目录
在构建 Smart Contract Sentinel(智能合同哨兵) 的过程中,我们需要处理大量的法律法规和合同文本。最初,我们通过简单的"Embedding + 向量数据库"构建了基础的 RAG(检索增强生成)系统,但在实际应用中,我们很快遇到了检索不精准、回答幻觉、上下文丢失等典型问题。
本文将结合 Smart Contract Sentinel 的实际代码和架构,分享我们在构建高可靠 RAG 系统时面临的四大挑战及解决方案。
整体架构图
为了直观展示我们正在构建的 RAG 系统优化路径,以下是系统的整体数据流转图:
挑战一:检索质量不稳定
问题描述 :
在法律场景下,用户查询往往包含精确的法律术语(如"不可抗力"、"违约责任")。单纯依赖语义检索(Dense Retrieval)有时会因为语义泛化而忽略了关键词的精确匹配,导致检索结果相关性不足。
当前现状 :
在我们的 backend/utils/ragSetting/vector_store.py 中,目前主要使用了 Milvus 进行向量检索:
python
# backend/utils/ragSetting/vector_store.py
async def milvus_async_query(query: str, collection_name: str = "law_default", top_k: int = 5) -> str:
# ... 省略部分初始化代码 ...
retriever = index.as_retriever(similarity_top_k=top_k)
nodes = retriever.retrieve(query)
# ...retriever=index.as_retriever(similarity_top_k=top_k)
创建了一个检索器(Retriever) 对象:
index.as_retriever():从向量索引中创建一个检索器
similarity_top_k=top_k:设置相似度检索的返回结果数量为 top_k 个最相关的文档
nodes = retriever.retrieve(query)
这行代码执行实际的检索操作:
retriever.retrieve(query):使用检索器对查询语句 query 进行检索
返回值 nodes:包含检索到的相关文档节点列表
解决方案:混合检索(Hybrid Search) + 重排序(Re-ranking)
为了解决这个问题,我们计划引入 混合检索 策略,结合 BM25 稀疏检索 (擅长关键词匹配)和 Embedding 密集检索(擅长语义理解)。
python
# 伪代码示例:混合检索实现
def hybrid_search(query, dense_weight=0.7, sparse_weight=0.3):
# 1. 密集检索 (原有逻辑)
dense_results = dense_retrieval(query)
# 2. 稀疏检索 (新增 BM25)
sparse_results = bm25_retrieval(query)
# 3. 融合策略 (Reciprocal Rank Fusion)
combined = weighted_fusion(
dense_results, sparse_results,
dense_weight, sparse_weight
)
# 4. 重排序 (Re-ranking)
# 使用 Cross-Encoder 对最终结果进行精细排序
reranked = reranker.rank(query, combined)
return reranked通过这种方式,我们可以确保既能召回语义相关的法条,又不会漏掉包含特定关键词的关键条款。
挑战二:长文档与上下文窗口限制
问题描述 :
法律法规和合同通常篇幅巨大。如果直接将整个文档塞给 LLM,很容易超出上下文窗口限制,或者导致"Lost in the Middle"(中间信息丢失)现象。
解决方案:结构化切分与递归检索
在 Smart Contract Sentinel 中,我们并没有简单地按字符数切分文档,而是针对法律条文的结构进行了定制化切分。
在 backend/utils/ragSetting/law_cut.py 中,我们实现了基于正则的层级切分:
python
# backend/utils/ragSetting/law_cut.py
def split_law_text(text: str, law_name: str = "劳动合同法") -> List[Document]:
# ...
article_pattern = re.compile(r"^\s*(第[零一二三四五六七八九十百]+条)\s*(.*)")
# 按"条"为单位进行切分,保留章节元数据
# ...
metadata = {
"law_name": law_name,
"chapter_title": current_chapter_title,
"section_title": current_section_title,
"article_title": current_article_title,
"content_type": "article"
}
documents.append(Document(text=full_text, metadata=metadata))
# ...

这种 基于语义结构(Semantic Structure) 的切分方式,保证了每一个检索到的 chunk 都是一个完整的法律条款,而不是被截断的碎片。
进阶优化 :
未来我们可以引入 父子索引(Parent-Child Indexing):检索时匹配细粒度的子块(如某一款),但在生成答案时返回其父块(完整的法条或章节),以提供更完整的上下文。
挑战三:回答的事实一致性与幻觉
问题描述 :
在法律咨询中,模型的"幻觉"是不可接受的。模型必须基于确凿的法律条文回答,而不能"自由发挥"。
解决方案:强制引用溯源与工具调用
我们在 backend/analytics/review_graph.py 中,通过 System Prompt 严格限制了模型的行为,并强制其使用检索工具:
python
# backend/analytics/review_graph.py
review_system_prompt = """
你是合同审查助手,负责输出结构化的审查结果。
...
