目录
[8.1 线性回归](#8.1 线性回归)
[8.1.1 学习(最小二乘法求解)](#8.1.1 学习(最小二乘法求解))
[8.1.2 线性回归模型的问题](#8.1.2 线性回归模型的问题)
[8.2 贝叶斯线性回归](#8.2 贝叶斯线性回归)
[8.2.1 实际考虑](#8.2.1 实际考虑)
[8.2.2 拟合方差](#8.2.2 拟合方差)
[完整代码(贝叶斯线性回归 + 方差可视化)](#完整代码(贝叶斯线性回归 + 方差可视化))
[8.3 非线性回归](#8.3 非线性回归)
[8.3.1 最大似然法](#8.3.1 最大似然法)
[8.3.2 贝叶斯非线性回归](#8.3.2 贝叶斯非线性回归)
[8.4 核与核技巧](#8.4 核与核技巧)
[8.5 高斯过程回归](#8.5 高斯过程回归)
[8.6 稀疏线性回归](#8.6 稀疏线性回归)
[代码(稀疏回归 vs 普通回归)](#代码(稀疏回归 vs 普通回归))
[8.7 二元线性回归](#8.7 二元线性回归)
[8.8 相关向量回归](#8.8 相关向量回归)
[8.9 多变量数据回归](#8.9 多变量数据回归)
[8.10 应用](#8.10 应用)
[8.10.1 人体姿势估计](#8.10.1 人体姿势估计)
[8.10.2 位移专家](#8.10.2 位移专家)
前言
大家好!今天我们来拆解《计算机视觉:模型、学习和推理》这本经典教材的第 8 章 ------ 回归模型 。回归是计算机视觉中最基础也最核心的技术之一,不管是人体姿势估计、目标跟踪还是图像拟合,都离不开回归的身影。
这篇文章不会堆砌复杂公式,而是用「大白话 + 可直接运行的代码 + 可视化对比图」的方式,把线性回归、贝叶斯回归、非线性回归等核心知识点讲透,所有代码都适配 Mac 系统的 Matplotlib 中文显示,复制就能跑!
8.1 线性回归

核心概念
线性回归就像**「找一根最贴合数据点的直线」** ,比如用身高预测体重、用像素值预测物体位置。它的核心逻辑是:假设输入特征 x 和输出标签 y 之间满足线性关系 y=wx+b+ϵ(ϵ 是噪声),我们的目标是找到最优的权重 w 和偏置 b ,让预测值和真实值的误差最小。
8.1.1 学习(最小二乘法求解)
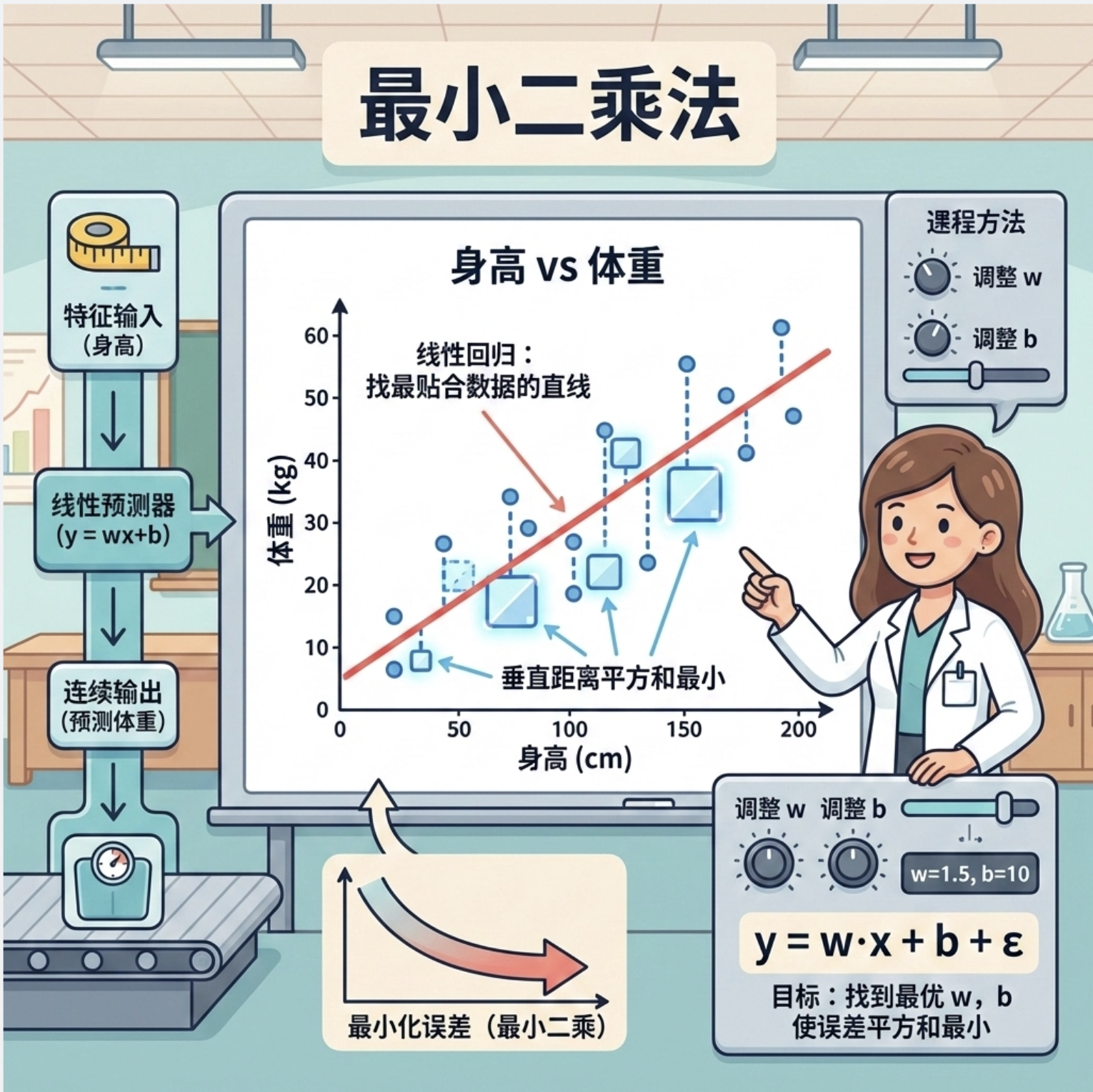
最小二乘法是线性回归最常用的求解方法,核心是「让所有数据点到直线的垂直距离平方和最小」。
完整代码(含可视化对比)
import numpy as np
import matplotlib.pyplot as plt
# ==================== Mac系统Matplotlib中文显示配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成模拟数据 ====================
# 真实模型:y = 2x + 1 + 噪声(模拟真实世界的误差)
np.random.seed(42) # 固定随机种子,保证结果可复现
x = np.linspace(0, 10, 100) # 生成0-10之间的100个均匀分布的数
noise = np.random.normal(0, 1, size=x.shape) # 高斯噪声
y_true = 2 * x + 1 # 真实值(无噪声)
y = y_true + noise # 带噪声的观测值
# ==================== 最小二乘法求解线性回归 ====================
# 构造X矩阵(添加偏置项,即常数项1)
X = np.vstack([x, np.ones_like(x)]).T
# 最小二乘法公式:w = (X^T X)^-1 X^T y
w = np.linalg.inv(X.T @ X) @ X.T @ y
w_slope = w[0] # 斜率(对应公式中的w)
w_intercept = w[1] # 截距(对应公式中的b)
# 生成预测值
y_pred = w_slope * x + w_intercept
# ==================== 可视化对比(原始数据+真实直线+拟合直线) ====================
plt.figure(figsize=(10, 6))
# 绘制带噪声的原始数据点
plt.scatter(x, y, label='带噪声的观测数据', color='lightcoral', alpha=0.7)
# 绘制真实的线性模型
plt.plot(x, y_true, label='真实模型: y=2x+1', color='darkgreen', linewidth=2, linestyle='--')
# 绘制拟合的线性模型
plt.plot(x, y_pred, label=f'拟合模型: y={w_slope:.2f}x+{w_intercept:.2f}', color='royalblue', linewidth=2)
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('线性回归最小二乘法拟合效果对比', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()
# 输出拟合结果
print(f"拟合得到的斜率:{w_slope:.4f}(真实值:2)")
