
目录
[一、什么是 Linux 线程?打破你的固有认知](#一、什么是 Linux 线程?打破你的固有认知)
[1.1 线程的内核定义:进程内部的控制序列](#1.1 线程的内核定义:进程内部的控制序列)
[1.2 线程的本质:进程资源的合理划分](#1.2 线程的本质:进程资源的合理划分)
[1.3 进程与线程的核心关联](#1.3 进程与线程的核心关联)
[2.1 为什么需要虚拟内存和分页?](#2.1 为什么需要虚拟内存和分页?)
[2.2 核心概念:虚拟地址、物理地址、页和页框](#2.2 核心概念:虚拟地址、物理地址、页和页框)
[2.3 页表:虚拟地址与物理地址的桥梁](#2.3 页表:虚拟地址与物理地址的桥梁)
[2.3.1 单级页表的计算与问题](#2.3.1 单级页表的计算与问题)
[2.3.2 多级页表:解决单级页表的痛点](#2.3.2 多级页表:解决单级页表的痛点)
[2.3.3 快表 TLB:提升地址转换效率](#2.3.3 快表 TLB:提升地址转换效率)
[2.4 物理内存的管理:struct page 结构体](#2.4 物理内存的管理:struct page 结构体)
[2.4.1 struct page 的核心参数](#2.4.1 struct page 的核心参数)
[2.4.2 struct page 的内存开销](#2.4.2 struct page 的内存开销)
[2.5 缺页异常:分页机制的重要补充](#2.5 缺页异常:分页机制的重要补充)
[2.5.1 硬缺页(Hard Page Fault / Major Page Fault)](#2.5.1 硬缺页(Hard Page Fault / Major Page Fault))
[2.5.2 软缺页(Soft Page Fault / Minor Page Fault)](#2.5.2 软缺页(Soft Page Fault / Minor Page Fault))
[2.5.3 无效缺页(Invalid Page Fault)](#2.5.3 无效缺页(Invalid Page Fault))
[2.5.4 缺页异常与越界访问的区分](#2.5.4 缺页异常与越界访问的区分)
[2.6 分页机制与线程的关联](#2.6 分页机制与线程的关联)
[三、Linux 线程的优点:为什么选择多线程?](#三、Linux 线程的优点:为什么选择多线程?)
[3.1 线程创建和切换的开销远小于进程](#3.1 线程创建和切换的开销远小于进程)
[3.1.1 线程创建开销小](#3.1.1 线程创建开销小)
[3.1.2 线程切换开销小](#3.1.2 线程切换开销小)
[3.2 线程占用的系统资源更少](#3.2 线程占用的系统资源更少)
[3.3 充分利用多核 CPU 的并行能力](#3.3 充分利用多核 CPU 的并行能力)
[3.4 实现 I/O 操作与计算操作的重叠](#3.4 实现 I/O 操作与计算操作的重叠)
[3.5 提升计算密集型和 I/O 密集型程序的性能](#3.5 提升计算密集型和 I/O 密集型程序的性能)
[四、Linux 线程的缺点:多线程的 "坑" 在哪里?](#四、Linux 线程的缺点:多线程的 “坑” 在哪里?)
[4.1 存在额外的性能损失](#4.1 存在额外的性能损失)
[4.2 程序的健壮性大幅降低](#4.2 程序的健壮性大幅降低)
[4.3 缺乏独立的访问控制](#4.3 缺乏独立的访问控制)
[4.4 编程和调试难度大幅提升](#4.4 编程和调试难度大幅提升)
[五、Linux 线程的异常:一个线程出错,整个进程陪葬](#五、Linux 线程的异常:一个线程出错,整个进程陪葬)
[5.1 线程异常的本质](#5.1 线程异常的本质)
[5.2 常见的线程异常场景](#5.2 常见的线程异常场景)
[5.3 线程异常的处理方式](#5.3 线程异常的处理方式)
[六、Linux 线程的用途:哪些场景适合使用多线程?](#六、Linux 线程的用途:哪些场景适合使用多线程?)
[6.1 充分利用多核 CPU 的计算密集型应用](#6.1 充分利用多核 CPU 的计算密集型应用)
[6.2 提升响应速度的 I/O 密集型应用](#6.2 提升响应速度的 I/O 密集型应用)
[6.3 需要资源共享的并发应用](#6.3 需要资源共享的并发应用)
[6.4 提升用户体验的交互式应用](#6.4 提升用户体验的交互式应用)
前言
在 Linux 开发的世界里,线程是绕不开的核心概念,它是程序并发执行的基础,也是充分利用多核 CPU 资源的关键。很多开发者在学习线程时,往往只停留在 API 调用层面,对其底层原理、与进程的本质区别、虚拟地址空间的关联等内容一知半解,导致在编写多线程程序时频繁出现各种诡异的问题。
本文将从Linux 线程的本质定义出发,深入剖析分页式存储管理的底层逻辑(这是理解线程运行的核心),再详细讲解线程的优缺点、异常处理和实际用途,用通俗的语言拆解复杂概念,让你真正吃透 Linux 线程的底层逻辑,做到知其然更知其所以然。下面就让我们正式开始吧!
