Linux进程管理深度解析:从fork到内核链表设计

🎬 Doro在努力 :个人主页
🔥 个人专栏 : 《MySQL数据库基础语法》《数据结构》
⛺️严于律己,宽以待人
文章目录
- Linux进程管理深度解析:从fork到内核链表设计
-
- 一、fork系统调用:进程创建的奥秘
-
- [1.1 父进程如何创建子进程](#1.1 父进程如何创建子进程)
- [1.2 代码共享与数据分离](#1.2 代码共享与数据分离)
- [1.3 fork为什么会有两个返回值](#1.3 fork为什么会有两个返回值)
- [1.4 同一个变量如何既等于0又大于0](#1.4 同一个变量如何既等于0又大于0)
- 二、进程状态:从概念到实现
-
- [2.1 进程状态的本质](#2.1 进程状态的本质)
- [2.2 运行状态与调度队列](#2.2 运行状态与调度队列)
- [2.3 阻塞状态与等待队列](#2.3 阻塞状态与等待队列)
- 三、Linux内核链表:嵌入式设计的艺术
-
- [3.1 传统链表 vs 内核链表](#3.1 传统链表 vs 内核链表)
- [3.2 偏移量计算:从链表节点到结构体](#3.2 偏移量计算:从链表节点到结构体)
- [3.3 一个节点,多个链表](#3.3 一个节点,多个链表)
- 四、虚拟地址空间:程序员的视角与物理现实
-
- [4.1 虚拟地址 vs 物理地址](#4.1 虚拟地址 vs 物理地址)
- [4.2 写时拷贝的页表操作](#4.2 写时拷贝的页表操作)
- 五、总结与思考
- 参考代码示例
一、fork系统调用:进程创建的奥秘
1.1 父进程如何创建子进程
在Linux系统中,当我们谈论进程创建时,fork系统调用无疑是绕不开的核心话题。很多同学在学习fork时,往往只停留在"调用fork就能创建子进程"这样的表面认知上,但对于其内部究竟发生了什么,却知之甚少。今天,我们就来彻底搞懂这个问题。
首先,我们需要明确一个概念:进程等于内核数据结构加上自己的代码和数据 。这里的内核数据结构,在Linux中就是著名的task_struct结构体,也就是我们常说的PCB(Process Control Block,进程控制块)。当一个父进程调用fork创建子进程时,操作系统内部实际上执行了一系列精密的操作。
