贝叶斯和特征降维
XGB的安装和使用
在sklean机器学习库中没有集成 xgb。想要使用 xgb,需要手工安装
bash
pip install xgboost可以在xgb的官网上查看最新版本:xgboost.readthedocs.io/en/latest/
XGB的编码风格
- 支持非sklearn方式,也即是自己的风格
- 支持sklearn方式,调用方式保持sklearn的形式
XGB 红酒分类案例
底层通过打分函数,决定是否划分分支。
- 分数 = 分裂前 - 分裂后的(左子树 + 右子树)
- 如果分数 > 0,可以考虑分裂。
- 如果分数 < 0,不分裂。

数据预处理
后面的案例使用该代码生成的文件
py
import pandas as pd
from collections import Counter # 统计
from sklearn.model_selection import train_test_split
# TODO:1.读取数据
data = pd.read_csv('./data/红酒品质分类.csv')
# TODO:2.数据预处理
# 抽取特征和标签
x = data.iloc[:, :-1] # 不要最后一列
y = data.iloc[:, -1] - 3 # 只取最后一列,原始数据是 3~8,这里减3,变成 0~5,适用于多分类法,共6个分类
# 查看数据分布情况,查看数据不均匀情况
# 可以看到,2,3,4 分类较多
print(Counter(y)) # Coun
# ter({2: 681, 3: 638, 4: 199, 1: 53, 5: 18, 0: 10})
# stratify 参考原始数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y, random_state=22)
# 打印拆分后,训练集和测试集标签分布情况
# 根据测试,stratify加上,会大概率的按照test_size的比例,将数据集进行拆分
print(Counter(y_train)) # Counter({2: 545, 3: 510, 4: 159, 1: 42, 5: 15, 0: 8})
print(Counter(y_test)) # Counter({2: 136, 3: 128, 4: 40, 1: 11, 5: 3, 0: 2})
# 保存到csv
pd.concat([x_train, y_train], axis=1).to_csv('./data/红酒品质分类_train.csv', index=False)
pd.concat([x_test, y_test], axis=1).to_csv('./data/红酒品质分类_test.csv', index=False)训练模型
py
import joblib
import pandas as pd
from collections import Counter # 统计
from sklearn.utils import class_weight # 平衡权重
from xgboost import XGBClassifier # 或者 import xgboost as xgb ,必须通过 xgb.XGBClassifier
# TODO:1.读取数据
train_data = pd.read_csv('./data/红酒品质分类_train.csv')
test_data = pd.read_csv('./data/红酒品质分类_test.csv')
# TODO:2.数据预处理
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
# 这里可以做权重平衡,平衡样本的权重问题
# 查看分布情况
print(Counter(y_train))
# balanced 平衡, 参数二;y_train 表示参考这个数据
class_weight.compute_sample_weight('balanced', y_train)
# TODO:3.构建模型
# 创建 XGBoost 模型对象
# 参数
# objective:损失函数,默认是二分类,我们的标签是【0~6】,所以需要设置成多分类,multi:softmax多分类
# learning_rate:学习率,默认是0.3,防止过拟合
# max_depth:树的深度,默认是6
# n_estimators:树的数量,默认是100
estimator = XGBClassifier(objective='multi:softmax', max_depth=6, learning_rate=0.3, n_estimators=100)
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
print('预测结果:', y_predict)
print('准确率:', estimator.score(x_test, y_test))
# 模型保存
joblib.dump(estimator, './data/红酒品质分类.pkl')模型预测
在之前做交叉验证的时候,数据可以做几折验证,那是基于数据混乱的情况下,如果数据样本不平衡,可以采用分层的方式
py
import joblib
import pandas as pd
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV
# TODO:1.读取数据
train_data = pd.read_csv('./data/红酒品质分类_train.csv')
test_data = pd.read_csv('./data/红酒品质分类_test.csv')
# TODO:2.数据预处理
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
# 查看分布情况,结果不均匀
# 采用分层采样(一般结合 网格搜索+交叉验证一起使用)。目的:避免过拟合
# 采样时 会让采样数据的各分类比例保持和原始数据的各分类比例保持近似一致
# 参1:采样的次数(类似于折数),参2:是否打乱,参3:随机种子
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=22)
# 读取文件加载,模型对象 -> XGBoost 模型对象,极限梯度提升树
estimator = joblib.load('./data/红酒品质分类.pkl')
# 定义超参字段,记录超参可取值。
param_dict = {'n_estimators': [60, 90, 130, 150, 200], 'max_depth': [2, 3, 5, 7, 9],
'learning_rate': [0.1, 0.2, 0.3, 1, 1.3]}
# 通过网格搜索 + 交叉验证,寻找最优的参数组合
estimator_gs = GridSearchCV(estimator, param_grid=param_dict, cv=skf)
# 模型训练
estimator_gs.fit(x_train, y_train)
# 模型预测
y_predict = estimator_gs.predict(x_test)
print('准确率:', estimator_gs.score(x_test, y_test))
# 打印最优组合
print('最优参数:', estimator_gs.best_params_)
print('最优结果:', estimator_gs.best_score_)


贝叶斯





拉普拉斯平滑系系数

- 朴素贝叶斯算法概念
用概率值进行分类的一种机器学习算法。贝叶斯基础上增加特征条件独立假设。
- 概率数学基础
- 概率:一件事情发生的可能性。
- 条件概率:表示事件A在另外一个事件B已经发生条件下的发生概率,P(A|B)
- 联合概率:表示多个条件同时成立的概率,P(AB) = P(A) * P(B|A) = P(B)* P(A|B)
- 贝叶斯公式

- 拉普拉斯平滑系数
为了避免概率值为 0,我们在分子和分母分别加上一个数值,这就是拉普拉斯平滑系数的作用

总结:
- 计算机为了方便计算,一般会把多个条件(特征)当作独立条件来处理,即:P(AB) = P(A) * P(B)
- 如果条件(特征)都是独立的,则称之为:朴素贝叶斯
- 上述公式中,分母是不能为零的,为了解决这个问题,我们可以分别给分子和分母加一个系数,这个系数 = 拉普拉斯平滑系数。
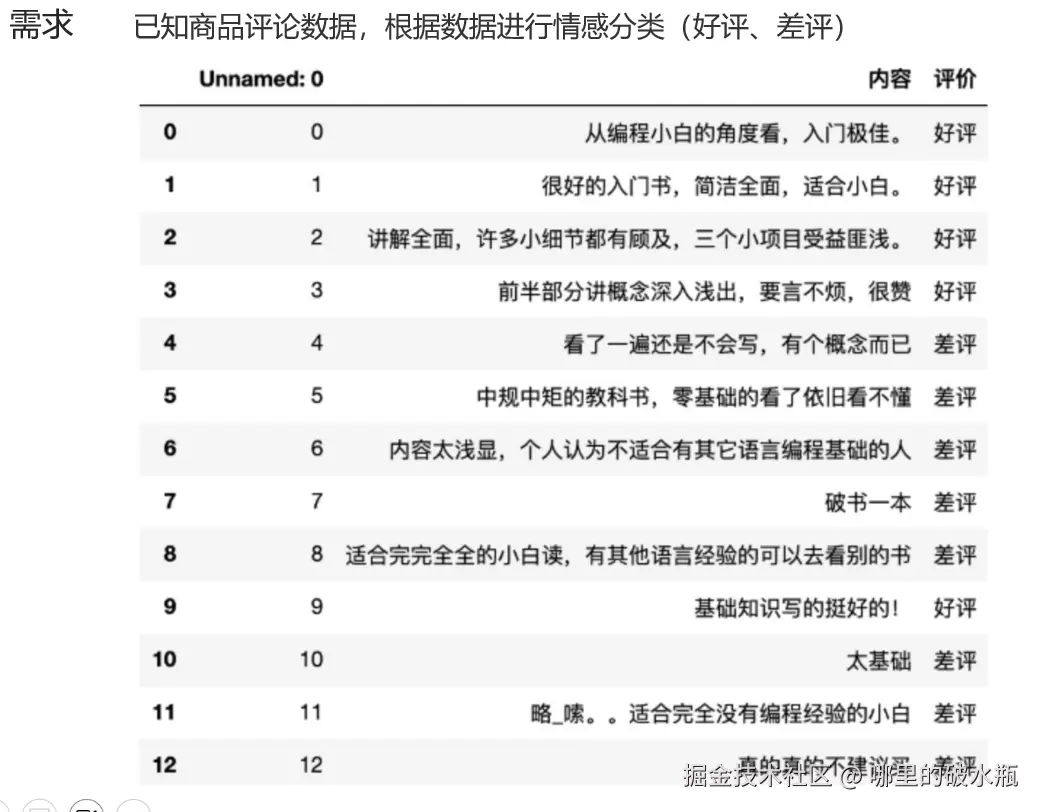
情感分析案例


它属于机器学习的算法一种,主要采用概率来划分分类
py
import jieba
import numpy as np
import pandas as pd
# TODO 1.读取数据
data = pd.read_csv('./书籍评价.csv', encoding="gbk")
# TODO 2.数据预处理
# 增加一列,评价为差评的为0,评价为好评的为1
data['labels'] = np.where(data['评价'] == '差评', 0, 1)
y = data['labels']
# 演示切词
# print(jieba.lcut('我爱你你爱我,蜜雪冰城甜蜜蜜!'))
# 对内容进行切词,去重并放到列表
comment_list = [','.join(jieba.lcut(line)) for line in data['内容']]
# print(comment_list)
# 读取无效词
with open('./stopwords.txt',encoding='utf-8') as f:
# 一次性读取一行
lines = f.readlines()
# 删除每行的换行符,把数据放到列表
stopwords = [line.strip() for line in lines]
# 去重
stopwords = list(set(stopwords))
# TODO 3.向量化处理
# 参数一:停用词列表
transfer = CountVectorizer(stop_words=stopwords)
# 具体的向量化过程,转成列表
x = transfer.fit_transform(comment_list).toarray()
# 打印切词内容
print(transfer.get_feature_names_out())
# TODO 4.训练模型
# 切分数据集和测试集,共 12 个 评论,我们让10个训练集,3个测试集
x_train = x[:10]
y_train = y[:10]
x_test = x[10:]
y_test = y[10:]
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 模型预测
y_predict = estimator.predict(x_test)
print('预测结果:', y_predict)
print(f'模型准确率:{estimator.score(x_test, y_test)}')打印的向量列表,其中1对应列表元素的中的1。
- 例如下图圈的第三个是 1,那么对应列表如下图的第三个。
- 对应的是,《三个》


特征降维
特征降维对原数据有影响
为什么要进行特征降维)?
特征对训练模型时非常重要的;用于训练的数据集包含一些不重要的特征 ,可能导致模型泛化性能不佳
- eg:某些特征的取值较为接近,其包含的信息较少
- eg:希望特征独立存在对预测产生影响,两个特征同增同减非常相关,不会给模型带来更多的信息
特征降维目的
- 指在某些限定条件下,降低特征个数
- 特征降维涉及的知识面比较多,当前阶段常用的方法: 低方差过滤法、PCA(主成分分析)降维法、相关系数(皮尔逊相关系数、斯皮尔曼相关系数)
低方差法
低方差过滤法:指的是删除方差低于某些阈值的一些特征
- 特征方差小:特征值的波动范围小,包含的信息少,模型很难学习到信息
- 特征方差大:特征值的波动范围大,包含的信息相对丰富,便于模型进行学习

机器学习步骤:
- 读取数据
- 数据预处理
- 特征工程(特征提取,特征预处理(归一化,标准化),特征降维,特征提取,特征组合)
- 模型训练
- 模型预测
- 模型评估
特征降维:
- 目的:减少特征,用来降低模型出现过拟合的情况(降低风险)
- 思路:低方差法,会设置一个方差阈值,小于该阈值的列,会被删除掉,只保留区别较大的字段,更容易分析出结果。
py
import pandas as pd
from sklearn.feature_selection import VarianceThreshold
# TODO 1.读取数据,查看维度
df = pd.read_csv('./垃圾邮件分类数据.csv')
print(df.shape) # (971, 25734) (行) -> (列)
# TODO 2.数据预处理
# 创建低方差对象
transfer = VarianceThreshold(threshold=0.01)
# 处理特征,筛选出特征在0.01以上的特征
x_new = transfer.fit_transform(df)
# 打印处理后的维度
print(x_new.shape) # (971, 4347)PCA分析法
不适合大批量的特征。

主成分分析(Principal Component Analysis,PCA)
PCA 通过对数据维数进行压缩,尽可能降低原数据的维数(复杂度)损失少量信息,在此过程中可能会舍弃原有数据、创造新的变量