print(f"拟合得到的截距:{w_intercept:.4f}(真实值:1)")代码解释
1.数据生成:模拟了真实线性关系 + 高斯噪声的数据集,更贴近实际场景;
2.最小二乘法求解:通过矩阵运算直接求解最优权重,避免手动迭代;
3.可视化对比:把「带噪声的原始数据」「真实直线」「拟合直线」放在同一张图里,直观看到拟合效果。
运行效果
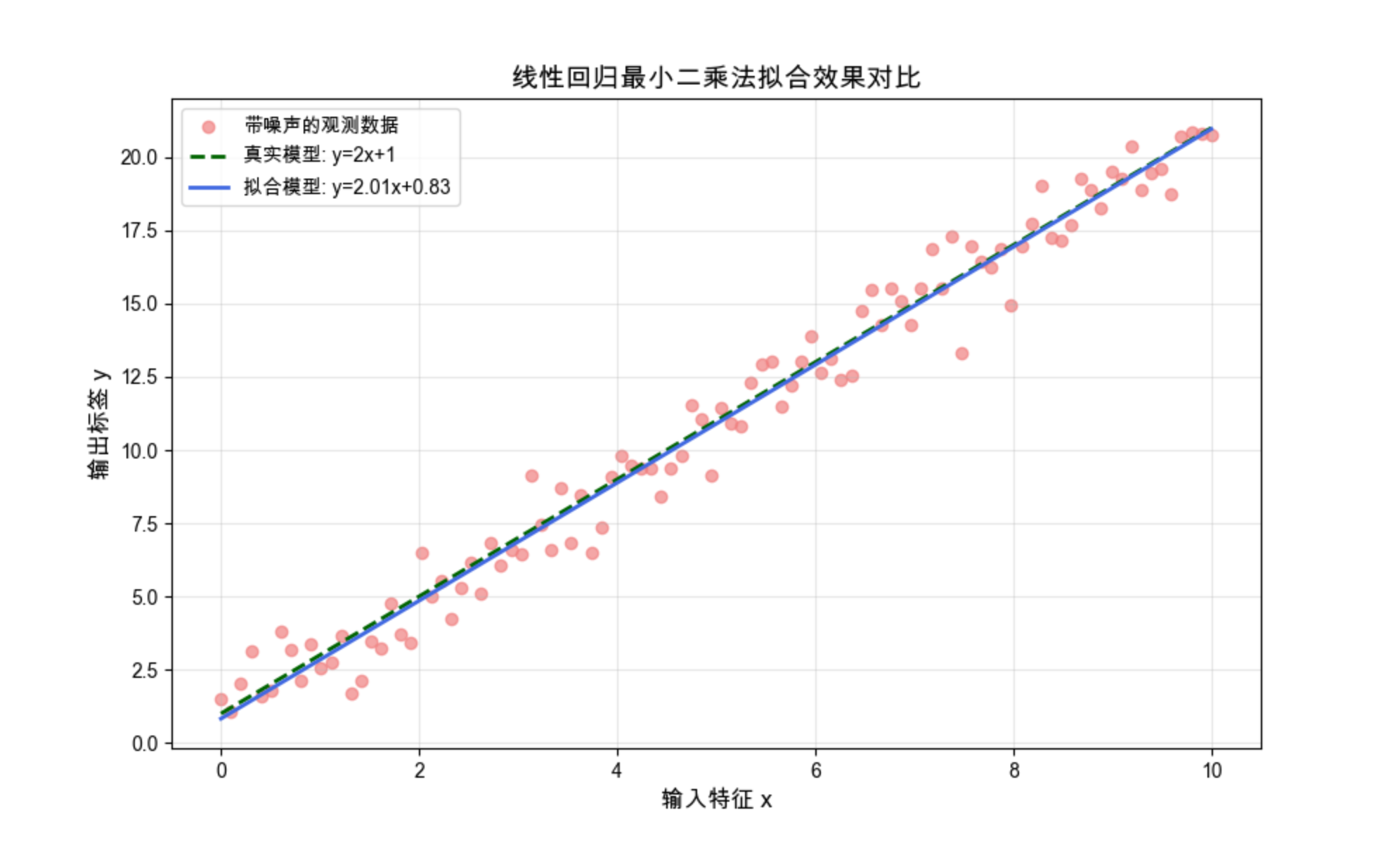
会弹出一个窗口,显示:
- 浅红色散点:带噪声的观测数据;
- 绿色虚线:真实的 y=2x+1;
- 蓝色实线:拟合的直线(接近真实值)。
8.1.2 线性回归模型的问题
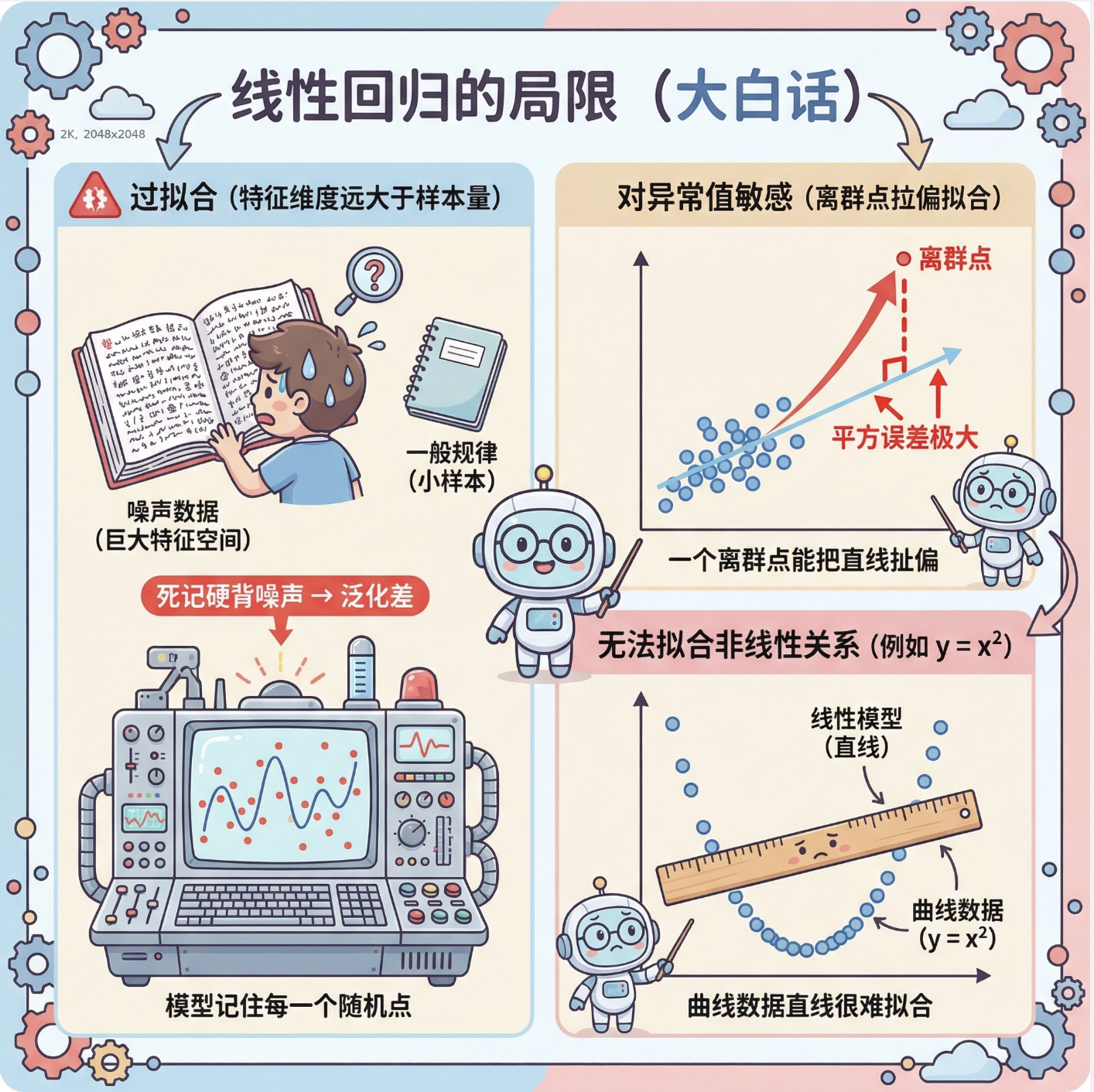
线性回归的「硬伤」很明显,用大白话总结就是:
- 过拟合风险 :当特征维度远大于数据量时,模型会「死记硬背」噪声,泛化能力差;
- 对异常值敏感 :最小二乘法会放大异常值的影响(比如一个离群点能把拟合直线拉偏);
- 无法拟合非线性关系 :如果数据本身是曲线(比如 y=x²),线性回归的拟合效果会极差。
可视化对比(线性回归拟合非线性数据)
python
import numpy as np
import matplotlib.pyplot as plt
# ==================== Mac系统Matplotlib中文显示配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成非线性数据 ====================
np.random.seed(42)
x = np.linspace(-2, 2, 100)
y_true = x**2 + 0.5 * x + 1 # 二次函数(非线性)
y = y_true + np.random.normal(0, 0.3, size=x.shape)
# ==================== 线性回归拟合 ====================
X = np.vstack([x, np.ones_like(x)]).T
w = np.linalg.inv(X.T @ X) @ X.T @ y
y_pred_linear = w[0] * x + w[1]
# ==================== 可视化对比 ====================
plt.figure(figsize=(10, 6))
plt.scatter(x, y, label='非线性观测数据', color='lightcoral', alpha=0.7)
plt.plot(x, y_true, label='真实非线性模型: y=x²+0.5x+1', color='darkgreen', linewidth=2, linestyle='--')
plt.plot(x, y_pred_linear, label=f'线性回归拟合', color='royalblue', linewidth=2)
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('线性回归拟合非线性数据的效果对比', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()运行效果
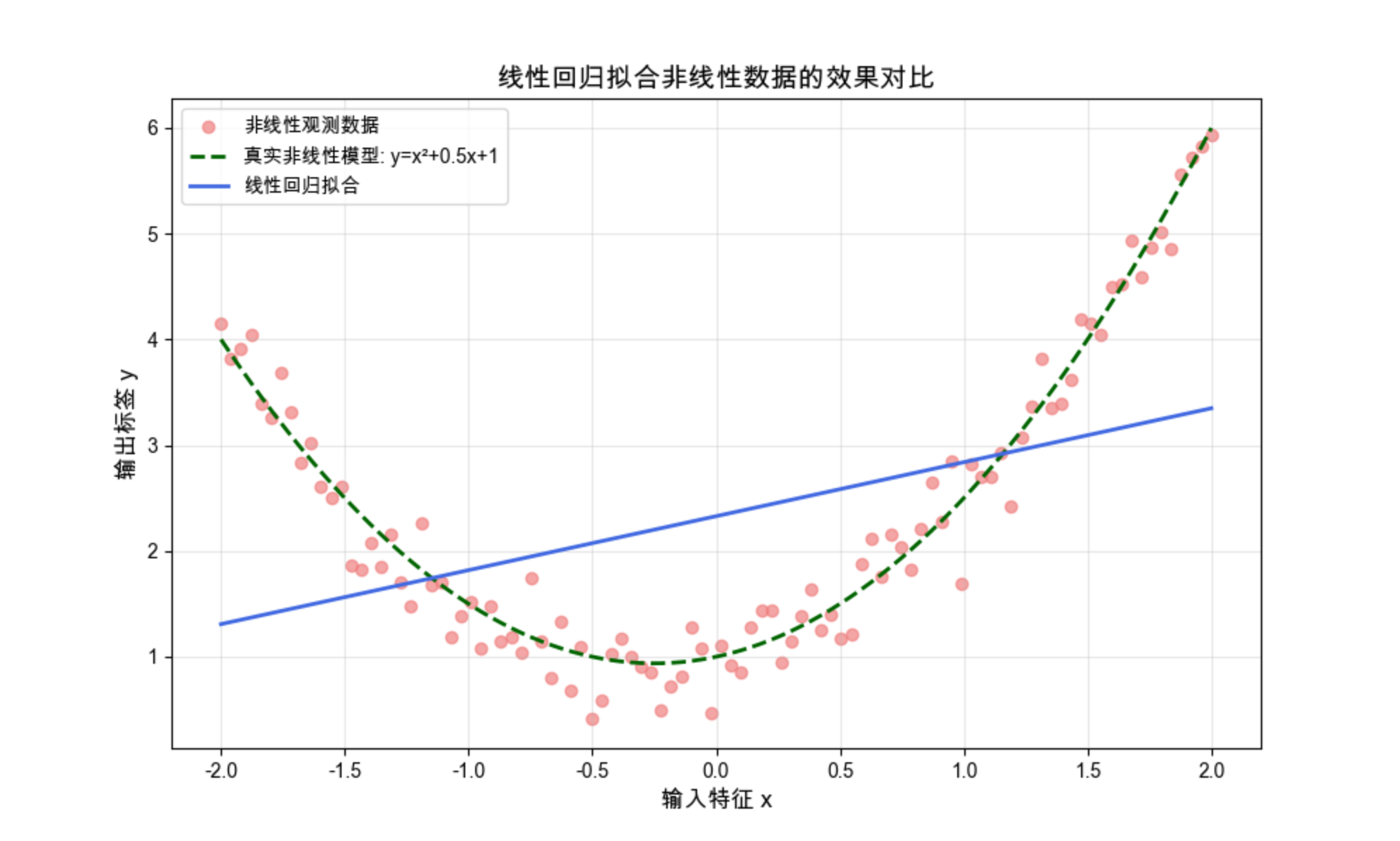
能明显看到:线性回归的直线完全无法贴合二次函数的曲线,这就是线性回归的核心局限性。
8.2 贝叶斯线性回归
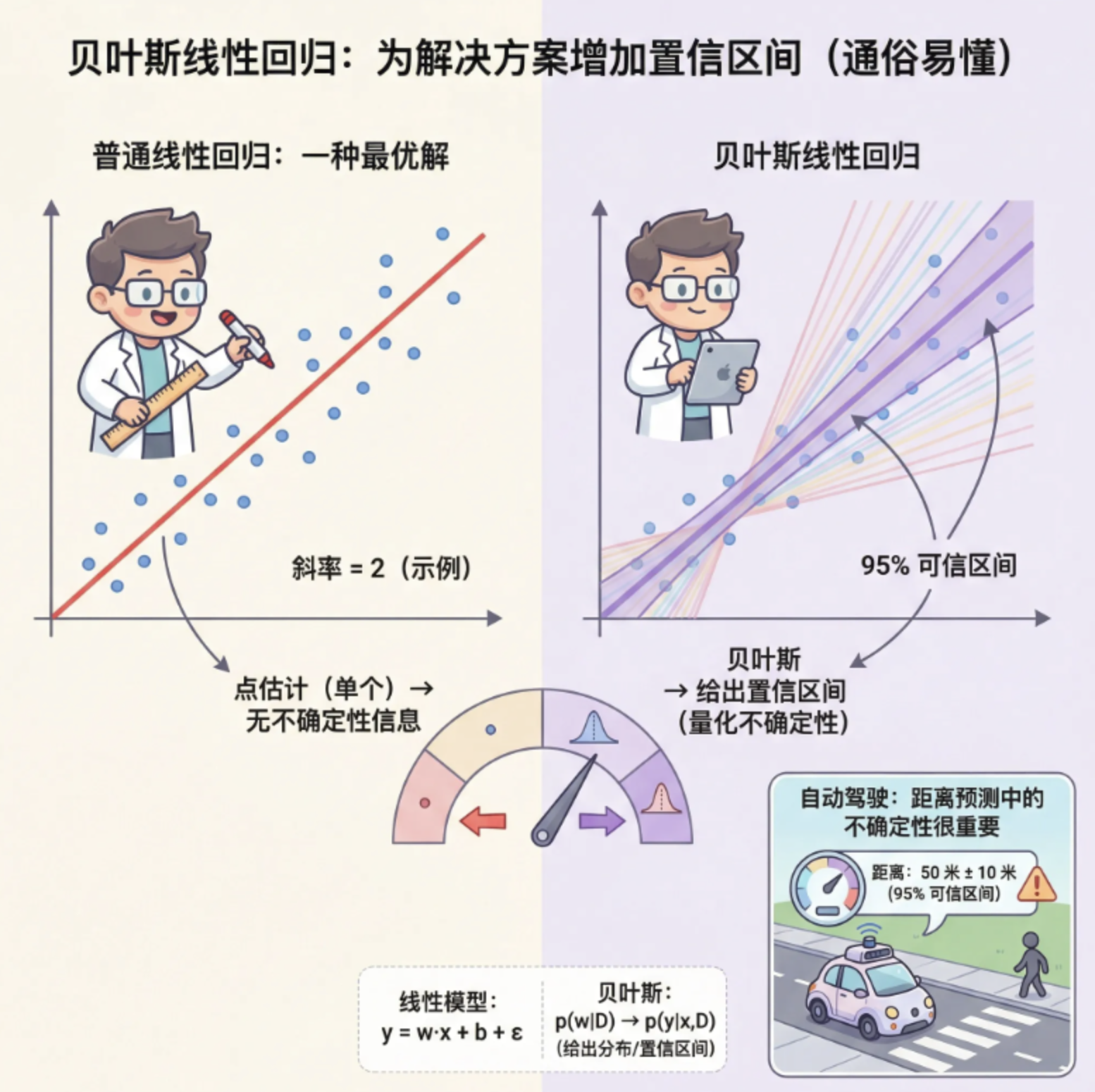
核心概念
如果说普通线性回归是「一次性算出最优解」,贝叶斯线性回归就是「给解加个 "置信区间"」------ 它不追求单一的最优 w 和 b,而是给出 w 的概率分布 ,能回答**「这个拟合结果有多可信?」**。
举个例子:普通线性回归告诉你「拟合斜率是 2」,贝叶斯线性回归会告诉你「斜率有 95% 的概率在 1.9~2.1 之间」,这对计算机视觉中需要评估预测不确定性的场景(比如自动驾驶的距离预测)非常重要。
8.2.1 实际考虑
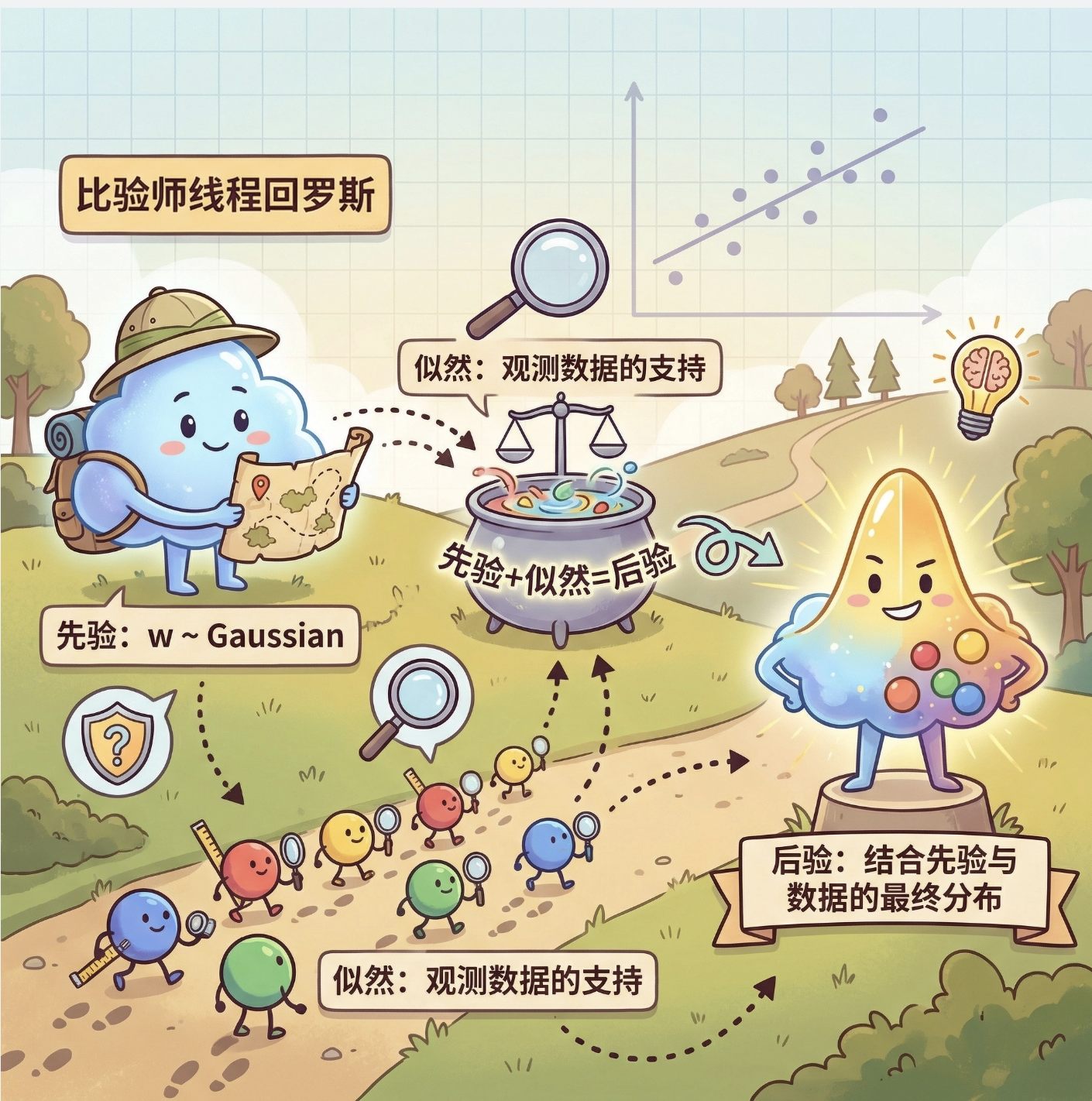
贝叶斯线性回归的核心是「先验 + 似然 = 后验」:
- 先验:对权重 w 的初始假设(比如假设 w 服从高斯分布);
- 似然:观测数据对 w 的支持程度;
- 后验:结合先验和数据后,w 的最终概率分布。
8.2.2 拟合方差
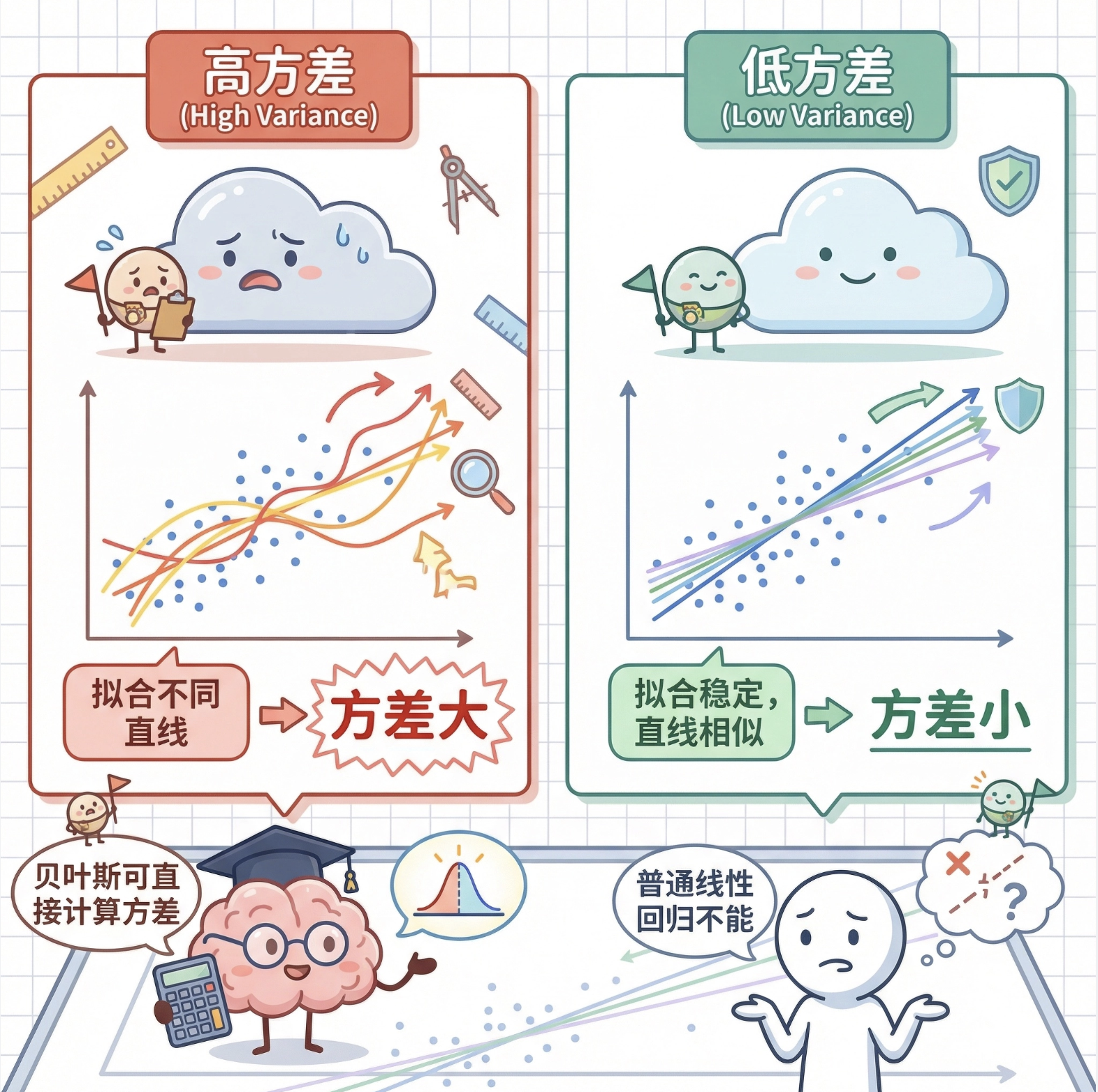
拟合方差反映了「模型对不同数据集的敏感程度」------ 方差大,说明换一批数据拟合出来的直线差异大;方差小,说明拟合结果稳定。贝叶斯线性回归能直接计算方差,而普通线性回归做不到。
完整代码(贝叶斯线性回归 + 方差可视化)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成数据 ====================
np.random.seed(42)
x = np.linspace(0, 10, 50)
y_true = 1.5 * x + 2
y = y_true + np.random.normal(0, 1.2, size=x.shape)
X = np.vstack([x, np.ones_like(x)]).T