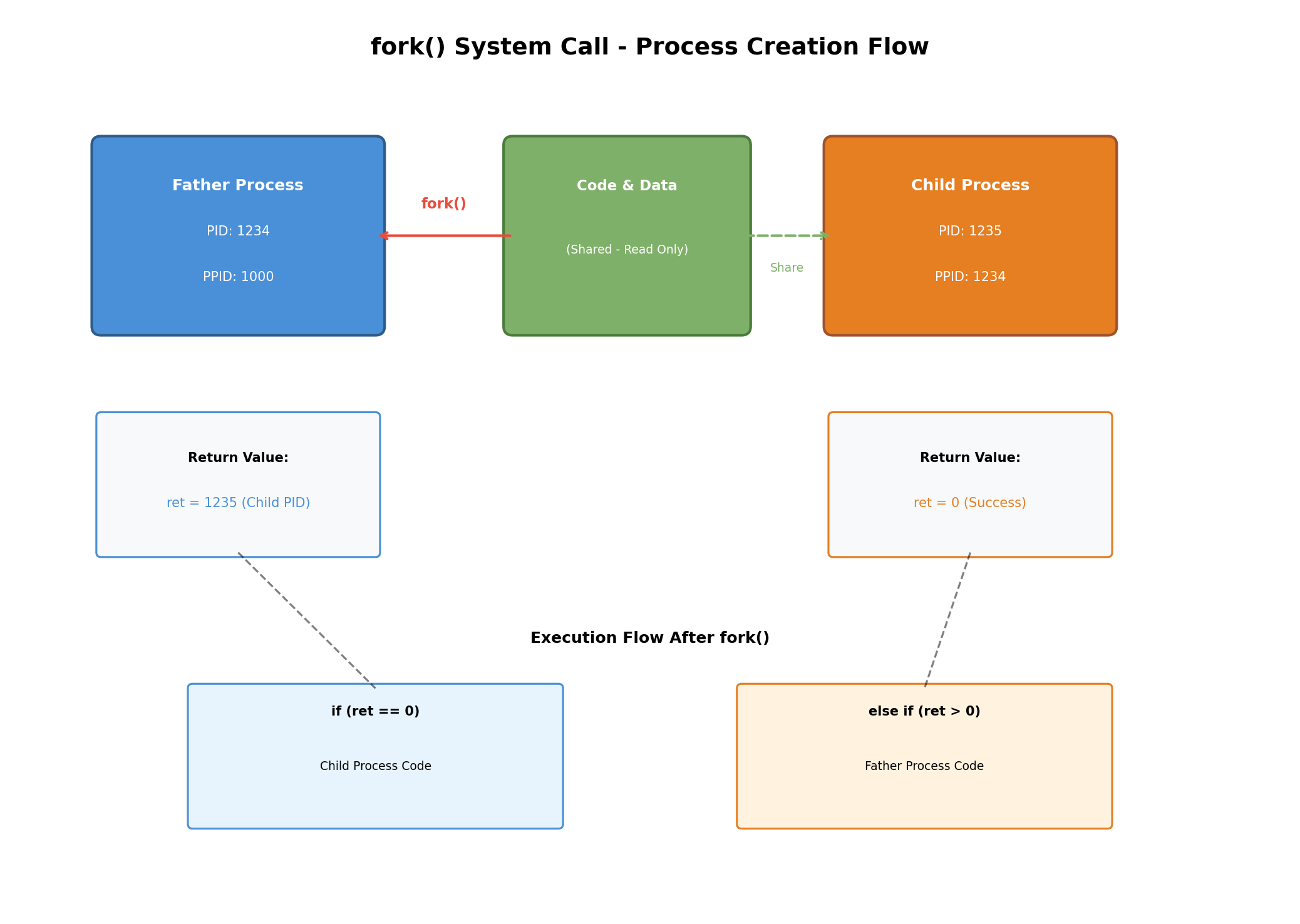
父进程创建子进程的过程,本质上是以父进程为模板进行的。具体来说,操作系统会为子进程分配一个新的task_struct结构体,然后将父进程的task_struct中的大部分属性直接拷贝给子进程。这包括进程的优先级、状态、时间片、当前工作路径、可执行程序路径等等。但是,子进程毕竟是全新的进程,它必须拥有自己独立的PID(进程标识符)和PPID(父进程标识符)。因此,在拷贝完成后,操作系统会修改这两个字段,确保子进程的身份信息是独立的。
这种"以父进程为模板"的设计带来了许多便利。例如,子进程会继承父进程的当前工作路径,这意味着如果父进程在某个目录下创建文件,子进程默认也会在同一个目录下创建文件。这种继承机制在多进程协作编程中非常实用,它确保了父子进程在文件系统层面的工作环境是一致的。
1.2 代码共享与数据分离
fork创建子进程后,一个非常关键的问题是:父子进程的代码和数据是如何处理的? 这里就涉及到了Linux进程管理的一个核心设计原则。
首先,关于代码部分。父进程的代码是从磁盘加载到内存中的,当fork创建子进程时,子进程并不会重新从磁盘加载一份代码,而是直接共享父进程的代码段。这是因为代码段通常是只读的,共享不会带来任何问题,反而可以节省大量的内存空间。我们可以这样理解:fork之后,父子进程看到的是同一份代码,只是各自从不同的位置开始执行而已。父进程从fork返回后继续执行,而子进程则从fork返回处开始它的生命周期。
但是,数据部分就完全不同了。如果父子进程共享数据,那么当子进程修改某个全局变量时,父进程也会看到这个修改,这就破坏了进程的独立性。在现代操作系统中,进程独立性是一个基本原则------一个进程的崩溃不应该影响到其他进程的正常运行。为了实现这一点,Linux采用了"写时拷贝"(Copy-On-Write,简称COW)机制。
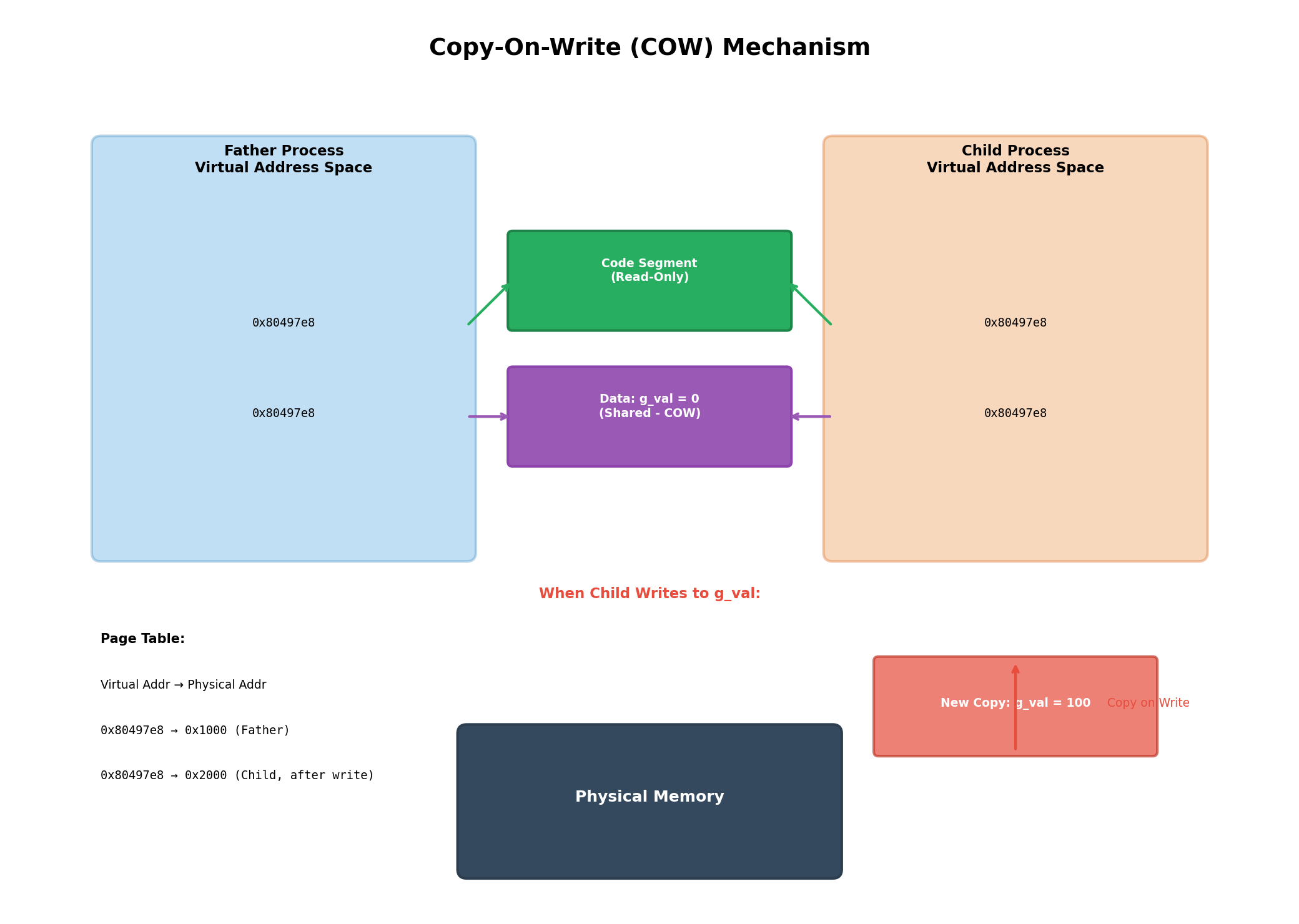
