高级语法
with语句
文件操作回顾

- 代码说明:
- 文件使用完后必须关闭
- 因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
- 存在的安全隐患
- 这种写法可能出现一定的安全隐患,错误代码如下:
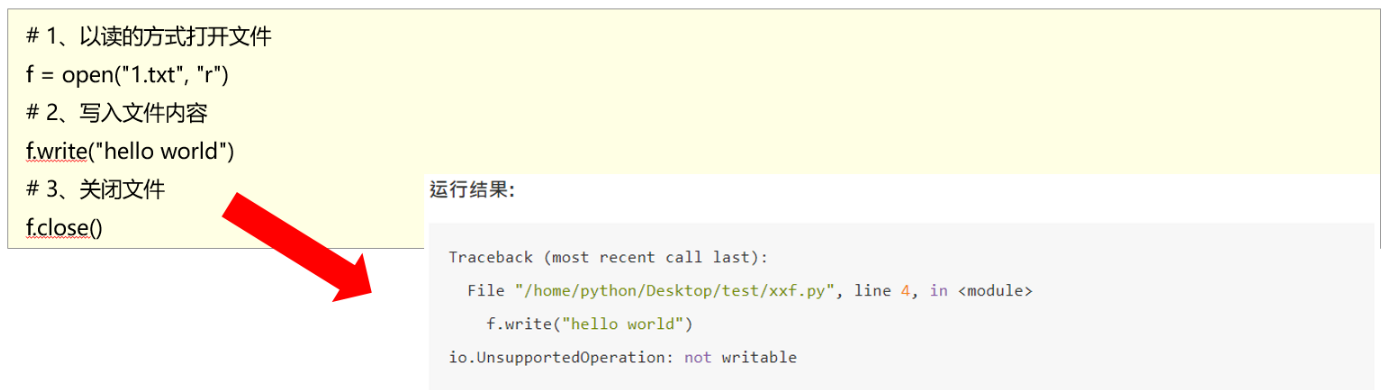
- 由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。
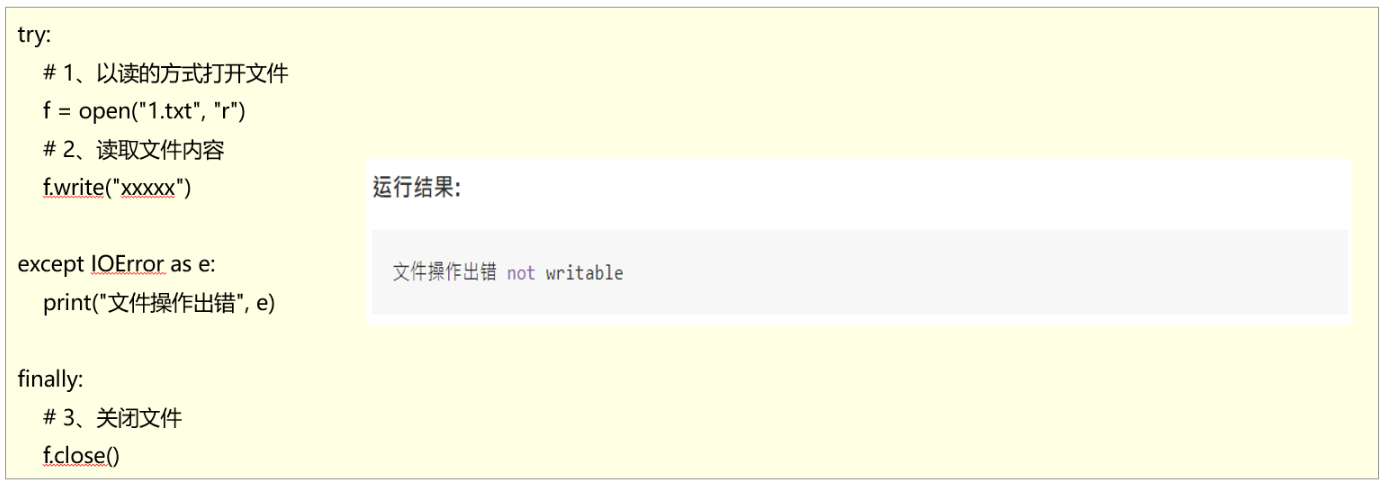
- 为了保证无论是否出错都能正确地关闭文件,我们可以使用try...finally来解决
- try...except...finally 解决文件操作异常
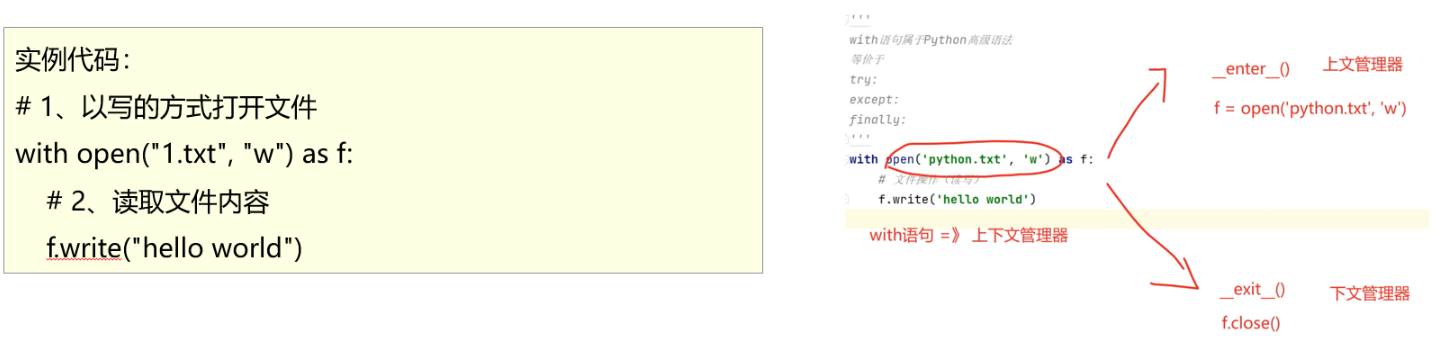
with语句
with语句执行完成后,自动调用关闭文件操作,即使出现异常也会自动调用关闭文件操作
- try-except-finally语句缺点: 代码过于冗长,不易用,易忘
- 上下文管理器with语句: 该机制简单、更安全的处理资源和异常
上下文管理器
一个类只要实现了__enter__()和__exit__()这个两个方法,通过该类创建的对象我们就称之为上下文管理器
- 上下文管理器可以使用with语句
- with语句之所以这么强大,背后是由上下文管理器做支撑的
- 刚才使用open函数创建的文件对象就是就是一个上下文管理器对象。
- 大白话: with管理的对象就是上下文管理器; with xxx as后面的操作的对象就是被管理的对象
- 定义上下文管理器类, 模拟文件操作
- 定义一个File类,实现__enter__()和__exit__()方法
- 然后使用with语句来完成操作文件


- 一个类只要实现了enter和exit这个两个方法,通过该类创建的对象我们就称之为上下文管理器
- enter()表示上文方法,需要返回一个操作文件对象
- exit()表示下文方法,with语句执行完成会自动执行,即使出现异常也会执行该方法
迭代器
什么是迭代器
迭代器(Iterator)是Python中的一种对象,用于在数据集合中逐个访问元素,而不需要暴露数据集合的底层实现。它提供了一种遍历集合元素的标准方式,适用于任何支持迭代的数据结构,如列表、元组等,range()就是一个迭代器
- 迭代器是一个实现了__iter__()和__next()__方法的对象,使得可以逐步遍历它的元素。
- 特点:
- 手动管理: 需要显式地实现__iter__()和__next__()方法。
- 状态管理: 迭代器需要自己管理迭代的状态,包括当前位置和结束条件。
- 内存使用: 内存使用取决于迭代器的实现,通常是惰性计算(即按需生成数据)。
-
示例代码
"""
演示自定义迭代器
概述: 自定义的类,只要重写了__iter__()和__next__()方法, 就可以称为迭代器
目的: 惰性加载, 用的时候才会获取
"""需求: 模拟range(1,6)
for i in range(1, 6):
print(i)自定义迭代器
class MyIterator:
# 重写init魔法方法,初始化属性,指定范围
def init(self, start, end):
self.current_value = start # 当前值, 默认为开始值
