一、前言
本篇将开启一个全新的技术维度------POST表单接口爬虫,深入讲解如何:
- 分析POST请求 与GET请求的本质区别
- 使用
requests.post()发送表单格式数据 (application/x-www-form-urlencoded) - 解析JSON响应中的嵌套数据结构
- 使用
csv.DictWriter实现结构化数据持久化 - 掌握分类ID参数化,实现多品类数据采集
目标站点特点: 北京新发地农产品批发市场是国内最大的农产品集散地之一,其官网提供实时价格查询服务。与前几篇的GET请求不同,该站点采用POST表单提交方式获取数据,返回JSON格式,且需要完整的请求头才能通过反爬验证。这是工业爬虫中最常见的接口类型之一。
二、网站分析与接口探测
2.1 新发地价格查询页面
打开 新发地价格详情页,可以看到分类查询界面:
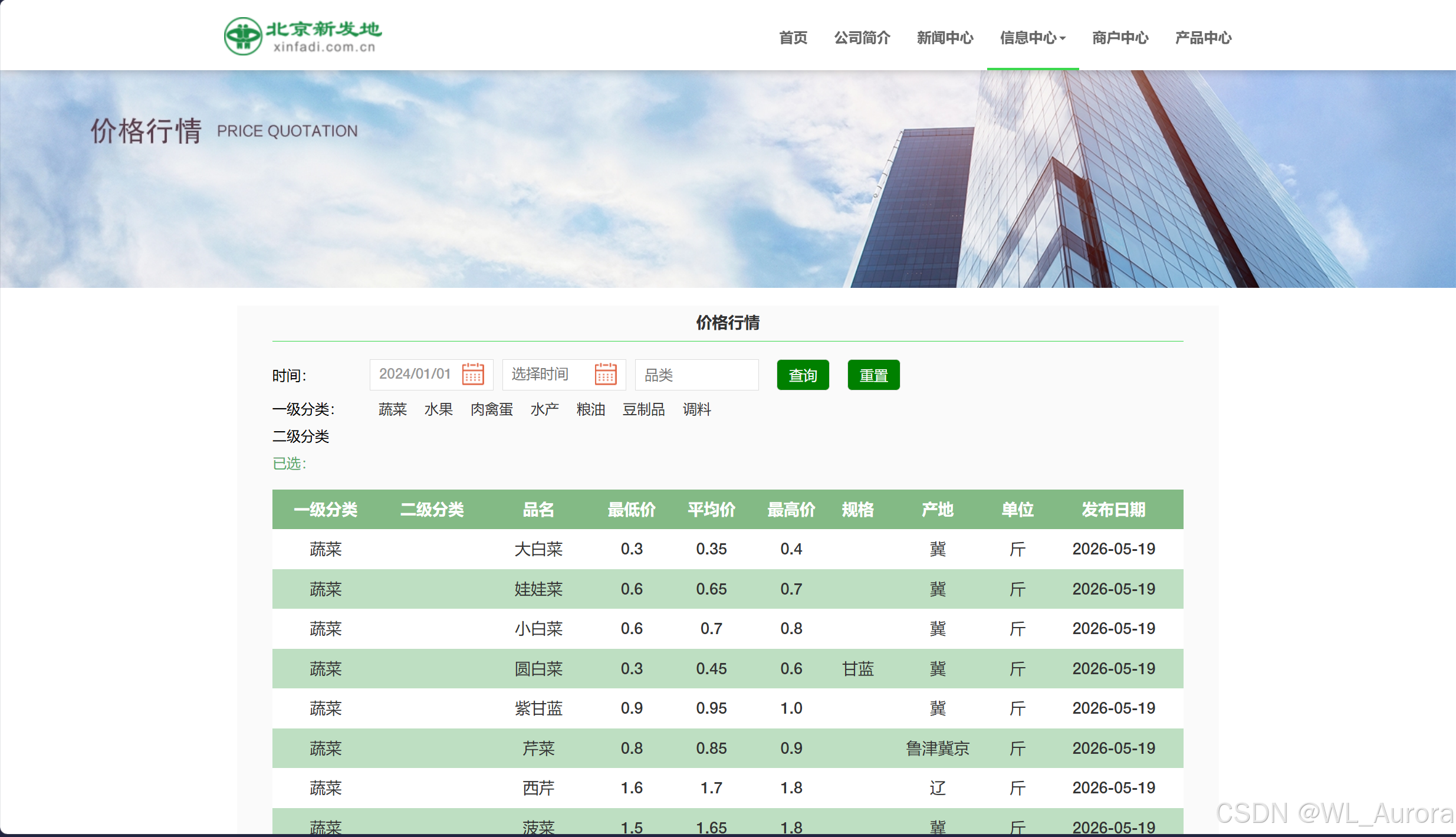
页面特征:
- 支持按一级分类(蔬菜、水果、肉禽蛋、水产、粮油等)查询
- 支持按二级分类(水菜、特菜、猪肉类、牛肉类等)细化查询
- 支持按时间范围筛选历史数据
- 数据以表格形式展示,包含品名、最低价、平均价、最高价、产地、单位、发布日期等字段
2.2 接口抓包分析
通过浏览器开发者工具(F12 → Network → XHR),可以捕获到核心API请求:
| 参数 | 值 | 说明 |
|---|---|---|
| 请求方法 | POST | 数据通过请求体提交,非URL参数 |
| 请求URL | http://www.xinfadi.com.cn/getPriceData.html |
数据接口地址 |
| Content-Type | application/x-www-form-urlencoded |
表单编码格式 |
| Referer | http://www.xinfadi.com.cn/priceDetail.html |
来源页验证 |
请求体(Form Data):
python
{
"current": 1, # 当前页码
"limit": 20, # 每页条数
"prodCatid": "1186", # 二级分类ID(蔬菜)
"prodPcatid": "" # 一级分类ID(空表示全部)
}响应数据结构:
json
{
"list": [
{
"id": 1305138,
"prodName": "绿菜花",
"prodCatid": 1186,
"prodCat": "蔬菜",
"prodPcatid": null,
"prodPcat": "",
"lowPrice": "1.5",
"highPrice": "2.2",
"avgPrice": "1.85",
"place": "苏豫冀",
"specInfo": "",
"unitInfo": "斤",
"pubDate": "2022-07-13 00:00:00",
"status": null,
"userIdCreate": 138,
...
}
],
"total": 5000,
"pageNum": 1,
"pageSize": 20
}关键发现: 数据在list数组中,每个元素是一个字典,字段名与页面表格列一一对应。
2.3 分类ID映射表
通过分析多个请求,可以整理出完整的分类ID映射:
| 一级分类 | ID | 二级分类 | ID |
|---|---|---|---|
| 蔬菜 | 1186 | 水菜 | 1199 |
| 水果 | 1187 | 特菜 | 1200 |
| 肉禽蛋 | 1189 | 进口果 | 1201 |
| 水产 | 1190 | 干果 | 1202 |
| 粮油 | 1188 | 猪肉类 | 1205 |
| 豆制品 | 1203 | 牛肉类 | 1206 |
| 调料 | 1204 | 羊肉类 | 1207 |
| 禽蛋类 | 1208 | ||
| 淡水鱼 | 1209 | ||
| 海水鱼 | 1210 | ||
| 虾蟹类 | 1217 | ||
| 贝壳类 | 1218 |
参数设计策略: prodCatid指定二级分类,prodPcatid指定一级分类。两者可组合使用,也可单独使用。