写时拷贝的核心思想是:初始时,父子进程共享同一份物理内存中的数据;只有当某个进程尝试修改数据时,操作系统才会为该进程创建一份数据的私有拷贝。这种设计既保证了进程的独立性,又避免了不必要的内存拷贝,极大地提高了系统效率。
让我们通过一个具体的例子来理解这一点。假设父进程中有一个全局变量int g_val = 0,fork之后,父子进程的虚拟地址空间中都有一个g_val,地址都是0x80497e8。但是,它们实际上指向的是同一块物理内存。当子进程执行g_val++时,操作系统检测到写操作,会立即为子进程在物理内存中分配一块新的空间,将原来的数据拷贝过去,然后让子进程的页表指向这块新的物理内存。此时,父子进程虽然虚拟地址相同,但物理地址已经不同了,因此它们各自看到的g_val值也就不同了。
1.3 fork为什么会有两个返回值
这是每一个学习fork的同学都会困惑的问题。为什么fork函数会返回两次?为什么给子进程返回0,给父进程返回子进程的PID?
要理解这个问题,我们需要深入到fork函数的内部执行流程。fork是一个系统调用,它的核心功能是创建子进程。当fork函数执行到准备return的时候,子进程已经被成功创建了。此时,系统中有两个独立的进程------父进程和子进程。由于fork之后的代码是父子共享的,return语句作为fork函数的一部分,自然会被父子进程各执行一次,因此就产生了"返回两次"的现象。
那么,为什么返回值不同呢?这是出于进程管理的需要。父进程创建子进程的目的是让子进程去执行特定的任务,父进程需要有一种方式来标识和管理它所创建的每一个子进程。因此,fork给父进程返回子进程的PID,父进程可以将这个PID保存起来,后续通过PID来控制子进程(例如发送信号、等待子进程结束等)。这就像现实生活中,父亲给每个孩子起不同的名字,这样才能区分和管理他们。
而对于子进程来说,它只有一个父进程,通过getppid()系统调用就能获取父进程的PID,因此fork只需要给子进程返回0,表示"你已经被成功创建了"即可。这种设计既满足了进程管理的需求,又保持了接口的简洁性。