它属于降维的一种思路,可以接收小数,表示特征的比例,接收整数,表示保留特征的个数。
弊端:PCA不适合处理大批次的特征数据,例如:有几W个特征列。
可以先使用低方差法删除保留的主要特征,然后结合PCA分析法实现。
整数
py
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# TODO:1.获取数据
x, y = load_iris(return_X_y=True)
# TODO:2.创建PCA对象,保留特征
pca = PCA(n_components=2) # 保留2个特征
# TODO:3.训练,得到结果
x_new = pca.fit_transform(x)
# TODO:4.查看结果
print(x_new)小数,保留N分之多少
py
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
# TODO:1.获取数据
x, y = load_iris(return_X_y=True)
# TODO:2.创建PCA对象,保留:n%
pca = PCA(n_components=0.6) # 保留60%
# TODO:3.训练,得到结果
x_new = pca.fit_transform(x)
# TODO:4.查看结果
print(x_new)相关系数
为什么会使用相关系数?
- 相关系数:反映特征列之间(变量之间)密切相关程度的统计指标
- 常见2个相关系数:皮尔逊相关系数、斯皮尔曼相关系数
独立的变量一定不相交,不相交的变量不一定独立
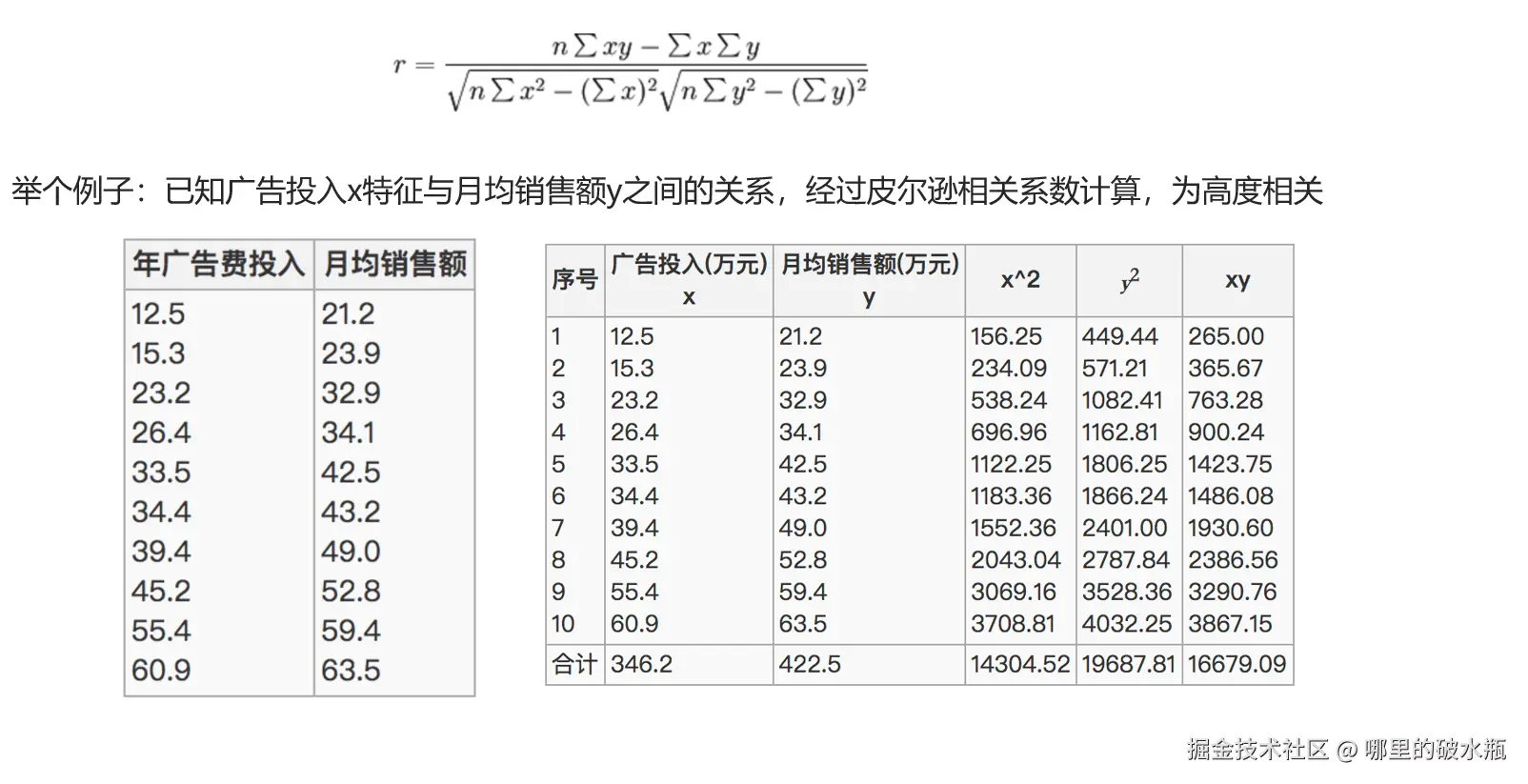
皮尔逊相关系数

作用:反映特征之间关系的密切程度,也就是关系是强还是弱
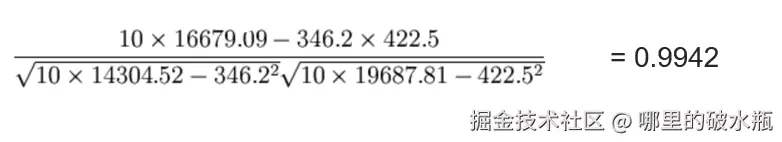
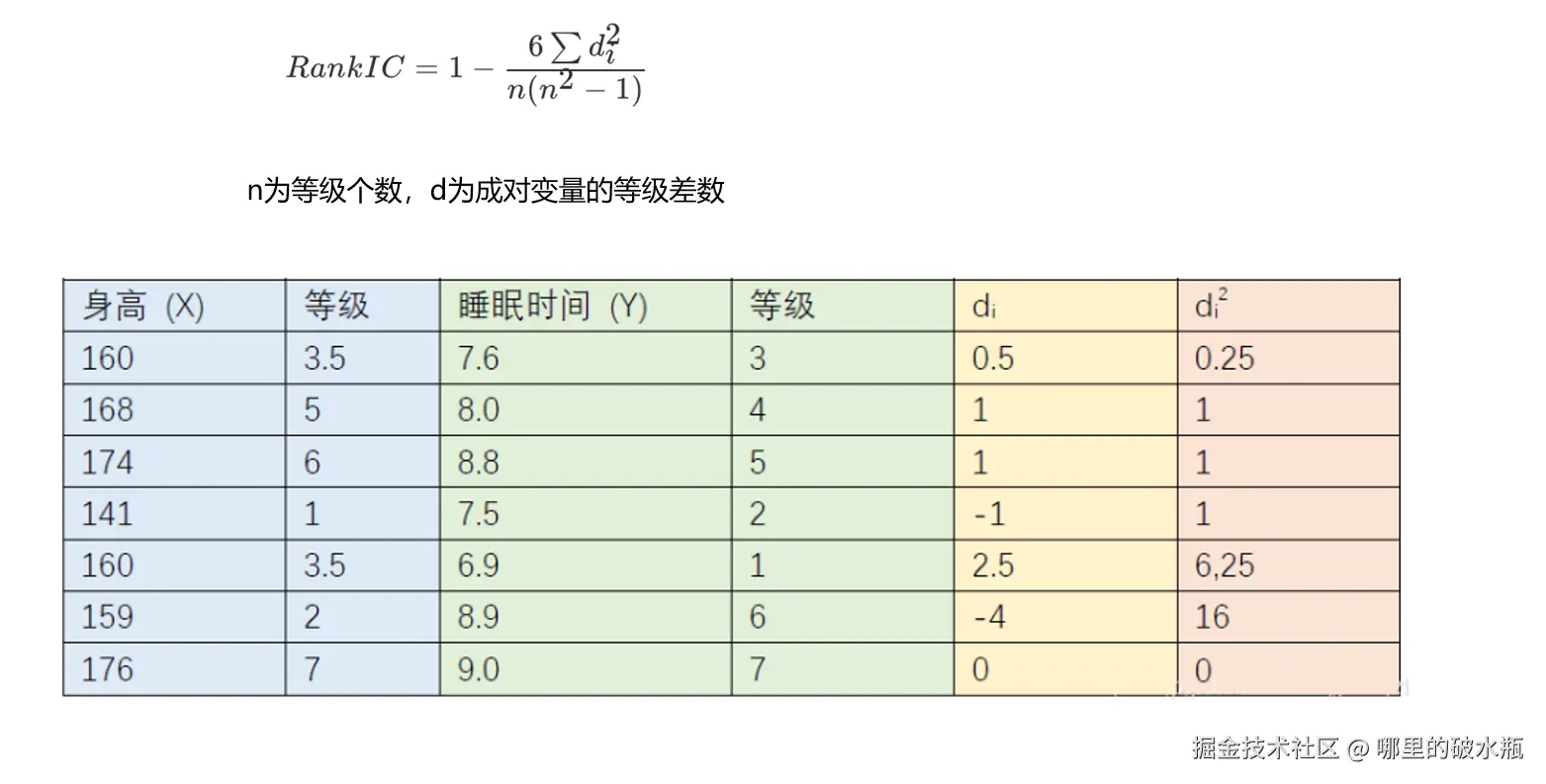
斯皮尔曼相关系数
思路:相关系数法
- 皮尔逊相关系数:计算x的累加和,y的累加和,x*y的累加和,x²的累加和,y²的累加和,繁琐。
- 斯皮尔曼相关系数:通过自定义等级(个数),求实现管理(特征筛选)的动作。
py
from scipy.stats import pearsonr, spearmanr
from sklearn.datasets import load_iris
# TODO:1.读取数据
x, y = load_iris(return_X_y=True)
# 2. x(特征) -> 花萼的长,花萼的宽,花瓣的长,花瓣的宽
# 因为皮尔逊相关系数,斯皮尔曼相关系数,都是计算两个变量之间的相关系数
# 故此,从x(特征)抽取两列,来分析这两列的相关系数
x1 = x[:, 0] # 花萼的长
x2 = x[:, 2] # 花萼的宽
# TODO:3.计算相关系数
# 皮尔逊相关系数:statistic=np.float64(-0.11756978413300204)
# statistic 参数:相关系数
print(f'皮尔逊相关系数:{pearsonr(x1, x2)}')
# 斯皮尔曼相关系数:(statistic=np.float64(-0.166777658283235) 负数,毫无关系
print(f'斯皮尔曼相关系数:{spearmanr(x1, x2)}')

聚类算法
一种典型的无监督学习算法 ,主要用于将相似的样本自动归到一个类别中。
目的是将数据集中的对象分成多个簇(Cluster),使得同一簇内的对象相似度较高,而不同簇之间的对象相似度较低。与分类不同,聚类不需要事先给定类别标签,算法根据数据本身的特征自动地将数据分组。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
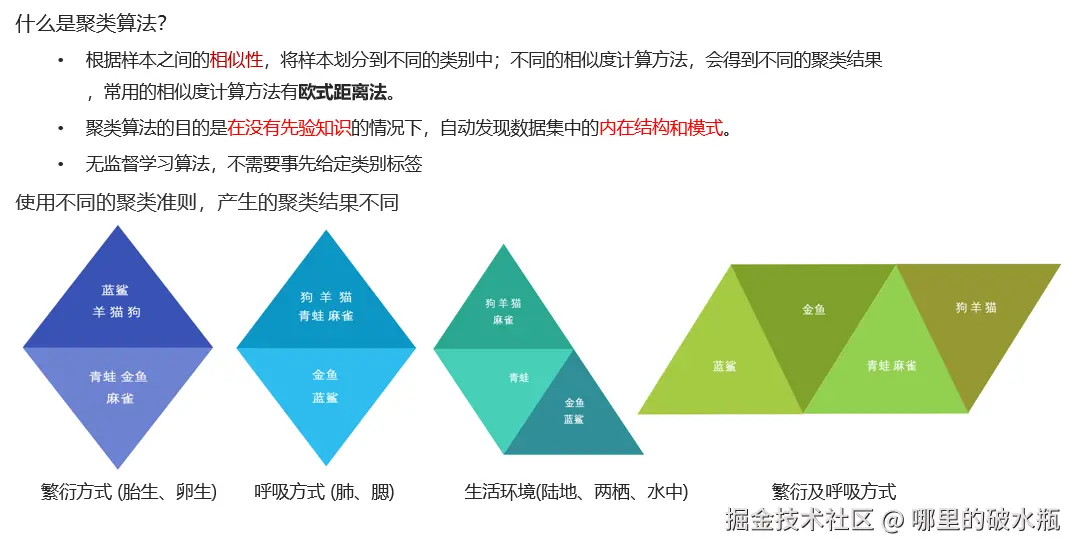
聚类算法在现实中的应用
- 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
- 基于位置信息的商业推送,新闻聚类,筛选排序
- 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
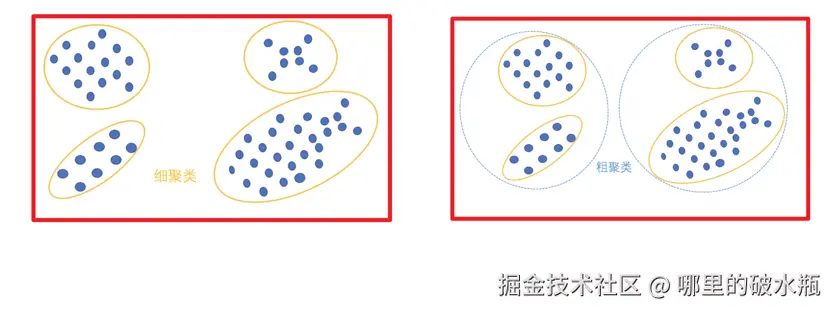
聚类算法分类
根据聚类颗粒度分类
根据实现方法分类
- 划分聚类:按照质心分类,主要介绍K-means,通用、普遍
- 层次聚类:对数据进行逐层划分,直到达到聚类的类别个数
- 密度聚类:按数据点的密度来形成簇,DBSCAN聚类是一种基于密度的聚类算法
- 谱聚类:基于图论的聚类算法,计算数据点之间的相似度矩阵
聚类颗粒度分类:细聚类,粗聚类


