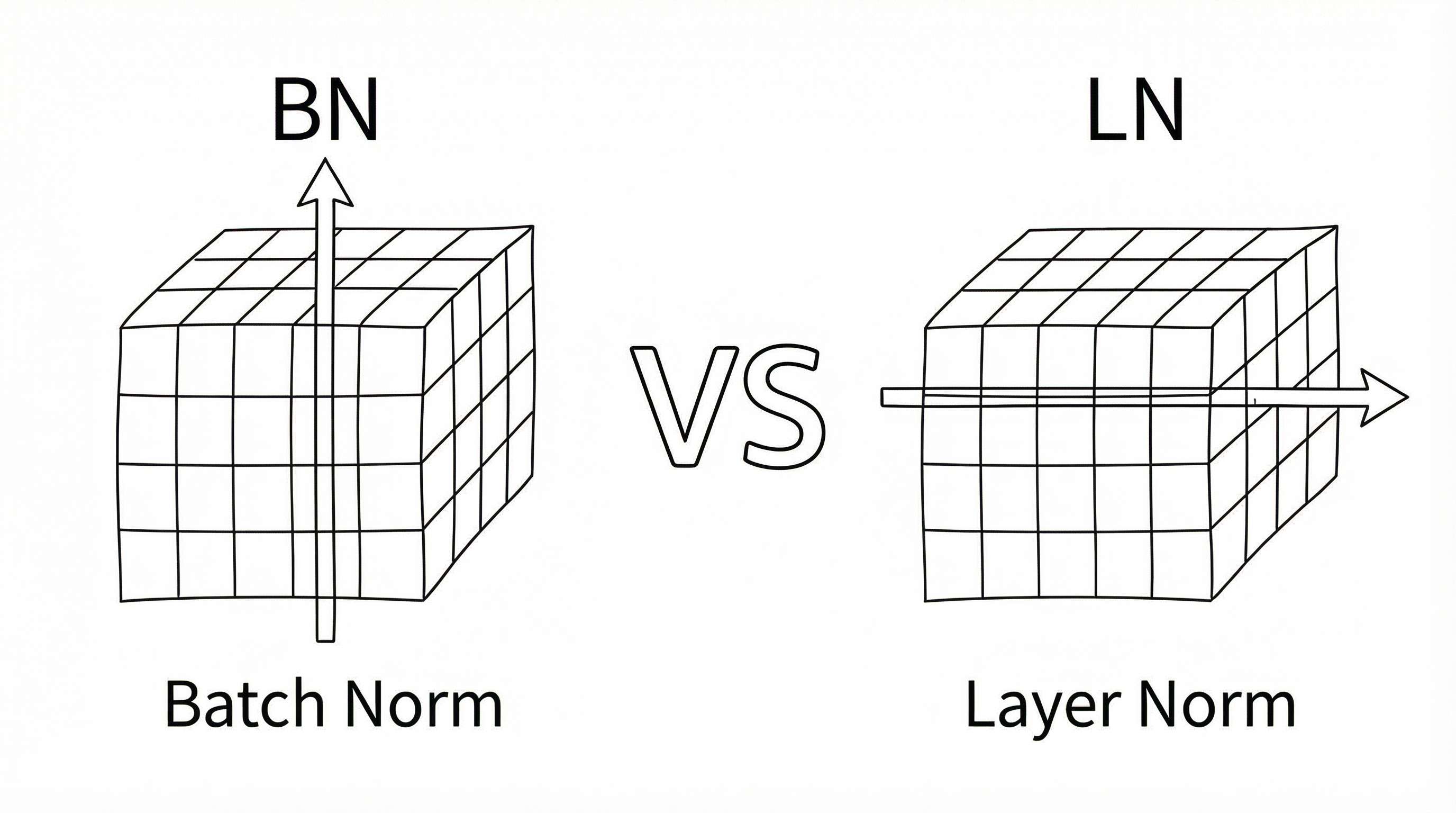
2. BatchNorm和LayerNorm有什么区别?
面试官:既然归一化的公式是固定的,那BatchNorm和LayerNorm的区别在哪?