如果未发现风险,risks 为空数组,summary 和 suggestion 仍需给出。相应的法律可以调用工具rag_search
collection_name可选的参数有:
1.劳动合同法:civil_code22
"""通过将 rag_search 作为一个明确的 Tool 提供给 Agent(基于 LangGraph),模型在需要法律依据时会主动发起检索,而不是凭空捏造。
优化方向 :
我们可以增加 自一致性检查(Self-Consistency Check):让模型生成多个回答,或者在生成回答后,再调用一次 LLM 来验证答案中的引用是否真实存在于检索到的文档中。
挑战四:多轮对话中的上下文管理
问题描述 :
用户在咨询法律问题时,往往会进行多轮追问。例如:
- 用户:"劳动合同没签会怎么样?"
- 用户:"那如果是试用期呢?"
如果直接检索"那如果是试用期呢?",系统无法理解其含义。
chat_graph.py文件中的对话历史处理机制。对话历史处理机制
1. 状态定义
在
ChatState类型定义中,对话历史被定义为:
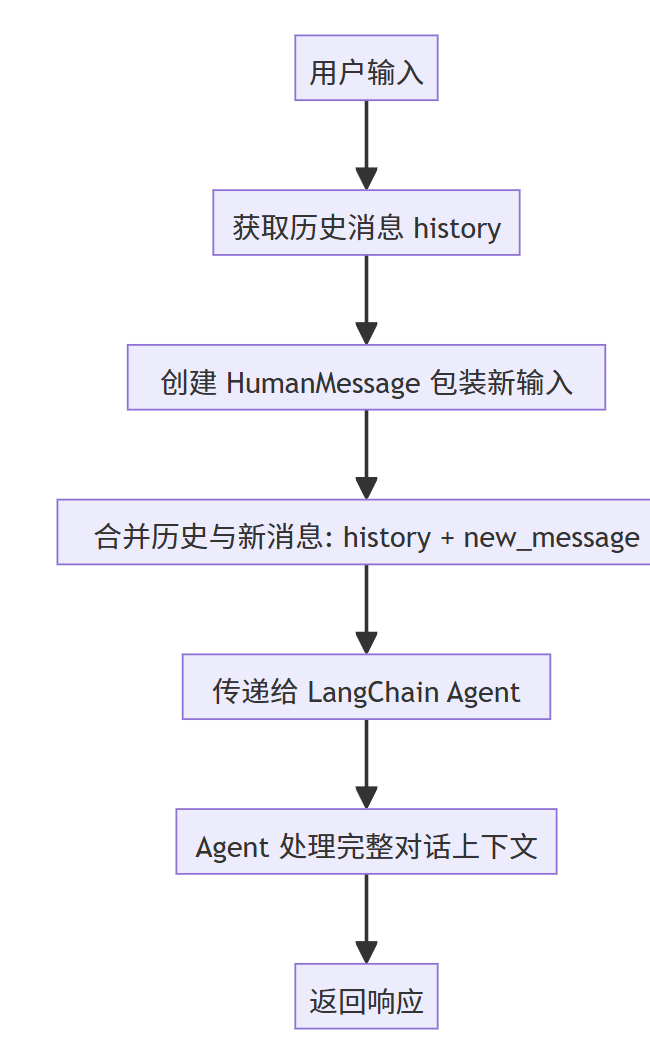
class ChatState(TypedDict): history: List[BaseMessage] # 存储对话历史消息2. 历史消息处理流程
在
agent_node函数中:
def agent_node(state: ChatState) -> dict: history = state.get("history") or [] # 获取历史消息,默认为空列表 input_text = state.get("input_text") or "" agent = _build_agent(state.get("model") or "deepseek") messages = history + [HumanMessage(content=input_text)] # 将历史与新消息合并 agent_result = agent.invoke({"messages": messages}) # ... 后续处理3. 关键特点
- 消息类型 :使用
BaseMessage及其子类(如HumanMessage)来存储消息- 累积式处理:每次调用都会将当前输入与历史消息合并
- 状态保持 :对话历史通过
ChatState在整个会话过程中保持- 顺序维护:消息按时间顺序排列,最新消息追加在末尾
4. 消息格式
- 历史消息:
List[BaseMessage]包含所有之前的对话消息- 新消息:
HumanMessage(content=input_text)包装当前用户输入- 合并后:完整的消息序列传递给 LangChain agent
5. 处理流程图示
解决方案:查询重写(Query Rewriting)虽然目前的
backend/chat/chat_graph.py主要处理了基本的对话历史,但为了提高检索准确率,我们需要在检索前引入 查询重写 模块。
💡 实际示例
用户输入 : "这个条款的违约金规定是什么?"