# ==================== 贝叶斯线性回归求解 ====================
# 超参数:先验的方差、似然的方差
alpha = 1.0 # 先验w ~ N(0, alpha^-1 I)
beta = 10.0 # 似然y | x, w ~ N(w^T x, beta^-1)
# 后验协方差矩阵:Sigma = (alpha I + beta X^T X)^-1
Sigma = np.linalg.inv(alpha * np.eye(X.shape[1]) + beta * X.T @ X)
# 后验均值:mu = beta Sigma X^T y
mu = beta * Sigma @ X.T @ y
# 生成预测区间
x_test = np.linspace(0, 10, 100)
X_test = np.vstack([x_test, np.ones_like(x_test)]).T
# 预测均值
y_pred_mean = X_test @ mu
# 预测方差(包含模型不确定性+噪声)
y_pred_var = 1/beta + np.diag(X_test @ Sigma @ X_test.T)
# 95%置信区间
y_pred_upper = y_pred_mean + 2 * np.sqrt(y_pred_var)
y_pred_lower = y_pred_mean - 2 * np.sqrt(y_pred_var)
# ==================== 可视化 ====================
plt.figure(figsize=(10, 6))
plt.scatter(x, y, label='观测数据', color='lightcoral', alpha=0.7)
plt.plot(x_test, y_pred_mean, label='贝叶斯回归均值', color='royalblue', linewidth=2)
# 填充95%置信区间(方差可视化)
plt.fill_between(x_test, y_pred_lower, y_pred_upper, color='skyblue', alpha=0.3, label='95%置信区间')
plt.plot(x, y_true, label='真实模型', color='darkgreen', linestyle='--', linewidth=2)
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('贝叶斯线性回归拟合效果(含方差可视化)', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()
# 输出后验均值和方差
print(f"权重后验均值:w={mu[0]:.4f}, b={mu[1]:.4f}")
print(f"权重后验方差:\n{Sigma}")运行效果
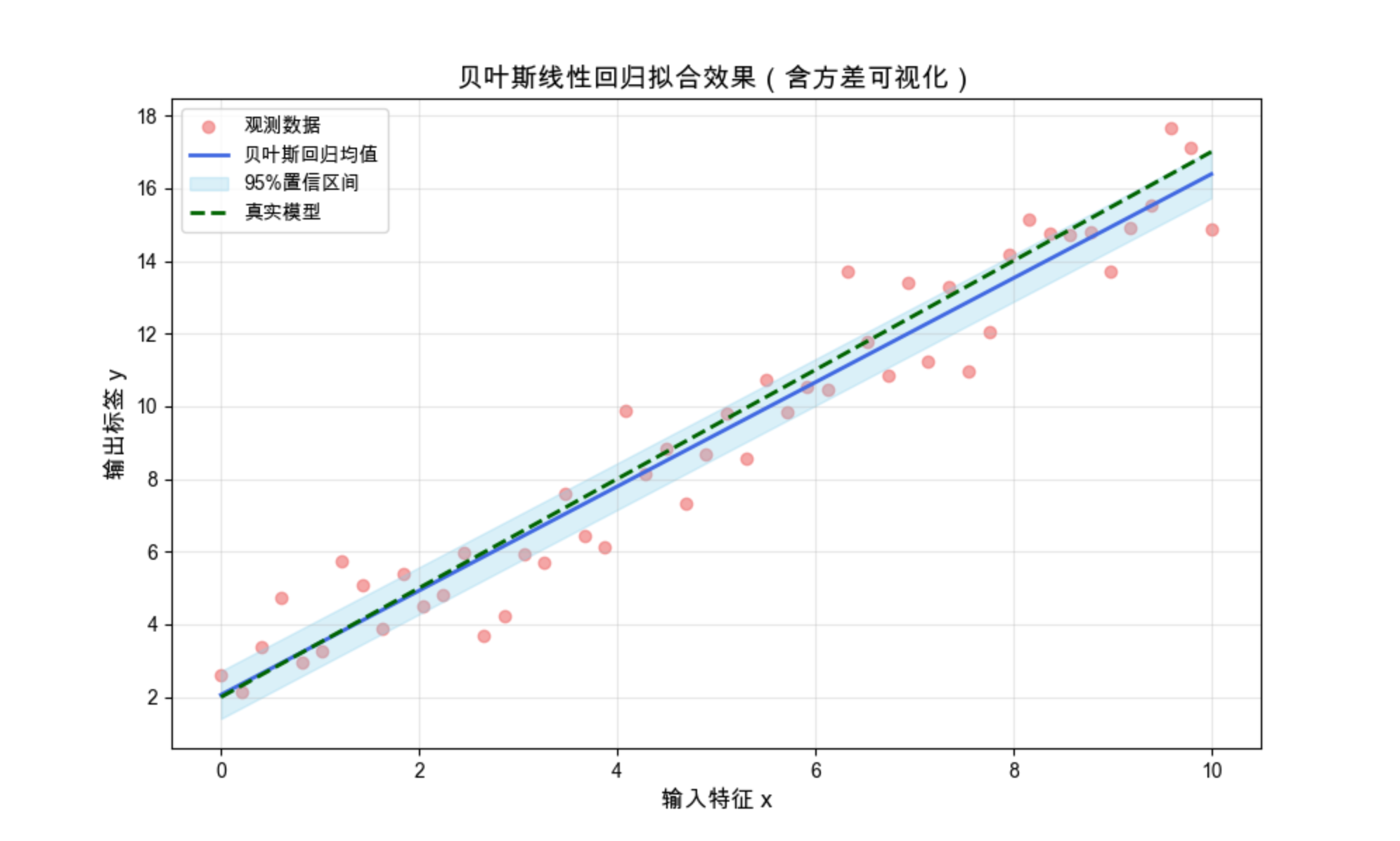
图中蓝色填充区域就是 95% 置信区间(方差的体现),区间越宽,说明该位置的预测不确定性越大,这是普通线性回归无法提供的关键信息。
8.3 非线性回归
核心概念
非线性回归就是「用曲线拟合数据」,解决线性回归无法处理的非线性问题。
核心思路是:把原始线性模型 y=wx+b 中的「线性项 wx」换成「非线性函数 φ(x)」,变成 y=wTφ(x)+b。
比如 φ(x)=x, x², x³,就能拟合三次曲线;φ(x)=sin (x), cos (x),就能拟合周期数据。
8.3.1 最大似然法
和线性回归的最小二乘法本质是一回事(高斯噪声下,最大似然等价于最小二乘),只是把特征换成了非线性特征。
8.3.2 贝叶斯非线性回归
在非线性特征空间中应用贝叶斯框架,既能拟合非线性数据,又能评估预测不确定性。
完整代码(非线性回归对比)
import numpy as np
import matplotlib.pyplot as plt
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成非线性数据(正弦曲线+噪声) ====================
np.random.seed(42)
x = np.linspace(0, 2*np.pi, 100)
y_true = np.sin(x) + 0.5 * np.cos(2*x)
y = y_true + np.random.normal(0, 0.15, size=x.shape)
# ==================== 1. 线性回归(对比组) ====================
X_linear = np.vstack([x, np.ones_like(x)]).T
w_linear = np.linalg.inv(X_linear.T @ X_linear) @ X_linear.T @ y
y_pred_linear = X_linear @ w_linear
# ==================== 2. 非线性回归(多项式特征,最大似然) ====================
# 构造非线性特征:[x, x², x³, x⁴, 1](4次多项式)
X_nonlinear = np.vstack([x, x**2, x**3, x**4, np.ones_like(x)]).T