候选人:它们计算均值和标准差的维度不一样?
面试官:对,但"维度不一样"太笼统了。能具体说说吗?
候选人:这个...让我想想。BatchNorm应该是在Batch维度上算的,就是把一批样本的同一个特征放在一起算均值?
面试官:继续用考试的例子来类比呢?
候选人 :哦!BatchNorm就像是看"全年级所有人的数学成绩",算出数学这科的平均分和标准差,然后给每个人的数学成绩做标准化。它关注的是某一个特征在所有样本中的分布。
面试官:那LayerNorm呢?
候选人:LayerNorm应该是...看"某一个学生的所有科目成绩"?比如小明语文130、数学85、英语100,就用小明自己这三科的平均分来标准化。它关注的是单个样本内部各特征之间的关系。
面试官:理解得很到位。那我追问一下------BatchNorm依赖什么?LayerNorm依赖什么?
候选人 :BatchNorm依赖其他样本,因为要跨样本算统计量。LayerNorm只依赖当前样本本身,不需要看别人。
面试官:这个区别会带来什么实际影响?
候选人:如果Batch Size很小,BatchNorm算出来的均值和方差就不准,会波动很大
面试官:对。而LayerNorm哪怕只有一个样本,也能正常计算。我们把区别总结成表格:
| 对比维度 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化方向 | 跨样本(Batch维度) | 跨特征(特征维度) |
| 计算依赖 | 需要一批样本 | 仅需当前样本 |
| Batch Size敏感 | 是,太小会不稳定 | 否 |
| 典型应用 | CNN图像处理 | Transformer/RNN |
3. Transformer为什么选择LayerNorm?
面试官:好,现在到核心问题了。BatchNorm在CNN里非常成功,为什么Transformer不用它,而选择LayerNorm?
候选人:是因为Transformer处理的是序列数据吗?
面试官:对,但能展开说说吗?序列数据有什么特点让BatchNorm失效?
候选人:序列长度不一样!比如"我爱你"是3个词,"今天天气真不错"是6个词。如果要对齐不同样本的相同位置...第4个词根本对不上。
面试官:很好,这是第一个原因。还有呢?
候选人:还有Batch Size的问题。训练大模型的时候,显存很紧张,Batch Size经常很小,甚至只有1。这时候BatchNorm就...
面试官:就怎么样?
候选人:均值方差会非常不稳定,训练可能直接崩掉。
面试官:对。我再给你补充一个原因------训练和推理的不一致性。BatchNorm训练时用的是当前Batch的统计量,推理时用的是训练阶段累积的全局统计量。这两套标准可能有偏差,在NLP任务中这个问题尤其严重。LayerNorm呢?
候选人:LayerNorm训练和推理用的是同一套计算方式,不存在这个问题!
面试官:还有最后一点。你想想,图像里不同图片的同一个像素位置,可能都是"天空"或者"地面",有一定的统计规律。但NLP里,不同句子的第3个词可能是"苹果"、"跑步"、"美丽"------把它们混在一起算均值,有意义吗?
候选人:没意义!语义完全不相关,跨样本统计根本不成立。
面试官:总结一下,Transformer选LayerNorm的四个原因?
候选人:第一,序列长度可变,位置无法对齐;第二,Batch Size常常很小,BatchNorm不稳定;第三,BatchNorm训练推理不一致;第四,不同样本相同位置的语义无关,跨样本统计没有意义。
面试官:非常好。
4. 收尾:延伸问题
面试官:最后问一个加分题。现在主流的大模型,比如LLaMA,用的还是标准的LayerNorm吗?
候选人:好像不是...我记得是RMSNorm?它省去了均值计算,只算均方根,更快一些。
面试官:对,LLaMA、Mistral都改用了RMSNorm。那Pre-LN和Post-LN你了解吗?