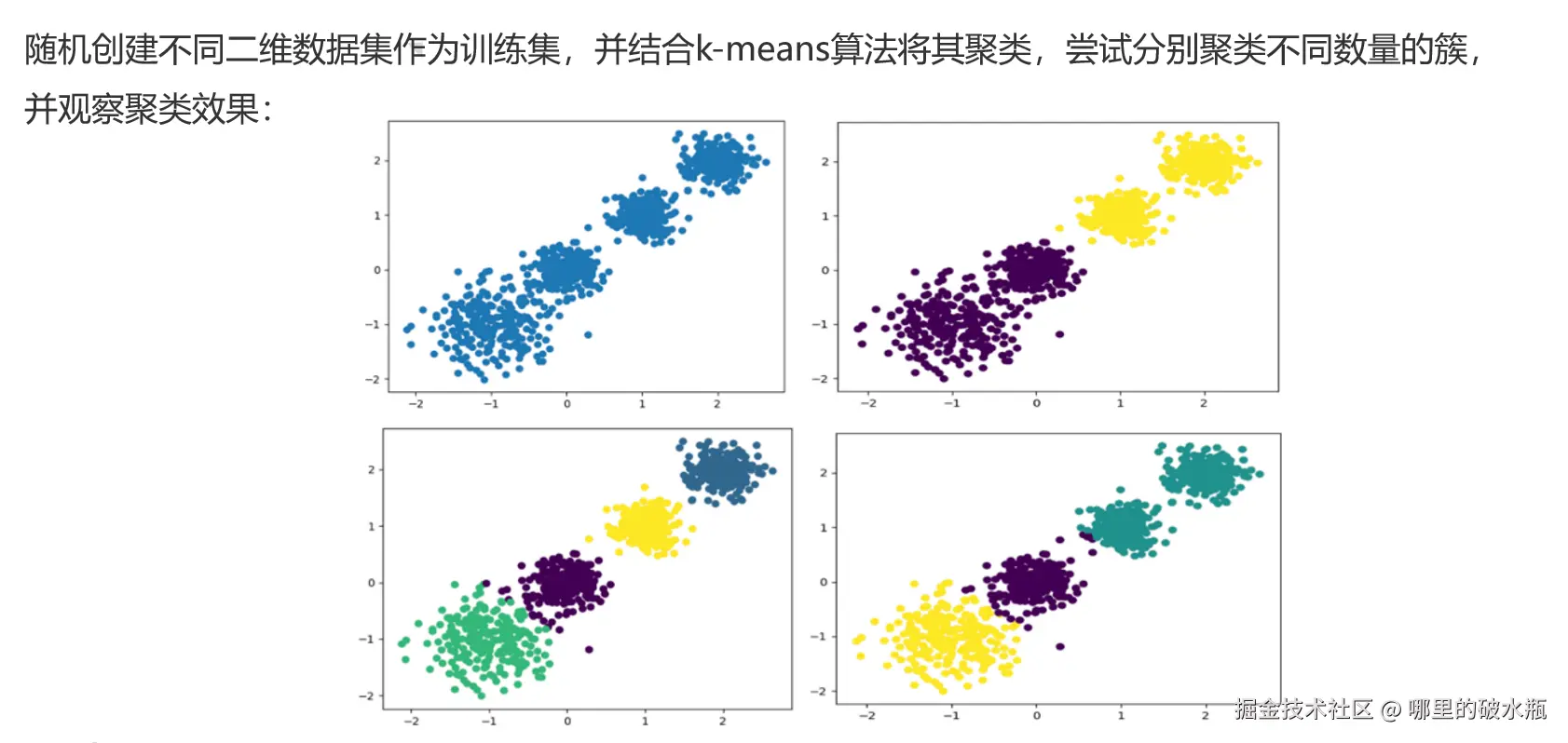
案例:使用KMeans模型数据探索聚类

py
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score
# TODO:1.生成1000个样本数据集
# 生成若干个簇的样本点,每个簇是一个高斯分布(正态分布)
# n_samples:生成样本的个数
# n_features:每个样本有多少个特征
# centers:簇的中心点怎么确定,显式给中心坐标
# cluster_std :每个簇的标准差
# random_state:随机数种子
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
# print(f'查看数据集x:{x}')
# print(f'查看数据集y:{y}')
# TODO:2.绘制样本,marker='o' 圆形,c=y 将颜色设置为y,只有四类
plt.figure(figsize=(8, 8))
plt.scatter(x[:, 0], x[:, 1], marker='o', c=y)
plt.show()
# TODO:3.使用KMeans算法进行聚类,把样本分成 K 个簇
# n_clusters:分成多少个簇,质心数
# random_state:随机数种子
kmeans = KMeans(n_clusters=4, random_state=22)
kmeans.fit(x)
# 进行聚类,返回的簇的编号,这里只有4个簇,所以是0~3
y_predict = kmeans.predict(x)
print(y_predict)
# TODO:4.模型评估,5813.864029456605
print(f'ch-score->{calinski_harabasz_score(x, y_predict)}')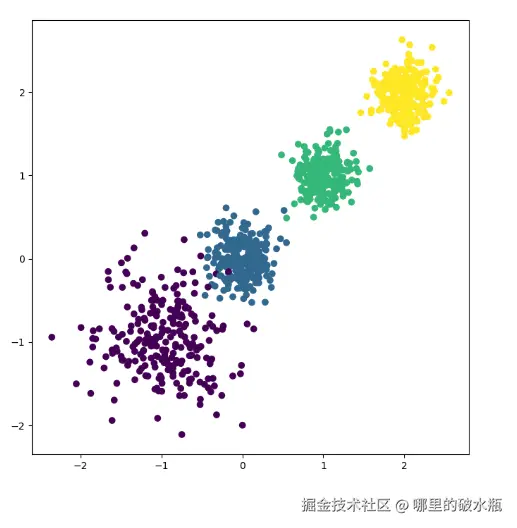
原理
KMeans中的K是类别数,means 是求平均。
- 事先确定常数K,常数K意味着最终的聚类类别数。
K 决定了聚类的类别数,一般由业务方决定,或者评估指标确定最佳的K。
- 随机选择 K 个样本点作为初始聚类中心
默认的init参数是k-means++,第一个质心点是随机选择的,第二个质心点离第一个质心点最远得到点,第三个质心点是离第二个质心点最远的点。
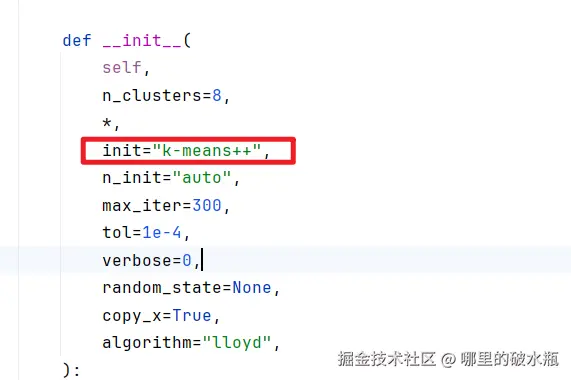
- 计算每个样本到 K 个中心的距离(默认欧式距离),选择最近的聚类中心点作为标记类别
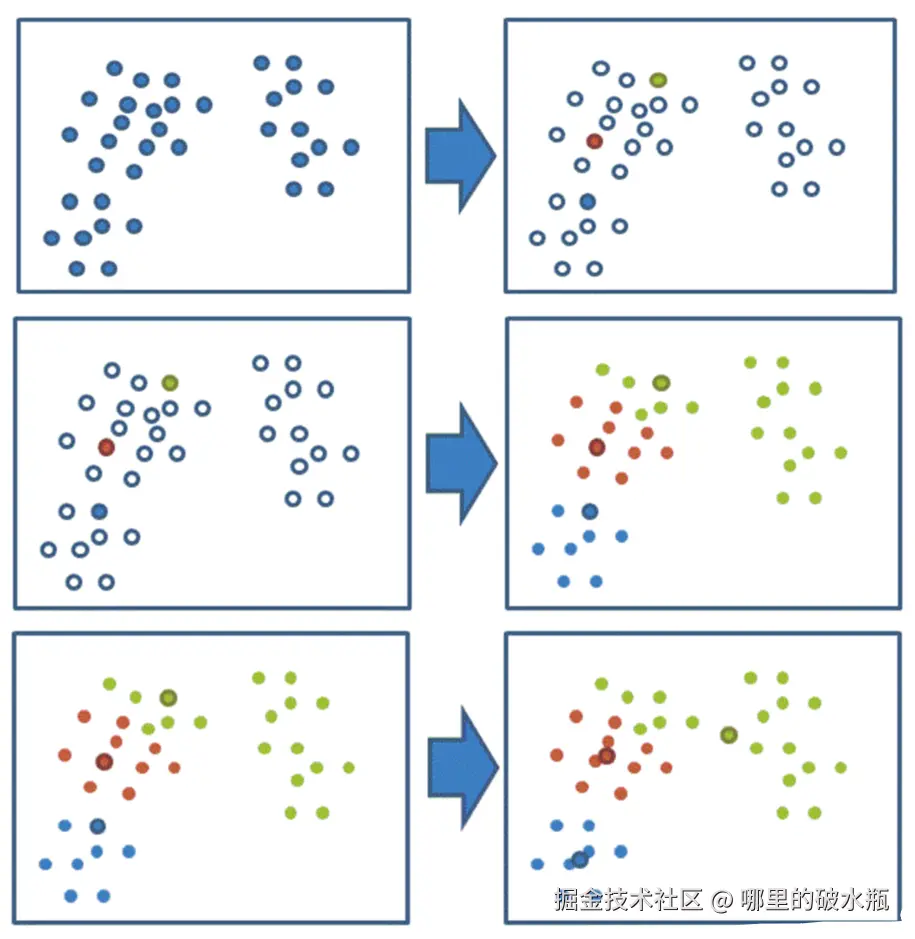
- 根据每个类别中的样本点,重新计算出新的聚类中心点(平均值),如果计算得出的新
- 中心点与原中心点一样则停止聚类,否则重新进行第 3 步过程,直到聚类中心不再变化
其中 total 字段,因为会无限的计算每个点,那怎么结束呢,中心点与原中心点一样则停止聚类。
当 tol=1e-4 从这里设置两个点啥时候可以结束,意思是:当算法的变化小到 0.0001 以内时,就认为已经收敛,可以停了,因此 tol 用来设置阈值,它的优先级高。
max_iter=300 迭代次数,最多迭代300次
总结
- 随机选取K个质心点,选取数据集中的样本点
- 计算每个样本点到K个质心点的距离(默认欧式距离),将未知的样本点划分到距离最小的质心点一类 -> 聚类
- 根据均值计算方法,计算每类的新质心点(每类样本的各特征列求平均),新质心点大概率不是样本(虚拟点)
- 直到新质心点和上一次质心点重合 / 小于指定阈值 / 到达迭代次数后,聚类结束