一、什么是 Linux 线程?打破你的固有认知
提到线程,很多教材的定义是 "程序执行的最小单位",这个定义太抽象,无法让我们理解 Linux 下线程的本质。在 Linux 系统中,线程的设计有其独特性,我们需要从内核视角 和进程视角两个维度来重新定义线程。
1.1 线程的内核定义:进程内部的控制序列
在 Linux 中,线程的准确定义是:一个进程内部的控制序列。这句话包含两个核心要点:
- **线程依赖进程存在:**一切进程至少都有一个执行线程(主线程),线程无法脱离进程独立运行,它是进程的一部分。
- **线程在进程地址空间内运行:**线程的所有执行操作,都是在所属进程的虚拟地址空间中完成的,它不会拥有独立的地址空间。
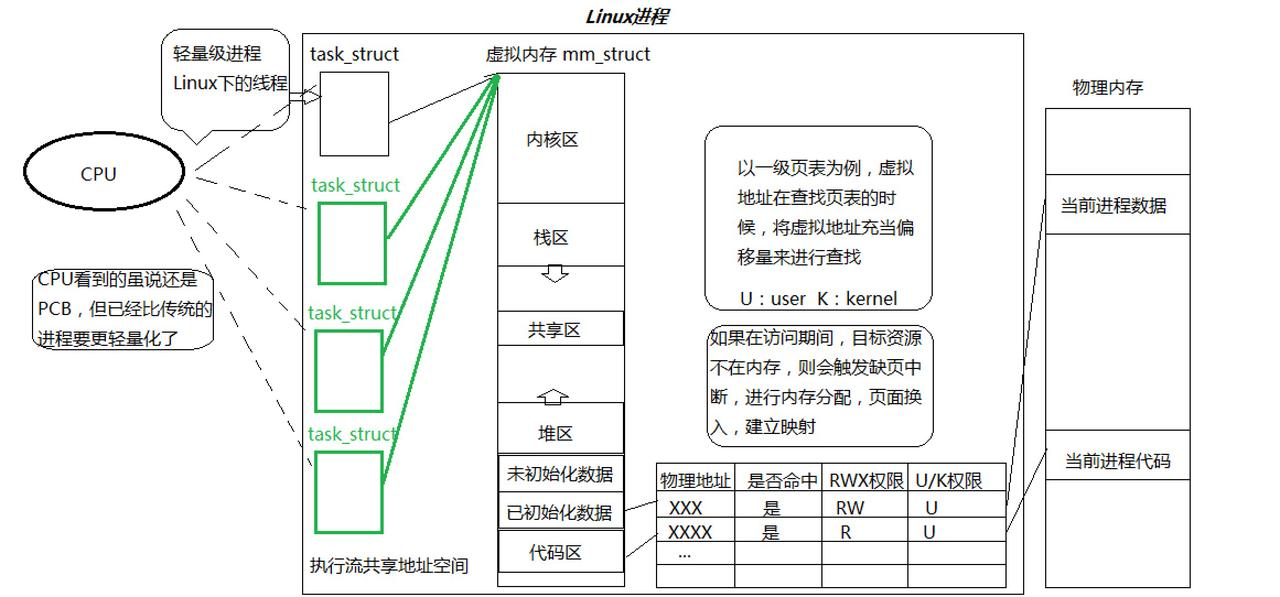
从 Linux 内核的角度来看,并不存在专门的线程结构体 ,我们常说的线程,其实是轻量级进程(Light Weight Process,LWP) 。内核中表示进程 / 线程的结构体都是**task_struct,只不过线程的task_struct**相比传统进程更加 "轻量化"------ 多个线程会共享同一个进程的大部分资源,而传统进程之间是完全独立的。
简单来说,Linux 内核对进程和线程的管理是 "一视同仁" 的,CPU 调度器看到的都是**task_struct**,只是线程的资源共享特性让它成为了 "轻量级" 的执行单元。
1.2 线程的本质:进程资源的合理划分
进程拥有系统分配的完整资源(虚拟地址空间、文件描述符、内存等),而线程的本质,就是将进程的资源合理分配给每个执行流,从而形成的多个并发执行的控制序列。
举个通俗的例子:如果把进程比作一家公司,那么公司拥有的办公场地、设备、资金就是进程的资源,而线程就是公司里的各个员工 ------ 员工共享公司的所有资源,同时各自执行不同的工作任务,共同完成公司的整体目标。如果公司只有一个员工,就是单线程进程;有多个员工,就是多线程进程。
1.3 进程与线程的核心关联
通过上面的分析,我们可以总结出 Linux 下进程和线程的核心关联:
- 进程是资源分配的基本单位:操作系统会为每个进程分配独立的虚拟地址空间、文件描述符表等资源,进程是资源分配的最小粒度。
- 线程是调度和执行的基本单位:CPU 调度器以线程为单位进行调度,CPU 执行的是线程的指令流,而不是进程。
- 多线程共享进程资源:同一个进程的所有线程,共享进程的代码段、数据段、堆区、文件描述符表等核心资源,同时每个线程拥有自己的私有资源(后续会详细讲解)。
二、分页式存储管理:理解线程运行的底层基石
要真正理解线程为什么能共享进程的地址空间,以及线程的运行机制,就必须掌握分页式存储管理的原理。因为 Linux 系统通过虚拟地址空间和分页机制,实现了进程资源的管理和共享,而线程正是基于这一机制实现的。
2.1 为什么需要虚拟内存和分页?