1.4 同一个变量如何既等于0又大于0
这是fork最神奇的地方,也是初学者最难理解的地方。我们通常这样写代码:
c
pid_t id = fork();
if (id == 0) {
// 子进程执行的代码
} else if (id > 0) {
// 父进程执行的代码
}同一个变量id,怎么可能既等于0又大于0呢?答案就在我们前面讲的写时拷贝机制中。
当fork准备return时,父子进程都已经存在了。return语句本质上是对id变量的赋值操作,也就是写入操作。由于父子进程共享id变量的物理内存,当第一个进程(可能是父进程也可能是子进程,取决于调度)执行return时,会触发写时拷贝。操作系统会为该进程创建id变量的私有拷贝,然后写入相应的值(0或子进程PID)。另一个进程return时,由于物理内存已经被分离,它写入的是自己的那份拷贝。
因此,表面上看是同一个变量,实际上父子进程操作的是不同的物理内存 。这就是为什么id可以同时满足两个不同的条件判断。这个例子完美地展示了虚拟地址和物理地址的区别------程序员看到的是虚拟地址(都是&id),但底层实际上是不同的物理地址。
二、进程状态:从概念到实现
2.1 进程状态的本质
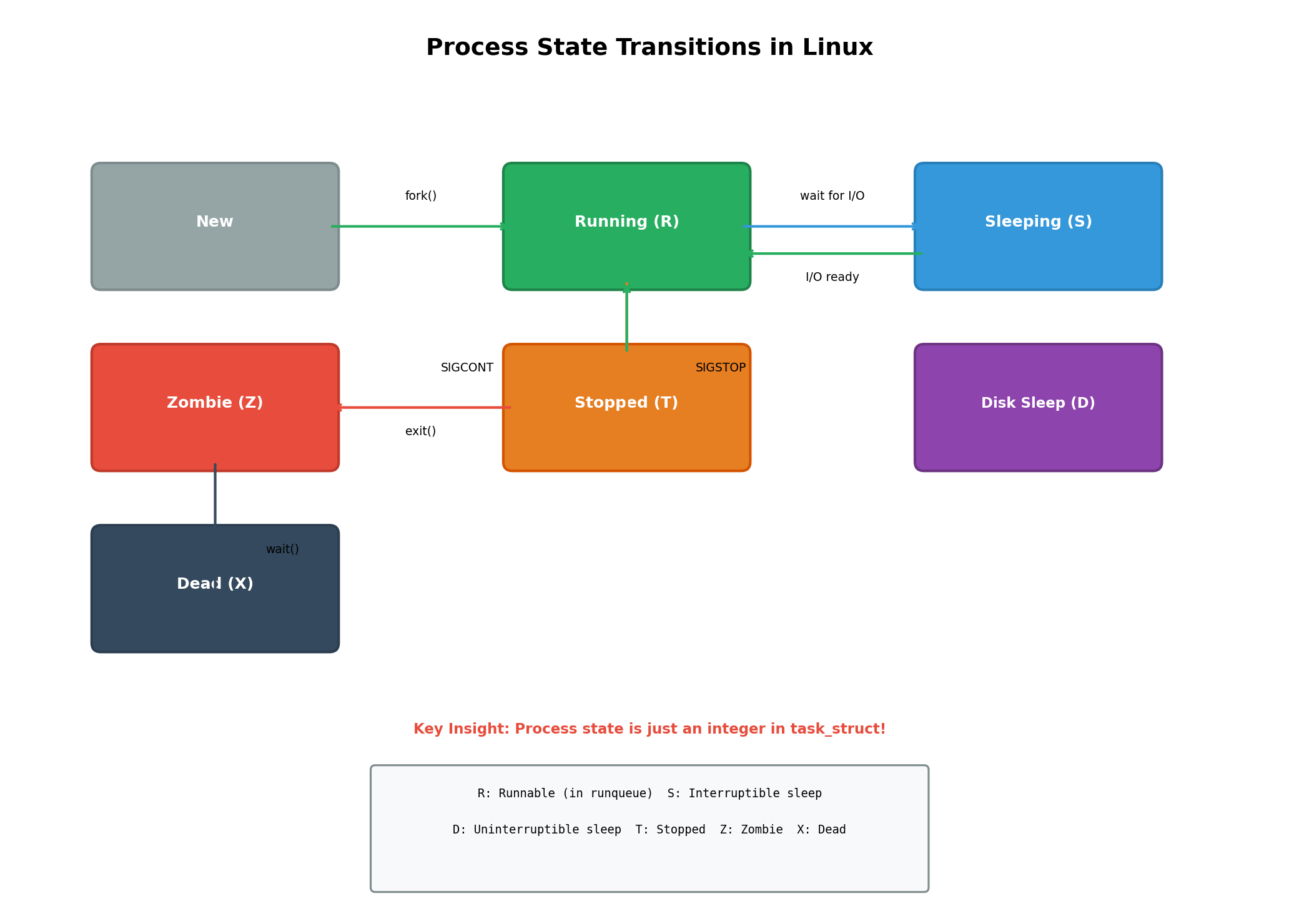
在操作系统课程中,我们学过进程有多种状态:新建、就绪、运行、阻塞、挂起、死亡等等。但在Linux内核的实现中,进程状态本质上就是task_struct结构体中的一个整型变量。这个变量用不同的数值来表示不同的状态,例如:
c
#define TASK_RUNNING 0 // 运行状态
#define TASK_INTERRUPTIBLE 1 // 可中断睡眠
#define TASK_UNINTERRUPTIBLE 2 // 不可中断睡眠
#define TASK_STOPPED 4 // 停止状态
#define TASK_TRACED 8 // 被追踪状态
#define EXIT_ZOMBIE 16 // 僵尸状态