评估指标
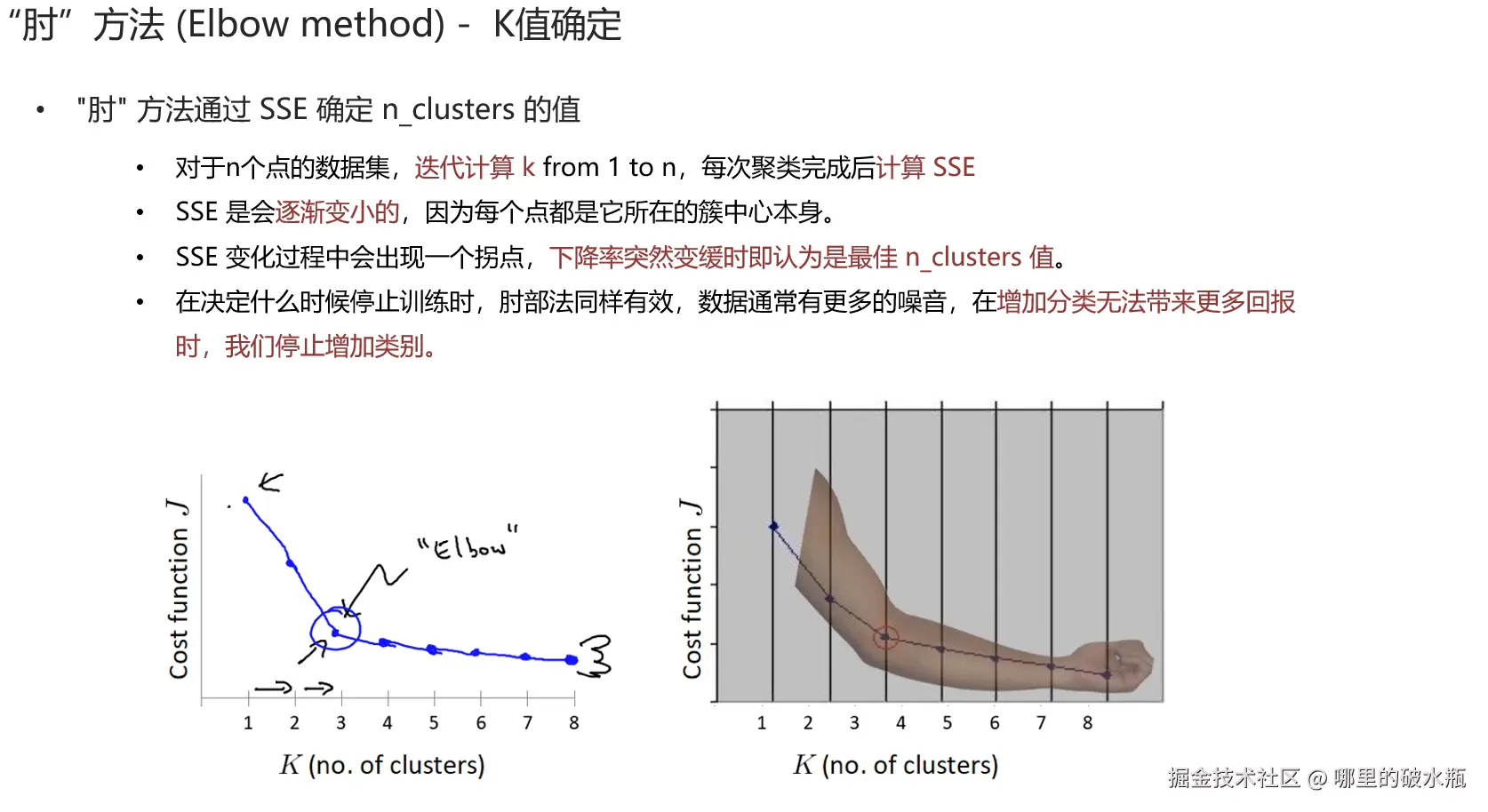
最常用的 SC 聚类评估指标
误差平方和 SSE

K 值确定,肘方法
案例
SSE的值
py
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# TODO: 1.生成1000个样本数据集,每个样本有2个特征,4个簇,四类
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
# TODO: 2.使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=2)
kmeans.fit(x)
# 计算SSE值
print(kmeans.inertia_) # 622.5502142159872,结果是 2 个簇的sse值使用肘部法
py
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# TODO: 1.生成1000个样本数据集,每个样本有2个特征,4个簇,四类
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
sse_list = []
for i in range(2, 100):
# TODO: 2.使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=i)
kmeans.fit(x)
# 计算SSE值
sse_list.append(kmeans.inertia_)
# TODO: 3.绘制肘部图
plt.figure(figsize=(18, 8), dpi=100)
# 设置 X 刻度值
plt.xticks(range(2, 100, 3), labels=range(2, 100, 3))
plt.grid()
plt.title('sse')
plt.plot(range(2, 100), sse_list, 'or-')
plt.show()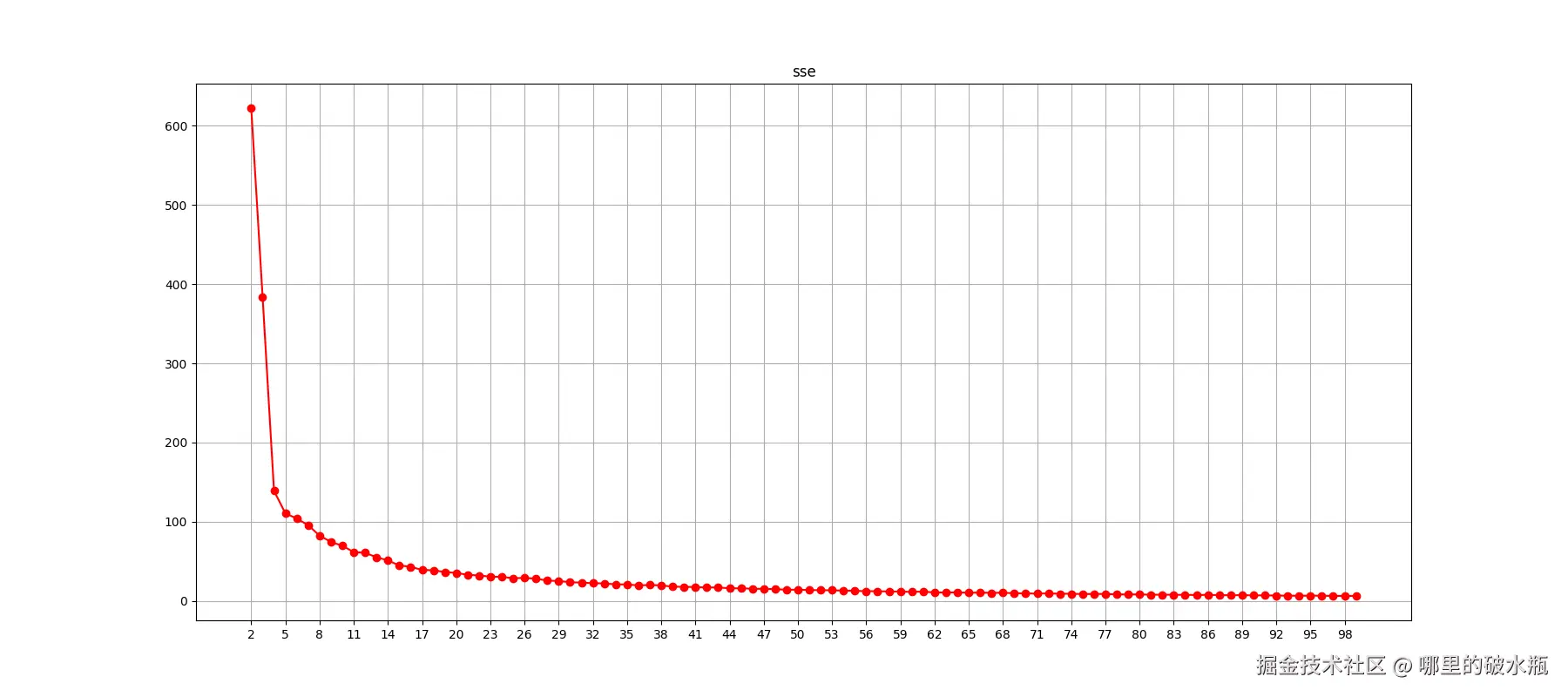
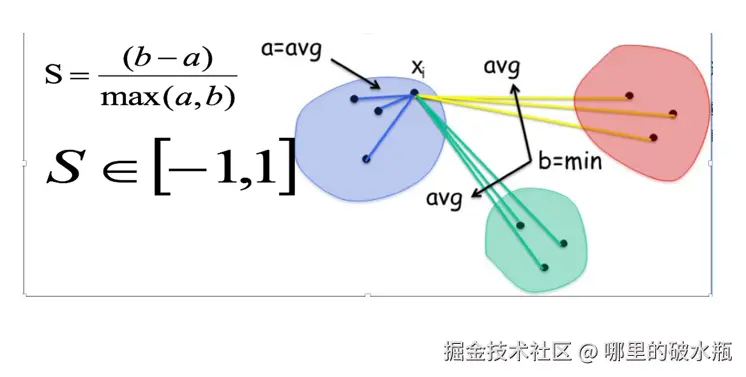
SC 轮廓系数法(重要)

案例,使用轮廓系数
py
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
# TODO: 1.生成1000个样本数据集,每个样本有2个特征,4个簇,四类
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
sse_list = []
for i in range(2, 100):
# TODO: 2.使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=i)
kmeans.fit(x)
# 预测 Y 值
y_pred = kmeans.predict(x)
# TODO: 获取轮廓系数
score = silhouette_score(x, y_pred)
sse_list.append(score)
# ch 系数
# ch_score = calinski_harabasz_score(x, y_pred)
# TODO: 3.绘制肘部图
plt.figure(figsize=(18, 8), dpi=100)
# 设置 X 刻度值
# plt.xticks(range(2, 100, 3), labels=range(2, 100, 3))
plt.grid()
plt.title('sse')
plt.plot(range(2, 100), sse_list, 'or-')
plt.show()- S = (b-a)/max(a,b)
- a: 簇内的平均误差 误差->距离
- b: 簇外最近簇的平均误差
- 取值范围是-1, 1, 越接近1, 聚类效果越好
ch 系数 / 总结