在没有虚拟内存和分页机制的早期计算机中,用户程序直接访问物理内存,带来了两个致命问题:
- 物理内存空间不连续 :每个程序的代码、数据长度不同,加载到物理内存后会分割出大量离散的内存块,程序退出后会产生内存碎片,导致后续程序无法利用这些碎片空间。
- 地址空间隔离性差:多个程序直接访问物理内存,容易出现地址冲突,一个程序的错误操作可能会覆盖另一个程序的内存数据,导致系统崩溃。
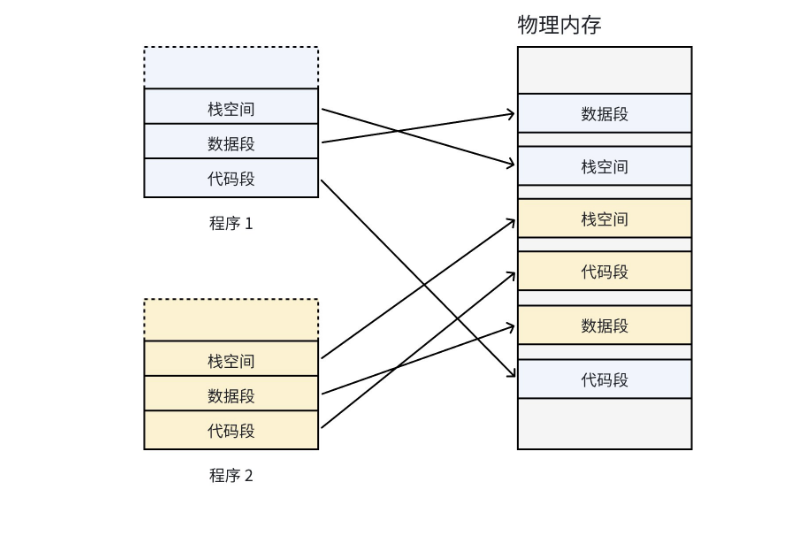
为了解决这些问题,操作系统引入了虚拟地址空间 和分页式存储管理 机制,核心思想是:给用户程序提供连续的虚拟地址空间,而实际映射到物理内存的空间可以是离散的。
2.2 核心概念:虚拟地址、物理地址、页和页框
在分页机制中,有四个核心概念必须掌握,我们用通俗的语言解释:
- 虚拟地址 :操作系统为每个进程分配的逻辑地址空间 ,进程所有的内存操作都是基于虚拟地址,而不是直接操作物理地址。在 32 位 Linux 系统中,虚拟地址空间的范围是
0 ~ 4G-1;64 位系统则是更大的地址范围。- 物理地址:计算机实际的内存硬件地址,是内存单元的真实编号,CPU 最终需要通过物理地址访问内存。
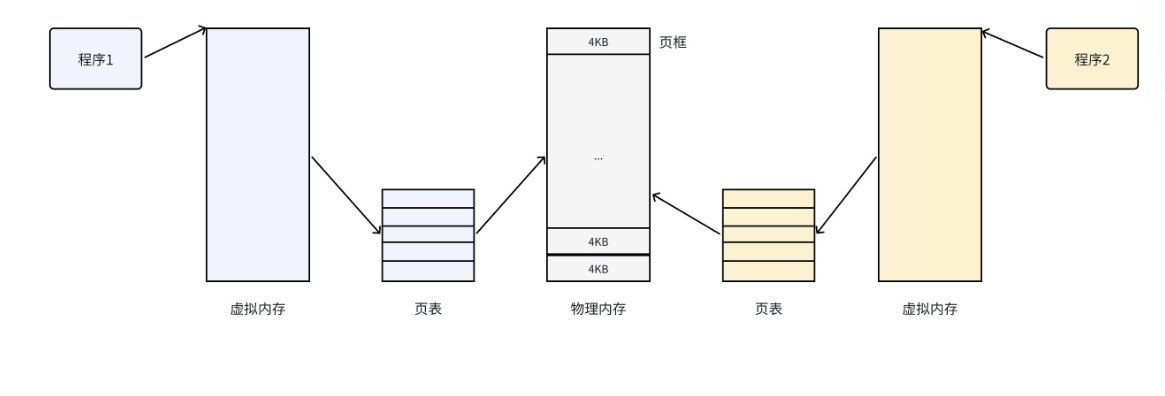
- 页(Page) :虚拟地址空间被划分为大小固定的数据块,称为页。大多数 32 位体系结构的页大小为 4KB,64 位体系结构一般为 8KB。
- 页框(Page Frame) :物理内存被划分为与页大小相同的存储区域,称为页框。页是数据块,页框是存储区域,一个页可以存放在任意一个页框中。
简单来说,分页机制就是将虚拟地址空间切分成页,物理内存切分成页框 ,然后通过一张表建立页和页框的映射关系,这张表就是页表。
2.3 页表:虚拟地址与物理地址的桥梁
页表 是操作系统为每个进程维护的映射表,它记录了虚拟地址的每一个页,对应到物理内存的哪一个页框。CPU 通过页表,将虚拟地址转换为物理地址,从而实现对内存的访问,这个转换过程由硬件内存管理单元(MMU) 完成,效率极高。
2.3.1 单级页表的计算与问题
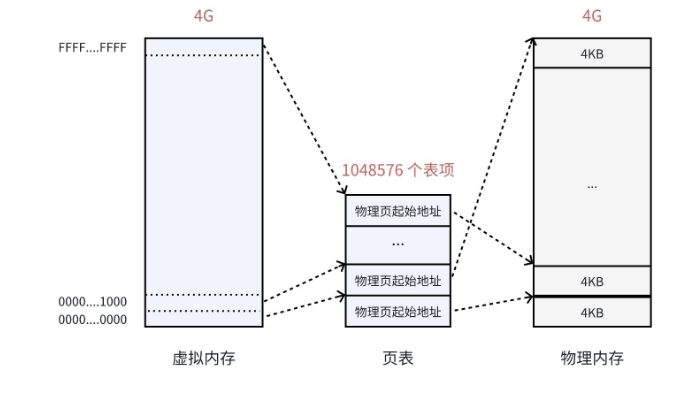
我们以 32 位 Linux 系统、4KB 页大小为例,计算单级页表的基本参数:
- 虚拟地址空间大小:4GB = 2^32 字节
- 单个页大小:4KB = 2^12 字节
- 页表项数量:4GB / 4KB = 1048576 个(1024*1024)
- 若每个页表项占 4 字节,页表总大小:1048576 * 4B = 4MB