#define EXIT_DEAD 32 // 死亡状态所谓的"改变进程状态",实际上就是修改这个整型变量的值。这个认知非常重要,因为它将抽象的状态概念具体化为简单的数值操作,让我们能够更好地理解操作系统是如何管理进程的。
2.2 运行状态与调度队列
Linux中的运行状态(R状态)有一个特殊的定义:只要进程的PCB在CPU的调度队列中,该进程就处于运行状态,而不一定真的在CPU上执行。这种设计体现了操作系统调度的本质------调度队列是进程等待CPU资源的队列,处于队列中的进程都是"可运行"的。
每个CPU都有一个独立的调度队列。如果你的系统有4个CPU,那么就有4个调度队列。调度队列的实现通常基于链表,队列中的每个节点都是指向task_struct的指针。当CPU需要选择下一个要执行的进程时,它会从调度队列的头部取出一个进程;当进程的时间片用完或者主动放弃CPU时,它会被放回到队列的尾部(或者根据调度策略放到其他位置)。
这里有一个非常有趣的问题:我们前面说过,Linux内核中所有的进程都是通过双链表管理的,那为什么进程又可以同时存在于调度队列中呢?这就涉及到了Linux内核链表的一个精妙设计。
2.3 阻塞状态与等待队列
当进程需要等待某个事件发生时(例如等待用户输入、等待磁盘I/O完成、等待网络数据到达),它就会进入阻塞状态。在Linux中,阻塞状态分为两种:可中断睡眠(S状态)和不可中断睡眠(D状态)。
阻塞的本质是什么呢?阻塞就是把进程的PCB从CPU的调度队列中移除,放到某个设备的等待队列中 。当进程调用scanf()等待键盘输入时,操作系统会检查键盘设备的状态。如果键盘没有数据就绪,操作系统就会把这个进程的PCB从调度队列中剥离,链入到键盘设备的等待队列中。此时,该进程就不再参与CPU调度,表现为"卡住"的状态。
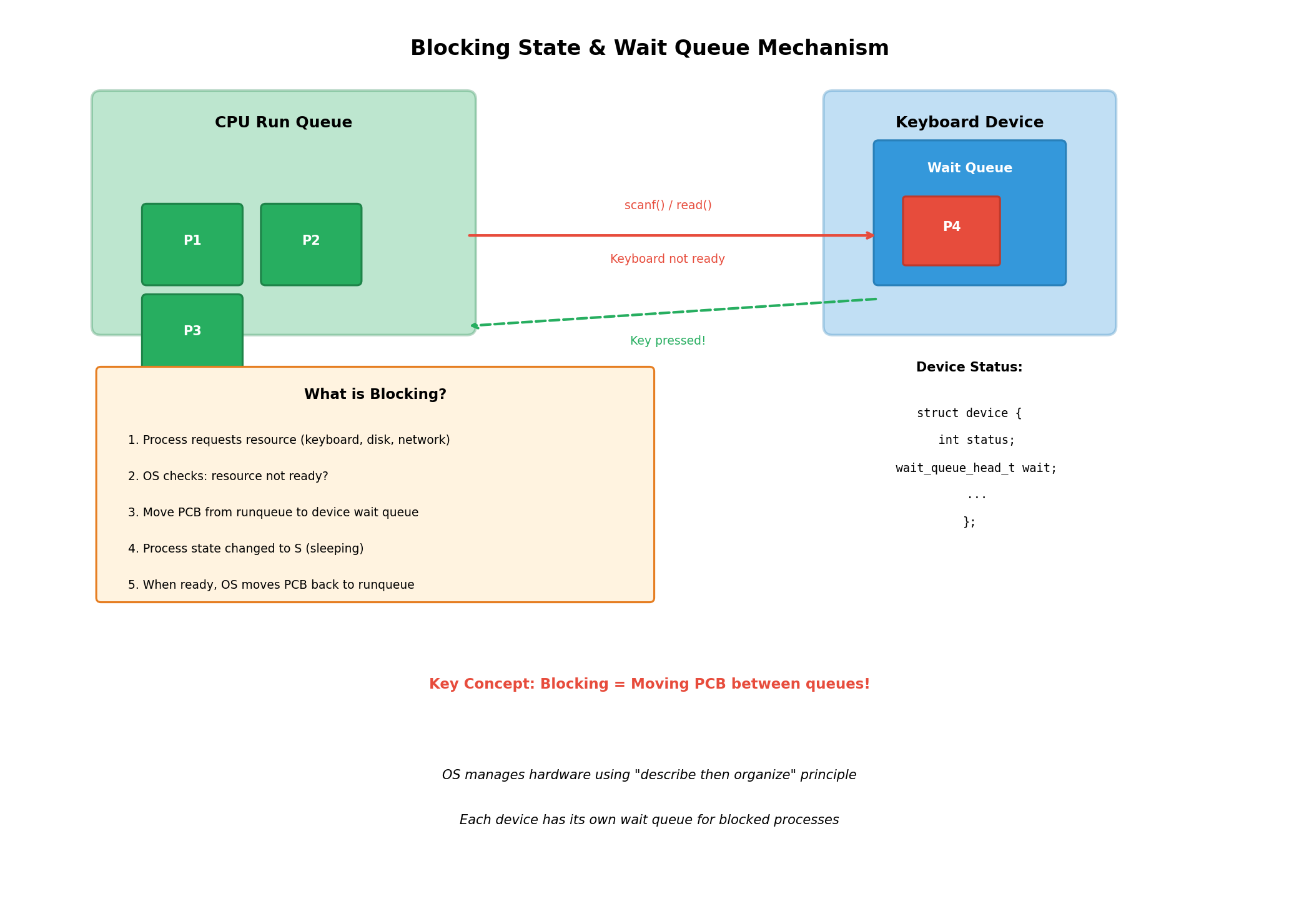
操作系统是如何管理硬件设备的呢?答案是:先描述,再组织 。每一种硬件设备在内核中都有对应的结构体来描述它的属性,包括设备类型、状态、生产厂商等。更重要的是,每个设备结构体中都包含一个等待队列头(wait_queue_head_t)。当进程因为等待该设备而阻塞时,它的PCB就会被加入到这个等待队列中。