- CH = SSB/SSW * (m-k)/(k-1)
- SSB: 簇外所有簇的误差和
- SSW: 簇内的误差和
- (m-k)/(k-1): 乘法系数, 如果没有乘法系数,K越大聚类效果越好, 有乘法系数限制k值越大
案例:顾客聚类分析
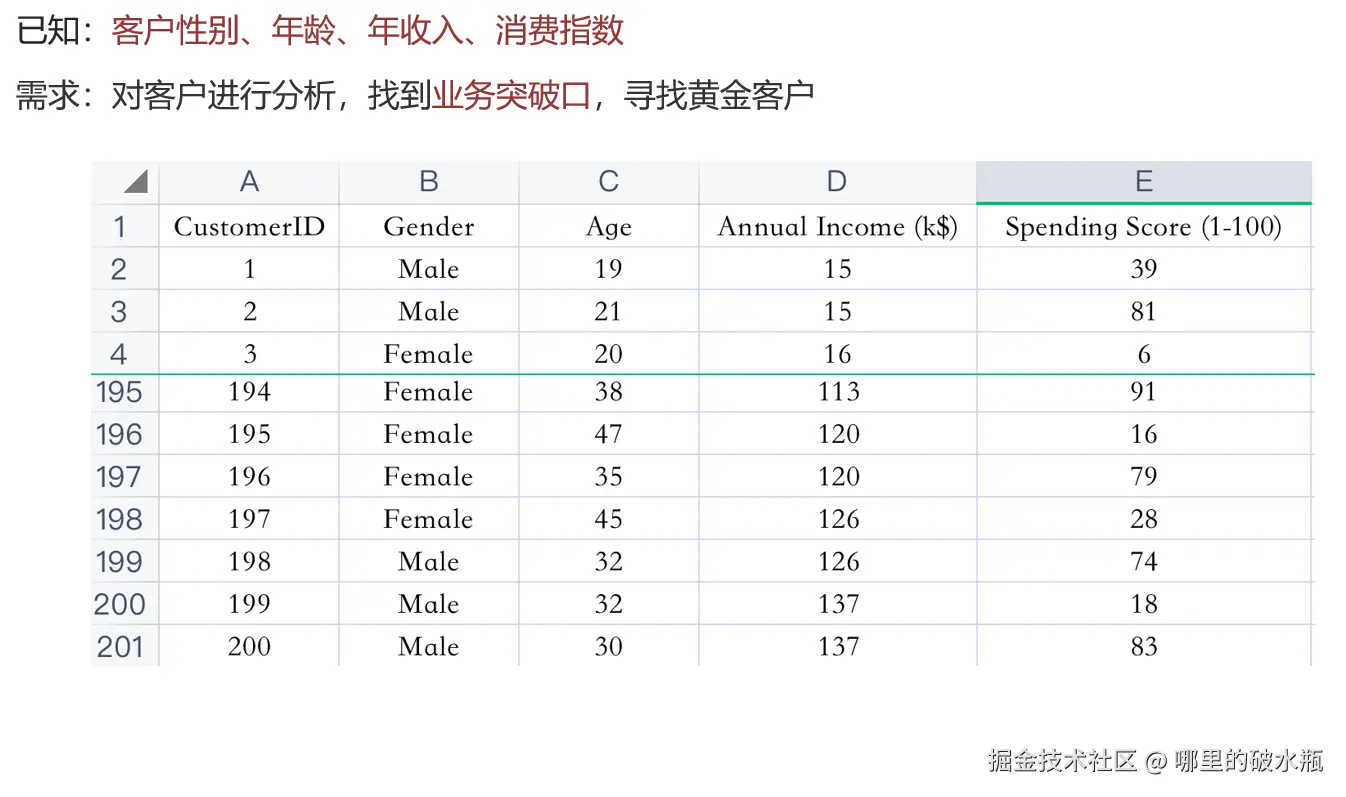
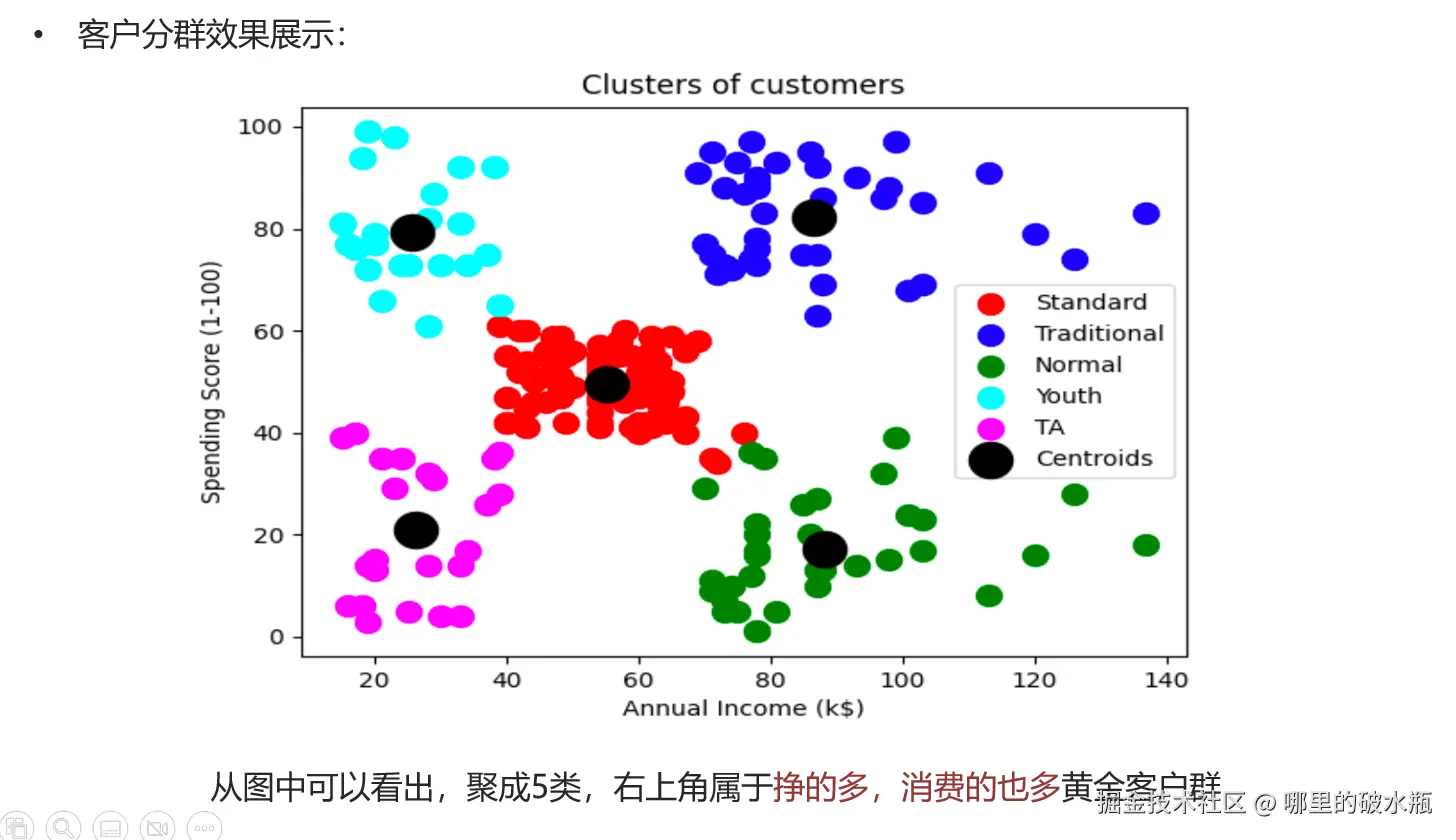
py
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# TODO: 1.加载数据
data = pd.read_csv('./customers.csv')
# TODO: 2.获取进行聚类的特征列
X = data.iloc[:, [3, 4]]
# 实际还需要,标准化处理,特征处理,删除异常值等等
# TODO: 3.使用KMeans算法进行聚类,绘制肘部图/SC系数图
sse_list = []
sc_list = []
for i in range(2, 11):
# 创建KMeans模型
kmeans = KMeans(n_clusters=i, random_state=22)
# 调用kmeans对象的fit训练
kmeans.fit(X)
y_predict = kmeans.predict(X)
# 计算sse值
sse_list.append(kmeans.inertia_)
# 计算sc值
sc_list.append(silhouette_score(X, y_predict))
plt.plot(range(2, 11), sse_list)
plt.title('the elbow method')
plt.grid()
plt.show()
plt.title('sh')
plt.plot(range(2,11), sc_list)
plt.grid()
plt.show()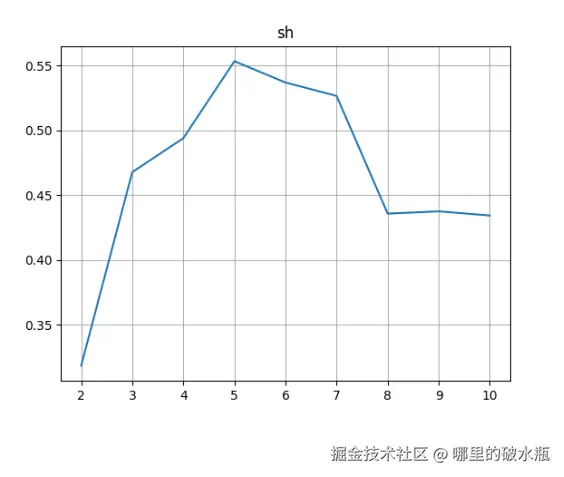
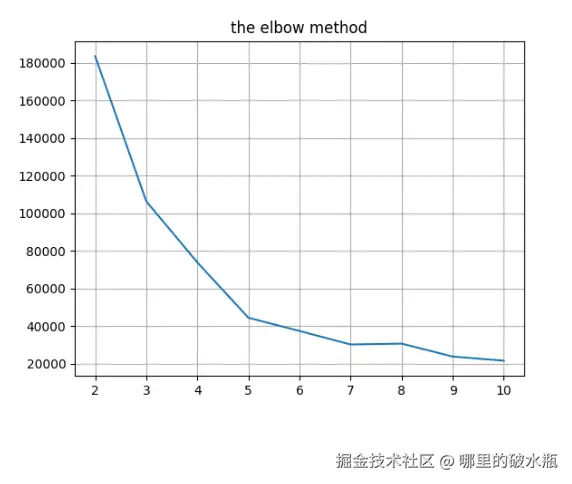
根据最佳的K值进行聚类
上图已经知道峰值最高的sh是5。
py
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
# TODO: 1.加载数据
data = pd.read_csv('./customers.csv')
# TODO: 2.获取进行聚类的特征列
X = data.iloc[:, [3, 4]]
# 实际还需要,标准化处理,特征处理,删除异常值等等
# TODO: 3.使用KMeans算法进行聚类,绘制肘部图/SC系数图
sse_list = []
sc_list = []
for i in range(2, 11):
# 创建KMeans模型
kmeans = KMeans(n_clusters=i, random_state=22)
# 调用kmeans对象的fit训练
kmeans.fit(X)
y_predict = kmeans.predict(X)
# 计算sse值
sse_list.append(kmeans.inertia_)
# 计算sc值
sc_list.append(silhouette_score(X, y_predict))
# plt.plot(range(2, 11), sse_list)
# plt.title('the elbow method')
# plt.grid()
# plt.show()
#
# plt.title('sh')
# plt.plot(range(2,11), sc_list)
# plt.grid()
# plt.show()
# TODO: 4.使用KMeans模型进行聚类
kmeans = KMeans(n_clusters=5, random_state=22)
y_pred = kmeans.fit_predict(X)
print(f'查看标签:{y_pred}')
# 查看每类的质心点值
print(f'查看质心点:{kmeans.cluster_centers_}')
# 通过可视化分析聚类结果
# y_pred = 0,行数据根据布尔值取值
plt.scatter(X.iloc[y_pred == 0, 0], X.iloc[y_pred == 0, 1], s=100, c='red', label='Standard')
plt.scatter(X.iloc[y_pred == 1, 0], X.iloc[y_pred == 1, 1], s=100, c='blue', label='Traditional')
plt.scatter(X.iloc[y_pred == 2, 0], X.iloc[y_pred == 2, 1], s=100, c='green', label='Normal')
plt.scatter(X.iloc[y_pred == 3, 0], X.iloc[y_pred == 3, 1], s=100, c='cyan', label='Youth')
plt.scatter(X.iloc[y_pred == 4, 0], X.iloc[y_pred == 4, 1], s=100, c='magenta', label='TA')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='black', label='Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()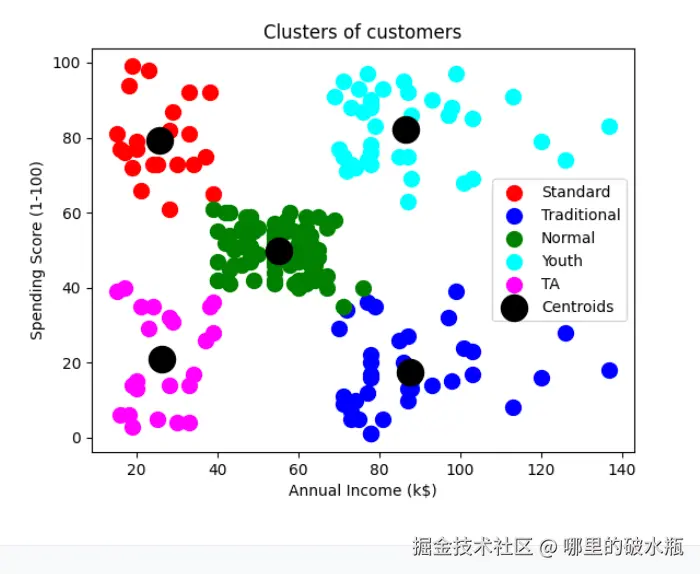
KMeans聚类算法注意点
- 数据集中是否有异常数据
- 异常值
- 特征列量纲异常 标准化 minmaxscaler standardscaler
- 数据集数据量
- 数据量大, 计算时间长
- MinBatchKMeans(n_clusters=, batch_size=)
样本异常数据
K均值(K-Means)是聚类中最常用的方法之一,它基于点与点距离的相似度来计算最佳类别归属。但K均值在应用之前一定要注意两种数据异常:
-
数据的异常值:数据中的异常值能明显改变不同点之间的距离相似度,并且这种影响是非常显著的。因此基于距离相似度的判别模式下,异常值的处理必不可少。
-
数据的异常量纲:不同的维度和变量之间,如果存在数值规模或量纲的差异,那么在做距离之前需要先将变量归一化或标准化。例如,跳出率的数值分布区间是0,1,订单金额可能是0,10000000,而订单数量则是0,1000。如果没有归一化或标准化操作,那么相似度将主要受到订单金额的影响。
样本数据量过大
数据量过大的时候不适合使用KMeans算法
K-Means在算法稳定性、效率和准确率(相对于真实标签的判别)上表现非常好,并且在应对大量数据时依然如此。它的算法时间复杂度上界为 n∗k∗t,其中n是样本量、k是划分的聚类数、t是迭代次数。
当聚类数和迭代次数不变时,K均值的算法消耗时间只跟样本量有关,因此会呈线性增长趋势。
当真正面对海量数据时,使用K均值算法将面临严重的结果延迟,尤其是当K均值被用做实时性或准实时性的数据预处理、分析和建模时,这种瓶颈效应尤为明显。
针对K均值的这一问题,很多延伸算法出现了,MiniBatchKMeans就是其中一个典型代表。
MiniBatchKMeans使用了一个名为Mini Batch(分批处理)的方法计算数据点之间的距离。
MiniBatch的好处是计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本(而非全部样本)作为代表参与聚类算法过程。
由于计算样本量少,所以会相应减少运行时间;但另一方面,由于是抽样方法,抽样样本很难完全代表整体样本的全部特征,因此会带来准确度的下降
经过对30000样本点分别使用KMeans 和 MiniBatchKMeans 进行聚类,对比之后运行时间 MiniBatchKMeans 是 K-Means的一半(0.17 vs 0.36),但聚类结果差异性很小。
结论: MiniBatchKMeans在基本保持了K-Means原有较高类别识别率的前提下,其计算效率的提升非常明显。因此,MiniBatchKMeans是一种能有效应对海量数据,尽量保持聚类准确性并且大幅度降低计算耗时的聚类算法。
能源之星案例
机器学习流程 
能源之星(公用建筑能源利用率预测)
数据查看与清洗
- 类型转换为浮点
- 删除缺失值大于 50%
py
import numpy as np
import pandas as pd
# TODO:1.查看数据
data = pd.read_csv('./Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# print(data.head())
# print(data.shape) # (11746, 60)
# print(data.describe())
# print(data.info())
# print(f'目标值: {data["ENERGY STAR Score"]}')
# TODO: 2.数据清洗
# 替换 Not Available 为空
data.replace('Not Available', np.nan, inplace=True)
# data.info()
# 将类型为 object 转换成数值列
# 需要转换的列,只要包含以下内容,就转换
cols = ['ft²', 'kBtu', 'Metric Tons CO2e', 'kWh', 'therms', 'Score']
for col in data.columns:
# 筛选出包含 cols 中内容,才进行转换
if any(k in col for k in cols):
data[col] = data[col].astype(float)
# TODO: 3.删除缺失值占比50%的列
# 统计每一列缺失值个数是否大于 50%
isnull__sum = data.isnull().sum()
mis_val_percent = isnull__sum / len(data) * 100
# 合并列,并命名
concat = pd.concat([mis_val_percent, isnull__sum], axis=1)
concat = concat.rename(columns={0: '% Missing Values', 1: 'Total Missing Values'})
# 根据缺失值排序
concat.sort_values('% Missing Values', ascending=False, inplace=True)
# 删除缺失值占比超过50%的列
dropIndex = concat[concat['% Missing Values'] > 50].index
data.drop(columns=dropIndex, inplace=True)
print(data.head())EDA 数据分析
对数据进行清晰,描述,查看数据分布,比较数据的关系,培养数据的直觉,进行总结。
- 通过直方图探索目标值y、特征值x数值分布
- 通过四分位距(IQR) 删除异常值
- 通过KDE图探索x和y的关系
- 通过相关系数和散点图计算x和x的相关性
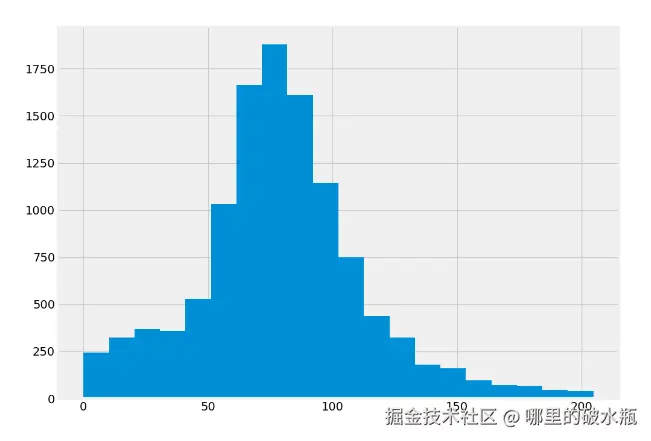
删除异常值
最大值和平均值差异过大。
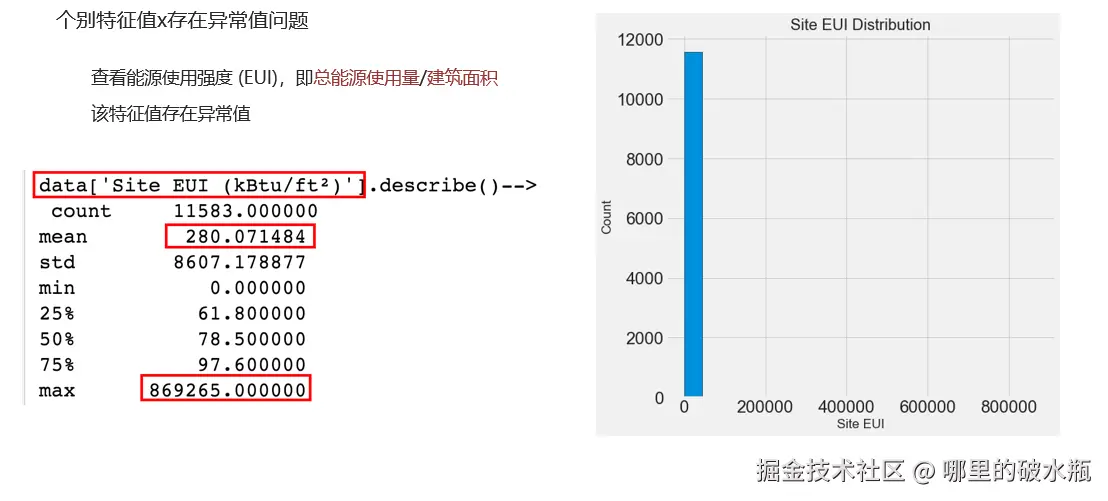
对数据的异常值-解决方法
- IQR = 3/4分位数 - 1/4分位数
- 1/4分位数 - 3IQR 极小值的阈值;小于该阈值数据判断为异常
- 3/4分位数 + 3IQR 极大值的阈值 ;大于该阈值数据判断为异常
处理之前
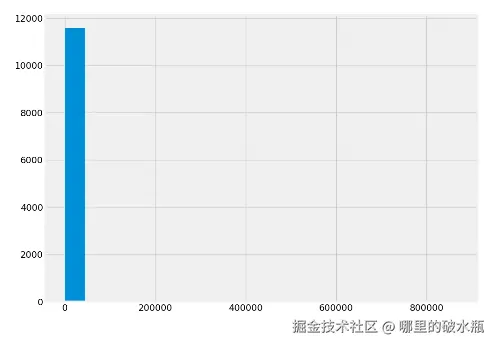
处理之后
完整代码
py
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# TODO:1.查看数据
data = pd.read_csv('./data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# TODO: 4.EDA异常值分析
data.rename(columns={'ENERGY STAR Score': 'score'}, inplace=True)
# print(data.score.describe()) # mean 59.854594 max 100.000000
# Score 字段的直方图
# 设置风格为 数据新闻风格
plt.figure(figsize=(12, 8))
plt.style.use('fivethirtyeight')
# 绘制直方图, bins 分成多少个区间,0~1 有多少个,越多越细致
# plt.hist(data.score.dropna(), bins=100)
# plt.xlabel('Score')
# plt.ylabel('Number of Buildings')
# plt.title('Energy Star Score Distribution')
# plt.show()
# Site EUI (kBtu/ft²) 的异常值
# print(data['Site EUI (kBtu/ft²)'].describe()) # mean 280.071484,max 869265.000000
# plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins=20)
# plt.show()
# TODO: 5.删除异常值,IQR 四分位距方法
# print(data.shape) # (11746, 49)
# 四分位数(Q1), 25% 的数据比这个值小
first_quartile = data['Site EUI (kBtu/ft²)'].quantile(0.25)