单级页表的问题很明显:需要连续的 4MB 物理内存来存储页表,这与我们引入分页机制 "解决物理内存不连续" 的初衷相悖;同时,进程在运行时往往只需要访问少量页,单级页表会加载所有页表项,造成内存资源的浪费。
2.3.2 多级页表:解决单级页表的痛点
为了解决单级页表的问题,Linux 引入了多级页表 (32 位系统为二级页表,64 位系统为四级页表),核心思想是对页表再进行分页,离散存储。
以 32 位系统的二级页表 为例,虚拟地址的高 20 位被拆分为两个 10 位,分别对应页目录号 和页表号 ,低 12 位为页内偏移:
- **第一级:**页目录表,包含 1024 个页目录项,每个项指向一个二级页表。
- **第二级:**页表,共 1024 个,每个页表包含 1024 个页表项,每个项指向物理内存的页框。
- **页内偏移:**确定虚拟地址在物理页框中的具体位置(0~4095)。
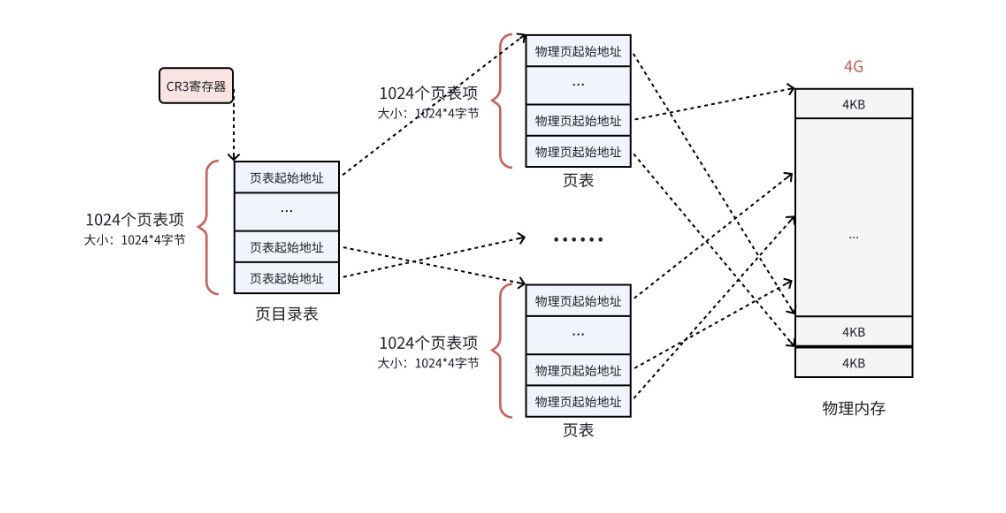
二级页表的优势在于:只有进程实际访问的页对应的页表,才会被加载到物理内存中,大大节省了物理内存资源。例如,一个 10MB 的程序,只需要 3 个二级页表(4MB*3=12MB),而不是 1024 个。
2.3.3 快表 TLB:提升地址转换效率
多级页表解决了内存浪费的问题,但带来了新的问题:地址转换需要多次查询页表(二级页表需要 2 次),降低了访问效率。
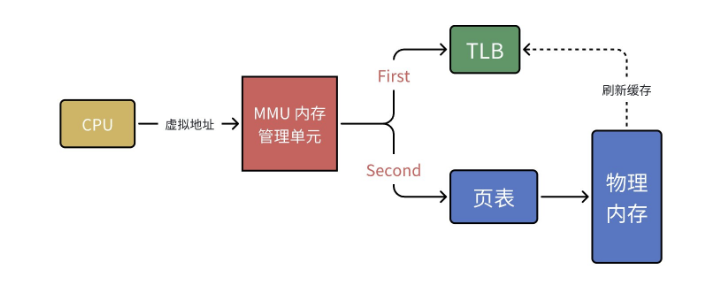
为了解决这个问题,MMU 引入了快表(Translation Lookaside Buffer,TLB),也叫转译后备缓冲器,本质是一个高速缓存,用于存储最近访问的虚拟地址和物理地址的映射关系。
CPU 的地址转换流程优化为:
- CPU 发出虚拟地址,MMU 首先查询 TLB,若存在对应的映射关系(TLB 命中),直接得到物理地址,访问内存。
- 若 TLB 中没有对应的映射(TLB 缺失),MMU 再去查询页表,得到物理地址后,将该映射关系写入 TLB,同时访问内存。
TLB 的访问速度接近 CPU 的运算速度,大大提升了地址转换的效率,是分页机制中不可或缺的组成部分。
2.4 物理内存的管理:struct page 结构体
操作系统需要对物理内存的所有页框进行管理,知道哪些页框被使用、哪些空闲、哪些被锁定等。在 Linux 内核中,用struct page结构体表示系统中的每个物理页框,它定义在include/linux/mm_types.h中。
2.4.1 struct page 的核心参数
struct page包含了物理页框的所有状态信息,核心参数有:
- flags:页框的状态标志,每一位表示一种状态,可同时表示 32 种状态(如**