self.end = end # 结束值# 重写inter魔法方法, 返回迭代器对象本身 def __iter__(self): return self # 迭代方法, 返回当前值, 并更新当前值 def __next__(self): if self.current_value >= self.end: raise StopIteration # 抛出异常, 迭代结束 value = self.current_value # 保存当前值, 返回给调用者 self.current_value += 1 # 更新当前值 return valuefor i in MyIterator(1, 6):
print(i)
生成器
什么是生成器
根据程序员制定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,可以节约大量的内存。

创建生成器的方式:
- 生成器推导式
- yield关键字
生成器推导式
"""
生成器推导式
"""
# 创建生成器
# 注意1: 括号()代表 这是一个生成器,不是元组
# 注意2: 括号()里面写的是数据生成的规则,返回一个对象
my_generator = (i * 2 for i in range(10))
print(my_generator) # <generator object <genexpr> at 0x000001D4D7597A00>
# next函数获取生成器下一个值
# value = next(my_generator)
# print(value)
# 遍历生成器
for i in my_generator:
print(i)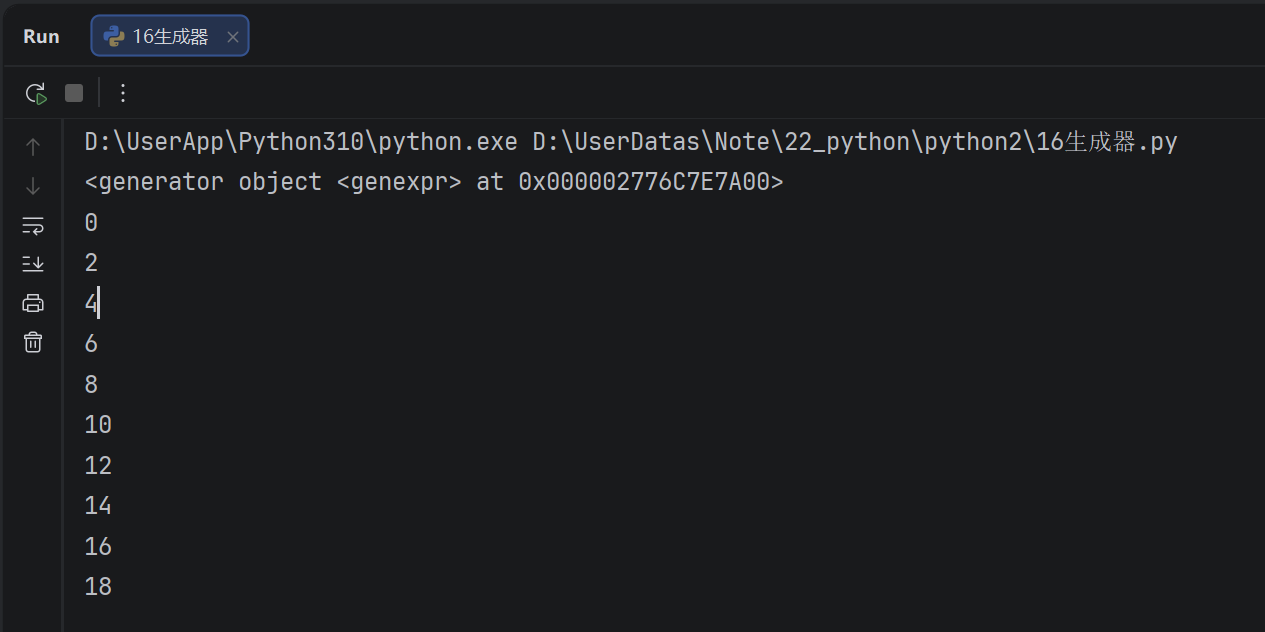
yield生成器
只要在def函数里面看到有yield关键字那么就是生成器
"""
yield生成器
"""
def my_generator(n):
for i in range(n):
yield i
if __name__ == '__main__':
g= my_generator(5)
# 获取生成器的下个值
# result = next(g)
# print(result)
# 遍历生成器
# while True:
# try:
# result = next(g)
# print(result)
# except StopIteration:
# break
# 遍历生成器
# for循环内部自动处理了停止迭代异常,使用起来更加方便
for i in g:
print(i)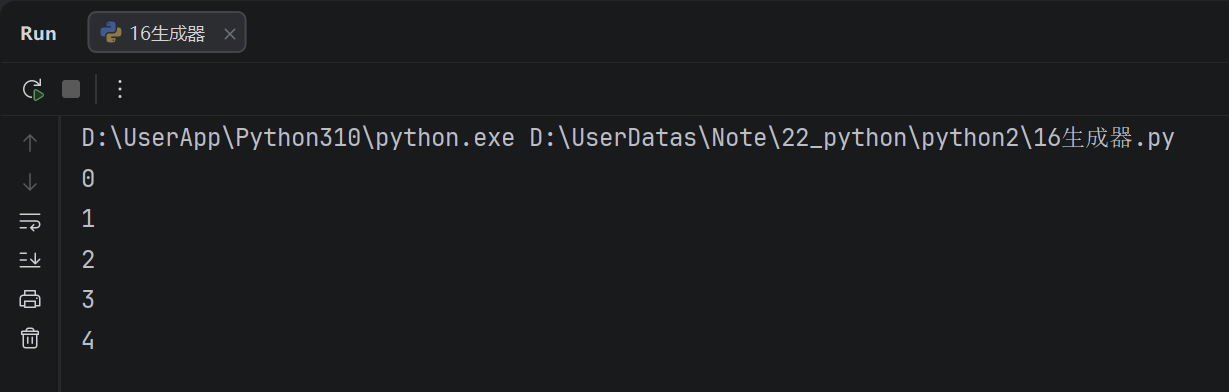
生成器的应用场景-数据迭代器dataloader的封装
-
很多模型都是一个批次一个批次的给模型喂数据,来训练模型的。
-
构建数据迭代器每8个条数据(8个样本)8个数据的给模型喂数据
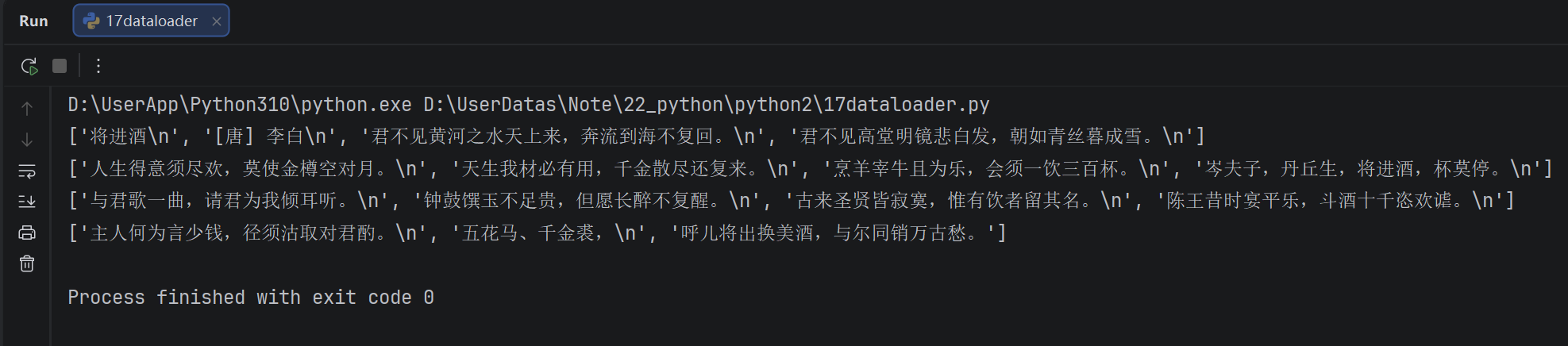
import math
def dataset_loader(bath_size):
# 读歌词
with open('data.txt', 'r', encoding='utf-8') as file:
lines = file.readlines()# 总计歌词总行数 lyrics_number = len(lines) # 计算批次数 batches_number = math.ceil(lyrics_number / bath_size) # 遍历每批数据 for i in range(batches_number): yield lines[i * bath_size : i * bath_size + bath_size]if name == 'main':
for batch in dataset_loader(4):
print(batch)
生成器和迭代器区别?