对话历史 : 之前讨论了"劳动合同解除"相关条款
重写后 : "劳动合同解除条款中关于违约金的具体规定"
用户输入 : "它有效吗?"
对话历史 : 之前询问了"电子签名法律效力"
重写后 : "电子签名在法律上的有效性认定标准"
实现思路 :
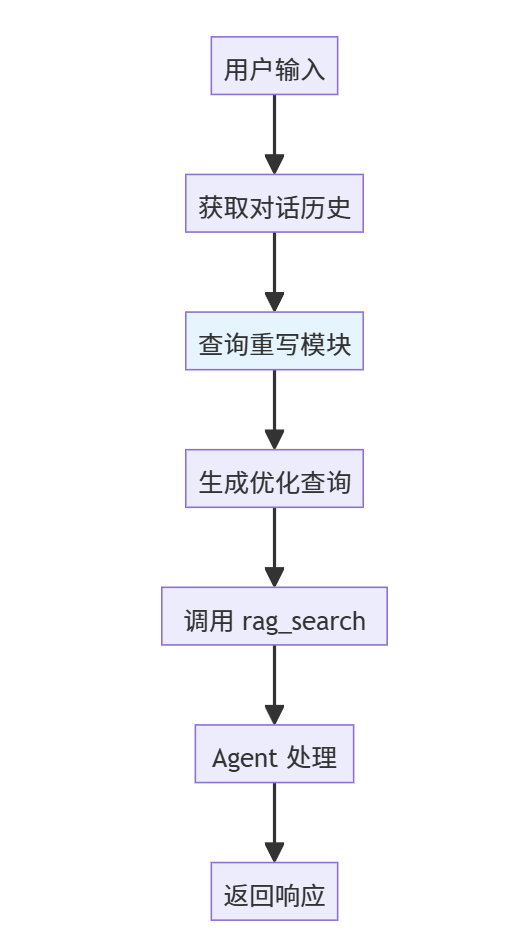
在调用检索工具前,先让 LLM 基于对话历史将当前问题改写为独立完整的查询。
python
# 伪代码:查询重写
current_query = "那如果是试用期呢?"
history = ["用户: 劳动合同没签会怎么样?", "AI: ..."]
rewritten_query = llm.rewrite(history, current_query)
# 结果: "试用期内未签劳动合同会有什么法律后果?"
# 使用重写后的查询进行检索
results = rag_search(rewritten_query)这样可以显著提高多轮对话场景下的检索命中率。
🛠️具体实现方案
基于当前 chat_graph.py 的架构,建议以下实现方式:
1. 创建查询重写工具
python# 在 chat_graph.py 中添加 def query_rewrite_tool(history: List[BaseMessage], current_query: str) -> str: """ 基于对话历史重写当前查询 """ # 提取历史对话内容 conversation_context = "\n".join([ f"{'用户' if isinstance(msg, HumanMessage) else '助手'}: {msg.content}" for msg in history[-6:] # 最近6条消息作为上下文 ]) # 使用LLM进行查询重写 rewrite_prompt = f""" 基于以下对话历史和当前查询,生成一个完整、明确的检索查询: 对话历史: {conversation_context} 当前查询:{current_query} 请生成一个适合法律文档检索的完整查询语句,要求: 1. 解析并明确所有指代关系 2. 补充必要的上下文信息 3. 使用专业法律术语 4. 保持查询的简洁性和准确性 优化后的查询: """ # 调用LLM进行重写(可以使用现有的ChatOpenAI实例) rewritten_query = llm.invoke(rewrite_prompt) return rewritten_query.strip()2. 修改 rag_search 调用
python# 在 agent_node 函数中修改检索调用 def agent_node(state: ChatState) -> dict: history = state.get("history") or [] input_text = state.get("input_text") or "" # 在调用 rag_search 前进行查询重写 optimized_query = query_rewrite_tool(history, input_text) # 使用优化后的查询进行检索 agent_result = agent.invoke({ "messages": history + [HumanMessage(content=input_text)], "query": optimized_query # 传递优化后的查询 })3. 集成架构
🎯 核心价值
- 提升检索精度:将模糊查询转换为明确的法律术语检索
- 增强上下文理解:充分利用对话历史中的关键信息
- 改善指代消解:自动解析代词和上下文引用
总结
构建一个生产级的 RAG 系统远比调用几个 API 复杂。通过 Smart Contract Sentinel 的实践,我们认识到:数据处理的精细度(如结构化切分)、检索策略的组合(混合检索)、以及 Agent 流程的编排(LangGraph) 才是决定系统上限的关键因素。
我们正在持续优化这些模块,致力于打造一个更专业、更可靠的智能合同审查助手。