目录
[3.1 RAG实战经验](#3.1 RAG实战经验)
[3.2 提示词工程的迭代之路](#3.2 提示词工程的迭代之路)
[3.3 生产环境必须考虑的问题](#3.3 生产环境必须考虑的问题)
第三部分:工程落地的那些"坑"
3.1 RAG实战经验
Retrieval-Augmented Generation (RAG) 听起来高大上,但实际落地时,全是细节。我们团队最开始简单地把文档按500字切分,扔进向量数据库,结果效果惨不忍睹
分块策略的选择
后来我们发现,按语义分块比按字数分块好得多。与其硬切,不如按段落切。如果是代码,就按函数切。我们现在的策略是:先按段落切,如果段落太长,再按句子切,并且相邻块之间保留10-20%的重叠(Overlap),防止上下文断裂
检索效果优化
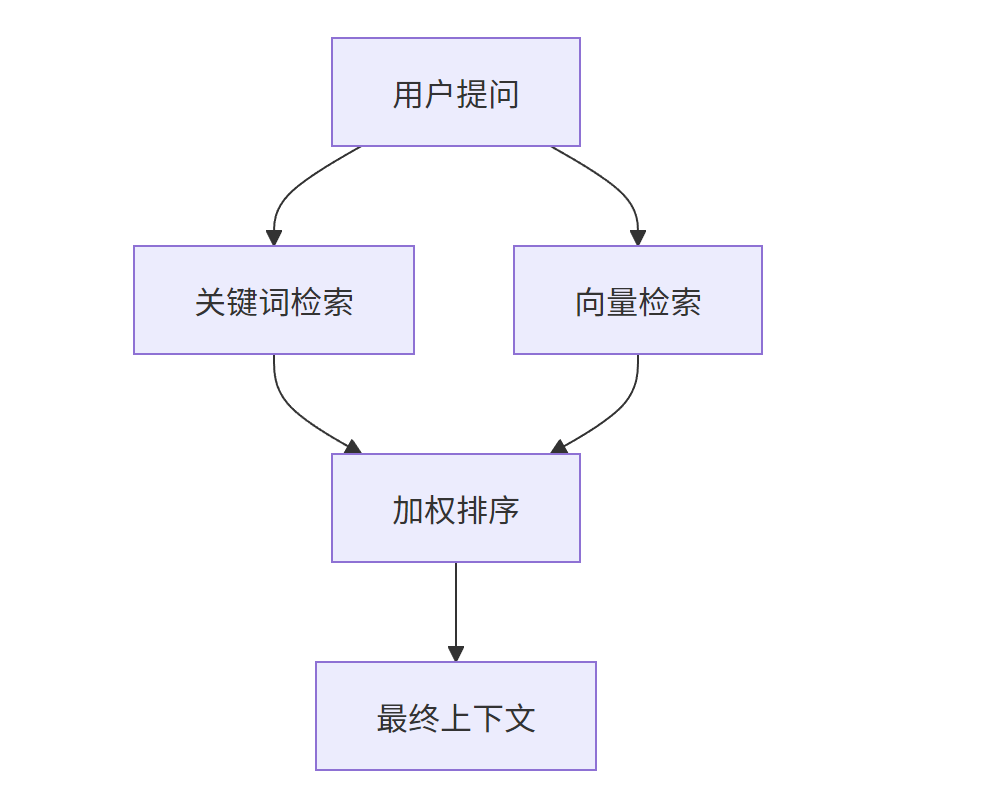
单纯的向量检索(Vector Search)对专有名词很不敏感。比如用户搜"ATM架构",向量可能给你找出一堆关于"银行取款机"的文档。解决办法是混合检索(Hybrid Search):同时用关键词检索(BM25)和向量检索,然后加权排序
3.2 提示词工程的迭代之路
Prompt不是写一次就完事的,它像代码一样需要迭代。看看我们的Prompt进化史:
- V1(小白版):
你是一个助手,请回答我的问题
- 结果:回答太发散,经常胡说八道
V2(进阶版) :
你是一个天气助手,只回答天气相关问题。如果不知道,就说不知道结果:好点了,但有时候还是会一本正经地胡说
V3(CoT版):
你是一个专业的气象分析师。
请严格遵循以下步骤思考:
- 分析用户意图,提取城市和日期
- 调用天气查询工具获取数据
- 根据数据生成简报,包含气温、湿度和穿衣建议
注意:禁止臆造数据,所有回复必须基于工具返回的结果
结果:逻辑清晰,准确率大幅提升
3.3 生产环境必须考虑的问题
并发控制 在Demo里,
agent对象可能是全局的。但在生产环境,每个用户的会话必须隔离。我们通常用session_id作为Key,把每个用户的LangChain Memory序列化存到Redis里。每次请求来了,先从Redis拉取历史记录,处理完再存回去超时与重试 LLM有时候会抽风,或者网络抖动。所有的工具调用(Tool Call)必须设置
timeout。对于非关键性的错误,可以设置自动重试(Retry),比如用tenacity库装饰一下你的工具函数成本控制 GPT-4虽好,但真贵。对于简单的意图识别,用GPT-3.5或者微调过的Llama-3足够了。另外,必须实施长上下文截断策略,防止历史记录无限堆积,把Token额度瞬间吃光
踩完了这些坑,你的Agent才算真正具备了上线的资格