w_nonlinear = np.linalg.inv(X_nonlinear.T @ X_nonlinear) @ X_nonlinear.T @ y
y_pred_nonlinear = X_nonlinear @ w_nonlinear
# ==================== 3. 贝叶斯非线性回归 ====================
alpha = 1.0
beta = 50.0
Sigma = np.linalg.inv(alpha * np.eye(X_nonlinear.shape[1]) + beta * X_nonlinear.T @ X_nonlinear)
mu = beta * Sigma @ X_nonlinear.T @ y
y_pred_bayes = X_nonlinear @ mu
# 计算预测方差
y_pred_var = 1/beta + np.diag(X_nonlinear @ Sigma @ X_nonlinear.T)
y_pred_upper = y_pred_bayes + 2 * np.sqrt(y_pred_var)
y_pred_lower = y_pred_bayes - 2 * np.sqrt(y_pred_var)
# ==================== 可视化对比 ====================
plt.figure(figsize=(12, 7))
plt.scatter(x, y, label='观测数据', color='lightcoral', alpha=0.7, s=30)
plt.plot(x, y_true, label='真实非线性模型(正弦+余弦)', color='darkgreen', linewidth=2, linestyle='--')
plt.plot(x, y_pred_linear, label='线性回归拟合', color='orange', linewidth=2)
plt.plot(x, y_pred_nonlinear, label='非线性回归(4次多项式)', color='royalblue', linewidth=2)
plt.fill_between(x, y_pred_lower, y_pred_upper, color='skyblue', alpha=0.3, label='贝叶斯非线性回归95%置信区间')
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('线性回归 vs 非线性回归 vs 贝叶斯非线性回归 效果对比', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()运行效果
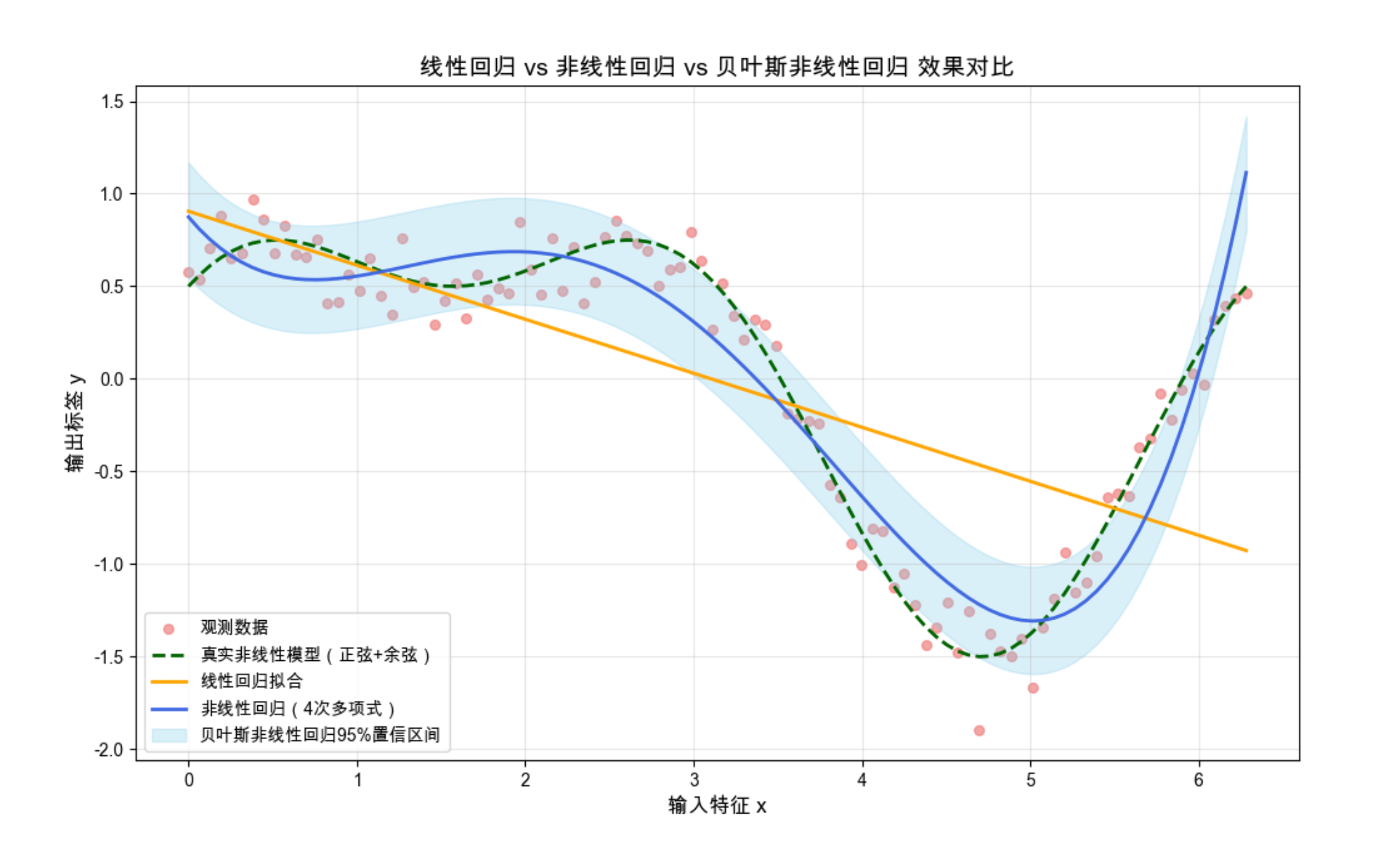
- 橙色直线:线性回归完全拟合不了正弦曲线;
- 蓝色曲线:非线性回归(4 次多项式)几乎和真实曲线重合;
- 浅蓝色填充:贝叶斯非线性回归的置信区间,能看到曲线两端的不确定性略大(数据少)。
8.4 核与核技巧
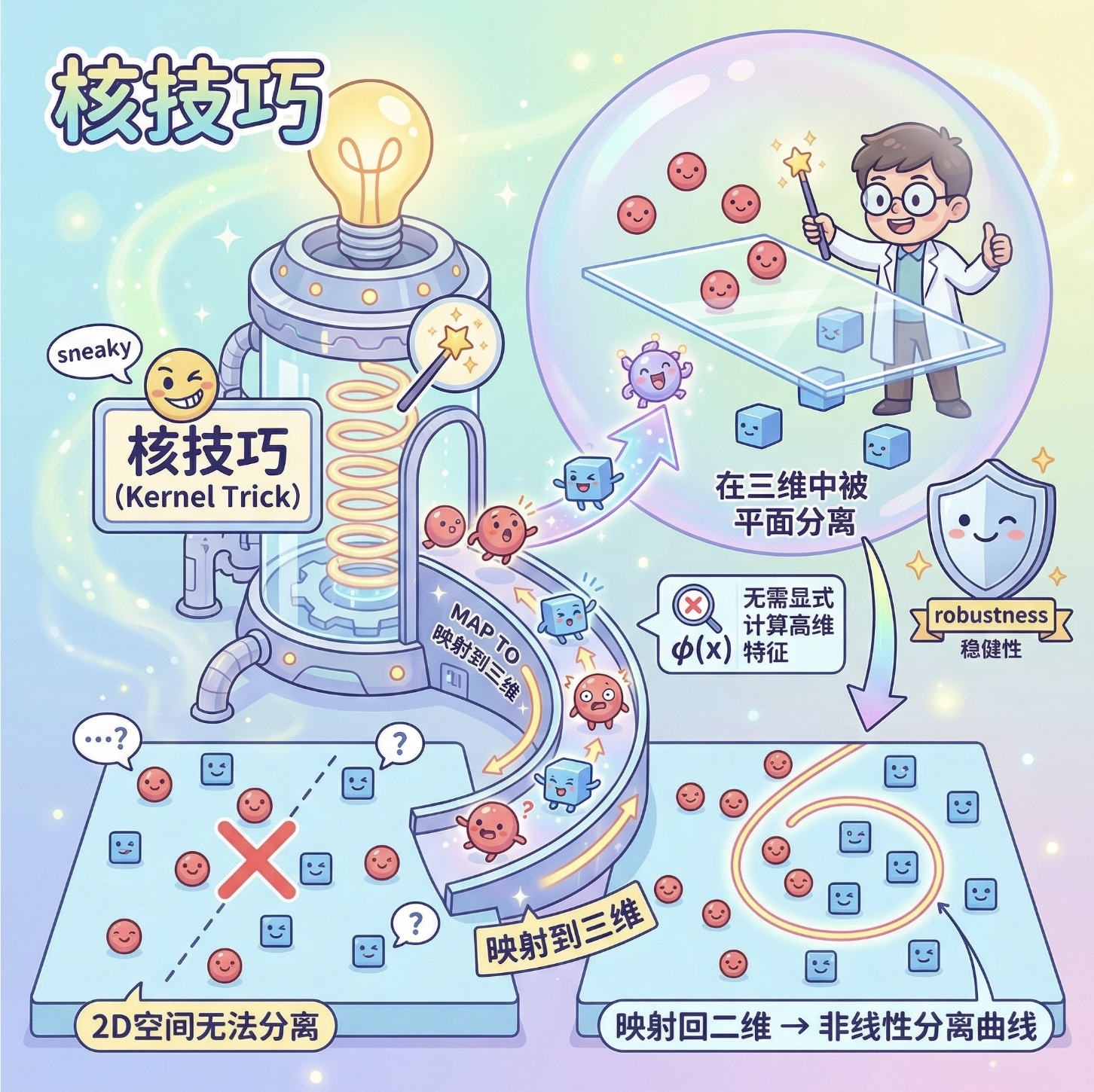
核心概念
核技巧是非线性回归的「神器」,可以理解为「不用显式计算高维非线性特征,就能间接在高维空间做线性回归」。
打个比方:你想把二维平面的非线性数据分开,直接在二维空间做不到,但核技巧能「偷偷把数据映射到三维空间」,在三维空间用平面分开后,再映射回二维,就得到了非线性的分隔曲线。
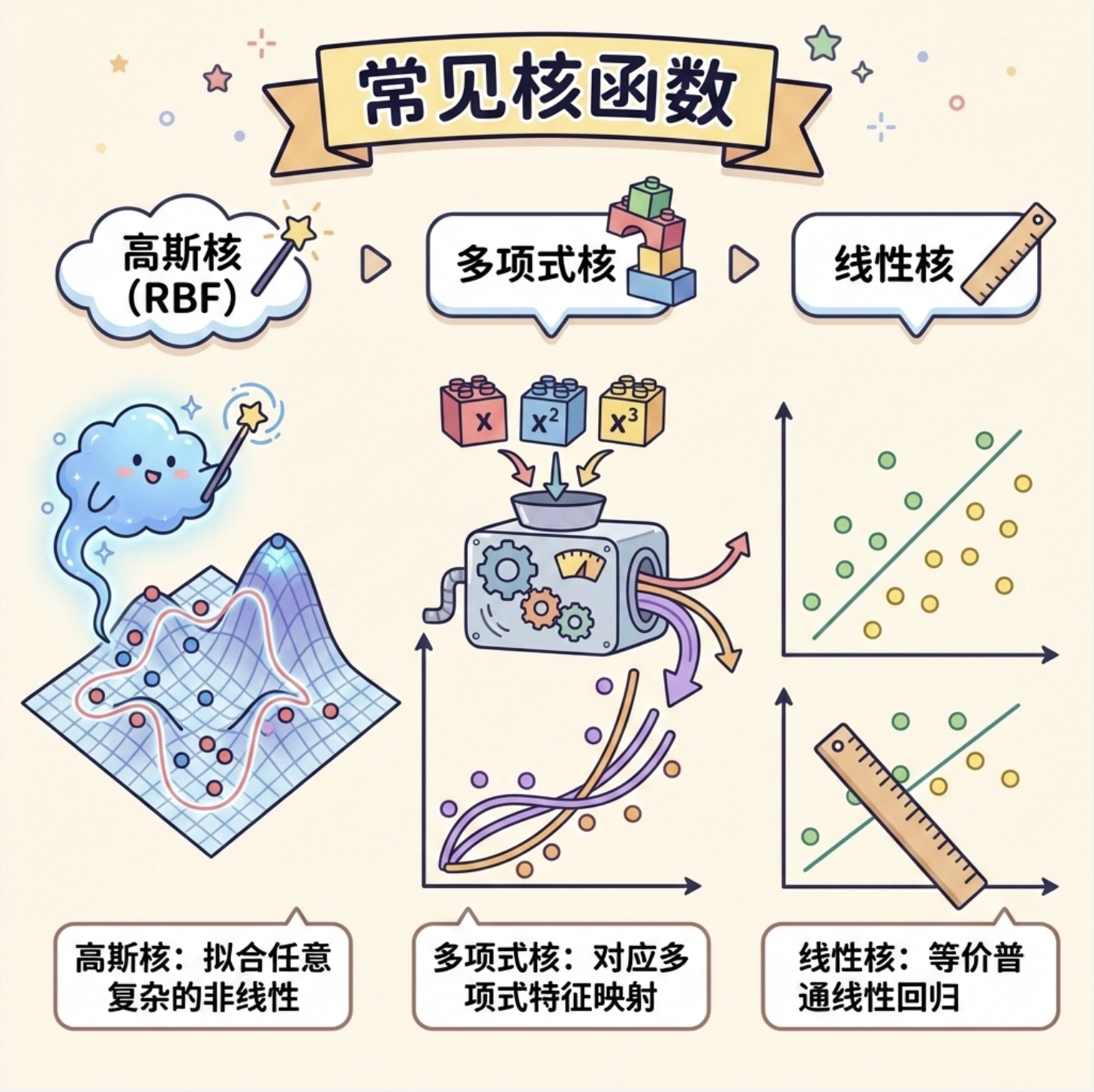
常用的核函数:
- 高斯核(RBF 核):最常用,能拟合任意复杂的非线性关系;
- 多项式核:对应多项式特征映射;
- 线性核:等价于普通线性回归。
代码(核技巧实现非线性回归)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.kernel_ridge import KernelRidge
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成数据 ====================
np.random.seed(42)
x = np.linspace(-3, 3, 100).reshape(-1, 1) # sklearn要求输入是2D数组
y_true = np.exp(-x**2) + 3 * np.exp(-(x-2)**2)
y = y_true + np.random.normal(0, 0.1, size=x.shape)
# ==================== 核回归 ====================
# 1. 线性核(对比组)
kr_linear = KernelRidge(kernel='linear', alpha=0.01)
kr_linear.fit(x, y)
y_pred_linear = kr_linear.predict(x)
# 2. 高斯核(RBF核)
kr_rbf = KernelRidge(kernel='rbf', gamma=0.5, alpha=0.01)
kr_rbf.fit(x, y)
y_pred_rbf = kr_rbf.predict(x)
# ==================== 可视化 ====================
plt.figure(figsize=(10, 6))