当设备就绪时(例如用户按下了键盘),设备驱动程序会通知操作系统。操作系统检查设备的等待队列,如果有进程在等待,就会把这些进程的PCB从设备的等待队列中移除,重新放回到CPU的调度队列中。这些进程再次变得可调度,当它们获得CPU时间时,就可以继续执行了。
这种设计的美妙之处在于,进程状态的变化被转化为了数据结构的操作------从调度队列移动到等待队列是阻塞,从等待队列移动回调度队列是唤醒。这种"用数据结构的变化来表示状态变化"的思想,是操作系统设计的精髓所在。
三、Linux内核链表:嵌入式设计的艺术
3.1 传统链表 vs 内核链表
在学习数据结构时,我们通常这样定义链表节点:
c
struct Node {
int data; // 数据
struct Node* next; // 指向下一个节点
};这种设计的问题是,链表操作与数据类型强耦合。如果你要管理的是struct Student而不是int,就需要重新定义节点结构,链表的操作函数也需要重新实现。
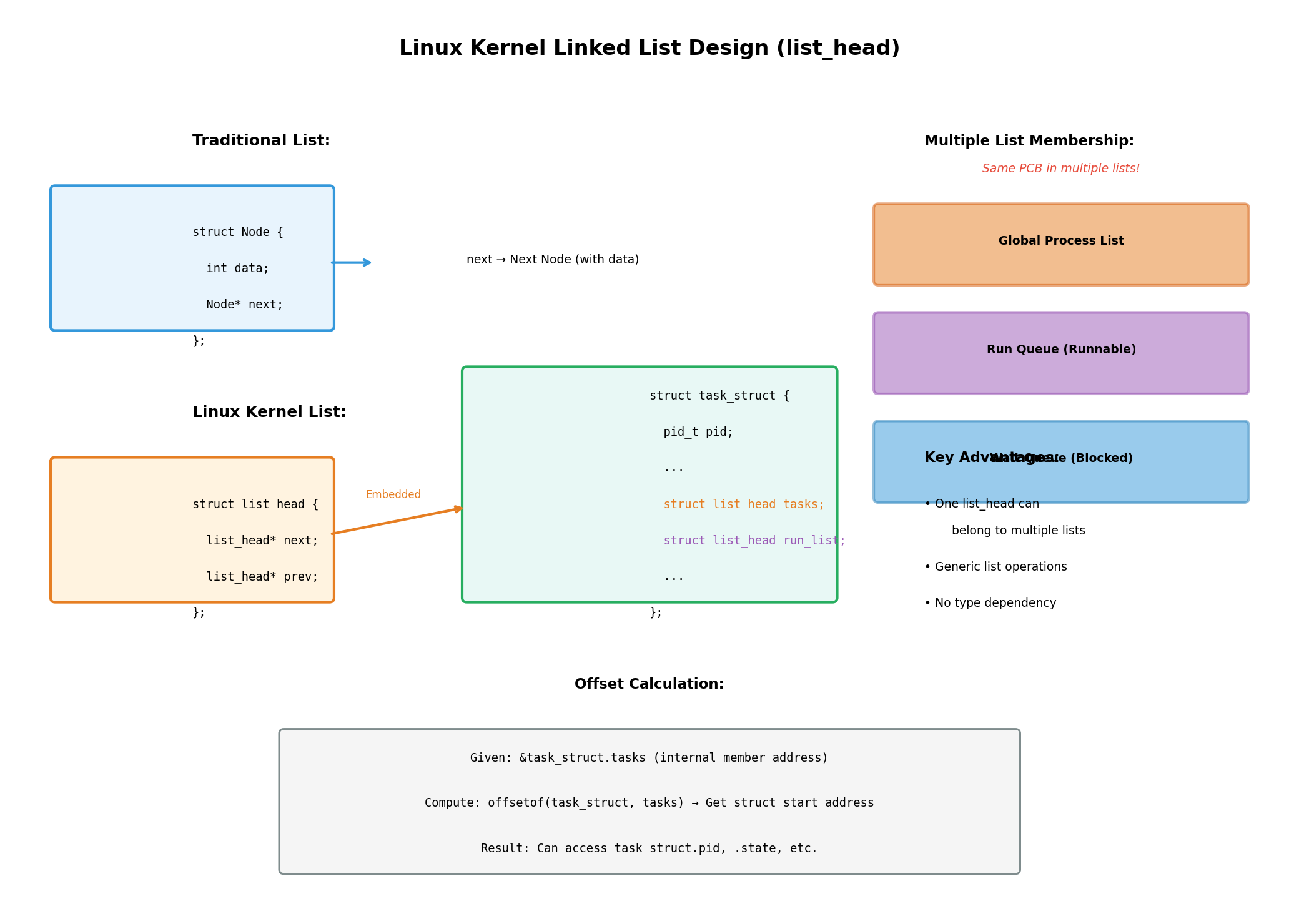
Linux内核采用了一种完全不同的设计------嵌入式链表(Embedded List) 。内核定义了一个纯粹的链表结构list_head:
c
struct list_head {
struct list_head *next;
struct list_head *prev;
};注意,这个结构体中没有任何数据字段 ,只有前后指针。那么,如何使用它来管理进程呢?答案是将list_head嵌入到要管理的结构体中:
c
struct task_struct {
pid_t pid;
// ... 其他属性
struct list_head tasks; // 用于全局进程链表
struct list_head run_list; // 用于调度队列
// ... 其他属性
};
3.2 偏移量计算:从链表节点到结构体
这种设计带来了一个关键问题:当我们遍历链表时,拿到的是list_head的地址,如何访问到task_struct的其他字段(如pid)呢?