候选人:LayerNorm放在子层之前叫Pre-LN,放在之后叫Post-LN。原始Transformer用Post-LN,但GPT-2之后普遍改用Pre-LN,因为训练更稳定。
面试官:基础很扎实。今天这个问题就聊到这里。
5. 总结
Transformer选择LayerNorm的核心原因可以归纳为四点: 1.NLP序列长度可变导致位置无法对齐、 2.大模型训练时Batch Size受限、 3.BatchNorm存在训练推理不一致问题、 4.以及不同样本相同位置语义无关使跨样本统计失去意义。
面试时抓住"归一化维度不同导致适用场景不同"这条主线,结合具体原因展开,就能清晰地回答这道高频题。
Transformer为何选择LayerNorm?------ 一场真实的AI面试实录
1. 归一化到底是什么?
面试官:看你简历上写熟悉Transformer架构,那我们先聊聊归一化。先问个基础的问题:你能用大白话解释一下,归一化到底在干嘛吗?
候选人:嗯...归一化就是把数据标准化,让它们的范围变得一致?
面试官:方向对,但太抽象了。我换个问法------你上学时,语文满分150,数学满分100,英语满分120。如果直接加总分来排名,公平吗?
候选人:哦,我明白您的意思了!语文的权重天然就更大,不太公平。所以需要把每科都转换成某种标准分
面试官:对,这就是归一化的目的。具体怎么转换呢?
候选人:应该是...先算出平均分,然后看每个人偏离平均分多少,再除以标准差?
面试官 :没错,公式就是 (原始值 - 均值) / 标准差。那在神经网络里,归一化解决的是什么问题?
候选人:我想想...神经网络每一层的输出数值范围可能差异很大,有的特征值很大,有的很小。如果不归一化,那些数值大的特征会"喧宾夺主"?
面试官 :说得好。还有一点------如果数值分布不稳定,梯度也会忽大忽小,训练就容易震荡甚至发散**。归一化能让训练更稳定、更快收敛**。这个基础清楚了,我们往下走。
2. BatchNorm和LayerNorm有什么区别?
面试官:既然归一化的公式是固定的,那BatchNorm和LayerNorm的区别在哪?
候选人:它们计算均值和标准差的维度不一样?
面试官:对,但"维度不一样"太笼统了。能具体说说吗?
候选人:这个...让我想想。BatchNorm应该是在Batch维度上算的,就是把一批样本的同一个特征放在一起算均值?
面试官:继续用考试的例子来类比呢?
候选人 :哦!BatchNorm就像是看"全年级所有人的数学成绩",算出数学这科的平均分和标准差,然后给每个人的数学成绩做标准化。它关注的是某一个特征在所有样本中的分布。
面试官:那LayerNorm呢?
候选人:LayerNorm应该是...看"某一个学生的所有科目成绩"?比如小明语文130、数学85、英语100,就用小明自己这三科的平均分来标准化。它关注的是单个样本内部各特征之间的关系。
面试官:理解得很到位。那我追问一下------BatchNorm依赖什么?LayerNorm依赖什么?
候选人 :BatchNorm依赖其他样本,因为要跨样本算统计量。LayerNorm只依赖当前样本本身,不需要看别人。
面试官:这个区别会带来什么实际影响?
候选人:如果Batch Size很小,BatchNorm算出来的均值和方差就不准,会波动很大
面试官:对。而LayerNorm哪怕只有一个样本,也能正常计算。我们把区别总结成表格:
| 对比维度 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化方向 | 跨样本(Batch维度) | 跨特征(特征维度) |
| 计算依赖 | 需要一批样本 | 仅需当前样本 |
| Batch Size敏感 | 是,太小会不稳定 | 否 |
| 典型应用 | CNN图像处理 | Transformer/RNN |
3. Transformer为什么选择LayerNorm?
面试官:好,现在到核心问题了。BatchNorm在CNN里非常成功,为什么Transformer不用它,而选择LayerNorm?
候选人:是因为Transformer处理的是序列数据吗?