plt.scatter(x, y, label='观测数据', color='lightcoral', alpha=0.7)
plt.plot(x, y_true, label='真实模型', color='darkgreen', linewidth=2, linestyle='--')
plt.plot(x, y_pred_linear, label='线性核回归', color='orange', linewidth=2)
plt.plot(x, y_pred_rbf, label='高斯核(RBF)回归', color='royalblue', linewidth=2)
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('核技巧:线性核 vs 高斯核 回归效果对比', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()运行效果
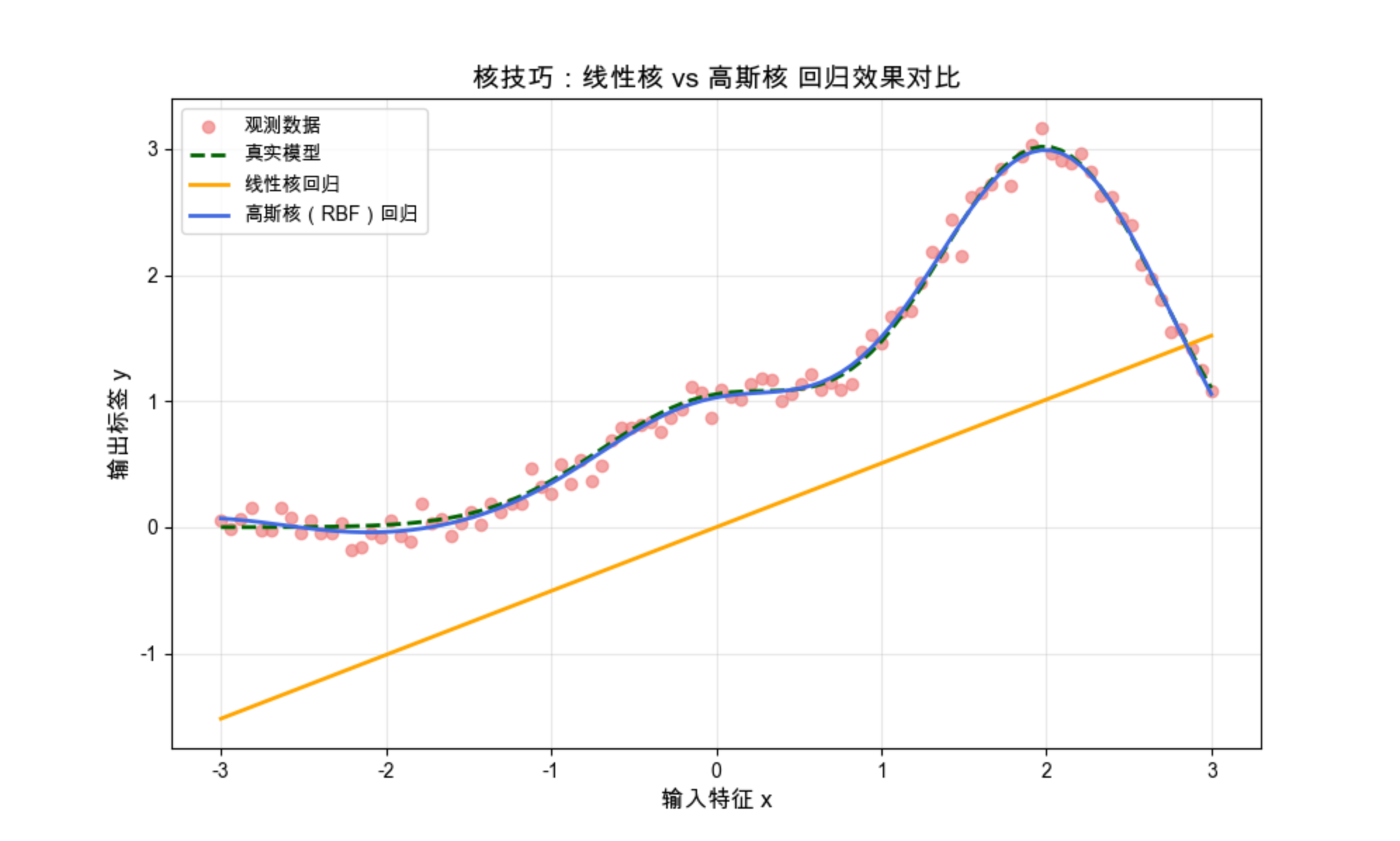
高斯核回归的曲线完美贴合真实模型,而线性核回归只能拟合出直线,体现了核技巧的强大之处。
8.5 高斯过程回归
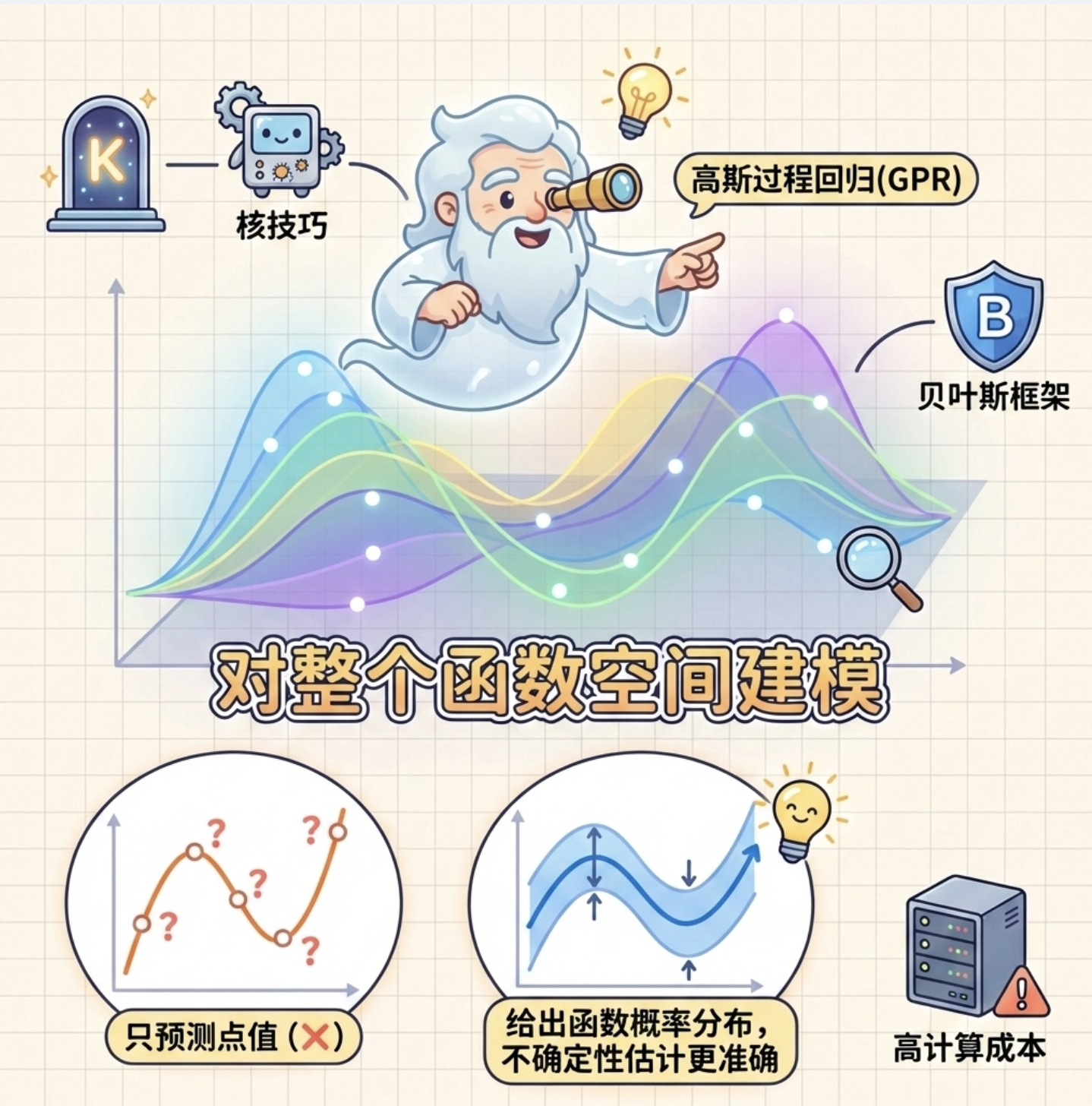
核心概念
高斯过程回归(GPR)是贝叶斯框架 + 核技巧的「终极形态」,可以理解为「对整个函数空间建模」------ 它不只是预测每个点的 y 值,而是给出整个函数的概率分布,不确定性估计更精准。
GPR 是计算机视觉中高端回归任务的首选(比如小样本的精细拟合),缺点是计算成本较高。
完整代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, WhiteKernel
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成数据 ====================
np.random.seed(42)
x = np.linspace(0, 10, 20).reshape(-1, 1) # 小样本(20个点)
y_true = np.sin(x) + 0.2 * x
y = y_true + np.random.normal(0, 0.2, size=x.shape)
# ==================== 高斯过程回归 ====================
# 定义核函数:RBF核 + 白噪声核(处理数据噪声)
kernel = RBF(length_scale=1.0, length_scale_bounds=(1e-1, 10.0)) + WhiteKernel(noise_level=1e-2, noise_level_bounds=(1e-4, 1e-1))
gpr = GaussianProcessRegressor(kernel=kernel, random_state=42)
gpr.fit(x, y)
# 预测(含不确定性)
x_test = np.linspace(0, 10, 100).reshape(-1, 1)
y_pred, y_std = gpr.predict(x_test, return_std=True)
# ==================== 可视化 ====================
plt.figure(figsize=(10, 6))
plt.scatter(x, y, label='观测数据(小样本)', color='lightcoral', alpha=0.7)
plt.plot(x_test, np.sin(x_test) + 0.2 * x_test, label='真实模型', color='darkgreen', linewidth=2, linestyle='--')
plt.plot(x_test, y_pred, label='高斯过程回归预测', color='royalblue', linewidth=2)
# 95%置信区间
plt.fill_between(x_test.ravel(), y_pred - 2*y_std, y_pred + 2*y_std, color='skyblue', alpha=0.3, label='95%置信区间')
plt.xlabel('输入特征 x', fontsize=12)
plt.ylabel('输出标签 y', fontsize=12)
plt.title('高斯过程回归(小样本拟合)', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
plt.show()
# 输出优化后的核参数
print(f"优化后的RBF长度尺度:{gpr.kernel_.k1.length_scale:.4f}")
print(f"优化后的噪声水平:{gpr.kernel_.k2.noise_level:.4f}")运行效果
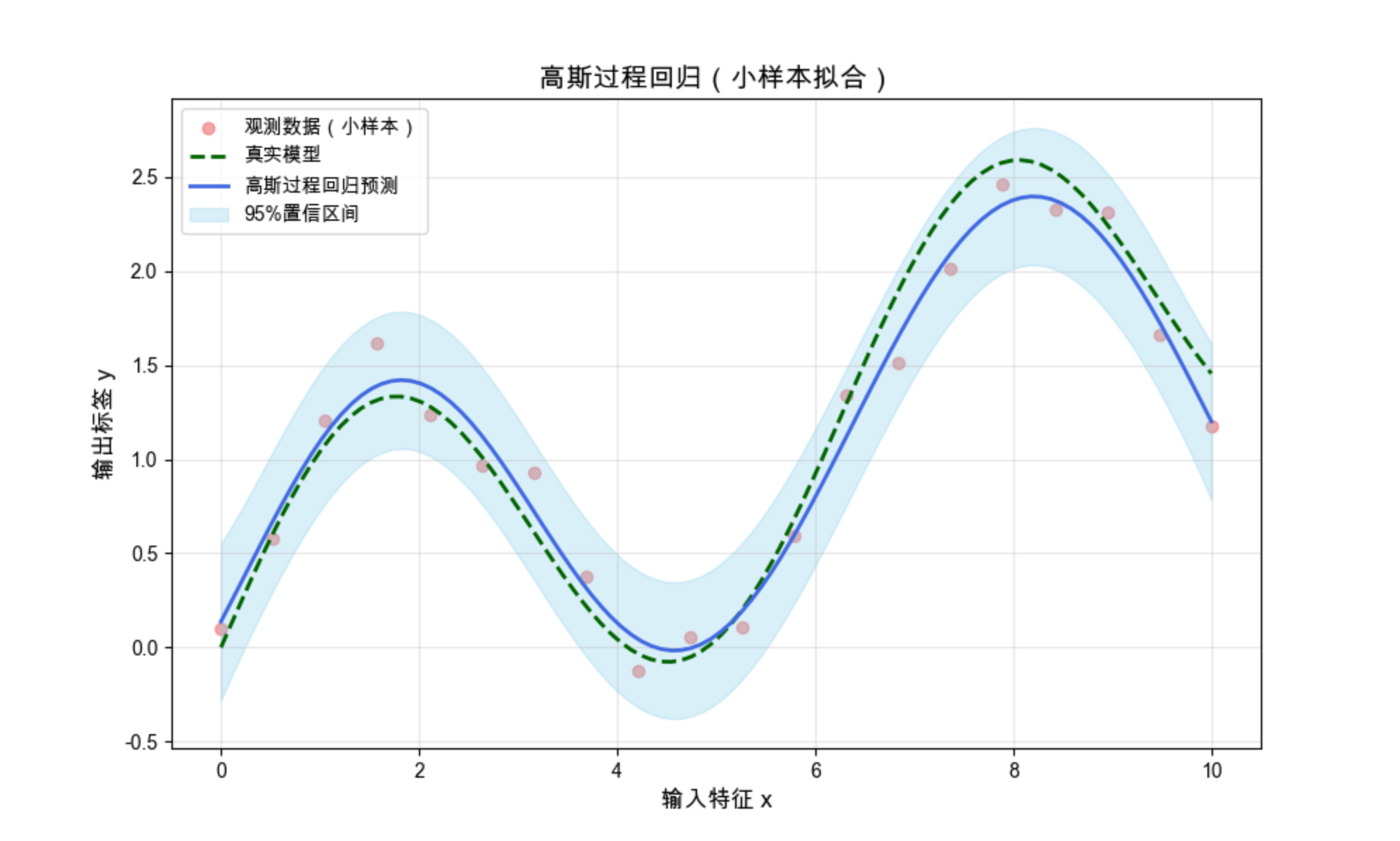
即使只有 20 个样本,GPR 也能精准拟合正弦曲线,且置信区间的宽度能反映预测的不确定性(数据密集处区间窄,稀疏处宽)。
8.6 稀疏线性回归

核心概念
稀疏线性回归的目标是「让大部分权重 w 为 0」,只保留少数重要特征,解决「维度灾难」问题。