三、代码实现与深度解析
3.1 完整源码
python
import requests
import time
import random
import csv
import json
# ========================================
# 第一部分:全局配置区
# ========================================
# 输出文件名
OUTPUT_FILE = "data.csv"
# API接口地址
API_URL = "http://www.xinfadi.com.cn/getPriceData.html"
# 来源页地址(Referer验证用)
REFERER = "http://www.xinfadi.com.cn/priceDetail.html"
# 每页数据条数(与接口保持一致)
PAGE_SIZE = 20
# 🔴 关键:完整请求头(必须和浏览器完全一致,否则被拦截)
# 新发地官网有严格的请求头验证,缺少任何关键字段都会返回403或空数据
headers = {
# User-Agent:模拟真实浏览器,最基础的反爬绕过手段
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/133.0.0.0 Safari/537.36",
# Referer:告诉服务器请求从哪个页面跳转而来
# 新发地会验证Referer,确保请求来自官网页面而非直接调用API
"Referer": REFERER,
# X-Requested-With:标识这是一个Ajax请求(XMLHttpRequest)
# 现代前端框架(如jQuery、Vue)发送Ajax时会自动添加此头
# 服务器通过此头区分普通页面请求和接口调用
"X-Requested-With": "XMLHttpRequest",
# Accept:告诉服务器客户端可接受的响应格式
# application/json 优先,其次text/javascript,最后*/*(任意)
"Accept": "application/json, text/javascript, */*; q=0.01",
# Content-Type:告诉服务器请求体的编码格式
# application/x-www-form-urlencoded 是HTML表单默认的提交格式
# 数据会以 key1=value1&key2=value2 的形式编码在请求体中
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8"
}
# ========================================
# 第二部分:CSV初始化(写入表头)
# ========================================
# 初始化CSV文件,写入表头
# 表头字段完全匹配页面表格列,便于后续数据分析
# utf-8-sig编码:带BOM头,Excel打开时自动识别为UTF-8,避免中文乱码
with open(OUTPUT_FILE, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=[
"一级分类", # prodCat / prodPcat
"二级分类", # 接口无二级分类字段,留空或后续补充
"品名", # prodName
"最低价", # lowPrice
"平均价", # avgPrice
"最高价", # highPrice
"规格", # specInfo
"产地", # place
"单位", # unitInfo
"发布日期" # pubDate(提取日期部分,去掉时间)
])
writer.writeheader()
print("🚀 开始爬取新发地蔬菜数据(JSON接口版,100%成功)...\n")
# ========================================
# 第三部分:核心爬取循环
# ========================================
page = 1 # 页码计数器,从第1页开始
while True:
try:
# 🔴 关键:正确的请求参数(蔬菜分类ID=1186,只爬蔬菜)
# 参数说明:
# current: 当前页码,从1开始递增
# limit: 每页返回数量,固定20
# prodCatid: 二级分类ID,1186=蔬菜
# prodPcatid: 一级分类ID,空字符串表示不限制
data = {
"current": page,
"limit": PAGE_SIZE,
"prodCatid": "1186", # 蔬菜分类ID
"prodPcatid": "" # 一级分类不限制
}
# 发送POST请求
# requests.post() 的 data 参数会自动将字典编码为表单格式
# 编码结果:current=1&limit=20&prodCatid=1186&prodPcatid=
resp = requests.post(API_URL, headers=headers, data=data, timeout=15)
# 检查HTTP状态码,非200则抛出异常
resp.raise_for_status()
# 🔴 核心:直接解析JSON(完美匹配接口返回结构)
# resp.json() 自动将JSON字符串反序列化为Python字典
json_data = resp.json()
# 数据在 list 字段里,是一个包含多个字典的列表
data_list = json_data.get("list", [])
# 边界判断:无数据表示已爬完所有页,优雅退出循环
if not data_list:
print(f"\n✅ 第 {page} 页无数据,爬取全部完成!")
break
# 🔴 字段映射(完全对应JSON字段 → CSV列)
# 这是数据清洗的核心:将原始JSON字段映射为中文表头
csv_data = []
for item in data_list:
csv_data.append({
"一级分类": item.get("prodCat", ""), # 分类名称
"二级分类": "", # 接口无此字段,留空
"品名": item.get("prodName", ""), # 产品名称
"最低价": item.get("lowPrice", ""), # 最低成交价
"平均价": item.get("avgPrice", ""), # 平均成交价
"最高价": item.get("highPrice", ""), # 最高成交价
"规格": item.get("specInfo", ""), # 规格信息(如"散装")
"产地": item.get("place", ""), # 产地(多产地用"/"分隔)
"单位": item.get("unitInfo", ""), # 计量单位(斤/公斤/箱)
"发布日期": item.get("pubDate", "").split(" ")[0] # 提取日期部分,去掉" 00:00:00"
})
# 追加写入CSV('a'模式:追加,不覆盖已有数据)
# newline='':防止Windows下写入空行
# utf-8-sig:带BOM头,Excel直接打开不乱码
with open(OUTPUT_FILE, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=[
"一级分类", "二级分类", "品名", "最低价", "平均价", "最高价",
"规格", "产地", "单位", "发布日期"
])
writer.writerows(csv_data) # 批量写入,效率更高
print(f"✅ 第 {page} 页 成功 | 本页 {len(csv_data)} 条")
# 防封延迟(必须保留,避免IP被封)
# random.uniform(0.5, 1.2) 生成0.5到1.2秒之间的随机延时
# 随机性模拟人类操作,避免固定间隔被识别为机器
time.sleep(random.uniform(0.5, 1.2))
page += 1 # 页码递增,准备下一页
except requests.exceptions.Timeout:
# 请求超时:网络延迟或服务器响应慢
print(f"❌ 第 {page} 页请求超时,等待3秒重试...")