这就需要用到偏移量计算 。我们知道,list_head是task_struct的一个成员,它在结构体中的位置是固定的。如果我们知道list_head的地址,以及它在task_struct中的偏移量,就可以计算出task_struct的起始地址。
Linux内核提供了一个宏offsetof来计算偏移量:
c
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)这个宏的巧妙之处在于,它将0地址强制转换为TYPE*类型,然后访问MEMBER成员并取地址。由于结构体的起始地址是0,MEMBER的地址就是它在结构体中的偏移量。
有了偏移量,我们就可以通过list_head的地址反推出task_struct的地址:
c
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) *__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })这个宏就是内核链表的"魔法"所在。它让我们能够从链表节点指针,反推出包含该节点的结构体的指针,从而访问结构体的任意字段。
3.3 一个节点,多个链表
嵌入式链表设计的另一个巨大优势是:一个结构体可以同时属于多个链表 。在task_struct中,我们可以嵌入多个list_head:
c
struct task_struct {
struct list_head tasks; // 全局进程链表
struct list_head run_list; // 调度队列
struct list_head wait_list; // 某个设备的等待队列
// ...
};这意味着同一个进程PCB,可以同时存在于全局进程链表、CPU调度队列、以及某个设备的等待队列中。这种设计极大地提高了数据结构的复用性和灵活性。
想象一下,如果没有这种设计,我们要如何实现"一个进程同时在多个队列中"的需求?可能需要为每个队列维护一个独立的节点,节点中保存指向PCB的指针,这样不仅浪费内存,还增加了维护的复杂度。而嵌入式链表设计,让这一切变得优雅而高效。
四、虚拟地址空间:程序员的视角与物理现实
4.1 虚拟地址 vs 物理地址
在学习C语言时,我们打印变量的地址,看到的都是虚拟地址。虚拟地址是操作系统为每个进程提供的一套独立的地址空间,它让程序员可以像独占整个内存一样编写程序,而不需要关心物理内存的实际布局。
让我们回到前面的fork例子。父子进程中都有一个变量g_val,当我们打印&g_val时,看到的地址是相同的(比如0x80497e8)。但是,当子进程修改g_val后,父子进程读取到的值却不同了。这说明,相同的虚拟地址背后,实际上是不同的物理地址。
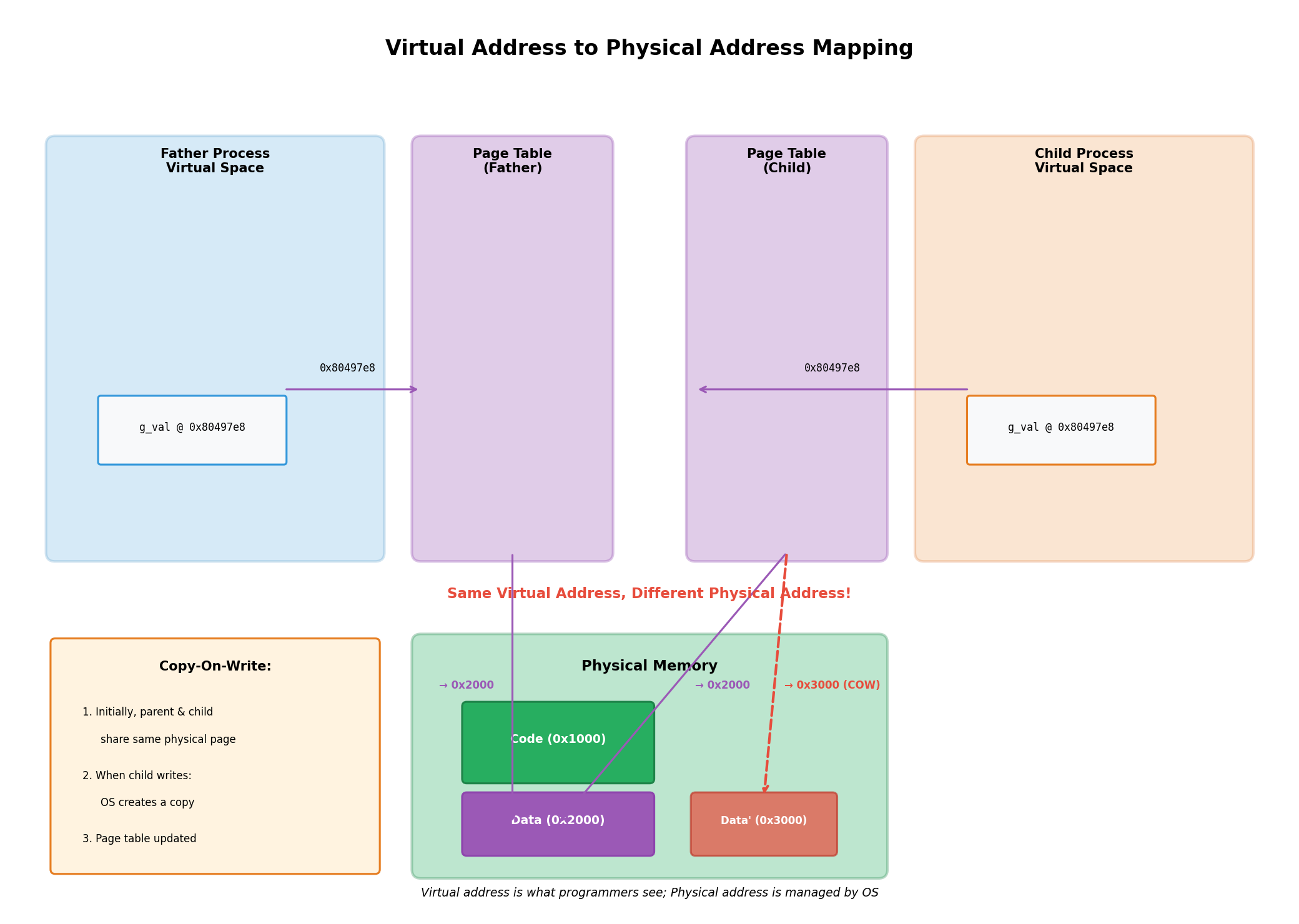
这种映射是通过页表(Page Table)实现的。每个进程都有自己的页表,页表记录了虚拟地址到物理地址的映射关系。当CPU访问某个虚拟地址时,内存管理单元(MMU)会查找页表,将其转换为物理地址,然后访问实际的物理内存。
4.2 写时拷贝的页表操作
在fork创建子进程时,操作系统会复制父进程的页表给子进程。此时,父子进程的页表指向相同的物理页面,并且这些页面被标记为"只读"。当任一进程尝试写入时,会触发页错误(Page Fault),操作系统捕获这个错误,执行写时拷贝:分配新的物理页面,拷贝数据,更新页表,然后重新执行写入操作。