- 实现方式
迭代器: 需要实现__iter__和__next__方法,手动管理迭代状态。
生成器: 通过yield关键字简化实现,自动管理迭代状态。
- 代码复杂度
迭代器: 通常需要更多的代码来管理状态和迭代逻辑。
生成器: 代码更简洁,更容易理解和维护。
- 性能与内存
迭代器: 性能和内存使用取决于实现,通常也是惰性计算。
生成器: 由于使用了 yield,内存使用和性能优化自动管理,适合处理大数据或流数。
- 使用场景
迭代器: 适合需要对迭代过程进行高度控制,或者需要自定义复杂的迭代逻辑时使用
生成器: 适合需要简洁地生成序列数据,尤其是在处理大数据或需要按需生成数据时,能够节省内存和提高性能
property
property属性的介绍
负责把一个方法当做属性进行使用,这样做可以简化代码使用。
定义property属性有两种方式:
- 装饰器方式
- 类属性方式
装饰器方式
-
@property 修饰获取值的方法
-
@方法名.setter修饰设置值的方法
"""
修饰器方式
"""
class Person:
def init(self, age):
self.__age = age# 获取属性 @property def age(self): return self.__age # 修改属性 @age.setter def age(self, age): self.__age = ageif name == 'main':
p = Person(18)
print(p.age)p.age = 20 print(p.age)
类属性方式
-
类属性=property(获取值方法,设置值方法)
"""
类属性方式
"""
class Person:
def init(self):
self.__age = 0# 获取属性 def get_age(self): return self.__age # 修改属性 def set_age(self, age): self.__age = age # 类属性方式的property属性 (封装操作age的方法) age = property(get_age, set_age)if name == 'main':
p = Person()