# 四分位数(Q3), 75% 的数据比这个值小
third_quartile = data['Site EUI (kBtu/ft²)'].quantile(0.75)
# IQR,表示 中间 50% 数据的跨度
IQR = third_quartile - first_quartile
# 删除异常值,过滤数据子集
d1 = data['Site EUI (kBtu/ft²)']
# first_quartile - 3 * IQR 下限
# third_quartile + 3 * IQR 上限
data = data[(d1 > first_quartile - 3 * IQR) & (d1 < third_quartile + 3 * IQR)]
# print(data.shape) # (11319, 49)
# 重新生成直方图
plt.hist(data['Site EUI (kBtu/ft²)'].dropna(), bins=20)
plt.show()探索特征值x与目标值y关系
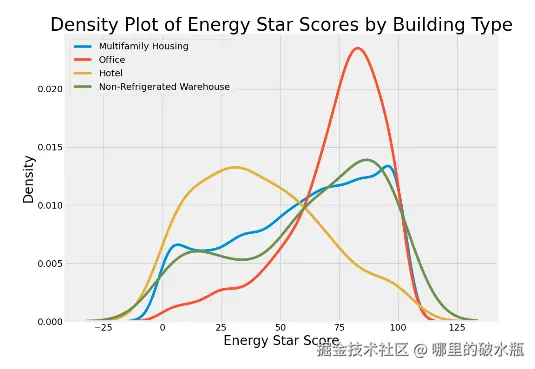
通过 KDE 图来查看特征值 x和特征值 y之间的关系,分析特征x对y的影响
- 可以查看数值型特征对y的影响,也可查看离散型数据对y的影响,KDE 图连续变量中不同数值的概率密度。举个例子:人的身高分布
- 本案例探索最大主业特征 data'Largest Property Use Type' 与y的 KDE图
- 本案例探索自治市镇 data'boroughs'特征与 y之间的关系
- 从图分析:行政区对目标值y的影响没有物业类型大
py
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
# TODO: 6.分析 X 和 Y 的关系
# 删除空值那一行
types = data.dropna(subset=['score'])
# 每个 Largest Property Use Type 特征出现的次数
types = types['Largest Property Use Type'].value_counts()
# 获取出现次数 > 100 的特征值
types = types[types > 100].index
# 绘制 KDE 核密度估计图
for b_count in types:
# 获取每个特征值对应的数据子集
subset = data[data['Largest Property Use Type'] == b_count]
# sns.kdeplot(subset.score.dropna(), label=b_count)
# plt.xlabel('Energy Star Score', size=20)
# plt.ylabel('Density', size=20)
# plt.title('Density Plot of Energy Star Scores by Building Type', size=28)
# plt.legend()
# plt.show()
print('----自治市镇特征列')
# 删除空值那一行
boroughs = data.dropna(subset=['score'])
# 每个 Largest Property Use Type 特征出现的次数
boroughs = boroughs['Borough'].value_counts()
# 获取出现次数 > 100 的特征值
boroughs = boroughs[boroughs > 100].index
# 绘制 KDE 核密度估计图
for b_count1 in boroughs:
# 获取每个特征值对应的数据子集
subset = data[data['Borough'] == b_count1]
sns.kdeplot(subset.score.dropna(), label=b_count1)
plt.legend()
plt.show()小结:
- 通过特征列不同的特征值(离散型特征)和 y 值核密度估计图查看关系
- 同一个分值上不同特征值概率差异大,说明当前特征值和 y 关系紧密。
计算相关性(皮尔逊相关系数)
通过计算皮尔逊相关系数,量化特征(变量)与目标之间的相关性
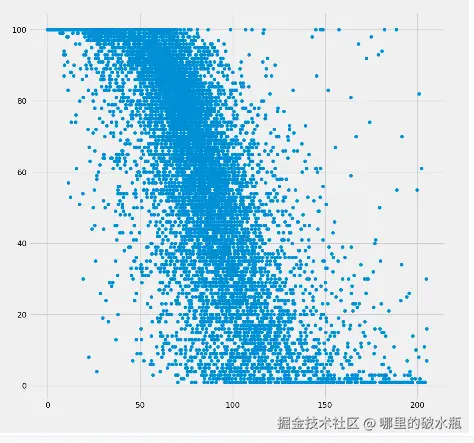
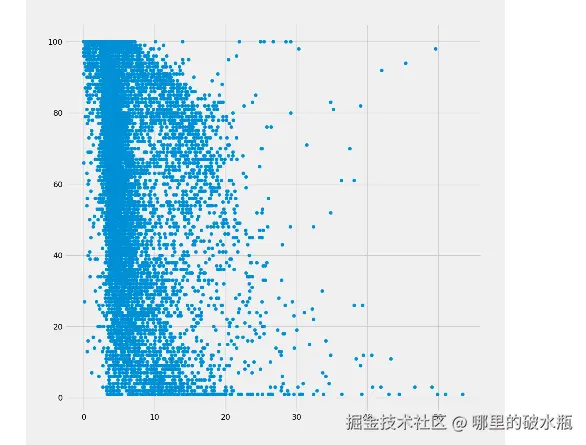
观察数据能源使用强度 (EUI)、站点 EUI (kBtu/ft²)与目标值y最负相关
进一步对相关系数数据进行处理来探索x和y之间是否存在线性关系、非线性关系
探索特征值x与y 方法:是不是存在非线性关系,对每一列x特征求平方根和对数, 然后再观察相关系数前后排名变化
相关性好的
 、
、
相关性不好的
py
print('----皮尔逊相关系数,分析x和y的关系')
# 原始数值特征列和 y 关系分析
# TODO:1.获取数值列,计算相关系数,获取特征列和score列的series对象
# 过滤出所有是数字的列
corr_data = data.select_dtypes(include=np.number)
# corr 计算的是数值型列两两之间的相关系数矩阵,默认用的是 皮尔逊相关系数
# 最终得到一个 N × N 的矩阵, method = 'pearson' 皮尔逊系数
c = corr_data.corr()
# 获取 score 列
score_ = c['score']
score_.to_csv('./score.csv')
# 特征列和y是否存在非线性关系
# 将数值列进行平方根和对数计算,衍生出两个新特征列
# TODO:1.获取数值列
numeric_cols = data.select_dtypes(include=np.number)
# TODO: 2.循环遍历对数值进行平方根和对数计算。衍生出两个新特征列
for cols in numeric_cols.columns:
if cols != 'score':
# 平方根特特征
numeric_cols['sqrt_' + cols] = np.sqrt(numeric_cols[cols])
# 对数特征列
numeric_cols['log_' + cols] = np.log(numeric_cols[cols])
# TODO: 3.获取离散型特征列,和第2步结果放到一起,观察 x 和 y 的非线性关系
categorical_subset = data[['Largest Property Use Type', 'Borough']]
# TODO: 4.离散型特征进行 one-hot 热编码处理
categorical_subset = pd.get_dummies(categorical_subset)
# TODO: 5.将离散型特征列和数值特征列合并到一起
features = pd.concat([numeric_cols, categorical_subset], axis=1)
# TODO: 6.删除score列中包含缺失值的样本
features.dropna(subset=['score'])
# TODO: 7.计算皮尔逊相关系数
# 为什么进行dropna, 因为 corr 会进行 log 计算,产生 nan
corr_data2 = features.corr()['score'].dropna().sort_values()
corr_data2.to_csv('./score2.csv')
# 通过图像观察, x 和 y 的关系---相关性密切
plt.figure(figsize(12, 12))
# plt.scatter(features['Site EUI (kBtu/ft²)'], features['score'])
# plt.show()
# 相关性差
plt.scatter(features['Weather Normalized Site Electricity Intensity (kWh/ft²)'], features['score'])
plt.show()数值列和y之间的线性关系
- df.corr()'score'.sort_values()
数值列+离散列和y之间的非线性关系
- 原始数值列衍生出非线性关系的新特征列
- sqrt 平方根
- log 对数
- 新特征列和y的相关系数 与 原特征列和y的相关系数比较, 系数越大, 说明存在非线性关系
- 离散特征列
- one-hot编码处理
EDA双变量关系探索x和y的关系
- 任意两个特征列和y绘制散点图
- 成对关系图,取多个特征列和y绘图
py
print("------双变量图分析x和y的关系------")
# 通过成对关系图,观察x和y之间是否存在线性关系
print(types)
# 最大物业特征列和EUI能源使用量特征列以及y列关系
# TODO:1.在features df 上添加最大物业特征列
features['Largest Property Use Type'] = data.dropna(subset=['score'])['Largest Property Use Type']
# TODO:2.获取条目数大于100的物业特征值对应的数据子集
# isin(values = [值1,值2], ....),意思是,等于1的样本有多少,等于2的样本有多少
features = features[features['Largest Property Use Type'].isin(types)]
# TODO: 3.绘制散点图
# size 高度,aspect 宽度比
sns.lmplot(x='Site EUI (kBtu/ft²)', y='score', hue='Largest Property Use Type', data=features,
scatter_kws={'alpha': 0.8, 's': 60}, fit_reg=False, height=15, aspect=1.2)
# 调整坐标轴上的标题和标签
plt.xlabel('Site EUI', size=28)
plt.ylabel('Energy Star Score', size=28)
plt.title('Energy Star Score vs Site EUI', size=36)
plt.show()
# 成对关系图
# 实际工作中要取更多的列来绘制成对关系图
plo_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)',
'log_Total GHG Emissions (Metric Tons CO2e)']]
print(plo_data)
# 将 inf 替换成 nan
# np.log(0) -> inf np.log(x),x 非常大,计算内存溢出 -> inf
plo_data = plo_data.replace({np.inf: np.nan, -np.inf: np.nan})
# 重命名列
plo_data = plo_data.rename(columns={'Site EUI (kBtu/ft²)': 'Site EUI',
'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Normalized Source EUI',
'log_Total GHG Emissions (Metric Tons CO2e)': 'log Total GHG Emissions'})
# 去掉缺失值
plo_data = plo_data.dropna()
# 绘制成对关系图
# 创建成对关系图对象
grid = sns.PairGrid(data=plo_data, height=3)
# 右上角绘制散点图
grid.map_upper(plt.scatter, color='red', alpha=0.6)
# 对角线绘制直方图
grid.map_diag(plt.hist, color='red', edgecolor='black')
# 计算相关系数
def corr_func(x, y, **kwargs):
# 根据数据格式把r提取出来 print('\n-->', np.corrcoef(x, y))
r = np.corrcoef(x, y)[0][1]
# Get Current Axes,获取当前坐标轴, 如果没有会创建新的坐标轴
ax = plt.gca()
# 在图形的指定位置添加文本注释
# xy:文本注释的位置, x轴位置是 20% 处, y轴位置是 80% 处
# xycoords:ax.transAxes 坐标系是基于轴的坐标系(轴坐标系),即 xy=(0, 0) 是坐标轴的左下角,xy=(1, 1) 是右上角
ax.annotate('r={:.2f}'.format(r), # 数据2位小数
xy=(.2, .8), xycoords=ax.transAxes,
size=20)
grid.map_lower(corr_func)
grid.map_lower(sns.kdeplot, cmap="Reds")
# 设置标题
plt.suptitle('Pairs Plot of Energy Data', size=36, y=1.02)
plt.show()特征工程
- 仅选择数值变量和两个分类变量(自治市镇和物业使用类型)
- 对数值变量进行对数变换,对类别型特征进行One-hot编码
- 组合上述特征,讨论共线性(也称为多重共线性),删除
共线性:对x和x进行,如果存在很强,就需要删除一个
其他特征工程:数据集划分、数据标准按照正常流程
前提处理代码
py
import numpy as np
import pandas as pd
# TODO:1.查看数据
data = pd.read_csv('./data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv')
# TODO: 2.数据清洗
# 替换 Not Available 为空
data.replace('Not Available', np.nan, inplace=True)