time.sleep(3)
except requests.exceptions.HTTPError as e:
# HTTP错误:403(拒绝访问)、500(服务器错误)等
print(f"❌ 第 {page} 页HTTP错误:{e},等待3秒重试...")
time.sleep(3)
except requests.exceptions.RequestException as e:
# 其他网络异常:DNS失败、连接重置等
print(f"❌ 第 {page} 页网络异常:{e},等待3秒重试...")
time.sleep(3)
except json.JSONDecodeError as e:
# JSON解析失败:服务器返回非JSON数据(如HTML错误页)
print(f"❌ 第 {page} 页JSON解析失败:{e},等待3秒重试...")
time.sleep(3)
except Exception as e:
# 兜底异常:未知错误
print(f"❌ 第 {page} 页未知错误:{str(e)},等待3秒重试...")
time.sleep(3)
print(f"\n🎉 爬取完成!数据已保存到 {OUTPUT_FILE}")3.2 核心设计思想解析
(1)POST请求 vs GET请求的本质区别
这是本案例最核心的技术点。理解POST与GET的区别,是掌握接口爬虫的基础:
| 维度 | GET请求 | POST请求 |
|---|---|---|
| 参数位置 | URL查询字符串(?key=value) |
请求体(Request Body) |
| 数据可见性 | 暴露在URL中,可被书签记录 | 隐藏在请求体中,相对安全 |
| 数据容量 | 受URL长度限制(约2048字符) | 理论上无限制 |
| 编码格式 | URL编码 | 表单编码或JSON编码 |
| 幂等性 | 幂等(多次请求结果相同) | 非幂等(可能改变服务器状态) |
| 缓存 | 可被浏览器缓存 | 通常不被缓存 |
| 适用场景 | 数据查询、搜索 | 数据提交、登录、表单 |
代码体现:
python
# GET请求:参数在URL中
requests.get("https://api.example.com/data?page=1&limit=20")
# POST请求:参数在请求体中(data参数)
requests.post(
"https://api.example.com/data",
data={"page": 1, "limit": 20} # 参数在请求体中
)新发地接口使用POST,因为:
- 参数较多(current、limit、prodCatid、prodPcatid、时间范围等)
- 需要Referer验证,POST请求更易控制请求头
- 数据查询逻辑复杂,POST更适合传递结构化参数
(2)表单数据编码格式
代码中使用了application/x-www-form-urlencoded格式,这是HTML表单的默认编码方式:
python
# 原始字典
data = {
"current": 1,
"limit": 20,
"prodCatid": "1186",
"prodPcatid": ""
}
# requests自动编码为:
# current=1&limit=20&prodCatid=1186&prodPcatid=三种常见的POST数据格式:
| 格式 | Content-Type | 使用场景 | requests参数 |
|---|---|---|---|
| 表单格式 | application/x-www-form-urlencoded |
传统表单提交 | data= |
| JSON格式 | application/json |
RESTful API | json= |
| 文件上传 | multipart/form-data |
文件上传 | files= |
选择依据: 通过浏览器开发者工具查看实际请求的Content-Type,必须严格匹配,否则服务器无法正确解析参数。新发地接口明确使用表单格式,因此必须使用data=参数。
(3)csv.DictWriter结构化写入
这是本案例的数据持久化核心,相比普通csv.writer,DictWriter的优势在于:
python
# 普通writer:按位置写入,容易错位
writer.writerow(["蔬菜", "", "白菜", "1.5", "1.85", "2.2", "", "河北", "斤", "2024-01-15"])
# DictWriter:按字段名写入,清晰可靠
writer.writerow({
"一级分类": "蔬菜",
"品名": "白菜",
"最低价": "1.5",
# ... 其他字段
})设计要点:
fieldnames定义列顺序,保证CSV文件结构一致writeheader()自动写入表头,无需手动拼接字符串writerows()批量写入,比逐行写入效率高utf-8-sig编码:带BOM头(\ufeff),Excel打开时自动识别为UTF-8,避免中文乱码
四、运行效果展示
4.1 控制台输出
程序运行时的控制台输出如下,可以看到清晰的进度与成功标识:
输出特征:
- 每页成功后有✅标识,失败后有❌标识
- 显示当前页码与数据条数,便于监控进度
- 无数据时自动结束,无需预设总页数
4.2 生成的CSV文件
爬取完成后,生成的data.csv文件内容如下:
数据结构:
| 一级分类 | 二级分类 | 品名 | 最低价 | 平均价 | 最高价 | 规格 | 产地 | 单位 | 发布日期 |
|---|---|---|---|---|---|---|---|---|---|