print(p.age)p.age = 20 print(p.age)
正则表达式
概述
为什么要学习正则表达式
在实际开发过程中经常会有查找符合某些规则的字符串
比如: 邮箱、图片地址、手机号码等。想匹配或者查找符合某些规则的字符串就可以使用正则表达式了。

什么是正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式
- 比如: 检索一个串是否含有某种子串(检索)
- 比如: 匹配的子串做替换(替换)
- 比如: 从一个串中取出符合某个条件的子串(提取)
- 模式: 一种特定的字符串模式,这个模式是通过一些特殊的符号组成的。
- 正则表达式并不是Python所特有的,在Java、PHP、Go以及JavaScript等语言中都是支持正则表达式的。
- 正则表达式的功能
- 数据验证(表单验证、如手机、邮箱、IP地址)
- 数据检索(数据检索、数据抓取)=>爬虫功能
- 数据隐藏(135****6235王先生)
- 数据过滤(论坛敏感关键词过滤)
re模块的介绍
在Python中需要通过正则表达式对字符串进行匹配时,可使用re模块
re模块使用三步走
- 第一步:导入re模块
- import re
- 第二步: 使用match方法进行匹配操作
- result =re.match(pattern正则表达式, string要匹配的字符串,flags=0)
- flags: 可选,表示匹配模式,比如忽略大小写,多行模式等
- 第三步: 如果数据匹配成功,使用group方法来提取数据
- result.group()
- 示例1
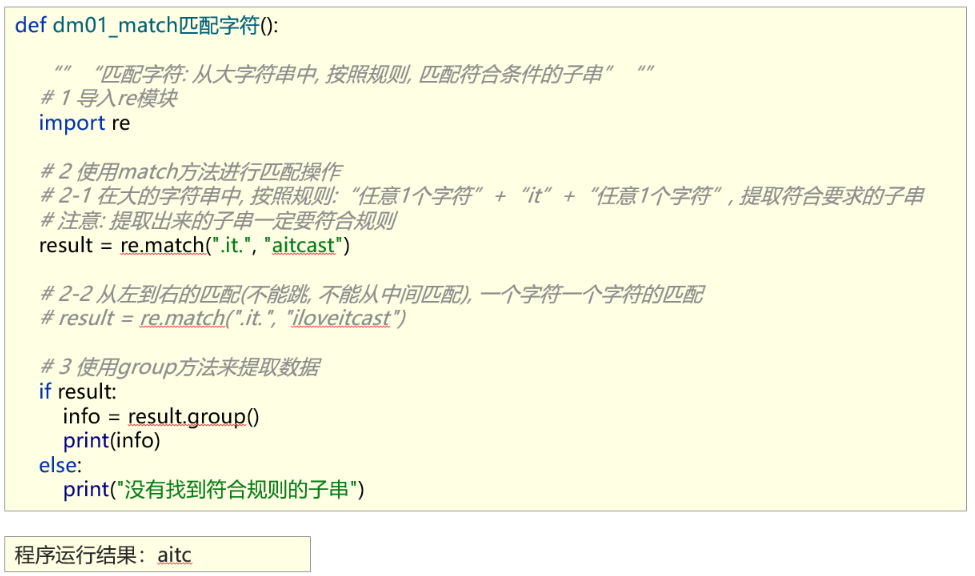
- 示例2

- 示例3
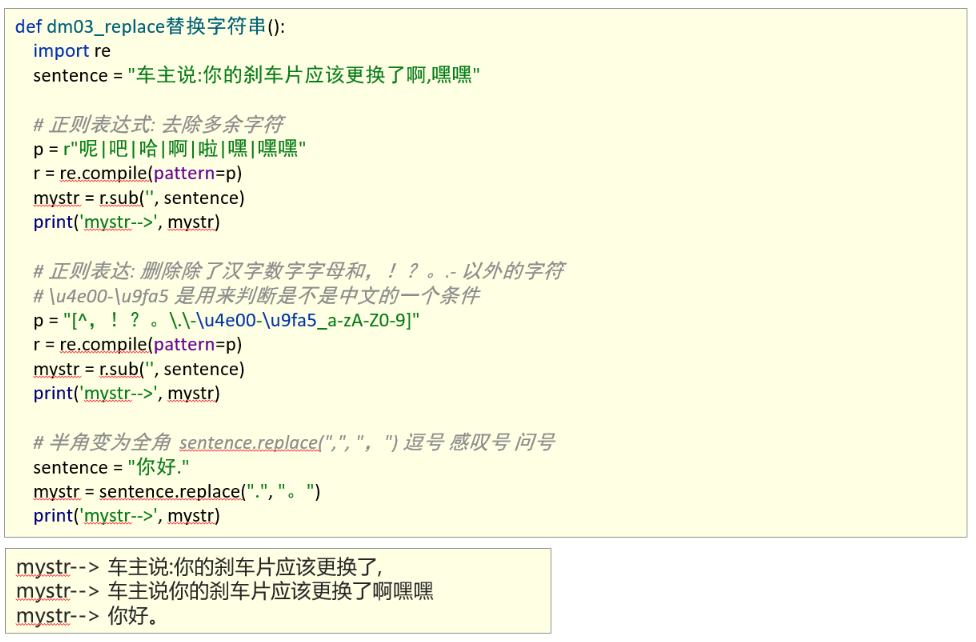
正则表达式编写
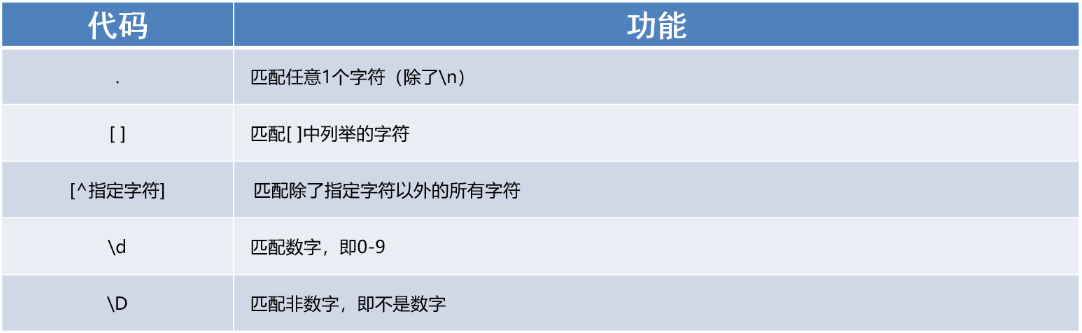
匹配单个字符
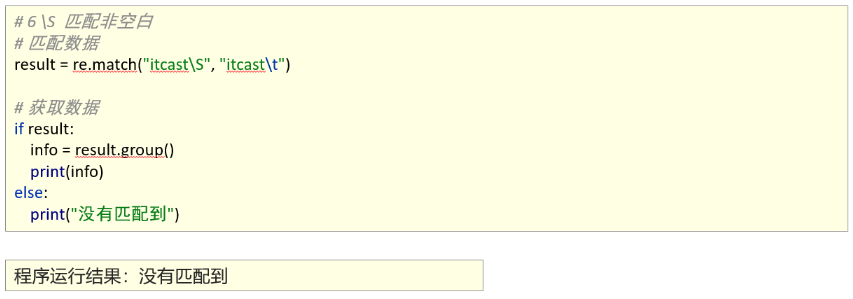
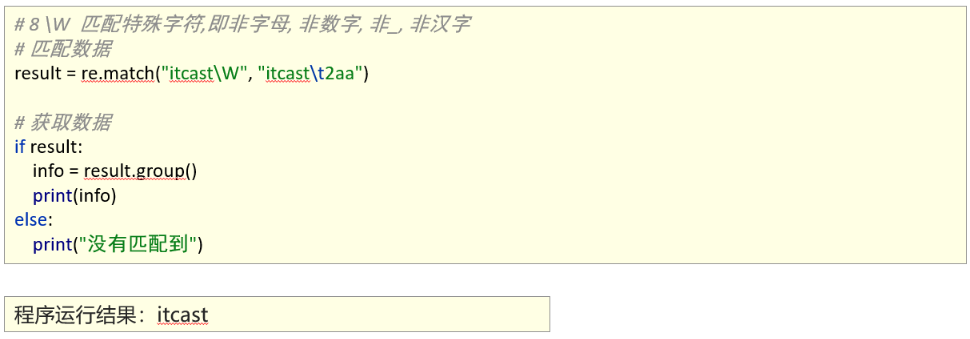
1、能够使用re模块匹配单个字符