比如在图像回归任务中,稀疏回归能自动筛选出对预测有用的像素,忽略无关像素,既减少计算量,又降低过拟合风险。最常用的方法是 Lasso 回归(L1 正则化)。
代码(稀疏回归 vs 普通回归)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Lasso
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成高维稀疏数据 ====================
np.random.seed(42)
n_samples = 100
n_features = 20
# 真实权重:只有前5个特征有非零值(稀疏)
w_true = np.zeros(n_features)
w_true[:5] = [1, -0.8, 0.6, -0.4, 0.2]
# 生成特征和标签
X = np.random.normal(0, 1, (n_samples, n_features))
y = X @ w_true + np.random.normal(0, 0.1, n_samples)
# ==================== 拟合模型 ====================
# 1. 普通线性回归
lr = LinearRegression()
lr.fit(X, y)
w_lr = lr.coef_
# 2. Lasso稀疏回归
lasso = Lasso(alpha=0.05, random_state=42)
lasso.fit(X, y)
w_lasso = lasso.coef_
# ==================== 可视化权重对比 ====================
plt.figure(figsize=(12, 6))
x_axis = np.arange(n_features)
width = 0.25
plt.bar(x_axis - width, w_true, width, label='真实权重', color='darkgreen', alpha=0.7)
plt.bar(x_axis, w_lr, width, label='普通线性回归权重', color='orange', alpha=0.7)
plt.bar(x_axis + width, w_lasso, width, label='Lasso稀疏回归权重', color='royalblue', alpha=0.7)
plt.axhline(y=0, color='black', linestyle='-', alpha=0.3)
plt.xlabel('特征维度', fontsize=12)
plt.ylabel('权重值', fontsize=12)
plt.title('稀疏线性回归(Lasso)vs 普通线性回归 权重对比', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3, axis='y')
plt.show()
# 输出稀疏性统计
print(f"普通回归非零权重数量:{np.sum(np.abs(w_lr) > 1e-4)}")
print(f"Lasso回归非零权重数量:{np.sum(np.abs(w_lasso) > 1e-4)}")运行效果
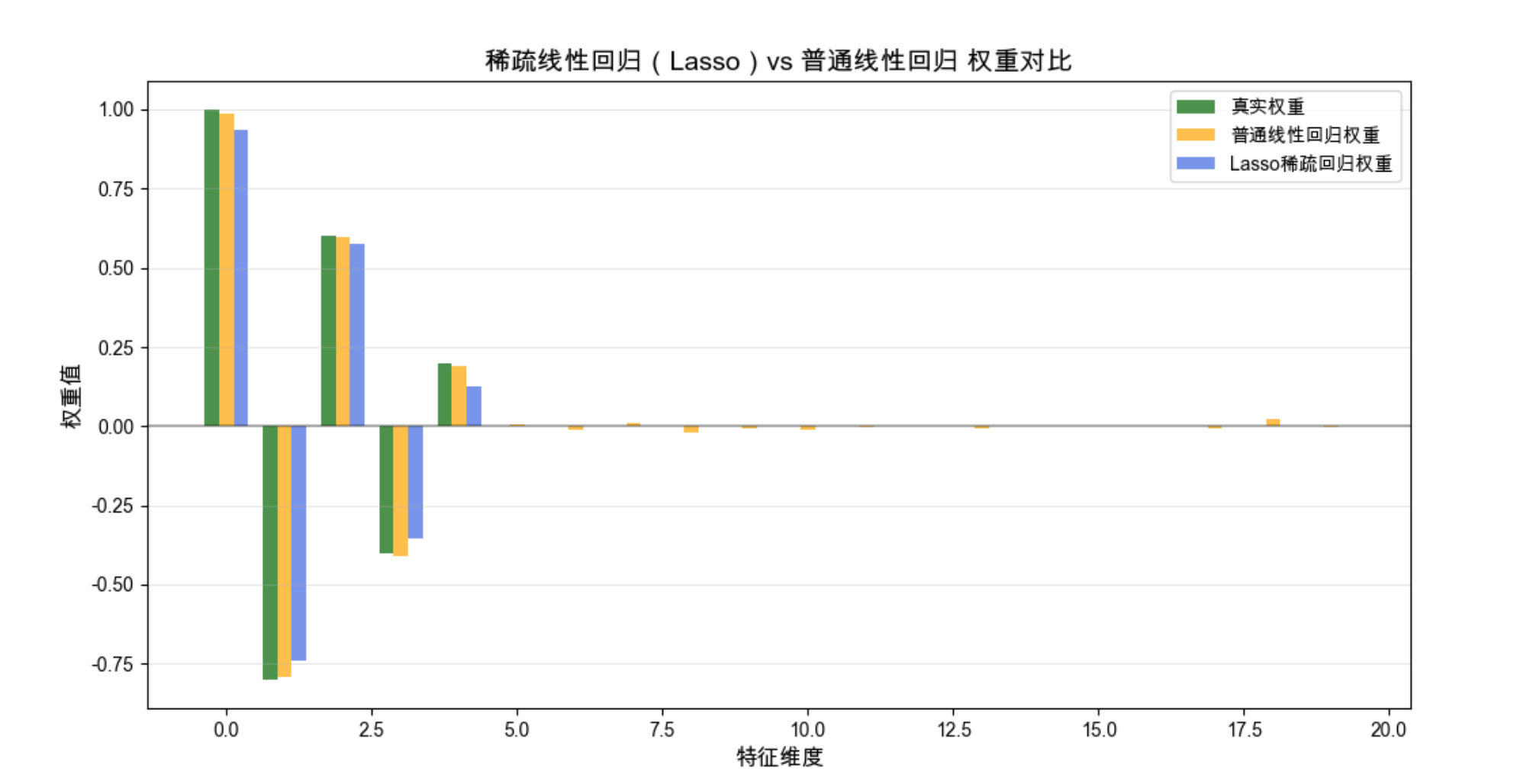
Lasso 回归的权重大部分为 0,只保留了前 5 个重要特征的非零权重,和真实权重高度一致;而普通线性回归的权重全部非零,引入了大量无关特征的噪声。
8.7 二元线性回归
核心概念
二元线性回归是「用线性模型解决二分类问题」(比如判断图像中的像素是前景还是背景),核心是把回归输出映射到 0/1 标签(比如用 sigmoid 函数)。
代码(二元回归分类)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 生成二元分类数据 ====================
np.random.seed(42)
# 类别0:均值(0,0),类别1:均值(2,2)
X0 = np.random.normal(0, 1, (50, 2))
X1 = np.random.normal(2, 1, (50, 2))
X = np.vstack([X0, X1])
y = np.hstack([np.zeros(50), np.ones(50)])
# ==================== 二元线性回归(逻辑回归) ====================
lr = LogisticRegression(random_state=42)
lr.fit(X, y)
# 生成网格用于绘制决策边界
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100), np.linspace(x2_min, x2_max, 100))
Z = lr.predict_proba(np.c_[xx1.ravel(), xx2.ravel()])[:, 1]
Z = Z.reshape(xx1.shape)
# ==================== 可视化 ====================
plt.figure(figsize=(10, 8))
# 绘制决策边界(概率=0.5的等高线)
contour = plt.contourf(xx1, xx2, Z, alpha=0.3, cmap='coolwarm')