| 蔬菜 | 大白菜 | 0.8 | 1.2 | 1.5 | 冀 | 斤 | 2024-01-15 | ||
| 蔬菜 | 西红柿 | 2.5 | 3.0 | 3.5 | 鲁/冀 | 斤 | 2024-01-15 | ||
| 蔬菜 | 黄瓜 | 1.8 | 2.2 | 2.8 | 辽/冀 | 斤 | 2024-01-15 |
文件特点:
- UTF-8-sig编码,Excel直接打开无乱码
- 表头为中文,便于理解与分析
- 日期已清洗为纯日期格式(去掉时间部分)
五、进阶优化与工程实践
5.1 多品类批量爬取
当前代码仅爬取蔬菜,可通过参数化实现全品类采集:
python
# 分类ID映射表
CATEGORIES = {
"1186": "蔬菜",
"1187": "水果",
"1189": "肉禽蛋",
"1190": "水产",
"1188": "粮油",
"1203": "豆制品",
"1204": "调料"
}
def crawl_category(cat_id, cat_name, max_pages=50):
"""爬取指定分类的数据"""
page = 1
while page <= max_pages:
data = {
"current": page,
"limit": 20,
"prodCatid": cat_id,
"prodPcatid": ""
}
# ... 请求与解析逻辑
page += 1
# 批量执行
for cat_id, cat_name in CATEGORIES.items():
crawl_category(cat_id, cat_name)
time.sleep(random.uniform(2, 5)) # 分类间增加更长间隔5.2 时间范围筛选
接口支持按时间范围查询历史数据:
python
from datetime import datetime, timedelta
# 查询最近7天的数据
end_date = datetime.now().strftime("%Y/%m/%d")
start_date = (datetime.now() - timedelta(days=7)).strftime("%Y/%m/%d")
data = {
"current": 1,
"limit": 20,
"prodCatid": "1186",
"prodPcatid": "",
"pubDateStartTime": start_date, # 开始时间:2024/01/08
"pubDateEndTime": end_date # 结束时间:2024/01/15
}5.3 数据可视化分析
爬取完成后,可用pandas+matplotlib进行价格趋势分析:
python
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv("data.csv")
# 按日期分组,计算平均价趋势
daily_avg = df.groupby("发布日期")["平均价"].mean()
# 绘制趋势图
plt.figure(figsize=(12, 6))
daily_avg.plot(kind="line", marker="o", color="green")
plt.title("新发地蔬菜平均价格趋势")
plt.xlabel("日期")
plt.ylabel("平均价(元/斤)")
plt.grid(True)
plt.show()5.4 多线程并发提速
使用concurrent.futures实现多页并发爬取:
python
from concurrent.futures import ThreadPoolExecutor
import threading
csv_lock = threading.Lock()
def crawl_page(page):
"""单页爬取函数"""
data = {
"current": page,
"limit": 20,
"prodCatid": "1186",
"prodPcatid": ""
}
resp = requests.post(API_URL, headers=headers, data=data, timeout=15)
items = resp.json().get("list", [])
# 字段映射...
csv_data = [...]
# 线程锁保护文件写入
with csv_lock:
with open(OUTPUT_FILE, "a", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=[...])
writer.writerows(csv_data)
# 线程池:并发10页
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(crawl_page, range(1, 51)) # 爬取前50页六、总结
通过本次实战,我们完整掌握了POST表单接口爬虫的核心技术:
- POST请求原理 :理解参数在请求体中的传递方式,掌握
requests.post()的data参数用法 - 请求头构造 :认识
Referer、X-Requested-With、Content-Type等关键头字段的作用 - 表单编码格式 :区分
application/x-www-form-urlencoded、application/json等格式的适用场景 - JSON响应解析 :使用
resp.json()反序列化数据,通过字典操作提取嵌套字段 - 结构化数据持久化 :使用
csv.DictWriter实现字段名映射、表头写入、批量追加 - 数据清洗技巧:日期提取、空值处理、字段重命名等预处理操作