PG_locked** 表示页框被锁定、PG_dirty表示页框数据被修改、**PG_uptodate**表示页框数据从磁盘读取完成)。- _mapcount:页表中指向该页框的表项数量,即页框的引用计数。当计数为 - 1 时,页框为空闲状态,可被重新分配。
- virtual:页框的内核虚拟地址。对于高端内存,该值为 NULL,需要动态映射。
2.4.2 struct page 的内存开销
struct page的大小约为 40 字节,我们以 4GB 物理内存、4KB 页框为例,计算其内存开销:
- 物理页框数量:4GB / 4KB = 1048576 个
- 总开销:1048576 * 40B = 40MB
40MB 的开销相对于 4GB 的物理内存来说,占比极小,因此这种管理方式的代价是完全可接受的。
2.5 缺页异常:分页机制的重要补充
在程序运行过程中,CPU 发出的虚拟地址,可能在 TLB 和页表中都没有对应的物理页框映射,这种情况称为缺页异常(Page Fault)。缺页异常是由硬件中断触发的,内核会通过缺页异常处理程序(Page Fault Handler) 进行处理,它是分页机制的重要补充。
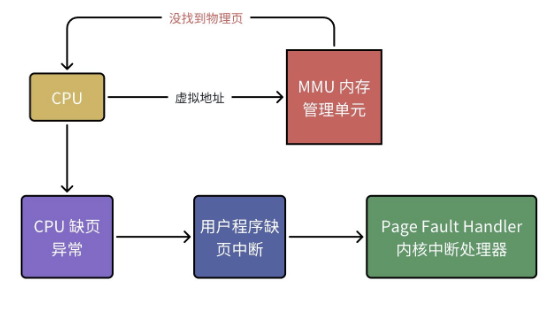
根据缺页的原因,缺页异常分为三类:
2.5.1 硬缺页(Hard Page Fault / Major Page Fault)
物理内存中没有对应的页框,需要内核从磁盘(交换分区或文件系统)中将数据读取到物理内存,再建立虚拟地址和物理地址的映射。硬缺页会产生磁盘 I/O 操作,开销较大。
2.5.2 软缺页(Soft Page Fault / Minor Page Fault)
物理内存中已经存在对应的页框,只是当前进程没有建立映射关系(例如多进程共享内存区域时,其他进程已经将数据加载到物理内存)。此时内核只需要建立映射即可,无需磁盘 I/O,开销较小。
2.5.3 无效缺页(Invalid Page Fault)
进程访问的虚拟地址是非法的(如地址越界、对空指针解引用),内核会触发段错误(Segment Fault),直接终止进程。这也是我们编写程序时常见的错误之一。
2.5.4 缺页异常与越界访问的区分
很多开发者会混淆缺页异常和越界访问,内核通过两个步骤进行严格区分:
- 页号合法性检查:检查虚拟地址的页号是否在进程的有效页号范围内。若页号合法但无物理映射,为缺页异常;若页号非法,为越界访问。
- 内存映射检查:检查虚拟地址是否在当前进程的内存映射范围内。若在范围内但无物理映射,为缺页异常;若不在范围内,为越界访问。
2.6 分页机制与线程的关联
看到这里,你可能会问:分页机制和线程有什么关系?