# data.info()
# 将类型为 object 转换成数值列
# 需要转换的列,只要包含以下内容,就转换
cols = ['ft²', 'kBtu', 'Metric Tons CO2e', 'kWh', 'therms', 'Score']
for col in data.columns:
# 筛选出包含 cols 中内容,才进行转换
if any(k in col for k in cols):
data[col] = data[col].astype(float)
# TODO: 3.删除缺失值占比50%的列
# 统计每一列缺失值个数是否大于 50%
isnull__sum = data.isnull().sum()
mis_val_percent = isnull__sum / len(data) * 100
# 合并列,并命名
concat = pd.concat([mis_val_percent, isnull__sum], axis=1)
concat = concat.rename(columns={0: '% Missing Values', 1: 'Total Missing Values'})
# 根据缺失值排序
concat.sort_values('% Missing Values', ascending=False, inplace=True)
# 删除缺失值占比超过50%的列
dropIndex = concat[concat['% Missing Values'] > 50].index
data.drop(columns=dropIndex, inplace=True)
# TODO: 4.EDA异常值分析
data.rename(columns={'ENERGY STAR Score': 'score'}, inplace=True)
# TODO: 5.删除异常值,IQR 四分位距方法
# 四分位数(Q1), 25% 的数据比这个值小
first_quartile = data['Site EUI (kBtu/ft²)'].quantile(0.25)
# 四分位数(Q3), 75% 的数据比这个值小
third_quartile = data['Site EUI (kBtu/ft²)'].quantile(0.75)
# IQR,表示 中间 50% 数据的跨度
IQR = third_quartile - first_quartile
# 删除异常值,过滤数据子集
d1 = data['Site EUI (kBtu/ft²)']
# first_quartile - 3 * IQR 下限
# third_quartile + 3 * IQR 上限
data = data[(d1 > first_quartile - 3 * IQR) & (d1 < third_quartile + 3 * IQR)]特征工程
特征选择和特征衍生
py
# TODO:1.复制data
features = data.copy()
# TODO:2.选择数值特征列 -> 特征选择
numeric_subset = features.select_dtypes(include=np.number)
# TODO: 3.对数值特征列进行对数计算生成新特征 -> 特征衍生
for col in numeric_subset.columns:
if col != 'score':
numeric_subset['log_' + col] = np.log(np.abs(numeric_subset[col]+1))
# TODO: 4.选择离散型特征列 -> 特征选择
categorical_subset = features[['Borough', 'Largest Property Use Type']]
# TODO: 5.对离散型特征列进行热编码,one-hot 编码
categorical_subset = pd.get_dummies(categorical_subset)
# TODO: 6.将数值特征列和离散型特征列合并
features = pd.concat([numeric_subset, categorical_subset], axis=1)下面我们要观察共性,并选择删除
py
# 移除相关特征- 线性相关性画图
plot_data = data[['Weather Normalized Site EUI (kBtu/ft²)', 'Site EUI (kBtu/ft²)']].dropna()
plt.plot(plot_data['Site EUI (kBtu/ft²)'], plot_data['Weather Normalized Site EUI (kBtu/ft²)'],
color='blue', marker='o', linestyle='None')
plt.xlabel('Site EUI')
plt.ylabel('Weather Norm EUI')
plt.title('Weather Norm EUI vs Site EUI')
plt.show()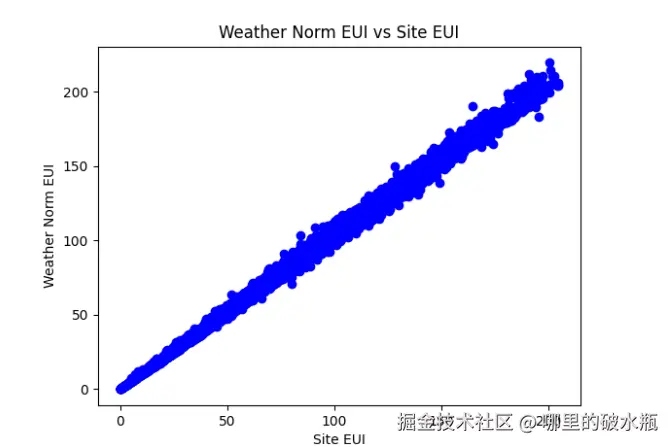
根据图片发现共性特别强,需要删除一列。
删除共线性特征列
py
# TODO:1.将目标值 y 保存起来,分析 x 和 x 之间的线性关系
y = features.score
# TODO:2.获取所有特征列子集
features = features.drop(columns=['score'])
print(features.shape)
# TODO:3.计算x和x之间的相关系数矩阵(对角线就是自己和自己,那完全是一模一样的,肯定是共线性,需要设置0)
# 一列中有多个相关系数,取最大值进行删除
while True:
corr_matrix = features.corr()
# TODO:4.将对角线的系数值1置为0,自己和自己相关性 1
for i in range(len(corr_matrix)):
corr_matrix.iloc[i, i] = 0
# TODO:5.定义空列表,存储待删除的列
drop_cols = []
# TODO:6.遍历相关系数矩阵
for col in corr_matrix.columns:
# 如果不在待删除的列中,则进行处理
if col not in drop_cols:
v = np.abs(corr_matrix[col])
# 是否大于阈值
if np.max(v) > 0.6:
# 获取最大值对应的列名保存到待删除列表中
idx = np.argmax(v)
print(idx)
# 获取列名
name = v.index[idx]
print(name)
drop_cols.append(name)
if drop_cols:
features.drop(columns=drop_cols, inplace=True)
else:
features['score'] = y
break
print(features.shape)数据集划分
py
# TODO:1.删除都为NaN的列
features.dropna(axis=1, how='all', inplace=True)
# TODO:2.删除Score为Nan的行
features.dropna(subset=['score'], inplace=True)
# TODO:3.获取目标值列
targets = pd.DataFrame(data=features['score'])
# TODO:4.删除Score列
features.drop(columns=['score'], inplace=True)
# TODO:5.将features 的数据集中的 -inf/ inf 值替换为 nan
# inf → 正无穷大
# -inf → 负无穷大
features.replace([np.inf, -np.inf], np.nan, inplace=True)
# TODO:6.数据集分割
x_train, x_test, y_train, y_test = train_test_split(features, targets, test_size=0.3, random_state=42)
# TODO:7.数据集保存在文件中
x_train.to_csv(r'./x_train.csv', index=False)
x_test.to_csv(r'./x_test.csv', index=False)
y_train.to_csv(r'./y_train.csv', index=False)
y_test.to_csv(r'./y_test.csv', index=False)缺失值填充归一化
- 获取数据集
- 中位数填充缺失值
- 数据归一化
- 修改目标列形状, 改为一维 (行数,)
py
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
# TODO:1.读取数据集
x_train = pd.read_csv('./x_train.csv')
x_test = pd.read_csv('./x_test.csv')
y_train = pd.read_csv('./y_train.csv')
y_test = pd.read_csv('./y_test.csv')
# print('x_train.shape:', x_train.shape)
# print('x_train 缺失值数量:', x_train.isnull().sum())
# TODO:2.特征列缺失值填充,中位数策略
# 创建缺失值填充其,strategy:填充策略,中位数
imputer = SimpleImputer(strategy='median')
# 训练填充器
imputer.fit(x_train)
# 注意:返回的是array,而不是 dateframe
x_train = imputer.transform(x_train)
x_test = imputer.transform(x_test)
# print('x_train 缺失值数量:', np.sum(np.isnan(x_train)))
# print('x_test 缺失值数量:', np.sum(np.isnan(x_test)))
# TODO:3.特征列归一化
scaler = MinMaxScaler()
scaler.fit_transform(x_train)
scaler.transform(x_test)
# TODO:4.目标列修改形状 原形状(6622, 1) 新形状(6622,)
# values 后取值,返回 numpy 数组
# -1 自动计算,一个参数一个维度,比如二维(-1,2)
y_train = y_train.values.reshape((-1,))
y_test = y_test.values.reshape((-1,))模型训练
查看结果,发现GBDT 回归模型和随机森林回归模型较好。KNN最差。
py
def fit_and_evaluate(x_train, x_test, y_train, y_test, model):
# TODO:1.模型训练
model.fit(x_train, y_train)
# TODO:2.模型预测
y_predict = model.predict(x_test)
# TODO:3.模型评估MAE
return mean_absolute_error(y_test, y_predict)
# 线性回归模型 lr
lr = LinearRegression()
lr_mae = fit_and_evaluate(x_train, x_test, y_train, y_test, lr)
print('lr_mae值:', lr_mae)
# 随机森林回归模型 rfr
rfr = RandomForestRegressor(random_state=60)
rfr_mae = fit_and_evaluate(x_train, x_test, y_train, y_test, rfr)
print('rfr_mae值:', rfr_mae)
# GBDT 回归模型 gbdt
gbdt = GradientBoostingRegressor(random_state=60)
gbdt_mae = fit_and_evaluate(x_train, x_test, y_train, y_test, gbdt)
print('gbdt_mae值:', gbdt_mae)
# KNN 模型 knn
knn = KNeighborsRegressor(n_neighbors=10)
knn_mae = fit_and_evaluate(x_train, x_test, y_train, y_test, knn)
print('knn_mae值:', knn_mae)
# 模型名称和MAE保存到df对象中
model_comparison = pd.DataFrame({'model': ['lr', 'rfr', 'gbdt', 'knn'],
'mae': [lr_mae, rfr_mae, gbdt_mae, knn_mae]})
print(model_comparison)
# 绘制横向柱状图
model_comparison.plot(kind='barh', x='model', y='mae', legend=True, color='red')
plt.ylabel('')
plt.yticks(size=14)
plt.xlabel('MAE Absolute Error')
plt.xticks(size=14)
plt.title('Model Comparison On Test MAE', size=20)
plt.show()
参数调优
思路:先进行粗调,再进行优调
结果的值,和上一步的结果差不多,可以确定是正确的,越靠近0越好。
py
# 调整 GBDT 模型
# TODO:1.设置粗调参数,字典类型
# 循环五次,每次的参数是30棵树,60棵树...
n_estimators = [30, 60, 90, 100, 150]