这个过程对进程是完全透明的。进程以为自己直接访问的是物理内存,实际上它看到的只是虚拟地址,真正的物理地址由操作系统管理。这种设计既保护了物理内存的安全,又提供了灵活的内存管理机制。
五、总结与思考
通过这篇文章的讲解,我们从fork系统调用出发,深入探讨了进程创建的机制、进程状态的管理、内核链表的设计艺术,以及虚拟地址空间的奥秘。这些知识点看似独立,实际上紧密相连,共同构成了Linux进程管理的核心框架。
fork的返回值之谜 让我们理解了进程创建的实质------父子进程共享代码,数据通过写时拷贝实现分离。进程状态的管理 让我们看到了操作系统如何用简单的数据结构操作来实现复杂的调度逻辑。内核链表的设计 则展示了软件工程中"解耦"与"复用"的思想。虚拟地址空间让我们明白了程序员视角与物理现实之间的映射关系。
操作系统的学习不能停留在概念的背诵上,而要深入到代码和数据结构的层面。只有真正理解了内核是如何实现的,你才能在遇到问题时游刃有余,才能写出高效、健壮的系统级程序。希望这篇文章能够成为你深入Linux内核世界的一个起点。
参考代码示例
示例1:fork基础用法
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main() {
pid_t id = fork();
if (id < 0) {
perror("fork failed");
return 1;
} else if (id == 0) {
// 子进程
printf("I am child process, PID: %d, PPID: %d\n", getpid(), getppid());
} else {
// 父进程
printf("I am father process, PID: %d, Child PID: %d\n", getpid(), id);
}
return 0;
}示例2:验证写时拷贝
c
#include <stdio.h>
#include <unistd.h>
int g_val = 0;
int main() {
pid_t id = fork();
if (id == 0) {
// 子进程修改全局变量
g_val = 100;
printf("Child: g_val = %d, address = %p\n", g_val, &g_val);
} else {
sleep(3); // 确保子进程先执行
printf("Father: g_val = %d, address = %p\n", g_val, &g_val);
}
return 0;
}示例3:使用循环创建多个子进程
c
#include <stdio.h>
#include <unistd.h>
#define N 10
int main() {
for (int i = 0; i < N; i++) {
pid_t id = fork();
if (id == 0) {
// 子进程进入循环,不再创建新进程
while (1) {
printf("Child %d: PID = %d, PPID = %d\n", i, getpid(), getppid());
sleep(1);
}
} else if (id > 0) {
// 父进程继续循环,创建下一个子进程
printf("Father created child %d, PID = %d\n", i, id);
sleep(1);
}
}
// 父进程也进入循环
while (1) {
printf("Father: PID = %d\n", getpid());
sleep(1);
}
return 0;
}