答案很简单:线程的资源共享特性,正是基于进程的虚拟地址空间和分页机制实现的。同一个进程的所有线程,共享同一个虚拟地址空间,也就共享了进程的页表 ------ 所有线程的虚拟地址,通过同一个页表映射到物理内存,因此线程可以直接访问进程的代码段、数据段、堆区等资源。
换句话说,只要将进程的虚拟地址空间进行合理划分,进程的资源就天然被分配给了各个线程,这就是线程资源划分的本质。
三、Linux 线程的优点:为什么选择多线程?
相比多进程,多线程是实现程序并发的更优选择,这是由线程的资源共享特性决定的。Linux 线程的优点主要体现在性能、资源利用率、并发能力等方面,具体如下:
3.1 线程创建和切换的开销远小于进程
3.1.1 线程创建开销小
创建一个新进程时,操作系统需要为其分配独立的虚拟地址空间、页表、文件描述符表等资源,还要复制父进程的内存数据(写时拷贝),开销极大。
而创建一个新线程时,操作系统只需要为其创建一个轻量级的**task_struct**,并分配少量私有资源(如栈、寄存器),无需分配新的虚拟地址空间和页表,因为线程共享所属进程的所有资源,因此创建线程的开销远小于创建进程。
3.1.2 线程切换开销小
进程切换时,操作系统需要完成以下工作:
- 保存当前进程的上下文(寄存器、程序计数器等)。
- 切换虚拟地址空间,刷新 TLB(快表)。
- 加载目标进程的上下文。
其中,刷新 TLB是进程切换的最大开销 ------TLB 中存储的是当前进程的虚拟地址映射,切换进程后需要清空 TLB,导致后续的内存访问都需要重新查询页表,效率大幅降低。
而线程切换时,由于多个线程共享同一个虚拟地址空间和页表,不需要切换虚拟地址空间,也不需要刷新 TLB,只需要保存和加载线程的私有上下文即可,因此切换开销远小于进程。
3.2 线程占用的系统资源更少
进程是资源分配的基本单位,每个进程都拥有独立的资源集合,即使是父子进程,也只是通过写时拷贝共享内存数据,其他资源(如文件描述符表)是独立的。
而线程共享进程的大部分资源,每个线程只拥有少量私有资源(线程 ID、栈、寄存器、errno、信号屏蔽字、调度优先级),因此多个线程的总资源占用,远小于相同数量的进程。
在资源受限的系统中(如嵌入式 Linux),多线程是实现并发的唯一选择。
3.3 充分利用多核 CPU 的并行能力
现代 CPU 都是多核架构,单线程程序只能利用一个 CPU 核心,无法发挥多核的优势。而多线程程序可以将不同的任务分配到不同的 CPU 核心上并行执行,大幅提升程序的运行效率。
例如,一个计算密集型程序,使用 8 线程可以充分利用 8 核 CPU 的资源,运行效率理论上可以提升 8 倍(忽略线程调度和同步开销)。
3.4 实现 I/O 操作与计算操作的重叠
在实际开发中,很多程序会涉及大量的 I/O 操作(如文件读写、网络通信、设备访问),而 I/O 操作的速度远慢于 CPU 的计算速度。如果使用单线程,程序会在 I/O 操作时阻塞,CPU 处于空闲状态,资源利用率极低。
而使用多线程可以实现I/O 操作与计算操作的重叠:一个线程进行 I/O 操作时(阻塞),其他线程可以进行 CPU 计算,充分利用 CPU 资源。
例如,在网络服务器程序中,一个线程负责接收客户端的网络请求(I/O 操作),其他线程负责处理请求(计算操作),服务器的并发处理能力会大幅提升。
3.5 提升计算密集型和 I/O 密集型程序的性能
根据程序的特性,可将其分为计算密集型 和I/O 密集型,多线程对这两种程序的性能都有显著提升:
- 计算密集型程序:将计算任务拆分为多个子任务,分配到多个线程并行执行,充分利用多核 CPU 资源,提升计算效率。
- I/O 密集型程序:通过多线程让多个 I/O 操作并行执行,同时让 I/O 操作和计算操作重叠,提升程序的响应速度和资源利用率。
四、Linux 线程的缺点:多线程的 "坑" 在哪里?