plt.contour(xx1, xx2, Z, levels=[0.5], colors='black', linewidths=2)
# 绘制样本点
plt.scatter(X0[:, 0], X0[:, 1], label='类别0', color='blue', alpha=0.7)
plt.scatter(X1[:, 0], X1[:, 1], label='类别1', color='red', alpha=0.7)
plt.xlabel('特征1', fontsize=12)
plt.ylabel('特征2', fontsize=12)
plt.title('二元线性回归(逻辑回归)决策边界', fontsize=14)
plt.legend(fontsize=10)
plt.colorbar(contour, label='类别1的概率')
plt.grid(True, alpha=0.3)
plt.show()运行效果
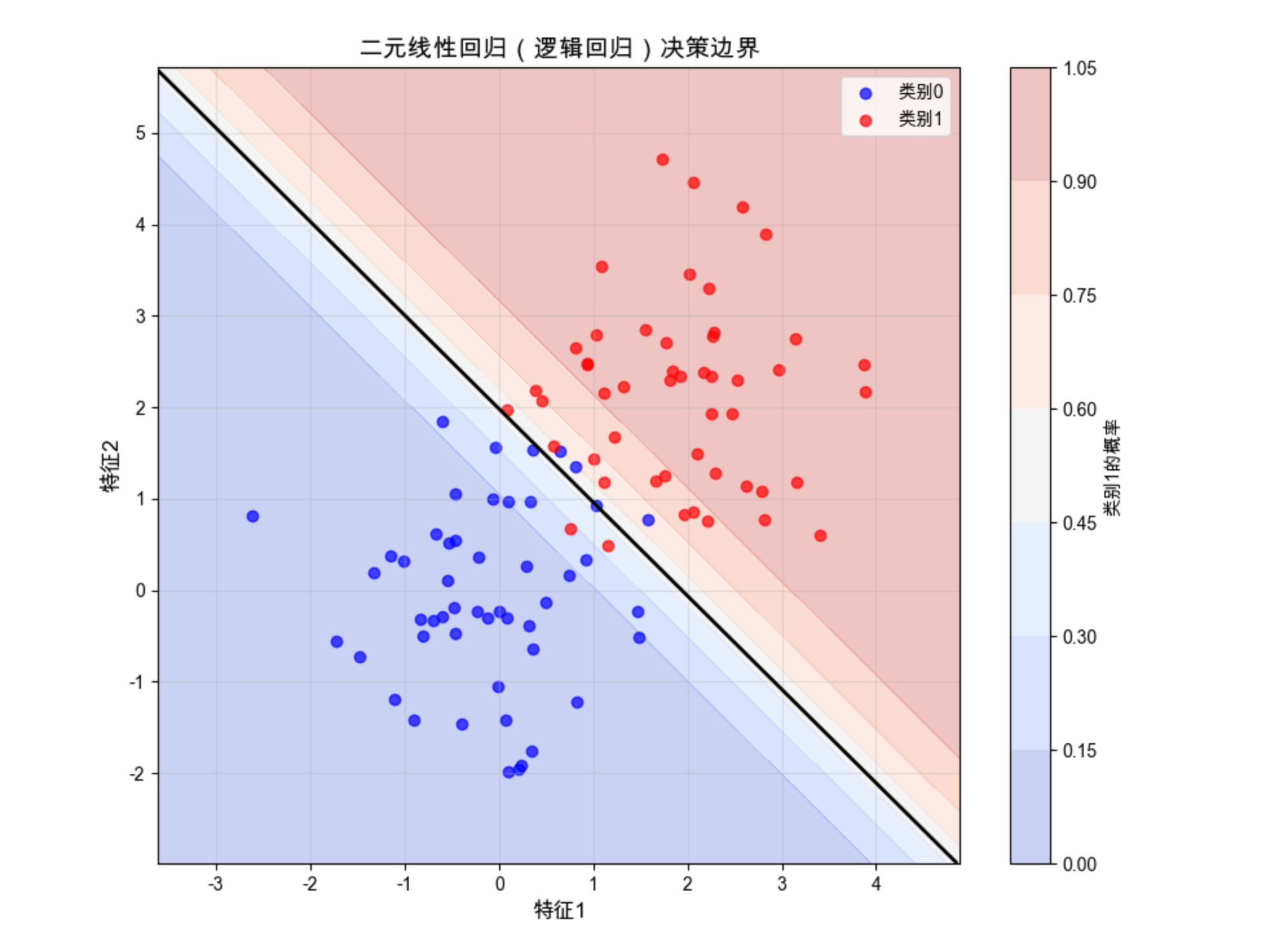
黑色直线是决策边界(概率 = 0.5),红色区域是类别 1 的高概率区,蓝色区域是类别 0 的高概率区,直观展示了二元线性回归的分类效果。
8.8 相关向量回归
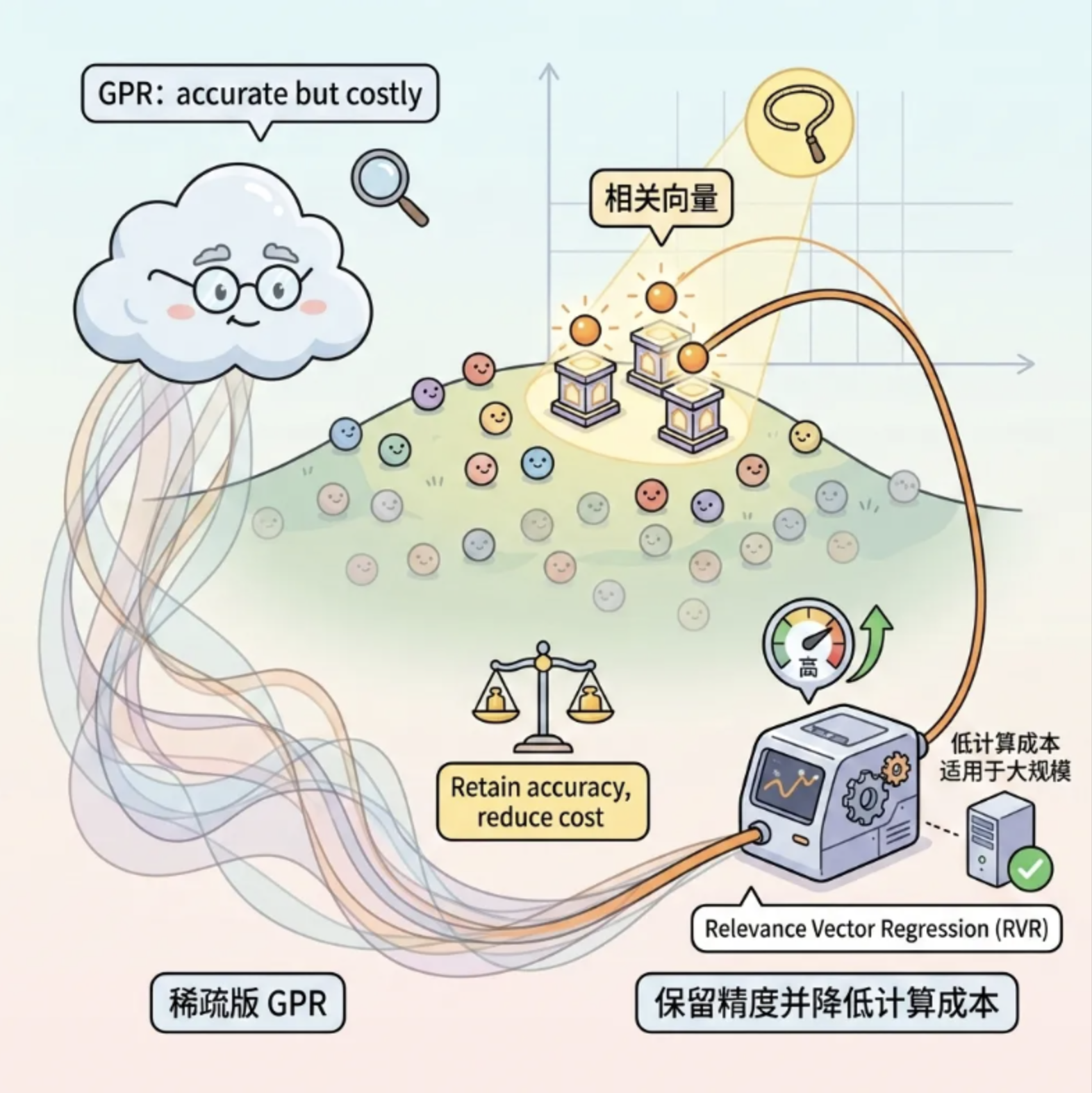
核心概念
相关向量回归(RVR)是「稀疏版的高斯过程回归」,它能自动选择少量「相关向量」(关键样本)来拟合数据,既保留了 GPR 的精准性,又大幅降低计算成本,适合大规模数据的回归任务。
8.9 多变量数据回归

核心概念
多变量回归就是「输入特征不止一个」的回归(比如用图像的 RGB 三个通道预测物体的深度),核心和单变量回归一致,只是权重 w 变成了向量,模型变成 y=w1x1+w2x2+...+wnxn+b。
代码(多变量回归:预测波士顿房价)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 加载多变量数据集(加州房价) ====================
data = fetch_california_housing()
X = data.data # 8个特征:平均收入、房屋年龄、平均房间数等
y = data.target # 房价(单位:10万美元)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ==================== 多变量线性回归 ====================
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
# ==================== 可视化预测效果 ====================
plt.figure(figsize=(10, 6))
# 绘制真实值vs预测值
plt.scatter(y_test, y_pred, alpha=0.5, color='royalblue')
# 绘制完美预测线(y=x)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', linewidth=2)
plt.xlabel('真实房价(10万美元)', fontsize=12)
plt.ylabel('预测房价(10万美元)', fontsize=12)
plt.title('多变量线性回归:加州房价预测效果', fontsize=14)
plt.grid(True, alpha=0.3)
plt.show()
# 输出结果
print(f"测试集均方误差:{mean_squared_error(y_test, y_pred):.4f}")
print(f"各特征权重:{lr.coef_}")
print(f"偏置项:{lr.intercept_:.4f}")运行效果
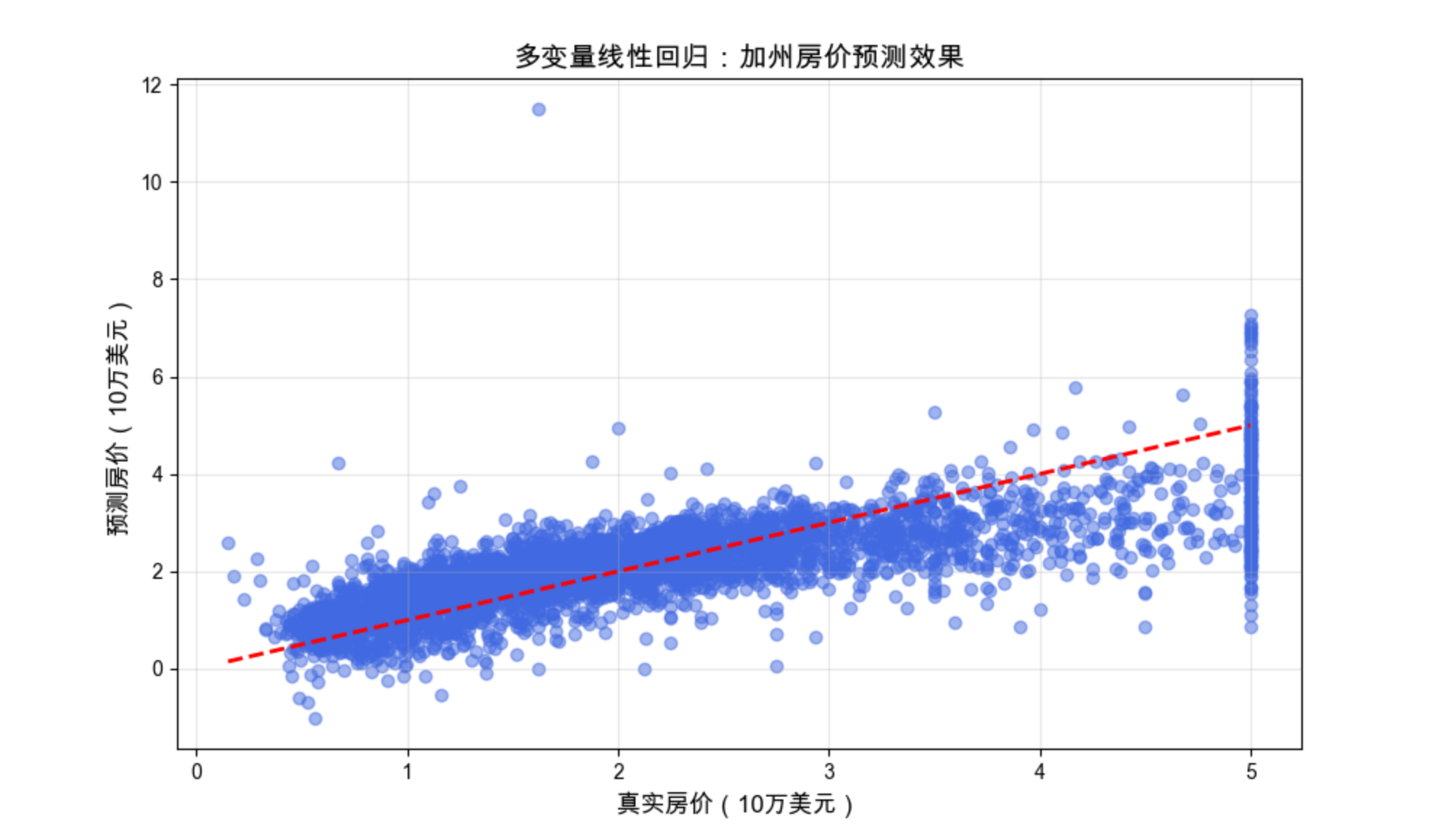
散点越靠近红色虚线,说明预测越准确,直观展示了多变量回归在真实场景中的应用效果。
8.10 应用
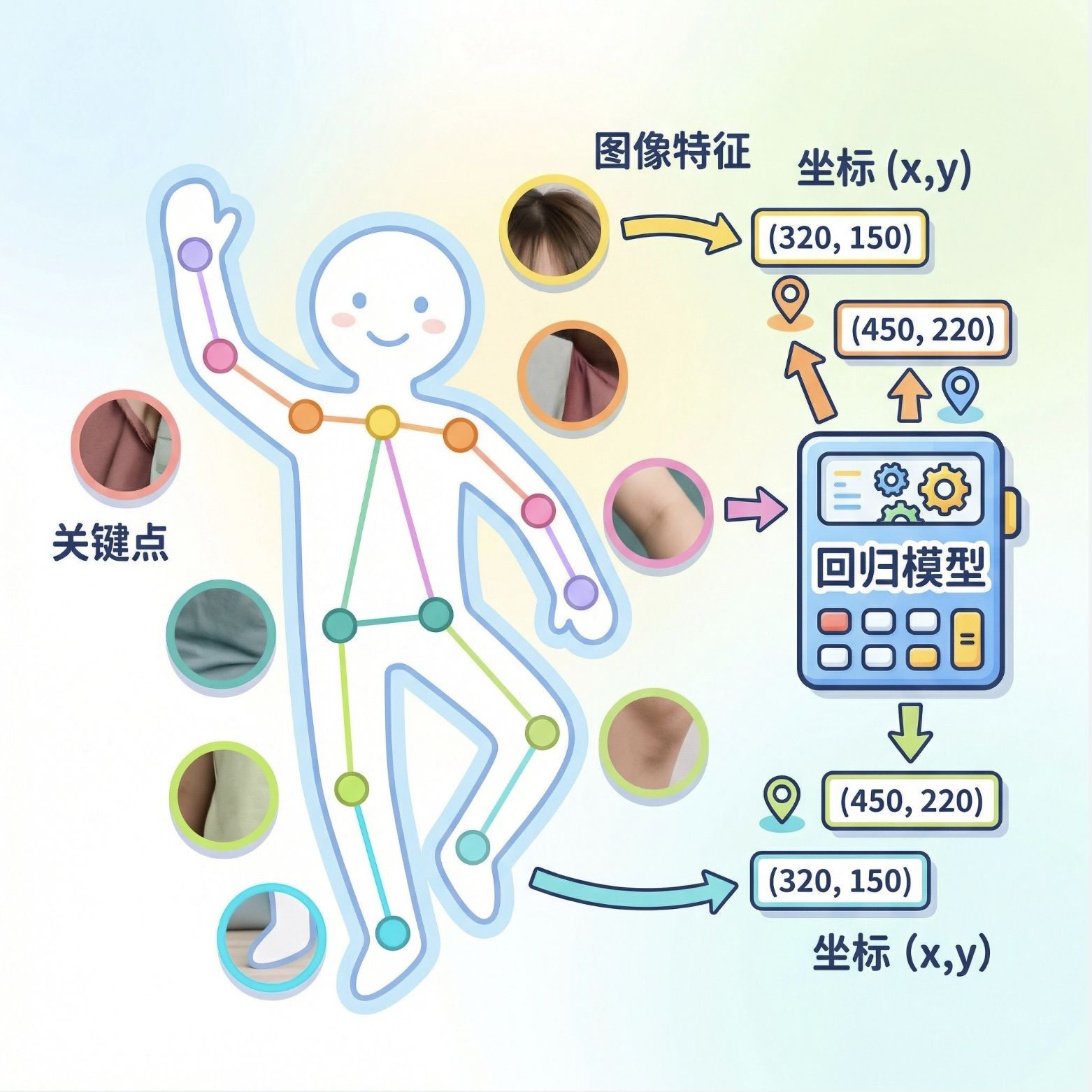
8.10.1 人体姿势估计
人体姿势估计是回归模型在计算机视觉中的经典应用:把图像中的关节点(比如手肘、膝盖)的坐标作为回归目标,用图像特征(比如关键点周围的像素)预测关节点的 (x,y) 坐标。
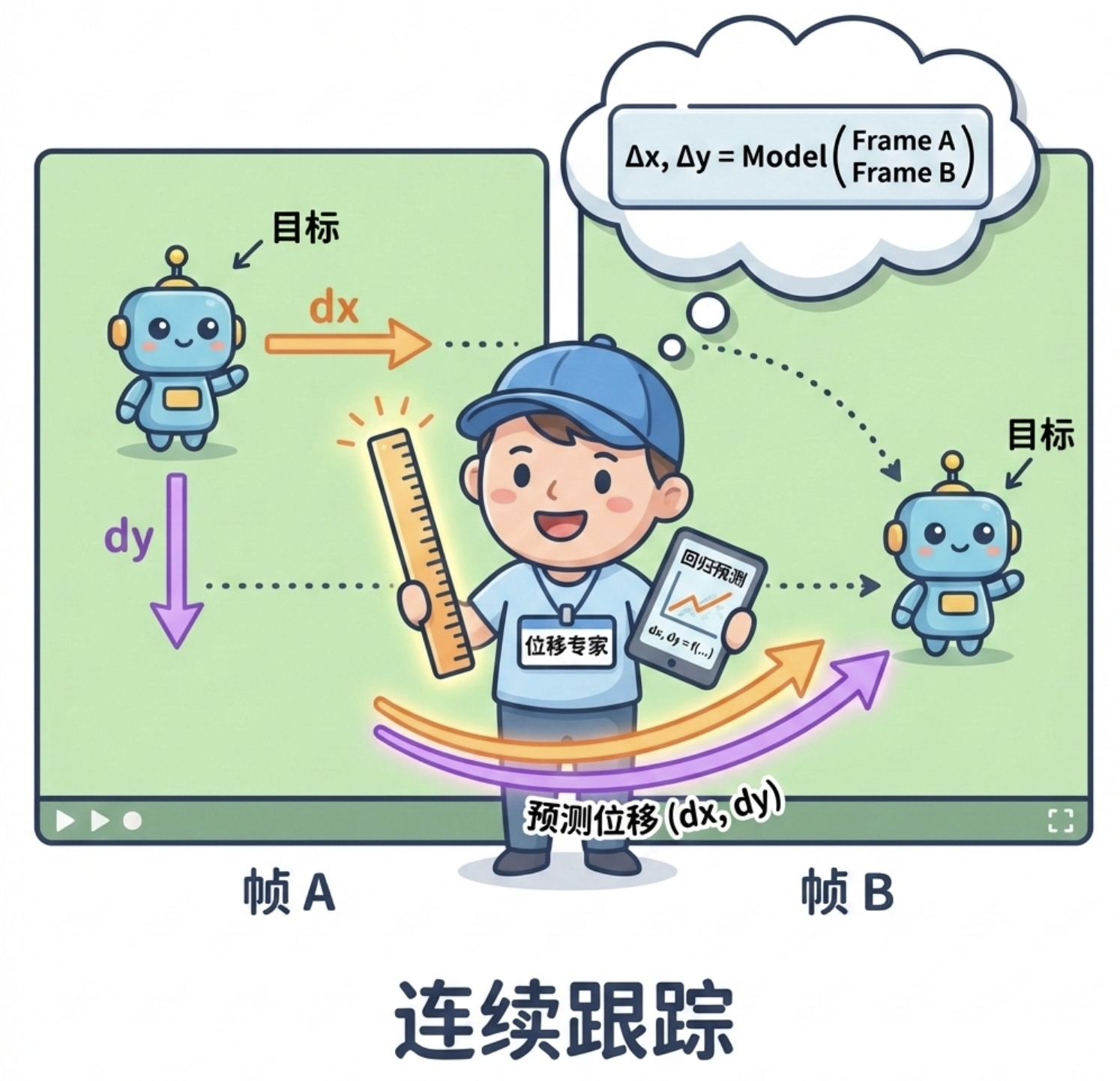
8.10.2 位移专家
位移专家(Displacement Expert)是目标跟踪中的核心技术:用回归模型预测目标在相邻帧中的位移(dx, dy),从而实现目标的持续跟踪。
简化示例代码(模拟位移预测)
python
import numpy as np
import matplotlib.pyplot as plt
# 新增:导入需要的sklearn模块
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# ==================== Mac字体配置 ====================
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# ==================== 模拟目标位移数据 ====================