面试官:对,但能展开说说吗?序列数据有什么特点让BatchNorm失效?
候选人:序列长度不一样!比如"我爱你"是3个词,"今天天气真不错"是6个词。如果要对齐不同样本的相同位置...第4个词根本对不上。
面试官:很好,这是第一个原因。还有呢?
候选人:还有Batch Size的问题。训练大模型的时候,显存很紧张,Batch Size经常很小,甚至只有1。这时候BatchNorm就...
面试官:就怎么样?
候选人:均值方差会非常不稳定,训练可能直接崩掉。
面试官:对。我再给你补充一个原因------训练和推理的不一致性。BatchNorm训练时用的是当前Batch的统计量,推理时用的是训练阶段累积的全局统计量。这两套标准可能有偏差,在NLP任务中这个问题尤其严重。LayerNorm呢?
候选人:LayerNorm训练和推理用的是同一套计算方式,不存在这个问题!
面试官:还有最后一点。你想想,图像里不同图片的同一个像素位置,可能都是"天空"或者"地面",有一定的统计规律。但NLP里,不同句子的第3个词可能是"苹果"、"跑步"、"美丽"------把它们混在一起算均值,有意义吗?
候选人:没意义!语义完全不相关,跨样本统计根本不成立。
面试官:总结一下,Transformer选LayerNorm的四个原因?
候选人:第一,序列长度可变,位置无法对齐;第二,Batch Size常常很小,BatchNorm不稳定;第三,BatchNorm训练推理不一致;第四,不同样本相同位置的语义无关,跨样本统计没有意义。
面试官:非常好。
4. 收尾:延伸问题
面试官:最后问一个加分题。现在主流的大模型,比如LLaMA,用的还是标准的LayerNorm吗?
候选人:好像不是...我记得是RMSNorm?它省去了均值计算,只算均方根,更快一些。
面试官:对,LLaMA、Mistral都改用了RMSNorm。那Pre-LN和Post-LN你了解吗?
候选人:LayerNorm放在子层之前叫Pre-LN,放在之后叫Post-LN。原始Transformer用Post-LN,但GPT-2之后普遍改用Pre-LN,因为训练更稳定。
面试官:基础很扎实。今天这个问题就聊到这里。
5. 总结
Transformer选择LayerNorm的核心原因可以归纳为四点: 1.NLP序列长度可变导致位置无法对齐、 2.大模型训练时Batch Size受限、 3.BatchNorm存在训练推理不一致问题、 4.以及不同样本相同位置语义无关使跨样本统计失去意义。
面试时抓住"归一化维度不同导致适用场景不同"这条主线,结合具体原因展开,就能清晰地回答这道高频题。
Transformer为何选择LayerNorm?------ 一场真实的AI面试实录
1. 归一化到底是什么?
面试官:看你简历上写熟悉Transformer架构,那我们先聊聊归一化。先问个基础的问题:你能用大白话解释一下,归一化到底在干嘛吗?
候选人:嗯...归一化就是把数据标准化,让它们的范围变得一致?
面试官:方向对,但太抽象了。我换个问法------你上学时,语文满分150,数学满分100,英语满分120。如果直接加总分来排名,公平吗?
候选人:哦,我明白您的意思了!语文的权重天然就更大,不太公平。所以需要把每科都转换成某种标准分
面试官:对,这就是归一化的目的。具体怎么转换呢?
候选人:应该是...先算出平均分,然后看每个人偏离平均分多少,再除以标准差?
面试官 :没错,公式就是 (原始值 - 均值) / 标准差。那在神经网络里,归一化解决的是什么问题?
候选人:我想想...神经网络每一层的输出数值范围可能差异很大,有的特征值很大,有的很小。如果不归一化,那些数值大的特征会"喧宾夺主"?
面试官 :说得好。还有一点------如果数值分布不稳定,梯度也会忽大忽小,训练就容易震荡甚至发散**。归一化能让训练更稳定、更快收敛**。这个基础清楚了,我们往下走。
2. BatchNorm和LayerNorm有什么区别?
面试官:既然归一化的公式是固定的,那BatchNorm和LayerNorm的区别在哪?