虽然多线程有诸多优点,但它并不是 "银弹",多线程程序的开发和维护难度远大于单线程程序,同时还存在性能损失、健壮性降低、编程难度提升等问题,这些都是开发者在使用多线程时需要注意的 "坑"。
4.1 存在额外的性能损失
在某些场景下,多线程不仅不会提升性能,还会带来额外的性能损失,主要体现在两个方面:
- 线程调度开销:当线程数量远大于 CPU 核心数量时,操作系统会频繁进行线程切换,而线程切换本身需要消耗 CPU 资源,导致程序的有效运行时间减少。
- 线程同步开销 :多个线程共享进程资源,当多个线程同时访问临界资源(如全局变量、文件)时,需要通过互斥锁、条件变量等同步机制进行保护,同步操作会带来额外的开销,甚至可能导致线程阻塞,降低程序的并发能力。
例如,一个计算密集型程序,若线程数量远大于 CPU 核心数,线程调度的开销会远大于并行计算带来的收益,程序的运行效率反而会下降。因此,在设计多线程程序时,线程数量一般建议设置为CPU 核心数 或CPU 核心数 + 1。
4.2 程序的健壮性大幅降低
健壮性是指程序在异常情况下的容错能力。单线程程序的错误通常只影响自身,而多线程程序的错误可能会导致整个进程崩溃,甚至影响其他线程的运行,主要原因有:
- 线程缺乏保护机制:线程共享进程的所有资源,一个线程的错误操作(如野指针、数组越界)可能会修改其他线程的内存数据,导致其他线程运行异常。
- 线程异常会导致进程崩溃:单个线程出现异常(如除零错误、段错误)时,内核会触发信号机制,终止整个进程,进程中的所有线程都会随之退出(后续会详细讲解线程异常)。
- 同步问题难以排查 :多线程的同步问题(如死锁、竞态条件)具有偶发性 和不可复现性,排查难度极大,往往需要借助专业的调试工具(如 GDB、Valgrind)。
例如,一个多线程程序中,线程 A 因野指针修改了进程的代码段数据,线程 B 在执行该代码段时会出现非法指令,最终导致整个进程崩溃。
4.3 缺乏独立的访问控制
在 Linux 中,进程是访问控制的基本粒度,操作系统的所有访问控制策略(如文件权限、用户组权限、内存权限)都是针对进程的,而不是线程。
这意味着,一个线程的操作会影响整个进程:
- 线程调用**chdir()**修改当前工作目录,整个进程的工作目录都会被修改,其他线程也会受到影响。
- 线程调用**close()**关闭一个文件描述符,整个进程的该文件描述符都会被关闭,其他线程无法再访问该文件。
- 线程修改进程的信号处理方式,整个进程的信号处理方式都会被修改,其他线程也会受到影响。
因此,在多线程程序中,线程的操作需要更加谨慎,避免因单个线程的操作影响整个进程的运行。
4.4 编程和调试难度大幅提升
编写正确、高效的多线程程序,对开发者的要求极高,相比单线程程序,多线程程序的编程和调试难度主要体现在:
- 需要考虑同步机制:开发者需要手动处理线程之间的同步问题,如互斥锁、条件变量、信号量等,若同步机制使用不当,会导致死锁、竞态条件、数据不一致等问题。
- 线程的执行顺序不确定:CPU 调度器对线程的调度是随机的,线程的执行顺序无法预测,这会导致程序的行为具有不确定性,增加了调试难度。
- 调试工具有限:传统的调试工具(如 GDB)对多线程程序的调试支持有限,难以跟踪多个线程的执行流程,排查同步问题和死锁问题需要借助专业的工具。
例如,一个多线程程序出现数据不一致的问题,可能是因为多个线程同时访问临界资源而未加锁,也可能是因为锁的粒度设置不合理,排查这类问题需要开发者对程序的执行流程有清晰的认识。
五、Linux 线程的异常:一个线程出错,整个进程陪葬
线程的异常处理是多线程程序开发的重点,也是难点。在 Linux 中,线程的异常会直接导致整个进程的崩溃,这是由线程和进程的资源共享特性决定的,也是多线程程序健壮性降低的核心原因。
5.1 线程异常的本质
线程是进程内部的控制序列,共享进程的虚拟地址空间和所有资源。当单个线程出现异常时(如除零错误、野指针、段错误、非法指令),内核会将其视为进程的异常 ,触发对应的信号机制(如SIGFPE、SIGSEGV、SIGILL)。
而 Linux 中进程对信号的默认处理方式是终止进程,因此当线程出现异常时,内核会向进程发送对应的信号,进程被终止后,该进程内的所有线程都会随之退出,这就是 "一个线程出错,整个进程陪葬" 的本质。
5.2 常见的线程异常场景
在实际开发中,常见的线程异常场景主要有:
- 除零错误 :线程执行除法运算时,除数为 0,触发
SIGFPE信号,进程被终止。- 野指针访问 :线程使用未初始化的指针或已释放的指针访问内存,触发
SIGSEGV信号,进程被终止。- 数组越界 :线程访问数组时,下标超出数组的有效范围,修改了非法的内存区域,触发
SIGSEGV信号,进程被终止。- 非法指令 :线程执行了无效的机器指令,触发
SIGILL信号,进程被终止。- 栈溢出 :线程的栈空间被耗尽(如递归调用过深),触发
SIGSEGV信号,进程被终止。
5.3 线程异常的处理方式
由于线程异常会导致整个进程崩溃,因此在多线程程序中,必须对线程的异常进行处理,常见的处理方式有:
- 严格的代码审查:在编写代码时,对指针、数组、除法运算等进行严格的检查,避免出现基础的错误,从源头减少线程异常。
- 信号处理 :在进程中注册信号处理函数,捕获线程异常触发的信号(如
SIGSEGV、SIGFPE),在信号处理函数中进行资源释放、日志记录等操作,然后优雅地终止进程。- 进程隔离:将关键的线程封装为独立的进程,通过进程间通信(IPC)进行交互,这样一个进程的崩溃不会影响其他进程,提升整个系统的健壮性。
- 监控线程:在进程中创建一个监控线程,定期检查其他线程的运行状态,若发现线程异常,及时进行处理(如重启线程、释放资源)。
需要注意的是,Linux 不支持单独终止一个异常的线程,只能通过终止进程的方式来处理线程异常,这是由 Linux 的线程设计决定的。
六、Linux 线程的用途:哪些场景适合使用多线程?