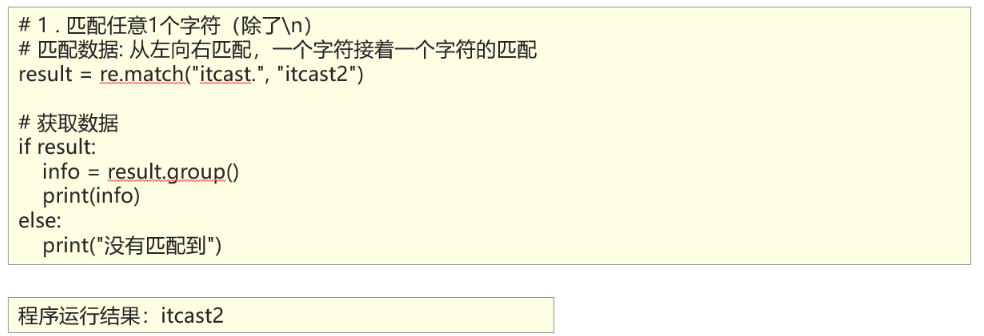
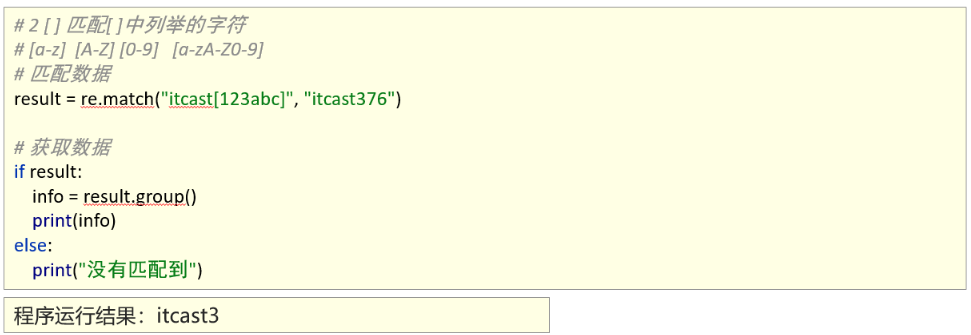
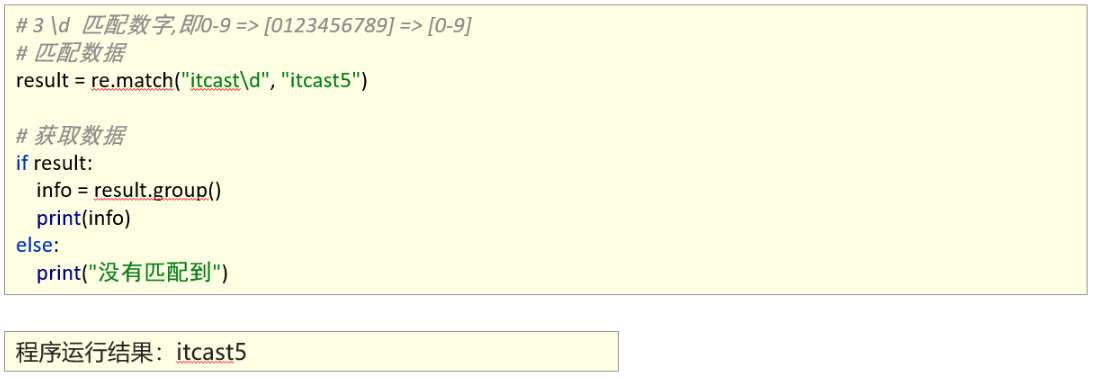
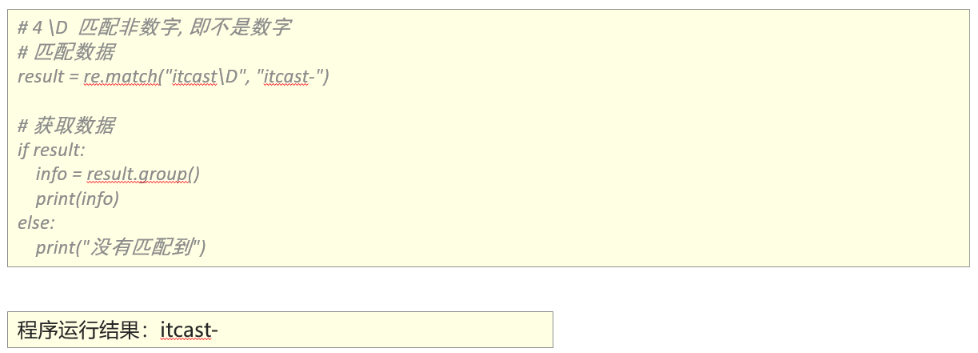
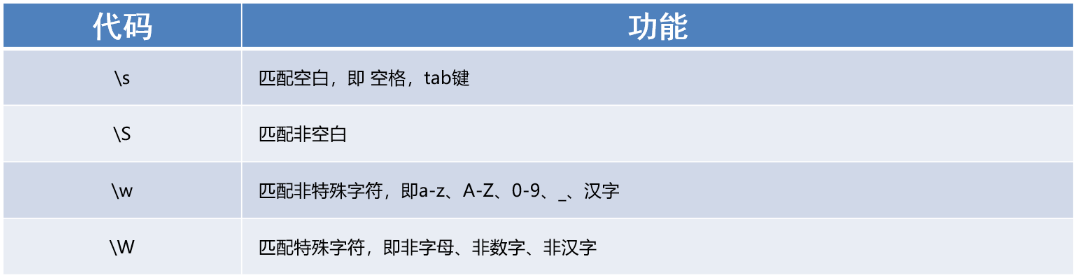
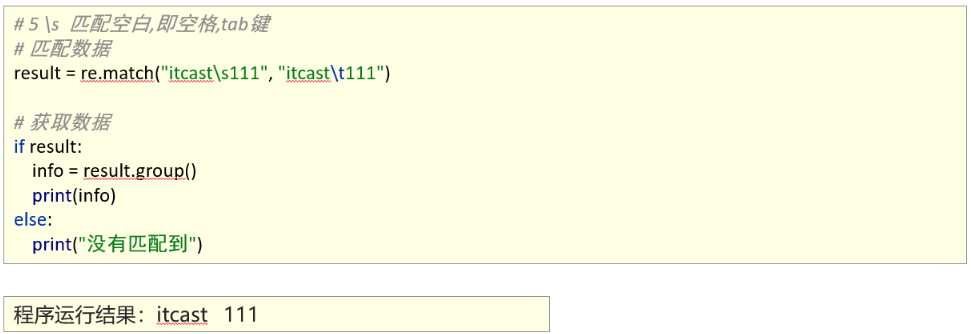
2、能够使用re模块匹配单个字符

匹配多个字符
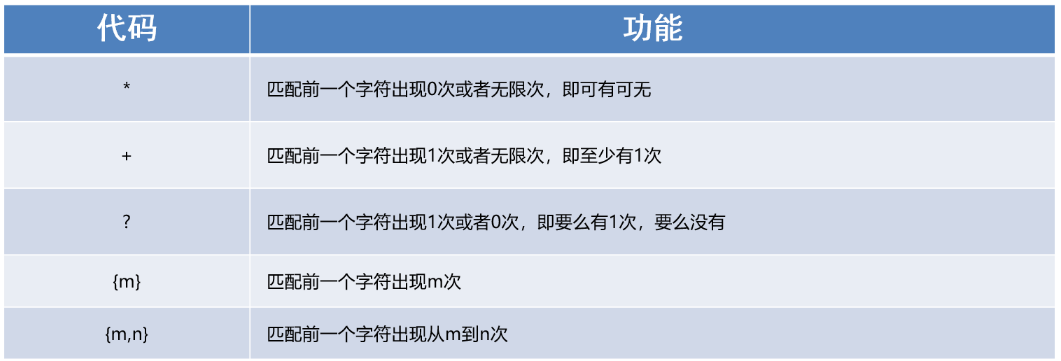
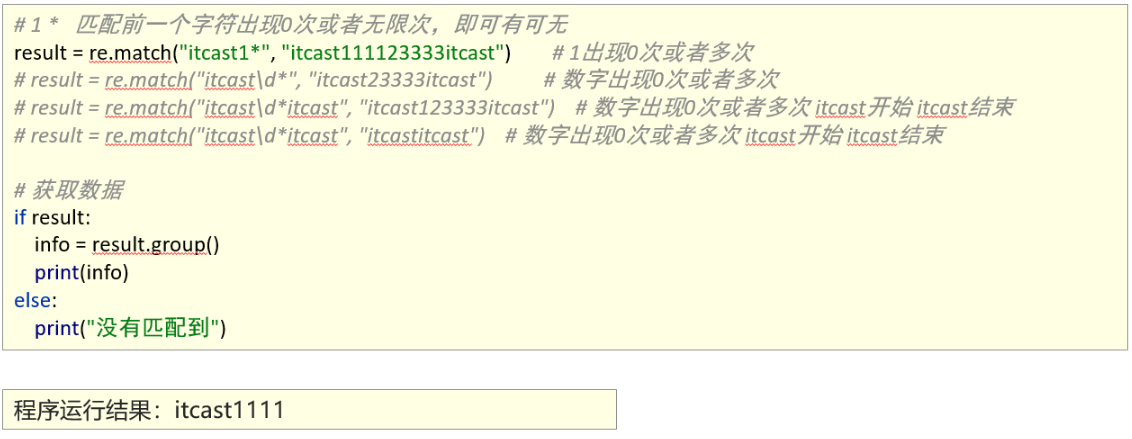
1、能够使用re模块匹配多个字符
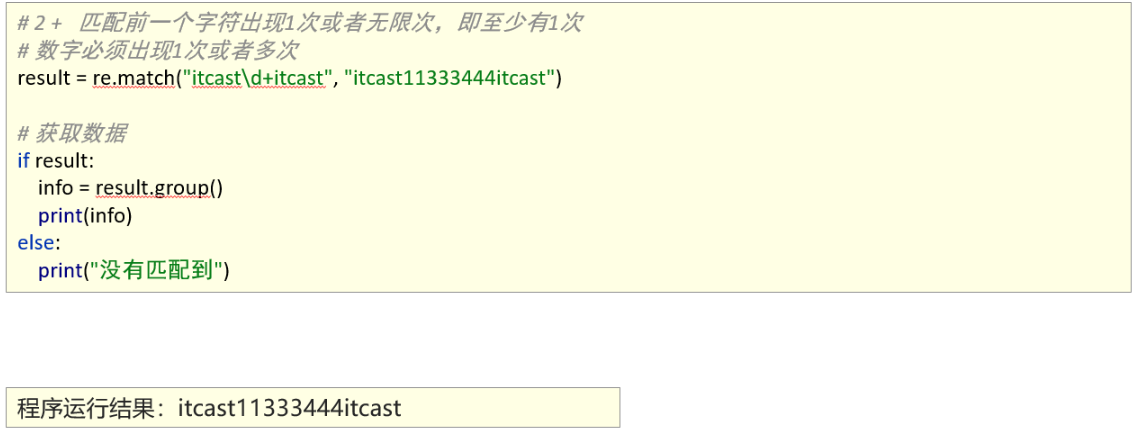
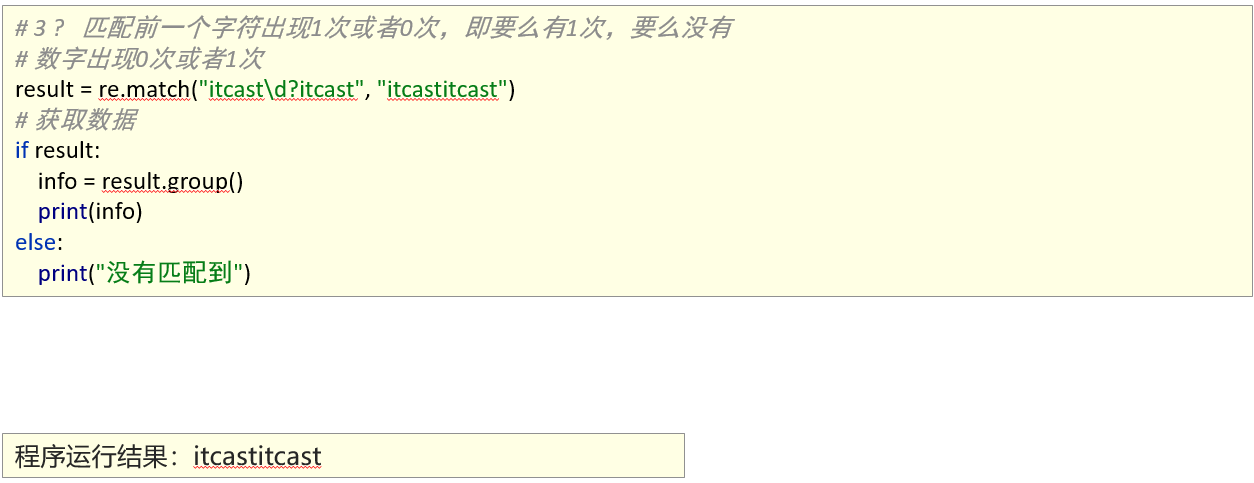
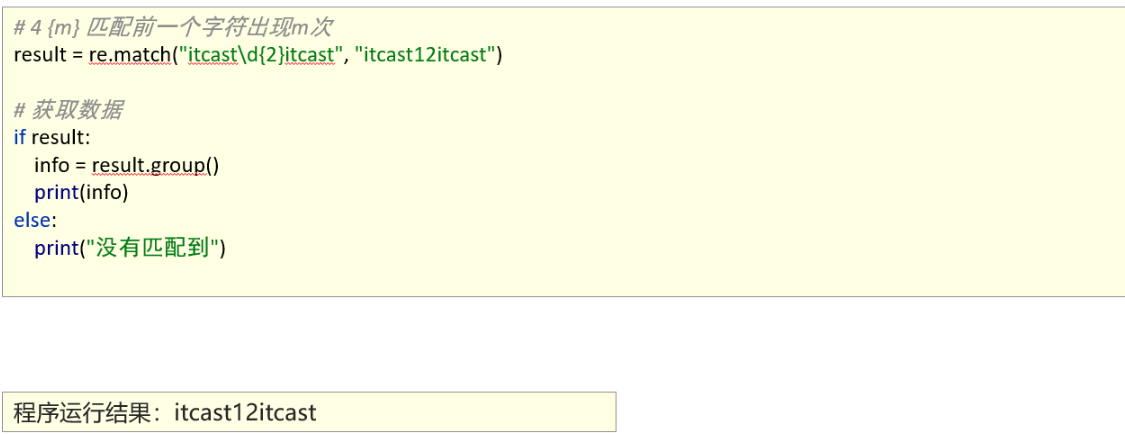