np.random.seed(42)
# 输入特征:前一帧目标的位置、大小、纹理特征(简化为3个特征)
X = np.random.normal(0, 1, (200, 3))
# 真实位移:dx = 0.5*X0 + 0.2*X1 - 0.1*X2 + 噪声
# dy = 0.3*X0 - 0.4*X1 + 0.2*X2 + 噪声
dx_true = 0.5 * X[:,0] + 0.2 * X[:,1] - 0.1 * X[:,2]
dy_true = 0.3 * X[:,0] - 0.4 * X[:,1] + 0.2 * X[:,2]
dx = dx_true + np.random.normal(0, 0.1, size=200)
dy = dy_true + np.random.normal(0, 0.1, size=200)
# ==================== 回归预测位移 ====================
# 预测dx
lr_dx = LinearRegression()
lr_dx.fit(X, dx)
dx_pred = lr_dx.predict(X)
# 预测dy
lr_dy = LinearRegression()
lr_dy.fit(X, dy)
dy_pred = lr_dy.predict(X)
# ==================== 可视化位移预测效果 ====================
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左图:dx预测
ax1.scatter(dx, dx_pred, alpha=0.5, color='royalblue')
ax1.plot([dx.min(), dx.max()], [dx.min(), dx.max()], 'r--', linewidth=2)
ax1.set_xlabel('真实dx', fontsize=12)
ax1.set_ylabel('预测dx', fontsize=12)
ax1.set_title('位移预测:dx', fontsize=14)
ax1.grid(True, alpha=0.3)
# 右图:dy预测
ax2.scatter(dy, dy_pred, alpha=0.5, color='lightcoral')
ax2.plot([dy.min(), dy.max()], [dy.min(), dy.max()], 'r--', linewidth=2)
ax2.set_xlabel('真实dy', fontsize=12)
ax2.set_ylabel('预测dy', fontsize=12)
ax2.set_title('位移预测:dy', fontsize=14)
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 输出预测误差
print(f"dx预测均方误差:{mean_squared_error(dx, dx_pred):.4f}")
print(f"dy预测均方误差:{mean_squared_error(dy, dy_pred):.4f}")运行效果
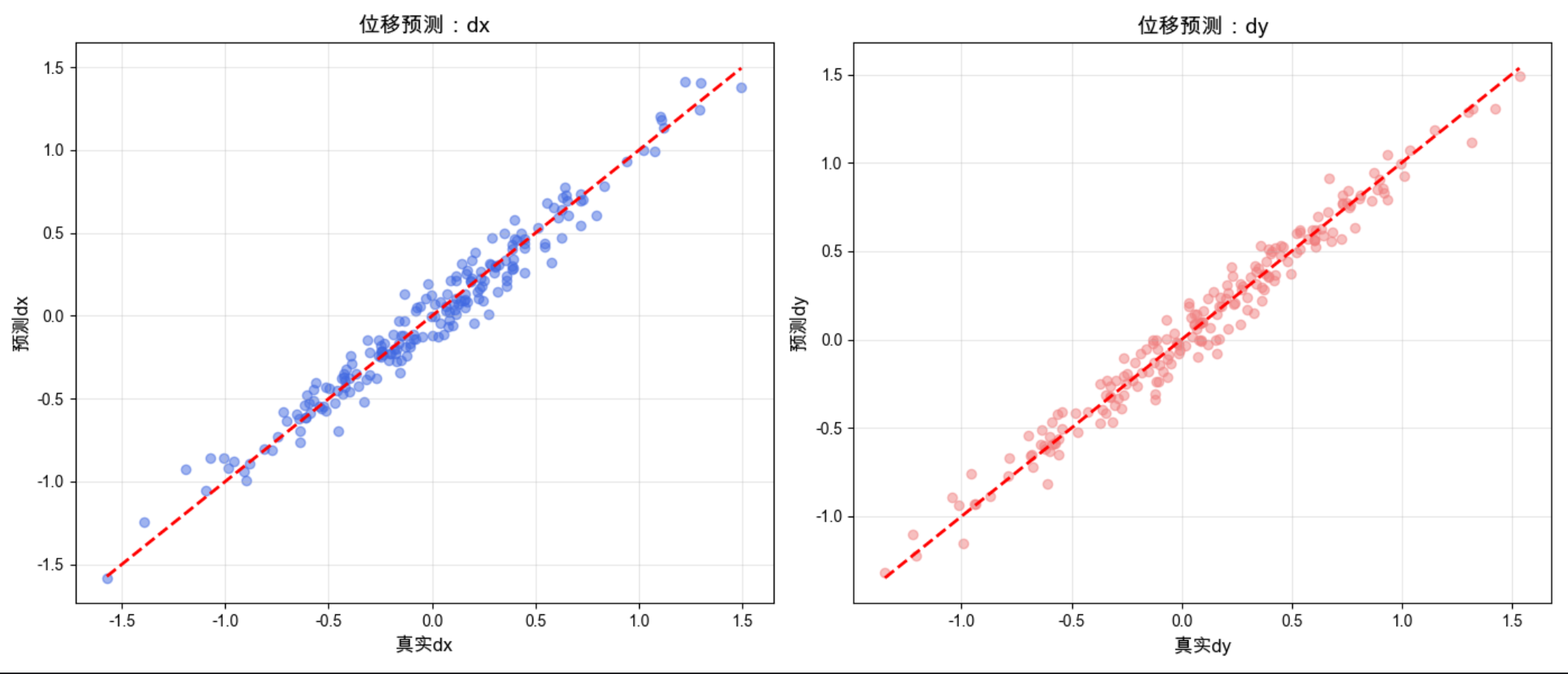
两张子图分别展示 dx 和 dy 的预测效果,散点越靠近红色虚线,说明位移预测越准确,模拟了「位移专家」的核心逻辑。
讨论
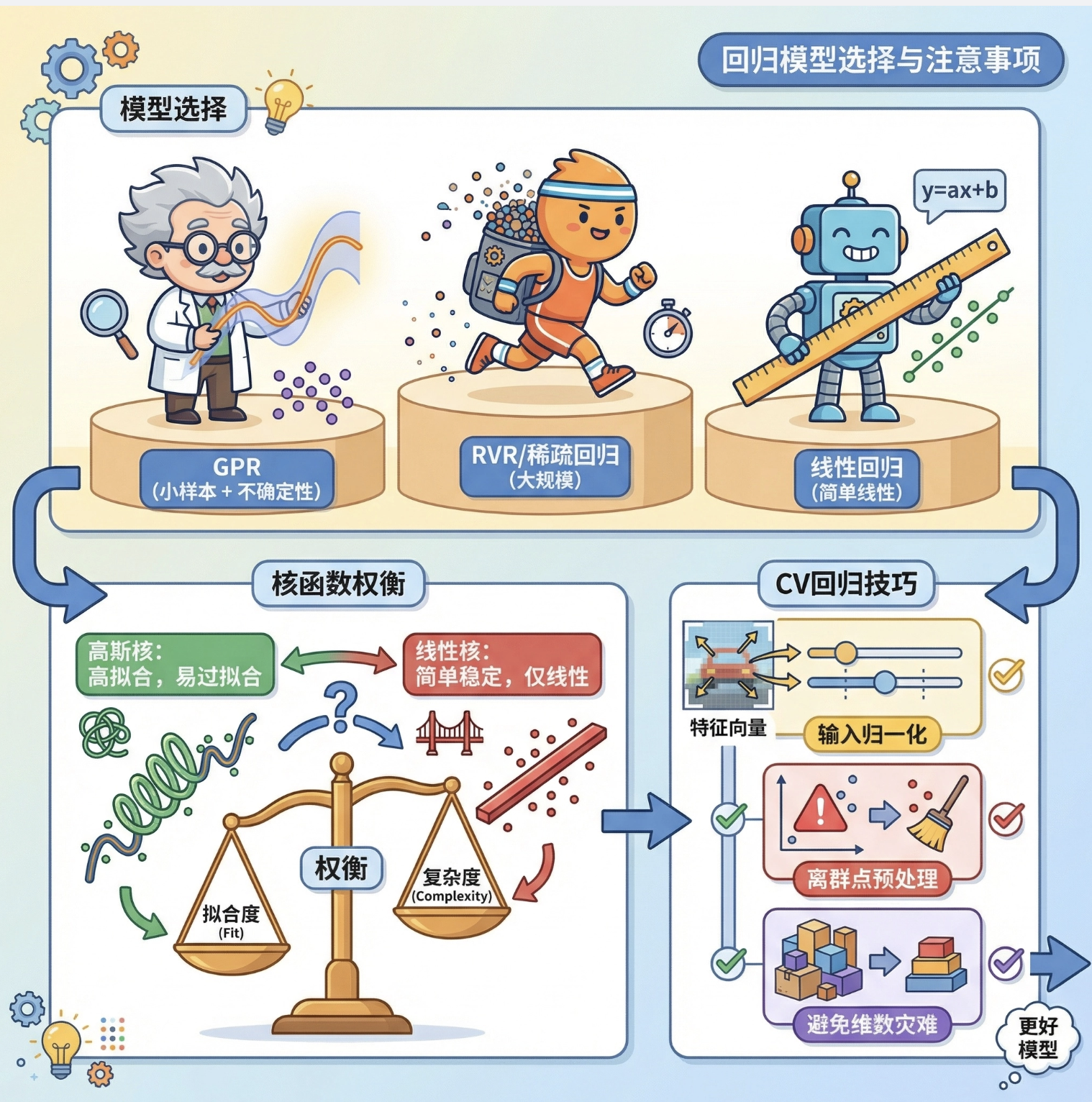
1.回归模型的选择:小样本、需要不确定性估计选 GPR;大规模数据选稀疏回归 / RVR;简单线性关系选普通线性回归;
2.核技巧的 Trade-off:高斯核拟合能力强,但容易过拟合;线性核简单稳定,但只能处理线性关系;
3.计算机视觉中的回归注意事项:输入特征需要归一化,异常值要预处理,避免维度灾难。
备注
1.所有代码均基于 Python 3.8+,依赖库:numpy、matplotlib、scikit-learn;
2.安装依赖:pip install numpy matplotlib scikit-learn;
3.Mac 系统若仍有中文显示问题,可检查是否安装了 Arial Unicode MS 字体(Mac 原生自带)。
习题
1.修改线性回归代码,加入 L2 正则化(Ridge 回归),对比普通线性回归和 Ridge 回归在有异常值时的拟合效果;
2.尝试用不同的核函数(多项式核、sigmoid 核)替换高斯核,对比非线性回归效果;
3.基于加州房价数据集,用 Lasso 回归筛选重要特征,再用筛选后的特征做回归,对比模型性能。
总结
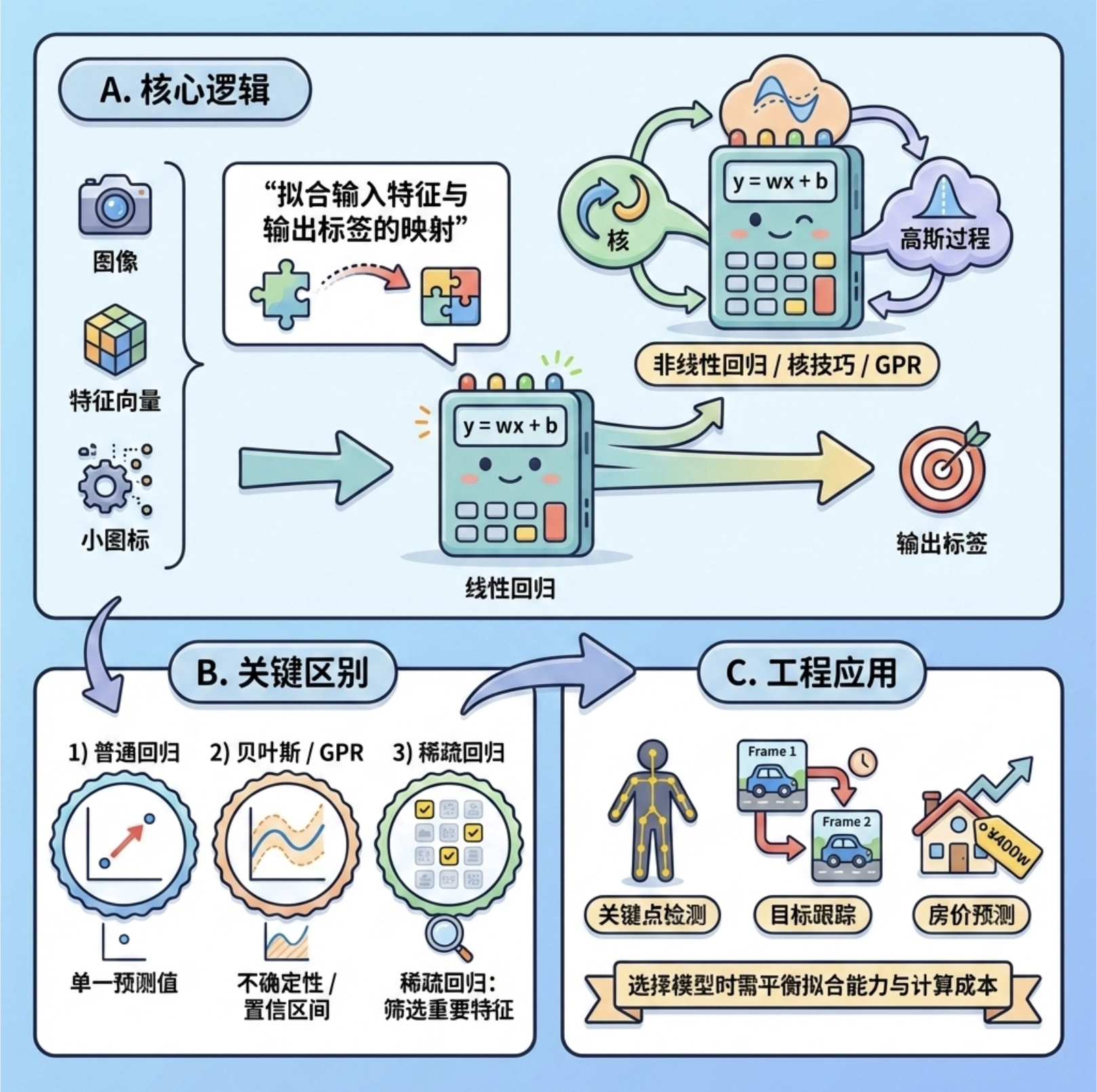
1.核心逻辑 :回归模型的本质是「拟合输入特征和输出标签的映射关系」,线性回归是基础,非线性回归 / 核技巧 / GPR 是对线性回归的扩展,解决非线性问题;
2.关键差异:普通回归只给单一预测值,贝叶斯回归 / GPR 能给出不确定性(置信区间),稀疏回归能筛选重要特征;
3.工程应用 :计算机视觉中,回归模型常用于关键点检测、目标跟踪、房价预测等场景,选择模型时需平衡拟合能力和计算成本。
希望这篇文章能帮你吃透回归模型!所有代码都能直接运行,建议动手改改参数(比如正则化强度、核函数参数),直观感受不同参数对结果的影响~