候选人:它们计算均值和标准差的维度不一样?
面试官:对,但"维度不一样"太笼统了。能具体说说吗?
候选人:这个...让我想想。BatchNorm应该是在Batch维度上算的,就是把一批样本的同一个特征放在一起算均值?
面试官:继续用考试的例子来类比呢?
候选人 :哦!BatchNorm就像是看"全年级所有人的数学成绩",算出数学这科的平均分和标准差,然后给每个人的数学成绩做标准化。它关注的是某一个特征在所有样本中的分布。
面试官:那LayerNorm呢?
候选人:LayerNorm应该是...看"某一个学生的所有科目成绩"?比如小明语文130、数学85、英语100,就用小明自己这三科的平均分来标准化。它关注的是单个样本内部各特征之间的关系。
面试官:理解得很到位。那我追问一下------BatchNorm依赖什么?LayerNorm依赖什么?
候选人 :BatchNorm依赖其他样本,因为要跨样本算统计量。LayerNorm只依赖当前样本本身,不需要看别人。
面试官:这个区别会带来什么实际影响?
候选人:如果Batch Size很小,BatchNorm算出来的均值和方差就不准,会波动很大
面试官:对。而LayerNorm哪怕只有一个样本,也能正常计算。我们把区别总结成表格:
| 对比维度 | BatchNorm | LayerNorm |
|---|---|---|
| 归一化方向 | 跨样本(Batch维度) | 跨特征(特征维度) |
| 计算依赖 | 需要一批样本 | 仅需当前样本 |
| Batch Size敏感 | 是,太小会不稳定 | 否 |
| 典型应用 | CNN图像处理 | Transformer/RNN |
3. Transformer为什么选择LayerNorm?
面试官:好,现在到核心问题了。BatchNorm在CNN里非常成功,为什么Transformer不用它,而选择LayerNorm?
候选人:是因为Transformer处理的是序列数据吗?
面试官:对,但能展开说说吗?序列数据有什么特点让BatchNorm失效?
候选人:序列长度不一样!比如"我爱你"是3个词,"今天天气真不错"是6个词。如果要对齐不同样本的相同位置...第4个词根本对不上。
面试官:很好,这是第一个原因。还有呢?
候选人:还有Batch Size的问题。训练大模型的时候,显存很紧张,Batch Size经常很小,甚至只有1。这时候BatchNorm就...
面试官:就怎么样?
候选人:均值方差会非常不稳定,训练可能直接崩掉。
面试官:对。我再给你补充一个原因------训练和推理的不一致性。BatchNorm训练时用的是当前Batch的统计量,推理时用的是训练阶段累积的全局统计量。这两套标准可能有偏差,在NLP任务中这个问题尤其严重。LayerNorm呢?
候选人:LayerNorm训练和推理用的是同一套计算方式,不存在这个问题!
面试官:还有最后一点。你想想,图像里不同图片的同一个像素位置,可能都是"天空"或者"地面",有一定的统计规律。但NLP里,不同句子的第3个词可能是"苹果"、"跑步"、"美丽"------把它们混在一起算均值,有意义吗?
候选人:没意义!语义完全不相关,跨样本统计根本不成立。
面试官:总结一下,Transformer选LayerNorm的四个原因?
候选人:第一,序列长度可变,位置无法对齐;第二,Batch Size常常很小,BatchNorm不稳定;第三,BatchNorm训练推理不一致;第四,不同样本相同位置的语义无关,跨样本统计没有意义。
面试官:非常好。
4. 收尾:延伸问题
面试官:最后问一个加分题。现在主流的大模型,比如LLaMA,用的还是标准的LayerNorm吗?
候选人:好像不是...我记得是RMSNorm?它省去了均值计算,只算均方根,更快一些。
面试官:对,LLaMA、Mistral都改用了RMSNorm。那Pre-LN和Post-LN你了解吗?