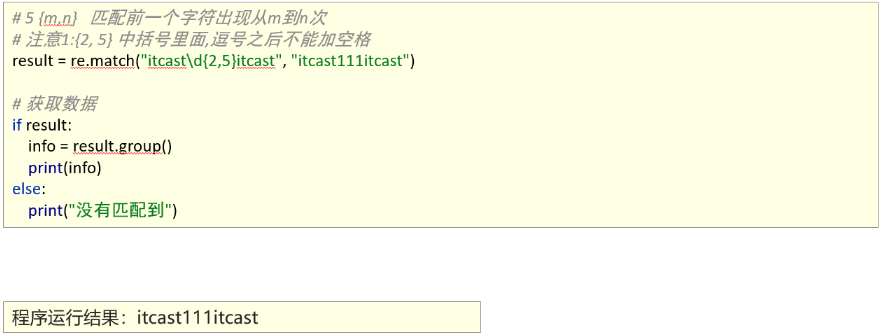
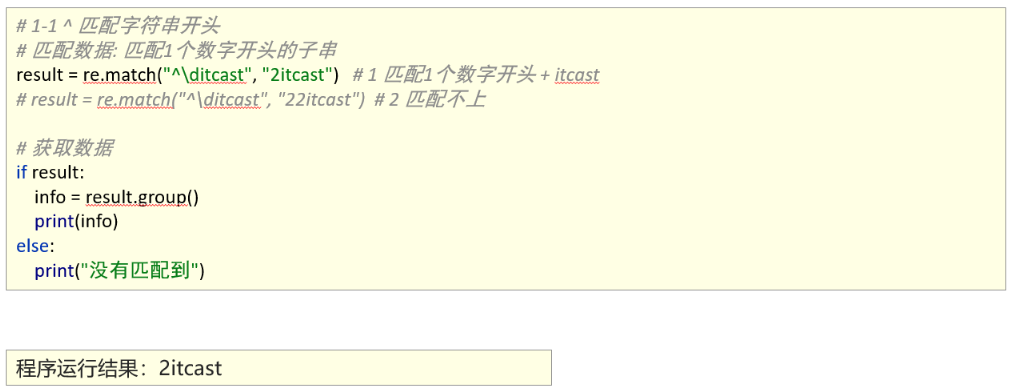
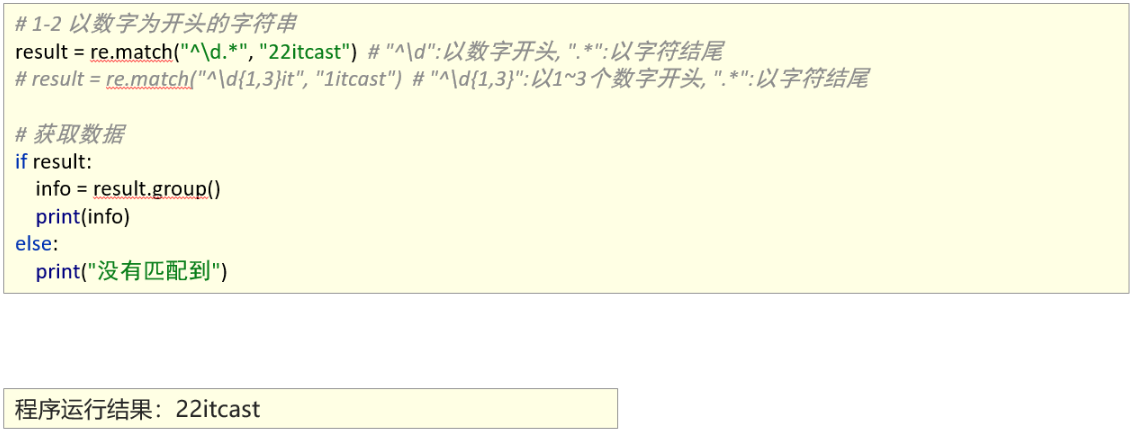
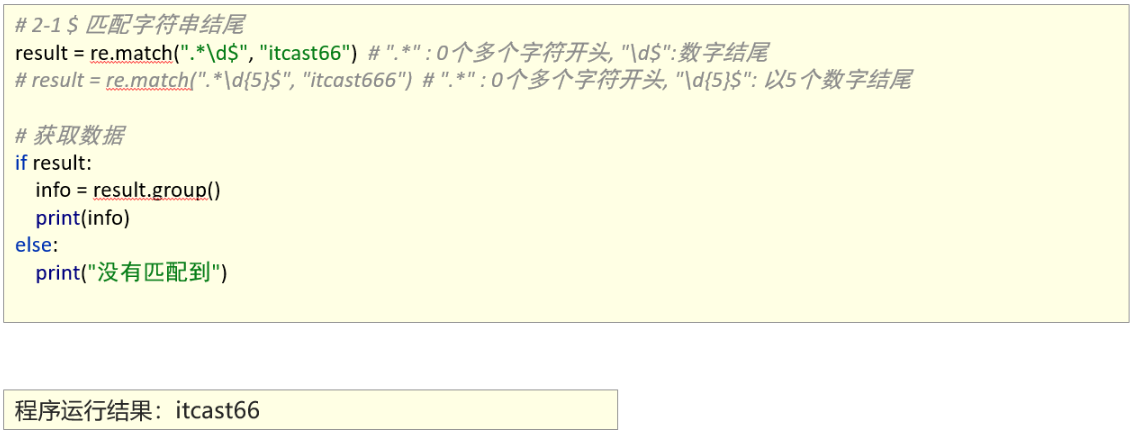
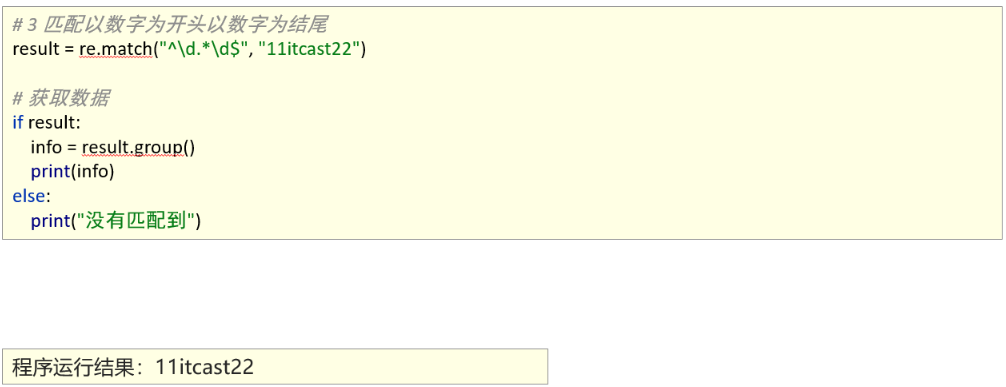
匹配首尾字符
1、能够使用re模块匹配指定字符串开头或者结尾

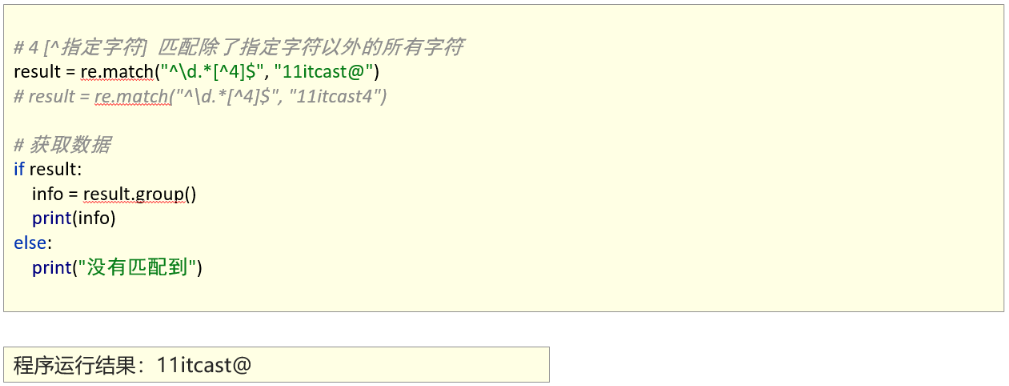
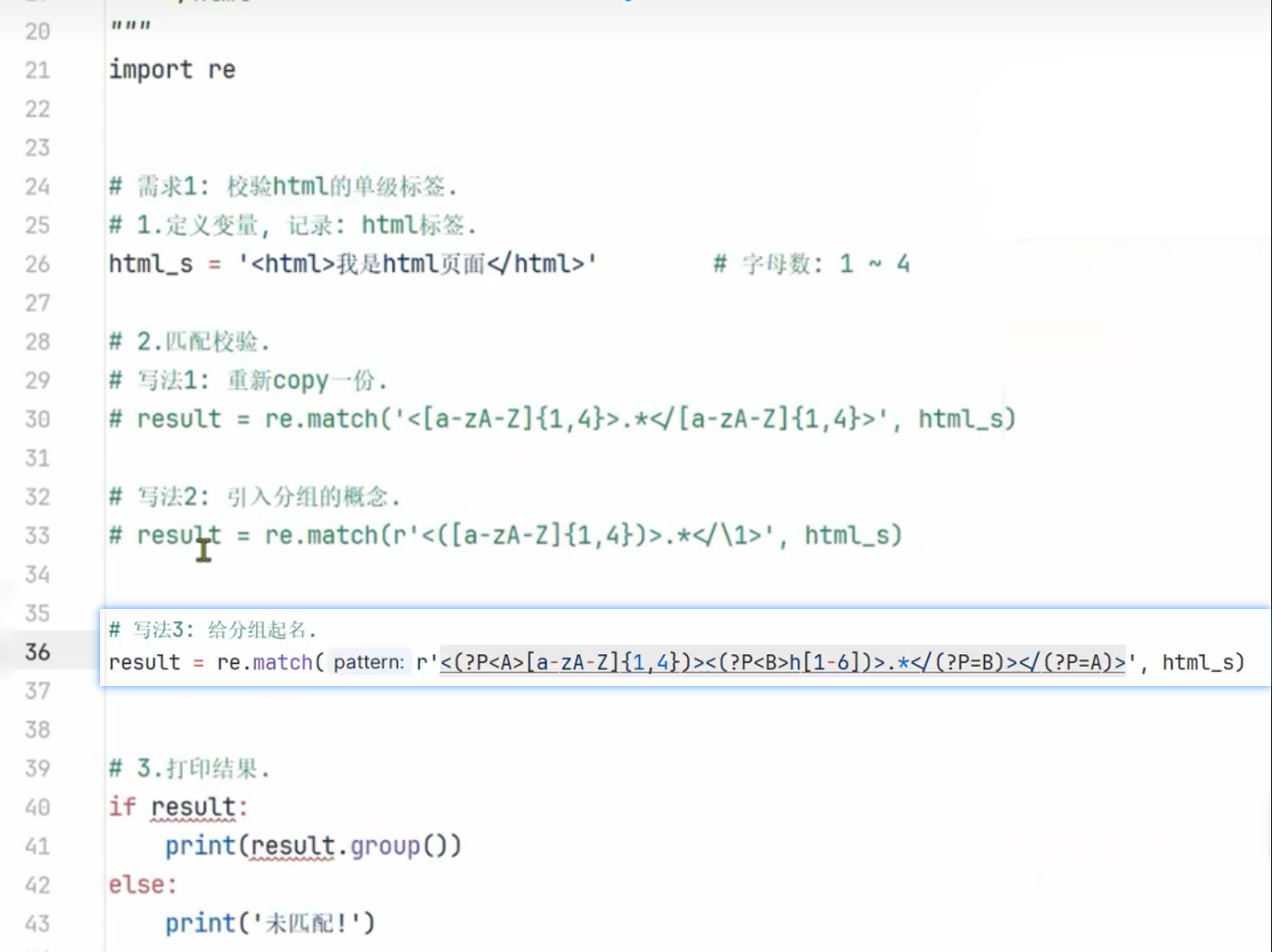
匹配分组
1、匹配分组
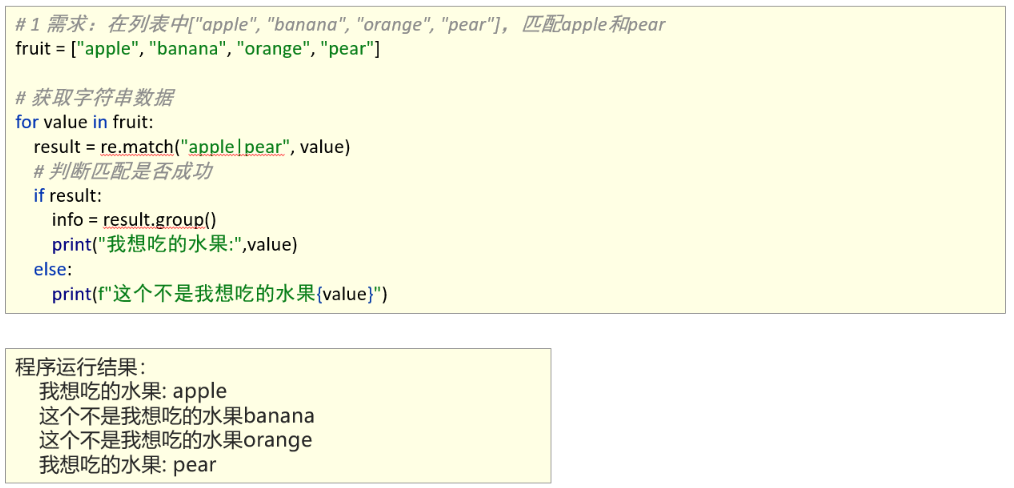
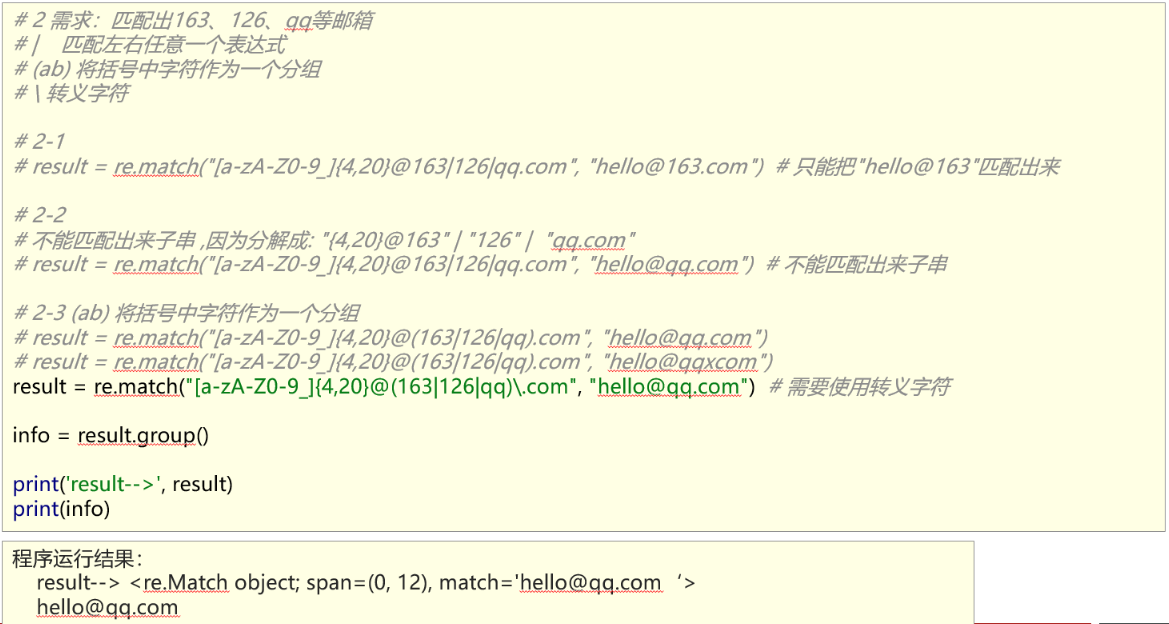

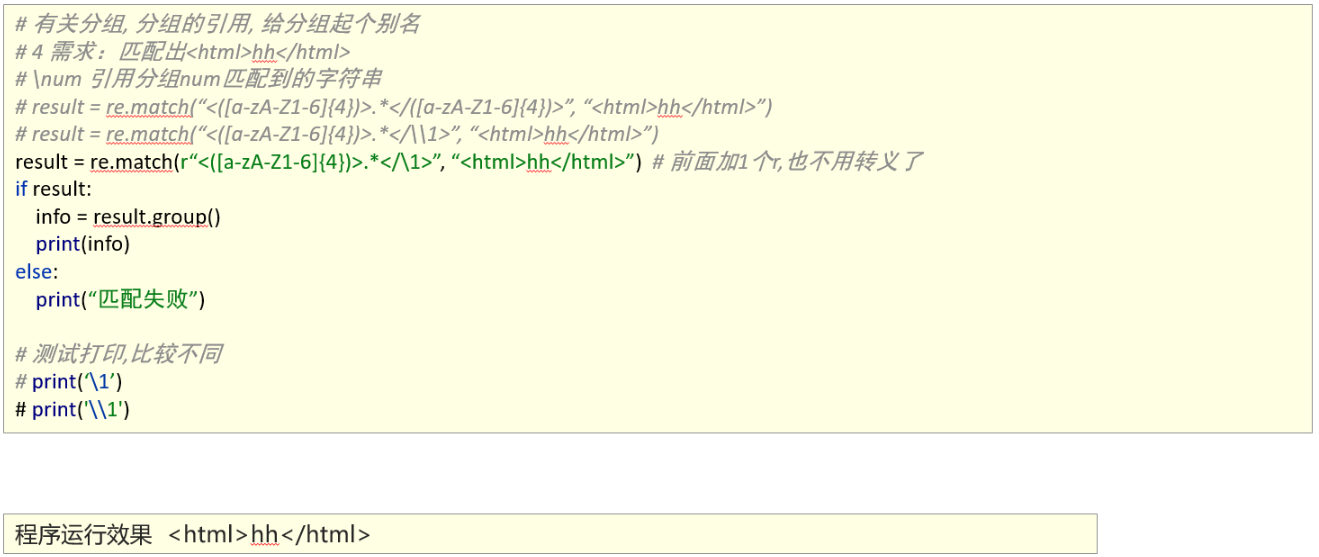
2、扩展
设置分组名: (?p<分组名>)
使用分组名: (?p=分组名)