# 数的最大深度(最终会用n_estimators 的每一个值,去循环,每次的深度如下,也就是1,2,3,4,5)
max_depth = [1, 2, 3, 4, 5]
# 每个叶子节点的最少样本数量
min_samples_leaf = [2, 4, 6, 8]
# 节点分裂需满足的最少样本数量
min_samples_split = [2, 4, 6, 10]
# 训练树模型的时候,想尝试四种 节点分裂规则
# 必须有 100% 的样本
# 按照 平方根策略选择特征去分裂 比如总共有 16 个特征,每次只随机挑 √16 = 4 个特征去考虑分裂
# 节点分裂时,按照 对数策略选择特征去分裂 例如 16 个特征,每次只考虑 log₂16 = 4 个特征
# 不限制节点分裂规则,让树自己决定
max_features = [1.0, 'sqrt', 'log2', None]
param_grid = {'n_estimators': n_estimators,
'max_depth': max_depth,
'min_samples_leaf': min_samples_leaf,
'min_samples_split': min_samples_split,
'max_features': max_features}
# TODO:2.创建 GBDT 模型对象
gbdt = GradientBoostingRegressor(random_state=60)
# TODO:3.参数粗调,随机参数搜索
random_cv = RandomizedSearchCV(estimator=gbdt, param_distributions=param_grid,
cv=4, # 4折交叉验证
n_iter=25, # 25 个参数组合
scoring='neg_mean_absolute_error', # 评估指标,这里是负的 MAE,越接近 0
n_jobs=1, # 1 表示1个核心,-1表示所有
verbose=1, # 打印基本的输出信息
random_state=42 # 随机数种子,保证每次运行结果一致
)
random_cv.fit(x_train, y_train)
# TODO:4.粗调效果
print('GBDT 模型参数结果:', random_cv.cv_results_)
print('GBDT 最优模型:', random_cv.best_params_)
# GBDT 最优模型: {'n_estimators': 150, 'min_samples_split': 4, 'min_samples_leaf': 6, 'max_features': None, 'max_depth': 5}
print('GBDT 最优模型分值:', random_cv.best_score_)
# GBDT 最优模型分值: -9.072070272120516绘制训练集和测试集误差曲线分析精调模型效果
横轴是树的数量,越多越复杂,可以看出,最好的测试集是200。测试集更重要。
数轴是MAE值,越低越好。
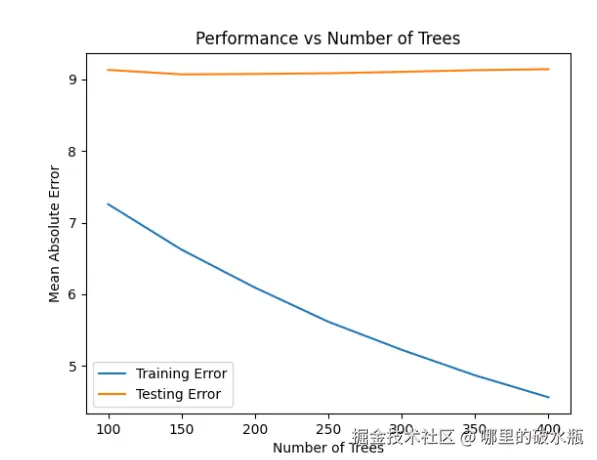
参数精调
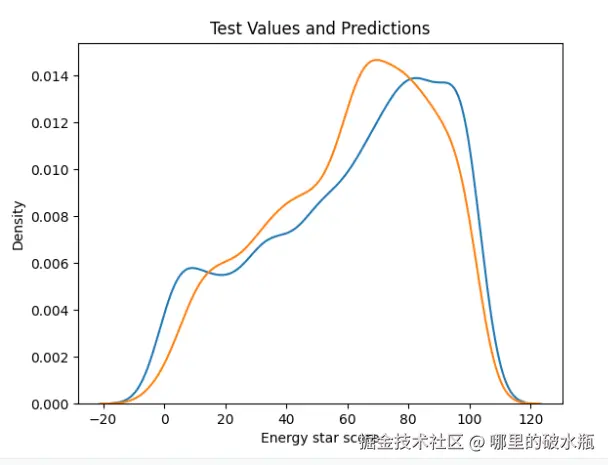
初版GBDT模型和精调版GBDT模型效果对比
越重合说明预测值越接近真实值。
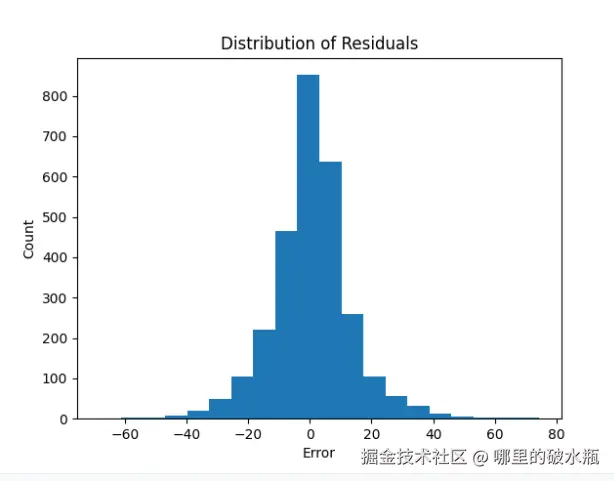
下图,是看误差的,误差等于 0 就是完美。
py
# TODO:1. 设置精调参数
trees_grid = {'n_estimators': [100, 150, 200, 250, 300, 350, 400]}
# TODO:2. 创建粗调后的GBDT模型对象
# {'n_estimators': 150 }
model_gbdt = GradientBoostingRegressor(max_depth=5, min_samples_leaf=6, min_samples_split=4, max_features=None)
# TODO:3.参数精调
grid_cv = GridSearchCV(estimator=model_gbdt, param_grid=trees_grid, cv=4, scoring='neg_mean_absolute_error', n_jobs=1,
verbose=1,
return_train_score=True # 是否在交叉验证过程中,同时返回训练集上的评分结果
)
grid_cv.fit(x_train, y_train)
# TODO:4.绘制训练集和测试集误差曲线分析精调模型效果
results = pd.DataFrame(grid_cv.cv_results_)
plt.plot(results['param_n_estimators'], -results['mean_train_score'], label='Training Error')
plt.plot(results['param_n_estimators'], -results['mean_test_score'], label='Testing Error')
plt.xlabel('Number of Trees')
plt.ylabel('Mean Absolute Error')
plt.legend()
plt.title('Performance vs Number of Trees')
plt.show()
# TODO:5.初版GBDT模型和精调版GBDT模型效果对比
# 创建初版GBDT对象
default_model = GradientBoostingRegressor(random_state=60)
# 获取精调版GBDT模型
final_model = grid_cv.best_estimator_
print('final_model->', final_model)
# 模型训练
default_model.fit(x_train, y_train)
final_model.fit(x_train, y_train)
# 模型预测
# 用 x_test 预测,得到预测值 default_pred,用真实值 y_test 计算误差《外部验证(泛化误差评估)》
default_pred = default_model.predict(x_test)
final_pred = final_model.predict(x_test)
print('默认模型 MAE', mean_absolute_error(y_test, default_pred))
print('精调模型 MAE', mean_absolute_error(y_test, final_pred))
# 查看精调模型的,绘制KDE图 真实值和预测值
sns.kdeplot(y_test, label='values')
sns.kdeplot(final_pred, label='prediction')
plt.xlabel('Energy star score')
plt.ylabel('Density')
plt.title('Test Values and Predictions')
plt.show()
# 绘制直方图,真实值和预测值误差
plt.hist(y_test - final_pred, bins=20)
plt.xlabel('Error')
plt.ylabel('Count')
plt.title('Distribution of Residuals')
plt.show()模型特征解读
取特征重要度分值排名的特征再进行模型训练(简单高效的模型)
- 获取所有特征列的列名
- 训练所有特征的GBDT模型
- GBDT模型获取特征重要分值,取前10特征子集
- 训练所有特征的lr模型/前10特征的GBDT模型,进行对比(一定要简单高效的模型)
py
import pandas as pd
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
from sklearn.preprocessing import MinMaxScaler
def load_features():
# TODO:1.读取数据集
x_train = pd.read_csv('./x_train.csv')
x_test = pd.read_csv('./x_test.csv')
y_train = pd.read_csv('./y_train.csv')
y_test = pd.read_csv('./y_test.csv')
# print('x_train.shape:', x_train.shape)
# print('x_train 缺失值数量:', x_train.isnull().sum())
# TODO:2.特征列缺失值填充,中位数策略
# 创建缺失值填充其,strategy:填充策略,中位数
imputer = SimpleImputer(strategy='median')
# 训练填充器
imputer.fit(x_train)
# 注意:返回的是array,而不是 dateframe
x_train = imputer.transform(x_train)
x_test = imputer.transform(x_test)
# print('x_train 缺失值数量:', np.sum(np.isnan(x_train)))
# print('x_test 缺失值数量:', np.sum(np.isnan(x_test)))
# TODO:3.特征列归一化
scaler = MinMaxScaler()
scaler.fit_transform(x_train)
scaler.transform(x_test)
# TODO:4.目标列修改形状 原形状(6622, 1) 新形状(6622,)
# values 后取值,返回 numpy 数组
# -1 自动计算
y_train = y_train.values.reshape((-1,))
y_test = y_test.values.reshape((-1,))
return x_train, x_test, y_train, y_test
if __name__ == '__main__':
x_train, x_test, y_train, y_test = load_features()
# TODO:1.读取数据集
train_features = pd.read_csv('./x_train.csv')
features_columns = train_features.columns
# TODO:2.训练精调GBDT模型
model_gbdt = GradientBoostingRegressor(max_depth=5, min_samples_leaf=4, min_samples_split=2, max_features=None,
n_estimators=400)
model_gbdt.fit(x_train, y_train)
gbdt_predict = model_gbdt.predict(x_test)
# TODO:3.获取GBDT模型特征重要分,保存到df对象
feature_result = pd.DataFrame({'feature': list(features_columns), 'importance': model_gbdt.feature_importances_})
# TODO:4.根据特征重要分进行降序排序,重置行索引
feature_result.sort_values(by='importance', ascending=False).reset_index(drop=True)
# TODO:5.获取特征重要分前10数据子集(训练和测试集)
# 获取特征重要分前10的特征列名索引下标
most_important_features = feature_result['feature'][:10]
# list.index(x) -> 获取列表中x元素对应的下标
indices = [list(features_columns).index(col) for col in most_important_features]
x_indices = x_train[:, indices]
x_test_indices = x_test[:, indices]
# TODO:6.模型训练 lr gbdt 模型
lr = LinearRegression()
lr.fit(x_train, y_train)
lr_pred = lr.predict(x_test)
lr.fit(x_indices, y_train)
lr_pred_indices = lr.predict(x_test_indices)
print('LR 全部特征模型 MAE', mean_absolute_error(y_test, lr_pred))
print('LR 10个特征模型 MAE', mean_absolute_error(y_test, lr_pred_indices))
gbdt_indices = GradientBoostingRegressor(max_depth=5, max_features=None, min_samples_leaf=4, min_samples_split=2,
n_estimators=200, random_state=42)
gbdt_indices.fit(x_indices, y_train)
gbdt_pred_indices = gbdt_indices.predict(x_test_indices)
print('GBDT 10个特征模型 MAE', mean_absolute_error(y_test, gbdt_pred_indices))
# LR 全部特征模型 MAE 13.430146649249526
# LR 10个特征模型 MAE 15.523677209066797
# GBDT 10个特征模型 MAE 11.340511317432801