多线程并非万能的,只有在合适的场景下使用,才能发挥其优势。根据线程的特性,Linux 线程主要适用于需要并发执行、资源共享、低开销的场景,具体分为以下几类,同时我们也会给出对应的应用示例。
6.1 充分利用多核 CPU 的计算密集型应用
计算密集型应用的特点是程序的大部分时间都在进行 CPU 计算,如数据处理、数值计算、图像渲染、加密解密等。这类应用的性能瓶颈是 CPU 的计算能力,单线程程序无法利用多核 CPU 的优势,运行效率极低。
多线程的解决方案:将计算任务拆分为多个独立的子任务,为每个子任务创建一个线程,分配到不同的 CPU 核心上并行执行,充分利用多核 CPU 的计算能力,大幅提升程序的运行效率。
应用示例:
- 大数据分析程序:将海量数据拆分为多个数据块,多个线程同时对不同的数据块进行分析。
- 图像渲染程序:将图像的不同区域分配给不同的线程,同时进行渲染,提升渲染速度。
- 加密解密程序:将大文件拆分为多个块,多个线程同时对不同的块进行加密 / 解密操作。
6.2 提升响应速度的 I/O 密集型应用
I/O 密集型应用的特点是程序的大部分时间都在进行 I/O 操作,如文件读写、网络通信、数据库操作、设备访问等。这类应用的性能瓶颈是 I/O 操作的速度,单线程程序会在 I/O 操作时阻塞,CPU 处于空闲状态。
多线程的解决方案:通过多线程让多个 I/O 操作并行执行,同时让 I/O 操作和计算操作重叠,充分利用 CPU 资源,提升程序的响应速度和并发处理能力。
应用示例:
- 网络服务器:如 Web 服务器、Socket 服务器,一个线程负责监听客户端连接,多个线程负责处理客户端的请求,实现高并发。
- 文件下载工具:多个线程同时从服务器下载文件的不同部分,提升下载速度。
- 数据库客户端:多个线程同时执行数据库查询操作,提升数据处理效率。
6.3 需要资源共享的并发应用
在某些应用场景中,多个执行流需要频繁地共享数据和资源,如实时监控系统、生产消费模型、消息队列等。如果使用多进程,进程间的资源共享需要通过管道、共享内存、消息队列等 IPC 机制实现,开销大、效率低。
多线程的解决方案:线程共享进程的所有资源,多个线程可以直接访问全局变量、堆区、文件描述符等资源,无需额外的 IPC 机制,资源共享的效率极高,开销极低。
应用示例:
- 生产消费模型:生产者线程生产数据,写入共享的缓冲区,消费者线程从缓冲区读取数据并处理,实现数据的高效传递。
- 实时监控系统:多个监控线程采集不同的监控数据(如 CPU 使用率、内存使用率、磁盘 I/O),写入共享的内存区域,主线程从共享区域读取数据并展示。
- 消息队列:多个生产者线程向消息队列中写入消息,多个消费者线程从消息队列中读取消息并处理,实现消息的并发处理。
6.4 提升用户体验的交互式应用
交互式应用的特点是需要及时响应用户的操作,如图形界面程序、终端工具、游戏等。如果使用单线程,当程序进行耗时的操作(如文件读写、网络请求)时,会阻塞用户界面,导致用户体验极差。
多线程的解决方案:将耗时的操作放到后台线程中执行,主线程专门负责响应用户的操作,保证用户界面的流畅性,提升用户体验。
应用示例:
- 图形界面程序:如 Qt、GTK 开发的程序,主线程负责绘制界面、响应用户的鼠标和键盘操作,后台线程负责进行文件读写、网络请求等耗时操作。
- 代码编辑器:主线程负责代码编辑、语法高亮,后台线程负责代码检查、自动补全、文件保存等操作。
- 游戏程序:主线程负责游戏画面的渲染、用户的操作响应,后台线程负责游戏逻辑计算、资源加载、网络通信等操作。
总结
学习 Linux 线程,不能只停留在 API 调用层面,更要理解其底层原理和内核设计思想。只有这样,才能在编写多线程程序时,做到心中有数,规避各种坑,写出高效、稳定、可靠的多线程程序。
后续我会继续讲解 Linux 线程的控制(创建、终止、等待、分离)、线程同步机制(互斥锁、条件变量、信号量)、线程安全等内容,敬请关注!
创作不易,若本文对你有帮助,欢迎点赞、收藏、关注!